
extension-gen-ai
Looker Extension GenAI - using LLMs to make exploration easier and getting dashboard insights
Stars: 59

The Looker GenAI Extension provides code examples and resources for building a Looker Extension that integrates with Vertex AI Large Language Models (LLMs). Users can leverage the power of LLMs to enhance data exploration and analysis within Looker. The extension offers generative explore functionality to ask natural language questions about data and generative insights on dashboards to analyze data by asking questions. It leverages components like BQML Remote Models, BQML Remote UDF with Vertex AI, and Custom Fine Tune Model for different integration options. Deployment involves setting up infrastructure with Terraform and deploying the Looker Extension by creating a Looker project, copying extension files, configuring BigQuery connection, connecting to Git, and testing the extension. Users can save example prompts and configure user settings for the extension. Development of the Looker Extension environment includes installing dependencies, starting the development server, and building for production.
README:
This repository provides code examples and resources for building a Looker Extension that integrates with Vertex AI Large Language Models (LLMs). This extension allows users to leverage the power of LLMs to enhance data exploration and analysis within Looker.
Note: For the Looker Explore Assistant, visit https://github.com/looker-open-source/looker-explore-assistant/.
The Looker GenAI Extension offers two key functionalities:
1. Generative Explore:
- Ask natural language questions about your data in Looker Explores.
- The LLM will automatically generate explores with the appropriate fields, filters, sorts, pivots, and limits.
- Visualize results using a variety of charts and dashboards.

2. Generative Insights on Dashboards:
- Analyze data from a Looker dashboard by asking natural language questions.
- The LLM considers all data from the dashboard tiles for context-aware insights.

The solution leverages the following components:

The extension supports multiple LLM integration options:
- BQML Remote Models: (Default) Uses native BigQuery ML integration for simple and quick deployment.
- BQML Remote UDF with Vertex AI: (Recommended) Uses Google Cloud Functions with Vertex AI for greater flexibility and production-ready scenarios.
- Custom Fine Tune Model: (Optional) Enables training a customized fine-tuned model for tailored responses.
Workflow for BQML Remote Models:

Workflow for BQML Remote UDF with Vertex AI:

Workflow for Custom Fine Tune Model:

This section guides you through deploying the necessary infrastructure using Terraform.
-
Clone the Repository:
cloudshell_open --repo_url "https://github.com/looker-open-source/extension-gen-ai" --page "shell" --open_workspace "deployment/terraform" --force_new_clone
Alternatively, open directly in Cloud Shell:
-
Set Project ID:
gcloud config set project PROJECT-ID -
IAM Roles:
- Ensure the following IAM roles are assigned at the project level:
roles/browserroles/cloudfunctions.developerroles/iam.serviceAccountUserroles/storage.adminroles/bigquery.userroles/bigquery.connectionAdminroles/resourcemanager.projectIamAdminroles/iam.serviceAccountCreator
For more detailed IAM information, see deployment/terraform/iam-issues.md.
- Ensure the following IAM roles are assigned at the project level:
-
Create Terraform State Buckets:
sh scripts/create-state-bucket.sh
-
Initialize Terraform Modules:
terraform init
-
Deploy Resources:
terraform apply -var="project_id=YOUR_PROJECT_ID"

-
Create Looker Project:
- Log into Looker and create a new project named
looker-genai. - Use "Blank Project" as the "Starting Point."
- Log into Looker and create a new project named
-
Copy Extension Files:
- Drag and drop the following files from the
looker-project-structurefolder into your Looker project:manifest.lkmllooker-genai.modelbundle.js
- Drag and drop the following files from the
-
Configure BigQuery Connection:
- Modify
looker-genai.modelto include a Looker connection to BigQuery. - You can either create a new connection or use an existing one. If using an existing connection, ensure the service account has the necessary IAM permissions.
- Modify
-
Connect to Git:
- Set up a Git repository and connect your Looker project to it.
-
Commit and Deploy:
- Commit your changes and deploy them to production.
-
Project Permissions:
- Grant the project permission to use the selected BigQuery connection.
-
Service Account Permissions:
- Verify that the service account associated with the connection has permission to access the
llmdataset in your GCP project.
- Verify that the service account associated with the connection has permission to access the
-
Test and Debug:
- Test the extension and use the browser's Web Developer Console to troubleshoot any errors.
- Review the
explore_logstable in BigQuery to monitor queries.
Store example prompts in the llm.explore_prompts table:
INSERT INTO `llm.explore_prompts`
VALUES("Top 3 brands in sales", "What are the top 3 brands that had the most sales price in the last 4 months?", "thelook.order_items", "explore")Values:
name of exampleprompt-
model.explore(LookML explore name) -
type(exploreordashboard)
Settings are managed in the llm.settings table. You can adjust these settings in the "Developer Settings" tab of the extension.
- Console Log Level: Controls the verbosity of logs.
- Use Native BQML or Remote UDF: Choose between native BigQuery ML functions or custom remote UDFs.
- Custom Prompt: Optionally set a custom prompt for your user ID.
Modify Settings with SQL:
-
Change settings for all users:
UPDATE `llm.settings` SET config = (SELECT config from `llm.settings` WHERE userId = "YOUR_USER_ID") WHERE True
-
Change settings for the default user:
UPDATE `llm.settings` SET config = (SELECT config from `llm.settings` WHERE userId = "YOUR_USER_ID") WHERE userId IS NULL
yarn installyarn developThe development server will run at https://localhost:8080/bundle.js.

yarn buildThis will generate the dist/bundle.js file. Replace the URL in your LookML manifest with the production bundle.js.
This section describes how to train and deploy a custom fine-tuned model using the provided Terraform scripts.
-
Infrastructure Setup:
- The provided Terraform code sets up Vertex AI, Cloud Functions, and BigQuery resources.
- It also includes the necessary IAM permissions.
-
Fine-Tuning:
- Execute the Cloud Workflow:
gcloud workflows execute fine_tuning_model
- Execute the Cloud Workflow:
-
Update BigQuery Endpoint:
- Modify the BigQuery endpoint to point to your custom fine-tuned model.
Note: The code for fine-tuned model integration is currently in progress and needs to be refactored for optimal use.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for extension-gen-ai
Similar Open Source Tools
extension-gen-ai
The Looker GenAI Extension provides code examples and resources for building a Looker Extension that integrates with Vertex AI Large Language Models (LLMs). Users can leverage the power of LLMs to enhance data exploration and analysis within Looker. The extension offers generative explore functionality to ask natural language questions about data and generative insights on dashboards to analyze data by asking questions. It leverages components like BQML Remote Models, BQML Remote UDF with Vertex AI, and Custom Fine Tune Model for different integration options. Deployment involves setting up infrastructure with Terraform and deploying the Looker Extension by creating a Looker project, copying extension files, configuring BigQuery connection, connecting to Git, and testing the extension. Users can save example prompts and configure user settings for the extension. Development of the Looker Extension environment includes installing dependencies, starting the development server, and building for production.

langmanus
LangManus is a community-driven AI automation framework that combines language models with specialized tools for tasks like web search, crawling, and Python code execution. It implements a hierarchical multi-agent system with agents like Coordinator, Planner, Supervisor, Researcher, Coder, Browser, and Reporter. The framework supports LLM integration, search and retrieval tools, Python integration, workflow management, and visualization. LangManus aims to give back to the open-source community and welcomes contributions in various forms.

company-research-agent
Agentic Company Researcher is a multi-agent tool that generates comprehensive company research reports by utilizing a pipeline of AI agents to gather, curate, and synthesize information from various sources. It features multi-source research, AI-powered content filtering, real-time progress streaming, dual model architecture, modern React frontend, and modular architecture. The tool follows an agentic framework with specialized research and processing nodes, leverages separate models for content generation, uses a content curation system for relevance scoring and document processing, and implements a real-time communication system via WebSocket connections. Users can set up the tool quickly using the provided setup script or manually, and it can also be deployed using Docker and Docker Compose. The application can be used for local development and deployed to various cloud platforms like AWS Elastic Beanstalk, Docker, Heroku, and Google Cloud Run.
RA.Aid
RA.Aid is an AI software development agent powered by `aider` and advanced reasoning models like `o1`. It combines `aider`'s code editing capabilities with LangChain's agent-based task execution framework to provide an intelligent assistant for research, planning, and implementation of multi-step development tasks. It handles complex programming tasks by breaking them down into manageable steps, running shell commands automatically, and leveraging expert reasoning models like OpenAI's o1. RA.Aid is designed for everyday software development, offering features such as multi-step task planning, automated command execution, and the ability to handle complex programming tasks beyond single-shot code edits.

maiar-ai
MAIAR is a composable, plugin-based AI agent framework designed to abstract data ingestion, decision-making, and action execution into modular plugins. It enables developers to define triggers and actions as standalone plugins, while the core runtime handles decision-making dynamically. This framework offers extensibility, composability, and model-driven behavior, allowing seamless addition of new functionality. MAIAR's architecture is influenced by Unix pipes, ensuring highly composable plugins, dynamic execution pipelines, and transparent debugging. It remains declarative and extensible, allowing developers to build complex AI workflows without rigid architectures.
rag-gpt
RAG-GPT is a tool that allows users to quickly launch an intelligent customer service system with Flask, LLM, and RAG. It includes frontend, backend, and admin console components. The tool supports cloud-based and local LLMs, enables deployment of conversational service robots in minutes, integrates diverse knowledge bases, offers flexible configuration options, and features an attractive user interface.
manifold
Manifold is a powerful platform for workflow automation using AI models. It supports text generation, image generation, and retrieval-augmented generation, integrating seamlessly with popular AI endpoints. Additionally, Manifold provides robust semantic search capabilities using PGVector combined with the SEFII engine. It is under active development and not production-ready.

code2prompt
Code2Prompt is a powerful command-line tool that generates comprehensive prompts from codebases, designed to streamline interactions between developers and Large Language Models (LLMs) for code analysis, documentation, and improvement tasks. It bridges the gap between codebases and LLMs by converting projects into AI-friendly prompts, enabling users to leverage AI for various software development tasks. The tool offers features like holistic codebase representation, intelligent source tree generation, customizable prompt templates, smart token management, Gitignore integration, flexible file handling, clipboard-ready output, multiple output options, and enhanced code readability.

AutoAgent
AutoAgent is a fully-automated and zero-code framework that enables users to create and deploy LLM agents through natural language alone. It is a top performer on the GAIA Benchmark, equipped with a native self-managing vector database, and allows for easy creation of tools, agents, and workflows without any coding. AutoAgent seamlessly integrates with a wide range of LLMs and supports both function-calling and ReAct interaction modes. It is designed to be dynamic, extensible, customized, and lightweight, serving as a personal AI assistant.
pipecat-flows
Pipecat Flows is a framework designed for building structured conversations in AI applications. It allows users to create both predefined conversation paths and dynamically generated flows, handling state management and LLM interactions. The framework includes a Python module for building conversation flows and a visual editor for designing and exporting flow configurations. Pipecat Flows is suitable for scenarios such as customer service scripts, intake forms, personalized experiences, and complex decision trees.
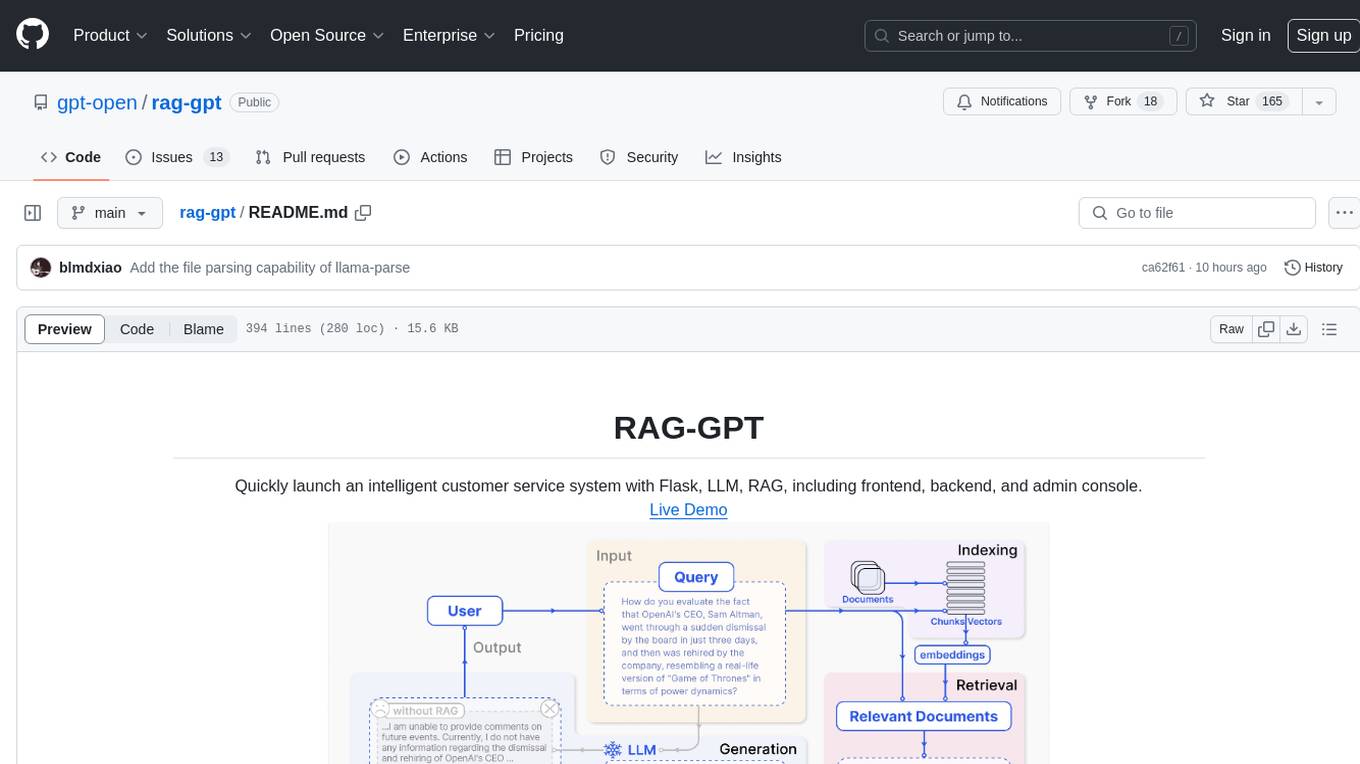
rag-gpt
RAG-GPT is a tool that allows users to quickly launch an intelligent customer service system with Flask, LLM, and RAG. It includes frontend, backend, and admin console components. The tool supports cloud-based and local LLMs, offers quick setup for conversational service robots, integrates diverse knowledge bases, provides flexible configuration options, and features an attractive user interface.

DevoxxGenieIDEAPlugin
Devoxx Genie is a Java-based IntelliJ IDEA plugin that integrates with local and cloud-based LLM providers to aid in reviewing, testing, and explaining project code. It supports features like code highlighting, chat conversations, and adding files/code snippets to context. Users can modify REST endpoints and LLM parameters in settings, including support for cloud-based LLMs. The plugin requires IntelliJ version 2023.3.4 and JDK 17. Building and publishing the plugin is done using Gradle tasks. Users can select an LLM provider, choose code, and use commands like review, explain, or generate unit tests for code analysis.
action_mcp
Action MCP is a powerful tool for managing and automating your cloud infrastructure. It provides a user-friendly interface to easily create, update, and delete resources on popular cloud platforms. With Action MCP, you can streamline your deployment process, reduce manual errors, and improve overall efficiency. The tool supports various cloud providers and offers a wide range of features to meet your infrastructure management needs. Whether you are a developer, system administrator, or DevOps engineer, Action MCP can help you simplify and optimize your cloud operations.
Toolify
Toolify is a middleware proxy that empowers Large Language Models (LLMs) and OpenAI API interfaces by enabling function calling capabilities. It acts as an intermediary between applications and LLM APIs, injecting prompts and parsing tool calls from the model's response. Key features include universal function calling, multiple function calls support, flexible initiation, compatibility with

open-webui-tools
Open WebUI Tools Collection is a set of tools for structured planning, arXiv paper search, Hugging Face text-to-image generation, prompt enhancement, and multi-model conversations. It enhances LLM interactions with academic research, image generation, and conversation management. Tools include arXiv Search Tool and Hugging Face Image Generator. Function Pipes like Planner Agent offer autonomous plan generation and execution. Filters like Prompt Enhancer improve prompt quality. Installation and configuration instructions are provided for each tool and pipe.
code-assistant
Code Assistant is an AI coding tool built in Rust that offers command-line and graphical interfaces for autonomous code analysis and modification. It supports multi-modal tool execution, real-time streaming interface, session-based project management, multiple interface options, and intelligent project exploration. The tool provides auto-loaded repository guidance and allows for project configuration with format-on-save feature. Users can interact with the tool in GUI, terminal, or MCP server mode, and configure LLM providers for advanced options. The architecture highlights adaptive tool syntax, smart tool filtering, and multi-threaded streaming for efficient performance. Contributions are welcome, and the roadmap includes features like block replacing in changed files, compact tool use failures, UI improvements, memory tools, security enhancements, fuzzy matching search blocks, editing user messages, and selecting in messages.
For similar tasks
extension-gen-ai
The Looker GenAI Extension provides code examples and resources for building a Looker Extension that integrates with Vertex AI Large Language Models (LLMs). Users can leverage the power of LLMs to enhance data exploration and analysis within Looker. The extension offers generative explore functionality to ask natural language questions about data and generative insights on dashboards to analyze data by asking questions. It leverages components like BQML Remote Models, BQML Remote UDF with Vertex AI, and Custom Fine Tune Model for different integration options. Deployment involves setting up infrastructure with Terraform and deploying the Looker Extension by creating a Looker project, copying extension files, configuring BigQuery connection, connecting to Git, and testing the extension. Users can save example prompts and configure user settings for the extension. Development of the Looker Extension environment includes installing dependencies, starting the development server, and building for production.
Forza-Mods-AIO
Forza Mods AIO is a free and open-source tool that enhances the gaming experience in Forza Horizon 4 and 5. It offers a range of time-saving and quality-of-life features, making gameplay more enjoyable and efficient. The tool is designed to streamline various aspects of the game, improving user satisfaction and overall enjoyment.

hass-ollama-conversation
The Ollama Conversation integration adds a conversation agent powered by Ollama in Home Assistant. This agent can be used in automations to query information provided by Home Assistant about your house, including areas, devices, and their states. Users can install the integration via HACS and configure settings such as API timeout, model selection, context size, maximum tokens, and other parameters to fine-tune the responses generated by the AI language model. Contributions to the project are welcome, and discussions can be held on the Home Assistant Community platform.

crawl4ai
Crawl4AI is a powerful and free web crawling service that extracts valuable data from websites and provides LLM-friendly output formats. It supports crawling multiple URLs simultaneously, replaces media tags with ALT, and is completely free to use and open-source. Users can integrate Crawl4AI into Python projects as a library or run it as a standalone local server. The tool allows users to crawl and extract data from specified URLs using different providers and models, with options to include raw HTML content, force fresh crawls, and extract meaningful text blocks. Configuration settings can be adjusted in the `crawler/config.py` file to customize providers, API keys, chunk processing, and word thresholds. Contributions to Crawl4AI are welcome from the open-source community to enhance its value for AI enthusiasts and developers.
MaterialSearch
MaterialSearch is a tool for searching local images and videos using natural language. It provides functionalities such as text search for images, image search for images, text search for videos (providing matching video clips), image search for videos (searching for the segment in a video through a screenshot), image-text similarity calculation, and Pexels video search. The tool can be deployed through the source code or Docker image, and it supports GPU acceleration. Users can configure the tool through environment variables or a .env file. The tool is still under development, and configurations may change frequently. Users can report issues or suggest improvements through issues or pull requests.
tenere
Tenere is a TUI interface for Language Model Libraries (LLMs) written in Rust. It provides syntax highlighting, chat history, saving chats to files, Vim keybindings, copying text from/to clipboard, and supports multiple backends. Users can configure Tenere using a TOML configuration file, set key bindings, and use different LLMs such as ChatGPT, llama.cpp, and ollama. Tenere offers default key bindings for global and prompt modes, with features like starting a new chat, saving chats, scrolling, showing chat history, and quitting the app. Users can interact with the prompt in different modes like Normal, Visual, and Insert, with various key bindings for navigation, editing, and text manipulation.
openkore
OpenKore is a custom client and intelligent automated assistant for Ragnarok Online. It is a free, open source, and cross-platform program (Linux, Windows, and MacOS are supported). To run OpenKore, you need to download and extract it or clone the repository using Git. Configure OpenKore according to the documentation and run openkore.pl to start. The tool provides a FAQ section for troubleshooting, guidelines for reporting issues, and information about botting status on official servers. OpenKore is developed by a global team, and contributions are welcome through pull requests. Various community resources are available for support and communication. Users are advised to comply with the GNU General Public License when using and distributing the software.
QA-Pilot
QA-Pilot is an interactive chat project that leverages online/local LLM for rapid understanding and navigation of GitHub code repository. It allows users to chat with GitHub public repositories using a git clone approach, store chat history, configure settings easily, manage multiple chat sessions, and quickly locate sessions with a search function. The tool integrates with `codegraph` to view Python files and supports various LLM models such as ollama, openai, mistralai, and localai. The project is continuously updated with new features and improvements, such as converting from `flask` to `fastapi`, adding `localai` API support, and upgrading dependencies like `langchain` and `Streamlit` to enhance performance.
For similar jobs

llmops-promptflow-template
LLMOps with Prompt flow is a template and guidance for building LLM-infused apps using Prompt flow. It provides centralized code hosting, lifecycle management, variant and hyperparameter experimentation, A/B deployment, many-to-many dataset/flow relationships, multiple deployment targets, comprehensive reporting, BYOF capabilities, configuration-based development, local prompt experimentation and evaluation, endpoint testing, and optional Human-in-loop validation. The tool is customizable to suit various application needs.

azure-search-vector-samples
This repository provides code samples in Python, C#, REST, and JavaScript for vector support in Azure AI Search. It includes demos for various languages showcasing vectorization of data, creating indexes, and querying vector data. Additionally, it offers tools like Azure AI Search Lab for experimenting with AI-enabled search scenarios in Azure and templates for deploying custom chat-with-your-data solutions. The repository also features documentation on vector search, hybrid search, creating and querying vector indexes, and REST API references for Azure AI Search and Azure OpenAI Service.

geti-sdk
The Intel® Geti™ SDK is a python package that enables teams to rapidly develop AI models by easing the complexities of model development and enhancing collaboration between teams. It provides tools to interact with an Intel® Geti™ server via the REST API, allowing for project creation, downloading, uploading, deploying for local inference with OpenVINO, setting project and model configuration, launching and monitoring training jobs, and media upload and prediction. The SDK also includes tutorial-style Jupyter notebooks demonstrating its usage.

booster
Booster is a powerful inference accelerator designed for scaling large language models within production environments or for experimental purposes. It is built with performance and scaling in mind, supporting various CPUs and GPUs, including Nvidia CUDA, Apple Metal, and OpenCL cards. The tool can split large models across multiple GPUs, offering fast inference on machines with beefy GPUs. It supports both regular FP16/FP32 models and quantised versions, along with popular LLM architectures. Additionally, Booster features proprietary Janus Sampling for code generation and non-English languages.

xFasterTransformer
xFasterTransformer is an optimized solution for Large Language Models (LLMs) on the X86 platform, providing high performance and scalability for inference on mainstream LLM models. It offers C++ and Python APIs for easy integration, along with example codes and benchmark scripts. Users can prepare models in a different format, convert them, and use the APIs for tasks like encoding input prompts, generating token ids, and serving inference requests. The tool supports various data types and models, and can run in single or multi-rank modes using MPI. A web demo based on Gradio is available for popular LLM models like ChatGLM and Llama2. Benchmark scripts help evaluate model inference performance quickly, and MLServer enables serving with REST and gRPC interfaces.

amazon-transcribe-live-call-analytics
The Amazon Transcribe Live Call Analytics (LCA) with Agent Assist Sample Solution is designed to help contact centers assess and optimize caller experiences in real time. It leverages Amazon machine learning services like Amazon Transcribe, Amazon Comprehend, and Amazon SageMaker to transcribe and extract insights from contact center audio. The solution provides real-time supervisor and agent assist features, integrates with existing contact centers, and offers a scalable, cost-effective approach to improve customer interactions. The end-to-end architecture includes features like live call transcription, call summarization, AI-powered agent assistance, and real-time analytics. The solution is event-driven, ensuring low latency and seamless processing flow from ingested speech to live webpage updates.

ai-lab-recipes
This repository contains recipes for building and running containerized AI and LLM applications with Podman. It provides model servers that serve machine-learning models via an API, allowing developers to quickly prototype new AI applications locally. The recipes include components like model servers and AI applications for tasks such as chat, summarization, object detection, etc. Images for sample applications and models are available in `quay.io`, and bootable containers for AI training on Linux OS are enabled.

XLearning
XLearning is a scheduling platform for big data and artificial intelligence, supporting various machine learning and deep learning frameworks. It runs on Hadoop Yarn and integrates frameworks like TensorFlow, MXNet, Caffe, Theano, PyTorch, Keras, XGBoost. XLearning offers scalability, compatibility, multiple deep learning framework support, unified data management based on HDFS, visualization display, and compatibility with code at native frameworks. It provides functions for data input/output strategies, container management, TensorBoard service, and resource usage metrics display. XLearning requires JDK >= 1.7 and Maven >= 3.3 for compilation, and deployment on CentOS 7.2 with Java >= 1.7 and Hadoop 2.6, 2.7, 2.8.