
Curie
❓Curie: Automated and Rigorous Scientific Experimentation with AI Agents
Stars: 52
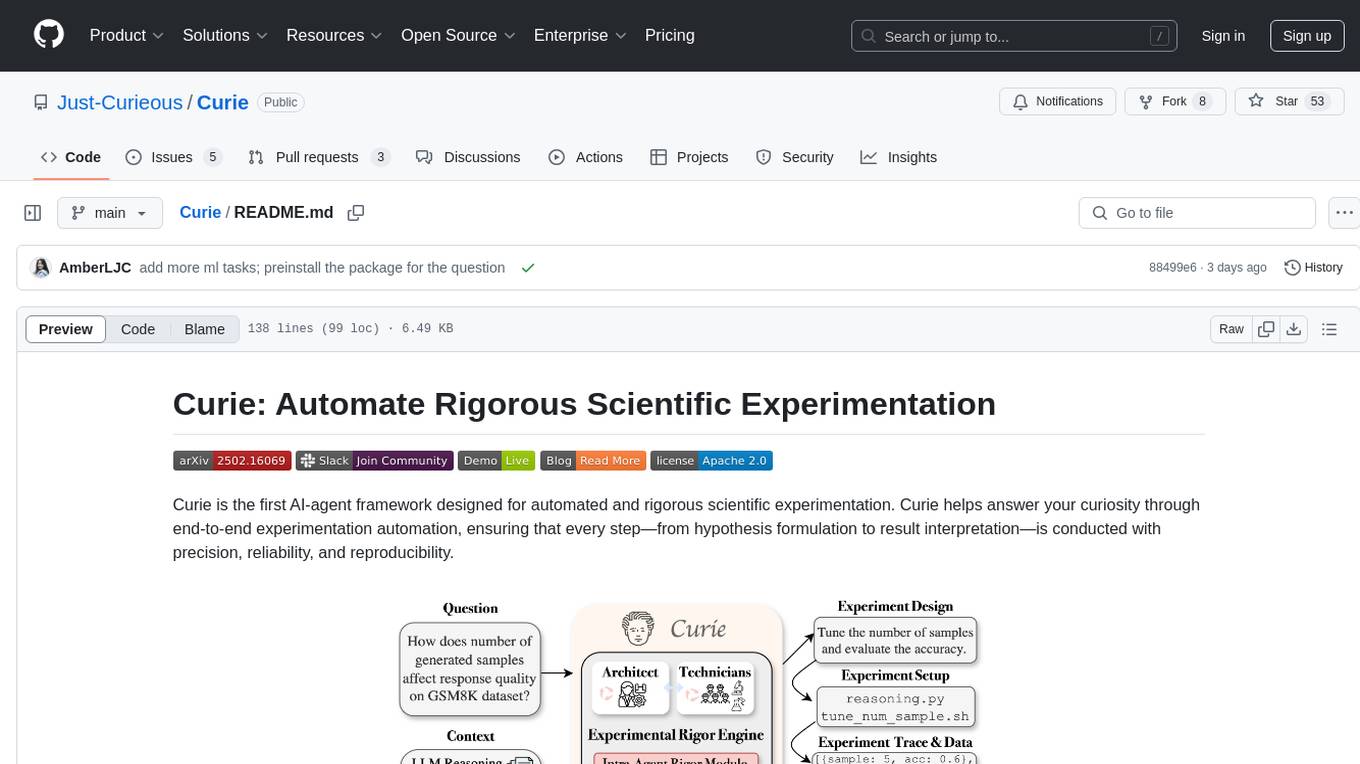
Curie is an AI-agent framework designed for automated and rigorous scientific experimentation. It automates end-to-end workflow management, ensures methodical procedure, reliability, and interpretability, and supports ML research, system analysis, and scientific discovery. It provides a benchmark with questions from 4 Computer Science domains. Users can customize experiment agents and adapt to their own tasks by configuring base_config.json. Curie is suitable for hyperparameter tuning, algorithm behavior analysis, system performance benchmarking, and automating computational simulations.
README:
Curie is the first AI-agent framework designed for automated and rigorous scientific experimentation. Curie helps answer your curiosity through end-to-end experimentation automation, ensuring that every step—from hypothesis formulation to result interpretation—is conducted with precision, reliability, and reproducibility.

Key Features
- 🚀 Automated Experimentation – End-to-end workflow management: hypothesis formulation, experiment setup, experiment execution, result analysis and finding reflection.
- 📊 Rigor Enhancement - Built-in verification modules enforce methodical procedure, reliability and interpretability.
- 🔬 Broad Applicability – Supports ML research, system analysis, and scientific discovery.
- 📖 Experimentation Benchmark - Provide 46 questions from 4 Computer Science domains, based on influential papers and open-source projects (
benchmark/experimentation_bench).
- Install docker: https://docs.docker.com/engine/install/ubuntu/.
-
Grant permission to docker via
sudo chmod 666 /var/run/docker.sock. -
If you encounter an error that
/var/run/docker.sockdoesn’t exist, you may find the actual path todocker.sockand create a soft link. For example, Docker Desktop stores this file at~/.docker/desktop/docker.sock, in which case you may use:sudo chmod 666 ~/.docker/desktop/docker.sock sudo ln -s ~/.docker/desktop/docker.sock /var/run/docker.sock
-
Run
docker psto check that permission has been granted with the Docker daemon.
- Clone the repository:
git clone https://github.com/Just-Curieous/Curie.git
cd Curie
- Put your LLM API credentials under
curie/setup/env.sh. Example:
export MODEL="gpt-4o"
export OPENAI_API_KEY="sk-xxx"
- Build the container image. This will take a few minutes. Note: you may need to setup a virtual environment before running pip install.
pip install -e .
docker images -q exp-agent-image | xargs -r docker rmi -f # remove any existing conflict image
cd curie && docker build --no-cache --progress=plain -t exp-agent-image -f ExpDockerfile_default .. && cd -Use the following command to input your research question or problem statement: python3 -m curie.main -q "<Your research question>".
python3 -m curie.main \
-q "How does the choice of sorting algorithm impact runtime performance across different \
input distributions (random, nearly sorted, reverse sorted)?" --report- Estimated runtime: ~5 minutes
- Sample log file: Available here
- Experiment report: Available here.
-
Log monitoring:
- Real-time logs are streamed to the console.
- Logs are also stored in:
logs/research_question_<ID>.loglogs/research_question_<ID>_verbose.log
- Experiment report details:
- Stored in:
logs/research_question_<ID>.md - Will only be produced when the
--reportflag is used.
- Stored in:
-
Reproducibility: The full experimentation process is saved in
workspace/research_<ID>/.
Example 2: How does the choice of activation function (e.g., ReLU, sigmoid, tanh) impact the model training convergence rate?
python3 -m curie.main -f benchmark/junior_ml_engineer_bench/q1_activation_func.txt --report- Detailed question:
q1_diffusion_step.txt - Sample log file: Available here
- Sample report file: Available here
More example questions can be found here.
- How to let Curie work on your own starter files?
- How to reproduce the results in `Large Language Monkeys'.
Curie is designed for scientific discovery across multiple domains:
- 🔬 Machine Learning & AI Research – Hyperparameter tuning and algorithm behavior
- 💻 System Performance Analysis – Benchmarking systems, optimizing configurations, investigating system trade-offs.
- 🧪 Algorithmic & Scientific Discovery – Validating hypotheses, automating computational simulations.

Config curie/configs/base_config.json to adapt to your own tasks:
- Add your domain-specific instructions by customizing
supervisor_system_prompt_filenamefor the supervisor,control_worker_system_prompt_filenamefor the experimentation worker, and so on. - Human interruption in the experiment design phase can be activated by setting the
is_user_interrupt_allowedkey totrue. - Configure timeouts and maximum number of steps (global, and coding agent specific).
For any issues or feature requests, please open an issue on our GitHub Issues page.
Curie is released under the Apache 2.0 License. See LICENSE for more details.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Curie
Similar Open Source Tools
Curie
Curie is an AI-agent framework designed for automated and rigorous scientific experimentation. It automates end-to-end workflow management, ensures methodical procedure, reliability, and interpretability, and supports ML research, system analysis, and scientific discovery. It provides a benchmark with questions from 4 Computer Science domains. Users can customize experiment agents and adapt to their own tasks by configuring base_config.json. Curie is suitable for hyperparameter tuning, algorithm behavior analysis, system performance benchmarking, and automating computational simulations.

deep-research
Deep Research is a lightning-fast tool that uses powerful AI models to generate comprehensive research reports in just a few minutes. It leverages advanced 'Thinking' and 'Task' models, combined with an internet connection, to provide fast and insightful analysis on various topics. The tool ensures privacy by processing and storing all data locally. It supports multi-platform deployment, offers support for various large language models, web search functionality, knowledge graph generation, research history preservation, local and server API support, PWA technology, multi-key payload support, multi-language support, and is built with modern technologies like Next.js and Shadcn UI. Deep Research is open-source under the MIT License.

Biomni
Biomni is a general-purpose biomedical AI agent designed to autonomously execute a wide range of research tasks across diverse biomedical subfields. By integrating cutting-edge large language model (LLM) reasoning with retrieval-augmented planning and code-based execution, Biomni helps scientists dramatically enhance research productivity and generate testable hypotheses.

RainbowGPT
RainbowGPT is a versatile tool that offers a range of functionalities, including Stock Analysis for financial decision-making, MySQL Management for database navigation, and integration of AI technologies like GPT-4 and ChatGlm3. It provides a user-friendly interface suitable for all skill levels, ensuring seamless information flow and continuous expansion of emerging technologies. The tool enhances adaptability, creativity, and insight, making it a valuable asset for various projects and tasks.

labo
LABO is a time series forecasting and analysis framework that integrates pre-trained and fine-tuned LLMs with multi-domain agent-based systems. It allows users to create and tune agents easily for various scenarios, such as stock market trend prediction and web public opinion analysis. LABO requires a specific runtime environment setup, including system requirements, Python environment, dependency installations, and configurations. Users can fine-tune their own models using LABO's Low-Rank Adaptation (LoRA) for computational efficiency and continuous model updates. Additionally, LABO provides a Python library for building model training pipelines and customizing agents for specific tasks.

ProX
ProX is a lm-based data refinement framework that automates the process of cleaning and improving data used in pre-training large language models. It offers better performance, domain flexibility, efficiency, and cost-effectiveness compared to traditional methods. The framework has been shown to improve model performance by over 2% and boost accuracy by up to 20% in tasks like math. ProX is designed to refine data at scale without the need for manual adjustments, making it a valuable tool for data preprocessing in natural language processing tasks.

BentoML
BentoML is an open-source model serving library for building performant and scalable AI applications with Python. It comes with everything you need for serving optimization, model packaging, and production deployment.

fuse-med-ml
FuseMedML is a Python framework designed to accelerate machine learning-based discovery in the medical field by promoting code reuse. It provides a flexible design concept where data is stored in a nested dictionary, allowing easy handling of multi-modality information. The framework includes components for creating custom models, loss functions, metrics, and data processing operators. Additionally, FuseMedML offers 'batteries included' key components such as fuse.data for data processing, fuse.eval for model evaluation, and fuse.dl for reusable deep learning components. It supports PyTorch and PyTorch Lightning libraries and encourages the creation of domain extensions for specific medical domains.
KnowAgent
KnowAgent is a tool designed for Knowledge-Augmented Planning for LLM-Based Agents. It involves creating an action knowledge base, converting action knowledge into text for model understanding, and a knowledgeable self-learning phase to continually improve the model's planning abilities. The tool aims to enhance agents' potential for application in complex situations by leveraging external reservoirs of information and iterative processes.
sec-parser
The `sec-parser` project simplifies extracting meaningful information from SEC EDGAR HTML documents by organizing them into semantic elements and a tree structure. It helps in parsing SEC filings for financial and regulatory analysis, analytics and data science, AI and machine learning, causal AI, and large language models. The tool is especially beneficial for AI, ML, and LLM applications by streamlining data pre-processing and feature extraction.

premsql
PremSQL is an open-source library designed to help developers create secure, fully local Text-to-SQL solutions using small language models. It provides essential tools for building and deploying end-to-end Text-to-SQL pipelines with customizable components, ideal for secure, autonomous AI-powered data analysis. The library offers features like Local-First approach, Customizable Datasets, Robust Executors and Evaluators, Advanced Generators, Error Handling and Self-Correction, Fine-Tuning Support, and End-to-End Pipelines. Users can fine-tune models, generate SQL queries from natural language inputs, handle errors, and evaluate model performance against predefined metrics. PremSQL is extendible for customization and private data usage.
Pixel-Reasoner
Pixel Reasoner is a framework that introduces reasoning in the pixel-space for Vision-Language Models (VLMs), enabling them to directly inspect, interrogate, and infer from visual evidences. This enhances reasoning fidelity for visual tasks by equipping VLMs with visual reasoning operations like zoom-in and select-frame. The framework addresses challenges like model's imbalanced competence and reluctance to adopt pixel-space operations through a two-phase training approach involving instruction tuning and curiosity-driven reinforcement learning. With these visual operations, VLMs can interact with complex visual inputs such as images or videos to gather necessary information, leading to improved performance across visual reasoning benchmarks.
distilabel
Distilabel is a framework for synthetic data and AI feedback for AI engineers that require high-quality outputs, full data ownership, and overall efficiency. It helps you synthesize data and provide AI feedback to improve the quality of your AI models. With Distilabel, you can: * **Synthesize data:** Generate synthetic data to train your AI models. This can help you to overcome the challenges of data scarcity and bias. * **Provide AI feedback:** Get feedback from AI models on your data. This can help you to identify errors and improve the quality of your data. * **Improve your AI output quality:** By using Distilabel to synthesize data and provide AI feedback, you can improve the quality of your AI models and get better results.

tinyllm
tinyllm is a lightweight framework designed for developing, debugging, and monitoring LLM and Agent powered applications at scale. It aims to simplify code while enabling users to create complex agents or LLM workflows in production. The core classes, Function and FunctionStream, standardize and control LLM, ToolStore, and relevant calls for scalable production use. It offers structured handling of function execution, including input/output validation, error handling, evaluation, and more, all while maintaining code readability. Users can create chains with prompts, LLM models, and evaluators in a single file without the need for extensive class definitions or spaghetti code. Additionally, tinyllm integrates with various libraries like Langfuse and provides tools for prompt engineering, observability, logging, and finite state machine design.
resume-job-matcher
Resume Job Matcher is a Python script that automates the process of matching resumes to a job description using AI. It leverages the Anthropic Claude API or OpenAI's GPT API to analyze resumes and provide a match score along with personalized email responses for candidates. The tool offers comprehensive resume processing, advanced AI-powered analysis, in-depth evaluation & scoring, comprehensive analytics & reporting, enhanced candidate profiling, and robust system management. Users can customize font presets, generate PDF versions of unified resumes, adjust logging level, change scoring model, modify AI provider, and adjust AI model. The final score for each resume is calculated based on AI-generated match score and resume quality score, ensuring content relevance and presentation quality are considered. Troubleshooting tips, best practices, contribution guidelines, and required Python packages are provided.

guidellm
GuideLLM is a platform for evaluating and optimizing the deployment of large language models (LLMs). By simulating real-world inference workloads, GuideLLM enables users to assess the performance, resource requirements, and cost implications of deploying LLMs on various hardware configurations. This approach ensures efficient, scalable, and cost-effective LLM inference serving while maintaining high service quality. The tool provides features for performance evaluation, resource optimization, cost estimation, and scalability testing.
For similar tasks
Curie
Curie is an AI-agent framework designed for automated and rigorous scientific experimentation. It automates end-to-end workflow management, ensures methodical procedure, reliability, and interpretability, and supports ML research, system analysis, and scientific discovery. It provides a benchmark with questions from 4 Computer Science domains. Users can customize experiment agents and adapt to their own tasks by configuring base_config.json. Curie is suitable for hyperparameter tuning, algorithm behavior analysis, system performance benchmarking, and automating computational simulations.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

clearml
ClearML is a suite of tools designed to streamline the machine learning workflow. It includes an experiment manager, MLOps/LLMOps, data management, and model serving capabilities. ClearML is open-source and offers a free tier hosting option. It supports various ML/DL frameworks and integrates with Jupyter Notebook and PyCharm. ClearML provides extensive logging capabilities, including source control info, execution environment, hyper-parameters, and experiment outputs. It also offers automation features, such as remote job execution and pipeline creation. ClearML is designed to be easy to integrate, requiring only two lines of code to add to existing scripts. It aims to improve collaboration, visibility, and data transparency within ML teams.
llm-strategy
The 'llm-strategy' repository implements the Strategy Pattern using Large Language Models (LLMs) like OpenAI’s GPT-3. It provides a decorator 'llm_strategy' that connects to an LLM to implement abstract methods in interface classes. The package uses doc strings, type annotations, and method/function names as prompts for the LLM and can convert the responses back to Python data. It aims to automate the parsing of structured data by using LLMs, potentially reducing the need for manual Python code in the future.

ml-retreat
ML-Retreat is a comprehensive machine learning library designed to simplify and streamline the process of building and deploying machine learning models. It provides a wide range of tools and utilities for data preprocessing, model training, evaluation, and deployment. With ML-Retreat, users can easily experiment with different algorithms, hyperparameters, and feature engineering techniques to optimize their models. The library is built with a focus on scalability, performance, and ease of use, making it suitable for both beginners and experienced machine learning practitioners.
For similar jobs
Interview-for-Algorithm-Engineer
This repository provides a collection of interview questions and answers for algorithm engineers. The questions are organized by topic, and each question includes a detailed explanation of the answer. This repository is a valuable resource for anyone preparing for an algorithm engineering interview.
LLM-as-HH
LLM-as-HH is a codebase that accompanies the paper ReEvo: Large Language Models as Hyper-Heuristics with Reflective Evolution. It introduces Language Hyper-Heuristics (LHHs) that leverage LLMs for heuristic generation with minimal manual intervention and open-ended heuristic spaces. Reflective Evolution (ReEvo) is presented as a searching framework that emulates the reflective design approach of human experts while surpassing human capabilities with scalable LLM inference, Internet-scale domain knowledge, and powerful evolutionary search. The tool can improve various algorithms on problems like Traveling Salesman Problem, Capacitated Vehicle Routing Problem, Orienteering Problem, Multiple Knapsack Problems, Bin Packing Problem, and Decap Placement Problem in both black-box and white-box settings.

universal
The Universal Numbers Library is a header-only C++ template library designed for universal number arithmetic, offering alternatives to native integer and floating-point for mixed-precision algorithm development and optimization. It tailors arithmetic types to the application's precision and dynamic range, enabling improved application performance and energy efficiency. The library provides fast implementations of special IEEE-754 formats like quarter precision, half-precision, and quad precision, as well as vendor-specific extensions. It supports static and elastic integers, decimals, fixed-points, rationals, linear floats, tapered floats, logarithmic, interval, and adaptive-precision integers, rationals, and floats. The library is suitable for AI, DSP, HPC, and HFT algorithms.
UmaAi
UmaAi is a tool designed for algorithm learning purposes, specifically focused on analyzing scenario mechanics in a game. It provides functionalities such as simulating scenarios, searching, handwritten-logic, and OCR integration. The tool allows users to modify settings in config.h for evaluating cardset strength, simulating games, and understanding game mechanisms through the source code. It emphasizes that it should not be used for illegal purposes and is intended for educational use only.
KuiperLLama
KuiperLLama is a custom large model inference framework that guides users in building a LLama-supported inference framework with Cuda acceleration from scratch. The framework includes modules for architecture design, LLama2 model support, model quantization, Cuda basics, operator implementation, and fun tasks like text generation and storytelling. It also covers learning other commercial inference frameworks for comprehensive understanding. The project provides detailed tutorials and resources for developing and optimizing large models for efficient inference.
Awesome-RoadMaps-and-Interviews
Awesome RoadMaps and Interviews is a comprehensive repository that aims to provide guidance for technical interviews and career development in the ITCS field. It covers a wide range of topics including interview strategies, technical knowledge, and practical insights gained from years of interviewing experience. The repository emphasizes the importance of combining theoretical knowledge with practical application, and encourages users to expand their interview preparation beyond just algorithms. It also offers resources for enhancing knowledge breadth, depth, and programming skills through curated roadmaps, mind maps, cheat sheets, and coding snippets. The content is structured to help individuals navigate various technical roles and technologies, fostering continuous learning and professional growth.
ai_igu
AI-IGU is a GitHub repository focused on Artificial Intelligence (AI) concepts, technology, software development, and algorithm improvement for all ages and professions. It emphasizes the importance of future software for future scientists and the increasing need for software developers in the industry. The repository covers various topics related to AI, including machine learning, deep learning, data mining, data science, big data, and more. It provides educational materials, practical examples, and hands-on projects to enhance software development skills and create awareness in the field of AI.

llm4ad
LLM4AD is an open-source Python-based platform leveraging Large Language Models (LLMs) for Automatic Algorithm Design (AD). It provides unified interfaces for methods, tasks, and LLMs, along with features like evaluation acceleration, secure evaluation, logs, GUI support, and more. The platform was originally developed for optimization tasks but is versatile enough to be used in other areas such as machine learning, science discovery, game theory, and engineering design. It offers various search methods and algorithm design tasks across different domains. LLM4AD supports remote LLM API, local HuggingFace LLM deployment, and custom LLM interfaces. The project is licensed under the MIT License and welcomes contributions, collaborations, and issue reports.