
distillKitPlus
Easy to use, High Performant Knowledge Distillation for LLMs
Stars: 52
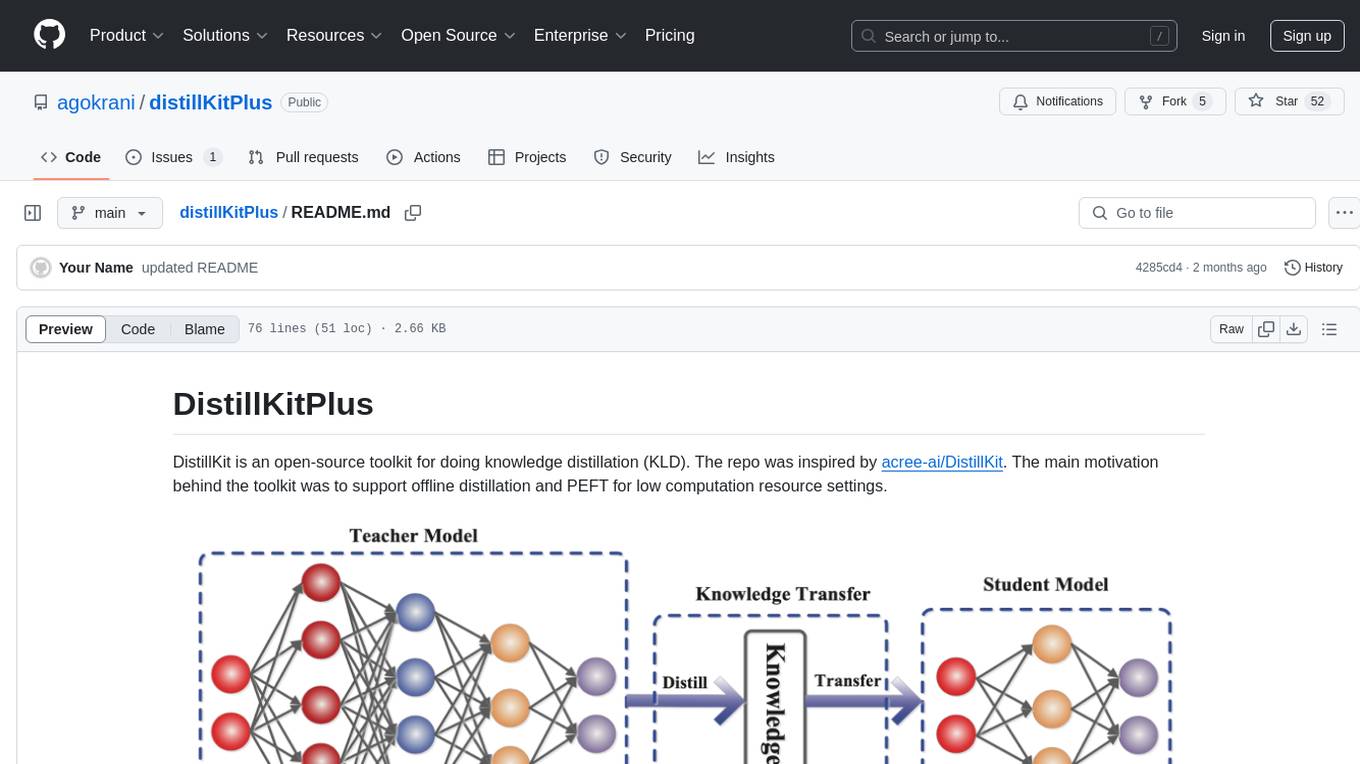
DistillKitPlus is an open-source toolkit designed for knowledge distillation (KLD) in low computation resource settings. It supports logit distillation, pre-computed logits for memory-efficient training, LoRA fine-tuning integration, and model quantization for faster inference. The toolkit utilizes a JSON configuration file for project, dataset, model, tokenizer, training, distillation, LoRA, and quantization settings. Users can contribute to the toolkit and contact the developers for technical questions or issues.
README:
DistillKit is an open-source toolkit for doing knowledge distillation (KLD). The repo was inspired by acree-ai/DistillKit. The main motivation behind the toolkit was to support offline distillation and PEFT for low computation resource settings.

- Logit Distillation: Supports same-architecture teacher and student models.
- Pre-Computed Logits: Enables memory-efficient training by generating logits in advance.
- LoRA Fine-Tuning Integration: Efficient low-rank adaptation fine-tuning support.
- Quantization Support: 4-bit model quantization for faster inference and reduced memory usage.
git clone https://github.com/agokrani/distillkitplus.git
cd distillkitplus
pip install -r requirements.txt
pip install .- Configure your distillation settings in
config/default_config.json - Generate teacher logits:
python scripts/local/generate_logits.py --config config/default_config.json
- Run distillation:
python scripts/local/distill_logits.py --config config/default_config.json
DistillKitPlus also supports running scripts using Modal. Follow the steps below to perform knowledge distillation with Modal.
Use the following command to generate pre-computed logits with Modal:
- Generate teacher logits:
python scripts/modal/generate_logits.py --config config/default_config.json
- Run distillation:
python scripts/modal/distill_logits.py --config config/default_config.json
The toolkit uses a JSON configuration file with the following main sections:
-
project_name: Name of your distillation project -
dataset: Dataset configuration including source and processing settings -
models: Teacher and student model specifications -
tokenizer: Tokenizer settings including max length and padding -
training: Training hyperparameters -
distillation: Distillation-specific parameters (temperature, alpha) -
lora: LoRA configuration for efficient fine-tuning -
quantization: Model quantization settings
See config/default_config.json for a complete example.
We welcome contributions from the community! If you have ideas for improvements, new features, or bug fixes, please feel free to open an issue or submit a pull request.
For any technical questions or issues, please open an issue in this repository. We appreciate your feedback and support!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for distillKitPlus
Similar Open Source Tools
distillKitPlus
DistillKitPlus is an open-source toolkit designed for knowledge distillation (KLD) in low computation resource settings. It supports logit distillation, pre-computed logits for memory-efficient training, LoRA fine-tuning integration, and model quantization for faster inference. The toolkit utilizes a JSON configuration file for project, dataset, model, tokenizer, training, distillation, LoRA, and quantization settings. Users can contribute to the toolkit and contact the developers for technical questions or issues.
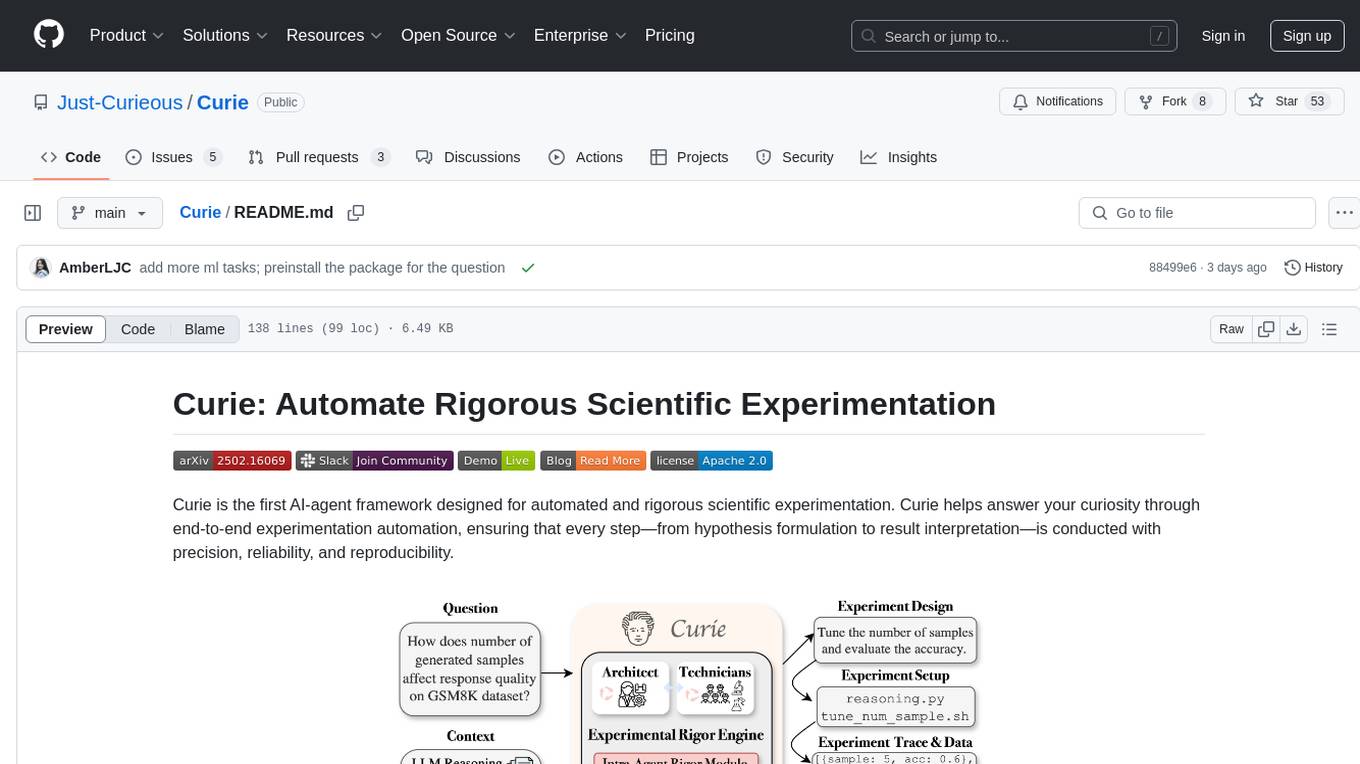
Curie
Curie is an AI-agent framework designed for automated and rigorous scientific experimentation. It automates end-to-end workflow management, ensures methodical procedure, reliability, and interpretability, and supports ML research, system analysis, and scientific discovery. It provides a benchmark with questions from 4 Computer Science domains. Users can customize experiment agents and adapt to their own tasks by configuring base_config.json. Curie is suitable for hyperparameter tuning, algorithm behavior analysis, system performance benchmarking, and automating computational simulations.

BentoML
BentoML is an open-source model serving library for building performant and scalable AI applications with Python. It comes with everything you need for serving optimization, model packaging, and production deployment.
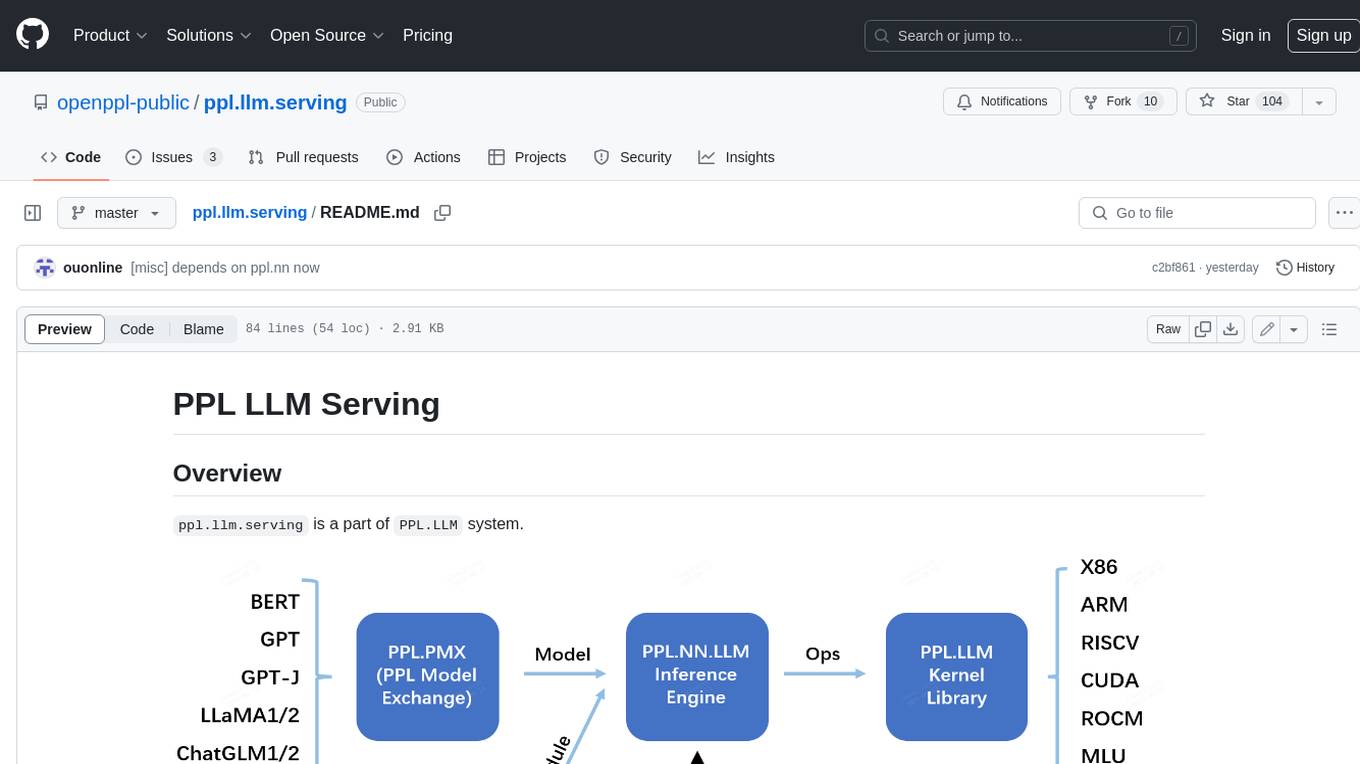
ppl.llm.serving
PPL LLM Serving is a serving based on ppl.nn for various Large Language Models (LLMs). It provides inference support for LLaMA. Key features include: * **High Performance:** Optimized for fast and efficient inference on LLM models. * **Scalability:** Supports distributed deployment across multiple GPUs or machines. * **Flexibility:** Allows for customization of model configurations and inference pipelines. * **Ease of Use:** Provides a user-friendly interface for deploying and managing LLM models. This tool is suitable for various tasks, including: * **Text Generation:** Generating text, stories, or code from scratch or based on a given prompt. * **Text Summarization:** Condensing long pieces of text into concise summaries. * **Question Answering:** Answering questions based on a given context or knowledge base. * **Language Translation:** Translating text between different languages. * **Chatbot Development:** Building conversational AI systems that can engage in natural language interactions. Keywords: llm, large language model, natural language processing, text generation, question answering, language translation, chatbot development

py-llm-core
PyLLMCore is a light-weighted interface with Large Language Models with native support for llama.cpp, OpenAI API, and Azure deployments. It offers a Pythonic API that is simple to use, with structures provided by the standard library dataclasses module. The high-level API includes the assistants module for easy swapping between models. PyLLMCore supports various models including those compatible with llama.cpp, OpenAI, and Azure APIs. It covers use cases such as parsing, summarizing, question answering, hallucinations reduction, context size management, and tokenizing. The tool allows users to interact with language models for tasks like parsing text, summarizing content, answering questions, reducing hallucinations, managing context size, and tokenizing text.
aisdk-prompt-optimizer
AISDK Prompt Optimizer is an open-source tool designed to transform AI interactions by optimizing prompts. It utilizes the GEPA reflective optimizer to evolve textual components of AI systems, providing features such as reflective prompt mutation, rich textual feedback, and Pareto-based selection. Users can teach their AI desired behaviors, collect ideal samples, run optimization to generate optimized prompts, and deploy the results in their applications. The tool leverages advanced optimization algorithms to guide AI through interactive conversations and refine prompt candidates for improved performance.
RA.Aid
RA.Aid is an AI software development agent powered by `aider` and advanced reasoning models like `o1`. It combines `aider`'s code editing capabilities with LangChain's agent-based task execution framework to provide an intelligent assistant for research, planning, and implementation of multi-step development tasks. It handles complex programming tasks by breaking them down into manageable steps, running shell commands automatically, and leveraging expert reasoning models like OpenAI's o1. RA.Aid is designed for everyday software development, offering features such as multi-step task planning, automated command execution, and the ability to handle complex programming tasks beyond single-shot code edits.

langmanus
LangManus is a community-driven AI automation framework that combines language models with specialized tools for tasks like web search, crawling, and Python code execution. It implements a hierarchical multi-agent system with agents like Coordinator, Planner, Supervisor, Researcher, Coder, Browser, and Reporter. The framework supports LLM integration, search and retrieval tools, Python integration, workflow management, and visualization. LangManus aims to give back to the open-source community and welcomes contributions in various forms.

premsql
PremSQL is an open-source library designed to help developers create secure, fully local Text-to-SQL solutions using small language models. It provides essential tools for building and deploying end-to-end Text-to-SQL pipelines with customizable components, ideal for secure, autonomous AI-powered data analysis. The library offers features like Local-First approach, Customizable Datasets, Robust Executors and Evaluators, Advanced Generators, Error Handling and Self-Correction, Fine-Tuning Support, and End-to-End Pipelines. Users can fine-tune models, generate SQL queries from natural language inputs, handle errors, and evaluate model performance against predefined metrics. PremSQL is extendible for customization and private data usage.

llama-cpp-agent
The llama-cpp-agent framework is a tool designed for easy interaction with Large Language Models (LLMs). Allowing users to chat with LLM models, execute structured function calls and get structured output (objects). It provides a simple yet robust interface and supports llama-cpp-python and OpenAI endpoints with GBNF grammar support (like the llama-cpp-python server) and the llama.cpp backend server. It works by generating a formal GGML-BNF grammar of the user defined structures and functions, which is then used by llama.cpp to generate text valid to that grammar. In contrast to most GBNF grammar generators it also supports nested objects, dictionaries, enums and lists of them.

atropos
Atropos is a robust and scalable framework for Reinforcement Learning Environments with Large Language Models (LLMs). It provides a flexible platform to accelerate LLM-based RL research across diverse interactive settings. Atropos supports multi-turn and asynchronous RL interactions, integrates with various inference APIs, offers a standardized training interface for experimenting with different RL algorithms, and allows for easy scalability by launching more environment instances. The framework manages diverse environment types concurrently for heterogeneous, multi-modal training.

Biomni
Biomni is a general-purpose biomedical AI agent designed to autonomously execute a wide range of research tasks across diverse biomedical subfields. By integrating cutting-edge large language model (LLM) reasoning with retrieval-augmented planning and code-based execution, Biomni helps scientists dramatically enhance research productivity and generate testable hypotheses.

deep-research
Deep Research is a lightning-fast tool that uses powerful AI models to generate comprehensive research reports in just a few minutes. It leverages advanced 'Thinking' and 'Task' models, combined with an internet connection, to provide fast and insightful analysis on various topics. The tool ensures privacy by processing and storing all data locally. It supports multi-platform deployment, offers support for various large language models, web search functionality, knowledge graph generation, research history preservation, local and server API support, PWA technology, multi-key payload support, multi-language support, and is built with modern technologies like Next.js and Shadcn UI. Deep Research is open-source under the MIT License.

ApeRAG
ApeRAG is a production-ready platform for Retrieval-Augmented Generation (RAG) that combines Graph RAG, vector search, and full-text search with advanced AI agents. It is ideal for building Knowledge Graphs, Context Engineering, and deploying intelligent AI agents for autonomous search and reasoning across knowledge bases. The platform offers features like advanced index types, intelligent AI agents with MCP support, enhanced Graph RAG with entity normalization, multimodal processing, hybrid retrieval engine, MinerU integration for document parsing, production-grade deployment with Kubernetes, enterprise management features, MCP integration, and developer-friendly tools for customization and contribution.
gitdiagram
GitDiagram is a tool that turns any GitHub repository into an interactive diagram for visualization in seconds. It offers instant visualization, interactivity, fast generation, customization, and API access. The tool utilizes a tech stack including Next.js, FastAPI, PostgreSQL, Claude 3.5 Sonnet, Vercel, EC2, GitHub Actions, PostHog, and Api-Analytics. Users can self-host the tool for local development and contribute to its development. GitDiagram is inspired by Gitingest and has future plans to use larger context models, allow user API key input, implement RAG with Mermaid.js docs, and include font-awesome icons in diagrams.

comfyui_LLM_Polymath
LLM Polymath Chat Node is an advanced Chat Node for ComfyUI that integrates large language models to build text-driven applications and automate data processes, enhancing prompt responses by incorporating real-time web search, linked content extraction, and custom agent instructions. It supports both OpenAI’s GPT-like models and alternative models served via a local Ollama API. The core functionalities include Comfy Node Finder and Smart Assistant, along with additional agents like Flux Prompter, Custom Instructors, Python debugger, and scripter. The tool offers features for prompt processing, web search integration, model & API integration, custom instructions, image handling, logging & debugging, output compression, and more.
For similar tasks

mindsdb
MindsDB is a platform for customizing AI from enterprise data. You can create, serve, and fine-tune models in real-time from your database, vector store, and application data. MindsDB "enhances" SQL syntax with AI capabilities to make it accessible for developers worldwide. With MindsDB’s nearly 200 integrations, any developer can create AI customized for their purpose, faster and more securely. Their AI systems will constantly improve themselves — using companies’ own data, in real-time.

training-operator
Kubeflow Training Operator is a Kubernetes-native project for fine-tuning and scalable distributed training of machine learning (ML) models created with various ML frameworks such as PyTorch, Tensorflow, XGBoost, MPI, Paddle and others. Training Operator allows you to use Kubernetes workloads to effectively train your large models via Kubernetes Custom Resources APIs or using Training Operator Python SDK. > Note: Before v1.2 release, Kubeflow Training Operator only supports TFJob on Kubernetes. * For a complete reference of the custom resource definitions, please refer to the API Definition. * TensorFlow API Definition * PyTorch API Definition * Apache MXNet API Definition * XGBoost API Definition * MPI API Definition * PaddlePaddle API Definition * For details of all-in-one operator design, please refer to the All-in-one Kubeflow Training Operator * For details on its observability, please refer to the monitoring design doc.

helix
HelixML is a private GenAI platform that allows users to deploy the best of open AI in their own data center or VPC while retaining complete data security and control. It includes support for fine-tuning models with drag-and-drop functionality. HelixML brings the best of open source AI to businesses in an ergonomic and scalable way, optimizing the tradeoff between GPU memory and latency.

nntrainer
NNtrainer is a software framework for training neural network models on devices with limited resources. It enables on-device fine-tuning of neural networks using user data for personalization. NNtrainer supports various machine learning algorithms and provides examples for tasks such as few-shot learning, ResNet, VGG, and product rating. It is optimized for embedded devices and utilizes CBLAS and CUBLAS for accelerated calculations. NNtrainer is open source and released under the Apache License version 2.0.

petals
Petals is a tool that allows users to run large language models at home in a BitTorrent-style manner. It enables fine-tuning and inference up to 10x faster than offloading. Users can generate text with distributed models like Llama 2, Falcon, and BLOOM, and fine-tune them for specific tasks directly from their desktop computer or Google Colab. Petals is a community-run system that relies on people sharing their GPUs to increase its capacity and offer a distributed network for hosting model layers.

LLaVA-pp
This repository, LLaVA++, extends the visual capabilities of the LLaVA 1.5 model by incorporating the latest LLMs, Phi-3 Mini Instruct 3.8B, and LLaMA-3 Instruct 8B. It provides various models for instruction-following LMMS and academic-task-oriented datasets, along with training scripts for Phi-3-V and LLaMA-3-V. The repository also includes installation instructions and acknowledgments to related open-source contributions.

KULLM
KULLM (구름) is a Korean Large Language Model developed by Korea University NLP & AI Lab and HIAI Research Institute. It is based on the upstage/SOLAR-10.7B-v1.0 model and has been fine-tuned for instruction. The model has been trained on 8×A100 GPUs and is capable of generating responses in Korean language. KULLM exhibits hallucination and repetition phenomena due to its decoding strategy. Users should be cautious as the model may produce inaccurate or harmful results. Performance may vary in benchmarks without a fixed system prompt.

Firefly
Firefly is an open-source large model training project that supports pre-training, fine-tuning, and DPO of mainstream large models. It includes models like Llama3, Gemma, Qwen1.5, MiniCPM, Llama, InternLM, Baichuan, ChatGLM, Yi, Deepseek, Qwen, Orion, Ziya, Xverse, Mistral, Mixtral-8x7B, Zephyr, Vicuna, Bloom, etc. The project supports full-parameter training, LoRA, QLoRA efficient training, and various tasks such as pre-training, SFT, and DPO. Suitable for users with limited training resources, QLoRA is recommended for fine-tuning instructions. The project has achieved good results on the Open LLM Leaderboard with QLoRA training process validation. The latest version has significant updates and adaptations for different chat model templates.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.