Best AI tools for< Quantize Models >
0 - AI tool Sites
20 - Open Source AI Tools

aimet
AIMET is a library that provides advanced model quantization and compression techniques for trained neural network models. It provides features that have been proven to improve run-time performance of deep learning neural network models with lower compute and memory requirements and minimal impact to task accuracy. AIMET is designed to work with PyTorch, TensorFlow and ONNX models. We also host the AIMET Model Zoo - a collection of popular neural network models optimized for 8-bit inference. We also provide recipes for users to quantize floating point models using AIMET.

AutoGPTQ
AutoGPTQ is an easy-to-use LLM quantization package with user-friendly APIs, based on GPTQ algorithm (weight-only quantization). It provides a simple and efficient way to quantize large language models (LLMs) to reduce their size and computational cost while maintaining their performance. AutoGPTQ supports a wide range of LLM models, including GPT-2, GPT-J, OPT, and BLOOM. It also supports various evaluation tasks, such as language modeling, sequence classification, and text summarization. With AutoGPTQ, users can easily quantize their LLM models and deploy them on resource-constrained devices, such as mobile phones and embedded systems.

hqq
HQQ is a fast and accurate model quantizer that skips the need for calibration data. It's super simple to implement (just a few lines of code for the optimizer). It can crunch through quantizing the Llama2-70B model in only 4 minutes! 🚀
Efficient-LLMs-Survey
This repository provides a systematic and comprehensive review of efficient LLMs research. We organize the literature in a taxonomy consisting of three main categories, covering distinct yet interconnected efficient LLMs topics from **model-centric** , **data-centric** , and **framework-centric** perspective, respectively. We hope our survey and this GitHub repository can serve as valuable resources to help researchers and practitioners gain a systematic understanding of the research developments in efficient LLMs and inspire them to contribute to this important and exciting field.

Qwen-TensorRT-LLM
Qwen-TensorRT-LLM is a project developed for the NVIDIA TensorRT Hackathon 2023, focusing on accelerating inference for the Qwen-7B-Chat model using TRT-LLM. The project offers various functionalities such as FP16/BF16 support, INT8 and INT4 quantization options, Tensor Parallel for multi-GPU parallelism, web demo setup with gradio, Triton API deployment for maximum throughput/concurrency, fastapi integration for openai requests, CLI interaction, and langchain support. It supports models like qwen2, qwen, and qwen-vl for both base and chat models. The project also provides tutorials on Bilibili and blogs for adapting Qwen models in NVIDIA TensorRT-LLM, along with hardware requirements and quick start guides for different model types and quantization methods.
LLM-Alchemy-Chamber
LLM Alchemy Chamber is a repository dedicated to exploring the world of Language Models (LLMs) through various experiments and projects. It contains scripts, notebooks, and experiments focused on tasks such as fine-tuning different LLM models, quantization for performance optimization, dataset generation for instruction/QA tasks, and more. The repository offers a collection of resources for beginners and enthusiasts interested in delving into the mystical realm of LLMs.

LLamaTuner
LLamaTuner is a repository for the Efficient Finetuning of Quantized LLMs project, focusing on building and sharing instruction-following Chinese baichuan-7b/LLaMA/Pythia/GLM model tuning methods. The project enables training on a single Nvidia RTX-2080TI and RTX-3090 for multi-round chatbot training. It utilizes bitsandbytes for quantization and is integrated with Huggingface's PEFT and transformers libraries. The repository supports various models, training approaches, and datasets for supervised fine-tuning, LoRA, QLoRA, and more. It also provides tools for data preprocessing and offers models in the Hugging Face model hub for inference and finetuning. The project is licensed under Apache 2.0 and acknowledges contributions from various open-source contributors.
LLM-Fine-Tuning
This GitHub repository contains examples of fine-tuning open source large language models. It showcases the process of fine-tuning and quantizing large language models using efficient techniques like Lora and QLora. The repository serves as a practical guide for individuals looking to optimize the performance of language models through fine-tuning.
AMchat
AMchat is a large language model that integrates advanced math concepts, exercises, and solutions. The model is based on the InternLM2-Math-7B model and is specifically designed to answer advanced math problems. It provides a comprehensive dataset that combines Math and advanced math exercises and solutions. Users can download the model from ModelScope or OpenXLab, deploy it locally or using Docker, and even retrain it using XTuner for fine-tuning. The tool also supports LMDeploy for quantization, OpenCompass for evaluation, and various other features for model deployment and evaluation. The project contributors have provided detailed documentation and guides for users to utilize the tool effectively.
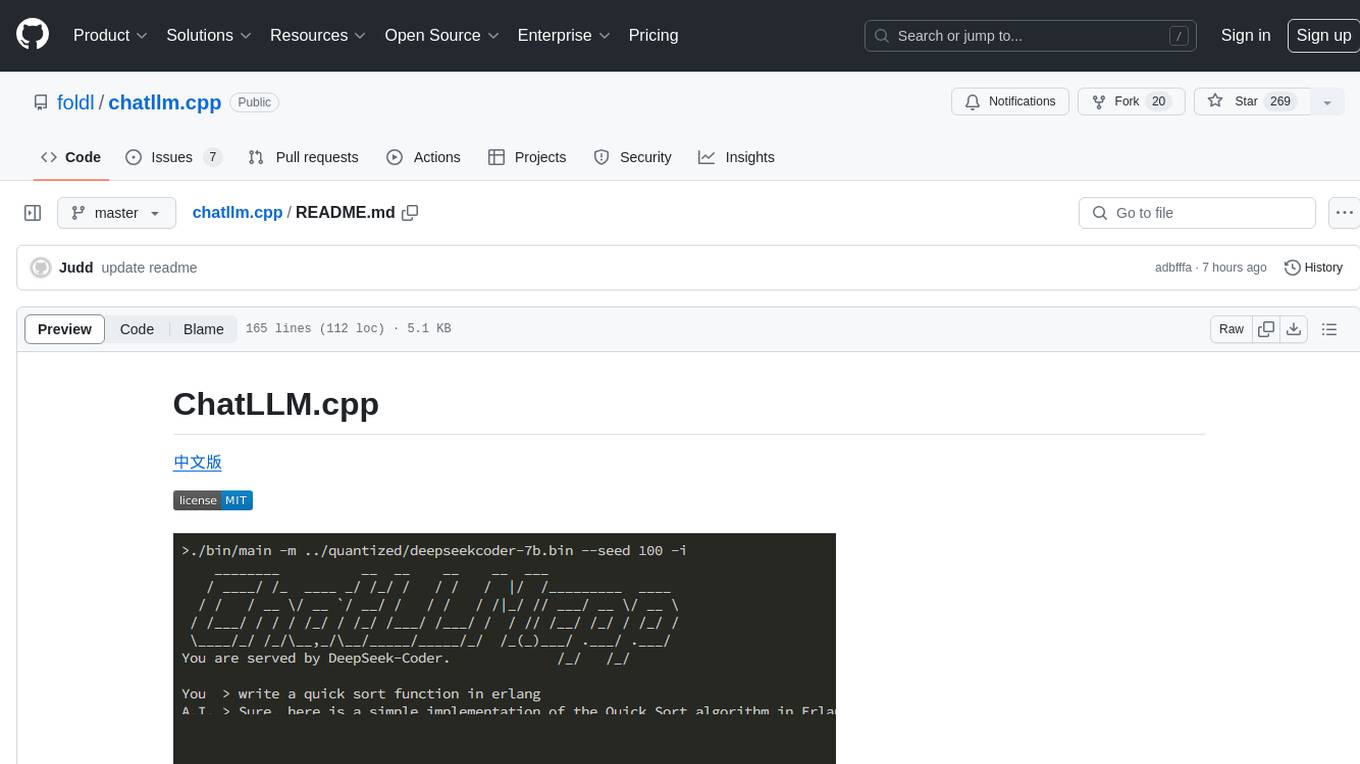
chatllm.cpp
ChatLLM.cpp is a pure C++ implementation tool for real-time chatting with RAG on your computer. It supports inference of various models ranging from less than 1B to more than 300B. The tool provides accelerated memory-efficient CPU inference with quantization, optimized KV cache, and parallel computing. It allows streaming generation with a typewriter effect and continuous chatting with virtually unlimited content length. ChatLLM.cpp also offers features like Retrieval Augmented Generation (RAG), LoRA, Python/JavaScript/C bindings, web demo, and more possibilities. Users can clone the repository, quantize models, build the project using make or CMake, and run quantized models for interactive chatting.

aimo-progress-prize
This repository contains the training and inference code needed to replicate the winning solution to the AI Mathematical Olympiad - Progress Prize 1. It consists of fine-tuning DeepSeekMath-Base 7B, high-quality training datasets, a self-consistency decoding algorithm, and carefully chosen validation sets. The training methodology involves Chain of Thought (CoT) and Tool Integrated Reasoning (TIR) training stages. Two datasets, NuminaMath-CoT and NuminaMath-TIR, were used to fine-tune the models. The models were trained using open-source libraries like TRL, PyTorch, vLLM, and DeepSpeed. Post-training quantization to 8-bit precision was done to improve performance on Kaggle's T4 GPUs. The project structure includes scripts for training, quantization, and inference, along with necessary installation instructions and hardware/software specifications.

ms-swift
ms-swift is an official framework provided by the ModelScope community for fine-tuning and deploying large language models and multi-modal large models. It supports training, inference, evaluation, quantization, and deployment of over 400 large models and 100+ multi-modal large models. The framework includes various training technologies and accelerates inference, evaluation, and deployment modules. It offers a Gradio-based Web-UI interface and best practices for easy application of large models. ms-swift supports a wide range of model types, dataset types, hardware support, lightweight training methods, distributed training techniques, quantization training, RLHF training, multi-modal training, interface training, plugin and extension support, inference acceleration engines, model evaluation, and model quantization.
Awesome-Efficient-AIGC
This repository, Awesome Efficient AIGC, collects efficient approaches for AI-generated content (AIGC) to cope with its huge demand for computing resources. It includes efficient Large Language Models (LLMs), Diffusion Models (DMs), and more. The repository is continuously improving and welcomes contributions of works like papers and repositories that are missed by the collection.
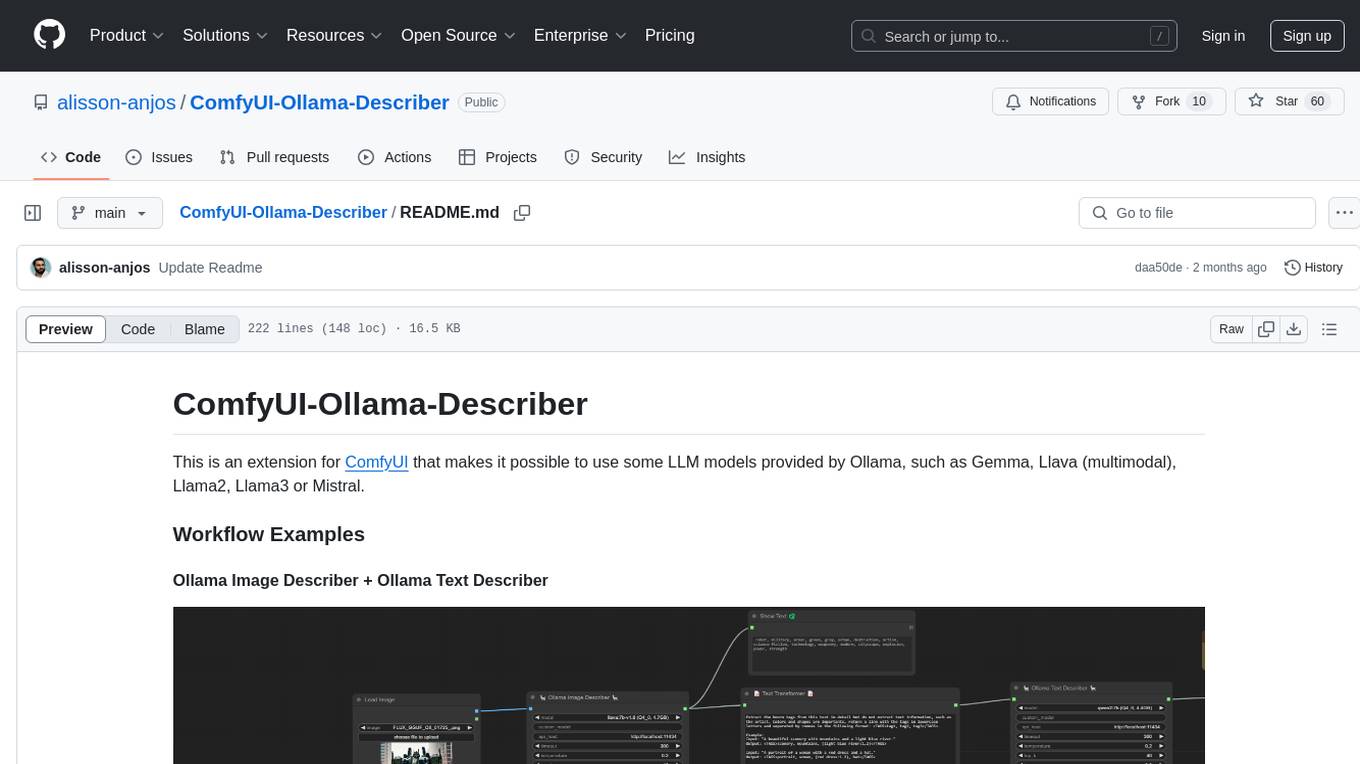
ComfyUI-Ollama-Describer
ComfyUI-Ollama-Describer is an extension for ComfyUI that enables the use of LLM models provided by Ollama, such as Gemma, Llava (multimodal), Llama2, Llama3, or Mistral. It requires the Ollama library for interacting with large-scale language models, supporting GPUs using CUDA and AMD GPUs on Windows, Linux, and Mac. The extension allows users to run Ollama through Docker and utilize NVIDIA GPUs for faster processing. It provides nodes for image description, text description, image captioning, and text transformation, with various customizable parameters for model selection, API communication, response generation, and model memory management.

llama.cpp
The main goal of llama.cpp is to enable LLM inference with minimal setup and state-of-the-art performance on a wide range of hardware - locally and in the cloud. It provides a Plain C/C++ implementation without any dependencies, optimized for Apple silicon via ARM NEON, Accelerate and Metal frameworks, and supports various architectures like AVX, AVX2, AVX512, and AMX. It offers integer quantization for faster inference, custom CUDA kernels for NVIDIA GPUs, Vulkan and SYCL backend support, and CPU+GPU hybrid inference. llama.cpp is the main playground for developing new features for the ggml library, supporting various models and providing tools and infrastructure for LLM deployment.
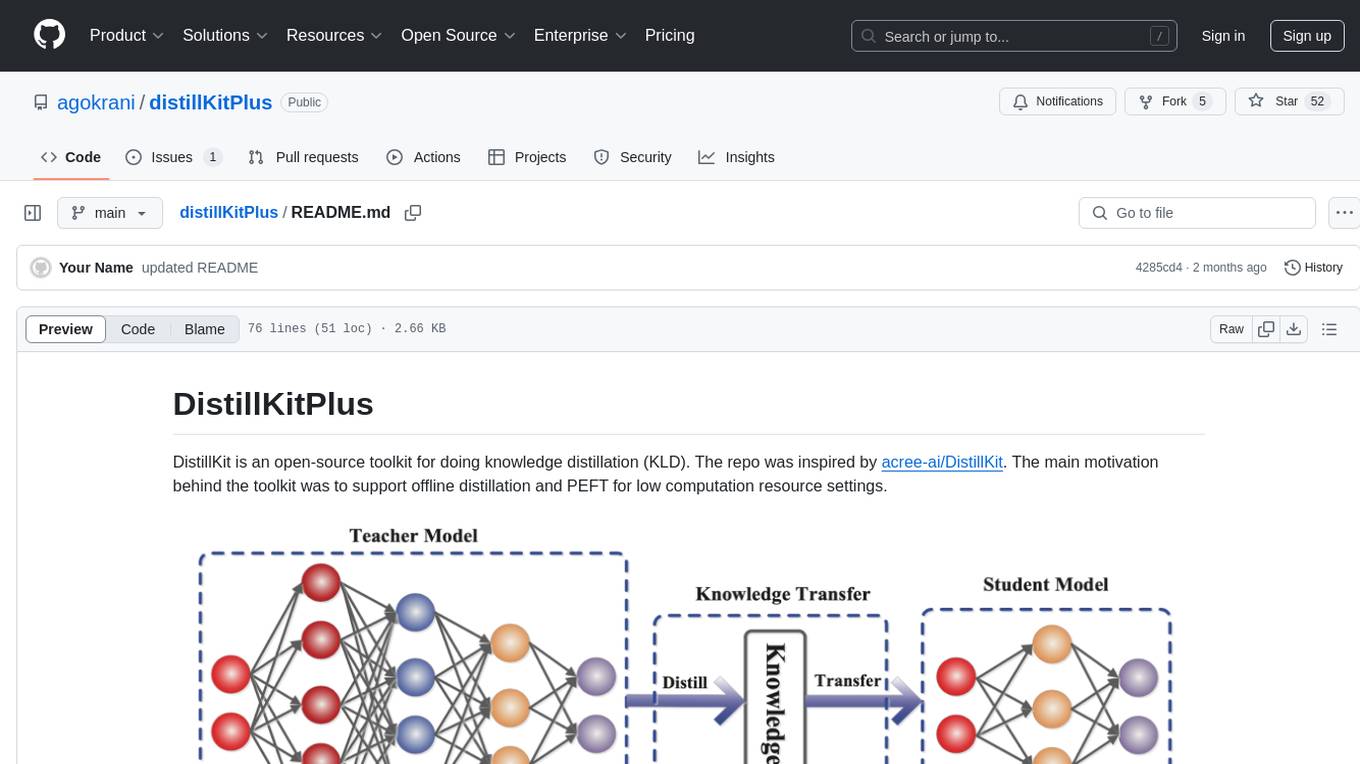
distillKitPlus
DistillKitPlus is an open-source toolkit designed for knowledge distillation (KLD) in low computation resource settings. It supports logit distillation, pre-computed logits for memory-efficient training, LoRA fine-tuning integration, and model quantization for faster inference. The toolkit utilizes a JSON configuration file for project, dataset, model, tokenizer, training, distillation, LoRA, and quantization settings. Users can contribute to the toolkit and contact the developers for technical questions or issues.

exllamav2
ExLlamaV2 is an inference library designed for running local LLMs on modern consumer GPUs. The library supports paged attention via Flash Attention 2.5.7+, offers a new dynamic generator with features like dynamic batching, smart prompt caching, and K/V cache deduplication. It also provides an API for local or remote inference using TabbyAPI, with extended features like HF model downloading and support for HF Jinja2 chat templates. ExLlamaV2 aims to optimize performance and speed across different GPU models, with potential future optimizations and variations in speeds. The tool can be integrated with TabbyAPI for OpenAI-style web API compatibility and supports a standalone web UI called ExUI for single-user interaction with chat and notebook modes. ExLlamaV2 also offers support for text-generation-webui and lollms-webui through specific loaders and bindings.
FastDeploy
FastDeploy is an inference and deployment toolkit for large language models and visual language models based on PaddlePaddle. It provides production-ready deployment solutions with core acceleration technologies such as load-balanced PD disaggregation, unified KV cache transmission, OpenAI API server compatibility, comprehensive quantization format support, advanced acceleration techniques, and multi-hardware support. The toolkit supports various hardware platforms like NVIDIA GPUs, Kunlunxin XPUs, Iluvatar GPUs, Enflame GCUs, and Hygon DCUs, with plans for expanding support to Ascend NPU and MetaX GPU. FastDeploy aims to optimize resource utilization, throughput, and performance for inference and deployment tasks.

AngelSlim
AngelSlim is a comprehensive and efficient large model compression toolkit designed to be user-friendly. It integrates mainstream compression algorithms for easy one-click access, continuously innovates compression algorithms, and optimizes end-to-end performance in model compression and deployment. It supports various models for quantization and speculative sampling, with a focus on performance optimization and ease of use.
SINQ
SINQ (Sinkhorn-Normalized Quantization) is a novel, fast, and high-quality quantization method designed to make any Large Language Models smaller while keeping their accuracy almost intact. It offers a model-agnostic quantization technique that delivers state-of-the-art performance for Large Language Models without sacrificing accuracy. With SINQ, users can deploy models that would otherwise be too big, drastically reducing memory usage while preserving LLM quality. The tool quantizes models using dual scaling for better quantization and achieves a more even error distribution, leading to stable behavior across layers and consistently higher accuracy even at very low bit-widths.