
ComfyUI-Ollama-Describer
A ComfyUI extension that allows you to use some LLM templates provided by Ollama, such as Gemma, Llava (multimodal), Llama2, Llama3 or Mistral
Stars: 70
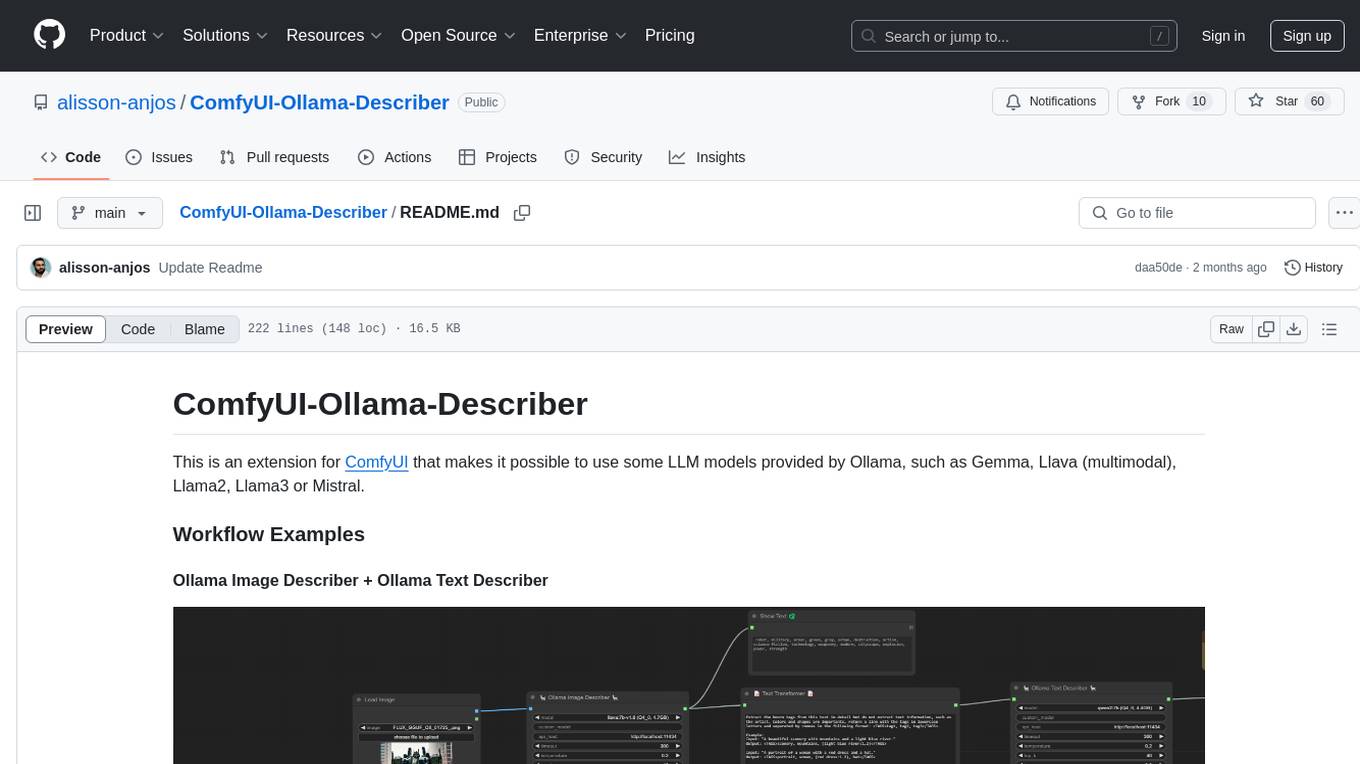
ComfyUI-Ollama-Describer is an extension for ComfyUI that enables the use of LLM models provided by Ollama, such as Gemma, Llava (multimodal), Llama2, Llama3, or Mistral. It requires the Ollama library for interacting with large-scale language models, supporting GPUs using CUDA and AMD GPUs on Windows, Linux, and Mac. The extension allows users to run Ollama through Docker and utilize NVIDIA GPUs for faster processing. It provides nodes for image description, text description, image captioning, and text transformation, with various customizable parameters for model selection, API communication, response generation, and model memory management.
README:
- Now, nodes can accept Pydantic Schemas as input, making it easier to define structured outputs.
- To generate Pydantic schemas, you can use the Python Interpreter Node by Christian Byrne.
This extension for ComfyUI enables the use of Ollama LLM models, such as Gemma, Llava (multimodal), Llama2, Llama3, and Mistral.
- Ollama Image Describer 🖼️: Generate structured descriptions of images.
- Ollama Text Describer 📝: Extract meaningful insights from text.
- Ollama Image Captioner 📷: Create automatic captions for images.
- Ollama Captioner Extra Options ⚙️: Advanced customization for captions.
- Text Transformer 🔄: Prepend, append, or modify text dynamically.
- JSON Property Extractor 📑: Extract specific values from JSON outputs.
Follow the official Ollama installation guide.
The easiest way to install this extension is through ComfyUI Manager:
- Open ComfyUI Manager.
- Search for ComfyUI-Ollama-Describer.
- Click Install and restart ComfyUI.
git clone https://github.com/alisson-anjos/ComfyUI-Ollama-Describer.gitPath should be custom_nodes\ComfyUI-Ollama-Describer.
Run install.bat
pip install -r requirements.txt
- Extracts structured descriptions from images using vision-enabled LLMs.
- Useful for analyzing images and generating detailed captions, including objects, actions, and surroundings.
-
model: Select LLaVa models (7B, 13B, etc.). -
custom_model: Specify a custom model from Ollama's library. -
api_host: Define the API address (e.g.,http://localhost:11434). -
timeout: Max response time before canceling the request. -
temperature: Controls randomness (0 = factual, 1 = creative). -
top_k,top_p,repeat_penalty: Fine-tune text generation. -
max_tokens: Maximum response length in tokens. -
seed_number: Set seed for reproducibility (-1 for random). -
keep_model_alive: Defines how long the model stays loaded after execution:-
0: Unloads immediately. -
-1: Stays loaded indefinitely. - Any other value (e.g.,
10) keeps it in memory for that number of seconds.
-
-
prompt: The main instruction for the model. -
system_context: Provide additional context for better responses. -
structured_output_format: Accepts either a Python dictionary or a valid JSON string to define the expected response structure.

- Used to extract specific values from structured JSON outputs returned by Ollama Image Describer or Ollama Text Describer.
- Works by selecting a key (or path) inside a JSON structure and outputting only the requested data.
- Useful for filtering, extracting key insights, or formatting responses for further processing.
- Compatible with
structured_output_format, which allows defining structured outputs via a Python dictionary or a valid JSON string.

- Processes text inputs to generate structured descriptions or summaries.
- Ideal for refining text-based outputs and enhancing context understanding.


- Automatically generates concise and relevant captions for images.
- Processes images from a specified folder, iterates through each file, and generates
.txtcaption files saved in the output directory. - Useful for bulk image captioning, dataset preparation, and AI-assisted annotation.
- Useful for image-to-text applications, content tagging, and accessibility.

-
Works in conjunction with Ollama Image Captioner to provide additional customization for captions.
-
Allows fine-tuning of captions by enabling or disabling specific details like lighting, camera angle, composition, and aesthetic quality.
-
Useful for controlling caption verbosity, accuracy, and inclusion of metadata like camera settings or image quality.
-
Helps tailor the output for different applications such as dataset labeling, content creation, and accessibility enhancements.
-
Provides additional customization settings for generated captions.
-
Helps refine style, verbosity, and accuracy based on user preferences.

- Allows users to modify, append, prepend, or replace text dynamically.
- Useful for formatting, restructuring, and enhancing text-based outputs.
| Suffix | Meaning |
|---|---|
| Q | Quantized model (smaller, faster) |
| 4, 8, etc. | Number of bits used (lower = smaller & faster) |
| K | K-means quantization (more efficient) |
| M | Medium-sized model |
| F16 / F32 | Floating-point precision (higher = more accurate) |
More details on quantization: Medium Article.
- Measures how well a model predicts text.
- Lower perplexity = better predictions.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ComfyUI-Ollama-Describer
Similar Open Source Tools
ComfyUI-Ollama-Describer
ComfyUI-Ollama-Describer is an extension for ComfyUI that enables the use of LLM models provided by Ollama, such as Gemma, Llava (multimodal), Llama2, Llama3, or Mistral. It requires the Ollama library for interacting with large-scale language models, supporting GPUs using CUDA and AMD GPUs on Windows, Linux, and Mac. The extension allows users to run Ollama through Docker and utilize NVIDIA GPUs for faster processing. It provides nodes for image description, text description, image captioning, and text transformation, with various customizable parameters for model selection, API communication, response generation, and model memory management.

layra
LAYRA is the world's first visual-native AI automation engine that sees documents like a human, preserves layout and graphical elements, and executes arbitrarily complex workflows with full Python control. It empowers users to build next-generation intelligent systems with no limits or compromises. Built for Enterprise-Grade deployment, LAYRA features a modern frontend, high-performance backend, decoupled service architecture, visual-native multimodal document understanding, and a powerful workflow engine.
retrace
Retrace is a local-first screen recording and search application for macOS, inspired by Rewind AI. It captures screen activity, extracts text via OCR, and makes everything searchable locally on-device. The project is in very early development, offering features like continuous screen capture, OCR text extraction, full-text search, timeline viewer, dashboard analytics, Rewind AI import, settings panel, global hotkeys, HEVC video encoding, search highlighting, privacy controls, and more. Built with a modular architecture, Retrace uses Swift 5.9+, SwiftUI, Vision framework, SQLite with FTS5, HEVC video encoding, CryptoKit for encryption, and more. Future releases will include features like audio transcription and semantic search. Retrace requires macOS 13.0+ (Apple Silicon required) and Xcode 15.0+ for building from source, with permissions for screen recording and accessibility. Contributions are welcome, and the project is licensed under the MIT License.

ComfyUI_Yvann-Nodes
ComfyUI_Yvann-Nodes is a pack of custom nodes that enable audio reactivity within ComfyUI, allowing users to create AI-driven animations that sync with music. Users can generate audio reactive AI videos, control AI generation styles, content, and composition with any audio input. The tool is simple to use by dropping workflows in ComfyUI and specifying audio and visual inputs. It is flexible and works with existing ComfyUI AI tech and nodes like IPAdapter, AnimateDiff, and ControlNet. Users can pick workflows for Images → Video or Video → Video, download the corresponding .json file, drop it into ComfyUI, install missing custom nodes, set inputs, and generate audio-reactive animations.
J.A.R.V.I.S.2.0
J.A.R.V.I.S. 2.0 is an AI-powered assistant designed for voice commands, capable of tasks like providing weather reports, summarizing news, sending emails, and more. It features voice activation, speech recognition, AI responses, and handles multiple tasks including email sending, weather reports, news reading, image generation, database functions, phone call automation, AI-based task execution, website & application automation, and knowledge-based interactions. The assistant also includes timeout handling, automatic input processing, and the ability to call multiple functions simultaneously. It requires Python 3.9 or later and specific API keys for weather, news, email, and AI access. The tool integrates Gemini AI for function execution and Ollama as a fallback mechanism. It utilizes a RAG-based knowledge system and ADB integration for phone automation. Future enhancements include deeper mobile integration, advanced AI-driven automation, improved NLP-based command execution, and multi-modal interactions.
evi-run
evi-run is a powerful, production-ready multi-agent AI system built on Python using the OpenAI Agents SDK. It offers instant deployment, ultimate flexibility, built-in analytics, Telegram integration, and scalable architecture. The system features memory management, knowledge integration, task scheduling, multi-agent orchestration, custom agent creation, deep research, web intelligence, document processing, image generation, DEX analytics, and Solana token swap. It supports flexible usage modes like private, free, and pay mode, with upcoming features including NSFW mode, task scheduler, and automatic limit orders. The technology stack includes Python 3.11, OpenAI Agents SDK, Telegram Bot API, PostgreSQL, Redis, and Docker & Docker Compose for deployment.
llxprt-code
LLxprt Code is an AI-powered coding assistant that works with any LLM provider, offering a command-line interface for querying and editing codebases, generating applications, and automating development workflows. It supports various subscriptions, provider flexibility, top open models, local model support, and a privacy-first approach. Users can interact with LLxprt Code in both interactive and non-interactive modes, leveraging features like subscription OAuth, multi-account failover, load balancer profiles, and extensive provider support. The tool also allows for the creation of advanced subagents for specialized tasks and integrates with the Zed editor for in-editor chat and code selection.
llmchat
LLMChat is an all-in-one AI chat interface that supports multiple language models, offers a plugin library for enhanced functionality, enables web search capabilities, allows customization of AI assistants, provides text-to-speech conversion, ensures secure local data storage, and facilitates data import/export. It also includes features like knowledge spaces, prompt library, personalization, and can be installed as a Progressive Web App (PWA). The tech stack includes Next.js, TypeScript, Pglite, LangChain, Zustand, React Query, Supabase, Tailwind CSS, Framer Motion, Shadcn, and Tiptap. The roadmap includes upcoming features like speech-to-text and knowledge spaces.
structured-prompt-builder
A lightweight, browser-first tool for designing well-structured AI prompts with a clean UI, live previews, a local Prompt Library, and optional Gemini-powered prompt optimization. It supports structured fields like Role, Task, Audience, Style, Tone, Constraints, Steps, Inputs, and Few-shot examples. Users can copy/download prompts in Markdown, JSON, and YAML formats, and utilize model parameters like Temperature, Top-p, Max tokens, Presence & Frequency penalties. The tool also features a Local Prompt Library for saving, loading, duplicating, and deleting prompts, as well as a Gemini Optimizer for cleaning grammar/clarity without altering the schema. It offers dark/light friendly styles and a focused reading mode for long prompts.
ito
Ito is an intelligent voice assistant that provides seamless voice dictation to any application on your computer. It works in any app, offers global keyboard shortcuts, real-time transcription, and instant text insertion. It is smart and adaptive with features like custom dictionary, context awareness, multi-language support, and intelligent punctuation. Users can customize trigger keys, audio preferences, and privacy controls. It also offers data management features like a notes system, interaction history, cloud sync, and export capabilities. Ito is built as a modern Electron application with a multi-process architecture and utilizes technologies like React, TypeScript, Rust, gRPC, and AWS CDK.
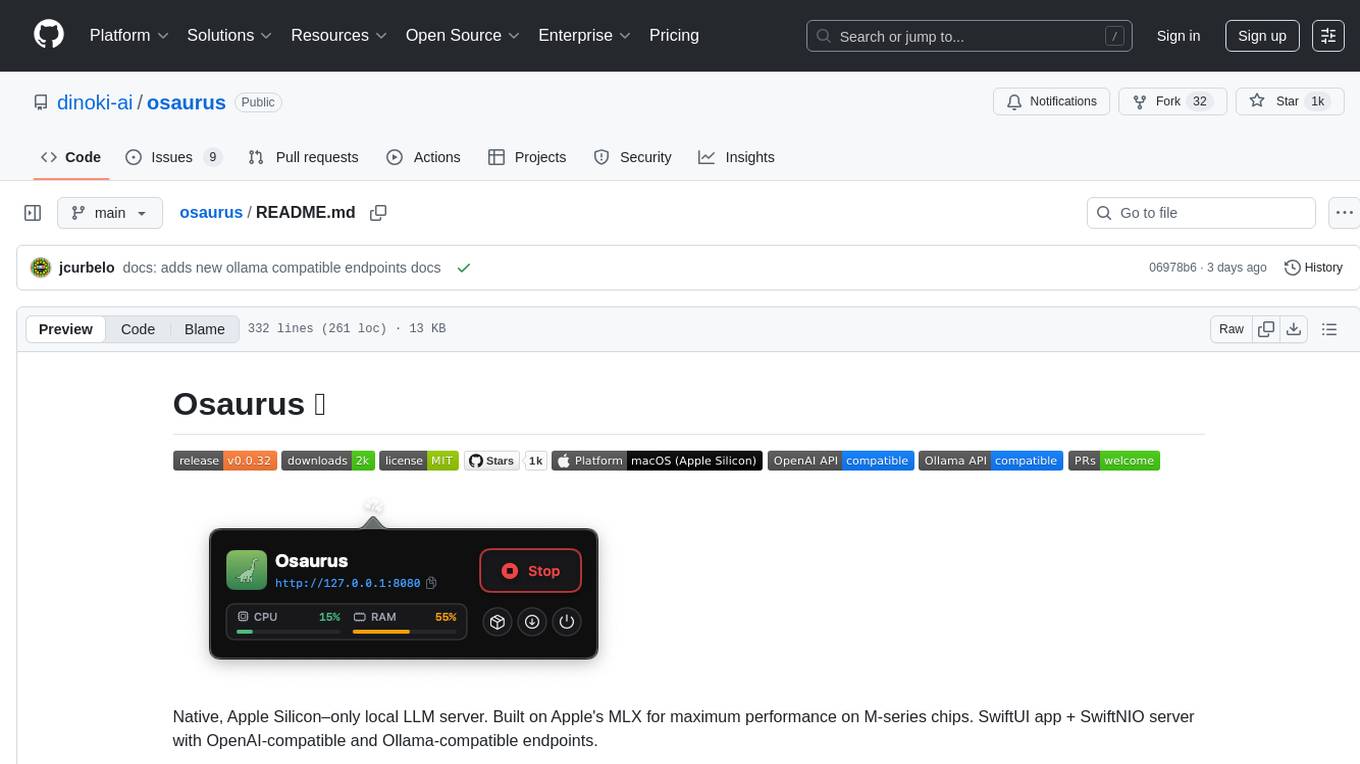
osaurus
Osaurus is a native, Apple Silicon-only local LLM server built on Apple's MLX for maximum performance on M‑series chips. It is a SwiftUI app + SwiftNIO server with OpenAI‑compatible and Ollama‑compatible endpoints. The tool supports native MLX text generation, model management, streaming and non‑streaming chat completions, OpenAI‑compatible function calling, real-time system resource monitoring, and path normalization for API compatibility. Osaurus is designed for macOS 15.5+ and Apple Silicon (M1 or newer) with Xcode 16.4+ required for building from source.

stable-diffusion.cpp
The stable-diffusion.cpp repository provides an implementation for inferring stable diffusion in pure C/C++. It offers features such as support for different versions of stable diffusion, lightweight and dependency-free implementation, various quantization support, memory-efficient CPU inference, GPU acceleration, and more. Users can download the built executable program or build it manually. The repository also includes instructions for downloading weights, building from scratch, using different acceleration methods, running the tool, converting weights, and utilizing various features like Flash Attention, ESRGAN upscaling, PhotoMaker support, and more. Additionally, it mentions future TODOs and provides information on memory requirements, bindings, UIs, contributors, and references.
persistent-ai-memory
Persistent AI Memory System is a comprehensive tool that offers persistent, searchable storage for AI assistants. It includes features like conversation tracking, MCP tool call logging, and intelligent scheduling. The system supports multiple databases, provides enhanced memory management, and offers various tools for memory operations, schedule management, and system health checks. It also integrates with various platforms like LM Studio, VS Code, Koboldcpp, Ollama, and more. The system is designed to be modular, platform-agnostic, and scalable, allowing users to handle large conversation histories efficiently.
ToolUniverse
ToolUniverse is a collection of 211 biomedical tools designed for Agentic AI, providing access to biomedical knowledge for solving therapeutic reasoning tasks. The tools cover various aspects of drugs and diseases, linked to trusted sources like US FDA-approved drugs since 1939, Open Targets, and Monarch Initiative.

TranslateBookWithLLM
TranslateBookWithLLM is a Python application designed for large-scale text translation, such as entire books (.EPUB), subtitle files (.SRT), and plain text. It leverages local LLMs via the Ollama API or Gemini API. The tool offers both a web interface for ease of use and a command-line interface for advanced users. It supports multiple format translations, provides a user-friendly browser-based interface, CLI support for automation, multiple LLM providers including local Ollama models and Google Gemini API, and Docker support for easy deployment.
oneclick-subtitles-generator
A comprehensive web application for auto-subtitling videos and audio, translating SRT files, generating AI narration with voice cloning, creating background images, and rendering professional subtitled videos. Designed for content creators, educators, and general users who need high-quality subtitle generation and video production capabilities.
For similar tasks

llama_ros
This repository provides a set of ROS 2 packages to integrate llama.cpp into ROS 2. By using the llama_ros packages, you can easily incorporate the powerful optimization capabilities of llama.cpp into your ROS 2 projects by running GGUF-based LLMs and VLMs.

InternVL
InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM. It is a vision-language foundation model that can perform various tasks, including: **Visual Perception** - Linear-Probe Image Classification - Semantic Segmentation - Zero-Shot Image Classification - Multilingual Zero-Shot Image Classification - Zero-Shot Video Classification **Cross-Modal Retrieval** - English Zero-Shot Image-Text Retrieval - Chinese Zero-Shot Image-Text Retrieval - Multilingual Zero-Shot Image-Text Retrieval on XTD **Multimodal Dialogue** - Zero-Shot Image Captioning - Multimodal Benchmarks with Frozen LLM - Multimodal Benchmarks with Trainable LLM - Tiny LVLM InternVL has been shown to achieve state-of-the-art results on a variety of benchmarks. For example, on the MMMU image classification benchmark, InternVL achieves a top-1 accuracy of 51.6%, which is higher than GPT-4V and Gemini Pro. On the DocVQA question answering benchmark, InternVL achieves a score of 82.2%, which is also higher than GPT-4V and Gemini Pro. InternVL is open-sourced and available on Hugging Face. It can be used for a variety of applications, including image classification, object detection, semantic segmentation, image captioning, and question answering.
RAG-Survey
This repository is dedicated to collecting and categorizing papers related to Retrieval-Augmented Generation (RAG) for AI-generated content. It serves as a survey repository based on the paper 'Retrieval-Augmented Generation for AI-Generated Content: A Survey'. The repository is continuously updated to keep up with the rapid growth in the field of RAG.
ComfyUI-Ollama-Describer
ComfyUI-Ollama-Describer is an extension for ComfyUI that enables the use of LLM models provided by Ollama, such as Gemma, Llava (multimodal), Llama2, Llama3, or Mistral. It requires the Ollama library for interacting with large-scale language models, supporting GPUs using CUDA and AMD GPUs on Windows, Linux, and Mac. The extension allows users to run Ollama through Docker and utilize NVIDIA GPUs for faster processing. It provides nodes for image description, text description, image captioning, and text transformation, with various customizable parameters for model selection, API communication, response generation, and model memory management.
ROSGPT_Vision
ROSGPT_Vision is a new robotic framework designed to command robots using only two prompts: a Visual Prompt for visual semantic features and an LLM Prompt to regulate robotic reactions. It is based on the Prompting Robotic Modalities (PRM) design pattern and is used to develop CarMate, a robotic application for monitoring driver distractions and providing real-time vocal notifications. The framework leverages state-of-the-art language models to facilitate advanced reasoning about image data and offers a unified platform for robots to perceive, interpret, and interact with visual data through natural language. LangChain is used for easy customization of prompts, and the implementation includes the CarMate application for driver monitoring and assistance.

aimet
AIMET is a library that provides advanced model quantization and compression techniques for trained neural network models. It provides features that have been proven to improve run-time performance of deep learning neural network models with lower compute and memory requirements and minimal impact to task accuracy. AIMET is designed to work with PyTorch, TensorFlow and ONNX models. We also host the AIMET Model Zoo - a collection of popular neural network models optimized for 8-bit inference. We also provide recipes for users to quantize floating point models using AIMET.

AutoGPTQ
AutoGPTQ is an easy-to-use LLM quantization package with user-friendly APIs, based on GPTQ algorithm (weight-only quantization). It provides a simple and efficient way to quantize large language models (LLMs) to reduce their size and computational cost while maintaining their performance. AutoGPTQ supports a wide range of LLM models, including GPT-2, GPT-J, OPT, and BLOOM. It also supports various evaluation tasks, such as language modeling, sequence classification, and text summarization. With AutoGPTQ, users can easily quantize their LLM models and deploy them on resource-constrained devices, such as mobile phones and embedded systems.

hqq
HQQ is a fast and accurate model quantizer that skips the need for calibration data. It's super simple to implement (just a few lines of code for the optimizer). It can crunch through quantizing the Llama2-70B model in only 4 minutes! 🚀
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.