
InternVL
[CVPR 2024 Oral] InternVL Family: A Pioneering Open-Source Alternative to GPT-4o. 接近GPT-4o表现的开源多模态对话模型
Stars: 6535

InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM. It is a vision-language foundation model that can perform various tasks, including: **Visual Perception** - Linear-Probe Image Classification - Semantic Segmentation - Zero-Shot Image Classification - Multilingual Zero-Shot Image Classification - Zero-Shot Video Classification **Cross-Modal Retrieval** - English Zero-Shot Image-Text Retrieval - Chinese Zero-Shot Image-Text Retrieval - Multilingual Zero-Shot Image-Text Retrieval on XTD **Multimodal Dialogue** - Zero-Shot Image Captioning - Multimodal Benchmarks with Frozen LLM - Multimodal Benchmarks with Trainable LLM - Tiny LVLM InternVL has been shown to achieve state-of-the-art results on a variety of benchmarks. For example, on the MMMU image classification benchmark, InternVL achieves a top-1 accuracy of 51.6%, which is higher than GPT-4V and Gemini Pro. On the DocVQA question answering benchmark, InternVL achieves a score of 82.2%, which is also higher than GPT-4V and Gemini Pro. InternVL is open-sourced and available on Hugging Face. It can be used for a variety of applications, including image classification, object detection, semantic segmentation, image captioning, and question answering.
README:
InternVL Family: Closing the Gap to Commercial Multimodal Models with Open-Source Suites —— A Pioneering Open-Source Alternative to GPT-4o
[🆕 Blog] [🤔 FAQs] [🗨️ Chat Demo] [🤗 HF Demo] [📖 Document] [🌐 API] [🚀 Quick Start]
[🔥 InternVL2.5 Report] [Mini-InternVL Paper] [InternVL2 Blog] [📜 InternVL 1.5 Paper] [📜 InternVL 1.0 Paper]
[📖 2.0 中文解读] [📖 1.5 中文解读] [📖 1.0 中文解读]
Switch to the Chinese version (切换至中文版)
-
2024/12/20: 🔥 We release the InternVL2.5-MPO, which is finetuned with Mixed Preference Optimization on MMPR-v1.1. The resulting models outperform their counterparts without MPO by an average of 2 points across all model scales on the OpenCompass leaderboard. These models are available at HF link. -
2024/12/17: 🚀 InternVL2/2.5 is supported in PaddleMIX by Paddle Team. -
2024/12/05: 🚀 We release the InternVL2.5, an advanced multimodal large language model (MLLM) series with parameter coverage ranging from 1B to 78B. InternVL2_5-78B is the first open-source MLLMs to achieve over 70% on the MMMU benchmark, matching the performance of leading closed-source commercial models like GPT-4o. These models are available at HF link. -
2024/11/14: We introduce MMPR, a high-quality, large-scale multimodal reasoning preference dataset, and MPO, an effective preference optimization algorithm. The resulting model, InternVL2-8B-MPO, achieves an accuracy of 67.0 on MathVista. Please refer to our paper, project page and document for more details. -
2024/10/21: We release the Mini-InternVL series. These models achieve impressive performance with minimal size: the 4B model achieves 90% of the performance with just 5% of the model size. For more details, please check our project page and document. -
2024/08/01: The Chartmimic team evaluated the InternVL2 series models on their benchmark. The InternVL2-26B and 76B models achieved the top two performances among open-source models, with the InternVL2 76B model surpassing GeminiProVision and exhibiting comparable results to Claude-3-opus. -
2024/08/01: InternVL2-Pro achieved the SOTA performance among open-source models on the CharXiv dataset, surpassing many closed-source models such as GPT-4V, Gemini 1.5 Flash, and Claude 3 Sonnet. -
2024/07/24: The MLVU team evaluated InternVL-1.5 on their benchmark. The average performance on the multiple-choice task was 50.4%, while the performance on the generative tasks was 4.02. The performance on the multiple-choice task ranked #1 among all open-source MLLMs. -
2024/07/04: We release the InternVL2 series. InternVL2-Pro achieved a 62.0% accuracy on the MMMU benchmark, matching the performance of leading closed-source commercial models like GPT-4o.
More News
-
2024/07/18: InternVL2-40B achieved SOTA performance among open-source models on the Video-MME dataset, scoring 61.2 when inputting 16 frames and 64.4 when inputting 32 frames. It significantly outperforms other open-source models and is the closest open-source model to GPT-4o mini. -
2024/07/18: InternVL2-Pro achieved the SOTA performance on the DocVQA and InfoVQA benchmarks. -
2024/06/19: We propose Needle In A Multimodal Haystack (MM-NIAH), the first benchmark designed to systematically evaluate the capability of existing MLLMs to comprehend long multimodal documents. -
2024/05/30: We release ShareGPT-4o, a large-scale dataset that we plan to open-source with 200K images, 10K videos, and 10K audios with detailed descriptions. -
2024/05/28: Thanks to the lmdeploy team for providing AWQ quantization support. The 4-bit model is available at OpenGVLab/InternVL-Chat-V1-5-AWQ. -
2024/05/13: InternVL 1.0 can now be used as the text encoder for diffusion models to support multilingual generation natively in over 110 languages worldwide. See MuLan for more details. -
2024/04/18: InternVL-Chat-V1-5 has been released at HF link, approaching the performance of GPT-4V and Gemini Pro on various benchmarks like MMMU, DocVQA, ChartQA, MathVista, etc. -
2024/02/27: InternVL is accepted by CVPR 2024 (Oral)! 🎉 -
2024/02/21: InternVL-Chat-V1-2-Plus achieved SOTA performance on MathVista (59.9), MMBench (83.8), and MMVP (58.7). See our blog for more details. -
2024/02/12: InternVL-Chat-V1-2 has been released. It achieves 51.6 on MMMU val and 82.3 on MMBench test. For more details, please refer to our blog and SFT data. The model is now available on HuggingFace, and both training / evaluation data and scripts are open-sourced. -
2024/01/24: InternVL-Chat-V1-1 is released, it supports Chinese and has stronger OCR capability, see here. -
2024/01/16: We release our customized mmcv/mmsegmentation/mmdetection code, integrated with DeepSpeed, which can be used for training large-scale detection and segmentation models.
- Installation: 🌱 Installation Guide | 📄 requirements.txt
- Chat Data Format: 📝 Meta File | ✏️ Text | 🖼️ Single-Image | 🖼️🖼️ Multi-Image | 🎥 Video
- Local Chat Demo: 🤖 Streamlit Demo
- InternVL-Chat API: 🌐 InternVL2-Pro
- Tutorials: 🚀 Enhancing InternVL2 on COCO Caption Using LoRA Fine-Tuning
- InternVL 2.5: 📖 Intro | ⚡ Quick Start | ✨ Finetune | 📊 Evaluate | 📦 Deploy | 🎯 MPO
- InternVL 2.0: 📖 Intro | ⚡ Quick Start | ✨ Finetune | 📊 Evaluate | 📦 Deploy | 🎯 MPO
- InternVL 1.5: 📖 Intro | ⚡ Quick Start | ✨ Finetune | 📊 Evaluate | 📦 Deploy
- InternVL 1.2: 📖 Intro | ⚡ Quick Start | ✨ Finetune | 📊 Evaluate
- InternVL 1.1: 📖 Intro | ⚡ Quick Start | 📊 Evaluation
- InternVL 1.0: 🖼️ Classification | 📊 CLIP-Benchmark | 🎨 Segmentation | 💬 Chat-LLaVA | ✨ InternVL-G
| Model Name | Vision Part | Language Part | HF Link | MS Link |
|---|---|---|---|---|
| InternVL2_5-1B | InternViT‑300M‑448px‑V2_5 | Qwen2.5‑0.5B‑Instruct | 🤗 link | 🤖 link |
| InternVL2_5-2B | InternViT-300M-448px-V2_5 | internlm2_5-1_8b-chat | 🤗 link | 🤖 link |
| InternVL2_5-4B | InternViT-300M-448px-V2_5 | Qwen2.5-3B-Instruct | 🤗 link | 🤖 link |
| InternVL2_5-8B | InternViT-300M-448px-V2_5 | internlm2_5-7b-chat | 🤗 link | 🤖 link |
| InternVL2_5-26B | InternViT-6B-448px-V2_5 | internlm2_5-20b-chat | 🤗 link | 🤖 link |
| InternVL2_5-38B | InternViT-6B-448px-V2_5 | Qwen2.5-32B-Instruct | 🤗 link | 🤖 link |
| InternVL2_5-78B | InternViT-6B-448px-V2_5 | Qwen2.5-72B-Instruct | 🤗 link | 🤖 link |
| Model Name | Vision Part | Language Part | HF Link | MS Link |
|---|---|---|---|---|
| InternVL2_5-1B-MPO | InternViT‑300M‑448px‑V2_5 | Qwen2.5‑0.5B‑Instruct | 🤗 link | 🤖 link |
| InternVL2_5-2B-MPO | InternViT-300M-448px-V2_5 | internlm2_5-1_8b-chat | 🤗 link | 🤖 link |
| InternVL2_5-4B-MPO | InternViT-300M-448px-V2_5 | Qwen2.5-3B-Instruct | 🤗 link | 🤖 link |
| InternVL2_5-8B-MPO | InternViT-300M-448px-V2_5 | internlm2_5-7b-chat | 🤗 link | 🤖 link |
| InternVL2_5-26B-MPO | InternViT-6B-448px-V2_5 | internlm2_5-20b-chat | 🤗 link | 🤖 link |
| InternVL2_5-38B-MPO | InternViT-6B-448px-V2_5 | Qwen2.5-32B-Instruct | 🤗 link | 🤖 link |
| InternVL2_5-78B-MPO | InternViT-6B-448px-V2_5 | Qwen2.5-72B-Instruct | 🤗 link | 🤖 link |
| Model Name | Vision Part | Language Part | HF Link | MS Link |
|---|---|---|---|---|
| InternVL2-1B | InternViT-300M-448px | Qwen2-0.5B-Instruct | 🤗 link | 🤖 link |
| InternVL2-2B | InternViT-300M-448px | internlm2-chat-1-8b | 🤗 link | 🤖 link |
| InternVL2-4B | InternViT-300M-448px | Phi‑3‑mini‑128k‑instruct | 🤗 link | 🤖 link |
| InternVL2-8B | InternViT-300M-448px | internlm2_5-7b-chat | 🤗 link | 🤖 link |
| InternVL2-26B | InternViT-6B-448px-V1-5 | internlm2-chat-20b | 🤗 link | 🤖 link |
| InternVL2-40B | InternViT‑6B‑448px‑V1‑5 | Nous‑Hermes‑2‑Yi‑34B | 🤗 link | 🤖 link |
| InternVL2‑Llama3-76B | InternViT-6B-448px-V1-5 | Hermes‑2‑Theta‑ Llama‑3‑70B |
🤗 link | 🤖 link |
| Model | Date | HF Link | MS Link | Note |
|---|---|---|---|---|
| Mini‑InternVL‑Chat‑4B‑V1‑5 | 2024.05.28 | 🤗 link | 🤖 link | 🚀🚀 16% of the model size, 90% of the performance |
| Mini-InternVL-Chat-2B-V1-5 | 2024.05.19 | 🤗 link | 🤖 link | 🚀 8% of the model size, 80% of the performance |
| InternVL-Chat-V1-5 | 2024.04.18 | 🤗 link | 🤖 link | support 4K image; super strong OCR; Approaching the performance of GPT-4V and Gemini Pro on various benchmarks like MMMU, DocVQA, ChartQA, MathVista, etc. |
| InternVL-Chat-V1-2-Plus | 2024.02.21 | 🤗 link | 🤖 link | more SFT data and stronger |
| InternVL-Chat-V1-2 | 2024.02.11 | 🤗 link | 🤖 link | scaling up LLM to 34B |
| InternVL-Chat-V1-1 | 2024.01.24 | 🤗 link | 🤖 link | support Chinese and stronger OCR |
| InternVL-Chat-19B | 2023.12.25 | 🤗 link | 🤖 link | English multimodal dialogue |
| InternVL-Chat-13B | 2023.12.25 | 🤗 link | 🤖 link | English multimodal dialogue |
| Model | Date | HF Link | MS Link | Note |
|---|---|---|---|---|
| InternViT-300M-448px-V2_5 | 2024.12.05 | 🤗 link | 🤖 link | 🚀🚀 A more powerful lightweight visual encoder. (🔥new) |
| InternViT-6B-448px-V2_5 | 2024.12.05 | 🤗 link | 🤖 link | 🚀🚀 A stronger visual encoder to extract visual features. (🔥new) |
| InternViT-300M-448px | 2024.05.25 | 🤗 link | 🤖 link | distilled small vision foundation model with 300M parameters |
| InternViT‑6B‑448px‑V1‑5 | 2024.04.20 | 🤗 link | 🤖 link | support dynamic resolution and super strong OCR feature extraction capability by incremental pre-training |
| InternViT-6B-448px-V1-2 | 2024.02.11 | 🤗 link | 🤖 link | support 448 resolution by incremental pre-training |
| InternViT-6B-448px-V1-0 | 2024.01.30 | 🤗 link | 🤖 link | support 448 resolution by incremental pre-training |
| InternViT-6B-224px | 2023.12.22 | 🤗 link | 🤖 link | the first version of InternViT-6B, extracted from InternVL‑14B‑224px |
| Model | Date | HF Link | MS Link | Note |
|---|---|---|---|---|
| InternVL‑14B‑224px | 2023.12.22 | 🤗 link | 🤖 link | vision-language foundation model, InternViT-6B + QLLaMA, can be used for image-text retrieval like CLIP |
- [x] Release training / evaluation code for InternVL2.5 series
- [x] Support liger kernels to save GPU memory
- [x] Release the code, model, and data of MPO
- [x] Support multimodal packed dataset
- [ ] Support vLLM and Ollama
- [ ] Support video and PDF input in online demo
- [ ] Release InternVL2 with VisionLLMv2 integration
- [x] Rebuild documents using readthedocs
- [x] Support fine-tuning different LLMs with LoRA
- [x] Release
requirements.txtfor InternVL2 - [x] Release training / evaluation code for InternVL2 series
- [x] Release Streamlit web UI for InternVL1.5 and InternVL2
Visual Perception (click to expand)
-
Linear-Probe Image Classification [see details]
ViT-22B uses the private JFT-3B dataset.
method #param IN-1K IN-ReaL IN-V2 IN-A IN-R IN-Sketch OpenCLIP-G 1.8B 86.2 89.4 77.2 63.8 87.8 66.4 DINOv2-g 1.1B 86.5 89.6 78.4 75.9 78.8 62.5 EVA-01-CLIP-g 1.1B 86.5 89.3 77.4 70.5 87.7 63.1 MAWS-ViT-6.5B 6.5B 87.8 - - - - - ViT-22B* 21.7B 89.5 90.9 83.2 83.8 87.4 - InternViT-6B (ours) 5.9B 88.2 90.4 79.9 77.5 89.8 69.1 -
Semantic Segmentation [see details]
method decoder #param (train/total) crop size mIoU OpenCLIP-G (frozen) Linear 0.3M / 1.8B 512 39.3 ViT-22B (frozen) Linear 0.9M / 21.7B 504 34.6 InternViT-6B (frozen) Linear 0.5M / 5.9B 504 47.2 (+12.6) ViT-22B (frozen) UperNet 0.8B / 22.5B 504 52.7 InternViT-6B (frozen) UperNet 0.4B / 6.3B 504 54.9 (+2.2) ViT-22B UperNet 22.5B / 22.5B 504 55.3 InternViT-6B UperNet 6.3B / 6.3B 504 58.9 (+3.6) -
Zero-Shot Image Classification [see details]
method IN-1K IN-A IN-R IN-V2 IN-Sketch ObjectNet OpenCLIP-G 80.1 69.3 92.1 73.6 68.9 73.0 EVA-02-CLIP-E+ 82.0 82.1 94.5 75.7 71.6 79.6 ViT-22B* 85.9 90.1 96.0 80.9 - 87.6 InternVL-C (ours) 83.2 83.8 95.5 77.3 73.9 80.6 -
Multilingual Zero-Shot Image Classification [see details]
EN: English, ZH: Chinese, JP: Japanese, Ar: Arabic, IT: Italian
method IN-1K (EN) IN-1K (ZH) IN-1K (JP) IN-1K (AR) IN-1K (IT) Taiyi-CLIP-ViT-H - 54.4 - - - WuKong-ViT-L-G - 57.5 - - - CN-CLIP-ViT-H - 59.6 - - - AltCLIP-ViT-L 74.5 59.6 - - - EVA-02-CLIP-E+ 82.0 - - - 41.2 OpenCLIP-XLM-R-H 77.0 55.7 53.1 37.0 56.8 InternVL-C (ours) 83.2 64.5 61.5 44.9 65.7 -
Zero-Shot Video Classification
method #frame K400 K600 K700 OpenCLIP-G 1 65.9 66.1 59.2 EVA-02-CLIP-E+ 1 69.8 69.3 63.4 InternVL-C (ours) 1 71.0 71.3 65.7 ViCLIP 8 75.7 73.5 66.4 InternVL-C (ours) 8 79.4 78.8 71.5
Cross-Modal Retrieval (click to expand)
-
English Zero-Shot Image-Text Retrieval [see details]
model Flickr30K COCO avg image-to-text text-to-image image-to-text text-to-image R@1 R@5 R@10 R@1 R@5 R@10 R@1 R@5 R@10 R@1 R@5 R@10 OpenCLIP-G 92.9 99.3 99.8 79.5 95.0 97.1 67.3 86.9 92.6 51.4 74.9 83.0 85.0 EVA-02-CLIP-E+ 93.9 99.4 99.8 78.8 94.2 96.8 68.8 87.8 92.8 51.1 75.0 82.7 85.1 EVA-CLIP-8B 95.6 99.6 99.9 80.8 95.5 97.6 70.3 89.3 93.9 53.0 76.0 83.4 86.2 InternVL-C (ours) 94.7 99.6 99.9 81.7 96.0 98.2 70.6 89.0 93.5 54.1 77.3 84.6 86.6 InternVL-G (ours) 95.7 99.7 99.9 85.0 97.0 98.6 74.9 91.3 95.2 58.6 81.3 88.0 88.8 -
Chinese Zero-Shot Image-Text Retrieval [see details]
model Flickr30K-CN COCO-CN avg image-to-text text-to-image image-to-text text-to-image R@1 R@5 R@10 R@1 R@5 R@10 R@1 R@5 R@10 R@1 R@5 R@10 CN-CLIP-ViT-H 81.6 97.5 98.8 71.2 91.4 95.5 63.0 86.6 92.9 69.2 89.9 96.1 86.1 OpenCLIP-XLM-R-H 86.1 97.5 99.2 71.0 90.5 94.9 70.0 91.5 97.0 66.1 90.8 96.0 87.6 InternVL-C (ours) 90.3 98.8 99.7 75.1 92.9 96.4 68.8 92.0 96.7 68.9 91.9 96.5 89.0 InternVL-G (ours) 92.9 99.4 99.8 77.7 94.8 97.3 71.4 93.9 97.7 73.8 94.4 98.1 90.9 -
Multilingual Zero-Shot Image-Text Retrieval on XTD [see details]
method EN ES FR ZH IT KO RU JP average AltCLIP 95.4 94.1 92.9 95.1 94.2 94.4 91.8 91.7 93.7 OpenCLIP-XLM-R-H 97.3 96.1 94.5 94.7 96.0 90.2 93.9 94.0 94.6 InternVL-C (ours) 97.3 95.7 95.1 95.6 96.0 92.2 93.3 95.5 95.1 InternVL-G (ours) 98.6 97.7 96.5 96.7 96.9 95.1 94.8 96.1 96.6
Multimodal Dialogue
using InternViT-6B for visual feature extraction (click to expand)
import torch
from PIL import Image
from transformers import AutoModel, CLIPImageProcessor
model = AutoModel.from_pretrained(
'OpenGVLab/InternViT-6B-448px-V2_5',
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True).cuda().eval()
image = Image.open('./examples/image1.jpg').convert('RGB')
image_processor = CLIPImageProcessor.from_pretrained('OpenGVLab/InternViT-6B-448px-V1-5')
pixel_values = image_processor(images=image, return_tensors='pt').pixel_values
pixel_values = pixel_values.to(torch.bfloat16).cuda()
outputs = model(pixel_values)using InternVL-C(ontrastive) and InternVL-G(enerative) for cross-modal retrieval (click to expand)
import torch
from PIL import Image
from transformers import AutoModel, CLIPImageProcessor
from transformers import AutoTokenizer
model = AutoModel.from_pretrained(
'OpenGVLab/InternVL-14B-224px',
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True).cuda().eval()
image_processor = CLIPImageProcessor.from_pretrained('OpenGVLab/InternVL-14B-224px')
tokenizer = AutoTokenizer.from_pretrained(
'OpenGVLab/InternVL-14B-224px', use_fast=False, add_eos_token=True)
tokenizer.pad_token_id = 0 # set pad_token_id to 0
images = [
Image.open('./examples/image1.jpg').convert('RGB'),
Image.open('./examples/image2.jpg').convert('RGB'),
Image.open('./examples/image3.jpg').convert('RGB')
]
prefix = 'summarize:'
texts = [
prefix + 'a photo of a red panda', # English
prefix + '一张熊猫的照片', # Chinese
prefix + '二匹の猫の写真' # Japanese
]
pixel_values = image_processor(images=images, return_tensors='pt').pixel_values
pixel_values = pixel_values.to(torch.bfloat16).cuda()
input_ids = tokenizer(texts, return_tensors='pt', max_length=80,
truncation=True, padding='max_length').input_ids.cuda()
# InternVL-C
logits_per_image, logits_per_text = model(
image=pixel_values, text=input_ids, mode='InternVL-C')
probs = logits_per_image.softmax(dim=-1)
# tensor([[9.9609e-01, 5.2185e-03, 6.0070e-08],
# [2.2949e-02, 9.7656e-01, 5.9903e-06],
# [3.2932e-06, 7.4863e-05, 1.0000e+00]], device='cuda:0',
# dtype=torch.bfloat16, grad_fn=<SoftmaxBackward0>)
# InternVL-G
logits_per_image, logits_per_text = model(
image=pixel_values, text=input_ids, mode='InternVL-G')
probs = logits_per_image.softmax(dim=-1)
# tensor([[9.9609e-01, 3.1738e-03, 3.6322e-08],
# [8.6060e-03, 9.9219e-01, 2.8759e-06],
# [1.7583e-06, 3.1233e-05, 1.0000e+00]], device='cuda:0',
# dtype=torch.bfloat16, grad_fn=<SoftmaxBackward0>)
# please set add_eos_token to False for generation
tokenizer.add_eos_token = False
image = Image.open('./examples/image1.jpg').convert('RGB')
pixel_values = image_processor(images=image, return_tensors='pt').pixel_values
pixel_values = pixel_values.to(torch.bfloat16).cuda()
tokenized = tokenizer("English caption:", return_tensors='pt')
pred = model.generate(
pixel_values=pixel_values,
input_ids=tokenized.input_ids.cuda(),
attention_mask=tokenized.attention_mask.cuda(),
num_beams=5,
min_new_tokens=8,
)
caption = tokenizer.decode(pred[0].cpu(), skip_special_tokens=True).strip()
# English caption: a red panda sitting on top of a wooden platformusing InternVL 2.5 for multimodal chat (click to expand)
Here, we take the smaller OpenGVLab/InternVL2_5-8B as an example:
import numpy as np
import torch
import torchvision.transforms as T
from decord import VideoReader, cpu
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
from transformers import AutoModel, AutoTokenizer
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
# If you have an 80G A100 GPU, you can put the entire model on a single GPU.
# Otherwise, you need to load a model using multiple GPUs, please refer to the `Multiple GPUs` section.
path = 'OpenGVLab/InternVL2_5-8B'
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True).eval().cuda()
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
# set the max number of tiles in `max_num`
pixel_values = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
generation_config = dict(max_new_tokens=1024, do_sample=False)
# pure-text conversation (纯文本对话)
question = 'Hello, who are you?'
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Can you tell me a story?'
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# single-image single-round conversation (单图单轮对话)
question = '<image>\nPlease describe the image shortly.'
response = model.chat(tokenizer, pixel_values, question, generation_config)
print(f'User: {question}\nAssistant: {response}')
# single-image multi-round conversation (单图多轮对话)
question = '<image>\nPlease describe the image in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Please write a poem according to the image.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, combined images (多图多轮对话,拼接图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
question = '<image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, separate images (多图多轮对话,独立图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
question = 'Image-1: <image>\nImage-2: <image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# batch inference, single image per sample (单图批处理)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
questions = ['<image>\nDescribe the image in detail.'] * len(num_patches_list)
responses = model.batch_chat(tokenizer, pixel_values,
num_patches_list=num_patches_list,
questions=questions,
generation_config=generation_config)
for question, response in zip(questions, responses):
print(f'User: {question}\nAssistant: {response}')
# video multi-round conversation (视频多轮对话)
def get_index(bound, fps, max_frame, first_idx=0, num_segments=32):
if bound:
start, end = bound[0], bound[1]
else:
start, end = -100000, 100000
start_idx = max(first_idx, round(start * fps))
end_idx = min(round(end * fps), max_frame)
seg_size = float(end_idx - start_idx) / num_segments
frame_indices = np.array([
int(start_idx + (seg_size / 2) + np.round(seg_size * idx))
for idx in range(num_segments)
])
return frame_indices
def load_video(video_path, bound=None, input_size=448, max_num=1, num_segments=32):
vr = VideoReader(video_path, ctx=cpu(0), num_threads=1)
max_frame = len(vr) - 1
fps = float(vr.get_avg_fps())
pixel_values_list, num_patches_list = [], []
transform = build_transform(input_size=input_size)
frame_indices = get_index(bound, fps, max_frame, first_idx=0, num_segments=num_segments)
for frame_index in frame_indices:
img = Image.fromarray(vr[frame_index].asnumpy()).convert('RGB')
img = dynamic_preprocess(img, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(tile) for tile in img]
pixel_values = torch.stack(pixel_values)
num_patches_list.append(pixel_values.shape[0])
pixel_values_list.append(pixel_values)
pixel_values = torch.cat(pixel_values_list)
return pixel_values, num_patches_list
video_path = './examples/red-panda.mp4'
pixel_values, num_patches_list = load_video(video_path, num_segments=8, max_num=1)
pixel_values = pixel_values.to(torch.bfloat16).cuda()
video_prefix = ''.join([f'Frame-{i+1}: <image>\n' for i in range(len(num_patches_list))])
question = video_prefix + 'What is the red panda doing?'
# Frame1: <image>\nFrame2: <image>\n...\nFrame8: <image>\n{question}
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Describe this video in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')This project is released under the MIT license. Parts of this project contain code and models from other sources, which are subject to their respective licenses.
If you find this project useful in your research, please consider cite:
@article{chen2024expanding,
title={Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling},
author={Chen, Zhe and Wang, Weiyun and Cao, Yue and Liu, Yangzhou and Gao, Zhangwei and Cui, Erfei and Zhu, Jinguo and Ye, Shenglong and Tian, Hao and Liu, Zhaoyang and others},
journal={arXiv preprint arXiv:2412.05271},
year={2024}
}
@article{wang2024mpo,
title={Enhancing the Reasoning Ability of Multimodal Large Language Models via Mixed Preference Optimization},
author={Wang, Weiyun and Chen, Zhe and Wang, Wenhai and Cao, Yue and Liu, Yangzhou and Gao, Zhangwei and Zhu, Jinguo and Zhu, Xizhou and Lu, Lewei and Qiao, Yu and Dai, Jifeng},
journal={arXiv preprint arXiv:2411.10442},
year={2024}
}
@article{gao2024mini,
title={Mini-InternVL: a flexible-transfer pocket multi-modal model with 5\% parameters and 90\% performance},
author={Gao, Zhangwei and Chen, Zhe and Cui, Erfei and Ren, Yiming and Wang, Weiyun and Zhu, Jinguo and Tian, Hao and Ye, Shenglong and He, Junjun and Zhu, Xizhou and others},
journal={Visual Intelligence},
volume={2},
number={1},
pages={1--17},
year={2024},
publisher={Springer}
}
@article{chen2024far,
title={How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites},
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others},
journal={Science China Information Sciences},
volume={67},
number={12},
pages={220101},
year={2024},
publisher={Springer}
}
@inproceedings{chen2024internvl,
title={Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks},
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and others},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={24185--24198},
year={2024}
}InternVL is built with reference to the code of the following projects: OpenAI CLIP, Open CLIP, CLIP Benchmark, EVA, InternImage, ViT-Adapter, MMSegmentation, Transformers, DINOv2, BLIP-2, Qwen-VL, and LLaVA-1.5. Thanks for their awesome work!
Scan the following QR Code, join our WeChat group.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for InternVL
Similar Open Source Tools
InternVL
InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM. It is a vision-language foundation model that can perform various tasks, including: **Visual Perception** - Linear-Probe Image Classification - Semantic Segmentation - Zero-Shot Image Classification - Multilingual Zero-Shot Image Classification - Zero-Shot Video Classification **Cross-Modal Retrieval** - English Zero-Shot Image-Text Retrieval - Chinese Zero-Shot Image-Text Retrieval - Multilingual Zero-Shot Image-Text Retrieval on XTD **Multimodal Dialogue** - Zero-Shot Image Captioning - Multimodal Benchmarks with Frozen LLM - Multimodal Benchmarks with Trainable LLM - Tiny LVLM InternVL has been shown to achieve state-of-the-art results on a variety of benchmarks. For example, on the MMMU image classification benchmark, InternVL achieves a top-1 accuracy of 51.6%, which is higher than GPT-4V and Gemini Pro. On the DocVQA question answering benchmark, InternVL achieves a score of 82.2%, which is also higher than GPT-4V and Gemini Pro. InternVL is open-sourced and available on Hugging Face. It can be used for a variety of applications, including image classification, object detection, semantic segmentation, image captioning, and question answering.

MOSS-TTS
MOSS-TTS Family is an open-source speech and sound generation model family designed for high-fidelity, high-expressiveness, and complex real-world scenarios. It includes five production-ready models: MOSS-TTS, MOSS-TTSD, MOSS-VoiceGenerator, MOSS-TTS-Realtime, and MOSS-SoundEffect, each serving specific purposes in speech generation, dialogue, voice design, real-time interactions, and sound effect generation. The models offer features like long-speech generation, fine-grained control over phonemes and duration, multilingual synthesis, voice cloning, and real-time voice agents.

DataFlow
DataFlow is a data preparation and training system designed to parse, generate, process, and evaluate high-quality data from noisy sources, improving the performance of large language models in specific domains. It constructs diverse operators and pipelines, validated to enhance domain-oriented LLM's performance in fields like healthcare, finance, and law. DataFlow also features an intelligent DataFlow-agent capable of dynamically assembling new pipelines by recombining existing operators on demand.

TRACE
TRACE is a temporal grounding video model that utilizes causal event modeling to capture videos' inherent structure. It presents a task-interleaved video LLM model tailored for sequential encoding/decoding of timestamps, salient scores, and textual captions. The project includes various model checkpoints for different stages and fine-tuning on specific datasets. It provides evaluation codes for different tasks like VTG, MVBench, and VideoMME. The repository also offers annotation files and links to raw videos preparation projects. Users can train the model on different tasks and evaluate the performance based on metrics like CIDER, METEOR, SODA_c, F1, mAP, Hit@1, etc. TRACE has been enhanced with trace-retrieval and trace-uni models, showing improved performance on dense video captioning and general video understanding tasks.

YuLan-Mini
YuLan-Mini is a lightweight language model with 2.4 billion parameters that achieves performance comparable to industry-leading models despite being pre-trained on only 1.08T tokens. It excels in mathematics and code domains. The repository provides pre-training resources, including data pipeline, optimization methods, and annealing approaches. Users can pre-train their own language models, perform learning rate annealing, fine-tune the model, research training dynamics, and synthesize data. The team behind YuLan-Mini is AI Box at Renmin University of China. The code is released under the MIT License with future updates on model weights usage policies. Users are advised on potential safety concerns and ethical use of the model.

langfuse
Langfuse is a powerful tool that helps you develop, monitor, and test your LLM applications. With Langfuse, you can: * **Develop:** Instrument your app and start ingesting traces to Langfuse, inspect and debug complex logs, and manage, version, and deploy prompts from within Langfuse. * **Monitor:** Track metrics (cost, latency, quality) and gain insights from dashboards & data exports, collect and calculate scores for your LLM completions, run model-based evaluations, collect user feedback, and manually score observations in Langfuse. * **Test:** Track and test app behaviour before deploying a new version, test expected in and output pairs and benchmark performance before deploying, and track versions and releases in your application. Langfuse is easy to get started with and offers a generous free tier. You can sign up for Langfuse Cloud or deploy Langfuse locally or on your own infrastructure. Langfuse also offers a variety of integrations to make it easy to connect to your LLM applications.

flute
FLUTE (Flexible Lookup Table Engine for LUT-quantized LLMs) is a tool designed for uniform quantization and lookup table quantization of weights in lower-precision intervals. It offers flexibility in mapping intervals to arbitrary values through a lookup table. FLUTE supports various quantization formats such as int4, int3, int2, fp4, fp3, fp2, nf4, nf3, nf2, and even custom tables. The tool also introduces new quantization algorithms like Learned Normal Float (NFL) for improved performance and calibration data learning. FLUTE provides benchmarks, model zoo, and integration with frameworks like vLLM and HuggingFace for easy deployment and usage.

oumi
Oumi is an open-source platform for building state-of-the-art foundation models, offering tools for data preparation, training, evaluation, and deployment. It supports training and fine-tuning models with various parameters, working with text and multimodal models, synthesizing and curating training data, deploying models efficiently, evaluating models comprehensively, and running on different platforms. Oumi provides a consistent API, reliability, and flexibility for research purposes.
FlipAttack
FlipAttack is a jailbreak attack tool designed to exploit black-box Language Model Models (LLMs) by manipulating text inputs. It leverages insights into LLMs' autoregressive nature to construct noise on the left side of the input text, deceiving the model and enabling harmful behaviors. The tool offers four flipping modes to guide LLMs in denoising and executing malicious prompts effectively. FlipAttack is characterized by its universality, stealthiness, and simplicity, allowing users to compromise black-box LLMs with just one query. Experimental results demonstrate its high success rates against various LLMs, including GPT-4o and guardrail models.
LightMem
LightMem is a lightweight and efficient memory management framework designed for Large Language Models and AI Agents. It provides a simple yet powerful memory storage, retrieval, and update mechanism to help you quickly build intelligent applications with long-term memory capabilities. The framework is minimalist in design, ensuring minimal resource consumption and fast response times. It offers a simple API for easy integration into applications with just a few lines of code. LightMem's modular architecture supports custom storage engines and retrieval strategies, making it flexible and extensible. It is compatible with various cloud APIs like OpenAI and DeepSeek, as well as local models such as Ollama and vLLM.
MMOS
MMOS (Mix of Minimal Optimal Sets) is a dataset designed for math reasoning tasks, offering higher performance and lower construction costs. It includes various models and data subsets for tasks like arithmetic reasoning and math word problem solving. The dataset is used to identify minimal optimal sets through reasoning paths and statistical analysis, with a focus on QA-pairs generated from open-source datasets. MMOS also provides an auto problem generator for testing model robustness and scripts for training and inference.
go-cyber
Cyber is a superintelligence protocol that aims to create a decentralized and censorship-resistant internet. It uses a novel consensus mechanism called CometBFT and a knowledge graph to store and process information. Cyber is designed to be scalable, secure, and efficient, and it has the potential to revolutionize the way we interact with the internet.
llmq
llm.q is an implementation of (quantized) large language model training in CUDA, inspired by llm.c. It is particularly aimed at medium-sized training setups, i.e., a single node with multiple GPUs. The code is written in C++20 and requires CUDA 12 or later. It depends on nccl for communication, and cudnn for fast attention. Multi-GPU training can either be run in multi-process mode (requires OpenMPI) or in multi-thread mode. Additional header-only dependencies are automatically downloaded by cmake during the build process. The tool provides detailed instructions on data preparation, training runs, inspecting logs, evaluations, and a larger example for real training runs. It also offers detailed usage instructions covering model configuration, data configuration, optimization parameters, checkpointing, output, low-bit settings, activation checkpointing/recomputation, multi-GPU settings, offloading, algorithm selection, and Python bindings. The code organization includes directories for kernels, models, training, and utilities. Speed benchmarks for different GPU configurations are provided, along with testing details for recomputation, fixed reference, and Python reference tests.

VoiceBench
VoiceBench is a repository containing code and data for benchmarking LLM-Based Voice Assistants. It includes a leaderboard with rankings of various voice assistant models based on different evaluation metrics. The repository provides setup instructions, datasets, evaluation procedures, and a curated list of awesome voice assistants. Users can submit new voice assistant results through the issue tracker for updates on the ranking list.
gpupixel
GPUPixel is a real-time, high-performance image and video filter library written in C++11 and based on OpenGL/ES. It incorporates a built-in beauty face filter that achieves commercial-grade beauty effects. The library is extremely easy to compile and integrate with a small size, supporting platforms including iOS, Android, Mac, Windows, and Linux. GPUPixel provides various filters like skin smoothing, whitening, face slimming, big eyes, lipstick, and blush. It supports input formats like YUV420P, RGBA, JPEG, PNG, and output formats like RGBA and YUV420P. The library's performance on devices like iPhone and Android is optimized, with low CPU usage and fast processing times. GPUPixel's lib size is compact, making it suitable for mobile and desktop applications.
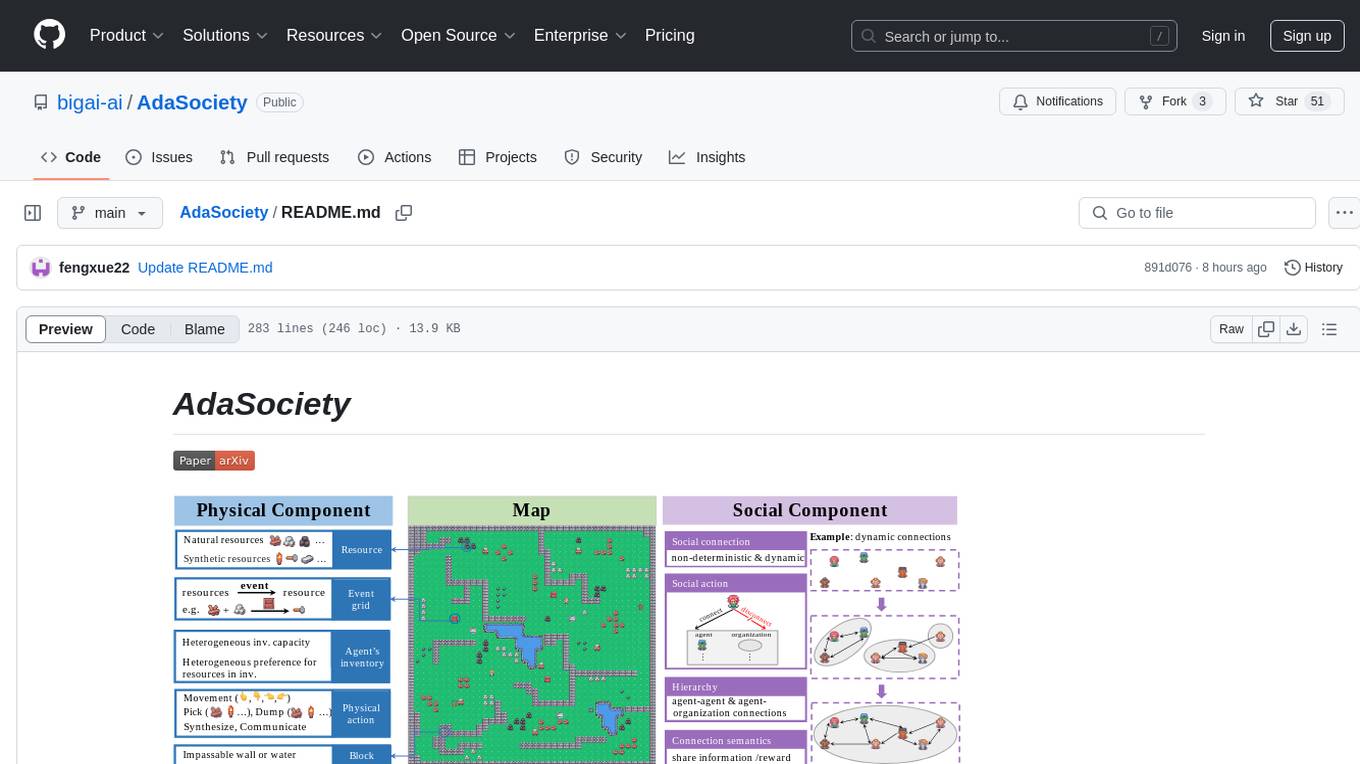
AdaSociety
AdaSociety is a multi-agent environment designed for simulating social structures and decision-making processes. It offers built-in resources, events, and player interactions. Users can customize the environment through JSON configuration or custom Python code. The environment supports training agents using RLlib and LLM frameworks. It provides a platform for studying multi-agent systems and social dynamics.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs
InternVL
InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM. It is a vision-language foundation model that can perform various tasks, including: **Visual Perception** - Linear-Probe Image Classification - Semantic Segmentation - Zero-Shot Image Classification - Multilingual Zero-Shot Image Classification - Zero-Shot Video Classification **Cross-Modal Retrieval** - English Zero-Shot Image-Text Retrieval - Chinese Zero-Shot Image-Text Retrieval - Multilingual Zero-Shot Image-Text Retrieval on XTD **Multimodal Dialogue** - Zero-Shot Image Captioning - Multimodal Benchmarks with Frozen LLM - Multimodal Benchmarks with Trainable LLM - Tiny LVLM InternVL has been shown to achieve state-of-the-art results on a variety of benchmarks. For example, on the MMMU image classification benchmark, InternVL achieves a top-1 accuracy of 51.6%, which is higher than GPT-4V and Gemini Pro. On the DocVQA question answering benchmark, InternVL achieves a score of 82.2%, which is also higher than GPT-4V and Gemini Pro. InternVL is open-sourced and available on Hugging Face. It can be used for a variety of applications, including image classification, object detection, semantic segmentation, image captioning, and question answering.
BlossomLM
BlossomLM is a series of open-source conversational large language models. This project aims to provide a high-quality general-purpose SFT dataset in both Chinese and English, making fine-tuning accessible while also providing pre-trained model weights. **Hint**: BlossomLM is a personal non-commercial project.
rtp-llm
**rtp-llm** is a Large Language Model (LLM) inference acceleration engine developed by Alibaba's Foundation Model Inference Team. It is widely used within Alibaba Group, supporting LLM service across multiple business units including Taobao, Tmall, Idlefish, Cainiao, Amap, Ele.me, AE, and Lazada. The rtp-llm project is a sub-project of the havenask.