
llm4s
Scala 3 bindings for llama.cpp
Stars: 56

llm4s is an experimental Scala 3 bindings tool for llama.cpp using Slinc. It provides version compatibility with Scala 3.3.0 and JDK 17, 19 for llama.cpp. Users can utilize llm4s to work with llama.cpp shared library and model, enabling completion and embeddings functionalities in Scala.
README:

Experimental Scala 3 bindings for llama.cpp using Slinc.
Add llm4s to your build.sbt:
libraryDependencies += "com.donderom" %% "llm4s" % "0.11.0"For JDK 17 add .jvmopts file in the project root:
--add-modules=jdk.incubator.foreign
--enable-native-access=ALL-UNNAMED
Version compatibility:
| llm4s | Scala | JDK | llama.cpp (commit hash) |
|---|---|---|---|
| 0.11+ | 3.3.0 | 17, 19 | 229ffff (May 8, 2024) |
Older versions
| llm4s | Scala | JDK | llama.cpp (commit hash) |
|---|---|---|---|
| 0.10+ | 3.3.0 | 17, 19 | 49e7cb5 (Jul 31, 2023) |
| 0.6+ | --- | --- | 49e7cb5 (Jul 31, 2023) |
| 0.4+ | --- | --- | 70d26ac (Jul 23, 2023) |
| 0.3+ | --- | --- | a6803ca (Jul 14, 2023) |
| 0.1+ | 3.3.0-RC3 | 17, 19 | 447ccbe (Jun 25, 2023) |
import java.nio.file.Paths
import com.donderom.llm4s.*
// Path to the llama.cpp shared library
System.load("llama.cpp/libllama.so")
// Path to the model supported by llama.cpp
val model = Paths.get("models/llama-7b-v2/llama-2-7b.Q4_K_M.gguf")
val prompt = "Large Language Model is"val llm = Llm(model)
// To print generation as it goes
llm(prompt).foreach: stream =>
stream.foreach: token =>
print(token)
// Or build a string
llm(prompt).foreach(stream => println(stream.mkString))
llm.close()val llm = Llm(model)
llm.embeddings(prompt).foreach: embeddings =>
embeddings.foreach: embd =>
print(embd)
print(' ')
llm.close()For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm4s
Similar Open Source Tools
llm4s
llm4s is an experimental Scala 3 bindings tool for llama.cpp using Slinc. It provides version compatibility with Scala 3.3.0 and JDK 17, 19 for llama.cpp. Users can utilize llm4s to work with llama.cpp shared library and model, enabling completion and embeddings functionalities in Scala.

flute
FLUTE (Flexible Lookup Table Engine for LUT-quantized LLMs) is a tool designed for uniform quantization and lookup table quantization of weights in lower-precision intervals. It offers flexibility in mapping intervals to arbitrary values through a lookup table. FLUTE supports various quantization formats such as int4, int3, int2, fp4, fp3, fp2, nf4, nf3, nf2, and even custom tables. The tool also introduces new quantization algorithms like Learned Normal Float (NFL) for improved performance and calibration data learning. FLUTE provides benchmarks, model zoo, and integration with frameworks like vLLM and HuggingFace for easy deployment and usage.

tiny-llm-zh
Tiny LLM zh is a project aimed at building a small-parameter Chinese language large model for quick entry into learning large model-related knowledge. The project implements a two-stage training process for large models and subsequent human alignment, including tokenization, pre-training, instruction fine-tuning, human alignment, evaluation, and deployment. It is deployed on ModeScope Tiny LLM website and features open access to all data and code, including pre-training data and tokenizer. The project trains a tokenizer using 10GB of Chinese encyclopedia text to build a Tiny LLM vocabulary. It supports training with Transformers deepspeed, multiple machine and card support, and Zero optimization techniques. The project has three main branches: llama2_torch, main tiny_llm, and tiny_llm_moe, each with specific modifications and features.
grps_trtllm
The grps-trtllm repository is a C++ implementation of a high-performance OpenAI LLM service, combining GRPS and TensorRT-LLM. It supports functionalities like Chat, Ai-agent, and Multi-modal. The repository offers advantages over triton-trtllm, including a complete LLM service implemented in pure C++, integrated tokenizer supporting huggingface and sentencepiece, custom HTTP functionality for OpenAI interface, support for different LLM prompt styles and result parsing styles, integration with tensorrt backend and opencv library for multi-modal LLM, and stable performance improvement compared to triton-trtllm.
LightMem
LightMem is a lightweight and efficient memory management framework designed for Large Language Models and AI Agents. It provides a simple yet powerful memory storage, retrieval, and update mechanism to help you quickly build intelligent applications with long-term memory capabilities. The framework is minimalist in design, ensuring minimal resource consumption and fast response times. It offers a simple API for easy integration into applications with just a few lines of code. LightMem's modular architecture supports custom storage engines and retrieval strategies, making it flexible and extensible. It is compatible with various cloud APIs like OpenAI and DeepSeek, as well as local models such as Ollama and vLLM.

InternVL
InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM. It is a vision-language foundation model that can perform various tasks, including: **Visual Perception** - Linear-Probe Image Classification - Semantic Segmentation - Zero-Shot Image Classification - Multilingual Zero-Shot Image Classification - Zero-Shot Video Classification **Cross-Modal Retrieval** - English Zero-Shot Image-Text Retrieval - Chinese Zero-Shot Image-Text Retrieval - Multilingual Zero-Shot Image-Text Retrieval on XTD **Multimodal Dialogue** - Zero-Shot Image Captioning - Multimodal Benchmarks with Frozen LLM - Multimodal Benchmarks with Trainable LLM - Tiny LVLM InternVL has been shown to achieve state-of-the-art results on a variety of benchmarks. For example, on the MMMU image classification benchmark, InternVL achieves a top-1 accuracy of 51.6%, which is higher than GPT-4V and Gemini Pro. On the DocVQA question answering benchmark, InternVL achieves a score of 82.2%, which is also higher than GPT-4V and Gemini Pro. InternVL is open-sourced and available on Hugging Face. It can be used for a variety of applications, including image classification, object detection, semantic segmentation, image captioning, and question answering.
react-native-nitro-mlx
The react-native-nitro-mlx repository allows users to run LLMs, Text-to-Speech, and Speech-to-Text on-device in React Native using MLX Swift. It provides functionalities for downloading models, loading and generating responses, streaming audio, text-to-speech, and speech-to-text capabilities. Users can interact with various MLX-compatible models from Hugging Face, with pre-defined models available for convenience. The repository supports iOS 26.0+ and offers detailed API documentation for each feature.
ReGraph
ReGraph is a decentralized AI compute marketplace that connects hardware providers with developers who need inference and training resources. It democratizes access to AI computing power by creating a global network of distributed compute nodes. It is cost-effective, decentralized, easy to integrate, supports multiple models, and offers pay-as-you-go pricing.

EVE
EVE is an official PyTorch implementation of Unveiling Encoder-Free Vision-Language Models. The project aims to explore the removal of vision encoders from Vision-Language Models (VLMs) and transfer LLMs to encoder-free VLMs efficiently. It also focuses on bridging the performance gap between encoder-free and encoder-based VLMs. EVE offers a superior capability with arbitrary image aspect ratio, data efficiency by utilizing publicly available data for pre-training, and training efficiency with a transparent and practical strategy for developing a pure decoder-only architecture across modalities.
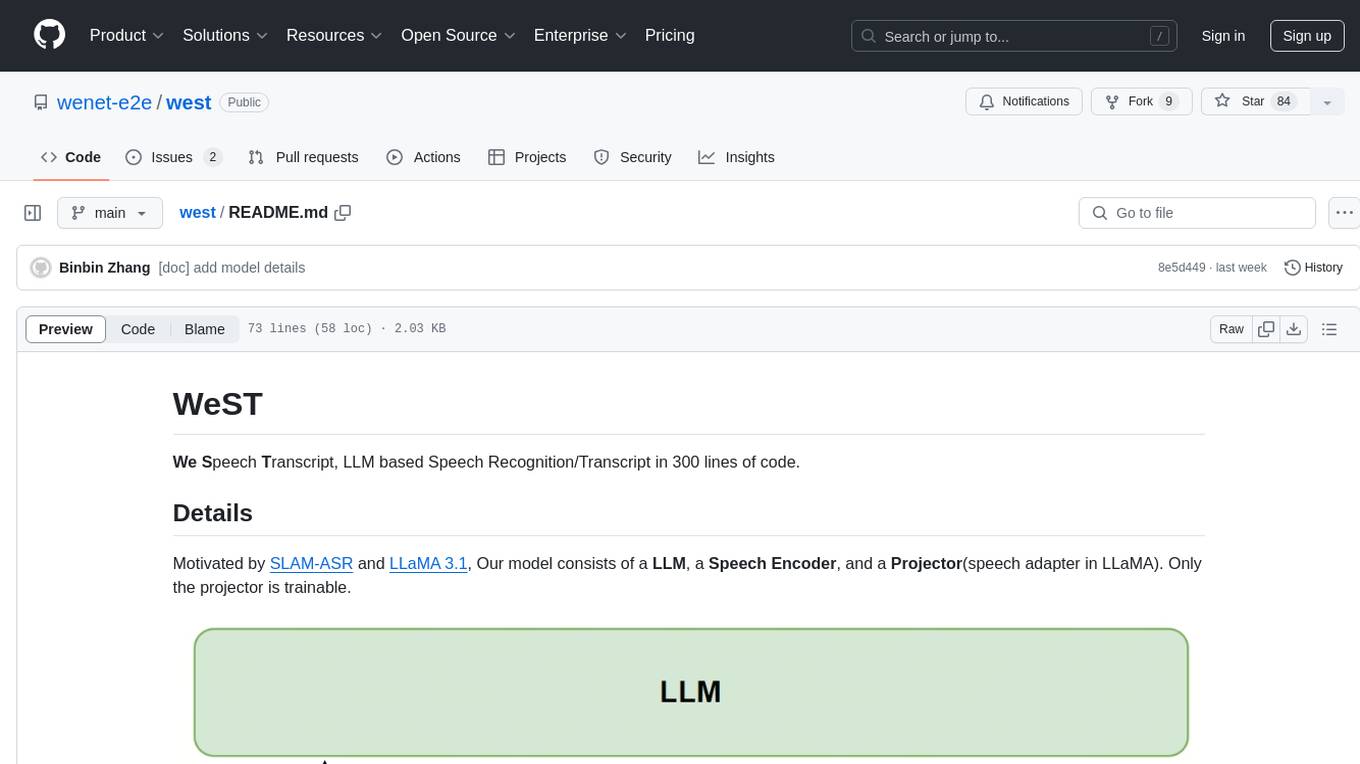
west
WeST is a Speech Recognition/Transcript tool developed in 300 lines of code, inspired by SLAM-ASR and LLaMA 3.1. The model includes a Language Model (LLM), a Speech Encoder, and a trainable Projector. It requires training data in jsonl format with 'wav' and 'txt' entries. WeST can be used for training and decoding speech recognition models.

bce-qianfan-sdk
The Qianfan SDK provides best practices for large model toolchains, allowing AI workflows and AI-native applications to access the Qianfan large model platform elegantly and conveniently. The core capabilities of the SDK include three parts: large model reasoning, large model training, and general and extension: * `Large model reasoning`: Implements interface encapsulation for reasoning of Yuyan (ERNIE-Bot) series, open source large models, etc., supporting dialogue, completion, Embedding, etc. * `Large model training`: Based on platform capabilities, it supports end-to-end large model training process, including training data, fine-tuning/pre-training, and model services. * `General and extension`: General capabilities include common AI development tools such as Prompt/Debug/Client. The extension capability is based on the characteristics of Qianfan to adapt to common middleware frameworks.

Steel-LLM
Steel-LLM is a project to pre-train a large Chinese language model from scratch using over 1T of data to achieve a parameter size of around 1B, similar to TinyLlama. The project aims to share the entire process including data collection, data processing, pre-training framework selection, model design, and open-source all the code. The goal is to enable reproducibility of the work even with limited resources. The name 'Steel' is inspired by a band '万能青年旅店' and signifies the desire to create a strong model despite limited conditions. The project involves continuous data collection of various cultural elements, trivia, lyrics, niche literature, and personal secrets to train the LLM. The ultimate aim is to fill the model with diverse data and leave room for individual input, fostering collaboration among users.
clother
Clother is a command-line tool that allows users to switch between different Claude Code providers instantly. It provides launchers for various cloud, open router, China endpoints, local, and custom providers, enabling users to configure, list profiles, test connectivity, check installation status, and uninstall. Users can also change the default model for each provider and troubleshoot common issues. Clother simplifies the management of API keys and installation directories, supporting macOS, Linux, and Windows (WSL) platforms. It is designed to streamline the workflow of interacting with different AI models and services.
ChatGLM3
ChatGLM3 is a conversational pretrained model jointly released by Zhipu AI and THU's KEG Lab. ChatGLM3-6B is the open-sourced model in the ChatGLM3 series. It inherits the advantages of its predecessors, such as fluent conversation and low deployment threshold. In addition, ChatGLM3-6B introduces the following features: 1. A stronger foundation model: ChatGLM3-6B's foundation model ChatGLM3-6B-Base employs more diverse training data, more sufficient training steps, and more reasonable training strategies. Evaluation on datasets from different perspectives, such as semantics, mathematics, reasoning, code, and knowledge, shows that ChatGLM3-6B-Base has the strongest performance among foundation models below 10B parameters. 2. More complete functional support: ChatGLM3-6B adopts a newly designed prompt format, which supports not only normal multi-turn dialogue, but also complex scenarios such as tool invocation (Function Call), code execution (Code Interpreter), and Agent tasks. 3. A more comprehensive open-source sequence: In addition to the dialogue model ChatGLM3-6B, the foundation model ChatGLM3-6B-Base, the long-text dialogue model ChatGLM3-6B-32K, and ChatGLM3-6B-128K, which further enhances the long-text comprehension ability, are also open-sourced. All the above weights are completely open to academic research and are also allowed for free commercial use after filling out a questionnaire.
WeClone
WeClone is a tool that fine-tunes large language models using WeChat chat records. It utilizes approximately 20,000 integrated and effective data points, resulting in somewhat satisfactory outcomes that are occasionally humorous. The tool's effectiveness largely depends on the quantity and quality of the chat data provided. It requires a minimum of 16GB of GPU memory for training using the default chatglm3-6b model with LoRA method. Users can also opt for other models and methods supported by LLAMA Factory, which consume less memory. The tool has specific hardware and software requirements, including Python, Torch, Transformers, Datasets, Accelerate, and other optional packages like CUDA and Deepspeed. The tool facilitates environment setup, data preparation, data preprocessing, model downloading, parameter configuration, model fine-tuning, and inference through a browser demo or API service. Additionally, it offers the ability to deploy a WeChat chatbot, although users should be cautious due to the risk of account suspension by WeChat.

cactus
Cactus is an energy-efficient and fast AI inference framework designed for phones, wearables, and resource-constrained arm-based devices. It provides a bottom-up approach with no dependencies, optimizing for budget and mid-range phones. The framework includes Cactus FFI for integration, Cactus Engine for high-level transformer inference, Cactus Graph for unified computation graph, and Cactus Kernels for low-level ARM-specific operations. It is suitable for implementing custom models and scientific computing on mobile devices.
For similar tasks
llm4s
llm4s is an experimental Scala 3 bindings tool for llama.cpp using Slinc. It provides version compatibility with Scala 3.3.0 and JDK 17, 19 for llama.cpp. Users can utilize llm4s to work with llama.cpp shared library and model, enabling completion and embeddings functionalities in Scala.
ollama-ai
Ollama AI is a Ruby gem designed to interact with Ollama's API, allowing users to run open source AI LLMs (Large Language Models) locally. The gem provides low-level access to Ollama, enabling users to build abstractions on top of it. It offers methods for generating completions, chat interactions, embeddings, creating and managing models, and more. Users can also work with text and image data, utilize Server-Sent Events for streaming capabilities, and handle errors effectively. Ollama AI is not an official Ollama project and is distributed under the MIT License.

ollama-ex
Ollama is a powerful tool for running large language models locally or on your own infrastructure. It provides a full implementation of the Ollama API, support for streaming requests, and tool use capability. Users can interact with Ollama in Elixir to generate completions, chat messages, and perform streaming requests. The tool also supports function calling on compatible models, allowing users to define tools with clear descriptions and arguments. Ollama is designed to facilitate natural language processing tasks and enhance user interactions with language models.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.