
west
We Speech Transcript based on LLM, in 300 lines of code.
Stars: 135
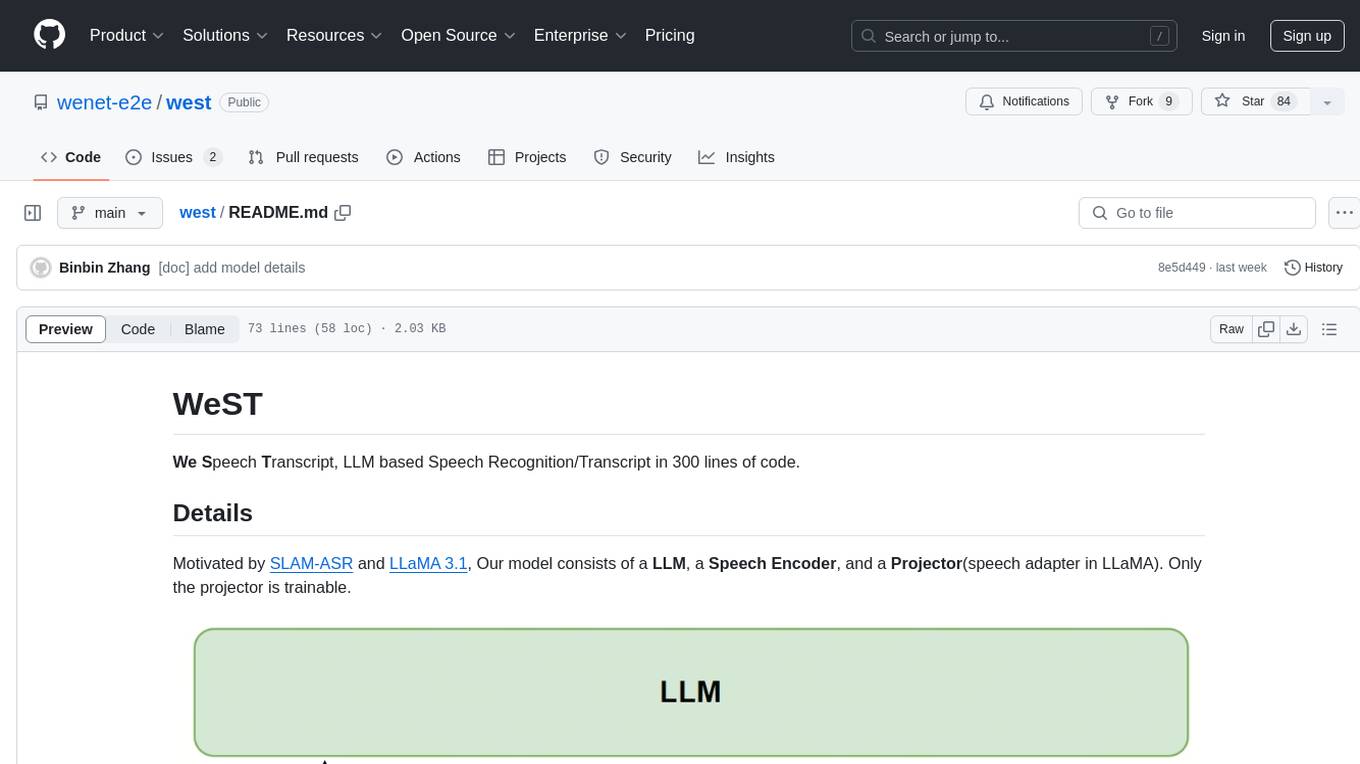
WeST is a Speech Recognition/Transcript tool developed in 300 lines of code, inspired by SLAM-ASR and LLaMA 3.1. The model includes a Language Model (LLM), a Speech Encoder, and a trainable Projector. It requires training data in jsonl format with 'wav' and 'txt' entries. WeST can be used for training and decoding speech recognition models.
README:
We Speech Transcript, LLM based Speech Recognition/Transcript in 300 lines of code.
Motivated by SLAM-ASR and LLaMA 3.1, Our model consists of a LLM, a Speech Encoder, and a Projector(speech adapter in LLaMA). Only the projector is trainable.

- LLM, could be LLaMA, QWen, etc.
- Speech Encoder, like whisper.
pip install -r requirements.txtThe training data(train.json) and test data(test.jsonl) should be prepared as jsonl format, which contains wav and txt in each line. Here is an example:
{"wav": "/data/BAC009S0764W0121.wav", "txt": "甚至出现交易几乎停滞的情况"}
{"wav": "/data/BAC009S0764W0122.wav", "txt": "一二线城市虽然也处于调整中"}
torchrun --standalone --nnodes=1 --nproc_per_node=8 train.py \
--llm_model_name_or_path Qwen2-1.5B-Instruct \
--whisper_model_name_or_path tiny \
--data_path train.jsonl \
--bf16 True \
--output_dir Qwen-1.5B-Instruct-whisper-tiny \
--num_train_epochs 5 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 100 \
--save_total_limit 10 \
--learning_rate 3e-4 \
--weight_decay 0.01 \
--adam_beta2 0.95 \
--warmup_ratio 0.01 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--report_to "none" \
--model_max_length 512 \
--gradient_checkpointing \
--dataloader_num_workers 4 \
--dataloader_prefetch_factor 10 \
--deepspeed ds_config_zero3.jsonpython recognize.py \
--llm_model_name_or_path Qwen2-1.5B-Instruct \
--whisper_model_name_or_path tiny \
--projector_model_path Qwen-1.5B-Instruct-whisper-tiny/checkpoint-600/model.safetensors \
--data_path test.jsonl \
--result_path result.txtDifferent LLM
| Exp | LLM | Speech Encoder | Projector | CER |
|---|---|---|---|---|
| 1 | QWen2 0.5B | Whisper Large 1.5G | Conv1d 12.07M | 9.77 |
| 2 | QWen2 1.5B | Whisper Large 1.5G | Conv1d 13.32M | 7.45 |
| 3 | QWen2 7B | Whisper Large 1.5G | Conv1d 17.32M | 5.55 |
Different Speech Encoder
| Exp | LLM | Speech Encoder | Projector | CER |
|---|---|---|---|---|
| 1 | QWen2 1.5B | Whisper tiny 39M | Conv1d 4.5M | 35.82 |
| 2 | QWen2 1.5B | Whisper small 244M | Conv1d 7.3M | 12.41 |
| 3 | QWen2 1.5B | Whisper Large 1.5G | Conv1d 13.32M | 7.45 |
Training Loss
 |
 |
Different Decoding Beam
Based on QWen2 1.5B + Whisper Large 1.5G.
| beam_size | 1 | 3 | 5 | 8 | 10 |
|---|---|---|---|---|---|
| CER | 7.45 | 6.82 | 6.84 | 6.83 | 6.87 |
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for west
Similar Open Source Tools
west
WeST is a Speech Recognition/Transcript tool developed in 300 lines of code, inspired by SLAM-ASR and LLaMA 3.1. The model includes a Language Model (LLM), a Speech Encoder, and a trainable Projector. It requires training data in jsonl format with 'wav' and 'txt' entries. WeST can be used for training and decoding speech recognition models.

EVE
EVE is an official PyTorch implementation of Unveiling Encoder-Free Vision-Language Models. The project aims to explore the removal of vision encoders from Vision-Language Models (VLMs) and transfer LLMs to encoder-free VLMs efficiently. It also focuses on bridging the performance gap between encoder-free and encoder-based VLMs. EVE offers a superior capability with arbitrary image aspect ratio, data efficiency by utilizing publicly available data for pre-training, and training efficiency with a transparent and practical strategy for developing a pure decoder-only architecture across modalities.

Open-dLLM
Open-dLLM is the most open release of a diffusion-based large language model, providing pretraining, evaluation, inference, and checkpoints. It introduces Open-dCoder, the code-generation variant of Open-dLLM. The repo offers a complete stack for diffusion LLMs, enabling users to go from raw data to training, checkpoints, evaluation, and inference in one place. It includes pretraining pipeline with open datasets, inference scripts for easy sampling and generation, evaluation suite with various metrics, weights and checkpoints on Hugging Face, and transparent configs for full reproducibility.

YuLan-Mini
YuLan-Mini is a lightweight language model with 2.4 billion parameters that achieves performance comparable to industry-leading models despite being pre-trained on only 1.08T tokens. It excels in mathematics and code domains. The repository provides pre-training resources, including data pipeline, optimization methods, and annealing approaches. Users can pre-train their own language models, perform learning rate annealing, fine-tune the model, research training dynamics, and synthesize data. The team behind YuLan-Mini is AI Box at Renmin University of China. The code is released under the MIT License with future updates on model weights usage policies. Users are advised on potential safety concerns and ethical use of the model.

flute
FLUTE (Flexible Lookup Table Engine for LUT-quantized LLMs) is a tool designed for uniform quantization and lookup table quantization of weights in lower-precision intervals. It offers flexibility in mapping intervals to arbitrary values through a lookup table. FLUTE supports various quantization formats such as int4, int3, int2, fp4, fp3, fp2, nf4, nf3, nf2, and even custom tables. The tool also introduces new quantization algorithms like Learned Normal Float (NFL) for improved performance and calibration data learning. FLUTE provides benchmarks, model zoo, and integration with frameworks like vLLM and HuggingFace for easy deployment and usage.
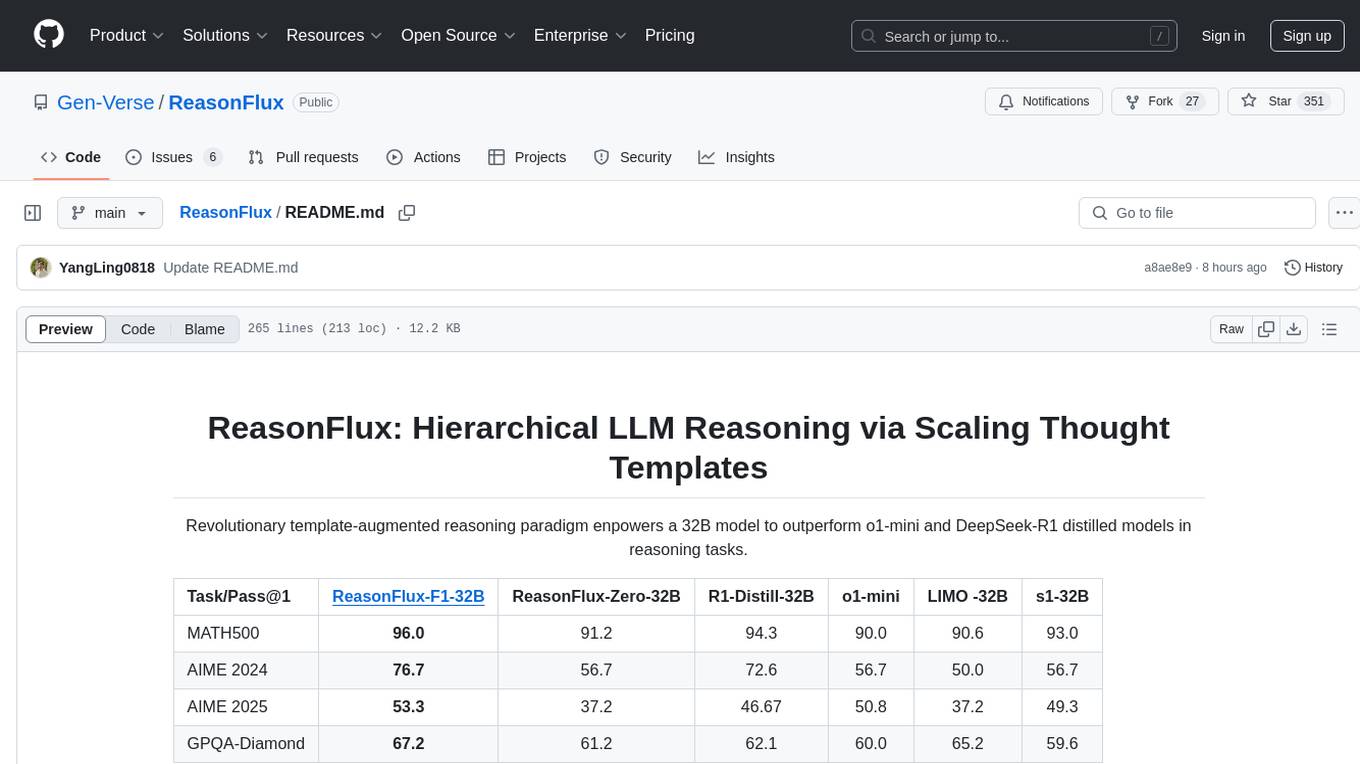
ReasonFlux
ReasonFlux is a revolutionary template-augmented reasoning paradigm that empowers a 32B model to outperform other models in reasoning tasks. The repository provides official resources for the paper 'ReasonFlux: Hierarchical LLM Reasoning via Scaling Thought Templates', including the latest released model ReasonFlux-F1-32B. It includes updates, dataset links, model zoo, getting started guide, training instructions, evaluation details, inference examples, performance comparisons, reasoning examples, preliminary work references, and citation information.
speechless
Speechless.AI is committed to integrating the superior language processing and deep reasoning capabilities of large language models into practical business applications. By enhancing the model's language understanding, knowledge accumulation, and text creation abilities, and introducing long-term memory, external tool integration, and local deployment, our aim is to establish an intelligent collaborative partner that can independently interact, continuously evolve, and closely align with various business scenarios.

MooER
MooER (摩耳) is an LLM-based speech recognition and translation model developed by Moore Threads. It allows users to transcribe speech into text (ASR) and translate speech into other languages (AST) in an end-to-end manner. The model was trained using 5K hours of data and is now also available with an 80K hours version. MooER is the first LLM-based speech model trained and inferred using domestic GPUs. The repository includes pretrained models, inference code, and a Gradio demo for a better user experience.

llm.nvim
llm.nvim is a universal plugin for a large language model (LLM) designed to enable users to interact with LLM within neovim. Users can customize various LLMs such as gpt, glm, kimi, and local LLM. The plugin provides tools for optimizing code, comparing code, translating text, and more. It also supports integration with free models from Cloudflare, Github models, siliconflow, and others. Users can customize tools, chat with LLM, quickly translate text, and explain code snippets. The plugin offers a flexible window interface for easy interaction and customization.

MOSS-TTS
MOSS-TTS Family is an open-source speech and sound generation model family designed for high-fidelity, high-expressiveness, and complex real-world scenarios. It includes five production-ready models: MOSS-TTS, MOSS-TTSD, MOSS-VoiceGenerator, MOSS-TTS-Realtime, and MOSS-SoundEffect, each serving specific purposes in speech generation, dialogue, voice design, real-time interactions, and sound effect generation. The models offer features like long-speech generation, fine-grained control over phonemes and duration, multilingual synthesis, voice cloning, and real-time voice agents.
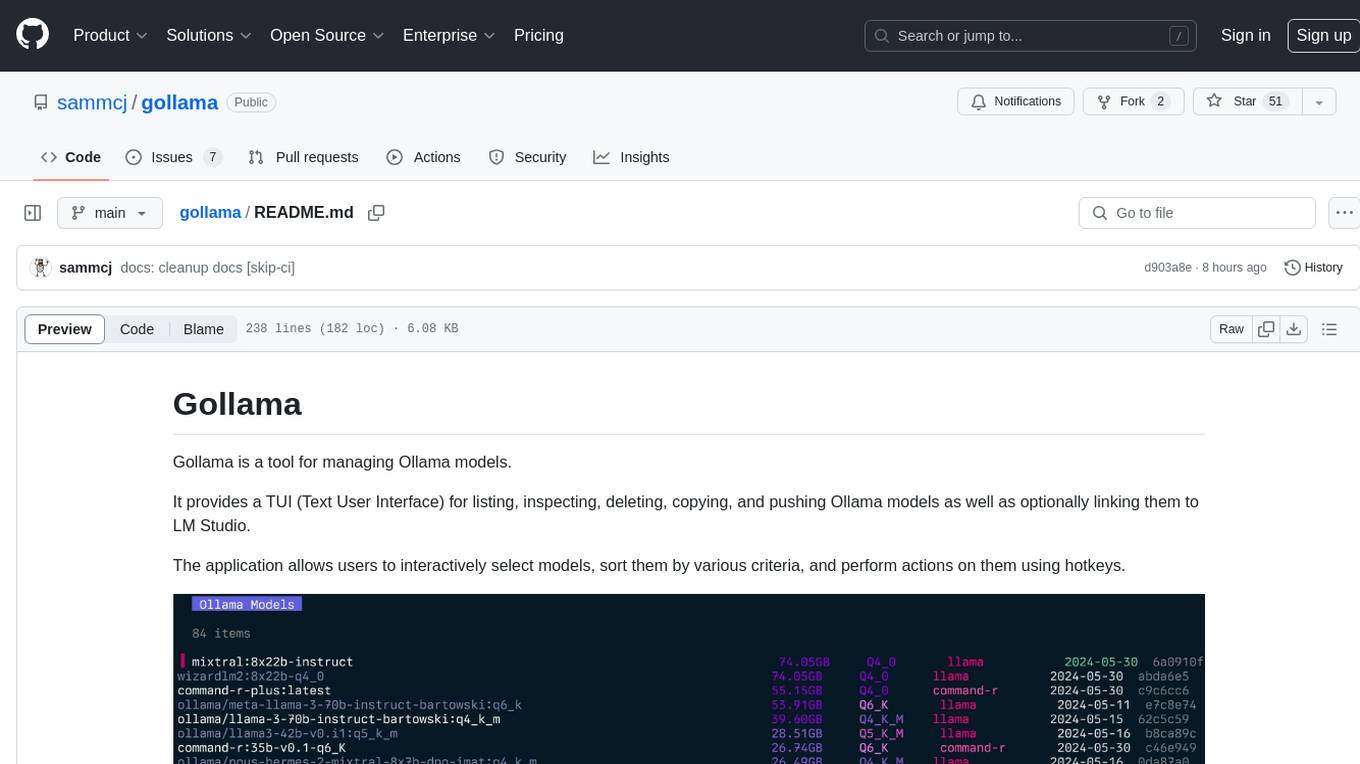
gollama
Gollama is a tool designed for managing Ollama models through a Text User Interface (TUI). Users can list, inspect, delete, copy, and push Ollama models, as well as link them to LM Studio. The application offers interactive model selection, sorting by various criteria, and actions using hotkeys. It provides features like sorting and filtering capabilities, displaying model metadata, model linking, copying, pushing, and more. Gollama aims to be user-friendly and useful for managing models, especially for cleaning up old models.
api-for-open-llm
This project provides a unified backend interface for open large language models (LLMs), offering a consistent experience with OpenAI's ChatGPT API. It supports various open-source LLMs, enabling developers to seamlessly integrate them into their applications. The interface features streaming responses, text embedding capabilities, and support for LangChain, a tool for developing LLM-based applications. By modifying environment variables, developers can easily use open-source models as alternatives to ChatGPT, providing a cost-effective and customizable solution for various use cases.

Native-LLM-for-Android
This repository provides a demonstration of running a native Large Language Model (LLM) on Android devices. It supports various models such as Qwen2.5-Instruct, MiniCPM-DPO/SFT, Yuan2.0, Gemma2-it, StableLM2-Chat/Zephyr, and Phi3.5-mini-instruct. The demo models are optimized for extreme execution speed after being converted from HuggingFace or ModelScope. Users can download the demo models from the provided drive link, place them in the assets folder, and follow specific instructions for decompression and model export. The repository also includes information on quantization methods and performance benchmarks for different models on various devices.

tiny-llm-zh
Tiny LLM zh is a project aimed at building a small-parameter Chinese language large model for quick entry into learning large model-related knowledge. The project implements a two-stage training process for large models and subsequent human alignment, including tokenization, pre-training, instruction fine-tuning, human alignment, evaluation, and deployment. It is deployed on ModeScope Tiny LLM website and features open access to all data and code, including pre-training data and tokenizer. The project trains a tokenizer using 10GB of Chinese encyclopedia text to build a Tiny LLM vocabulary. It supports training with Transformers deepspeed, multiple machine and card support, and Zero optimization techniques. The project has three main branches: llama2_torch, main tiny_llm, and tiny_llm_moe, each with specific modifications and features.
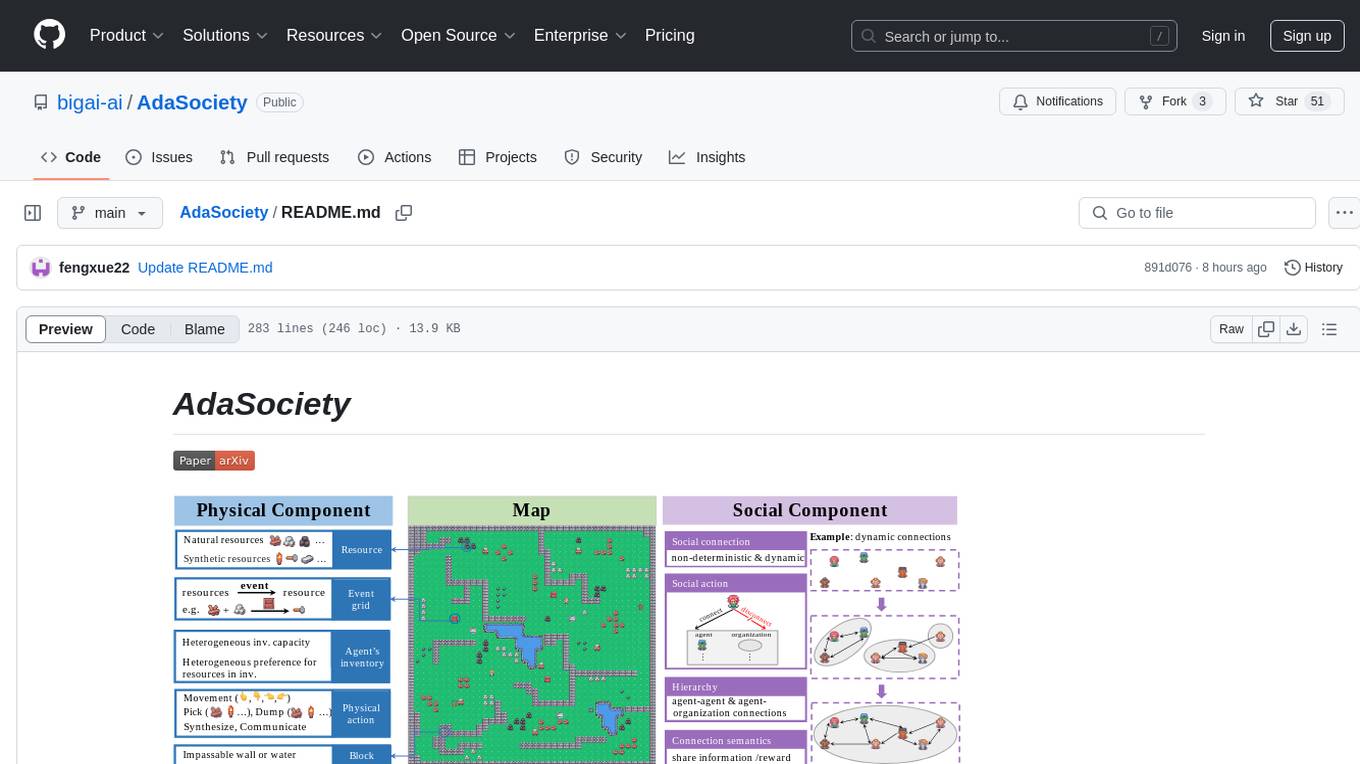
AdaSociety
AdaSociety is a multi-agent environment designed for simulating social structures and decision-making processes. It offers built-in resources, events, and player interactions. Users can customize the environment through JSON configuration or custom Python code. The environment supports training agents using RLlib and LLM frameworks. It provides a platform for studying multi-agent systems and social dynamics.
chatglm.cpp
ChatGLM.cpp is a C++ implementation of ChatGLM-6B, ChatGLM2-6B, ChatGLM3-6B and more LLMs for real-time chatting on your MacBook. It is based on ggml, working in the same way as llama.cpp. ChatGLM.cpp features accelerated memory-efficient CPU inference with int4/int8 quantization, optimized KV cache and parallel computing. It also supports P-Tuning v2 and LoRA finetuned models, streaming generation with typewriter effect, Python binding, web demo, api servers and more possibilities.
For similar tasks
west
WeST is a Speech Recognition/Transcript tool developed in 300 lines of code, inspired by SLAM-ASR and LLaMA 3.1. The model includes a Language Model (LLM), a Speech Encoder, and a trainable Projector. It requires training data in jsonl format with 'wav' and 'txt' entries. WeST can be used for training and decoding speech recognition models.

lighteval
LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron. We're releasing it with the community in the spirit of building in the open. Note that it is still very much early so don't expect 100% stability ^^' In case of problems or question, feel free to open an issue!

Firefly
Firefly is an open-source large model training project that supports pre-training, fine-tuning, and DPO of mainstream large models. It includes models like Llama3, Gemma, Qwen1.5, MiniCPM, Llama, InternLM, Baichuan, ChatGLM, Yi, Deepseek, Qwen, Orion, Ziya, Xverse, Mistral, Mixtral-8x7B, Zephyr, Vicuna, Bloom, etc. The project supports full-parameter training, LoRA, QLoRA efficient training, and various tasks such as pre-training, SFT, and DPO. Suitable for users with limited training resources, QLoRA is recommended for fine-tuning instructions. The project has achieved good results on the Open LLM Leaderboard with QLoRA training process validation. The latest version has significant updates and adaptations for different chat model templates.

Awesome-Text2SQL
Awesome Text2SQL is a curated repository containing tutorials and resources for Large Language Models, Text2SQL, Text2DSL, Text2API, Text2Vis, and more. It provides guidelines on converting natural language questions into structured SQL queries, with a focus on NL2SQL. The repository includes information on various models, datasets, evaluation metrics, fine-tuning methods, libraries, and practice projects related to Text2SQL. It serves as a comprehensive resource for individuals interested in working with Text2SQL and related technologies.

create-million-parameter-llm-from-scratch
The 'create-million-parameter-llm-from-scratch' repository provides a detailed guide on creating a Large Language Model (LLM) with 2.3 million parameters from scratch. The blog replicates the LLaMA approach, incorporating concepts like RMSNorm for pre-normalization, SwiGLU activation function, and Rotary Embeddings. The model is trained on a basic dataset to demonstrate the ease of creating a million-parameter LLM without the need for a high-end GPU.

StableToolBench
StableToolBench is a new benchmark developed to address the instability of Tool Learning benchmarks. It aims to balance stability and reality by introducing features such as a Virtual API System with caching and API simulators, a new set of solvable queries determined by LLMs, and a Stable Evaluation System using GPT-4. The Virtual API Server can be set up either by building from source or using a prebuilt Docker image. Users can test the server using provided scripts and evaluate models with Solvable Pass Rate and Solvable Win Rate metrics. The tool also includes model experiments results comparing different models' performance.

BetaML.jl
The Beta Machine Learning Toolkit is a package containing various algorithms and utilities for implementing machine learning workflows in multiple languages, including Julia, Python, and R. It offers a range of supervised and unsupervised models, data transformers, and assessment tools. The models are implemented entirely in Julia and are not wrappers for third-party models. Users can easily contribute new models or request implementations. The focus is on user-friendliness rather than computational efficiency, making it suitable for educational and research purposes.

AI-TOD
AI-TOD is a dataset for tiny object detection in aerial images, containing 700,621 object instances across 28,036 images. Objects in AI-TOD are smaller with a mean size of 12.8 pixels compared to other aerial image datasets. To use AI-TOD, download xView training set and AI-TOD_wo_xview, then generate the complete dataset using the provided synthesis tool. The dataset is publicly available for academic and research purposes under CC BY-NC-SA 4.0 license.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.