
speechless
LLM based agents with proactive interactions, long-term memory, external tool integration, and local deployment capabilities.
Stars: 100
Speechless.AI is committed to integrating the superior language processing and deep reasoning capabilities of large language models into practical business applications. By enhancing the model's language understanding, knowledge accumulation, and text creation abilities, and introducing long-term memory, external tool integration, and local deployment, our aim is to establish an intelligent collaborative partner that can independently interact, continuously evolve, and closely align with various business scenarios.
README:
LLM based agents with proactive interactions, long-term memory, external tool integration, and local deployment capabilities.

Speechless.AI is committed to integrating the superior language processing and deep reasoning capabilities of large language models into practical business applications. By enhancing the model's language understanding, knowledge accumulation, and text creation abilities, and introducing long-term memory, external tool integration, and local deployment, our aim is to establish an intelligent collaborative partner that can independently interact, continuously evolve, and closely align with various business scenarios.
-
Firstly, we focus on building a large model with enhanced reasoning capabilities, ensuring its outstanding performance in language processing and logical analysis.
-
Next, we design and implement an efficient operational framework for the intelligent entity. This framework not only supports rapid deployment and invocation of the model but also boasts features like autonomous interaction, real-time feedback adjustment, context awareness, and long-term memory. For instance, in customer service scenarios, the intelligent entity can provide more precise and personalized responses based on a user's historical interactions and current context. In content recommendation scenarios, it can dynamically adjust its strategies by capturing real-time shifts in user interests.
-
Ultimately, we integrate it with real business scenarios, ensuring that the intelligent entity seamlessly aligns with various business processes, delivering tangible value to enterprises.
- [2024-05-20] Release speechless-instruct-mistral-7b-v0.2
- [2024-03-13] Release speechless-starcoder2-15b
- [2024-03-10] Release speechless-starcoder2-7b
- [2024-02-15] Reelase speechless-thoughts-mistral-7b-v1.0 (Change same hyperparameters)
- [2024-02-12] Release speechless-thoughts-mistral-7b
- [2024-02-10] Release speechless-sparsetral-16x7b-MoE, the MoE upgraded version of speechless-code-mistral-7b-v1.0. The MoE fine-tuning adopts Parameter-Efficient Sparsity Crafting (PESC), which is an efficient fine-tuning architecture that uses LoRA modules as expert models, similar to the concept of multi-loras.
- [2024-02-06] Release speechless-mistral-hermes-code-7b fine-tuned by speechless-thoughts-252K dataset.
- [2024-01-23] Release speechless-zephyr-code-functionary-7b
- [2024-01-15] Release speechless-nl2sql-ds-6.7b, finetune based on deepseek-coder-6.7b-base.
- [2024-01-05] Release speechless-mistral-moloras-7b, which is the static version of moloras (Mixture-of-multi-LoRAs)
- [2023/12/30] Release speechless-coder-ds-1.3b that finetune based on deepseek-coder-1.3b-base.
- [2023/12/30] Release speechless-coder-ds-6.7b that finetune based on deepseek-coder-6.7b-base.
- [2023/12/23] Uploaded the float16 version of prometheus-7b-v1.0-fp16 for instruction fine-tuning data quality assessment.
- [2023/12/23] Uploaded the float16 version of prometheus-13b-v1.0-fp16 for instruction fine-tuning data quality assessment.
- [2023/11/26] Built 7 DARE models and their respective LoRA modules.
- [2023/11/24] Start Mixture-of-Multi-LoRAs experiments. Released speechless-mistral-7b-dare-0.85
- [2023/11/21] Speechless.Tools: Released speechless-tools-7b which is trained 3 epochs on the ToolEval dataset, achieving performance comparable to ToolLlama-2-7b-v2.
- [2023/10/16] Multi-LoRAs: Load multiple LoRA modules simultaneously and automatically switch the appropriate combination of LoRA modules to generate the best answer based on user queries. uukuguy/multi-loras

The speechless-tools-7b model is fine-tuned on speechless-coding-7b-16k-tora, following the guidance of the ToolLlama project, aims to empower open-source LLMs with the ability to handle thousands of diverse real-world APIs.
speechless-tools-7b-dfs vs chatgpt-cot
| Dataset | Win Rate |
|---|---|
| G1_instruction | 0.465 |
| G1_category | 0.495 |
| G1_tool | 0.505 |
| G2_instruction | 0.61 |
| G2_category | 0.585 |
| G3_instruction | 0.66 |
speechless-tools-7b-dfs vs toolllama-dfs
| Dataset | Win Rate |
|---|---|
| G1_instruction | 0.45 |
| G1_category | 0.45 |
| G1_tool | 0.51 |
| G2_instruction | 0.53 |
| G2_category | 0.575 |
| G3_instruction | 0.46 |
⭐️ My Focus 🔥🔥🔥 DL > 10k/month 🔥🔥 DL > 7K/month 🔥 DL > 3K/month
-
speechless-starcoder2-15b 2024.03.13
-
speechless-starcoder2-7b 2024.03.10
-
speechless-thoughts-mistral-7b-v1.0 2024.02.15
Change some hyperparameters compared to speechless-thoughts-mistral-7b.
learning_rate=2e-4 lora_r=64 lora_alpha=16 model_max_length=8192
-
speechless-thoughts-mistral-7b 2024.02.12
speechless-thoughts-mistral-7b is fine-tuned as a baseline of the speechless-sparsetral-16x7b-MoE.
Open LLM Language Model Evaluation Harness
Average ARC HellaSwag MMLU TruthfulQA Winogrande GSM8K 59.72 58.96 87.10 60.11 49.91 77.82 30.78 -
⭐ speechless-sparsetral-16x7b-MoE 2024.02.10
The MoE upgraded version of speechless-code-mistral-7b-v1.0. The MoE fine-tuning adopts Parameter-Efficient Sparsity Crafting (PESC), which is an efficient fine-tuning architecture that uses LoRA modules as expert models, similar to the concept of multi-loras.
-
⭐ speechless-mistral-hermes-code-7b 2024.02.06
Using the speechless-thoughts-252K dataset, it was fine-tuned based on the Mistral-7B-v0.1 base model in preparation for comparison with speechless-code-mistral-7b-v1.0.
-
zephyr-7b-alpha-dare-0.85 2023.11.24
A part of Mixture-of-Multi-LoRAs
-
⭐ speechless-mistral-7b-dare-0.85 2023.11.23
A part of Mixture-of-Multi-LoRAs
-
CollectiveCognition-v1.1-Mistral-7B-dare-0.85 2023.11.23
A part of Mixture-of-Multi-LoRAs
-
SynthIA-7B-v1.3-dare-0.85 2023.11.22
A part of Mixture-of-Multi-LoRAs
-
airoboros-m-7b-3.1.2-dare-0.85 2023.11.22
A part of Mixture-of-Multi-LoRAs
-
neural-chat-7b-v3-1-dare-0.85 2023.11.20
A part of Mixture-of-Multi-LoRAs
-
⭐️ speechless-coding-7b-16k-tora 2023.11.01
Fine-tune on the llm_agents/tora-code-7b-v1.0. The primary goal is to enhance the code generation capability of the model, thereby achieving a large-scale intelligent agent base model with good planning and reasoning abilities.
HumanEval & MultiPL-E
HumanEval-Python Python Java JavaScript CPP Rust Go Shell Julia D Lua PHP R 52.44 55.96 37.84 46.93 37.48 29.01 28.99 12.11 31.47 12.05 26.52 39.25 22.09
-
⭐️ speechless-mistral-six-in-one-7b 2023.10.15
This model is a merge of 6 SOTA Mistral-7B based models. Model benchmark by sethuiyer.
-
⭐️ speechless-mistral-dolphin-orca-platypus-samantha-7b 2023.10.14
The subsequent version of Speechless SuperLongName based on Mistral. Ranked high in the Mistral category on the open-llm leaderboard of new evaluation indicators.
Open LLM Language Model Evaluation Harness
Average ARC HellaSwag MMLU TruthfulQA Winogrande GSM8K DROP 53.34 64.33 84.4 63.72 52.52 78.37 21.38 8.66 -
🔥🔥 speechless-tora-code-7b-v1.0 2023.10.10
-
🔥🔥 speechless-code-mistral-orca-7b-v1.0 2023.10.10
Open LLM Language Model Evaluation Harness
Average ARC HellaSwag MMLU TruthfulQA Winogrande GSM8K DROP 55.33 59.64 82.25 61.33 48.45 77.51 8.26 49.89 -
🔥🔥 speechless-code-mistral-7b-v1.0 2023.10.10
Open LLM Language Model Evaluation Harness
Average ARC HellaSwag MMLU TruthfulQA Winogrande GSM8K DROP 53.47 60.58 83.75 62.98 47.9 78.69 19.18 21.19 -
⭐️🔥🔥 speechless-codellama-34b-v2.0 2023.10.04
My current strongest code generation model supports 12 commonly used programming languages, including Python, Java, C++, Rust, Go etc. pass@1 on humaneval: 75.61, NL2SQL SQLEval: 71.43% (EM: 67.43%)
HumanEval & MultiPL-E
HumanEval-Python Python Java JavaScript CPP Rust 75.61 67.55 51.93 64.81 55.81 52.98 Open LLM Language Model Evaluation Harness
Average ARC HellaSwag MMLU TruthfulQA Winogrande GSM8K DROP 50.96 54.35 75.65 54.67 45.21 73.56 11.6 41.71
-
⭐️🔥🔥🔥 speechless-llama2-13b 2023.09.14
-
🔥🔥 speechless-codellama-airoboros-orca-platypus-13b 2023.09.19
-
🔥🔥 speechless-codellama-dolphin-orca-platypus-34b 2023.09.14
-
🔥🔥 speechless-llama2-dolphin-orca-platypus-13b 2023.09.16
-
speechless-codellama-34b-v1.0 2023.09.14
-
⭐️🔥🔥🔥 speechless-codellama-platypus-13b 2023.09.13
-
⭐️🔥🔥🔥 speechless-codellama-orca-13b 2023.09.13
-
⭐️🔥 speechless-llama2-hermes-orca-platypus-wizardlm-13b 2023.09.10
Guys called it "Speechless SuperLongName". My first model with a download volume exceeding 10K last month on HuggingFace. It is said to be widely used by die-hard fans and hotly discussed on Reddit. Funny discuss on Reddit
-
speechless-llama2-hermes-orca-platypus-13b 2023.09.02
-
speechless-llama2-luban-orca-platypus-13b 2023.09.01
- speechless-hermes-coig-lite-13b 2023.08.22
-
⭐️🔥🔥 speechless-codellama-34b-v2.0 2023.10.04
My current strongest code generation model supports 12 commonly used programming languages, including Python, Java, C++, Rust, Go etc. pass@1 on humaneval: 75.61, NL2SQL SQLEval: 71.43% (EM: 67.43%)
HumanEval & MultiPL-E
HumanEval-Python Python Java JavaScript CPP Rust 75.61 67.55 51.93 64.81 55.81 52.98 Open LLM Language Model Evaluation Harness
Average ARC HellaSwag MMLU TruthfulQA Winogrande GSM8K DROP 50.96 54.35 75.65 54.67 45.21 73.56 11.6 41.71 -
🔥🔥 speechless-codellama-airoboros-orca-platypus-13b 2023.09.19
-
⭐️🔥🔥🔥 speechless-codellama-platypus-13b 2023.09.13
-
⭐️🔥🔥🔥 speechless-codellama-orca-13b 2023.09.13
-
⭐️ speechless-mistral-six-in-one-7b 2023.10.15
This model is a merge of 6 SOTA Mistral-7B based models. Model benchmark by sethuiyer.
-
⭐️ speechless-mistral-dolphin-orca-platypus-samantha-7b 2023.10.14
The subsequent version of Speechless SuperLongName based on Mistral. Ranked high in the Mistral category on the open-llm leaderboard of new evaluation indicators.
Open LLM Language Model Evaluation Harness
Average ARC HellaSwag MMLU TruthfulQA Winogrande GSM8K DROP 53.34 64.33 84.4 63.72 52.52 78.37 21.38 8.66 -
⭐️🔥🔥 speechless-code-mistral-7b-v1.0 2023.10.10
-
⭐️ speechless-coding-7b-16k-tora 2023.11.01
Fine-tune on the llm_agents/tora-code-7b-v1.0. The primary goal is to enhance the code generation capability of the model, thereby achieving a large-scale intelligent agent base model with good planning and reasoning abilities.
HumanEval & MultiPL-E
HumanEval-Python Python Java JavaScript CPP Rust Go Shell Julia D Lua PHP R 52.44 55.96 37.84 46.93 37.48 29.01 28.99 12.11 31.47 12.05 26.52 39.25 22.09 -
🔥🔥 speechless-tora-code-7b-v1.0 2023.10.10
-
⭐️🔥🔥🔥 speechless-llama2-13b 2023.09.14
-
⭐️🔥 speechless-llama2-hermes-orca-platypus-wizardlm-13b 2023.09.10
Guys called it "Speechless SuperLongName". My first model with a download volume exceeding 10K last month on HuggingFace. It is said to be widely used by die-hard fans and hotly discussed on Reddit. Funny discuss on Reddit
- jondurbin/airoboros-2.2.1
- Open-Orca/OpenOrca
- garage-bAInd/Open-Platypus
- WizardLM/WizardLM_evol_instruct_V2_196k
- ehartford/dolphin
- ehartford/samantha-data
python -m speechless.finetune init --task_name my_task
python -m speechless.finetune run --task_name my_task
python -m speechless.finetune merge --task_name my_task
python -m speechless.finetune backup --task_name my_task
python -m speechless.finetune list
pip install speechlessThe training dataset is a jsonl file, with each line containing a JSON formatted instruction data. The data format is as follows:
{
"conversations":[
{"from": "human", "value": "Human's Instruction"},
{"from": "assistant", "value": "Assistant's response"}
],
"prompt_type": "alpaca", # Current support 'alpaca', 'toolllama-multi-rounds', default is 'alpaca' if prompt_type set to empty.
"system_prompt": "", # Use alpaca system prompt if system_prompt filed is empty, otherwise use it as system prompt of this instruction.
"category": "my_category", # User customized category, can be anythings.
}#!/bin/bash
SCRIPT_PATH=$(cd $(dirname ${BASH_SOURCE[0]}); pwd)
# -------------------- Model --------------------
export MODELS_ROOT_DIR=/opt/local/llm_models/huggingface.co
export BASE_MODEL_PATH=${MODELS_ROOT_DIR}/llm_agents/tora-code-7b-v1.0
export TEST_MODEL_PATH=${MODELS_ROOT_DIR}/speechlessai/$(basename ${PWD})
# -------------------- Dataset --------------------
export SPEECHLESS_DATA_DIR=/opt/local/datasets/speechless_data
export DATASET=${SPEECHLESS_DATA_DIR}/speechless-toolbench-multi-rounds.jsonl
export DATASET_FORMAT=dialog
# -------------------- Environment --------------------
export OUTPUT_DIR=./outputs
export RAY_memory_monitor_refresh_ms=0
# -------------------- Task --------------------
export TASK_NAME=$(basename ${TEST_MODEL_PATH})
export TASK_CHECKPOINT_DIR=${OUTPUT_DIR}
export WANDB_PROJECT=${TASK_NAME}
# -------------------- Train --------------------
export SAVE_STEPS=10
export EVAL_STEPS=10
export WARMUP_STEPS=10
export MAX_EVAL_SAMPLES=200
export EVAL_DATASET_SIZE=0.005
export GROUP_BY_LENGTH=False
export LR_SCHEDULER_TYPE=cosine
export LEARNING_RATE=2e-4
export BITS=4
export LORA_R=32
export LORA_ALPHA=256
export MODEL_MAX_LENGTH=32768
export ROPE_THETA=1000000
export SLIDING_WINDOW=8192
export NUM_GPUS=2
export NUM_TRAIN_EPOCHS=3
export SAVE_STRATEGY=epoch
export SAVE_TOTAL_LIMIT="--save_total_limit ${NUM_TRAIN_EPOCHS}"
export PER_DEVICE_TRAIN_BATCH_SIZE=2
export GRADIENT_ACCUMULATION_STEPS=16
export MAX_MEMORY_MB=32000
PYTHONPATH=${SPEECHLESS_ROOT} \
torchrun --nnodes=1 --nproc_per_node=${NUM_GPUS} \
-m speechless.finetune.finetune_dialog \
--task_name ${TASK_NAME} \
--run_name $(date +%Y%m%d-%H%M%S) \
--model_name_or_path ${BASE_MODEL_PATH} \
--output_dir ${OUTPUT_DIR} \
--num_train_epochs ${NUM_TRAIN_EPOCHS} \
--data_seed 10042 \
--save_strategy ${SAVE_STRATEGY} \
${SAVE_TOTAL_LIMIT} \
--evaluation_strategy steps \
--eval_dataset_size ${EVAL_DATASET_SIZE} \
--save_steps ${SAVE_STEPS} \
--eval_steps ${EVAL_STEPS} \
--warmup_steps ${WARMUP_STEPS} \
--max_train_samples ${MAX_TRAIN_SAMPLES} \
--max_eval_samples ${MAX_EVAL_SAMPLES} \
--dataloader_num_workers 3 \
--logging_strategy steps \
--logging_steps 1 \
--report_to tensorboard \
--remove_unused_columns False \
--do_train \
--max_memory_MB ${MAX_MEMORY_MB} \
--bits ${BITS} \
--lora_r ${LORA_R} \
--lora_alpha ${LORA_ALPHA} \
--lora_dropout 0.05 \
--lora_modules all \
--double_quant \
--quant_type nf4 \
--bf16 \
--sliding_window ${SLIDING_WINDOW} \
--rope_theta ${ROPE_THETA} \
--dataset ${DATASET} \
--dataset_format ${DATASET_FORMAT} \
--max_new_tokens ${MODEL_MAX_LENGTH} \
--model_max_len ${MODEL_MAX_LENGTH} \
--per_device_train_batch_size ${PER_DEVICE_TRAIN_BATCH_SIZE} \
--gradient_accumulation_steps ${GRADIENT_ACCUMULATION_STEPS} \
--per_device_eval_batch_size 1 \
--learning_rate ${LEARNING_RATE} \
--lr_scheduler_type ${LR_SCHEDULER_TYPE} \
--weight_decay 0.0 \
--seed 10042 \
--optim paged_adamw_8bit \
--gradient_checkpointing True \
--group_by_length ${GROUP_BY_LENGTH} \
--ddp_find_unused_parameters False \
--force_remove_overlength_samples False \
--flash_attention True Speechless currently supports GGUF quantification, including the following types: q4_k_m, q5_k_m, q8_0.
# quant_type: q4_km/q5_km/q8_0
python -m speechless.quant llamacpp --model_path path/to/hf/model --llamacpp_quant_type <quant_type>Ollama is used as default backend, and litellm is used as default frontend api.
The unified classic application paradigm is to use the unified OpenAI API access interface, and the backend defaults to using the GGUF Q4_K_M quantization model.
python -m speechless.infer litellm_proxy --litellm_port 18342python -m speechless.infer ollama_create path/to/gguf/filepython -m speechless.api.server \
start \
--model ${TASK_MODEL_PATH} \
--backbone vllm \
--host 0.0.0.0 \
--port 5001Speechless supports HumanEval, MultiPL-E, SQLEval, lm-evaluation-harness.
LMEVAL_OUTPUT_DIR=eval_results/lm_eval/${TASK_NAME}
# lmeval
python -m speechless.eval.lmeval \
--do_gen \
--model hf-causal-experimental \
--model_args pretrained=${TEST_MODEL_PATH},use_accelerate=True \
--batch_size 4 \
--output_path ${LMEVAL_OUTPUT_DIR}
# lmeval_show_results
python -m speechless.eval.lmeval \
--show_results \
--output_path eval_results/lm_eval/${TASK_NAME}
--output_path ${LMEVAL_OUTPUT_DIR} Execute the HumanEval geenrate command on the GPU server where the model is located.
HUMANEVAL_OUTPUT_DIR=eval_results/human_eval/${TASK_NAME}
# humaneval
PYTHONLIB=${SPEECHLESS_ROOT} \
python -m speechless.eval.humaneval \
--do_gen \
--do_eval \
--model ${TEST_MODEL_PATH} \
--output_dir ${HUMANEVAL_OUTPUT_DIR}
# humaneval_show_results
PYTHONLIB=${SPEECHLESS_ROOT} \
python -m speechless.eval.lmeval \
--show_result \
--output_path ${HUMANEVAL_OUTPU_DIR}
docker pull ghcr.io/bigcode-project/evaluation-harness
docker tag ghcr.io/bigcode-project/evaluation-harness evaluation-harness
docker pull ghcr.io/bigcode-project/evaluation-harness-multiple
docker tag ghcr.io/bigcode-project/evaluation-harness-multiple evaluation-harness-multiplepython -m speechless.eval.multiple \
genrate \
--name ${TASK_MODEL_PATH} \
--output_dir_prefix ${EVAL_OUTPUT_DIR} \
python -m speechless.eval.multiple \
eval \
--results_dir ${EVAL_OUTPUT_DIR}python -m speechless.eval.sqleval \
genrate \
--model ${TASK_MODEL_PATH} \
--output_dir ${EVAL_OUTPUT_DIR} \
python -m speechless.eval.sqleval \
eval \
--eval_dir ${EVAL_OUTPUT_DIR}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for speechless
Similar Open Source Tools
speechless
Speechless.AI is committed to integrating the superior language processing and deep reasoning capabilities of large language models into practical business applications. By enhancing the model's language understanding, knowledge accumulation, and text creation abilities, and introducing long-term memory, external tool integration, and local deployment, our aim is to establish an intelligent collaborative partner that can independently interact, continuously evolve, and closely align with various business scenarios.

Step-DPO
Step-DPO is a method for enhancing long-chain reasoning ability of LLMs with a data construction pipeline creating a high-quality dataset. It significantly improves performance on math and GSM8K tasks with minimal data and training steps. The tool fine-tunes pre-trained models like Qwen2-7B-Instruct with Step-DPO, achieving superior results compared to other models. It provides scripts for training, evaluation, and deployment, along with examples and acknowledgements.

Xwin-LM
Xwin-LM is a powerful and stable open-source tool for aligning large language models, offering various alignment technologies like supervised fine-tuning, reward models, reject sampling, and reinforcement learning from human feedback. It has achieved top rankings in benchmarks like AlpacaEval and surpassed GPT-4. The tool is continuously updated with new models and features.
LlamaV-o1
LlamaV-o1 is a Large Multimodal Model designed for spontaneous reasoning tasks. It outperforms various existing models on multimodal reasoning benchmarks. The project includes a Step-by-Step Visual Reasoning Benchmark, a novel evaluation metric, and a combined Multi-Step Curriculum Learning and Beam Search Approach. The model achieves superior performance in complex multi-step visual reasoning tasks in terms of accuracy and efficiency.

Open-dLLM
Open-dLLM is the most open release of a diffusion-based large language model, providing pretraining, evaluation, inference, and checkpoints. It introduces Open-dCoder, the code-generation variant of Open-dLLM. The repo offers a complete stack for diffusion LLMs, enabling users to go from raw data to training, checkpoints, evaluation, and inference in one place. It includes pretraining pipeline with open datasets, inference scripts for easy sampling and generation, evaluation suite with various metrics, weights and checkpoints on Hugging Face, and transparent configs for full reproducibility.

EVE
EVE is an official PyTorch implementation of Unveiling Encoder-Free Vision-Language Models. The project aims to explore the removal of vision encoders from Vision-Language Models (VLMs) and transfer LLMs to encoder-free VLMs efficiently. It also focuses on bridging the performance gap between encoder-free and encoder-based VLMs. EVE offers a superior capability with arbitrary image aspect ratio, data efficiency by utilizing publicly available data for pre-training, and training efficiency with a transparent and practical strategy for developing a pure decoder-only architecture across modalities.

MMOS
MMOS (Mix of Minimal Optimal Sets) is a dataset designed for math reasoning tasks, offering higher performance and lower construction costs. It includes various models and data subsets for tasks like arithmetic reasoning and math word problem solving. The dataset is used to identify minimal optimal sets through reasoning paths and statistical analysis, with a focus on QA-pairs generated from open-source datasets. MMOS also provides an auto problem generator for testing model robustness and scripts for training and inference.
vlmrun-cookbook
VLM Run Cookbook is a repository containing practical examples and tutorials for extracting structured data from images, videos, and documents using Vision Language Models (VLMs). It offers comprehensive Colab notebooks demonstrating real-world applications of VLM Run, with complete code and documentation for easy adaptation. The examples cover various domains such as financial documents and TV news analysis.

deepfabric
DeepFabric is a CLI tool and SDK designed for researchers and developers to generate high-quality synthetic datasets at scale using large language models. It leverages a graph and tree-based architecture to create diverse and domain-specific datasets while minimizing redundancy. The tool supports generating Chain of Thought datasets for step-by-step reasoning tasks and offers multi-provider support for using different language models. DeepFabric also allows for automatic dataset upload to Hugging Face Hub and uses YAML configuration files for flexibility in dataset generation.
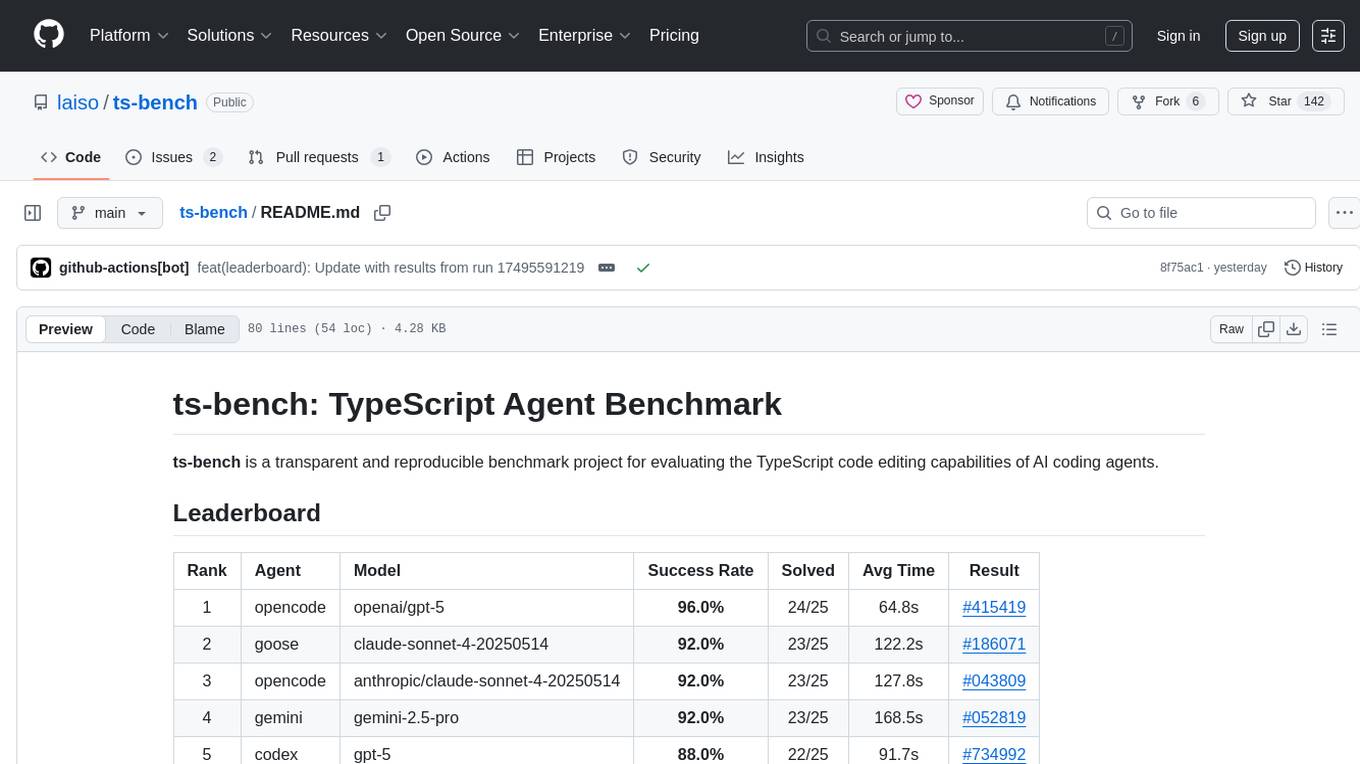
ts-bench
TS-Bench is a performance benchmarking tool for TypeScript projects. It provides detailed insights into the performance of TypeScript code, helping developers optimize their projects. With TS-Bench, users can measure and compare the execution time of different code snippets, functions, or modules. The tool offers a user-friendly interface for running benchmarks and analyzing the results. TS-Bench is a valuable asset for developers looking to enhance the performance of their TypeScript applications.
Video-ChatGPT
Video-ChatGPT is a video conversation model that aims to generate meaningful conversations about videos by combining large language models with a pretrained visual encoder adapted for spatiotemporal video representation. It introduces high-quality video-instruction pairs, a quantitative evaluation framework for video conversation models, and a unique multimodal capability for video understanding and language generation. The tool is designed to excel in tasks related to video reasoning, creativity, spatial and temporal understanding, and action recognition.
rag-web-ui
RAG Web UI is an intelligent dialogue system based on RAG (Retrieval-Augmented Generation) technology. It helps enterprises and individuals build intelligent Q&A systems based on their own knowledge bases. By combining document retrieval and large language models, it delivers accurate and reliable knowledge-based question-answering services. The system is designed with features like intelligent document management, advanced dialogue engine, and a robust architecture. It supports multiple document formats, async document processing, multi-turn contextual dialogue, and reference citations in conversations. The architecture includes a backend stack with Python FastAPI, MySQL + ChromaDB, MinIO, Langchain, JWT + OAuth2 for authentication, and a frontend stack with Next.js, TypeScript, Tailwind CSS, Shadcn/UI, and Vercel AI SDK for AI integration. Performance optimization includes incremental document processing, streaming responses, vector database performance tuning, and distributed task processing. The project is licensed under the Apache-2.0 License and is intended for learning and sharing RAG knowledge only, not for commercial purposes.
langtrace
Langtrace is an open source observability software that lets you capture, debug, and analyze traces and metrics from all your applications that leverage LLM APIs, Vector Databases, and LLM-based Frameworks. It supports Open Telemetry Standards (OTEL), and the traces generated adhere to these standards. Langtrace offers both a managed SaaS version (Langtrace Cloud) and a self-hosted option. The SDKs for both Typescript/Javascript and Python are available, making it easy to integrate Langtrace into your applications. Langtrace automatically captures traces from various vendors, including OpenAI, Anthropic, Azure OpenAI, Langchain, LlamaIndex, Pinecone, and ChromaDB.
actor-core
Actor-core is a lightweight and flexible library for building actor-based concurrent applications in Java. It provides a simple API for creating and managing actors, as well as handling message passing between actors. With actor-core, developers can easily implement scalable and fault-tolerant systems using the actor model.
ZhiLight
ZhiLight is a highly optimized large language model (LLM) inference engine developed by Zhihu and ModelBest Inc. It accelerates the inference of models like Llama and its variants, especially on PCIe-based GPUs. ZhiLight offers significant performance advantages compared to mainstream open-source inference engines. It supports various features such as custom defined tensor and unified global memory management, optimized fused kernels, support for dynamic batch, flash attention prefill, prefix cache, and different quantization techniques like INT8, SmoothQuant, FP8, AWQ, and GPTQ. ZhiLight is compatible with OpenAI interface and provides high performance on mainstream NVIDIA GPUs with different model sizes and precisions.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

ChatFAQ
ChatFAQ is an open-source comprehensive platform for creating a wide variety of chatbots: generic ones, business-trained, or even capable of redirecting requests to human operators. It includes a specialized NLP/NLG engine based on a RAG architecture and customized chat widgets, ensuring a tailored experience for users and avoiding vendor lock-in.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.
ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

mikupad
mikupad is a lightweight and efficient language model front-end powered by ReactJS, all packed into a single HTML file. Inspired by the likes of NovelAI, it provides a simple yet powerful interface for generating text with the help of various backends.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.
onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

firecrawl
Firecrawl is an API service that takes a URL, crawls it, and converts it into clean markdown. It crawls all accessible subpages and provides clean markdown for each, without requiring a sitemap. The API is easy to use and can be self-hosted. It also integrates with Langchain and Llama Index. The Python SDK makes it easy to crawl and scrape websites in Python code.