
Xwin-LM
Xwin-LM: Powerful, Stable, and Reproducible LLM Alignment
Stars: 982

Xwin-LM is a powerful and stable open-source tool for aligning large language models, offering various alignment technologies like supervised fine-tuning, reward models, reject sampling, and reinforcement learning from human feedback. It has achieved top rankings in benchmarks like AlpacaEval and surpassed GPT-4. The tool is continuously updated with new models and features.
README:
Step up your LLM alignment with Xwin-LM!
Xwin-LM aims to develop and open-source alignment technologies for large language models, including supervised fine-tuning (SFT), reward models (RM), reject sampling, reinforcement learning from human feedback (RLHF), etc. Our first release, built-upon on the Llama2 base models, ranked TOP-1 on AlpacaEval. Notably, it's the first to surpass GPT-4 on this benchmark. The project will be continuously updated.
- 💥 [May, 2024] The Xwin-Math-70B-V1.1 and Xwin-Math-7B-V1.1 model achieve 51.9 and 44.7 pass@1 on the MATH benchmark and 90.6 and 84.4 pass@1 on the GSM8K benchmark. These are new SoTA models based on LLaMA-2!
- 💥 [Jan, 2024] We update XwinLM-V0.3 on AlpacaEval, ranking as top-1 among open-source models.
- 💥 [Nov, 2023] The Xwin-Math-70B-V1.0 model achieves 31.8 pass@1 on the MATH benchmark and 87.0 pass@1 on the GSM8K benchmark. This performance places it first amongst all open-source models!
- 💥 [Nov, 2023] The Xwin-Math-7B-V1.0 and Xwin-Math-13B-V1.0 models achieve 66.6 and 76.2 pass@1 on the GSM8K benchmark, ranking as top-1 among all LLaMA-2 based 7B and 13B open-source models, respectively!
- 💥 [Nov, 2023] We released XwinCoder-7B, XwinCoder-13B, XwinCoder-34B. Our XwinCoder-34B reached 74.2 on HumanEval and it achieves comparable performance as GPT-3.5-turbo on 6 benchmarks.
- 💥 [Oct 12, 2023] Xwin-LM-7B-V0.2 and Xwin-LM-13B-V0.2 have been released, with improved comparison data and RL training (i.e., PPO). Their winrates v.s. GPT-4 have increased significantly, reaching 59.83% (7B model) and 70.36% (13B model) respectively. The 70B model will be released soon.
- 💥 [Sep, 2023] We released Xwin-LM-70B-V0.1, which has achieved a win-rate against Davinci-003 of 95.57% on AlpacaEval benchmark, ranking as TOP-1 on AlpacaEval. It was the FIRST model surpassing GPT-4 on AlpacaEval. Also note its winrate v.s. GPT-4 is 60.61.
- 🔍 [Sep, 2023] RLHF plays crucial role in the strong performance of Xwin-LM-V0.1 release!
- 💥 [Sep, 2023] We released Xwin-LM-13B-V0.1, which has achieved 91.76% win-rate on AlpacaEval, ranking as top-1 among all 13B models.
- 💥 [Sep, 2023] We released Xwin-LM-7B-V0.1, which has achieved 87.82% win-rate on AlpacaEval, ranking as top-1 among all 7B models.
| Model | Checkpoint | Report | License |
|---|---|---|---|
| Xwin-LM-7B-V0.2 | 🤗 HF Link | 📃Paper Link | Llama 2 License |
| Xwin-LM-13B-V0.2 | 🤗 HF Link | Llama 2 License | |
| Xwin-LM-7B-V0.1 | 🤗 HF Link | Llama 2 License | |
| Xwin-LM-13B-V0.1 | 🤗 HF Link | Llama 2 License | |
| Xwin-LM-70B-V0.1 | 🤗 HF Link | Llama 2 License | |
| Xwin-Coder-7B | 🤗 HF Link | 📃Brief introduction | Llama 2 License |
| Xwin-Coder-13B | 🤗 HF Link | Llama 2 License | |
| Xwin-Coder-34B | 🤗 HF Link | Llama 2 License | |
| Xwin-Math-7B-V1.1 | 🤗 HF Link | 📃Paper Link | Llama 2 License |
| Xwin-Math-70B-V1.1 | 🤗 HF Link | Llama 2 License | |
| Xwin-Math-7B-V1.0 | 🤗 HF Link | Llama 2 License | |
| Xwin-Math-13B-V1.0 | 🤗 HF Link | Llama 2 License | |
| Xwin-Math-70B-V1.0 | 🤗 HF Link | Llama 2 License |
Xwin-LM performance on AlpacaEval.
The table below displays the performance of Xwin-LM on AlpacaEval, where evaluates its win-rate against Text-Davinci-003 across 805 questions. To provide a comprehensive evaluation, we present, for the first time, the win-rate against ChatGPT and GPT-4 as well. Our Xwin-LM model family establish a new state-of-the-art performance across all metrics. Notably, Xwin-LM-70B-V0.1 has eclipsed GPT-4 for the first time, achieving an impressive win-rate of 95.57% to Text-Davinci-003 and 60.61% to GPT-4.
| Model | AlpacaEval (winrate %) | AlpacaEval (winrate %) | AlpacaEval (winrate %) |
|---|---|---|---|
| v.s. Text-Davinci-003 | v.s. ChatGPT | v.s. GPT4 | |
| Xwin-LM-70B-V0.1 | 95.57 | 87.50 | 60.61 |
| GPT-4 | 95.28 | 84.66 | 50.00 |
| Xwin-LM-13B-V0.2 | 93.22 | 87.14 | 70.36 |
| WizardLM-70B-V1.0 | 92.91 | 80.19 | 46.70 |
| Llama-2-70B-Chat | 92.66 | 81.97 | 51.19 |
| Xwin-LM-13B-V0.1 | 91.76 | 81.79 | 55.30 |
| ChatGPT | 89.37 | 50.00 | 16.60 |
| Xwin-LM-7B-V0.2 | 89.31 | 79.60 | 59.83 |
| WizardLM-13B-V1.2 | 89.17 | 75.75 | 41.91 |
| Xwin-LM-7B-V0.1 | 87.35 | 76.40 | 47.57 |
| Llama-2-13B-Chat | 81.09 | 64.22 | 30.92 |
Case study on AlpacaEval
| Prompts | GPT4 response | Xwin-LM response |
|---|---|---|
| I've put a plate on top of an apple, and take the plate from kitchen to dinning room. Where is the apple now | The apple is now in the dining room, as it was underneath the plate when you moved the plate from the kitchen to the dining room. | The apple is still in the kitchen, as you have only moved the plate. The apple is under the plate, so if you want to bring the apple to the dining room, you should either move the apple directly or put the apple on the plate and then move the plate to the dining room. |
| Answer the following question. How do you say "good evening" in French. |
In French, "good evening" is said as "bonsoir." | In French, "good evening" is translated to "bonsoir." This greeting is used in the evening and nighttime hours, typically after 6 p.m. It is a combination of "bon," which means "good," and "soir," which means "evening." To pronounce it, say "bone-swahr." |
The following table provides a comparison of Xwin-LMs with other LLMs on NLP foundation tasks in Open LLM Leaderboard.
| Model | MMLU 5-shot | ARC 25-shot | TruthfulQA 0-shot | HellaSwag 10-shot | Average |
|---|---|---|---|---|---|
| Text-davinci-003 | 56.9 | 85.2 | 59.3 | 82.2 | 70.9 |
| Vicuna-13b 1.1 | 51.3 | 53.0 | 51.8 | 80.1 | 59.1 |
| Guanaco 30B | 57.6 | 63.7 | 50.7 | 85.1 | 64.3 |
| WizardLM-7B 1.0 | 42.7 | 51.6 | 44.7 | 77.7 | 54.2 |
| WizardLM-13B 1.0 | 52.3 | 57.2 | 50.5 | 81.0 | 60.2 |
| WizardLM-30B 1.0 | 58.8 | 62.5 | 52.4 | 83.3 | 64.2 |
| Llama-2-7B-Chat | 48.3 | 52.9 | 45.6 | 78.6 | 56.4 |
| Llama-2-13B-Chat | 54.6 | 59.0 | 44.1 | 81.9 | 59.9 |
| Llama-2-70B-Chat | 63.9 | 64.6 | 52.8 | 85.9 | 66.8 |
| Xwin-LM-7B-V0.1 | 49.7 | 56.2 | 48.1 | 79.5 | 58.4 |
| Xwin-LM-13B-V0.1 | 56.6 | 62.4 | 45.5 | 83.0 | 61.9 |
| Xwin-LM-70B-V0.1 | 69.6 | 70.5 | 60.1 | 87.1 | 71.8 |
| Xwin-LM-7B-V0.2 | 50.0 | 56.4 | 49.5 | 78.9 | 58.7 |
| Xwin-LM-13B-V0.2 | 56.6 | 61.5 | 43.8 | 82.9 | 61.2 |
To obtain desired results, please strictly follow the conversation templates when utilizing our model for inference. Our model adopts the prompt format established by Vicuna and is equipped to support multi-turn conversations.
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: Hi! ASSISTANT: Hello.</s>USER: Who are you? ASSISTANT: I am Xwin-LM.</s>......
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("Xwin-LM/Xwin-LM-7B-V0.1")
tokenizer = AutoTokenizer.from_pretrained("Xwin-LM/Xwin-LM-7B-V0.1")
(
prompt := "A chat between a curious user and an artificial intelligence assistant. "
"The assistant gives helpful, detailed, and polite answers to the user's questions. "
"USER: Hello, can you help me? "
"ASSISTANT:"
)
inputs = tokenizer(prompt, return_tensors="pt")
samples = model.generate(**inputs, max_new_tokens=4096, temperature=0.7)
output = tokenizer.decode(samples[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True)
print(output)
# Of course! I'm here to help. Please feel free to ask your question or describe the issue you're having, and I'll do my best to assist you.Because Xwin-LM is based on Llama2, it also offers support for rapid inference using vLLM. Please refer to vLLM for detailed installation instructions.
from vllm import LLM, SamplingParams
(
prompt := "A chat between a curious user and an artificial intelligence assistant. "
"The assistant gives helpful, detailed, and polite answers to the user's questions. "
"USER: Hello, can you help me? "
"ASSISTANT:"
)
sampling_params = SamplingParams(temperature=0.7, max_tokens=4096)
llm = LLM(model="Xwin-LM/Xwin-LM-7B-V0.1")
outputs = llm.generate([prompt,], sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(generated_text)- [ ] Release the source code
- [ ] Release more capabilities, such as math, reasoning, and etc.
Please consider citing our work if you use the data or code in this repo.
@software{xwin-lm,
title = {Xwin-LM},
author = {Xwin-LM Team},
url = {https://github.com/Xwin-LM/Xwin-LM},
version = {pre-release},
year = {2023},
month = {9},
}
Thanks to Llama 2, FastChat, AlpacaFarm, and vLLM.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Xwin-LM
Similar Open Source Tools
Xwin-LM
Xwin-LM is a powerful and stable open-source tool for aligning large language models, offering various alignment technologies like supervised fine-tuning, reward models, reject sampling, and reinforcement learning from human feedback. It has achieved top rankings in benchmarks like AlpacaEval and surpassed GPT-4. The tool is continuously updated with new models and features.
LlamaV-o1
LlamaV-o1 is a Large Multimodal Model designed for spontaneous reasoning tasks. It outperforms various existing models on multimodal reasoning benchmarks. The project includes a Step-by-Step Visual Reasoning Benchmark, a novel evaluation metric, and a combined Multi-Step Curriculum Learning and Beam Search Approach. The model achieves superior performance in complex multi-step visual reasoning tasks in terms of accuracy and efficiency.

Step-DPO
Step-DPO is a method for enhancing long-chain reasoning ability of LLMs with a data construction pipeline creating a high-quality dataset. It significantly improves performance on math and GSM8K tasks with minimal data and training steps. The tool fine-tunes pre-trained models like Qwen2-7B-Instruct with Step-DPO, achieving superior results compared to other models. It provides scripts for training, evaluation, and deployment, along with examples and acknowledgements.

IDvs.MoRec
This repository contains the source code for the SIGIR 2023 paper 'Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited'. It provides resources for evaluating foundation, transferable, multi-modal, and LLM recommendation models, along with datasets, pre-trained models, and training strategies for IDRec and MoRec using in-batch debiased cross-entropy loss. The repository also offers large-scale datasets, code for SASRec with in-batch debias cross-entropy loss, and information on joining the lab for research opportunities.

DataFlow
DataFlow is a data preparation and training system designed to parse, generate, process, and evaluate high-quality data from noisy sources, improving the performance of large language models in specific domains. It constructs diverse operators and pipelines, validated to enhance domain-oriented LLM's performance in fields like healthcare, finance, and law. DataFlow also features an intelligent DataFlow-agent capable of dynamically assembling new pipelines by recombining existing operators on demand.
END-TO-END-GENERATIVE-AI-PROJECTS
The 'END TO END GENERATIVE AI PROJECTS' repository is a collection of awesome industry projects utilizing Large Language Models (LLM) for various tasks such as chat applications with PDFs, image to speech generation, video transcribing and summarizing, resume tracking, text to SQL conversion, invoice extraction, medical chatbot, financial stock analysis, and more. The projects showcase the deployment of LLM models like Google Gemini Pro, HuggingFace Models, OpenAI GPT, and technologies such as Langchain, Streamlit, LLaMA2, LLaMAindex, and more. The repository aims to provide end-to-end solutions for different AI applications.

MOSS-TTS
MOSS-TTS Family is an open-source speech and sound generation model family designed for high-fidelity, high-expressiveness, and complex real-world scenarios. It includes five production-ready models: MOSS-TTS, MOSS-TTSD, MOSS-VoiceGenerator, MOSS-TTS-Realtime, and MOSS-SoundEffect, each serving specific purposes in speech generation, dialogue, voice design, real-time interactions, and sound effect generation. The models offer features like long-speech generation, fine-grained control over phonemes and duration, multilingual synthesis, voice cloning, and real-time voice agents.

UniCoT
Uni-CoT is a unified reasoning framework that extends Chain-of-Thought (CoT) principles to the multimodal domain, enabling Multimodal Large Language Models (MLLMs) to perform interpretable, step-by-step reasoning across both text and vision. It decomposes complex multimodal tasks into structured, manageable steps that can be executed sequentially or in parallel, allowing for more scalable and systematic reasoning.
Video-ChatGPT
Video-ChatGPT is a video conversation model that aims to generate meaningful conversations about videos by combining large language models with a pretrained visual encoder adapted for spatiotemporal video representation. It introduces high-quality video-instruction pairs, a quantitative evaluation framework for video conversation models, and a unique multimodal capability for video understanding and language generation. The tool is designed to excel in tasks related to video reasoning, creativity, spatial and temporal understanding, and action recognition.
awesome-ai-efficiency
Awesome AI Efficiency is a curated list of resources dedicated to enhancing efficiency in AI systems. The repository covers various topics essential for optimizing AI models and processes, aiming to make AI faster, cheaper, smaller, and greener. It includes topics like quantization, pruning, caching, distillation, factorization, compilation, parameter-efficient fine-tuning, speculative decoding, hardware optimization, training techniques, inference optimization, sustainability strategies, and scalability approaches.
RLinf
RLinf is a flexible and scalable open-source infrastructure designed for post-training foundation models via reinforcement learning. It provides a robust backbone for next-generation training, supporting open-ended learning, continuous generalization, and limitless possibilities in intelligence development. The tool offers unique features like Macro-to-Micro Flow, flexible execution modes, auto-scheduling strategy, embodied agent support, and fast adaptation for mainstream VLA models. RLinf is fast with hybrid mode and automatic online scaling strategy, achieving significant throughput improvement and efficiency. It is also flexible and easy to use with multiple backend integrations, adaptive communication, and built-in support for popular RL methods. The roadmap includes system-level enhancements and application-level extensions to support various training scenarios and models. Users can get started with complete documentation, quickstart guides, key design principles, example gallery, advanced features, and guidelines for extending the framework. Contributions are welcome, and users are encouraged to cite the GitHub repository and acknowledge the broader open-source community.

Q-Bench
Q-Bench is a benchmark for general-purpose foundation models on low-level vision, focusing on multi-modality LLMs performance. It includes three realms for low-level vision: perception, description, and assessment. The benchmark datasets LLVisionQA and LLDescribe are collected for perception and description tasks, with open submission-based evaluation. An abstract evaluation code is provided for assessment using public datasets. The tool can be used with the datasets API for single images and image pairs, allowing for automatic download and usage. Various tasks and evaluations are available for testing MLLMs on low-level vision tasks.

pai-opencode
PAI-OpenCode is a complete port of Daniel Miessler's Personal AI Infrastructure (PAI) to OpenCode, an open-source, provider-agnostic AI coding assistant. It brings modular capabilities, dynamic multi-agent orchestration, session history, and lifecycle automation to personalize AI assistants for users. With support for 75+ AI providers, PAI-OpenCode offers dynamic per-task model routing, full PAI infrastructure, real-time session sharing, and multiple client options. The tool optimizes cost and quality with a 3-tier model strategy and a 3-tier research system, allowing users to switch presets for different routing strategies. PAI-OpenCode's architecture preserves PAI's design while adapting to OpenCode, documented through Architecture Decision Records (ADRs).

qserve
QServe is a serving system designed for efficient and accurate Large Language Models (LLM) on GPUs with W4A8KV4 quantization. It achieves higher throughput compared to leading industry solutions, allowing users to achieve A100-level throughput on cheaper L40S GPUs. The system introduces the QoQ quantization algorithm with 4-bit weight, 8-bit activation, and 4-bit KV cache, addressing runtime overhead challenges. QServe improves serving throughput for various LLM models by implementing compute-aware weight reordering, register-level parallelism, and fused attention memory-bound techniques.


EVE
EVE is an official PyTorch implementation of Unveiling Encoder-Free Vision-Language Models. The project aims to explore the removal of vision encoders from Vision-Language Models (VLMs) and transfer LLMs to encoder-free VLMs efficiently. It also focuses on bridging the performance gap between encoder-free and encoder-based VLMs. EVE offers a superior capability with arbitrary image aspect ratio, data efficiency by utilizing publicly available data for pre-training, and training efficiency with a transparent and practical strategy for developing a pure decoder-only architecture across modalities.
For similar tasks
alignment-handbook
The Alignment Handbook provides robust training recipes for continuing pretraining and aligning language models with human and AI preferences. It includes techniques such as continued pretraining, supervised fine-tuning, reward modeling, rejection sampling, and direct preference optimization (DPO). The handbook aims to fill the gap in public resources on training these models, collecting data, and measuring metrics for optimal downstream performance.
Xwin-LM
Xwin-LM is a powerful and stable open-source tool for aligning large language models, offering various alignment technologies like supervised fine-tuning, reward models, reject sampling, and reinforcement learning from human feedback. It has achieved top rankings in benchmarks like AlpacaEval and surpassed GPT-4. The tool is continuously updated with new models and features.

Awesome-LLM-Preference-Learning
The repository 'Awesome-LLM-Preference-Learning' is the official repository of a survey paper titled 'Towards a Unified View of Preference Learning for Large Language Models: A Survey'. It contains a curated list of papers related to preference learning for Large Language Models (LLMs). The repository covers various aspects of preference learning, including on-policy and off-policy methods, feedback mechanisms, reward models, algorithms, evaluation techniques, and more. The papers included in the repository explore different approaches to aligning LLMs with human preferences, improving mathematical reasoning in LLMs, enhancing code generation, and optimizing language model performance.
LLM-Synthetic-Data
LLM-Synthetic-Data is a repository focused on real-time, fine-grained LLM-Synthetic-Data generation. It includes methods, surveys, and application areas related to synthetic data for language models. The repository covers topics like pre-training, instruction tuning, model collapse, LLM benchmarking, evaluation, and distillation. It also explores application areas such as mathematical reasoning, code generation, text-to-SQL, alignment, reward modeling, long context, weak-to-strong generalization, agent and tool use, vision and language, factuality, federated learning, generative design, and safety.

LLM-Tool-Survey
This repository contains a collection of papers related to tool learning with large language models (LLMs). The papers are organized according to the survey paper 'Tool Learning with Large Language Models: A Survey'. The survey focuses on the benefits and implementation of tool learning with LLMs, covering aspects such as task planning, tool selection, tool calling, response generation, benchmarks, evaluation, challenges, and future directions in the field. It aims to provide a comprehensive understanding of tool learning with LLMs and inspire further exploration in this emerging area.
Awesome-AI-Agents
Awesome-AI-Agents is a curated list of projects, frameworks, benchmarks, platforms, and related resources focused on autonomous AI agents powered by Large Language Models (LLMs). The repository showcases a wide range of applications, multi-agent task solver projects, agent society simulations, and advanced components for building and customizing AI agents. It also includes frameworks for orchestrating role-playing, evaluating LLM-as-Agent performance, and connecting LLMs with real-world applications through platforms and APIs. Additionally, the repository features surveys, paper lists, and blogs related to LLM-based autonomous agents, making it a valuable resource for researchers, developers, and enthusiasts in the field of AI.
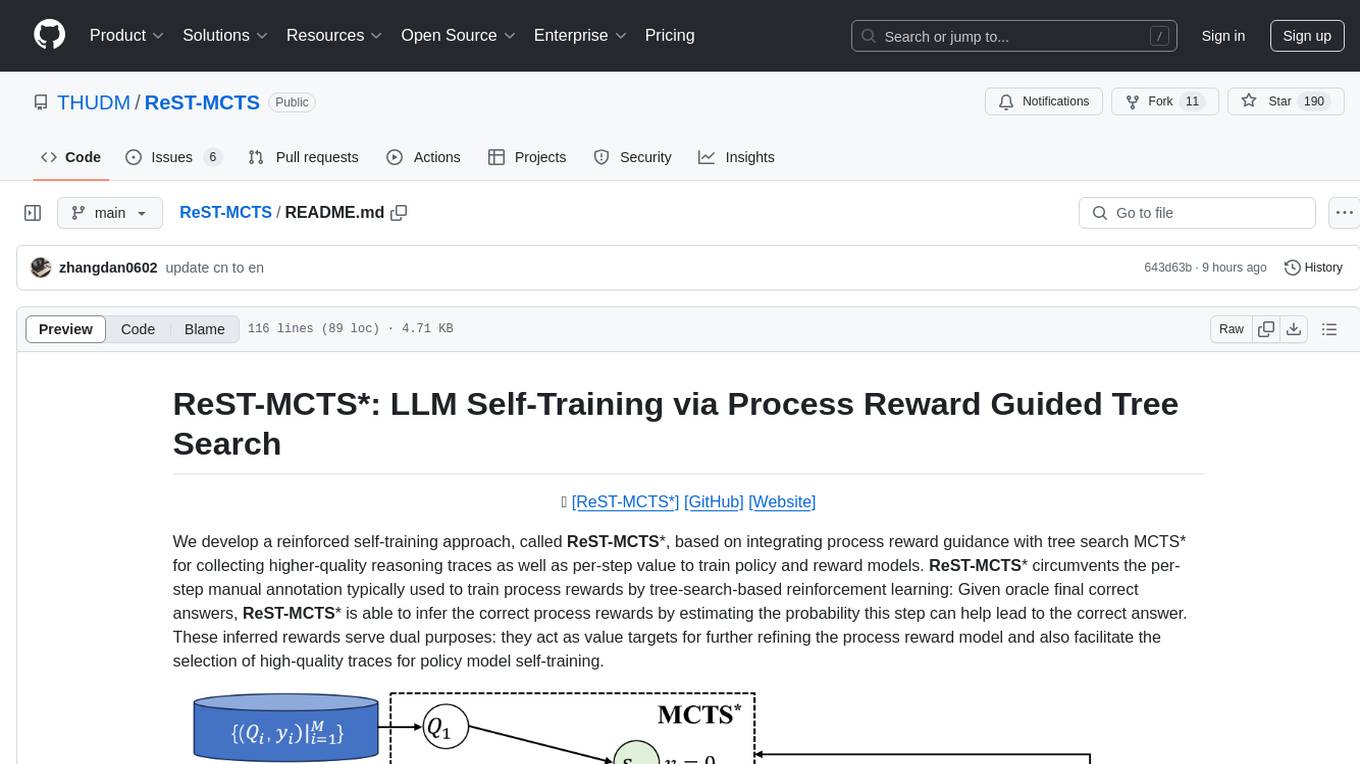
ReST-MCTS
ReST-MCTS is a reinforced self-training approach that integrates process reward guidance with tree search MCTS to collect higher-quality reasoning traces and per-step value for training policy and reward models. It eliminates the need for manual per-step annotation by estimating the probability of steps leading to correct answers. The inferred rewards refine the process reward model and aid in selecting high-quality traces for policy model self-training.
LongCite
LongCite is a tool that enables Large Language Models (LLMs) to generate fine-grained citations in long-context Question Answering (QA) scenarios. It provides models trained on GLM-4-9B and Meta-Llama-3.1-8B, supporting up to 128K context. Users can deploy LongCite chatbots, generate accurate responses, and obtain precise sentence-level citations. The tool includes components for model deployment, Coarse to Fine (CoF) pipeline for data construction, model training using LongCite-45k dataset, evaluation with LongBench-Cite benchmark, and citation generation.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.