
ReST-MCTS
ReST-MCTS*: LLM Self-Training via Process Reward Guided Tree Search (NeurIPS 2024)
Stars: 452
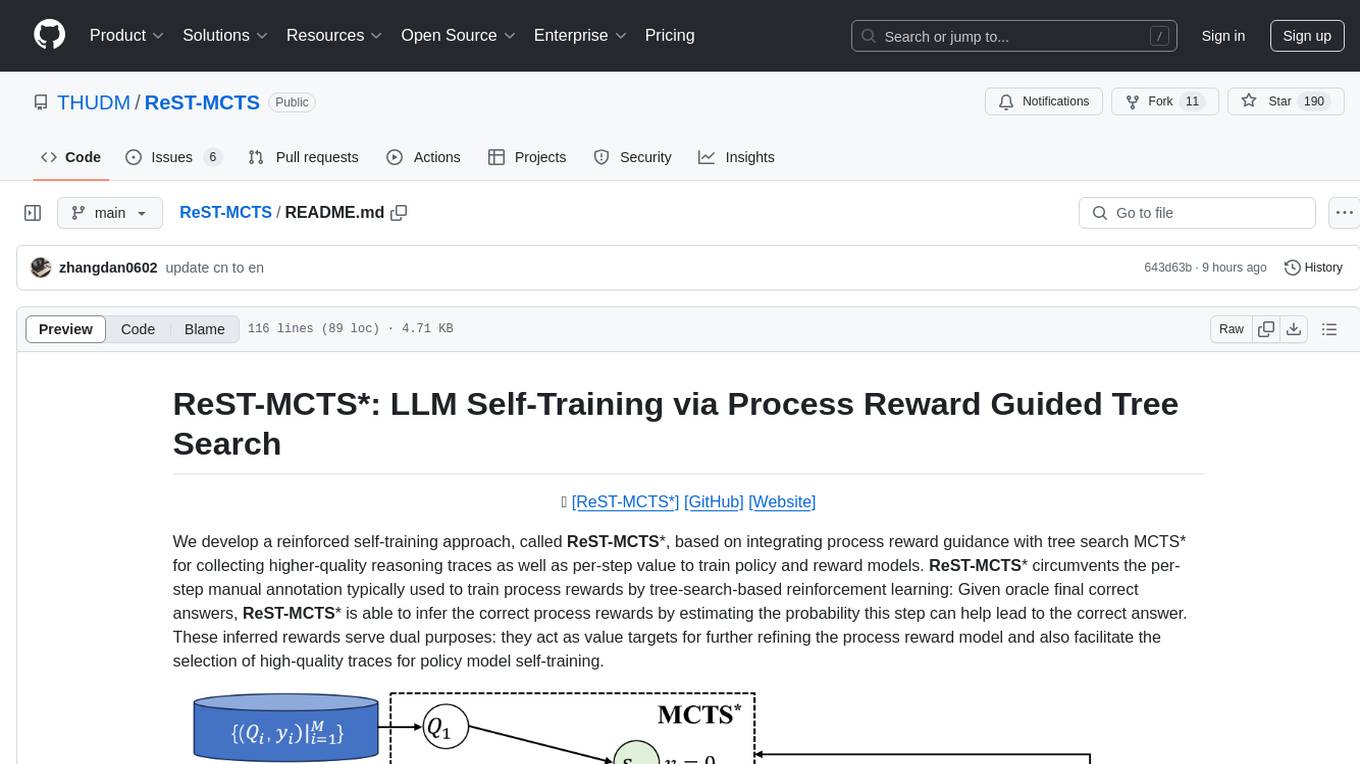
ReST-MCTS is a reinforced self-training approach that integrates process reward guidance with tree search MCTS to collect higher-quality reasoning traces and per-step value for training policy and reward models. It eliminates the need for manual per-step annotation by estimating the probability of steps leading to correct answers. The inferred rewards refine the process reward model and aid in selecting high-quality traces for policy model self-training.
README:
📃 [ReST-MCTS*]
[GitHub]
[Website]
We develop a reinforced self-training approach, called ReST-MCTS*, based on integrating process reward guidance with tree search MCTS* for collecting higher-quality reasoning traces as well as per-step value to train policy and reward models. ReST-MCTS* circumvents the per-step manual annotation typically used to train process rewards by tree-search-based reinforcement learning: Given oracle final correct answers, ReST-MCTS* is able to infer the correct process rewards by estimating the probability this step can help lead to the correct answer. These inferred rewards serve dual purposes: they act as value targets for further refining the process reward model and also facilitate the selection of high-quality traces for policy model self-training.

We summary the key differences between existing self-improvement methods and our approach. Train refers to whether to train a reward model.

Considering the different dependency versions of transformers for Mistral (or Llama) and SciGLM, you should install different environments through miniconda and install corresponding required packages by:
running Mistral (or Llama)
pip install -r requirements_mistral.txtor running SciGLM
pip install -r requirements_sciglm.txtNote that for some models on huggingface like the GLM series, you may need to install specific versions of transformers.
The Python version for running GLM is 3.11. The Python version for running Mistral or Llama is 3.12.
To run MCTS* search, you should implement a policy as well as a process reward model (value model).
You can download initial checkpoint and directly set these models by providing the model paths in the file models/model.py, substituting INFERENCE_MODEL_DIR, VALUE_BASE_MODEL_DIR and VALUE_MODEL_STATE_DICT.
INFERENCE_MODEL_DIR is the local path to the policy model, model could be [Llama3-8B-Instruct], [Mistral-7B: MetaMATH], and [SciGLM-6B].
VALUE_BASE_MODEL_DIR is the local path to the value model. Considering the different dependency versions of transformers, Mistral-7B is adopted as the backbone of the value model when the policy model is [Llama3-8B-Instruct] or [Mistral-7B: MetaMATH]. When the policy model is [SciGLM-6B], we use [ChatGLM3-6B] as the backbone of the value model.
Aiming to gather value train data for science, we integrate questions of a lean science dataset $D_{sci}$ within [SciInstruct] to construct $D_{V_0}$. This dataset consists of 11,554 questions, where each question is paired with a correct step-by-step solution. (See Fine-grained dataset for science and math. in Section 4.1 of [the paper] for more details.)
You can download [$D_{V_0}$] and put them in PRM/data to train Mistral-7B as the initial process reward model and obtain VALUE_MODEL_STATE_DICT.
We also provide PRM/train_VM_chatglm.py and PRM/train_VM_mistral.py.
The experimental settings are as follows:
For ChatGLM3-6B, learning rate (lr) is 2e-5, the number of epochs is 2 or 3, and batch size is 3.
For Mistral, learning rate (lr) is 3e-6, the number of epochs is 2 or 3, and batch size is 3.
We now only provide the implementation of the llama, glm and mistral as policy, with glm and mistral as value model in models/model.py.
If you are trying with other models, you can refer to our implementation and modify relevant codes to implement the corresponding models.
Once you've implemented the policy and value model, you should modify the LOCAL_INFERENCE_IDX and LOCAL_VALUE_IDX in models/model.py to the corresponding model index.
Before running search for evaluation or generation, you have to make sure your target question dataset is in the correct format. The data file should be a json file with items in the following format:
{
"content": "Calculate the sum of the first 10 prime numbers.",
"answer": "129"
}The content entry is required, serving as the question. While the answer entry is optional, it is used for evaluation.
The implementation of MCTS* search can be found in MCTS. We provide a search interface in MCTS/task.py. To run MCTS* search for a single question, you can refer to the following script:
from MCTS.task import *
question = "Calculate the sum of the first 10 prime numbers."
task = MCTS_Task(question, 'llama', 'local', lang='en')
output = task.run()
print(output['solution'])For evaluation of MCTS* on benchmarks, you can refer to evaluate.py, setting the parameter --mode to "mcts". You should specify the benchmark name and the exact file (subset) you want to evaluate. A simple demonstration is provided below:
python evaluate.py \
--task_name "scibench" \
--file "thermo" \
--propose_method "gpt" \
--value_method "local" \
--mode "mcts" \
--evaluate "scibench" \
--iteration_limit 50 \
--use_reflection "simple" \
--branch 3You can also refer to the MCTS/args.md for more details on the search parameters.
Given question set $D_G$, we use three backbones (Llama3-8B-Instruct, Mistral-7b: MetaMATH, and SciGLM-6B) guided by MCTS* to generate synthetic data for policy model and value model. (See Algorithm 1 of [the paper] for more details.)
Download policy data for training and comparing 1st policy model. Noting that CoT and MCTS only include positive samples. DPO includes both positive and negative samples.
| Backbone | Iteration | Self-Training | Full Name | Link |
|---|---|---|---|---|
| Llama3-8b-Instruct | 1st | ReST-EM (CoT) | ReST-MCTS_Llama3-8b-Instruct_ReST-EM-CoT_1st | [Hugging Face] |
| Self-Rewarding (DPO) | ReST-MCTS_Llama3-8b-Instruct_Self-Rewarding-DPO_1st | [Hugging Face] | ||
| ReST-MCTS | ReST-MCTS_Llama3-8b-Instruct_ReST-MCTS_Policy_1st | [Hugging Face] | ||
| Mistral: MetaMATH-7b | 1st | ReST-EM (CoT) | ReST-MCTS_Mistral-MetaMATH-7b-Instruct_ReST-EM-CoT_1st | [Hugging Face] |
| Self-Rewarding (DPO) | ReST-MCTS_Mistral-MetaMATH-7b-Instruct_Self-Rewarding-DPO_1st | [Hugging Face] | ||
| ReST-MCTS | ReST-MCTS_Mistral-MetaMATH-7b-Instruct_ReST-MCTS_1st | [Hugging Face] | ||
| SciGLM-6B | 1st | ReST-EM (CoT) | ReST-MCTS_SciGLM-6B_ReST-EM-CoT_1st | [Hugging Face] |
| Self-Rewarding (DPO) | ReST-MCTS_SciGLM-6B_Self-Rewarding-DPO_1st | [Hugging Face] | ||
| ReST-MCTS | ReST-MCTS_SciGLM-6B_ReST-MCTS_Policy_1st | [Hugging Face] | ||
Download policy data for training and comparing 2nd policy model.
| Backbone | Iteration | Self-Training | Full Name | Link |
|---|---|---|---|---|
| Llama3-8b-Instruct | 2nd | ReST-EM (CoT) | ReST-MCTS_Llama3-8b-Instruct_ReST-EM-CoT_2nd | [Hugging Face] |
| Self-Rewarding (DPO) | ReST-MCTS_Llama3-8b-Instruct_Self-Rewarding-DPO_2nd | [Hugging Face] | ||
| ReST-MCTS | ReST-MCTS_Llama3-8b-Instruct_ReST-MCTS_Policy_2nd | [Hugging Face] | ||
| Mistral: MetaMATH-7b | 2nd | ReST-EM (CoT) | ReST-MCTS_Mistral-MetaMATH-7b-Instruct_ReST-EM-CoT_2nd | [Hugging Face] |
| Self-Rewarding (DPO) | ReST-MCTS_Mistral-MetaMATH-7b-Instruct_Self-Rewarding-DPO_2nd | [Hugging Face] | ||
| ReST-MCTS | ReST-MCTS_Mistral-MetaMATH-7b-Instruct_ReST-MCTS_2nd | [Hugging Face] | ||
| SciGLM-6B | 2nd | ReST-EM (CoT) | ReST-MCTS_SciGLM-6B_ReST-EM-CoT_2nd | [Hugging Face] |
| Self-Rewarding (DPO) | ReST-MCTS_SciGLM-6B_Self-Rewarding-DPO_2nd | [Hugging Face] | ||
| ReST-MCTS | ReST-MCTS_SciGLM-6B_ReST-MCTS_Policy_2nd | [Hugging Face] | ||
Download PRM data (positive and negative samples) for training 1st reward model (Llama3-8b-Instruct): [Hugging Face]
For our methods:
Regarding Llama3-8B-Instruct and Mistral-7B: MetaMATH, we use the default repo of [MAmmoTH] to train the policy model and evaluate.
Regarding SciGLM-6B, we use the default repo of [SciGLM] to train the policy model and evaluate.
We also implement self-rewarding as our baseline in ./self_train/self_train_dpo.py.
Self-training Results:

Accuracy of Different Verifiers:

Accuracy of Different Searches (we also provide the plot code in figures/plot_math_self_training.py):

If you find our work helpful, please kindly cite our paper:
@article{zhang2024rest,
title={ReST-MCTS*: LLM Self-Training via Process Reward Guided Tree Search},
author={Zhang, Dan and Zhoubian, Sining and Hu, Ziniu and Yue, Yisong and Dong, Yuxiao and Tang, Jie},
journal={arXiv preprint arXiv:2406.03816},
year={2024}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ReST-MCTS
Similar Open Source Tools
ReST-MCTS
ReST-MCTS is a reinforced self-training approach that integrates process reward guidance with tree search MCTS to collect higher-quality reasoning traces and per-step value for training policy and reward models. It eliminates the need for manual per-step annotation by estimating the probability of steps leading to correct answers. The inferred rewards refine the process reward model and aid in selecting high-quality traces for policy model self-training.

KwaiAgents
KwaiAgents is a series of Agent-related works open-sourced by the [KwaiKEG](https://github.com/KwaiKEG) from [Kuaishou Technology](https://www.kuaishou.com/en). The open-sourced content includes: 1. **KAgentSys-Lite**: a lite version of the KAgentSys in the paper. While retaining some of the original system's functionality, KAgentSys-Lite has certain differences and limitations when compared to its full-featured counterpart, such as: (1) a more limited set of tools; (2) a lack of memory mechanisms; (3) slightly reduced performance capabilities; and (4) a different codebase, as it evolves from open-source projects like BabyAGI and Auto-GPT. Despite these modifications, KAgentSys-Lite still delivers comparable performance among numerous open-source Agent systems available. 2. **KAgentLMs**: a series of large language models with agent capabilities such as planning, reflection, and tool-use, acquired through the Meta-agent tuning proposed in the paper. 3. **KAgentInstruct**: over 200k Agent-related instructions finetuning data (partially human-edited) proposed in the paper. 4. **KAgentBench**: over 3,000 human-edited, automated evaluation data for testing Agent capabilities, with evaluation dimensions including planning, tool-use, reflection, concluding, and profiling.

IDvs.MoRec
This repository contains the source code for the SIGIR 2023 paper 'Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited'. It provides resources for evaluating foundation, transferable, multi-modal, and LLM recommendation models, along with datasets, pre-trained models, and training strategies for IDRec and MoRec using in-batch debiased cross-entropy loss. The repository also offers large-scale datasets, code for SASRec with in-batch debias cross-entropy loss, and information on joining the lab for research opportunities.

optillm
optillm is an OpenAI API compatible optimizing inference proxy implementing state-of-the-art techniques to enhance accuracy and performance of LLMs, focusing on reasoning over coding, logical, and mathematical queries. By leveraging additional compute at inference time, it surpasses frontier models across diverse tasks.

Q-Bench
Q-Bench is a benchmark for general-purpose foundation models on low-level vision, focusing on multi-modality LLMs performance. It includes three realms for low-level vision: perception, description, and assessment. The benchmark datasets LLVisionQA and LLDescribe are collected for perception and description tasks, with open submission-based evaluation. An abstract evaluation code is provided for assessment using public datasets. The tool can be used with the datasets API for single images and image pairs, allowing for automatic download and usage. Various tasks and evaluations are available for testing MLLMs on low-level vision tasks.

EasyEdit
EasyEdit is a Python package for edit Large Language Models (LLM) like `GPT-J`, `Llama`, `GPT-NEO`, `GPT2`, `T5`(support models from **1B** to **65B**), the objective of which is to alter the behavior of LLMs efficiently within a specific domain without negatively impacting performance across other inputs. It is designed to be easy to use and easy to extend.

ColossalAI
Colossal-AI is a deep learning system for large-scale parallel training. It provides a unified interface to scale sequential code of model training to distributed environments. Colossal-AI supports parallel training methods such as data, pipeline, tensor, and sequence parallelism and is integrated with heterogeneous training and zero redundancy optimizer.
TokenPacker
TokenPacker is a novel visual projector that compresses visual tokens by 75%∼89% with high efficiency. It adopts a 'coarse-to-fine' scheme to generate condensed visual tokens, achieving comparable or better performance across diverse benchmarks. The tool includes TokenPacker for general use and TokenPacker-HD for high-resolution image understanding. It provides training scripts, checkpoints, and supports various compression ratios and patch numbers.
ExplainableAI.jl
ExplainableAI.jl is a Julia package that implements interpretability methods for black-box classifiers, focusing on local explanations and attribution maps in input space. The package requires models to be differentiable with Zygote.jl. It is similar to Captum and Zennit for PyTorch and iNNvestigate for Keras models. Users can analyze and visualize explanations for model predictions, with support for different XAI methods and customization. The package aims to provide transparency and insights into model decision-making processes, making it a valuable tool for understanding and validating machine learning models.
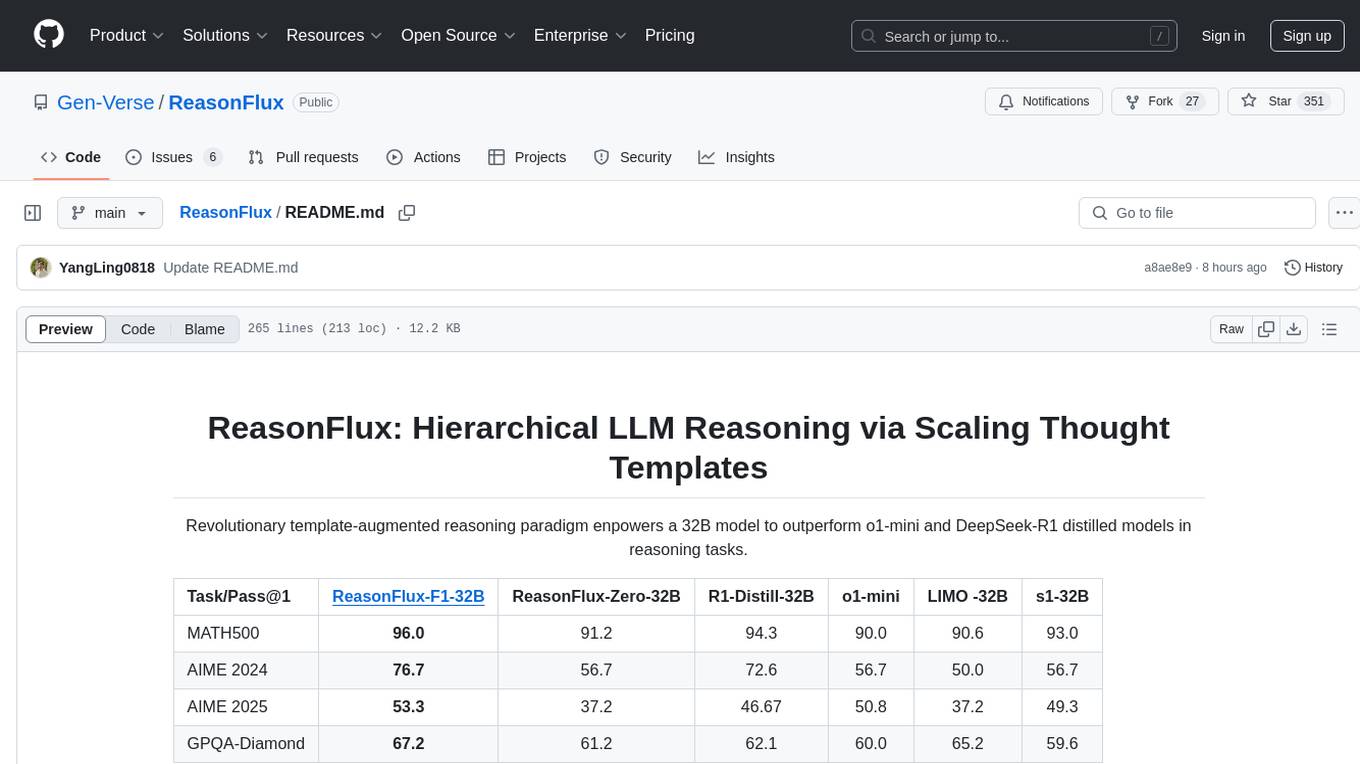
ReasonFlux
ReasonFlux is a revolutionary template-augmented reasoning paradigm that empowers a 32B model to outperform other models in reasoning tasks. The repository provides official resources for the paper 'ReasonFlux: Hierarchical LLM Reasoning via Scaling Thought Templates', including the latest released model ReasonFlux-F1-32B. It includes updates, dataset links, model zoo, getting started guide, training instructions, evaluation details, inference examples, performance comparisons, reasoning examples, preliminary work references, and citation information.

chat-your-doc
Chat Your Doc is an experimental project exploring various applications based on LLM technology. It goes beyond being just a chatbot project, focusing on researching LLM applications using tools like LangChain and LlamaIndex. The project delves into UX, computer vision, and offers a range of examples in the 'Lab Apps' section. It includes links to different apps, descriptions, launch commands, and demos, aiming to showcase the versatility and potential of LLM applications.

agentscope
AgentScope is a multi-agent platform designed to empower developers to build multi-agent applications with large-scale models. It features three high-level capabilities: Easy-to-Use, High Robustness, and Actor-Based Distribution. AgentScope provides a list of `ModelWrapper` to support both local model services and third-party model APIs, including OpenAI API, DashScope API, Gemini API, and ollama. It also enables developers to rapidly deploy local model services using libraries such as ollama (CPU inference), Flask + Transformers, Flask + ModelScope, FastChat, and vllm. AgentScope supports various services, including Web Search, Data Query, Retrieval, Code Execution, File Operation, and Text Processing. Example applications include Conversation, Game, and Distribution. AgentScope is released under Apache License 2.0 and welcomes contributions.

MooER
MooER (摩耳) is an LLM-based speech recognition and translation model developed by Moore Threads. It allows users to transcribe speech into text (ASR) and translate speech into other languages (AST) in an end-to-end manner. The model was trained using 5K hours of data and is now also available with an 80K hours version. MooER is the first LLM-based speech model trained and inferred using domestic GPUs. The repository includes pretrained models, inference code, and a Gradio demo for a better user experience.

llm4ad
LLM4AD is an open-source Python-based platform leveraging Large Language Models (LLMs) for Automatic Algorithm Design (AD). It provides unified interfaces for methods, tasks, and LLMs, along with features like evaluation acceleration, secure evaluation, logs, GUI support, and more. The platform was originally developed for optimization tasks but is versatile enough to be used in other areas such as machine learning, science discovery, game theory, and engineering design. It offers various search methods and algorithm design tasks across different domains. LLM4AD supports remote LLM API, local HuggingFace LLM deployment, and custom LLM interfaces. The project is licensed under the MIT License and welcomes contributions, collaborations, and issue reports.

vscode-unify-chat-provider
The 'vscode-unify-chat-provider' repository is a tool that integrates multiple LLM API providers into VS Code's GitHub Copilot Chat using the Language Model API. It offers free tier access to mainstream models, perfect compatibility with major LLM API formats, deep adaptation to API features, best performance with built-in parameters, out-of-the-box configuration, import/export support, great UX, and one-click use of various models. The tool simplifies model setup, migration, and configuration for users, providing a seamless experience within VS Code for utilizing different language models.
For similar tasks

Xwin-LM
Xwin-LM is a powerful and stable open-source tool for aligning large language models, offering various alignment technologies like supervised fine-tuning, reward models, reject sampling, and reinforcement learning from human feedback. It has achieved top rankings in benchmarks like AlpacaEval and surpassed GPT-4. The tool is continuously updated with new models and features.

LLM-Tool-Survey
This repository contains a collection of papers related to tool learning with large language models (LLMs). The papers are organized according to the survey paper 'Tool Learning with Large Language Models: A Survey'. The survey focuses on the benefits and implementation of tool learning with LLMs, covering aspects such as task planning, tool selection, tool calling, response generation, benchmarks, evaluation, challenges, and future directions in the field. It aims to provide a comprehensive understanding of tool learning with LLMs and inspire further exploration in this emerging area.
Awesome-AI-Agents
Awesome-AI-Agents is a curated list of projects, frameworks, benchmarks, platforms, and related resources focused on autonomous AI agents powered by Large Language Models (LLMs). The repository showcases a wide range of applications, multi-agent task solver projects, agent society simulations, and advanced components for building and customizing AI agents. It also includes frameworks for orchestrating role-playing, evaluating LLM-as-Agent performance, and connecting LLMs with real-world applications through platforms and APIs. Additionally, the repository features surveys, paper lists, and blogs related to LLM-based autonomous agents, making it a valuable resource for researchers, developers, and enthusiasts in the field of AI.
ReST-MCTS
ReST-MCTS is a reinforced self-training approach that integrates process reward guidance with tree search MCTS to collect higher-quality reasoning traces and per-step value for training policy and reward models. It eliminates the need for manual per-step annotation by estimating the probability of steps leading to correct answers. The inferred rewards refine the process reward model and aid in selecting high-quality traces for policy model self-training.
LongCite
LongCite is a tool that enables Large Language Models (LLMs) to generate fine-grained citations in long-context Question Answering (QA) scenarios. It provides models trained on GLM-4-9B and Meta-Llama-3.1-8B, supporting up to 128K context. Users can deploy LongCite chatbots, generate accurate responses, and obtain precise sentence-level citations. The tool includes components for model deployment, Coarse to Fine (CoF) pipeline for data construction, model training using LongCite-45k dataset, evaluation with LongBench-Cite benchmark, and citation generation.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.