
LongCite
LongCite: Enabling LLMs to Generate Fine-grained Citations in Long-context QA
Stars: 295
LongCite is a tool that enables Large Language Models (LLMs) to generate fine-grained citations in long-context Question Answering (QA) scenarios. It provides models trained on GLM-4-9B and Meta-Llama-3.1-8B, supporting up to 128K context. Users can deploy LongCite chatbots, generate accurate responses, and obtain precise sentence-level citations. The tool includes components for model deployment, Coarse to Fine (CoF) pipeline for data construction, model training using LongCite-45k dataset, evaluation with LongBench-Cite benchmark, and citation generation.
README:
🤗 HF Repo • 📃 Paper • 🚀 HF Space
https://github.com/user-attachments/assets/68f6677a-3ffd-41a8-889c-d56a65f9e3bb
Environmental Setup:
We recommend using transformers>=4.43.0 to successfully deploy our models.
We open-source two models: LongCite-glm4-9b and LongCite-llama3.1-8b, which are trained based on GLM-4-9B and Meta-Llama-3.1-8B, respectively, and support up to 128K context. These two models point to the "LongCite-9B" and "LongCite-8B" models in our paper. Given a long-context-based query, these models can generate accurate responses and precise sentence-level citations, making it easy for users to verify the output information. Try the model:
import json
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained('THUDM/LongCite-glm4-9b', trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained('THUDM/LongCite-glm4-9b', torch_dtype=torch.bfloat16, trust_remote_code=True, device_map='auto')
context = '''
W. Russell Todd, 94, United States Army general (b. 1928). February 13. Tim Aymar, 59, heavy metal singer (Pharaoh) (b. 1963). Marshall \"Eddie\" Conway, 76, Black Panther Party leader (b. 1946). Roger Bonk, 78, football player (North Dakota Fighting Sioux, Winnipeg Blue Bombers) (b. 1944). Conrad Dobler, 72, football player (St. Louis Cardinals, New Orleans Saints, Buffalo Bills) (b. 1950). Brian DuBois, 55, baseball player (Detroit Tigers) (b. 1967). Robert Geddes, 99, architect, dean of the Princeton University School of Architecture (1965–1982) (b. 1923). Tom Luddy, 79, film producer (Barfly, The Secret Garden), co-founder of the Telluride Film Festival (b. 1943). David Singmaster, 84, mathematician (b. 1938).
'''
query = "What was Robert Geddes' profession?"
result = model.query_longcite(context, query, tokenizer=tokenizer, max_input_length=128000, max_new_tokens=1024)
print("Answer:\n{}\n".format(result['answer']))
print("Statement with citations:\n{}\n".format(
json.dumps(result['statements_with_citations'], indent=2, ensure_ascii=False)))
print("Context (divided into sentences):\n{}\n".format(result['splited_context']))You may deploy your own LongCite chatbot (like the one we show in the above video) by running
CUDA_VISIBLE_DEVICES=0 streamlit run demo.py --server.fileWatcherType none
Alternatively, you can deploy the model with vllm, which allows faster generation and multiconcurrent server. See the code example in vllm_inference.py.
We are also open-sourcing CoF (Coarse to Fine) under CoF/, our automated SFT data construction pipeline for generating high-quality long-context QA instances with fine-grained citations. Please configure your API key in the utils/llm_api.py, then run the following four scripts to obtain the final data:
1_qa_generation.py, 2_chunk_level_citation.py, 3_sentence_level_citaion.py, and 4_postprocess_and_filter.py.
You can download and save the LongCite-45k dataset through the Hugging Face datasets (🤗 HF Repo):
dataset = load_dataset('THUDM/LongCite-45k')
for split, split_dataset in dataset.items():
split_dataset.to_json("train/long.jsonl")You can mix it with general SFT data such as ShareGPT. We adopt Metragon-LM for model training. For a more lightweight implementation, you may adopt the code and environment from LongAlign, which can support a max training sequence length of 32k tokens for GLM-4-9B and Llama-3.1-8B.
We introduce an automatic benchmark: LongBench-Cite, which adopt long-context QA pairs from LongBench and LongBench-Chat, to measure the citation quality as well as response correctness in long-context QA scenarios.
We provide our evaluation data and code under LongBench-Cite/. Run pred_sft.py and pred_one_shot.py to get responses from fine-tuned models (e.g., LongCite-glm4-9b) and normal models (e.g., GPT-4o). Then run eval_cite.py and eval_correct.py to evaluate the citation quality and response correctness. Remember to configure your OpenAI API key in utils/llm_api.py since we adopt GPT-4o as the judge.
Here are the evaluation results on LongBench-Cite:
If you find our work useful, please consider citing LongCite:
@article{zhang2024longcite,
title = {LongCite: Enabling LLMs to Generate Fine-grained Citations in Long-context QA}
author={Jiajie Zhang and Yushi Bai and Xin Lv and Wanjun Gu and Danqing Liu and Minhao Zou and Shulin Cao and Lei Hou and Yuxiao Dong and Ling Feng and Juanzi Li},
journal={arXiv preprint arXiv:2409.02897},
year={2024}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LongCite
Similar Open Source Tools
LongCite
LongCite is a tool that enables Large Language Models (LLMs) to generate fine-grained citations in long-context Question Answering (QA) scenarios. It provides models trained on GLM-4-9B and Meta-Llama-3.1-8B, supporting up to 128K context. Users can deploy LongCite chatbots, generate accurate responses, and obtain precise sentence-level citations. The tool includes components for model deployment, Coarse to Fine (CoF) pipeline for data construction, model training using LongCite-45k dataset, evaluation with LongBench-Cite benchmark, and citation generation.

MInference
MInference is a tool designed to accelerate pre-filling for long-context Language Models (LLMs) by leveraging dynamic sparse attention. It achieves up to a 10x speedup for pre-filling on an A100 while maintaining accuracy. The tool supports various decoding LLMs, including LLaMA-style models and Phi models, and provides custom kernels for attention computation. MInference is useful for researchers and developers working with large-scale language models who aim to improve efficiency without compromising accuracy.
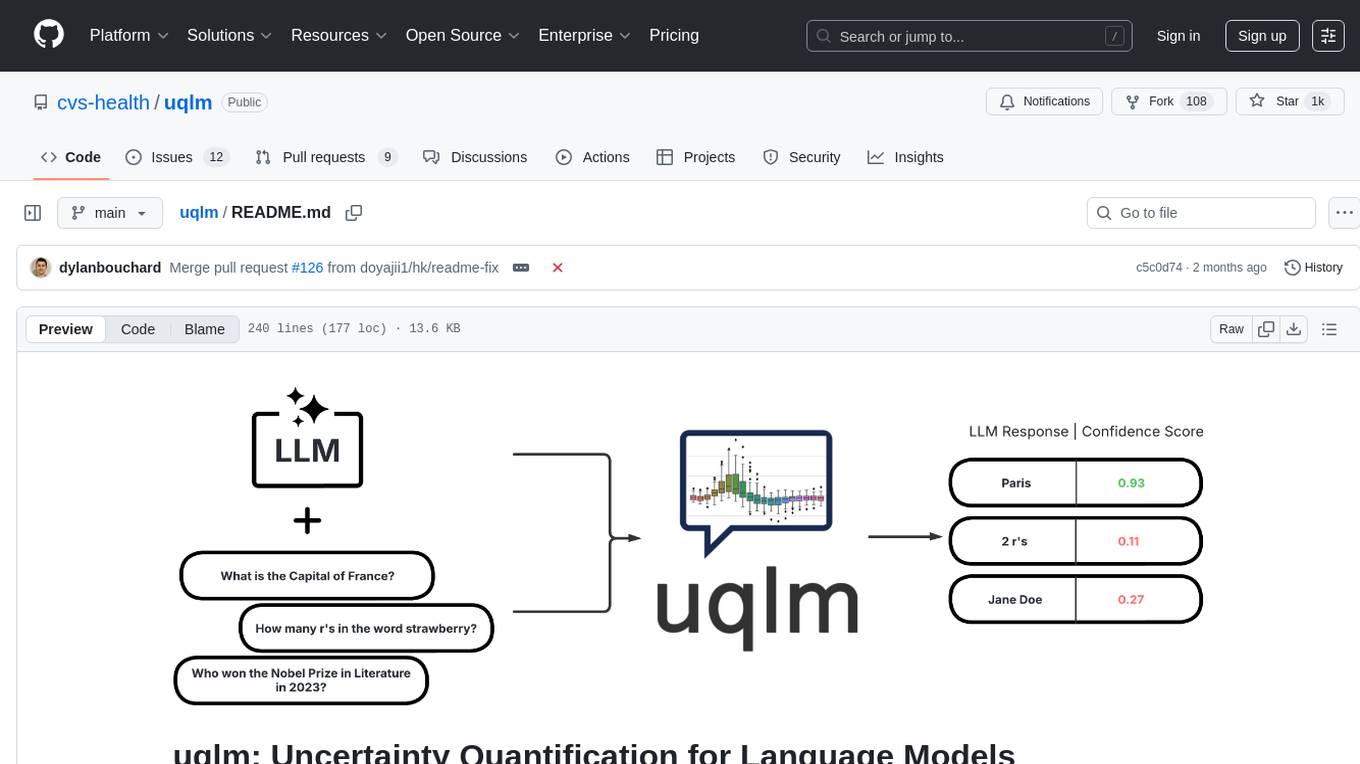
uqlm
UQLM is a Python library for Large Language Model (LLM) hallucination detection using state-of-the-art uncertainty quantification techniques. It provides response-level scorers for quantifying uncertainty of LLM outputs, categorized into four main types: Black-Box Scorers, White-Box Scorers, LLM-as-a-Judge Scorers, and Ensemble Scorers. Users can leverage different scorers to assess uncertainty in generated responses, with options for off-the-shelf usage or customization. The library offers illustrative code snippets and detailed information on available scorers for each type, along with example usage for conducting hallucination detection. Additionally, UQLM includes documentation, example notebooks, and associated research for further exploration and understanding.

SeerAttention
SeerAttention is a novel trainable sparse attention mechanism that learns intrinsic sparsity patterns directly from LLMs through self-distillation at post-training time. It achieves faster inference while maintaining accuracy for long-context prefilling. The tool offers features such as trainable sparse attention, block-level sparsity, self-distillation, efficient kernel, and easy integration with existing transformer architectures. Users can quickly start using SeerAttention for inference with AttnGate Adapter and training attention gates with self-distillation. The tool provides efficient evaluation methods and encourages contributions from the community.

RLAIF-V
RLAIF-V is a novel framework that aligns MLLMs in a fully open-source paradigm for super GPT-4V trustworthiness. It maximally exploits open-source feedback from high-quality feedback data and online feedback learning algorithm. Notable features include achieving super GPT-4V trustworthiness in both generative and discriminative tasks, using high-quality generalizable feedback data to reduce hallucination of different MLLMs, and exhibiting better learning efficiency and higher performance through iterative alignment.

catalyst
Catalyst is a C# Natural Language Processing library designed for speed, inspired by spaCy's design. It provides pre-trained models, support for training word and document embeddings, and flexible entity recognition models. The library is fast, modern, and pure-C#, supporting .NET standard 2.0. It is cross-platform, running on Windows, Linux, macOS, and ARM. Catalyst offers non-destructive tokenization, named entity recognition, part-of-speech tagging, language detection, and efficient binary serialization. It includes pre-built models for language packages and lemmatization. Users can store and load models using streams. Getting started with Catalyst involves installing its NuGet Package and setting the storage to use the online repository. The library supports lazy loading of models from disk or online. Users can take advantage of C# lazy evaluation and native multi-threading support to process documents in parallel. Training a new FastText word2vec embedding model is straightforward, and Catalyst also provides algorithms for fast embedding search and dimensionality reduction.

ALMA
ALMA (Advanced Language Model-based Translator) is a many-to-many LLM-based translation model that utilizes a two-step fine-tuning process on monolingual and parallel data to achieve strong translation performance. ALMA-R builds upon ALMA models with LoRA fine-tuning and Contrastive Preference Optimization (CPO) for even better performance, surpassing GPT-4 and WMT winners. The repository provides ALMA and ALMA-R models, datasets, environment setup, evaluation scripts, training guides, and data information for users to leverage these models for translation tasks.

raid
RAID is the largest and most comprehensive dataset for evaluating AI-generated text detectors. It contains over 10 million documents spanning 11 LLMs, 11 genres, 4 decoding strategies, and 12 adversarial attacks. RAID is designed to be the go-to location for trustworthy third-party evaluation of popular detectors. The dataset covers diverse models, domains, sampling strategies, and attacks, making it a valuable resource for training detectors, evaluating generalization, protecting against adversaries, and comparing to state-of-the-art models from academia and industry.

LongBench
LongBench v2 is a benchmark designed to assess the ability of large language models (LLMs) to handle long-context problems requiring deep understanding and reasoning across various real-world multitasks. It consists of 503 challenging multiple-choice questions with contexts ranging from 8k to 2M words, covering six major task categories. The dataset is collected from nearly 100 highly educated individuals with diverse professional backgrounds and is designed to be challenging even for human experts. The evaluation results highlight the importance of enhanced reasoning ability and scaling inference-time compute to tackle the long-context challenges in LongBench v2.
evidently
Evidently is an open-source Python library designed for evaluating, testing, and monitoring machine learning (ML) and large language model (LLM) powered systems. It offers a wide range of functionalities, including working with tabular, text data, and embeddings, supporting predictive and generative systems, providing over 100 built-in metrics for data drift detection and LLM evaluation, allowing for custom metrics and tests, enabling both offline evaluations and live monitoring, and offering an open architecture for easy data export and integration with existing tools. Users can utilize Evidently for one-off evaluations using Reports or Test Suites in Python, or opt for real-time monitoring through the Dashboard service.

transformers
Transformers is a state-of-the-art pretrained models library that acts as the model-definition framework for machine learning models in text, computer vision, audio, video, and multimodal tasks. It centralizes model definition for compatibility across various training frameworks, inference engines, and modeling libraries. The library simplifies the usage of new models by providing simple, customizable, and efficient model definitions. With over 1M+ Transformers model checkpoints available, users can easily find and utilize models for their tasks.

only_train_once
Only Train Once (OTO) is an automatic, architecture-agnostic DNN training and compression framework that allows users to train a general DNN from scratch or a pretrained checkpoint to achieve high performance and slimmer architecture simultaneously in a one-shot manner without fine-tuning. The framework includes features for automatic structured pruning and erasing operators, as well as hybrid structured sparse optimizers for efficient model compression. OTO provides tools for pruning zero-invariant group partitioning, constructing pruned models, and visualizing pruning and erasing dependency graphs. It supports the HESSO optimizer and offers a sanity check for compliance testing on various DNNs. The repository also includes publications, installation instructions, quick start guides, and a roadmap for future enhancements and collaborations.

swiftide
Swiftide is a fast, streaming indexing and query library tailored for Retrieval Augmented Generation (RAG) in AI applications. It is built in Rust, utilizing parallel, asynchronous streams for blazingly fast performance. With Swiftide, users can easily build AI applications from idea to production in just a few lines of code. The tool addresses frustrations around performance, stability, and ease of use encountered while working with Python-based tooling. It offers features like fast streaming indexing pipeline, experimental query pipeline, integrations with various platforms, loaders, transformers, chunkers, embedders, and more. Swiftide aims to provide a platform for data indexing and querying to advance the development of automated Large Language Model (LLM) applications.
keras-hub
KerasHub is a pretrained modeling library that provides Keras 3 implementations of popular model architectures with pretrained checkpoints. It supports text, image, and audio data for generation, classification, and other tasks. Models are compatible with JAX, TensorFlow, and PyTorch, and can be fine-tuned on GPUs and TPUs. KerasHub components are provided as Layer and Model implementations, extending the core Keras API.

OpenMusic
OpenMusic is a repository providing an implementation of QA-MDT, a Quality-Aware Masked Diffusion Transformer for music generation. The code integrates state-of-the-art models and offers training strategies for music generation. The repository includes implementations of AudioLDM, PixArt-alpha, MDT, AudioMAE, and Open-Sora. Users can train or fine-tune the model using different strategies and datasets. The model is well-pretrained and can be used for music generation tasks. The repository also includes instructions for preparing datasets, training the model, and performing inference. Contact information is provided for any questions or suggestions regarding the project.

Trace
Trace is a new AutoDiff-like tool for training AI systems end-to-end with general feedback. It generalizes the back-propagation algorithm by capturing and propagating an AI system's execution trace. Implemented as a PyTorch-like Python library, users can write Python code directly and use Trace primitives to optimize certain parts, similar to training neural networks.
For similar tasks
LongCite
LongCite is a tool that enables Large Language Models (LLMs) to generate fine-grained citations in long-context Question Answering (QA) scenarios. It provides models trained on GLM-4-9B and Meta-Llama-3.1-8B, supporting up to 128K context. Users can deploy LongCite chatbots, generate accurate responses, and obtain precise sentence-level citations. The tool includes components for model deployment, Coarse to Fine (CoF) pipeline for data construction, model training using LongCite-45k dataset, evaluation with LongBench-Cite benchmark, and citation generation.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

botpress
Botpress is a platform for building next-generation chatbots and assistants powered by OpenAI. It provides a range of tools and integrations to help developers quickly and easily create and deploy chatbots for various use cases.
Conversational-Azure-OpenAI-Accelerator
The Conversational Azure OpenAI Accelerator is a tool designed to provide rapid, no-cost custom demos tailored to customer use cases, from internal HR/IT to external contact centers. It focuses on top use cases of GenAI conversation and summarization, plus live backend data integration. The tool automates conversations across voice and text channels, providing a valuable way to save money and improve customer and employee experience. By combining Azure OpenAI + Cognitive Search, users can efficiently deploy a ChatGPT experience using web pages, knowledge base articles, and data sources. The tool enables simultaneous deployment of conversational content to chatbots, IVR, voice assistants, and more in one click, eliminating the need for in-depth IT involvement. It leverages Microsoft's advanced AI technologies, resulting in a conversational experience that can converse in human-like dialogue, respond intelligently, and capture content for omni-channel unified analytics.

Xwin-LM
Xwin-LM is a powerful and stable open-source tool for aligning large language models, offering various alignment technologies like supervised fine-tuning, reward models, reject sampling, and reinforcement learning from human feedback. It has achieved top rankings in benchmarks like AlpacaEval and surpassed GPT-4. The tool is continuously updated with new models and features.

LLM-Tool-Survey
This repository contains a collection of papers related to tool learning with large language models (LLMs). The papers are organized according to the survey paper 'Tool Learning with Large Language Models: A Survey'. The survey focuses on the benefits and implementation of tool learning with LLMs, covering aspects such as task planning, tool selection, tool calling, response generation, benchmarks, evaluation, challenges, and future directions in the field. It aims to provide a comprehensive understanding of tool learning with LLMs and inspire further exploration in this emerging area.
Awesome-AI-Agents
Awesome-AI-Agents is a curated list of projects, frameworks, benchmarks, platforms, and related resources focused on autonomous AI agents powered by Large Language Models (LLMs). The repository showcases a wide range of applications, multi-agent task solver projects, agent society simulations, and advanced components for building and customizing AI agents. It also includes frameworks for orchestrating role-playing, evaluating LLM-as-Agent performance, and connecting LLMs with real-world applications through platforms and APIs. Additionally, the repository features surveys, paper lists, and blogs related to LLM-based autonomous agents, making it a valuable resource for researchers, developers, and enthusiasts in the field of AI.
For similar jobs

Perplexica
Perplexica is an open-source AI-powered search engine that utilizes advanced machine learning algorithms to provide clear answers with sources cited. It offers various modes like Copilot Mode, Normal Mode, and Focus Modes for specific types of questions. Perplexica ensures up-to-date information by using SearxNG metasearch engine. It also features image and video search capabilities and upcoming features include finalizing Copilot Mode and adding Discover and History Saving features.

KULLM
KULLM (구름) is a Korean Large Language Model developed by Korea University NLP & AI Lab and HIAI Research Institute. It is based on the upstage/SOLAR-10.7B-v1.0 model and has been fine-tuned for instruction. The model has been trained on 8×A100 GPUs and is capable of generating responses in Korean language. KULLM exhibits hallucination and repetition phenomena due to its decoding strategy. Users should be cautious as the model may produce inaccurate or harmful results. Performance may vary in benchmarks without a fixed system prompt.

MMMU
MMMU is a benchmark designed to evaluate multimodal models on college-level subject knowledge tasks, covering 30 subjects and 183 subfields with 11.5K questions. It focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform tasks akin to those faced by experts. The evaluation of various models highlights substantial challenges, with room for improvement to stimulate the community towards expert artificial general intelligence (AGI).

1filellm
1filellm is a command-line data aggregation tool designed for LLM ingestion. It aggregates and preprocesses data from various sources into a single text file, facilitating the creation of information-dense prompts for large language models. The tool supports automatic source type detection, handling of multiple file formats, web crawling functionality, integration with Sci-Hub for research paper downloads, text preprocessing, and token count reporting. Users can input local files, directories, GitHub repositories, pull requests, issues, ArXiv papers, YouTube transcripts, web pages, Sci-Hub papers via DOI or PMID. The tool provides uncompressed and compressed text outputs, with the uncompressed text automatically copied to the clipboard for easy pasting into LLMs.

gpt-researcher
GPT Researcher is an autonomous agent designed for comprehensive online research on a variety of tasks. It can produce detailed, factual, and unbiased research reports with customization options. The tool addresses issues of speed, determinism, and reliability by leveraging parallelized agent work. The main idea involves running 'planner' and 'execution' agents to generate research questions, seek related information, and create research reports. GPT Researcher optimizes costs and completes tasks in around 3 minutes. Features include generating long research reports, aggregating web sources, an easy-to-use web interface, scraping web sources, and exporting reports to various formats.

ChatTTS
ChatTTS is a generative speech model optimized for dialogue scenarios, providing natural and expressive speech synthesis with fine-grained control over prosodic features. It supports multiple speakers and surpasses most open-source TTS models in terms of prosody. The model is trained with 100,000+ hours of Chinese and English audio data, and the open-source version on HuggingFace is a 40,000-hour pre-trained model without SFT. The roadmap includes open-sourcing additional features like VQ encoder, multi-emotion control, and streaming audio generation. The tool is intended for academic and research use only, with precautions taken to limit potential misuse.

HebTTS
HebTTS is a language modeling approach to diacritic-free Hebrew text-to-speech (TTS) system. It addresses the challenge of accurately mapping text to speech in Hebrew by proposing a language model that operates on discrete speech representations and is conditioned on a word-piece tokenizer. The system is optimized using weakly supervised recordings and outperforms diacritic-based Hebrew TTS systems in terms of content preservation and naturalness of generated speech.

do-research-in-AI
This repository is a collection of research lectures and experience sharing posts from frontline researchers in the field of AI. It aims to help individuals upgrade their research skills and knowledge through insightful talks and experiences shared by experts. The content covers various topics such as evaluating research papers, choosing research directions, research methodologies, and tips for writing high-quality scientific papers. The repository also includes discussions on academic career paths, research ethics, and the emotional aspects of research work. Overall, it serves as a valuable resource for individuals interested in advancing their research capabilities in the field of AI.