
Quantus
Quantus is an eXplainable AI toolkit for responsible evaluation of neural network explanations
Stars: 502

Quantus is a toolkit designed for the evaluation of neural network explanations. It offers more than 30 metrics in 6 categories for eXplainable Artificial Intelligence (XAI) evaluation. The toolkit supports different data types (image, time-series, tabular, NLP) and models (PyTorch, TensorFlow). It provides built-in support for explanation methods like captum, tf-explain, and zennit. Quantus is under active development and aims to provide a comprehensive set of quantitative evaluation metrics for XAI methods.
README:
![]()
PyTorch and TensorFlow
![]()
![]()

Quantus is currently under active development so carefully note the Quantus release version to ensure reproducibility of your work.
- If you want to contribute/ improve/ extend Quantus, join our Discord!
- New metrics added: EfficientMPRT and SmoothMPRT by Hedström et al., (2023)
- Released a new version here with Python 3.7 discontinued
- Accepted to Journal of Machine Learning Research (MLOSS), read the paper
- Offers more than 30+ metrics in 6 categories for XAI evaluation
- Supports different data types (image, time-series, tabular, NLP next up!) and models (PyTorch, TensorFlow)
- Extended built-in support for explanation methods (captum, tf-explain and zennit)
If you find this toolkit or its companion paper Quantus: An Explainable AI Toolkit for Responsible Evaluation of Neural Network Explanations and Beyond interesting or useful in your research, use the following Bibtex annotation to cite us:
@article{hedstrom2023quantus,
author = {Anna Hedstr{\"{o}}m and Leander Weber and Daniel Krakowczyk and Dilyara Bareeva and Franz Motzkus and Wojciech Samek and Sebastian Lapuschkin and Marina Marina M.{-}C. H{\"{o}}hne},
title = {Quantus: An Explainable AI Toolkit for Responsible Evaluation of Neural Network Explanations and Beyond},
journal = {Journal of Machine Learning Research},
year = {2023},
volume = {24},
number = {34},
pages = {1--11},
url = {http://jmlr.org/papers/v24/22-0142.html}
}When applying the individual metrics of Quantus, please make sure to also properly cite the work of the original authors (as linked below).
A simple visual comparison of eXplainable Artificial Intelligence (XAI) methods is often not sufficient to decide which explanation method works best as shown exemplarily in Figure a) for four gradient-based methods — Saliency (Mørch et al., 1995; Baehrens et al., 2010), Integrated Gradients (Sundararajan et al., 2017), GradientShap (Lundberg and Lee, 2017) or FusionGrad (Bykov et al., 2021), yet it is a common practice for evaluation XAI methods in absence of ground truth data. Therefore, we developed Quantus, an easy-to-use yet comprehensive toolbox for quantitative evaluation of explanations — including 30+ different metrics.
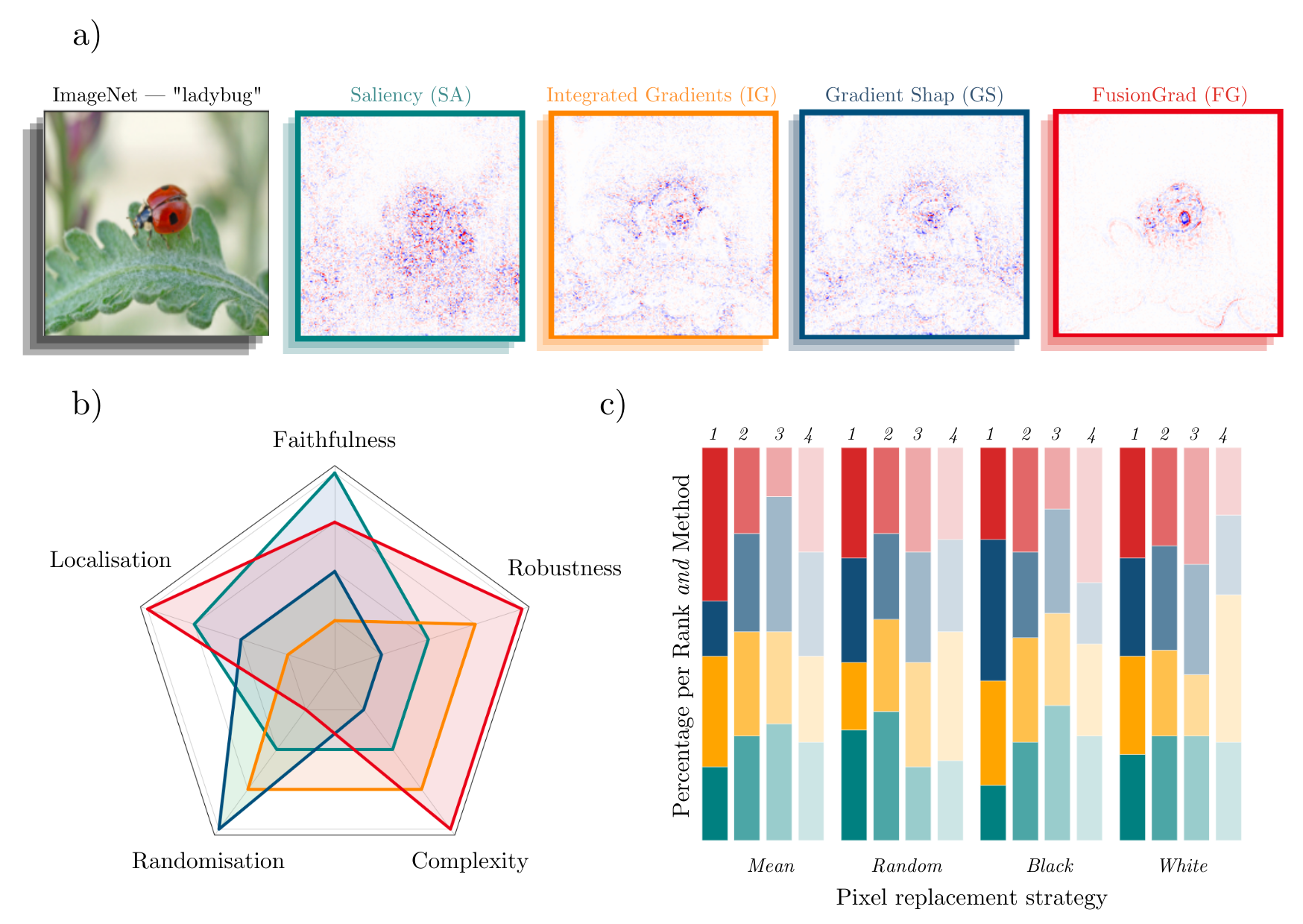
With Quantus, we can obtain richer insights on how the methods compare e.g., b) by holistic quantification on several evaluation criteria and c) by providing sensitivity analysis of how a single parameter e.g. the pixel replacement strategy of a faithfulness test influences the ranking of the XAI methods.
This project started with the goal of collecting existing evaluation metrics that have been introduced in the context of XAI research — to help automate the task of XAI quantification. Along the way of implementation, it became clear that XAI metrics most often belong to one out of six categories i.e., 1) faithfulness, 2) robustness, 3) localisation 4) complexity 5) randomisation (sensitivity) or 6) axiomatic metrics. The library contains implementations of the following evaluation metrics:
Faithfulness
quantifies to what extent explanations follow the predictive behaviour of the model (asserting that more important features play a larger role in model outcomes)- Faithfulness Correlation (Bhatt et al., 2020): iteratively replaces a random subset of given attributions with a baseline value and then measuring the correlation between the sum of this attribution subset and the difference in function output
- Faithfulness Estimate (Alvarez-Melis et al., 2018): computes the correlation between probability drops and attribution scores on various points
- Monotonicity Metric (Arya et al. 2019): starts from a reference baseline to then incrementally replace each feature in a sorted attribution vector, measuring the effect on model performance
- Monotonicity Metric (Nguyen et al, 2020): measures the spearman rank correlation between the absolute values of the attribution and the uncertainty in the probability estimation
- Pixel Flipping (Bach et al., 2015): captures the impact of perturbing pixels in descending order according to the attributed value on the classification score
- Region Perturbation (Samek et al., 2015): is an extension of Pixel-Flipping to flip an area rather than a single pixel
- Selectivity (Montavon et al., 2018): measures how quickly an evaluated prediction function starts to drop when removing features with the highest attributed values
- SensitivityN (Ancona et al., 2019): computes the correlation between the sum of the attributions and the variation in the target output while varying the fraction of the total number of features, averaged over several test samples
- IROF (Rieger at el., 2020): computes the area over the curve per class for sorted mean importances of feature segments (superpixels) as they are iteratively removed (and prediction scores are collected), averaged over several test samples
- Infidelity (Chih-Kuan, Yeh, et al., 2019): represents the expected mean square error between 1) a dot product of an attribution and input perturbation and 2) difference in model output after significant perturbation
- ROAD (Rong, Leemann, et al., 2022): measures the accuracy of the model on the test set in an iterative process of removing k most important pixels, at each step k most relevant pixels (MoRF order) are replaced with noisy linear imputations
- Sufficiency (Dasgupta et al., 2022): measures the extent to which similar explanations have the same prediction label
Robustness
measures to what extent explanations are stable when subject to slight perturbations of the input, assuming that model output approximately stayed the same- Local Lipschitz Estimate (Alvarez-Melis et al., 2018): tests the consistency in the explanation between adjacent examples
- Max-Sensitivity (Yeh et al., 2019): measures the maximum sensitivity of an explanation using a Monte Carlo sampling-based approximation
- Avg-Sensitivity (Yeh et al., 2019): measures the average sensitivity of an explanation using a Monte Carlo sampling-based approximation
- Continuity (Montavon et al., 2018): captures the strongest variation in explanation of an input and its perturbed version
- Consistency (Dasgupta et al., 2022): measures the probability that the inputs with the same explanation have the same prediction label
- Relative Input Stability (RIS) (Agarwal, et. al., 2022): measures the relative distance between explanations e_x and e_x' with respect to the distance between the two inputs x and x'
- Relative Representation Stability (RRS) (Agarwal, et. al., 2022): measures the relative distance between explanations e_x and e_x' with respect to the distance between internal models representations L_x and L_x' for x and x' respectively
- Relative Output Stability (ROS) (Agarwal, et. al., 2022): measures the relative distance between explanations e_x and e_x' with respect to the distance between output logits h(x) and h(x') for x and x' respectively
Localisation
tests if the explainable evidence is centred around a region of interest (RoI) which may be defined around an object by a bounding box, a segmentation mask or, a cell within a grid- Pointing Game (Zhang et al., 2018): checks whether attribution with the highest score is located within the targeted object
- Attribution Localization (Kohlbrenner et al., 2020): measures the ratio of positive attributions within the targeted object towards the total positive attributions
- Top-K Intersection (Theiner et al., 2021): computes the intersection between a ground truth mask and the binarized explanation at the top k feature locations
- Relevance Rank Accuracy (Arras et al., 2021): measures the ratio of highly attributed pixels within a ground-truth mask towards the size of the ground truth mask
- Relevance Mass Accuracy (Arras et al., 2021): measures the ratio of positively attributed attributions inside the ground-truth mask towards the overall positive attributions
- AUC (Fawcett et al., 2006): compares the ranking between attributions and a given ground-truth mask
- Focus (Arias et al., 2022): quantifies the precision of the explanation by creating mosaics of data instances from different classes
Complexity
captures to what extent explanations are concise i.e., that few features are used to explain a model prediction- Sparseness (Chalasani et al., 2020): uses the Gini Index for measuring, if only highly attributed features are truly predictive of the model output
- Complexity (Bhatt et al., 2020): computes the entropy of the fractional contribution of all features to the total magnitude of the attribution individually
- Effective Complexity (Nguyen at el., 2020): measures how many attributions in absolute values are exceeding a certain threshold
Randomisation (Sensitivity)
tests to what extent explanations deteriorate as inputs to the evaluation problem e.g., model parameters are increasingly randomised- MPRT (Model Parameter Randomisation Test) (Adebayo et. al., 2018): randomises the parameters of single model layers in a cascading or independent way and measures the distance of the respective explanation to the original explanation
- Smooth MPRT (Hedström et. al., 2023): adds a "denoising" preprocessing step to the original MPRT, where the explanations are averaged over N noisy samples before the similarity between the original- and fully random model's explanations is measured
- Efficient MPRT (Hedström et. al., 2023): reinterprets MPRT by evaluating the rise in explanation complexity (discrete entropy) before and after full model randomisation, asking for increased explanation complexity post-randomisation
- Random Logit Test (Sixt et al., 2020): computes for the distance between the original explanation and the explanation for a random other class
Axiomatic
assesses if explanations fulfil certain axiomatic properties- Completeness (Sundararajan et al., 2017): evaluates whether the sum of attributions is equal to the difference between the function values at the input x and baseline x' (and referred to as Summation to Delta (Shrikumar et al., 2017), Sensitivity-n (slight variation, Ancona et al., 2018) and Conservation (Montavon et al., 2018))
- Non-Sensitivity (Nguyen at el., 2020): measures whether the total attribution is proportional to the explainable evidence at the model output
- Input Invariance (Kindermans et al., 2017): adds a shift to input, asking that attributions should not change in response (assuming the model does not)
Additional metrics will be included in future releases. Please open an issue if you have a metric you believe should be apart of Quantus.
Disclaimers. It is worth noting that the implementations of the metrics in this library have not been verified by the original authors. Thus any metric implementation in this library may differ from the original authors. Further, bear in mind that evaluation metrics for XAI methods are often empirical interpretations (or translations) of qualities that some researcher(s) claimed were important for explanations to fulfil, so it may be a discrepancy between what the author claims to measure by the proposed metric and what is actually measured e.g., using entropy as an operationalisation of explanation complexity. Please read the user guidelines for further guidance on how to best use the library.
If you already have PyTorch or TensorFlow installed on your machine, the most light-weight version of Quantus can be obtained from PyPI as follows (no additional explainability functionality or deep learning framework will be included):
pip install quantus
Alternatively, you can simply add the desired deep learning framework (in brackets) to have the package installed together with Quantus. To install Quantus with PyTorch, please run:
pip install "quantus[torch]"
For TensorFlow, please run:
pip install "quantus[tensorflow]"
The package requirements are as follows:
python>=3.8.0
torch>=1.11.0
tensorflow>=2.5.0
Please note that the exact PyTorch and/ or TensorFlow versions
to be installed depends on your Python version (3.8-3.11) and platform (darwin, linux, …).
See [project.optional-dependencies] section in the pyproject.toml file.
The following will give a short introduction to how to get started with Quantus. Note that this example is based on the PyTorch framework, but we also support TensorFlow, which would differ only in the loading of the model, data and explanations. To get started with Quantus, you need:
- A model (
model), inputs (x_batch) and labels (y_batch) - Some explanations you want to evaluate (
a_batch)
Step 1. Load data and model
Let's first load the data and model. In this example, a pre-trained LeNet available from Quantus
for the purpose of this tutorial is loaded, but generally, you might use any Pytorch (or TensorFlow) model instead. To follow this example, one needs to have quantus and torch installed, by e.g., pip install 'quantus[torch]'.
import quantus
from quantus.helpers.model.models import LeNet
import torch
import torchvision
from torchvision import transforms
# Enable GPU.
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Load a pre-trained LeNet classification model (architecture at quantus/helpers/models).
model = LeNet()
if device.type == "cpu":
model.load_state_dict(torch.load("tests/assets/mnist", map_location=torch.device('cpu')))
else:
model.load_state_dict(torch.load("tests/assets/mnist"))
# Load datasets and make loaders.
test_set = torchvision.datasets.MNIST(root='./sample_data', download=True, transform=transforms.Compose([transforms.ToTensor()]))
test_loader = torch.utils.data.DataLoader(test_set, batch_size=24)
# Load a batch of inputs and outputs to use for XAI evaluation.
x_batch, y_batch = iter(test_loader).next()
x_batch, y_batch = x_batch.cpu().numpy(), y_batch.cpu().numpy()Step 2. Load explanations
We still need some explanations to evaluate. For this, there are two possibilities in Quantus. You can provide either:
- a set of re-computed attributions (
np.ndarray) - any arbitrary explanation function (
callable), e.g., the built-in methodquantus.explainor your own customised function
We show the different options below.
Quantus allows you to evaluate explanations that you have pre-computed,
assuming that they match the data you provide in x_batch. Let's say you have explanations
for Saliency and Integrated Gradients
already pre-computed.
In that case, you can simply load these into corresponding variables a_batch_saliency
and a_batch_intgrad:
a_batch_saliency = load("path/to/precomputed/saliency/explanations")
a_batch_intgrad = load("path/to/precomputed/intgrad/explanations")Another option is to simply obtain the attributions using one of many XAI frameworks out there, such as Captum, Zennit, tf.explain, or iNNvestigate. The following code example shows how to obtain explanations (Saliency and Integrated Gradients, to be specific) using Captum:
import captum
from captum.attr import Saliency, IntegratedGradients
# Generate Integrated Gradients attributions of the first batch of the test set.
a_batch_saliency = Saliency(model).attribute(inputs=x_batch, target=y_batch, abs=True).sum(axis=1).cpu().numpy()
a_batch_intgrad = IntegratedGradients(model).attribute(inputs=x_batch, target=y_batch, baselines=torch.zeros_like(x_batch)).sum(axis=1).cpu().numpy()
# Save x_batch and y_batch as numpy arrays that will be used to call metric instances.
x_batch, y_batch = x_batch.cpu().numpy(), y_batch.cpu().numpy()
# Quick assert.
assert [isinstance(obj, np.ndarray) for obj in [x_batch, y_batch, a_batch_saliency, a_batch_intgrad]]If you don't have a pre-computed set of explanations but rather want to pass an arbitrary explanation function that you wish to evaluate with Quantus, this option exists.
For this, you can for example rely on the built-in quantus.explain function to get started, which includes some popular explanation methods
(please run quantus.available_methods() to see which ones). Examples of how to use quantus.explain
or your own customised explanation function are included in the next section.

As seen in the above image, the qualitative aspects of explanations may look fairly uninterpretable --- since we lack ground truth of what the explanations should be looking like, it is hard to draw conclusions about the explainable evidence. To gather quantitative evidence for the quality of the different explanation methods, we can apply Quantus.
Step 3. Evaluate with Quantus
Quantus implements XAI evaluation metrics from different categories,
e.g., Faithfulness, Localisation and Robustness etc which all inherit from the base quantus.Metric class.
To apply a metric to your setting (e.g., Max-Sensitivity)
it first needs to be instantiated:
metric = quantus.MaxSensitivity(nr_samples=10,
lower_bound=0.2,
norm_numerator=quantus.fro_norm,
norm_denominator=quantus.fro_norm,
perturb_func=quantus.uniform_noise,
similarity_func=quantus.difference,
abs=True,
normalise=True)and then applied to your model, data, and (pre-computed) explanations:
scores = metric(
model=model,
x_batch=x_batch,
y_batch=y_batch,
a_batch=a_batch_saliency,
device=device,
explain_func=quantus.explain,
explain_func_kwargs={"method": "Saliency"},
)Since a re-computation of the explanations is necessary for robustness evaluation, in this example, we also pass an explanation function (explain_func) to the metric call. Here, we rely on the built-in quantus.explain function to recompute the explanations. The hyperparameters are set with the explain_func_kwargs dictionary. Please find more details on how to use quantus.explain at API documentation.
You can alternatively use your own customised explanation function
(assuming it returns an np.ndarray in a shape that matches the input x_batch). This is done as follows:
def your_own_callable(model, models, targets, **kwargs) -> np.ndarray
"""Logic goes here to compute the attributions and return an
explanation in the same shape as x_batch (np.array),
(flatten channels if necessary)."""
return explanation(model, x_batch, y_batch)
scores = metric(
model=model,
x_batch=x_batch,
y_batch=y_batch,
device=device,
explain_func=your_own_callable
)Quantus also provides high-level functionality to support large-scale evaluations,
e.g., multiple XAI methods, multifaceted evaluation through several metrics, or a combination thereof. To utilise quantus.evaluate(), you simply need to define two things:
-
The Metrics you would like to use for evaluation (each
__init__parameter configuration counts as its own metric):metrics = { "max-sensitivity-10": quantus.MaxSensitivity(nr_samples=10), "max-sensitivity-20": quantus.MaxSensitivity(nr_samples=20), "region-perturbation": quantus.RegionPerturbation(), }
-
The XAI methods you would like to evaluate, e.g., a
dictwith pre-computed attributions:xai_methods = { "Saliency": a_batch_saliency, "IntegratedGradients": a_batch_intgrad }
You can then simply run a large-scale evaluation as follows (this aggregates the result by np.mean averaging):
import numpy as np
results = quantus.evaluate(
metrics=metrics,
xai_methods=xai_methods,
agg_func=np.mean,
model=model,
x_batch=x_batch,
y_batch=y_batch,
**{"softmax": False,}
)Please see Getting started tutorial to run code similar to this example. For more information on how to customise metrics and extend Quantus' functionality, please see Getting started guide.
Further tutorials are available that showcase the many types of analysis that can be done using Quantus. For this purpose, please see notebooks in the tutorials folder which includes examples such as:
- All Metrics ImageNet Example: shows how to instantiate the different metrics for ImageNet dataset
- Metric Parameterisation Analysis: explores how sensitive a metric could be to its hyperparameters
- Robustness Analysis Model Training: measures robustness of explanations as model accuracy increases
- Full Quantification with Quantus: example of benchmarking explanation methods
- Tabular Data Example: example of how to use Quantus with tabular data
- Quantus and TensorFlow Data Example: showcases how to use Quantus with TensorFlow
... and more.
We welcome any sort of contribution to Quantus! For a detailed contribution guide, please refer to Contributing documentation first.
If you have any developer-related questions, please open an issue or write us at [email protected].
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Quantus
Similar Open Source Tools
Quantus
Quantus is a toolkit designed for the evaluation of neural network explanations. It offers more than 30 metrics in 6 categories for eXplainable Artificial Intelligence (XAI) evaluation. The toolkit supports different data types (image, time-series, tabular, NLP) and models (PyTorch, TensorFlow). It provides built-in support for explanation methods like captum, tf-explain, and zennit. Quantus is under active development and aims to provide a comprehensive set of quantitative evaluation metrics for XAI methods.

gepa
GEPA (Genetic-Pareto) is a framework for optimizing arbitrary systems composed of text components like AI prompts, code snippets, or textual specs against any evaluation metric. It employs LLMs to reflect on system behavior, using feedback from execution and evaluation traces to drive targeted improvements. Through iterative mutation, reflection, and Pareto-aware candidate selection, GEPA evolves robust, high-performing variants with minimal evaluations, co-evolving multiple components in modular systems for domain-specific gains. The repository provides the official implementation of the GEPA algorithm as proposed in the paper titled 'GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning'.

llm-reasoners
LLM Reasoners is a library that enables LLMs to conduct complex reasoning, with advanced reasoning algorithms. It approaches multi-step reasoning as planning and searches for the optimal reasoning chain, which achieves the best balance of exploration vs exploitation with the idea of "World Model" and "Reward". Given any reasoning problem, simply define the reward function and an optional world model (explained below), and let LLM reasoners take care of the rest, including Reasoning Algorithms, Visualization, LLM calling, and more!

zshot
Zshot is a highly customizable framework for performing Zero and Few shot named entity and relationships recognition. It can be used for mentions extraction, wikification, zero and few shot named entity recognition, zero and few shot named relationship recognition, and visualization of zero-shot NER and RE extraction. The framework consists of two main components: the mentions extractor and the linker. There are multiple mentions extractors and linkers available, each serving a specific purpose. Zshot also includes a relations extractor and a knowledge extractor for extracting relations among entities and performing entity classification. The tool requires Python 3.6+ and dependencies like spacy, torch, transformers, evaluate, and datasets for evaluation over datasets like OntoNotes. Optional dependencies include flair and blink for additional functionalities. Zshot provides examples, tutorials, and evaluation methods to assess the performance of the components.

llms
The 'llms' repository is a comprehensive guide on Large Language Models (LLMs), covering topics such as language modeling, applications of LLMs, statistical language modeling, neural language models, conditional language models, evaluation methods, transformer-based language models, practical LLMs like GPT and BERT, prompt engineering, fine-tuning LLMs, retrieval augmented generation, AI agents, and LLMs for computer vision. The repository provides detailed explanations, examples, and tools for working with LLMs.

fuse-med-ml
FuseMedML is a Python framework designed to accelerate machine learning-based discovery in the medical field by promoting code reuse. It provides a flexible design concept where data is stored in a nested dictionary, allowing easy handling of multi-modality information. The framework includes components for creating custom models, loss functions, metrics, and data processing operators. Additionally, FuseMedML offers 'batteries included' key components such as fuse.data for data processing, fuse.eval for model evaluation, and fuse.dl for reusable deep learning components. It supports PyTorch and PyTorch Lightning libraries and encourages the creation of domain extensions for specific medical domains.

MME-RealWorld
MME-RealWorld is a benchmark designed to address real-world applications with practical relevance, featuring 13,366 high-resolution images and 29,429 annotations across 43 tasks. It aims to provide substantial recognition challenges and overcome common barriers in existing Multimodal Large Language Model benchmarks, such as small data scale, restricted data quality, and insufficient task difficulty. The dataset offers advantages in data scale, data quality, task difficulty, and real-world utility compared to existing benchmarks. It also includes a Chinese version with additional images and QA pairs focused on Chinese scenarios.

SheetCopilot
SheetCopilot is an assistant agent that manipulates spreadsheets by following user commands. It leverages Large Language Models (LLMs) to interact with spreadsheets like a human expert, enabling non-expert users to complete tasks on complex software such as Google Sheets and Excel via a language interface. The tool observes spreadsheet states, polishes generated solutions based on external action documents and error feedback, and aims to improve success rate and efficiency. SheetCopilot offers a dataset with diverse task categories and operations, supporting operations like entry & manipulation, management, formatting, charts, and pivot tables. Users can interact with SheetCopilot in Excel or Google Sheets, executing tasks like calculating revenue, creating pivot tables, and plotting charts. The tool's evaluation includes performance comparisons with leading LLMs and VBA-based methods on specific datasets, showcasing its capabilities in controlling various aspects of a spreadsheet.

xFinder
xFinder is a model specifically designed for key answer extraction from large language models (LLMs). It addresses the challenges of unreliable evaluation methods by optimizing the key answer extraction module. The model achieves high accuracy and robustness compared to existing frameworks, enhancing the reliability of LLM evaluation. It includes a specialized dataset, the Key Answer Finder (KAF) dataset, for effective training and evaluation. xFinder is suitable for researchers and developers working with LLMs to improve answer extraction accuracy.

RLHF-Reward-Modeling
This repository contains code for training reward models for Deep Reinforcement Learning-based Reward-modulated Hierarchical Fine-tuning (DRL-based RLHF), Iterative Selection Fine-tuning (Rejection sampling fine-tuning), and iterative Decision Policy Optimization (DPO). The reward models are trained using a Bradley-Terry model based on the Gemma and Mistral language models. The resulting reward models achieve state-of-the-art performance on the RewardBench leaderboard for reward models with base models of up to 13B parameters.

k2
K2 (GeoLLaMA) is a large language model for geoscience, trained on geoscience literature and fine-tuned with knowledge-intensive instruction data. It outperforms baseline models on objective and subjective tasks. The repository provides K2 weights, core data of GeoSignal, GeoBench benchmark, and code for further pretraining and instruction tuning. The model is available on Hugging Face for use. The project aims to create larger and more powerful geoscience language models in the future.

LongBench
LongBench v2 is a benchmark designed to assess the ability of large language models (LLMs) to handle long-context problems requiring deep understanding and reasoning across various real-world multitasks. It consists of 503 challenging multiple-choice questions with contexts ranging from 8k to 2M words, covering six major task categories. The dataset is collected from nearly 100 highly educated individuals with diverse professional backgrounds and is designed to be challenging even for human experts. The evaluation results highlight the importance of enhanced reasoning ability and scaling inference-time compute to tackle the long-context challenges in LongBench v2.

Trace
Trace is a new AutoDiff-like tool for training AI systems end-to-end with general feedback. It generalizes the back-propagation algorithm by capturing and propagating an AI system's execution trace. Implemented as a PyTorch-like Python library, users can write Python code directly and use Trace primitives to optimize certain parts, similar to training neural networks.

BambooAI
BambooAI is a lightweight library utilizing Large Language Models (LLMs) to provide natural language interaction capabilities, much like a research and data analysis assistant enabling conversation with your data. You can either provide your own data sets, or allow the library to locate and fetch data for you. It supports Internet searches and external API interactions.

LLMeBench
LLMeBench is a flexible framework designed for accelerating benchmarking of Large Language Models (LLMs) in the field of Natural Language Processing (NLP). It supports evaluation of various NLP tasks using model providers like OpenAI, HuggingFace Inference API, and Petals. The framework is customizable for different NLP tasks, LLM models, and datasets across multiple languages. It features extensive caching capabilities, supports zero- and few-shot learning paradigms, and allows on-the-fly dataset download and caching. LLMeBench is open-source and continuously expanding to support new models accessible through APIs.

kafka-ml
Kafka-ML is a framework designed to manage the pipeline of Tensorflow/Keras and PyTorch machine learning models on Kubernetes. It enables the design, training, and inference of ML models with datasets fed through Apache Kafka, connecting them directly to data streams like those from IoT devices. The Web UI allows easy definition of ML models without external libraries, catering to both experts and non-experts in ML/AI.
For similar tasks
Quantus
Quantus is a toolkit designed for the evaluation of neural network explanations. It offers more than 30 metrics in 6 categories for eXplainable Artificial Intelligence (XAI) evaluation. The toolkit supports different data types (image, time-series, tabular, NLP) and models (PyTorch, TensorFlow). It provides built-in support for explanation methods like captum, tf-explain, and zennit. Quantus is under active development and aims to provide a comprehensive set of quantitative evaluation metrics for XAI methods.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.