
only_train_once
OTOv1-v3, NeurIPS, ICLR, TMLR, DNN Training, Compression, Structured Pruning, Erasing Operators, CNN, Diffusion, LLM
Stars: 261

Only Train Once (OTO) is an automatic, architecture-agnostic DNN training and compression framework that allows users to train a general DNN from scratch or a pretrained checkpoint to achieve high performance and slimmer architecture simultaneously in a one-shot manner without fine-tuning. The framework includes features for automatic structured pruning and erasing operators, as well as hybrid structured sparse optimizers for efficient model compression. OTO provides tools for pruning zero-invariant group partitioning, constructing pruned models, and visualizing pruning and erasing dependency graphs. It supports the HESSO optimizer and offers a sanity check for compliance testing on various DNNs. The repository also includes publications, installation instructions, quick start guides, and a roadmap for future enhancements and collaborations.
README:
This repository is the (deprecated) Pytorch implementation of Only-Train-Once (OTO). OTO is an $\color{LimeGreen}{\textbf{automatic}}$, $\color{LightCoral}{\textbf{architecture}}$ $\color{LightCoral}{\textbf{agnostic}}$ DNN $\color{Orange}{\textbf{training}}$ and $\color{Violet}{\textbf{compression}}$ (via $\color{CornflowerBlue}{\textbf{structure pruning}}$ and $\color{DarkGoldenRod}{\textbf{erasing}}$ operators) framework. By OTO, users could train a general DNN either from scratch or a pretrained checkpoint to achieve both high performance and slimmer architecture simultaneously in the one-shot manner (without fine-tuning).
Please find our series of works and bibtexs for kind citations.
- OTOv3: Automatic Architecture-Agnostic Neural Network Training and Compression from Structured Pruning to Erasing Operators preprint.
- LoRAShear: Efficient Large Language Model Structured Pruning and Knowledge Recovery preprint.
- An Adaptive Half-Space Projection Method for Stochastic Optimization Problems with Group Sparse Regularization in TMLR 2023.
- OTOv2: Automatic, Generic, User-Friendly in ICLR 2023.
- Only Train Once (OTO): A One-Shot Neural Network Training And Pruning Framework in NeurIPS 2021.
In addition, we recommend our following efficient ML works.
- DREAM: Diffusion Rectification and Estimation-Adaptive Models, efficient diffusion training, in CVPR 2024.
- DISTILLM: Towards Streamlined Distillation for Large Language Models, LLM distillation, in ICML 2024.
We recommend to run the framework under pytorch>=2.0. Use pip or git clone to install.
pip install only_train_onceor
git clone https://github.com/tianyic/only_train_once.gitWe provide an example of OTO framework usage. More explained details can be found in tutorials.
import torch
from sanity_check.backends import densenet121
from only_train_once import OTO
# Create OTO instance
model = densenet121()
dummy_input = torch.zeros(1, 3, 32, 32)
oto = OTO(model=model.cuda(), dummy_input=dummy_input.cuda())
# Create HESSO optimizer
optimizer = oto.hesso(variant='sgd', lr=0.1, target_group_sparsity=0.7)
# Train the DNN as normal via HESSO
model.train()
model.cuda()
criterion = torch.nn.CrossEntropyLoss()
for epoch in range(max_epoch):
f_avg_val = 0.0
for X, y in trainloader:
X, y = X.cuda(), y.cuda()
y_pred = model.forward(X)
f = criterion(y_pred, y)
optimizer.zero_grad()
f.backward()
optimizer.step()
# A compressed densenet will be generated.
oto.construct_subnet(out_dir='./')-
Pruning Zero-Invariant Group Partition. OTO at first automatically figures out the dependancy inside the target DNN to build a pruning dependency graph. Then OTO partitions DNN's trainable variables into so-called Pruning Zero-Invariant Groups (PZIGs). PZIG describes a class of pruning minimally removal structure of DNN, or can be largely interpreted as the minimal group of variables that must be pruned together.

-
Hybrid Structured Sparse Optimizer. A structured sparsity optimization problem is formulated. A hybrid structured sparse optimizer, including HESSO, DHSPG, LSHPG, is then employed to find out which PZIGs are redundant, and which PZIGs are important for the model prediction. The selected hybrid optimizer explores group sparsity more reliably and typically achieves higher generalization performance than other sparse optimizers.

-
Construct pruned model. The structures corresponding to redundant PZIGs (being zero) are removed to form the pruned model. Due to the property of PZIGs, the pruned model returns the exact same output as the full model. Therefore, no further fine-tuning is required.

The sanity check provides the tests for pruning mode in OTO onto various DNNs from CNN to LLM. The pass of sanity check indicates the compliance of OTO onto target DNN.
python sanity_check/sanity_check.py
Note that some tests require additional dependency. Comment off unnecessary tests. We highly recommend to proceed a sanity check over a new customized DNN for testing compliance.
The visual_examples provides the visualization of pruning dependency graphs and erasing dependency graphs. Visualization serves as a frequently used tool for employing OTO onto new unseen DNNs if meets errors.
-
Add more explanations into the current repository.
-
Release a technical report regarding the HESSO optimizer which is not discussed yet in our papers.
-
Release refactorized DHSPG and LHSPG.
-
Release the full pipeline of LoRAShear (upon business administration).
-
Provide more tutorials to cover the experiments in the pruning mode. Main experiments in OTOv2 can be found at otov2_branch.
-
Release official erasing mode after the review process of OTOv3.
-
Provide documentations of the OTO API.
We would greatly appreciate the contributions in any form, such as bug fixes, new features and new tutorials, from our open-source community.
We are humble to provide benefits for the AI community. We look forward to working with the community together to make DNN's training and compression to be more automatic and convinient.
We are open and happy for collabrations. Feel free to reach out [email protected] if have any interesting idea.
The previous OTOv2 repo has been moved into legacy_branch for academic replication.
If you find the repo useful, please kindly star this repository and cite our papers:
For OTOv3 preprint
@article{chen2023otov3,
title={OTOv3: Automatic Architecture-Agnostic Neural Network Training and Compression from Structured Pruning to Erasing Operators},
author={Chen, Tianyi and Ding, Tianyu and Zhu, Zhihui and Chen, Zeyu and Wu, HsiangTao and Zharkov, Ilya and Liang, Luming},
journal={arXiv preprint arXiv:2312.09411},
year={2023}
}
For LoRAShear preprint
@article{chen2023lorashear,
title={LoRAShear: Efficient Large Language Model Structured Pruning and Knowledge Recovery},
author={Chen, Tianyi and Ding, Tianyu and Yadav, Badal and Zharkov, Ilya and Liang, Luming},
journal={arXiv preprint arXiv:2310.18356},
year={2023}
}
For AdaHSPG+ publication in TMLR (theoretical optimization paper)
@article{dai2023adahspg,
title={An adaptive half-space projection method for stochastic optimization problems with group sparse regularization},
author={Dai, Yutong and Chen, Tianyi and Wang, Guanyi and Robinson, Daniel P},
journal={Transactions on machine learning research},
year={2023}
}
For OTOv2 publication in ICLR 2023
@inproceedings{chen2023otov2,
title={OTOv2: Automatic, Generic, User-Friendly},
author={Chen, Tianyi and Liang, Luming and Tianyu, DING and Zhu, Zhihui and Zharkov, Ilya},
booktitle={International Conference on Learning Representations},
year={2023}
}
For OTOv1 publication in NeurIPS 2021
@inproceedings{chen2021otov1,
title={Only Train Once: A One-Shot Neural Network Training And Pruning Framework},
author={Chen, Tianyi and Ji, Bo and Tianyu, DING and Fang, Biyi and Wang, Guanyi and Zhu, Zhihui and Liang, Luming and Shi, Yixin and Yi, Sheng and Tu, Xiao},
booktitle={Thirty-Fifth Conference on Neural Information Processing Systems},
year={2021}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for only_train_once
Similar Open Source Tools
only_train_once
Only Train Once (OTO) is an automatic, architecture-agnostic DNN training and compression framework that allows users to train a general DNN from scratch or a pretrained checkpoint to achieve high performance and slimmer architecture simultaneously in a one-shot manner without fine-tuning. The framework includes features for automatic structured pruning and erasing operators, as well as hybrid structured sparse optimizers for efficient model compression. OTO provides tools for pruning zero-invariant group partitioning, constructing pruned models, and visualizing pruning and erasing dependency graphs. It supports the HESSO optimizer and offers a sanity check for compliance testing on various DNNs. The repository also includes publications, installation instructions, quick start guides, and a roadmap for future enhancements and collaborations.
uccl
UCCL is a command-line utility tool designed to simplify the process of converting Unix-style file paths to Windows-style file paths and vice versa. It provides a convenient way for developers and system administrators to handle file path conversions without the need for manual adjustments. With UCCL, users can easily convert file paths between different operating systems, making it a valuable tool for cross-platform development and file management tasks.

pytorch-forecasting
PyTorch Forecasting is a PyTorch-based package for time series forecasting with state-of-the-art network architectures. It offers a high-level API for training networks on pandas data frames and utilizes PyTorch Lightning for scalable training on GPUs and CPUs. The package aims to simplify time series forecasting with neural networks by providing a flexible API for professionals and default settings for beginners. It includes a timeseries dataset class, base model class, multiple neural network architectures, multi-horizon timeseries metrics, and hyperparameter tuning with optuna. PyTorch Forecasting is built on pytorch-lightning for easy training on various hardware configurations.

pytorch-forecasting
PyTorch Forecasting is a PyTorch-based package designed for state-of-the-art timeseries forecasting using deep learning architectures. It offers a high-level API and leverages PyTorch Lightning for efficient training on GPU or CPU with automatic logging. The package aims to simplify timeseries forecasting tasks by providing a flexible API for professionals and user-friendly defaults for beginners. It includes features such as a timeseries dataset class for handling data transformations, missing values, and subsampling, various neural network architectures optimized for real-world deployment, multi-horizon timeseries metrics, and hyperparameter tuning with optuna. Built on pytorch-lightning, it supports training on CPUs, single GPUs, and multiple GPUs out-of-the-box.

Macaw-LLM
Macaw-LLM is a pioneering multi-modal language modeling tool that seamlessly integrates image, audio, video, and text data. It builds upon CLIP, Whisper, and LLaMA models to process and analyze multi-modal information effectively. The tool boasts features like simple and fast alignment, one-stage instruction fine-tuning, and a new multi-modal instruction dataset. It enables users to align multi-modal features efficiently, encode instructions, and generate responses across different data types.
InsPLAD
InsPLAD is a dataset and benchmark for power line asset inspection in UAV images. It contains 10,607 high-resolution UAV color images of seventeen unique power line assets with six defects. The dataset is used for object detection, defect classification, and anomaly detection tasks in computer vision. InsPLAD offers challenges like multi-scale objects, intra-class variation, cluttered background, and varied lighting conditions, aiming to improve state-of-the-art methods in the field.

FuseAI
FuseAI is a repository that focuses on knowledge fusion of large language models. It includes FuseChat, a state-of-the-art 7B LLM on MT-Bench, and FuseLLM, which surpasses Llama-2-7B by fusing three open-source foundation LLMs. The repository provides tech reports, releases, and datasets for FuseChat and FuseLLM, showcasing their performance and advancements in the field of chat models and large language models.
ProLLM
ProLLM is a framework that leverages Large Language Models to interpret and analyze protein sequences and interactions through natural language processing. It introduces the Protein Chain of Thought (ProCoT) method to transform complex protein interaction data into intuitive prompts, enhancing predictive accuracy by incorporating protein-specific embeddings and fine-tuning on domain-specific datasets.

lightllm
LightLLM is a Python-based LLM (Large Language Model) inference and serving framework known for its lightweight design, scalability, and high-speed performance. It offers features like tri-process asynchronous collaboration, Nopad for efficient attention operations, dynamic batch scheduling, FlashAttention integration, tensor parallelism, Token Attention for zero memory waste, and Int8KV Cache. The tool supports various models like BLOOM, LLaMA, StarCoder, Qwen-7b, ChatGLM2-6b, Baichuan-7b, Baichuan2-7b, Baichuan2-13b, InternLM-7b, Yi-34b, Qwen-VL, Llava-7b, Mixtral, Stablelm, and MiniCPM. Users can deploy and query models using the provided server launch commands and interact with multimodal models like QWen-VL and Llava using specific queries and images.
aitviewer
A set of tools to visualize and interact with sequences of 3D data with cross-platform support on Windows, Linux, and macOS. It provides a native Python interface for loading and displaying SMPL[-H/-X], MANO, FLAME, STAR, and SUPR sequences in an interactive viewer. Users can render 3D data on top of images, edit SMPL sequences and poses, export screenshots and videos, and utilize a high-performance ModernGL-based rendering pipeline. The tool is designed for easy use and hacking, with features like headless mode, remote mode, animatable camera paths, and a built-in extensible GUI.

slideflow
Slideflow is a deep learning library for digital pathology, offering a user-friendly interface for model development. It is designed for medical researchers and AI enthusiasts, providing an accessible platform for developing state-of-the-art pathology models. Slideflow offers customizable training pipelines, robust slide processing and stain normalization toolkit, support for weakly-supervised or strongly-supervised labels, built-in foundation models, multiple-instance learning, self-supervised learning, generative adversarial networks, explainability tools, layer activation analysis tools, uncertainty quantification, interactive user interface for model deployment, and more. It supports both PyTorch and Tensorflow, with optional support for Libvips for slide reading. Slideflow can be installed via pip, Docker container, or from source, and includes non-commercial add-ons for additional tools and pretrained models. It allows users to create projects, extract tiles from slides, train models, and provides evaluation tools like heatmaps and mosaic maps.

SeerAttention
SeerAttention is a novel trainable sparse attention mechanism that learns intrinsic sparsity patterns directly from LLMs through self-distillation at post-training time. It achieves faster inference while maintaining accuracy for long-context prefilling. The tool offers features such as trainable sparse attention, block-level sparsity, self-distillation, efficient kernel, and easy integration with existing transformer architectures. Users can quickly start using SeerAttention for inference with AttnGate Adapter and training attention gates with self-distillation. The tool provides efficient evaluation methods and encourages contributions from the community.
chembench
ChemBench is a project aimed at expanding chemistry benchmark tasks in a BIG-bench compatible way, providing a pipeline to benchmark frontier and open models. It enables benchmarking across a wide range of API-based models and employs an LLM-based extractor as a fallback mechanism. Users can evaluate models on specific chemistry topics and run comprehensive evaluations across all topics in the benchmark suite. The tool facilitates seamless benchmarking for any model supported by LiteLLM and allows running non-API hosted models.

Quantus
Quantus is a toolkit designed for the evaluation of neural network explanations. It offers more than 30 metrics in 6 categories for eXplainable Artificial Intelligence (XAI) evaluation. The toolkit supports different data types (image, time-series, tabular, NLP) and models (PyTorch, TensorFlow). It provides built-in support for explanation methods like captum, tf-explain, and zennit. Quantus is under active development and aims to provide a comprehensive set of quantitative evaluation metrics for XAI methods.

catalyst
Catalyst is a C# Natural Language Processing library designed for speed, inspired by spaCy's design. It provides pre-trained models, support for training word and document embeddings, and flexible entity recognition models. The library is fast, modern, and pure-C#, supporting .NET standard 2.0. It is cross-platform, running on Windows, Linux, macOS, and ARM. Catalyst offers non-destructive tokenization, named entity recognition, part-of-speech tagging, language detection, and efficient binary serialization. It includes pre-built models for language packages and lemmatization. Users can store and load models using streams. Getting started with Catalyst involves installing its NuGet Package and setting the storage to use the online repository. The library supports lazy loading of models from disk or online. Users can take advantage of C# lazy evaluation and native multi-threading support to process documents in parallel. Training a new FastText word2vec embedding model is straightforward, and Catalyst also provides algorithms for fast embedding search and dimensionality reduction.
FATE-LLM
FATE-LLM is a framework supporting federated learning for large and small language models. It promotes training efficiency of federated LLMs using Parameter-Efficient methods, protects the IP of LLMs using FedIPR, and ensures data privacy during training and inference through privacy-preserving mechanisms.
For similar tasks
only_train_once
Only Train Once (OTO) is an automatic, architecture-agnostic DNN training and compression framework that allows users to train a general DNN from scratch or a pretrained checkpoint to achieve high performance and slimmer architecture simultaneously in a one-shot manner without fine-tuning. The framework includes features for automatic structured pruning and erasing operators, as well as hybrid structured sparse optimizers for efficient model compression. OTO provides tools for pruning zero-invariant group partitioning, constructing pruned models, and visualizing pruning and erasing dependency graphs. It supports the HESSO optimizer and offers a sanity check for compliance testing on various DNNs. The repository also includes publications, installation instructions, quick start guides, and a roadmap for future enhancements and collaborations.

ChaKt-KMP
ChaKt is a multiplatform app built using Kotlin and Compose Multiplatform to demonstrate the use of Generative AI SDK for Kotlin Multiplatform to generate content using Google's Generative AI models. It features a simple chat based user interface and experience to interact with AI. The app supports mobile, desktop, and web platforms, and is built with Kotlin Multiplatform, Kotlin Coroutines, Compose Multiplatform, Generative AI SDK, Calf - File picker, and BuildKonfig. Users can contribute to the project by following the guidelines in CONTRIBUTING.md. The app is licensed under the MIT License.

crawl4ai
Crawl4AI is a powerful and free web crawling service that extracts valuable data from websites and provides LLM-friendly output formats. It supports crawling multiple URLs simultaneously, replaces media tags with ALT, and is completely free to use and open-source. Users can integrate Crawl4AI into Python projects as a library or run it as a standalone local server. The tool allows users to crawl and extract data from specified URLs using different providers and models, with options to include raw HTML content, force fresh crawls, and extract meaningful text blocks. Configuration settings can be adjusted in the `crawler/config.py` file to customize providers, API keys, chunk processing, and word thresholds. Contributions to Crawl4AI are welcome from the open-source community to enhance its value for AI enthusiasts and developers.
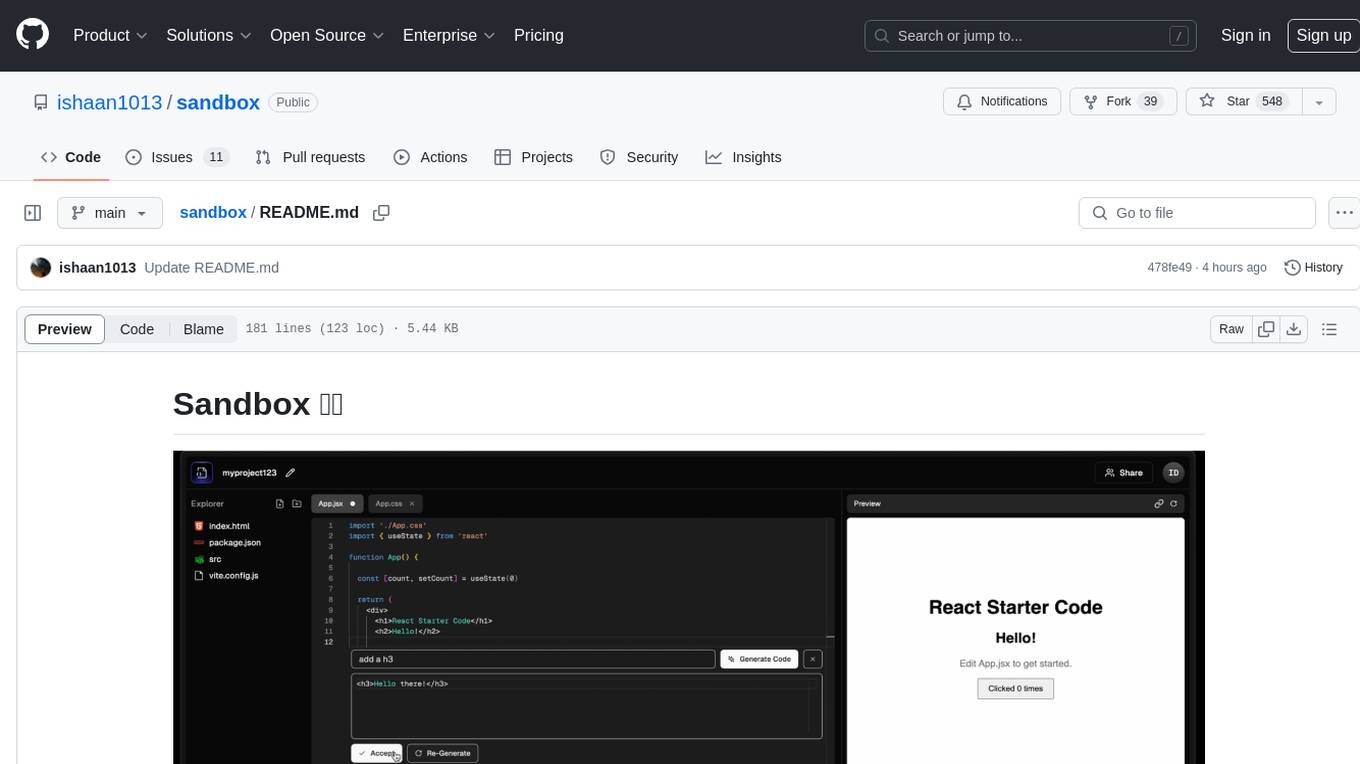
sandbox
Sandbox is an open-source cloud-based code editing environment with custom AI code autocompletion and real-time collaboration. It consists of a frontend built with Next.js, TailwindCSS, Shadcn UI, Clerk, Monaco, and Liveblocks, and a backend with Express, Socket.io, Cloudflare Workers, D1 database, R2 storage, Workers AI, and Drizzle ORM. The backend includes microservices for database, storage, and AI functionalities. Users can run the project locally by setting up environment variables and deploying the containers. Contributions are welcome following the commit convention and structure provided in the repository.
void
Void is an open-source Cursor alternative, providing a full source code for users to build and develop. It is a fork of the vscode repository, offering a waitlist for the official release. Users can contribute by checking the Project board and following the guidelines in CONTRIBUTING.md. Support is available through Discord or email.

aphrodite-engine
Aphrodite is an inference engine optimized for serving HuggingFace-compatible models at scale. It leverages vLLM's Paged Attention technology to deliver high-performance model inference for multiple concurrent users. The engine supports continuous batching, efficient key/value management, optimized CUDA kernels, quantization support, distributed inference, and modern samplers. It can be easily installed and launched, with Docker support for deployment. Aphrodite requires Linux or Windows OS, Python 3.8 to 3.12, and CUDA >= 11. It is designed to utilize 90% of GPU VRAM but offers options to limit memory usage. Contributors are welcome to enhance the engine.
cua
Cua is a tool for creating and running high-performance macOS and Linux virtual machines on Apple Silicon, with built-in support for AI agents. It provides libraries like Lume for running VMs with near-native performance, Computer for interacting with sandboxes, and Agent for running agentic workflows. Users can refer to the documentation for onboarding, explore demos showcasing AI-Gradio and GitHub issue fixing, and utilize accessory libraries like Core, PyLume, Computer Server, and SOM. Contributions are welcome, and the tool is open-sourced under the MIT License.
GeneratedOnBoardings
GeneratedOnBoardings is a repository containing automatically generated onboarding diagrams for over 800+ Python projects using CodeBoarding, an open-source tool for creating interactive visual documentation. The tool helps developers explore unfamiliar codebases through visual documentation, making it easier to understand and contribute to open-source projects. Users can provide feedback to improve the tool, and can also generate onboarding diagrams for their own projects by running CodeBoarding locally or trying the online demo at CodeBoarding.org/demo.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.