
InsPLAD
Inspection of Power Line Assets Dataset (InsPLAD)
Stars: 77
InsPLAD is a dataset and benchmark for power line asset inspection in UAV images. It contains 10,607 high-resolution UAV color images of seventeen unique power line assets with six defects. The dataset is used for object detection, defect classification, and anomaly detection tasks in computer vision. InsPLAD offers challenges like multi-scale objects, intra-class variation, cluttered background, and varied lighting conditions, aiming to improve state-of-the-art methods in the field.
README:
This repository stores InsPLAD, a dataset introduced in "InsPLAD: A Dataset and Benchmark for Power Line Asset Inspection in UAV Images" IJRS | arXiv. InsPLAD is also used in "Attention Modules Improve Image-Level Anomaly Detection for Industrial Inspection: A DifferNet Case Study" WACV2024 CVF | arXiv.
Power line maintenance and inspection are essential to avoid power supply interruptions, reducing its high social and financial impacts yearly. Automating power line visual inspections remains a relevant open problem for the industry due to the lack of public real-world datasets of power line components and their various defects to foster new research. This paper introduces InsPLAD, a Power Line Asset Inspection Dataset and Benchmark containing 10,607 high-resolution Unmanned Aerial Vehicles colour images. The dataset contains seventeen unique power line assets captured from real-world operating power lines. Additionally, five of those assets present six defects: four of which are corrosion, one is a broken component, and one is a bird's nest presence. All assets were labelled according to their condition, whether normal or the defect name found on an image level. We thoroughly evaluate state-of-the-art and popular methods for three image-level computer vision tasks covered by InsPLAD: object detection, through the AP metric; defect classification, through Balanced Accuracy; and anomaly detection, through the AUROC metric. InsPLAD offers various vision challenges from uncontrolled environments, such as multi-scale objects, multi-size class instances, multiple objects per image, intra-class variation, cluttered background, distinct point-of-views, perspective distortion, occlusion, and varied lighting conditions. To the best of our knowledge, InsPLAD is the first large real-world dataset and benchmark for power line asset inspection with multiple components and defects for various computer vision tasks, with a potential impact to improve state-of-the-art methods in the field. It will be publicly available in its integrity on a repository with a thorough description.
You can download the dataset here (Google Drive). Labels, when applicable, are in the zip files.
Three datasets in one. In the link above, you will find three zip files:
-
InsPLAD-det.zipis an Object Detection dataset for Asset detection - InsPLAD-fault folder:
-
supervised_fault_classification.zipis an Image Classification dataset for Fault Classification of the Assets -
unsupervised_anomaly_detection.zipis an Unsupervised Anomaly Detection dataset also for Fault Classification of the Assets
-
Here is a straightforward workflow that can be applied when using InsPLAD:

The black boxes indicate the function of each sub-dataset in the Power line domain and which Computer Vision task (in parentheses) should be used for each sub-dataset.
- Object Detection dataset
- 17 classes (assets categories)
- 10,607 total images
- 28,933 total instances
- Other properties:

Different bounding box colors mean different classes (not normal/defective objects)

InsPLAD-fault is generated from InsPLAD-det. The annotated objects are cropped and classified into normal/defective.

- Image Classification dataset
- Five assets, 2 to 3 classes each (defect types, e.g., corrosion)
- Other properties in the table above
- Anomaly Detection dataset
- Five assets, 2 classes each (normal or anomalous)
- Other properties in the table above
Normal on top (green frame), and defective at the bottom (red frame)

We started a new annotation project for Instance Segmentation (it will be the 4th CV task) here: https://universe.roboflow.com/andreluizbvs/insplad-seg When it is finished we will update this repo.
If you use InsPLAD in your research, please cite it:
@article{doi:10.1080/01431161.2023.2283900,
author = {André Luiz Buarque Vieira e Silva, Heitor de Castro Felix, Franscisco Paulo Magalhães Simões, Veronica Teichrieb, Michel dos Santos, Hemir Santiago, Virginia Sgotti and Henrique Lott Neto},
title = {InsPLAD: A Dataset and Benchmark for Power Line Asset Inspection in UAV Images},
journal = {International Journal of Remote Sensing},
volume = {44},
number = {23},
pages = {1-27},
year = {2023},
publisher = {Taylor & Francis},
doi = {10.1080/01431161.2023.2283900},
URL = {https://doi.org/10.1080/01431161.2023.2283900},
eprint = {https://doi.org/10.1080/01431161.2023.2283900},
}
@InProceedings{Vieira_2024_WACV,
author = {e Silva, Andr\'e Luiz Vieira and Sim\~oes, Francisco and Kowerko, Danny and Schlosser, Tobias and Battisti, Felipe and Teichrieb, Veronica},
title = {Attention Modules Improve Image-Level Anomaly Detection for Industrial Inspection: A DifferNet Case Study},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
month = {January},
year = {2024},
pages = {8246-8255}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for InsPLAD
Similar Open Source Tools
InsPLAD
InsPLAD is a dataset and benchmark for power line asset inspection in UAV images. It contains 10,607 high-resolution UAV color images of seventeen unique power line assets with six defects. The dataset is used for object detection, defect classification, and anomaly detection tasks in computer vision. InsPLAD offers challenges like multi-scale objects, intra-class variation, cluttered background, and varied lighting conditions, aiming to improve state-of-the-art methods in the field.

fuse-med-ml
FuseMedML is a Python framework designed to accelerate machine learning-based discovery in the medical field by promoting code reuse. It provides a flexible design concept where data is stored in a nested dictionary, allowing easy handling of multi-modality information. The framework includes components for creating custom models, loss functions, metrics, and data processing operators. Additionally, FuseMedML offers 'batteries included' key components such as fuse.data for data processing, fuse.eval for model evaluation, and fuse.dl for reusable deep learning components. It supports PyTorch and PyTorch Lightning libraries and encourages the creation of domain extensions for specific medical domains.

aitlas
The AiTLAS toolbox (Artificial Intelligence Toolbox for Earth Observation) includes state-of-the-art machine learning methods for exploratory and predictive analysis of satellite imagery as well as a repository of AI-ready Earth Observation (EO) datasets. It can be easily applied for a variety of Earth Observation tasks, such as land use and cover classification, crop type prediction, localization of specific objects (semantic segmentation), etc. The main goal of AiTLAS is to facilitate better usability and adoption of novel AI methods (and models) by EO experts, while offering easy access and standardized format of EO datasets to AI experts which allows benchmarking of various existing and novel AI methods tailored for EO data.

zshot
Zshot is a highly customizable framework for performing Zero and Few shot named entity and relationships recognition. It can be used for mentions extraction, wikification, zero and few shot named entity recognition, zero and few shot named relationship recognition, and visualization of zero-shot NER and RE extraction. The framework consists of two main components: the mentions extractor and the linker. There are multiple mentions extractors and linkers available, each serving a specific purpose. Zshot also includes a relations extractor and a knowledge extractor for extracting relations among entities and performing entity classification. The tool requires Python 3.6+ and dependencies like spacy, torch, transformers, evaluate, and datasets for evaluation over datasets like OntoNotes. Optional dependencies include flair and blink for additional functionalities. Zshot provides examples, tutorials, and evaluation methods to assess the performance of the components.

Reflection_Tuning
Reflection-Tuning is a project focused on improving the quality of instruction-tuning data through a reflection-based method. It introduces Selective Reflection-Tuning, where the student model can decide whether to accept the improvements made by the teacher model. The project aims to generate high-quality instruction-response pairs by defining specific criteria for the oracle model to follow and respond to. It also evaluates the efficacy and relevance of instruction-response pairs using the r-IFD metric. The project provides code for reflection and selection processes, along with data and model weights for both V1 and V2 methods.

gepa
GEPA (Genetic-Pareto) is a framework for optimizing arbitrary systems composed of text components like AI prompts, code snippets, or textual specs against any evaluation metric. It employs LLMs to reflect on system behavior, using feedback from execution and evaluation traces to drive targeted improvements. Through iterative mutation, reflection, and Pareto-aware candidate selection, GEPA evolves robust, high-performing variants with minimal evaluations, co-evolving multiple components in modular systems for domain-specific gains. The repository provides the official implementation of the GEPA algorithm as proposed in the paper titled 'GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning'.

k2
K2 (GeoLLaMA) is a large language model for geoscience, trained on geoscience literature and fine-tuned with knowledge-intensive instruction data. It outperforms baseline models on objective and subjective tasks. The repository provides K2 weights, core data of GeoSignal, GeoBench benchmark, and code for further pretraining and instruction tuning. The model is available on Hugging Face for use. The project aims to create larger and more powerful geoscience language models in the future.

pytorch-forecasting
PyTorch Forecasting is a PyTorch-based package for time series forecasting with state-of-the-art network architectures. It offers a high-level API for training networks on pandas data frames and utilizes PyTorch Lightning for scalable training on GPUs and CPUs. The package aims to simplify time series forecasting with neural networks by providing a flexible API for professionals and default settings for beginners. It includes a timeseries dataset class, base model class, multiple neural network architectures, multi-horizon timeseries metrics, and hyperparameter tuning with optuna. PyTorch Forecasting is built on pytorch-lightning for easy training on various hardware configurations.

Quantus
Quantus is a toolkit designed for the evaluation of neural network explanations. It offers more than 30 metrics in 6 categories for eXplainable Artificial Intelligence (XAI) evaluation. The toolkit supports different data types (image, time-series, tabular, NLP) and models (PyTorch, TensorFlow). It provides built-in support for explanation methods like captum, tf-explain, and zennit. Quantus is under active development and aims to provide a comprehensive set of quantitative evaluation metrics for XAI methods.

nixtla
Nixtla is a production-ready generative pretrained transformer for time series forecasting and anomaly detection. It can accurately predict various domains such as retail, electricity, finance, and IoT with just a few lines of code. TimeGPT introduces a paradigm shift with its standout performance, efficiency, and simplicity, making it accessible even to users with minimal coding experience. The model is based on self-attention and is independently trained on a vast time series dataset to minimize forecasting error. It offers features like zero-shot inference, fine-tuning, API access, adding exogenous variables, multiple series forecasting, custom loss function, cross-validation, prediction intervals, and handling irregular timestamps.

semlib
Semlib is a Python library for building data processing and data analysis pipelines that leverage the power of large language models (LLMs). It provides functional programming primitives like map, reduce, sort, and filter, programmed with natural language descriptions. Semlib handles complexities such as prompting, parsing, concurrency control, caching, and cost tracking. The library breaks down sophisticated data processing tasks into simpler steps to improve quality, feasibility, latency, cost, security, and flexibility of data processing tasks.

MME-RealWorld
MME-RealWorld is a benchmark designed to address real-world applications with practical relevance, featuring 13,366 high-resolution images and 29,429 annotations across 43 tasks. It aims to provide substantial recognition challenges and overcome common barriers in existing Multimodal Large Language Model benchmarks, such as small data scale, restricted data quality, and insufficient task difficulty. The dataset offers advantages in data scale, data quality, task difficulty, and real-world utility compared to existing benchmarks. It also includes a Chinese version with additional images and QA pairs focused on Chinese scenarios.

merlin
Merlin is a groundbreaking model capable of generating natural language responses intricately linked with object trajectories of multiple images. It excels in predicting and reasoning about future events based on initial observations, showcasing unprecedented capability in future prediction and reasoning. Merlin achieves state-of-the-art performance on the Future Reasoning Benchmark and multiple existing multimodal language models benchmarks, demonstrating powerful multi-modal general ability and foresight minds.
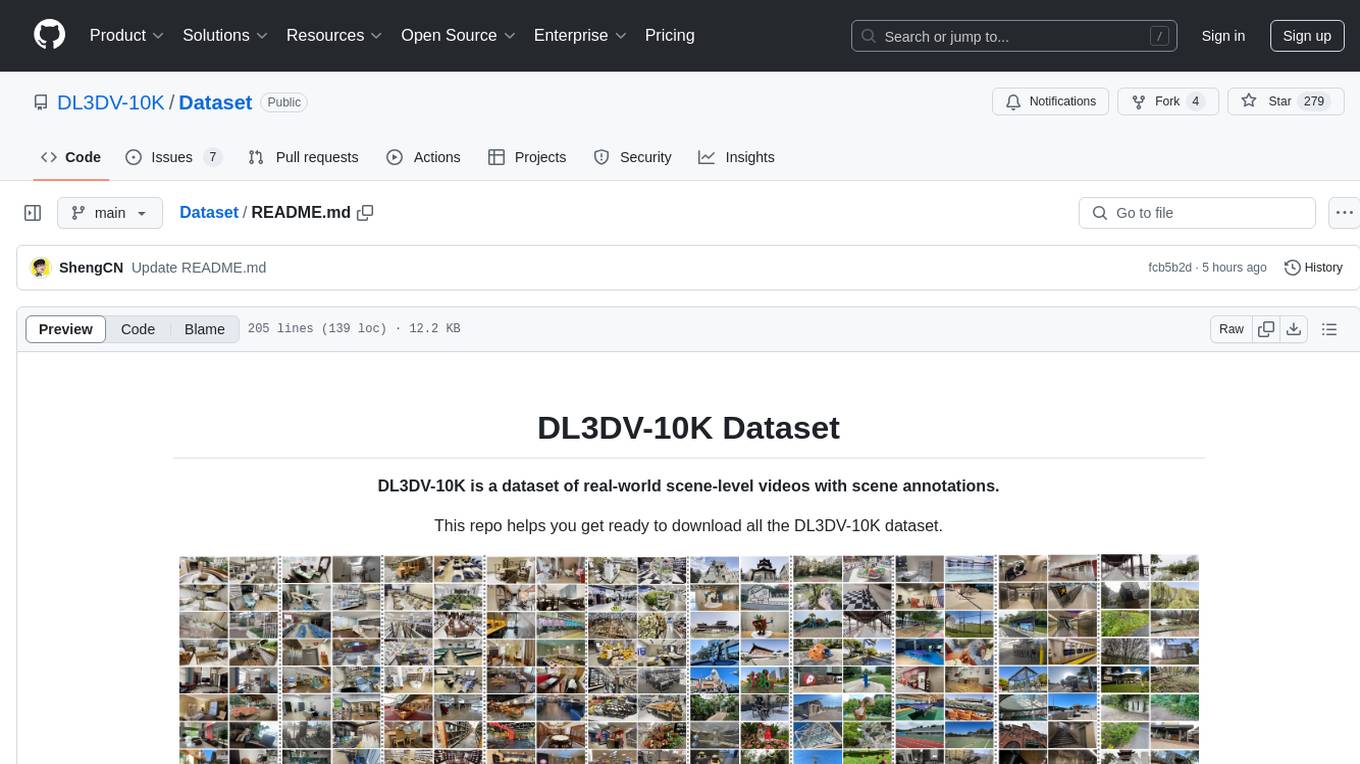
Dataset
DL3DV-10K is a large-scale dataset of real-world scene-level videos with annotations, covering diverse scenes with different levels of reflection, transparency, and lighting. It includes 10,510 multi-view scenes with 51.2 million frames at 4k resolution, and offers benchmark videos for novel view synthesis (NVS) methods. The dataset is designed to facilitate research in deep learning-based 3D vision and provides valuable insights for future research in NVS and 3D representation learning.

SheetCopilot
SheetCopilot is an assistant agent that manipulates spreadsheets by following user commands. It leverages Large Language Models (LLMs) to interact with spreadsheets like a human expert, enabling non-expert users to complete tasks on complex software such as Google Sheets and Excel via a language interface. The tool observes spreadsheet states, polishes generated solutions based on external action documents and error feedback, and aims to improve success rate and efficiency. SheetCopilot offers a dataset with diverse task categories and operations, supporting operations like entry & manipulation, management, formatting, charts, and pivot tables. Users can interact with SheetCopilot in Excel or Google Sheets, executing tasks like calculating revenue, creating pivot tables, and plotting charts. The tool's evaluation includes performance comparisons with leading LLMs and VBA-based methods on specific datasets, showcasing its capabilities in controlling various aspects of a spreadsheet.

venice
Venice is a derived data storage platform, providing the following characteristics: 1. High throughput asynchronous ingestion from batch and streaming sources (e.g. Hadoop and Samza). 2. Low latency online reads via remote queries or in-process caching. 3. Active-active replication between regions with CRDT-based conflict resolution. 4. Multi-cluster support within each region with operator-driven cluster assignment. 5. Multi-tenancy, horizontal scalability and elasticity within each cluster. The above makes Venice particularly suitable as the stateful component backing a Feature Store, such as Feathr. AI applications feed the output of their ML training jobs into Venice and then query the data for use during online inference workloads.
For similar tasks
InsPLAD
InsPLAD is a dataset and benchmark for power line asset inspection in UAV images. It contains 10,607 high-resolution UAV color images of seventeen unique power line assets with six defects. The dataset is used for object detection, defect classification, and anomaly detection tasks in computer vision. InsPLAD offers challenges like multi-scale objects, intra-class variation, cluttered background, and varied lighting conditions, aiming to improve state-of-the-art methods in the field.

qdrant
Qdrant is a vector similarity search engine and vector database. It is written in Rust, which makes it fast and reliable even under high load. Qdrant can be used for a variety of applications, including: * Semantic search * Image search * Product recommendations * Chatbots * Anomaly detection Qdrant offers a variety of features, including: * Payload storage and filtering * Hybrid search with sparse vectors * Vector quantization and on-disk storage * Distributed deployment * Highlighted features such as query planning, payload indexes, SIMD hardware acceleration, async I/O, and write-ahead logging Qdrant is available as a fully managed cloud service or as an open-source software that can be deployed on-premises.
SynapseML
SynapseML (previously known as MMLSpark) is an open-source library that simplifies the creation of massively scalable machine learning (ML) pipelines. It provides simple, composable, and distributed APIs for various machine learning tasks such as text analytics, vision, anomaly detection, and more. Built on Apache Spark, SynapseML allows seamless integration of models into existing workflows. It supports training and evaluation on single-node, multi-node, and resizable clusters, enabling scalability without resource wastage. Compatible with Python, R, Scala, Java, and .NET, SynapseML abstracts over different data sources for easy experimentation. Requires Scala 2.12, Spark 3.4+, and Python 3.8+.

mlx-vlm
MLX-VLM is a package designed for running Vision LLMs on Mac systems using MLX. It provides a convenient way to install and utilize the package for processing large language models related to vision tasks. The tool simplifies the process of running LLMs on Mac computers, offering a seamless experience for users interested in leveraging MLX for vision-related projects.
Java-AI-Book-Code
The Java-AI-Book-Code repository contains code examples for the 2020 edition of 'Practical Artificial Intelligence With Java'. It is a comprehensive update of the previous 2013 edition, featuring new content on deep learning, knowledge graphs, anomaly detection, linked data, genetic algorithms, search algorithms, and more. The repository serves as a valuable resource for Java developers interested in AI applications and provides practical implementations of various AI techniques and algorithms.
Awesome-AI-Data-Guided-Projects
A curated list of data science & AI guided projects to start building your portfolio. The repository contains guided projects covering various topics such as large language models, time series analysis, computer vision, natural language processing (NLP), and data science. Each project provides detailed instructions on how to implement specific tasks using different tools and technologies.
awesome-AIOps
awesome-AIOps is a curated list of academic researches and industrial materials related to Artificial Intelligence for IT Operations (AIOps). It includes resources such as competitions, white papers, blogs, tutorials, benchmarks, tools, companies, academic materials, talks, workshops, papers, and courses covering various aspects of AIOps like anomaly detection, root cause analysis, incident management, microservices, dependency tracing, and more.
AI-Security-and-Privacy-Events
AI-Security-and-Privacy-Events is a curated list of academic events focusing on AI security and privacy. It includes seminars, conferences, workshops, tutorials, special sessions, and covers various topics such as NLP & LLM Security, Privacy and Security in ML, Machine Learning Security, AI System with Confidential Computing, Adversarial Machine Learning, and more.
For similar jobs

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

openvino
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference. It provides a common API to deliver inference solutions on various platforms, including CPU, GPU, NPU, and heterogeneous devices. OpenVINO™ supports pre-trained models from Open Model Zoo and popular frameworks like TensorFlow, PyTorch, and ONNX. Key components of OpenVINO™ include the OpenVINO™ Runtime, plugins for different hardware devices, frontends for reading models from native framework formats, and the OpenVINO Model Converter (OVC) for adjusting models for optimal execution on target devices.

peft
PEFT (Parameter-Efficient Fine-Tuning) is a collection of state-of-the-art methods that enable efficient adaptation of large pretrained models to various downstream applications. By only fine-tuning a small number of extra model parameters instead of all the model's parameters, PEFT significantly decreases the computational and storage costs while achieving performance comparable to fully fine-tuned models.

jetson-generative-ai-playground
This repo hosts tutorial documentation for running generative AI models on NVIDIA Jetson devices. The documentation is auto-generated and hosted on GitHub Pages using their CI/CD feature to automatically generate/update the HTML documentation site upon new commits.

emgucv
Emgu CV is a cross-platform .Net wrapper for the OpenCV image-processing library. It allows OpenCV functions to be called from .NET compatible languages. The wrapper can be compiled by Visual Studio, Unity, and "dotnet" command, and it can run on Windows, Mac OS, Linux, iOS, and Android.

MMStar
MMStar is an elite vision-indispensable multi-modal benchmark comprising 1,500 challenge samples meticulously selected by humans. It addresses two key issues in current LLM evaluation: the unnecessary use of visual content in many samples and the existence of unintentional data leakage in LLM and LVLM training. MMStar evaluates 6 core capabilities across 18 detailed axes, ensuring a balanced distribution of samples across all dimensions.

VLMEvalKit
VLMEvalKit is an open-source evaluation toolkit of large vision-language models (LVLMs). It enables one-command evaluation of LVLMs on various benchmarks, without the heavy workload of data preparation under multiple repositories. In VLMEvalKit, we adopt generation-based evaluation for all LVLMs, and provide the evaluation results obtained with both exact matching and LLM-based answer extraction.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.