
DBCopilot
Code and data for the paper "DBCᴏᴘɪʟᴏᴛ: Natural Language Querying over Massive Database via Schema Routing" (EDBT 2025)
Stars: 77
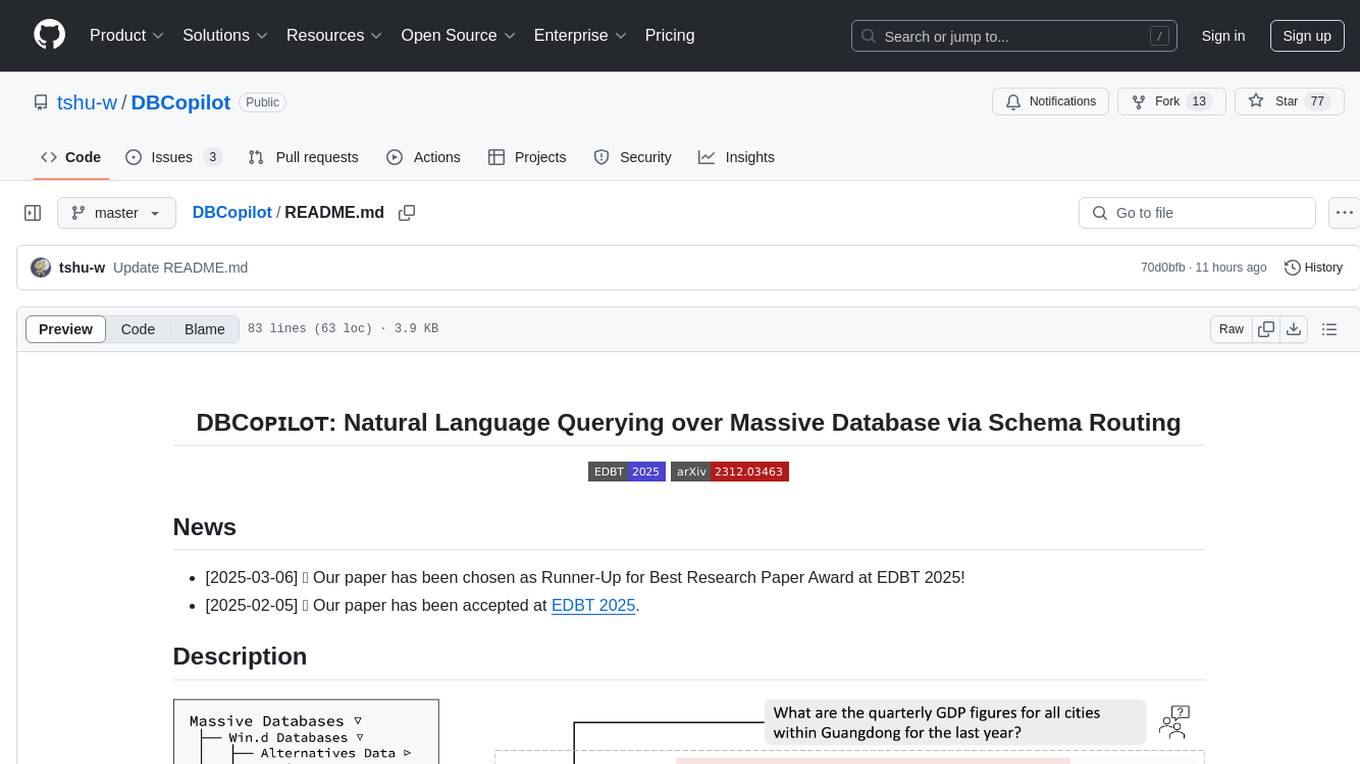
The development of Natural Language Interfaces to Databases (NLIDBs) has been greatly advanced by the advent of large language models (LLMs), which provide an intuitive way to translate natural language (NL) questions into Structured Query Language (SQL) queries. DBCopilot is a framework that addresses challenges in real-world scenarios of natural language querying over massive databases by employing a compact and flexible copilot model for routing. It decouples schema-agnostic NL2SQL into schema routing and SQL generation, utilizing a lightweight differentiable search index for semantic mappings and relation-aware joint retrieval. DBCopilot introduces a reverse schema-to-question generation paradigm for automatic learning and adaptation over massive databases, providing a scalable and effective solution for schema-agnostic NL2SQL.
README:
- [2025-03-06] 🏆 Our paper has been chosen as Runner-Up for Best Research Paper Award at EDBT 2025!
- [2025-02-05] 🎉 Our paper has been accepted at EDBT 2025.
The development of Natural Language Interfaces to Databases (NLIDBs) has been greatly advanced by the advent of large language models (LLMs), which provide an intuitive way to translate natural language (NL) questions into Structured Query Language (SQL) queries. While significant progress has been made in LLM-based NL2SQL, existing approaches face several challenges in real-world scenarios of natural language querying over massive databases. In this paper, we present DBCopilot, a framework that addresses these challenges by employing a compact and flexible copilot model for routing over massive databases. Specifically, DBCopilot decouples schema-agnostic NL2SQL into schema routing and SQL generation. This framework utilizes a single lightweight differentiable search index to construct semantic mappings for massive database schemata, and navigates natural language questions to their target databases and tables in a relation-aware joint retrieval manner. The routed schemata and questions are then fed into LLMs for effective SQL generation. Furthermore, DBCopilot introduces a reverse schema-to-question generation paradigm that can automatically learn and adapt the router over massive databases without manual intervention. Experimental results verify that DBCopilot is a scalable and effective solution for schema-agnostic NL2SQL, providing a significant advance in handling natural language querying over massive databases for NLIDBs.
First, install dependencies
# clone project
git clone --recursive https://github.com/tshu-w/DBCopilot
cd DBCopilot
# [SUGGESTED] use conda environment
conda env create -f environment.yaml
conda activate DBCopilot
# [ALTERNATIVE] install requirements directly
pip install -r requirements.txtNext, download and extract the data from OneDrive Share Link.
Finally, run the experiments with the following commands:
# Train the schema questioning models:
./scripts/sweep --config configs/sweep_fit_schema_questioning.yaml
# Training data synthesis
python scripts/synthesize_data.py
# Train the schema routers:
./scripts/sweep --config configs/sweep_fit_schema_routing.yaml
# End-to-end text-to-SQL evaluation:
python scripts/evaluate_text2sql.pyYou can also train and evaluate a single model with the run script.
# fit with the XXX config
./run fit --config configs/XXX.yaml
# or specific command line arguments
./run fit --model Model --data DataModule --data.batch_size 32 --trainer.gpus 0,
# evaluate with the checkpoint
./run test --config configs/XXX.yaml --ckpt_path ckpt_path
# get the script help
./run --help
./run fit --help@article{wang2023dbcopilot,
author = {Tianshu Wang and Hongyu Lin and Xianpei Han and Le Sun and Xiaoyang Chen and Hao Wang and Zhenyu Zeng},
title = {DBCopilot: Scaling Natural Language Querying to Massive Databases},
journal = {CoRR},
year = 2023,
volume = {abs/2312.03463},
doi = {10.48550/arXiv.2312.03463},
eprint = {2312.03463},
eprinttype = {arXiv},
url = {https://doi.org/10.48550/arXiv.2312.03463},
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for DBCopilot
Similar Open Source Tools
DBCopilot
The development of Natural Language Interfaces to Databases (NLIDBs) has been greatly advanced by the advent of large language models (LLMs), which provide an intuitive way to translate natural language (NL) questions into Structured Query Language (SQL) queries. DBCopilot is a framework that addresses challenges in real-world scenarios of natural language querying over massive databases by employing a compact and flexible copilot model for routing. It decouples schema-agnostic NL2SQL into schema routing and SQL generation, utilizing a lightweight differentiable search index for semantic mappings and relation-aware joint retrieval. DBCopilot introduces a reverse schema-to-question generation paradigm for automatic learning and adaptation over massive databases, providing a scalable and effective solution for schema-agnostic NL2SQL.
CodeFuse-ModelCache
Codefuse-ModelCache is a semantic cache for large language models (LLMs) that aims to optimize services by introducing a caching mechanism. It helps reduce the cost of inference deployment, improve model performance and efficiency, and provide scalable services for large models. The project caches pre-generated model results to reduce response time for similar requests and enhance user experience. It integrates various embedding frameworks and local storage options, offering functionalities like cache-writing, cache-querying, and cache-clearing through RESTful API. The tool supports multi-tenancy, system commands, and multi-turn dialogue, with features for data isolation, database management, and model loading schemes. Future developments include data isolation based on hyperparameters, enhanced system prompt partitioning storage, and more versatile embedding models and similarity evaluation algorithms.

DeepFabric
Deepfabric is an SDK and CLI tool that leverages large language models to generate high-quality synthetic datasets. It's designed for researchers and developers building teacher-student distillation pipelines, creating evaluation benchmarks for models and agents, or conducting research requiring diverse training data. The key innovation lies in Deepfabric's graph and tree-based architecture, which uses structured topic nodes as generation seeds. This approach ensures the creation of datasets that are both highly diverse and domain-specific, while minimizing redundancy and duplication across generated samples.

llm-analysis
llm-analysis is a tool designed for Latency and Memory Analysis of Transformer Models for Training and Inference. It automates the calculation of training or inference latency and memory usage for Large Language Models (LLMs) or Transformers based on specified model, GPU, data type, and parallelism configurations. The tool helps users to experiment with different setups theoretically, understand system performance, and optimize training/inference scenarios. It supports various parallelism schemes, communication methods, activation recomputation options, data types, and fine-tuning strategies. Users can integrate llm-analysis in their code using the `LLMAnalysis` class or use the provided entry point functions for command line interface. The tool provides lower-bound estimations of memory usage and latency, and aims to assist in achieving feasible and optimal setups for training or inference.
FATE-LLM
FATE-LLM is a framework supporting federated learning for large and small language models. It promotes training efficiency of federated LLMs using Parameter-Efficient methods, protects the IP of LLMs using FedIPR, and ensures data privacy during training and inference through privacy-preserving mechanisms.
InstructGraph
InstructGraph is a framework designed to enhance large language models (LLMs) for graph-centric tasks by utilizing graph instruction tuning and preference alignment. The tool collects and decomposes 29 standard graph datasets into four groups, enabling LLMs to better understand and generate graph data. It introduces a structured format verbalizer to transform graph data into a code-like format, facilitating code understanding and generation. Additionally, it addresses hallucination problems in graph reasoning and generation through direct preference optimization (DPO). The tool aims to bridge the gap between textual LLMs and graph data, offering a comprehensive solution for graph-related tasks.

HuixiangDou2
HuixiangDou2 is a robustly optimized GraphRAG approach that integrates multiple open-source projects to improve performance in graph-based augmented generation. It conducts comparative experiments and achieves a significant score increase, leading to a GraphRAG implementation with recognized performance. The repository provides code improvements, dense retrieval for querying entities and relationships, real domain knowledge testing, and impact analysis on accuracy.
GOLEM
GOLEM is an open-source AI framework focused on optimization and learning of structured graph-based models using meta-heuristic methods. It emphasizes the potential of meta-heuristics in complex problem spaces where gradient-based methods are not suitable, and the importance of structured models in various problem domains. The framework offers features like structured model optimization, metaheuristic methods, multi-objective optimization, constrained optimization, extensibility, interpretability, and reproducibility. It can be applied to optimization problems represented as directed graphs with defined fitness functions. GOLEM has applications in areas like AutoML, Bayesian network structure search, differential equation discovery, geometric design, and neural architecture search. The project structure includes packages for core functionalities, adapters, graph representation, optimizers, genetic algorithms, utilities, serialization, visualization, examples, and testing. Contributions are welcome, and the project is supported by ITMO University's Research Center Strong Artificial Intelligence in Industry.

semlib
Semlib is a Python library for building data processing and data analysis pipelines that leverage the power of large language models (LLMs). It provides functional programming primitives like map, reduce, sort, and filter, programmed with natural language descriptions. Semlib handles complexities such as prompting, parsing, concurrency control, caching, and cost tracking. The library breaks down sophisticated data processing tasks into simpler steps to improve quality, feasibility, latency, cost, security, and flexibility of data processing tasks.

pytorch-forecasting
PyTorch Forecasting is a PyTorch-based package for time series forecasting with state-of-the-art network architectures. It offers a high-level API for training networks on pandas data frames and utilizes PyTorch Lightning for scalable training on GPUs and CPUs. The package aims to simplify time series forecasting with neural networks by providing a flexible API for professionals and default settings for beginners. It includes a timeseries dataset class, base model class, multiple neural network architectures, multi-horizon timeseries metrics, and hyperparameter tuning with optuna. PyTorch Forecasting is built on pytorch-lightning for easy training on various hardware configurations.

guidellm
GuideLLM is a platform for evaluating and optimizing the deployment of large language models (LLMs). By simulating real-world inference workloads, GuideLLM enables users to assess the performance, resource requirements, and cost implications of deploying LLMs on various hardware configurations. This approach ensures efficient, scalable, and cost-effective LLM inference serving while maintaining high service quality. The tool provides features for performance evaluation, resource optimization, cost estimation, and scalability testing.

Adaptive-MT-LLM-Fine-tuning
The repository Adaptive-MT-LLM-Fine-tuning contains code and data for the paper 'Fine-tuning Large Language Models for Adaptive Machine Translation'. It focuses on enhancing Mistral 7B, a large language model, for real-time adaptive machine translation in the medical domain. The fine-tuning process involves using zero-shot and one-shot translation prompts to improve terminology and style adherence. The repository includes training and test data, data processing code, fuzzy match retrieval techniques, fine-tuning methods, conversion to CTranslate2 format, tokenizers, translation codes, and evaluation metrics.

LMOps
LMOps is a research initiative focusing on fundamental research and technology for building AI products with foundation models, particularly enabling AI capabilities with Large Language Models (LLMs) and Generative AI models. The project explores various aspects such as prompt optimization, longer context handling, LLM alignment, acceleration of LLMs, LLM customization, and understanding in-context learning. It also includes tools like Promptist for automatic prompt optimization, Structured Prompting for efficient long-sequence prompts consumption, and X-Prompt for extensible prompts beyond natural language. Additionally, LLMA accelerators are developed to speed up LLM inference by referencing and copying text spans from documents. The project aims to advance technologies that facilitate prompting language models and enhance the performance of LLMs in various scenarios.
ModelGenerator
AIDO.ModelGenerator is a software stack designed for developing AI-driven Digital Organisms. It enables researchers to adapt pretrained models and generate finetuned models for various tasks. The framework supports rapid prototyping with experiments like applying pre-trained models to new data, developing finetuning tasks, benchmarking models, and testing new architectures. Built on PyTorch, HuggingFace, and Lightning, it facilitates seamless integration with these ecosystems. The tool caters to cross-disciplinary teams in ML & Bio, offering installation, usage, tutorials, and API reference in its documentation.
A-mem
A-MEM is a novel agentic memory system designed for Large Language Model (LLM) agents to dynamically organize memories in an agentic way. It introduces advanced memory organization capabilities, intelligent indexing, and linking of memories, comprehensive note generation, interconnected knowledge networks, continuous memory evolution, and agent-driven decision making for adaptive memory management. The system facilitates agent construction and enables dynamic memory operations and flexible agent-memory interactions.
robot-3dlotus
Towards Generalizable Vision-Language Robotic Manipulation: A Benchmark and LLM-guided 3D Policy is a research project focusing on addressing the challenge of generalizing language-conditioned robotic policies to new tasks. The project introduces GemBench, a benchmark to evaluate the generalization capabilities of vision-language robotic manipulation policies. It also presents the 3D-LOTUS approach, which leverages rich 3D information for action prediction conditioned on language. Additionally, the project introduces 3D-LOTUS++, a framework that integrates 3D-LOTUS's motion planning capabilities with the task planning capabilities of LLMs and the object grounding accuracy of VLMs to achieve state-of-the-art performance on novel tasks in robotic manipulation.
For similar tasks
DBCopilot
The development of Natural Language Interfaces to Databases (NLIDBs) has been greatly advanced by the advent of large language models (LLMs), which provide an intuitive way to translate natural language (NL) questions into Structured Query Language (SQL) queries. DBCopilot is a framework that addresses challenges in real-world scenarios of natural language querying over massive databases by employing a compact and flexible copilot model for routing. It decouples schema-agnostic NL2SQL into schema routing and SQL generation, utilizing a lightweight differentiable search index for semantic mappings and relation-aware joint retrieval. DBCopilot introduces a reverse schema-to-question generation paradigm for automatic learning and adaptation over massive databases, providing a scalable and effective solution for schema-agnostic NL2SQL.
SQLAgent
DataAgent is a multi-agent system for data analysis, capable of understanding data development and data analysis requirements, understanding data, and generating SQL and Python code for tasks such as data query, data visualization, and machine learning.
airda
airda(Air Data Agent) is a multi-agent system for data analysis, which can understand data development and data analysis requirements, understand data, and generate SQL and Python code for data query, data visualization, machine learning and other tasks.

dbhub
DBHub is a universal database gateway that implements the Model Context Protocol (MCP) server interface. It allows MCP-compatible clients to connect to and explore different databases. The gateway supports various database resources and tools, providing capabilities such as executing queries, listing connectors, generating SQL, and explaining database elements. Users can easily configure their database connections and choose between different transport modes like stdio and sse. DBHub also offers a demo mode with a sample employee database for testing purposes.
Chat2DB
Chat2DB is an AI-driven data development and analysis platform that enables users to communicate with databases using natural language. It supports a wide range of databases, including MySQL, PostgreSQL, Oracle, SQLServer, SQLite, MariaDB, ClickHouse, DM, Presto, DB2, OceanBase, Hive, KingBase, MongoDB, Redis, and Snowflake. Chat2DB provides a user-friendly interface that allows users to query databases, generate reports, and explore data using natural language commands. It also offers a variety of features to help users improve their productivity, such as auto-completion, syntax highlighting, and error checking.

Hurley-AI
Hurley AI is a next-gen framework for developing intelligent agents through Retrieval-Augmented Generation. It enables easy creation of custom AI assistants and agents, supports various agent types, and includes pre-built tools for domains like finance and legal. Hurley AI integrates with LLM inference services and provides observability with Arize Phoenix. Users can create Hurley RAG tools with a single line of code and customize agents with specific instructions. The tool also offers various helper functions to connect with Hurley RAG and search tools, along with pre-built tools for tasks like summarizing text, rephrasing text, understanding memecoins, and querying databases.
spring-ai-apps
spring-ai-apps is a collection of Spring AI small applications designed to help users easily apply Spring AI for AI application development. Each small application comes with minimal code and a fully set up framework to resolve version conflict issues.

OpenGateLLM
OpenGateLLM is an open-source API gateway developed by the French Government, designed to serve AI models in production. It follows OpenAI standards and offers robust features like RAG integration, audio transcription, OCR, and more. With support for multiple AI backends and built-in security, OpenGateLLM provides a production-ready solution for various AI tasks.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.