
RAG-FiT
Framework for enhancing LLMs for RAG tasks using fine-tuning.
Stars: 517

RAG-FiT is a library designed to improve Language Models' ability to use external information by fine-tuning models on specially created RAG-augmented datasets. The library assists in creating training data, training models using parameter-efficient finetuning (PEFT), and evaluating performance using RAG-specific metrics. It is modular, customizable via configuration files, and facilitates fast prototyping and experimentation with various RAG settings and configurations.
README:

RAG-FiT is a library designed to improve LLMs ability to use external information by fine-tuning models on specially created RAG-augmented datasets. The library helps create the data for training, given a RAG technique, helps easily train models using parameter-efficient finetuning (PEFT), and finally can help users measure the improved performance using various, RAG-specific metrics. The library is modular, workflows are customizable using configuration files. Formerly called RAG Foundry.
Comments, suggestions, issues and pull-requests are welcomed! ❤️
Clone and run:
pip install -e .Optional packages can be installed:
pip install -e .[haystack]
pip install -e .[deepeval]For a simple, end-to-end example, see the PubmedQA Tutorial.
The RAG-FiT framework facilitates fast prototyping and experimentation with various RAG settings and configurations, including data selection and filtering, processing, retrieval, ranking, query manipulation, prompt generation, training, inference, output processing and evaluation. The library is comprised of 4 modules: dataset creation, training, inference and evaluation.
-
Dataset Creation: The processing module creates datasets, persisting RAG interactions, to be used for RAG training and inference. RAG interactions include dataset loading, columns normalization, data aggregation (fewshot creation), information retrieval using external tools and frameworks, API integration, template-based prompt creation and any other form of pre-processing. The data is saved in a consistent, model-independent, input-output format, along with all other fields and metadata. See Processing.md.
-
Training: using PEFT for efficient training and TRL (e.g. supervised FT) users can train any model on the augmented datasets. Training is done on the completions. Models can be pushed to HF Hub. See Training.md.
-
Inference: generating predictions using the augmented datasets with trained or untrained LLMs. See Inference.md.
-
Evaluation: running evaluation on the generated output from the inference module. Users can provide a list of metrics to run; custom metrics can be implemented easily. Current metrics include EM, F1, ROUGE, BERTScore, Deepeval, RAGAS, HF
evaluateand classification. Metrics can be local—run on each example, or global—run on the entire dataset, e.g. recall. Metrics can utilize any feature in the dataset, like retrieval results, reasoning, citations and attributions, not just the input and output texts. See Evaluation.md.
The 4 modules are represented as scripts: processing.py, training.py, inference.py and evaluation.py at the top
level. Every call has the form python SCRIPT options....
The library utilizes the Hydra configuration tool; it enables the use of hierarchical
configurations, easily overridden of values in the CLI and the ability to run multiple jobs remotely (e.g. integrations with
SLURM and Ray). It represents a configuration-as-code approach, as it can instantiate python classes according to
configuration (the _target_ keyword indicates the python class to use in a given context).
There are default configurations for each module in the configs folder. A configuration file can be overridden like so:
python processing -cp configs/paper -cn processing-asqa-retrievalIndividual keywords can be overridden as well:
python processing -cp configs/paper -cn processing-asqa-retrieval \
output_path=/store/data/here \
cache=trueFor a complete set of configurations, reproducing the experimentation in the paper with the ASQA dataset, see the configurations in the Paper folder.
Please cite our paper if it helps your research: RAG Foundry: A Framework for Enhancing LLMs for Retrieval Augmented Generation.
@article{fleischerRAGFoundryFramework2024,
title = {{RAG} {Foundry}: {A} {Framework} for {Enhancing} {LLMs} for {Retrieval} {Augmented} {Generation}},
author = {Fleischer, Daniel and Berchansky, Moshe and Wasserblat, Moshe and Izsak, Peter},
year = 2024,
note = {arXiv:2408.02545 [cs]},
annote = {Comment: 10 pages},
url = {http://arxiv.org/abs/2408.02545},
publisher = {arXiv},
}The code is licensed under the Apache 2.0 License.
This is not an official Intel product.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for RAG-FiT
Similar Open Source Tools
RAG-FiT
RAG-FiT is a library designed to improve Language Models' ability to use external information by fine-tuning models on specially created RAG-augmented datasets. The library assists in creating training data, training models using parameter-efficient finetuning (PEFT), and evaluating performance using RAG-specific metrics. It is modular, customizable via configuration files, and facilitates fast prototyping and experimentation with various RAG settings and configurations.

RAGFoundry
RAG Foundry is a library designed to enhance Large Language Models (LLMs) by fine-tuning models on RAG-augmented datasets. It helps create training data, train models using parameter-efficient finetuning (PEFT), and measure performance using RAG-specific metrics. The library is modular, customizable using configuration files, and facilitates prototyping with various RAG settings and configurations for tasks like data processing, retrieval, training, inference, and evaluation.

llm-on-ray
LLM-on-Ray is a comprehensive solution for building, customizing, and deploying Large Language Models (LLMs). It simplifies complex processes into manageable steps by leveraging the power of Ray for distributed computing. The tool supports pretraining, finetuning, and serving LLMs across various hardware setups, incorporating industry and Intel optimizations for performance. It offers modular workflows with intuitive configurations, robust fault tolerance, and scalability. Additionally, it provides an Interactive Web UI for enhanced usability, including a chatbot application for testing and refining models.


guidellm
GuideLLM is a platform for evaluating and optimizing the deployment of large language models (LLMs). By simulating real-world inference workloads, GuideLLM enables users to assess the performance, resource requirements, and cost implications of deploying LLMs on various hardware configurations. This approach ensures efficient, scalable, and cost-effective LLM inference serving while maintaining high service quality. The tool provides features for performance evaluation, resource optimization, cost estimation, and scalability testing.

postgresml
PostgresML is a powerful Postgres extension that seamlessly combines data storage and machine learning inference within your database. It enables running machine learning and AI operations directly within PostgreSQL, leveraging GPU acceleration for faster computations, integrating state-of-the-art large language models, providing built-in functions for text processing, enabling efficient similarity search, offering diverse ML algorithms, ensuring high performance, scalability, and security, supporting a wide range of NLP tasks, and seamlessly integrating with existing PostgreSQL tools and client libraries.

CoLLM
CoLLM is a novel method that integrates collaborative information into Large Language Models (LLMs) for recommendation. It converts recommendation data into language prompts, encodes them with both textual and collaborative information, and uses a two-step tuning method to train the model. The method incorporates user/item ID fields in prompts and employs a conventional collaborative model to generate user/item representations. CoLLM is built upon MiniGPT-4 and utilizes pretrained Vicuna weights for training.

ollama-grid-search
A Rust based tool to evaluate LLM models, prompts and model params. It automates the process of selecting the best model parameters, given an LLM model and a prompt, iterating over the possible combinations and letting the user visually inspect the results. The tool assumes the user has Ollama installed and serving endpoints, either in `localhost` or in a remote server. Key features include: * Automatically fetches models from local or remote Ollama servers * Iterates over different models and params to generate inferences * A/B test prompts on different models simultaneously * Allows multiple iterations for each combination of parameters * Makes synchronous inference calls to avoid spamming servers * Optionally outputs inference parameters and response metadata (inference time, tokens and tokens/s) * Refetching of individual inference calls * Model selection can be filtered by name * List experiments which can be downloaded in JSON format * Configurable inference timeout * Custom default parameters and system prompts can be defined in settings

poml
POML (Prompt Orchestration Markup Language) is a novel markup language designed to bring structure, maintainability, and versatility to advanced prompt engineering for Large Language Models (LLMs). It addresses common challenges in prompt development, such as lack of structure, complex data integration, format sensitivity, and inadequate tooling. POML provides a systematic way to organize prompt components, integrate diverse data types seamlessly, and manage presentation variations, empowering developers to create more sophisticated and reliable LLM applications.

EDA-GPT
EDA GPT is an open-source data analysis companion that offers a comprehensive solution for structured and unstructured data analysis. It streamlines the data analysis process, empowering users to explore, visualize, and gain insights from their data. EDA GPT supports analyzing structured data in various formats like CSV, XLSX, and SQLite, generating graphs, and conducting in-depth analysis of unstructured data such as PDFs and images. It provides a user-friendly interface, powerful features, and capabilities like comparing performance with other tools, analyzing large language models, multimodal search, data cleaning, and editing. The tool is optimized for maximal parallel processing, searching internet and documents, and creating analysis reports from structured and unstructured data.

HuixiangDou2
HuixiangDou2 is a robustly optimized GraphRAG approach that integrates multiple open-source projects to improve performance in graph-based augmented generation. It conducts comparative experiments and achieves a significant score increase, leading to a GraphRAG implementation with recognized performance. The repository provides code improvements, dense retrieval for querying entities and relationships, real domain knowledge testing, and impact analysis on accuracy.

Upsonic
Upsonic offers a cutting-edge enterprise-ready framework for orchestrating LLM calls, agents, and computer use to complete tasks cost-effectively. It provides reliable systems, scalability, and a task-oriented structure for real-world cases. Key features include production-ready scalability, task-centric design, MCP server support, tool-calling server, computer use integration, and easy addition of custom tools. The framework supports client-server architecture and allows seamless deployment on AWS, GCP, or locally using Docker.

graphrag-local-ollama
GraphRAG Local Ollama is a repository that offers an adaptation of Microsoft's GraphRAG, customized to support local models downloaded using Ollama. It enables users to leverage local models with Ollama for large language models (LLMs) and embeddings, eliminating the need for costly OpenAPI models. The repository provides a simple setup process and allows users to perform question answering over private text corpora by building a graph-based text index and generating community summaries for closely-related entities. GraphRAG Local Ollama aims to improve the comprehensiveness and diversity of generated answers for global sensemaking questions over datasets.

LazyLLM
LazyLLM is a low-code development tool for building complex AI applications with multiple agents. It assists developers in building AI applications at a low cost and continuously optimizing their performance. The tool provides a convenient workflow for application development and offers standard processes and tools for various stages of application development. Users can quickly prototype applications with LazyLLM, analyze bad cases with scenario task data, and iteratively optimize key components to enhance the overall application performance. LazyLLM aims to simplify the AI application development process and provide flexibility for both beginners and experts to create high-quality applications.

comfyui_LLM_Polymath
LLM Polymath Chat Node is an advanced Chat Node for ComfyUI that integrates large language models to build text-driven applications and automate data processes, enhancing prompt responses by incorporating real-time web search, linked content extraction, and custom agent instructions. It supports both OpenAI’s GPT-like models and alternative models served via a local Ollama API. The core functionalities include Comfy Node Finder and Smart Assistant, along with additional agents like Flux Prompter, Custom Instructors, Python debugger, and scripter. The tool offers features for prompt processing, web search integration, model & API integration, custom instructions, image handling, logging & debugging, output compression, and more.

radicalbit-ai-monitoring
The Radicalbit AI Monitoring Platform provides a comprehensive solution for monitoring Machine Learning and Large Language models in production. It helps proactively identify and address potential performance issues by analyzing data quality, model quality, and model drift. The repository contains files and projects for running the platform, including UI, API, SDK, and Spark components. Installation using Docker compose is provided, allowing deployment with a K3s cluster and interaction with a k9s container. The platform documentation includes a step-by-step guide for installation and creating dashboards. Community engagement is encouraged through a Discord server. The roadmap includes adding functionalities for batch and real-time workloads, covering various model types and tasks.
For similar tasks

cyclops
Cyclops is a toolkit for facilitating research and deployment of ML models for healthcare. It provides a few high-level APIs namely: data - Create datasets for training, inference and evaluation. We use the popular 🤗 datasets to efficiently load and slice different modalities of data models - Use common model implementations using scikit-learn and PyTorch tasks - Use common ML task formulations such as binary classification or multi-label classification on tabular, time-series and image data evaluate - Evaluate models on clinical prediction tasks monitor - Detect dataset shift relevant for clinical use cases report - Create model report cards for clinical ML models
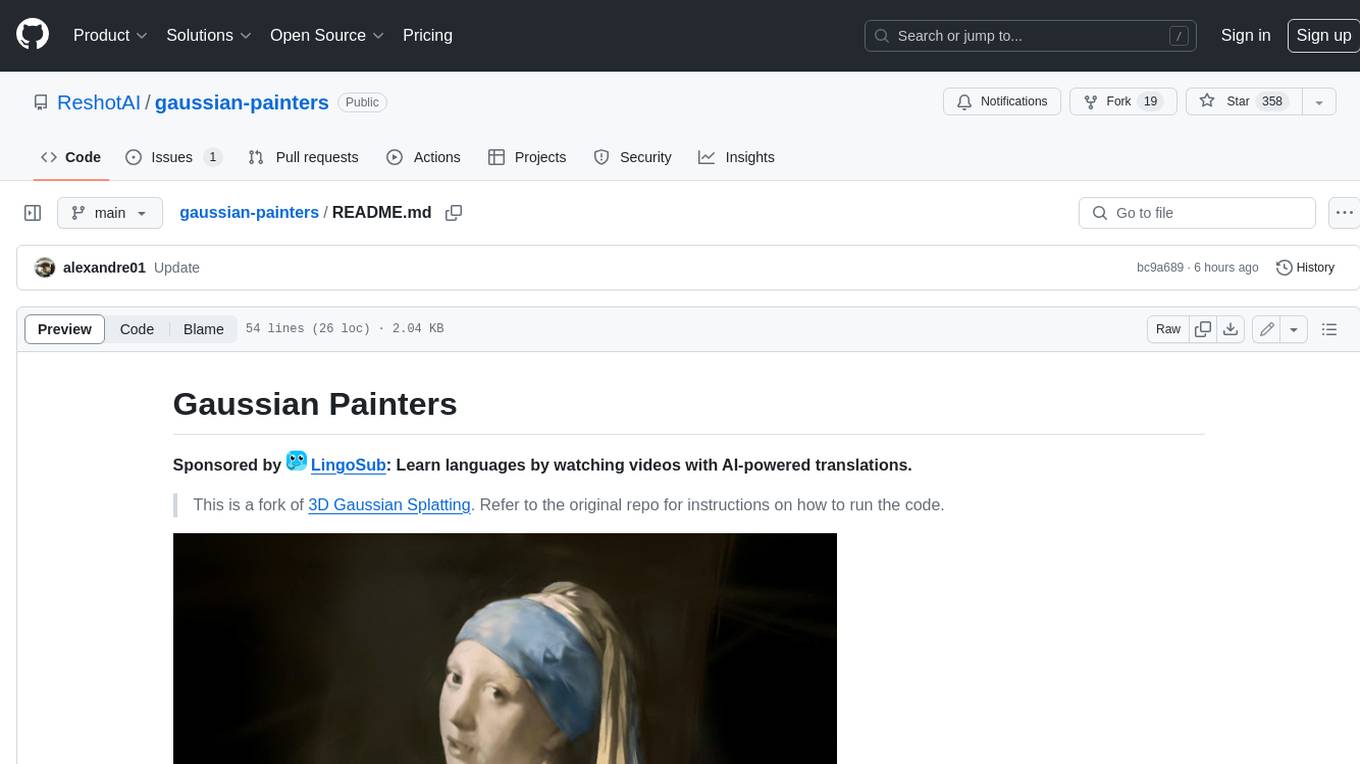
gaussian-painters
This tool is a fork of the 3D Gaussian Splatting code. It allows users to create a dataset ready to be trained with the Gaussian Splatting code. The dataset can be used for various experiments, such as creating orthogonal images, steganography, and lenticular effects. The tool also includes a visualizer that allows users to visualize the "painting" process during the Gaussian Splatting optimization.
UHGEval
UHGEval is a comprehensive framework designed for evaluating the hallucination phenomena. It includes UHGEval, a framework for evaluating hallucination, XinhuaHallucinations dataset, and UHGEval-dataset pipeline for creating XinhuaHallucinations. The framework offers flexibility and extensibility for evaluating common hallucination tasks, supporting various models and datasets. Researchers can use the open-source pipeline to create customized datasets. Supported tasks include QA, dialogue, summarization, and multi-choice tasks.
RAGFoundry
RAG Foundry is a library designed to enhance Large Language Models (LLMs) by fine-tuning models on RAG-augmented datasets. It helps create training data, train models using parameter-efficient finetuning (PEFT), and measure performance using RAG-specific metrics. The library is modular, customizable using configuration files, and facilitates prototyping with various RAG settings and configurations for tasks like data processing, retrieval, training, inference, and evaluation.
ollama-ebook-summary
The 'ollama-ebook-summary' repository is a Python project that creates bulleted notes summaries of books and long texts, particularly in epub and pdf formats with ToC metadata. It automates the extraction of chapters, splits them into ~2000 token chunks, and allows for asking arbitrary questions to parts of the text for improved granularity of response. The tool aims to provide summaries for each page of a book rather than a one-page summary of the entire document, enhancing content curation and knowledge sharing capabilities.

agentneo
AgentNeo is a Python package that provides functionalities for project, trace, dataset, experiment management. It allows users to authenticate, create projects, trace agents and LangGraph graphs, manage datasets, and run experiments with metrics. The tool aims to streamline AI project management and analysis by offering a comprehensive set of features.
RAG-FiT
RAG-FiT is a library designed to improve Language Models' ability to use external information by fine-tuning models on specially created RAG-augmented datasets. The library assists in creating training data, training models using parameter-efficient finetuning (PEFT), and evaluating performance using RAG-specific metrics. It is modular, customizable via configuration files, and facilitates fast prototyping and experimentation with various RAG settings and configurations.
RagaAI-Catalyst
RagaAI Catalyst is a comprehensive platform designed to enhance the management and optimization of LLM projects. It offers features such as project management, dataset management, evaluation management, trace management, prompt management, synthetic data generation, and guardrail management. These functionalities enable efficient evaluation and safeguarding of LLM applications.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.