
Woodpecker
✨✨Woodpecker: Hallucination Correction for Multimodal Large Language Models. The first work to correct hallucinations in MLLMs.
Stars: 567

Woodpecker is a tool designed to correct hallucinations in Multimodal Large Language Models (MLLMs) by introducing a training-free method that picks out and corrects inconsistencies between generated text and image content. It consists of five stages: key concept extraction, question formulation, visual knowledge validation, visual claim generation, and hallucination correction. Woodpecker can be easily integrated with different MLLMs and provides interpretable results by accessing intermediate outputs of the stages. The tool has shown significant improvements in accuracy over baseline models like MiniGPT-4 and mPLUG-Owl.
README:


Hallucination is a big shadow hanging over the rapidly evolving Multimodal Large Language Models (MLLMs), referring to the phenomenon that the generated text is inconsistent with the image content. In order to mitigate hallucinations, existing studies mainly resort to an instruction-tuning manner that requires retraining the models with specific data. In this paper, we pave a different way, introducing a training-free method named Woodpecker. Like a woodpecker heals trees, it picks out and corrects hallucinations from the generated text. Concretely, Woodpecker consists of five stages: key concept extraction, question formulation, visual knowledge validation, visual claim generation, and hallucination correction. Implemented in a post-remedy manner, Woodpecker can easily serve different MLLMs, while being interpretable by accessing intermediate outputs of the five stages. We evaluate Woodpecker both quantitatively and qualitatively and show the huge potential of this new paradigm. On the POPE benchmark, our method obtains a 30.66%/24.33% improvement in accuracy over the baseline MiniGPT-4/mPLUG-Owl.
This is the first work to correct hallucination in multimodal large language models. If you have any question, please feel free to email [email protected] or add weChat ID xjtupanda.
We perform experiments based on four baseline models:
The experimental results are shown below. For more details, please check out our paper.

This part focuses on object-level hallucinations.

This part focuses on both object- and attribute-level hallucinations.

We also propose to perform open-ended evaluation directly via the recently opened GPT-4V interface. We design two metrics: accuracy and detailedness.

Please feel free to try our Online Demo!

- Create conda environment
conda create -n corrector python=3.10
conda activate corrector
pip install -r requirements.txt- Install required packages and models
- Install
spacyand relevant model packages, following the instructions in Link. This is used for some text processing operations.
pip install -U spacy
python -m spacy download en_core_web_lg
python -m spacy download en_core_web_md
python -m spacy download en_core_web_sm- For our Open-set Detector. Install GroundingDINO following the instructions in Link.
1. Inference
To make corrections based on an image and a text output from MLLM, run the inference code as follows:
python inference.py \
--image-path {path/to/image} \
--query "Some query.(e.x. Describe this image.)" \
--text "Some text to be corrected." \
--detector-config "path/to/GroundingDINO_SwinT_OGC.py" \
--detector-model "path/to/groundingdino_swint_ogc.pth" \
--api-key "sk-xxxxxxx" \
The output text will be printed in the terminal, and intermediate results saved by default as ./intermediate_view.json.
2. Demo setup
We use mPLUG-Owl as our default MLLM in experiments. If you wish to replicate the online demo, please clone the project and modify the variables in https://github.com/BradyFU/Woodpecker/blob/e3fcac307cc5ff5a3dc079d9a94b924ebcdc2531/gradio_demo.py#L7 and https://github.com/BradyFU/Woodpecker/blob/e3fcac307cc5ff5a3dc079d9a94b924ebcdc2531/gradio_demo.py#L35-L36
Then simply run:
CUDA_VISIBLE_DEVICES=0,1 python gradio_demo.pyHere we put the corrector components on GPU with id 0 and mPLUG-Owl on GPU with id 1.
This repository benefits from mPLUG-Owl, GroundingDINO, BLIP-2, and LLaMA-Adapter. Thanks for their awesome works.
If you find our project helpful to your research, please consider citing:
@article{yin2023woodpecker,
title={Woodpecker: Hallucination correction for multimodal large language models},
author={Yin, Shukang and Fu, Chaoyou and Zhao, Sirui and Xu, Tong and Wang, Hao and Sui, Dianbo and Shen, Yunhang and Li, Ke and Sun, Xing and Chen, Enhong},
journal={arXiv preprint arXiv:2310.16045},
year={2023}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Woodpecker
Similar Open Source Tools
Woodpecker
Woodpecker is a tool designed to correct hallucinations in Multimodal Large Language Models (MLLMs) by introducing a training-free method that picks out and corrects inconsistencies between generated text and image content. It consists of five stages: key concept extraction, question formulation, visual knowledge validation, visual claim generation, and hallucination correction. Woodpecker can be easily integrated with different MLLMs and provides interpretable results by accessing intermediate outputs of the stages. The tool has shown significant improvements in accuracy over baseline models like MiniGPT-4 and mPLUG-Owl.

llms
The 'llms' repository is a comprehensive guide on Large Language Models (LLMs), covering topics such as language modeling, applications of LLMs, statistical language modeling, neural language models, conditional language models, evaluation methods, transformer-based language models, practical LLMs like GPT and BERT, prompt engineering, fine-tuning LLMs, retrieval augmented generation, AI agents, and LLMs for computer vision. The repository provides detailed explanations, examples, and tools for working with LLMs.

fuse-med-ml
FuseMedML is a Python framework designed to accelerate machine learning-based discovery in the medical field by promoting code reuse. It provides a flexible design concept where data is stored in a nested dictionary, allowing easy handling of multi-modality information. The framework includes components for creating custom models, loss functions, metrics, and data processing operators. Additionally, FuseMedML offers 'batteries included' key components such as fuse.data for data processing, fuse.eval for model evaluation, and fuse.dl for reusable deep learning components. It supports PyTorch and PyTorch Lightning libraries and encourages the creation of domain extensions for specific medical domains.
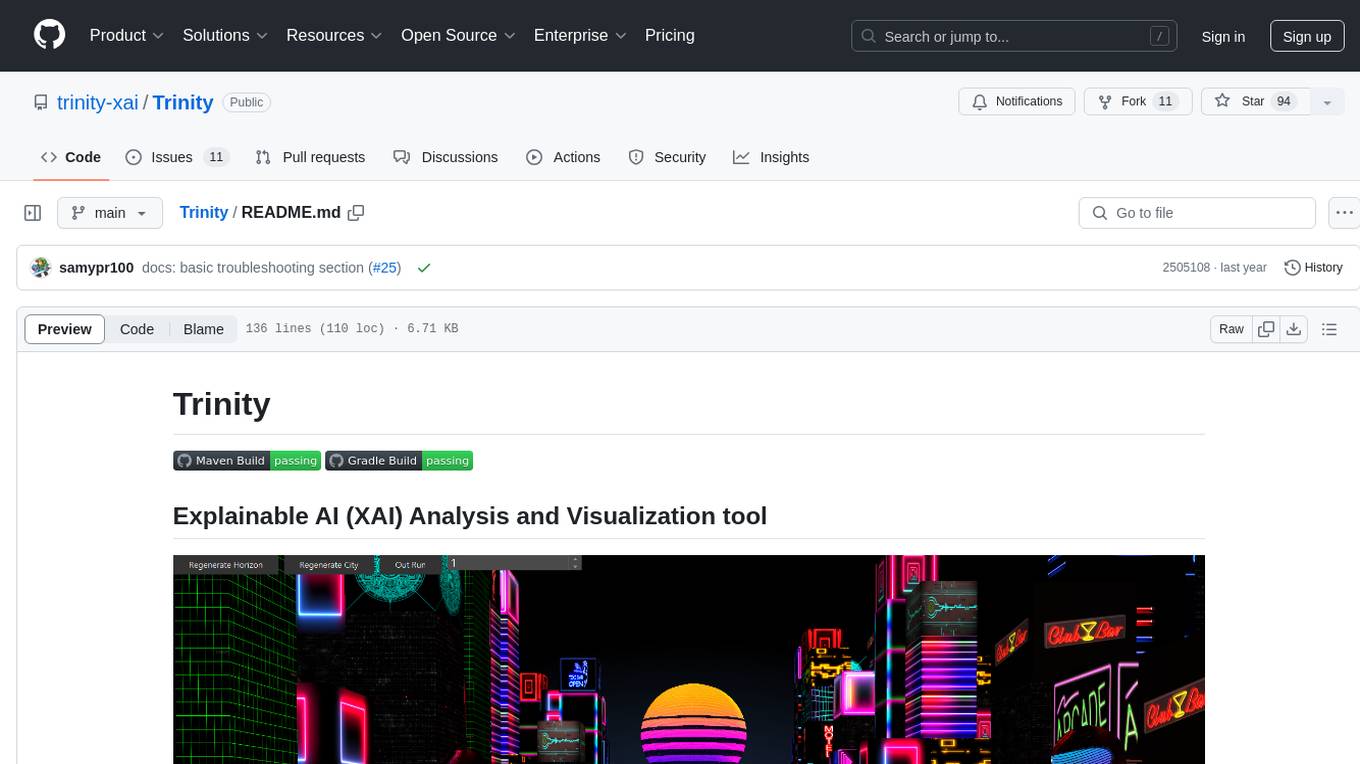
Trinity
Trinity is an Explainable AI (XAI) Analysis and Visualization tool designed for Deep Learning systems or other models performing complex classification or decoding. It provides performance analysis through interactive 3D projections that are hyper-dimensional aware, allowing users to explore hyperspace, hypersurface, projections, and manifolds. Trinity primarily works with JSON data formats and supports the visualization of FeatureVector objects. Users can analyze and visualize data points, correlate inputs with classification results, and create custom color maps for better data interpretation. Trinity has been successfully applied to various use cases including Deep Learning Object detection models, COVID gene/tissue classification, Brain Computer Interface decoders, and Large Language Model (ChatGPT) Embeddings Analysis.

llm-reasoners
LLM Reasoners is a library that enables LLMs to conduct complex reasoning, with advanced reasoning algorithms. It approaches multi-step reasoning as planning and searches for the optimal reasoning chain, which achieves the best balance of exploration vs exploitation with the idea of "World Model" and "Reward". Given any reasoning problem, simply define the reward function and an optional world model (explained below), and let LLM reasoners take care of the rest, including Reasoning Algorithms, Visualization, LLM calling, and more!

CogAgent
CogAgent is an advanced intelligent agent model designed for automating operations on graphical interfaces across various computing devices. It supports platforms like Windows, macOS, and Android, enabling users to issue commands, capture device screenshots, and perform automated operations. The model requires a minimum of 29GB of GPU memory for inference at BF16 precision and offers capabilities for executing tasks like sending Christmas greetings and sending emails. Users can interact with the model by providing task descriptions, platform specifications, and desired output formats.

gepa
GEPA (Genetic-Pareto) is a framework for optimizing arbitrary systems composed of text components like AI prompts, code snippets, or textual specs against any evaluation metric. It employs LLMs to reflect on system behavior, using feedback from execution and evaluation traces to drive targeted improvements. Through iterative mutation, reflection, and Pareto-aware candidate selection, GEPA evolves robust, high-performing variants with minimal evaluations, co-evolving multiple components in modular systems for domain-specific gains. The repository provides the official implementation of the GEPA algorithm as proposed in the paper titled 'GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning'.

Trace
Trace is a new AutoDiff-like tool for training AI systems end-to-end with general feedback. It generalizes the back-propagation algorithm by capturing and propagating an AI system's execution trace. Implemented as a PyTorch-like Python library, users can write Python code directly and use Trace primitives to optimize certain parts, similar to training neural networks.

llamabot
LlamaBot is a Pythonic bot interface to Large Language Models (LLMs), providing an easy way to experiment with LLMs in Jupyter notebooks and build Python apps utilizing LLMs. It supports all models available in LiteLLM. Users can access LLMs either through local models with Ollama or by using API providers like OpenAI and Mistral. LlamaBot offers different bot interfaces like SimpleBot, ChatBot, QueryBot, and ImageBot for various tasks such as rephrasing text, maintaining chat history, querying documents, and generating images. The tool also includes CLI demos showcasing its capabilities and supports contributions for new features and bug reports from the community.
nitrain
Nitrain is a framework for medical imaging AI that provides tools for sampling and augmenting medical images, training models on medical imaging datasets, and visualizing model results in a medical imaging context. It supports using pytorch, keras, and tensorflow.

kafka-ml
Kafka-ML is a framework designed to manage the pipeline of Tensorflow/Keras and PyTorch machine learning models on Kubernetes. It enables the design, training, and inference of ML models with datasets fed through Apache Kafka, connecting them directly to data streams like those from IoT devices. The Web UI allows easy definition of ML models without external libraries, catering to both experts and non-experts in ML/AI.

RLHF-Reward-Modeling
This repository contains code for training reward models for Deep Reinforcement Learning-based Reward-modulated Hierarchical Fine-tuning (DRL-based RLHF), Iterative Selection Fine-tuning (Rejection sampling fine-tuning), and iterative Decision Policy Optimization (DPO). The reward models are trained using a Bradley-Terry model based on the Gemma and Mistral language models. The resulting reward models achieve state-of-the-art performance on the RewardBench leaderboard for reward models with base models of up to 13B parameters.

langchain
LangChain is a framework for developing Elixir applications powered by language models. It enables applications to connect language models to other data sources and interact with the environment. The library provides components for working with language models and off-the-shelf chains for specific tasks. It aims to assist in building applications that combine large language models with other sources of computation or knowledge. LangChain is written in Elixir and is not aimed for parity with the JavaScript and Python versions due to differences in programming paradigms and design choices. The library is designed to make it easy to integrate language models into applications and expose features, data, and functionality to the models.

LongBench
LongBench v2 is a benchmark designed to assess the ability of large language models (LLMs) to handle long-context problems requiring deep understanding and reasoning across various real-world multitasks. It consists of 503 challenging multiple-choice questions with contexts ranging from 8k to 2M words, covering six major task categories. The dataset is collected from nearly 100 highly educated individuals with diverse professional backgrounds and is designed to be challenging even for human experts. The evaluation results highlight the importance of enhanced reasoning ability and scaling inference-time compute to tackle the long-context challenges in LongBench v2.

pydantic-ai
PydanticAI is a Python agent framework designed to make it less painful to build production grade applications with Generative AI. It is built by the Pydantic Team and supports various AI models like OpenAI, Anthropic, Gemini, Ollama, Groq, and Mistral. PydanticAI seamlessly integrates with Pydantic Logfire for real-time debugging, performance monitoring, and behavior tracking of LLM-powered applications. It is type-safe, Python-centric, and offers structured responses, dependency injection system, and streamed responses. PydanticAI is in early beta, offering a Python-centric design to apply standard Python best practices in AI-driven projects.

baal
Baal is an active learning library that supports both industrial applications and research use cases. It provides a framework for Bayesian active learning methods such as Monte-Carlo Dropout, MCDropConnect, Deep ensembles, and Semi-supervised learning. Baal helps in labeling the most uncertain items in the dataset pool to improve model performance and reduce annotation effort. The library is actively maintained by a dedicated team and has been used in various research papers for production and experimentation.
For similar tasks
Woodpecker
Woodpecker is a tool designed to correct hallucinations in Multimodal Large Language Models (MLLMs) by introducing a training-free method that picks out and corrects inconsistencies between generated text and image content. It consists of five stages: key concept extraction, question formulation, visual knowledge validation, visual claim generation, and hallucination correction. Woodpecker can be easily integrated with different MLLMs and provides interpretable results by accessing intermediate outputs of the stages. The tool has shown significant improvements in accuracy over baseline models like MiniGPT-4 and mPLUG-Owl.

MiniAI-Face-LivenessDetection-AndroidSDK
The MiniAiLive Face Liveness Detection Android SDK provides advanced computer vision techniques to enhance security and accuracy on Android platforms. It offers 3D Passive Face Liveness Detection capabilities, ensuring that users are physically present and not using spoofing methods to access applications or services. The SDK is fully on-premise, with all processing happening on the hosting server, ensuring data privacy and security.

AIMr
AIMr is an AI aimbot tool written in Python that leverages modern technologies to achieve an undetected system with a pleasing appearance. It works on any game that uses human-shaped models. To optimize its performance, users should build OpenCV with CUDA. For Valorant, additional perks in the Discord and an Arduino Leonardo R3 are required.
Fortnite-menu
Welcome to the Fortnite Menu repository! This project offers a multi-functional cheat for Valorant, providing features like Aimbot, Wallhack, ESP, No Recoil, Triggerbot, and Radar Hack to enhance your gameplay. Please note that using cheats in Fortnite is against Epic Games' terms of service and can lead to permanent bans. The repository is for educational purposes only, and fair play is encouraged.
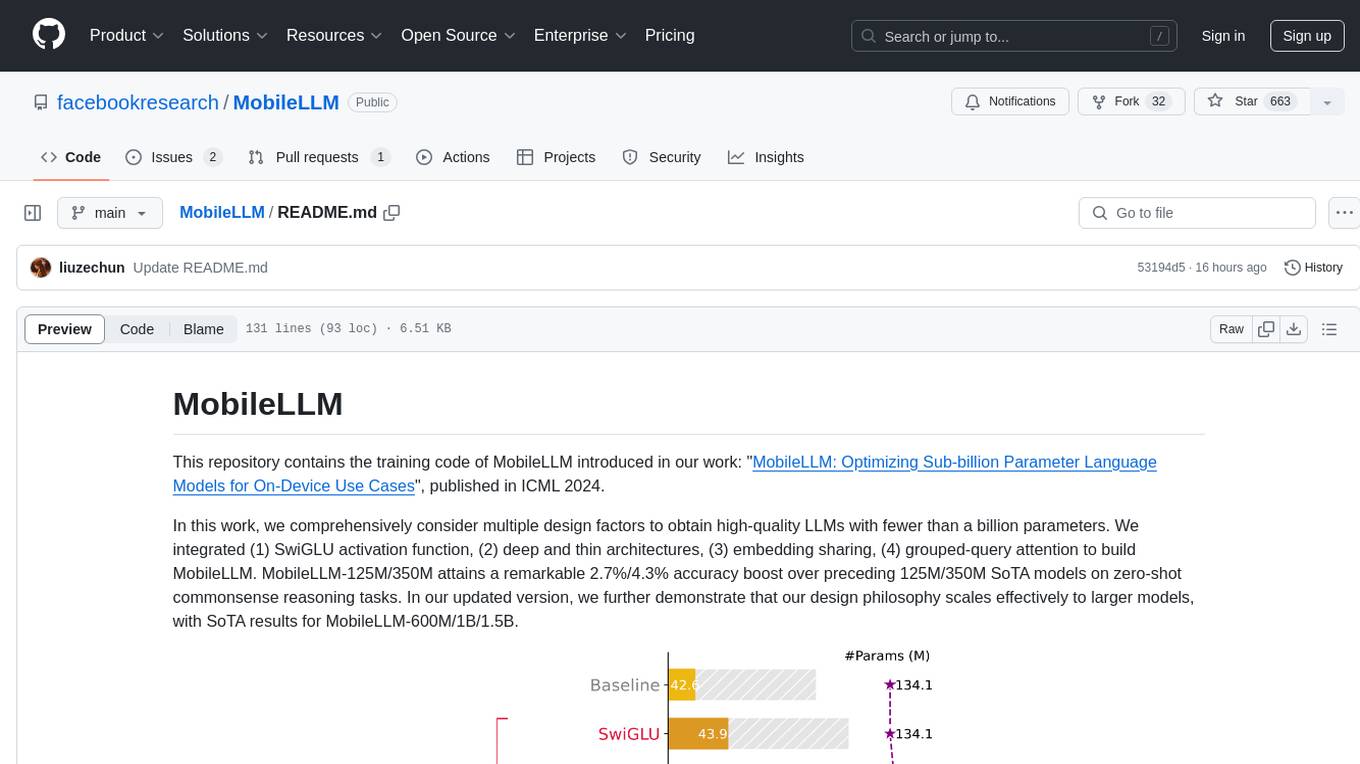
MobileLLM
This repository contains the training code of MobileLLM, a language model optimized for on-device use cases with fewer than a billion parameters. It integrates SwiGLU activation function, deep and thin architectures, embedding sharing, and grouped-query attention to achieve high-quality LLMs. MobileLLM-125M/350M shows significant accuracy improvements over previous models on zero-shot commonsense reasoning tasks. The design philosophy scales effectively to larger models, with state-of-the-art results for MobileLLM-600M/1B/1.5B.
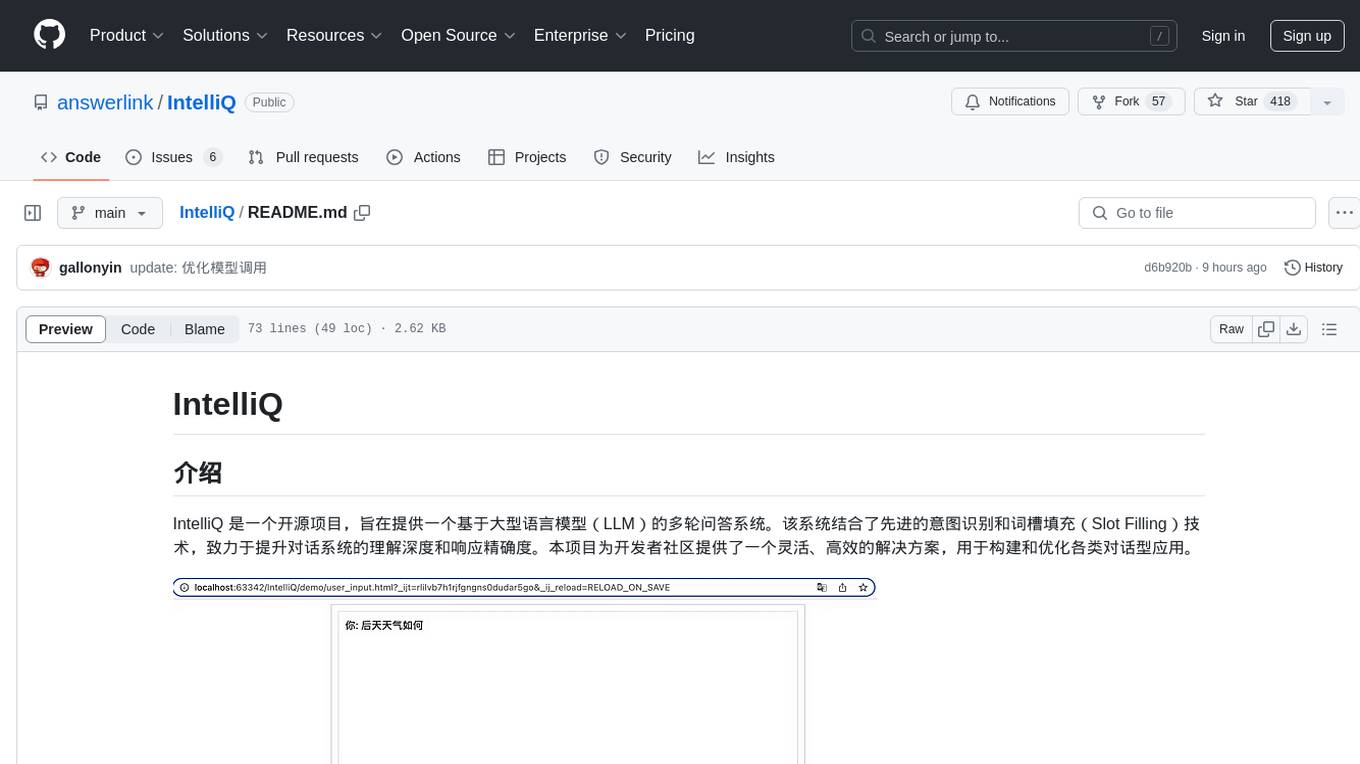
IntelliQ
IntelliQ is an open-source project aimed at providing a multi-turn question-answering system based on a large language model (LLM). The system combines advanced intent recognition and slot filling technology to enhance the depth of understanding and accuracy of responses in conversation systems. It offers a flexible and efficient solution for developers to build and optimize various conversational applications. The system features multi-turn dialogue management, intent recognition, slot filling, interface slot technology for real-time data retrieval and processing, adaptive learning for improving response accuracy and speed, and easy integration with detailed API documentation supporting multiple programming languages and platforms.
BetterOCR
BetterOCR is a tool that enhances text detection by combining multiple OCR engines with LLM (Language Model). It aims to improve OCR results, especially for languages with limited training data or noisy outputs. The tool combines results from EasyOCR, Tesseract, and Pororo engines, along with LLM support from OpenAI. Users can provide custom context for better accuracy, view performance examples by language, and upcoming features include box detection, improved interface, and async support. The package is under rapid development and contributions are welcomed.
flash-tokenizer
FlashTokenizer is a high-performance CPU tokenizer library implemented in C++ for LLM inference serving. It is 10 times faster than BertTokenizerFast in transformers, offering the highest speed and accuracy. Developed to be faster, more accurate, and easier to use than existing tokenizers like BertTokenizerFast, FlashTokenizer is implemented in C++ for straightforward maintenance. It supports parallel processing at the C++ level for batch encoding, delivering outstanding speed. The tokenizer is based on the LinMax Tokenizer proposed in Fast WordPiece Tokenization, enabling tokenization in linear time.
For similar jobs

tts-generation-webui
TTS Generation WebUI is a comprehensive tool that provides a user-friendly interface for text-to-speech and voice cloning tasks. It integrates various AI models such as Bark, MusicGen, AudioGen, Tortoise, RVC, Vocos, Demucs, SeamlessM4T, and MAGNeT. The tool offers one-click installers, Google Colab demo, videos for guidance, and extra voices for Bark. Users can generate audio outputs, manage models, caches, and system space for AI projects. The project is open-source and emphasizes ethical and responsible use of AI technology.
start-machine-learning
Start Machine Learning in 2024 is a comprehensive guide for beginners to advance in machine learning and artificial intelligence without any prior background. The guide covers various resources such as free online courses, articles, books, and practical tips to become an expert in the field. It emphasizes self-paced learning and provides recommendations for learning paths, including videos, podcasts, and online communities. The guide also includes information on building language models and applications, practicing through Kaggle competitions, and staying updated with the latest news and developments in AI. The goal is to empower individuals with the knowledge and resources to excel in machine learning and AI.
Woodpecker
Woodpecker is a tool designed to correct hallucinations in Multimodal Large Language Models (MLLMs) by introducing a training-free method that picks out and corrects inconsistencies between generated text and image content. It consists of five stages: key concept extraction, question formulation, visual knowledge validation, visual claim generation, and hallucination correction. Woodpecker can be easily integrated with different MLLMs and provides interpretable results by accessing intermediate outputs of the stages. The tool has shown significant improvements in accuracy over baseline models like MiniGPT-4 and mPLUG-Owl.

raga-llm-hub
Raga LLM Hub is a comprehensive evaluation toolkit for Language and Learning Models (LLMs) with over 100 meticulously designed metrics. It allows developers and organizations to evaluate and compare LLMs effectively, establishing guardrails for LLMs and Retrieval Augmented Generation (RAG) applications. The platform assesses aspects like Relevance & Understanding, Content Quality, Hallucination, Safety & Bias, Context Relevance, Guardrails, and Vulnerability scanning, along with Metric-Based Tests for quantitative analysis. It helps teams identify and fix issues throughout the LLM lifecycle, revolutionizing reliability and trustworthiness.
trustworthyAI
Trustworthy AI is a repository from Huawei Noah's Ark Lab containing works related to trustworthy AI. It includes a causal structure learning toolchain, information on causality-related competitions, real-world datasets, and research works on causality such as CausalVAE, GAE, and causal discovery with reinforcement learning.

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.