
curated-transformers
🤖 A PyTorch library of curated Transformer models and their composable components
Stars: 833

Curated Transformers is a transformer library for PyTorch that provides state-of-the-art models composed of reusable components. It supports various transformer architectures, including encoders like ALBERT, BERT, and RoBERTa, and decoders like Falcon, Llama, and MPT. The library emphasizes consistent type annotations, minimal dependencies, and ease of use for education and research. It has been production-tested by Explosion and will be the default transformer implementation in spaCy 3.7.
README:
![]()

State-of-the-art transformers, brick by brick
Curated Transformers is a transformer library for PyTorch. It provides state-of-the-art models that are composed from a set of reusable components. The stand-out features of Curated Transformer are:
- ⚡️ Supports state-of-the art transformer models, including LLMs such as Falcon, Llama, and Dolly v2.
- 👩🎨 Each model is composed from a set of reusable building blocks,
providing many benefits:
- Implementing a feature or bugfix benefits all models. For example,
all models support 4/8-bit inference through the
bitsandbyteslibrary and each model can use the PyTorchmetadevice to avoid unnecessary allocations and initialization. - Adding new models to the library is low-effort.
- Do you want to try a new transformer architecture? A BERT encoder with rotary embeddings? You can make it in a pinch.
- Implementing a feature or bugfix benefits all models. For example,
all models support 4/8-bit inference through the
- 💎 Consistent type annotations of all public APIs:
- Get great coding support from your IDE.
- Integrates well with your existing type-checked code.
- 🎓 Great for education, because the building blocks are easy to study.
- 📦 Minimal dependencies.
Curated Transformers has been production-tested by Explosion and will be used as the default transformer implementation in spaCy 3.7.
Supported encoder-only models:
- ALBERT
- BERT
- CamemBERT
- RoBERTa
- XLM-RoBERTa
Supported decoder-only models:
- Falcon
- GPT-NeoX
- Llama 1/2
- MPT
Generator wrappers:
- Dolly v2
- Falcon
- Llama 1/2
- MPT
All types of models can be loaded from Huggingface Hub.
spaCy integration for curated transformers is provided by the
spacy-curated-transformers
package.
pip install curated-transformersThe default Linux build of PyTorch is built with CUDA 11.7 support. You should explicitly install a CUDA build in the following cases:
- If you want to use Curated Transformers on Windows.
- If you want to use Curated Transformers on Linux with Ada-generation GPUs. The standard PyTorch build supports Ada GPUs, but you can get considerable performance improvements by installing PyTorch with CUDA 11.8 support.
In both cases, you can install PyTorch with:
pip install torch --index-url https://download.pytorch.org/whl/cu118>>> import torch
>>> from curated_transformers.generation import AutoGenerator, GreedyGeneratorConfig
>>> generator = AutoGenerator.from_hf_hub(name="tiiuae/falcon-7b-instruct", device=torch.device("cuda"))
>>> generator(["What is Python in one sentence?", "What is Rust in one sentence?"], GreedyGeneratorConfig())
['Python is a high-level programming language that is easy to learn and widely used for web development, data analysis, and automation.',
'Rust is a programming language that is designed to be a safe, concurrent, and efficient replacement for C++.']You can find more usage examples
in the documentation. You can also find example programs that use Curated Transformers in the
examples directory.
You can read more about how to use Curated Transformers here:
curated-transformers supports dynamic 8-bit and 4-bit quantization of models by leveraging the bitsandbytes library.
Use the quantization variant to automatically install the necessary dependencies:
pip install curated-transformers[quantization]For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for curated-transformers
Similar Open Source Tools
curated-transformers
Curated Transformers is a transformer library for PyTorch that provides state-of-the-art models composed of reusable components. It supports various transformer architectures, including encoders like ALBERT, BERT, and RoBERTa, and decoders like Falcon, Llama, and MPT. The library emphasizes consistent type annotations, minimal dependencies, and ease of use for education and research. It has been production-tested by Explosion and will be the default transformer implementation in spaCy 3.7.

lmql
LMQL is a programming language designed for large language models (LLMs) that offers a unique way of integrating traditional programming with LLM interaction. It allows users to write programs that combine algorithmic logic with LLM calls, enabling model reasoning capabilities within the context of the program. LMQL provides features such as Python syntax integration, rich control-flow options, advanced decoding techniques, powerful constraints via logit masking, runtime optimization, sync and async API support, multi-model compatibility, and extensive applications like JSON decoding and interactive chat interfaces. The tool also offers library integration, flexible tooling, and output streaming options for easy model output handling.

eole
EOLE is an open language modeling toolkit based on PyTorch. It aims to provide a research-friendly approach with a comprehensive yet compact and modular codebase for experimenting with various types of language models. The toolkit includes features such as versatile training and inference, dynamic data transforms, comprehensive large language model support, advanced quantization, efficient finetuning, flexible inference, and tensor parallelism. EOLE is a work in progress with ongoing enhancements in configuration management, command line entry points, reproducible recipes, core API simplification, and plans for further simplification, refactoring, inference server development, additional recipes, documentation enhancement, test coverage improvement, logging enhancements, and broader model support.

fuse-med-ml
FuseMedML is a Python framework designed to accelerate machine learning-based discovery in the medical field by promoting code reuse. It provides a flexible design concept where data is stored in a nested dictionary, allowing easy handling of multi-modality information. The framework includes components for creating custom models, loss functions, metrics, and data processing operators. Additionally, FuseMedML offers 'batteries included' key components such as fuse.data for data processing, fuse.eval for model evaluation, and fuse.dl for reusable deep learning components. It supports PyTorch and PyTorch Lightning libraries and encourages the creation of domain extensions for specific medical domains.

CogVideo
CogVideo is an open-source repository that provides pretrained text-to-video models for generating videos based on input text. It includes models like CogVideoX-2B and CogVideo, offering powerful video generation capabilities. The repository offers tools for inference, fine-tuning, and model conversion, along with demos showcasing the model's capabilities through CLI, web UI, and online experiences. CogVideo aims to facilitate the creation of high-quality videos from textual descriptions, catering to a wide range of applications.
craftium
Craftium is an open-source platform based on the Minetest voxel game engine and the Gymnasium and PettingZoo APIs, designed for creating fast, rich, and diverse single and multi-agent environments. It allows for connecting to Craftium's Python process, executing actions as keyboard and mouse controls, extending the Lua API for creating RL environments and tasks, and supporting client/server synchronization for slow agents. Craftium is fully extensible, extensively documented, modern RL API compatible, fully open source, and eliminates the need for Java. It offers a variety of environments for research and development in reinforcement learning.
rig
Rig is a Rust library designed for building scalable, modular, and user-friendly applications powered by large language models (LLMs). It provides full support for LLM completion and embedding workflows, offers simple yet powerful abstractions for LLM providers like OpenAI and Cohere, as well as vector stores such as MongoDB and in-memory storage. With Rig, users can easily integrate LLMs into their applications with minimal boilerplate code.

UltraRAG
The UltraRAG framework is a researcher and developer-friendly RAG system solution that simplifies the process from data construction to model fine-tuning in domain adaptation. It introduces an automated knowledge adaptation technology system, supporting no-code programming, one-click synthesis and fine-tuning, multidimensional evaluation, and research-friendly exploration work integration. The architecture consists of Frontend, Service, and Backend components, offering flexibility in customization and optimization. Performance evaluation in the legal field shows improved results compared to VanillaRAG, with specific metrics provided. The repository is licensed under Apache-2.0 and encourages citation for support.

BentoML
BentoML is an open-source model serving library for building performant and scalable AI applications with Python. It comes with everything you need for serving optimization, model packaging, and production deployment.

Easy-Translate
Easy-Translate is a script designed for translating large text files with a single command. It supports various models like M2M100, NLLB200, SeamlessM4T, LLaMA, and Bloom. The tool is beginner-friendly and offers seamless and customizable features for advanced users. It allows acceleration on CPU, multi-CPU, GPU, multi-GPU, and TPU, with support for different precisions and decoding strategies. Easy-Translate also provides an evaluation script for translations. Built on HuggingFace's Transformers and Accelerate library, it supports prompt usage and loading huge models efficiently.
AITemplate
AITemplate (AIT) is a Python framework that transforms deep neural networks into CUDA (NVIDIA GPU) / HIP (AMD GPU) C++ code for lightning-fast inference serving. It offers high performance close to roofline fp16 TensorCore (NVIDIA GPU) / MatrixCore (AMD GPU) performance on major models. AITemplate is unified, open, and flexible, supporting a comprehensive range of fusions for both GPU platforms. It provides excellent backward capability, horizontal fusion, vertical fusion, memory fusion, and works with or without PyTorch. FX2AIT is a tool that converts PyTorch models into AIT for fast inference serving, offering easy conversion and expanded support for models with unsupported operators.

magpie
This is the official repository for 'Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing'. Magpie is a tool designed to synthesize high-quality instruction data at scale by extracting it directly from an aligned Large Language Models (LLMs). It aims to democratize AI by generating large-scale alignment data and enhancing the transparency of model alignment processes. Magpie has been tested on various model families and can be used to fine-tune models for improved performance on alignment benchmarks such as AlpacaEval, ArenaHard, and WildBench.

qdrant
Qdrant is a vector similarity search engine and vector database. It is written in Rust, which makes it fast and reliable even under high load. Qdrant can be used for a variety of applications, including: * Semantic search * Image search * Product recommendations * Chatbots * Anomaly detection Qdrant offers a variety of features, including: * Payload storage and filtering * Hybrid search with sparse vectors * Vector quantization and on-disk storage * Distributed deployment * Highlighted features such as query planning, payload indexes, SIMD hardware acceleration, async I/O, and write-ahead logging Qdrant is available as a fully managed cloud service or as an open-source software that can be deployed on-premises.

chroma
Chroma is an open-source embedding database that provides a simple, scalable, and feature-rich way to build Python or JavaScript LLM apps with memory. It offers a fully-typed, fully-tested, and fully-documented API that makes it easy to get started and scale your applications. Chroma also integrates with popular tools like LangChain and LlamaIndex, and supports a variety of embedding models, including Sentence Transformers, OpenAI embeddings, and Cohere embeddings. With Chroma, you can easily add documents to your database, query relevant documents with natural language, and compose documents into the context window of an LLM like GPT3 for additional summarization or analysis.

spacy-llm
This package integrates Large Language Models (LLMs) into spaCy, featuring a modular system for **fast prototyping** and **prompting** , and turning unstructured responses into **robust outputs** for various NLP tasks, **no training data** required. It supports open-source LLMs hosted on Hugging Face 🤗: Falcon, Dolly, Llama 2, OpenLLaMA, StableLM, Mistral. Integration with LangChain 🦜️🔗 - all `langchain` models and features can be used in `spacy-llm`. Tasks available out of the box: Named Entity Recognition, Text classification, Lemmatization, Relationship extraction, Sentiment analysis, Span categorization, Summarization, Entity linking, Translation, Raw prompt execution for maximum flexibility. Soon: Semantic role labeling. Easy implementation of **your own functions** via spaCy's registry for custom prompting, parsing and model integrations. For an example, see here. Map-reduce approach for splitting prompts too long for LLM's context window and fusing the results back together

llm-on-ray
LLM-on-Ray is a comprehensive solution for building, customizing, and deploying Large Language Models (LLMs). It simplifies complex processes into manageable steps by leveraging the power of Ray for distributed computing. The tool supports pretraining, finetuning, and serving LLMs across various hardware setups, incorporating industry and Intel optimizations for performance. It offers modular workflows with intuitive configurations, robust fault tolerance, and scalability. Additionally, it provides an Interactive Web UI for enhanced usability, including a chatbot application for testing and refining models.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs
curated-transformers
Curated Transformers is a transformer library for PyTorch that provides state-of-the-art models composed of reusable components. It supports various transformer architectures, including encoders like ALBERT, BERT, and RoBERTa, and decoders like Falcon, Llama, and MPT. The library emphasizes consistent type annotations, minimal dependencies, and ease of use for education and research. It has been production-tested by Explosion and will be the default transformer implementation in spaCy 3.7.

bert4torch
**bert4torch** is a high-level framework for training and deploying transformer models in PyTorch. It provides a simple and efficient API for building, training, and evaluating transformer models, and supports a wide range of pre-trained models, including BERT, RoBERTa, ALBERT, XLNet, and GPT-2. bert4torch also includes a number of useful features, such as data loading, tokenization, and model evaluation. It is a powerful and versatile tool for natural language processing tasks.
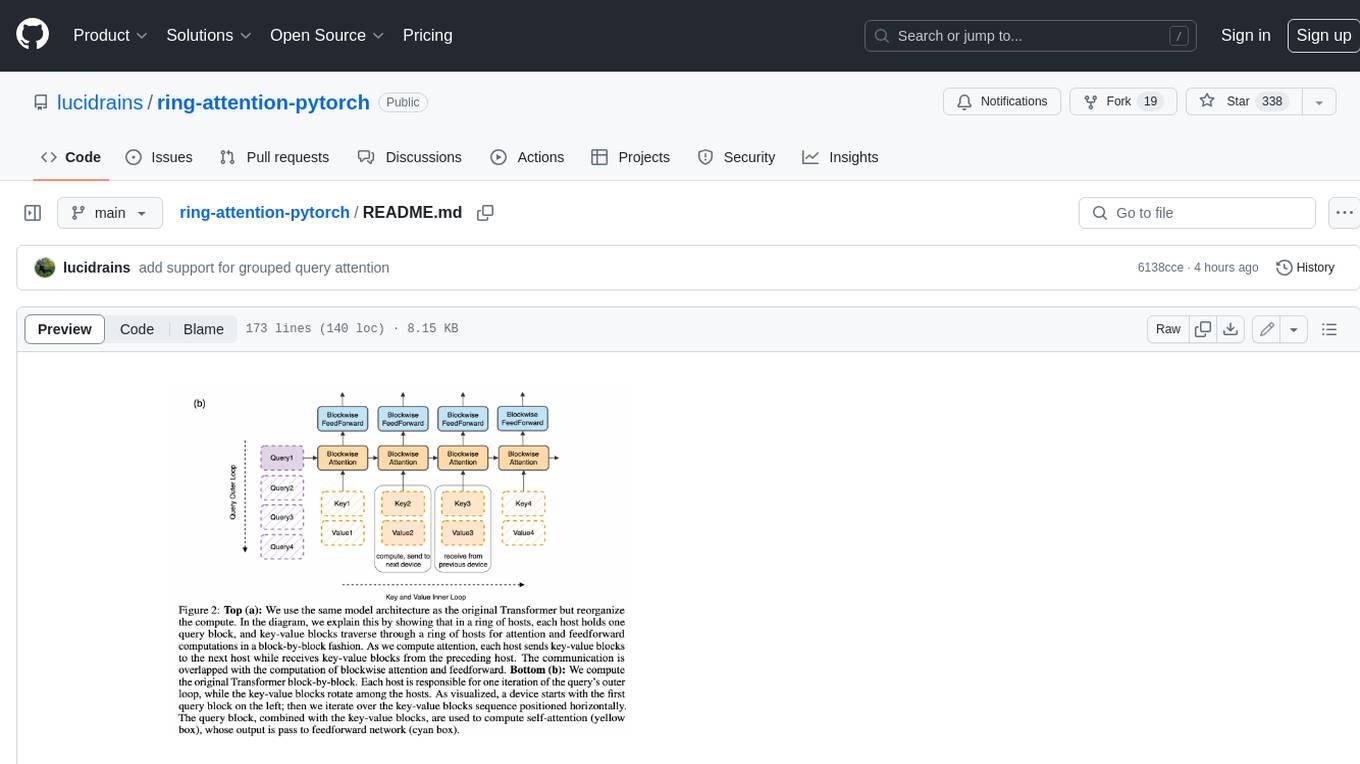
ring-attention-pytorch
This repository contains an implementation of Ring Attention, a technique for processing large sequences in transformers. Ring Attention splits the data across the sequence dimension and applies ring reduce to the processing of the tiles of the attention matrix, similar to flash attention. It also includes support for Striped Attention, a follow-up paper that permutes the sequence for better workload balancing for autoregressive transformers, and grouped query attention, which saves on communication costs during the ring reduce. The repository includes a CUDA version of the flash attention kernel, which is used for the forward and backward passes of the ring attention. It also includes logic for splitting the sequence evenly among ranks, either within the attention function or in the external ring transformer wrapper, and basic test cases with two processes to check for equivalent output and gradients.

FlagEmbedding
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently: * **Long-Context LLM** : Activation Beacon * **Fine-tuning of LM** : LM-Cocktail * **Embedding Model** : Visualized-BGE, BGE-M3, LLM Embedder, BGE Embedding * **Reranker Model** : llm rerankers, BGE Reranker * **Benchmark** : C-MTEB

edenai-apis
Eden AI aims to simplify the use and deployment of AI technologies by providing a unique API that connects to all the best AI engines. With the rise of **AI as a Service** , a lot of companies provide off-the-shelf trained models that you can access directly through an API. These companies are either the tech giants (Google, Microsoft , Amazon) or other smaller, more specialized companies, and there are hundreds of them. Some of the most known are : DeepL (translation), OpenAI (text and image analysis), AssemblyAI (speech analysis). There are **hundreds of companies** doing that. We're regrouping the best ones **in one place** !

llm2vec
LLM2Vec is a simple recipe to convert decoder-only LLMs into text encoders. It consists of 3 simple steps: 1) enabling bidirectional attention, 2) training with masked next token prediction, and 3) unsupervised contrastive learning. The model can be further fine-tuned to achieve state-of-the-art performance.
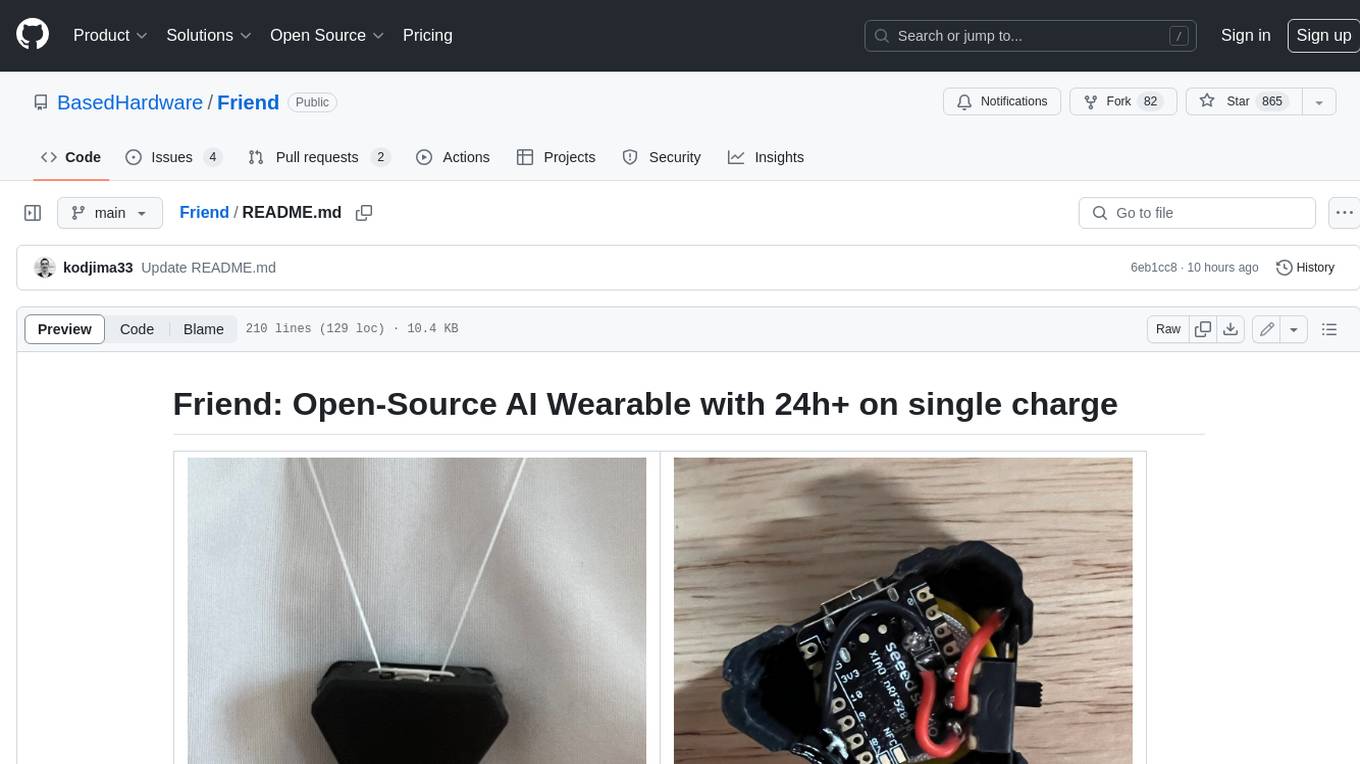
Friend
Friend is an open-source AI wearable device that records everything you say, gives you proactive feedback and advice. It has real-time AI audio processing capabilities, low-powered Bluetooth, open-source software, and a wearable design. The device is designed to be affordable and easy to use, with a total cost of less than $20. To get started, you can clone the repo, choose the version of the app you want to install, and follow the instructions for installing the firmware and assembling the device. Friend is still a prototype project and is provided "as is", without warranty of any kind. Use of the device should comply with all local laws and regulations concerning privacy and data protection.

clarifai-python
The Clarifai Python SDK offers a comprehensive set of tools to integrate Clarifai's AI platform to leverage computer vision capabilities like classification , detection ,segementation and natural language capabilities like classification , summarisation , generation , Q&A ,etc into your applications. With just a few lines of code, you can leverage cutting-edge artificial intelligence to unlock valuable insights from visual and textual content.