
clarifai-python
Experience the power of Clarifai’s AI platform with the python SDK. 🌟 Star to support our work!
Stars: 392

The Clarifai Python SDK offers a comprehensive set of tools to integrate Clarifai's AI platform to leverage computer vision capabilities like classification , detection ,segementation and natural language capabilities like classification , summarisation , generation , Q&A ,etc into your applications. With just a few lines of code, you can leverage cutting-edge artificial intelligence to unlock valuable insights from visual and textual content.
README:


This is the official Python client for interacting with our powerful API. The Clarifai Python SDK offers a comprehensive set of tools to integrate Clarifai's AI platform to leverage computer vision capabilities like classification , detection ,segementation and natural language capabilities like classification , summarisation , generation , Q&A ,etc into your applications. With just a few lines of code, you can leverage cutting-edge artificial intelligence to unlock valuable insights from visual and textual content.
Website | Schedule Demo | Signup for a Free Account | API Docs | Clarifai Community | Python SDK Docs | Examples | Colab Notebooks | Discord
- Installation
- Getting Started
- Interacting with Datasets
- Interacting with Inputs
- Interacting with Models
- Interacting with Workflows
- Search
- Retrieval Augmented Generation (RAG)
- More Examples
Install from PyPi:
pip install -U clarifaiInstall from Source:
git clone https://github.com/Clarifai/clarifai-python.git
cd clarifai-python
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
python setup.py installClarifai uses Personal Access Tokens(PATs) to validate requests. You can create and manage PATs under your Clarifai account security settings.
-
🔗 Create PAT: Log into Portal → Profile Icon → Security Settings → Create Personal Access Token → Set the scopes → Confirm
-
🔗 Get User ID: Log into Portal → Profile Icon → Account → Profile → User-ID
Export your PAT as an environment variable. Then, import and initialize the API Client.
Set PAT as environment variable through terminal:
export CLARIFAI_PAT={your personal access token}# Note: CLARIFAI_PAT must be set as env variable.
from clarifai.client.user import User
client = User(user_id="user_id")
# Get all apps
apps_generator = client.list_apps()
apps = list(apps_generator)OR
PAT can be passed as constructor argument
from clarifai.client.user import User
client = User(user_id="user_id", pat="your personal access token")Clarifai datasets help in managing datasets used for model training and evaluation. It provides functionalities like creating datasets,uploading datasets, retrying failed uploads from logs and exporting datasets as .zip files.
# Note: CLARIFAI_PAT must be set as env variable.
# Create app and dataset
app = client.create_app(app_id="demo_app", base_workflow="Universal")
dataset = app.create_dataset(dataset_id="demo_dataset")
# execute data upload to Clarifai app dataset
from clarifai.datasets.upload.laoders.coco_detection import COCODetectionDataLoader
coco_dataloader = COCODetectionDataLoader("images_dir", "coco_annotation_filepath")
dataset.upload_dataset(dataloader=coco_dataloader, get_upload_status=True)
#Try upload and record the failed outputs in log file.
from clarifai.datasets.upload.utils import load_module_dataloader
cifar_dataloader = load_module_dataloader('./image_classification/cifar10')
dataset.upload_dataset(dataloader=cifar_dataloader,
get_upload_status=True,
log_warnings =True)
#Retry upload from logs for `upload_dataset`
# Set retry_duplicates to True if you want to ingest failed inputs due to duplication issues. by default it is set to 'False'.
dataset.retry_upload_from_logs(dataloader=cifar_dataloader, log_file_path='log_file.log',
retry_duplicates=True,
log_warnings=True)
#upload text from csv
dataset.upload_from_csv(csv_path='csv_path', input_type='text', csv_type='raw', labels=True)
#upload data from folder
dataset.upload_from_folder(folder_path='folder_path', input_type='text', labels=True)
# Export Dataset
dataset.export(save_path='output.zip')You can use inputs() for adding and interacting with input data. Inputs can be uploaded directly from a URL or a file. You can also view input annotations and concepts.
# Note: CLARIFAI_PAT must be set as env variable.
from clarifai.client.user import User
app = User(user_id="user_id").app(app_id="app_id")
input_obj = app.inputs()
#input upload from url
input_obj.upload_from_url(input_id = 'demo', image_url='https://samples.clarifai.com/metro-north.jpg')
#input upload from filename
input_obj.upload_from_file(input_id = 'demo', video_file='demo.mp4')
# text upload
input_obj.upload_text(input_id = 'demo', raw_text = 'This is a test')#listing inputs
input_generator = input_obj.list_inputs(page_no=1,per_page=10,input_type='image')
inputs_list = list(input_generator)
#listing annotations
annotation_generator = input_obj.list_annotations(batch_input=inputs_list)
annotations_list = list(annotation_generator)
#listing concepts
all_concepts = list(app.list_concepts())#listing inputs
input_generator = input_obj.list_inputs(page_no=1,per_page=1,input_type='image')
inputs_list = list(input_generator)
#downloading_inputs
input_bytes = input_obj.download_inputs(inputs_list)
with open('demo.jpg','wb') as f:
f.write(input_bytes[0])The Model Class allows you to perform predictions using Clarifai models. You can specify which model to use by providing the model URL or ID. This gives you flexibility in choosing models. The App Class also allows listing of all available Clarifai models for discovery.
For greater control over model predictions, you can pass in an output_config to modify the model output as demonstrated below.
# Note: CLARIFAI_PAT must be set as env variable.
from clarifai.client.model import Model
"""
Get Model information on details of model(description, usecases..etc) and info on training or
# other inference parameters(eg: temperature, top_k, max_tokens..etc for LLMs)
"""
gpt_4_model = Model("https://clarifai.com/openai/chat-completion/models/GPT-4")
print(gpt_4_model)
# Model Predict
model_prediction = Model("https://clarifai.com/anthropic/completion/models/claude-v2").predict_by_bytes(b"Write a tweet on future of AI", input_type="text")
# Customizing Model Inference Output
model_prediction = gpt_4_model.predict_by_bytes(b"Write a tweet on future of AI", "text", inference_params=dict(temperature=str(0.7), max_tokens=30))
# Return predictions having prediction confidence > 0.98
model_prediction = model.predict_by_filepath(filepath="local_filepath", input_type, output_config={"min_value": 0.98}) # Supports image, text, audio, video
# Supports prediction by url
model_prediction = model.predict_by_url(url="url", input_type) # Supports image, text, audio, video
# Return predictions for specified interval of video
video_input_proto = [input_obj.get_input_from_url("Input_id", video_url=BEER_VIDEO_URL)]
model_prediction = model.predict(video_input_proto, input_type="video", output_config={"sample_ms": 2000})# Note: CLARIFAI_PAT must be set as env variable.
from clarifai.client.app import App
from clarifai.client.model import Model
"""
Create model with trainable model_type
"""
app = App(user_id="user_id", app_id="app_id")
model = app.create_model(model_id="model_id", model_type_id="visual-classifier")
(or)
model = Model('url')
"""
List training templates for the model_type
"""
templates = model.list_training_templates()
print(templates)
"""
Get parameters for the model.
"""
params = model.get_params(template='classification_basemodel_v1', save_to='model_params.yaml')
"""
Update the model params yaml and pass it to model.train()
"""
model_version_id = model.train('model_params.yaml')
"""
Training status and saving logs
"""
status = model.training_status(version_id=model_version_id,training_logs=True)
print(status)Model Export feature enables you to package your trained model into a model.tar file. This file enables deploying your model within a Triton Inference Server deployment.
from clarifai.client.model import Model
model = Model('url')
model.export('output/folder/')When your model is trained and ready, you can evaluate by the following code
from clarifai.client.model import Model
model = Model('url')
model.evaluate(dataset_id='your-dataset-id')Compare the evaluation results of your models.
from clarifai.client.model import Model
from clarifai.client.dataset import Dataset
from clarifai.utils.evaluation import EvalResultCompare
models = ['model url1', 'model url2'] # or [Model(url1), Model(url2)]
dataset = 'dataset url' # or Dataset(dataset_url)
compare = EvalResultCompare(
models=models,
datasets=dataset,
attempt_evaluate=True # attempt evaluate when the model is not evaluated with the dataset
)
compare.all('output/folder/')# Note: CLARIFAI_PAT must be set as env variable.
# List all model versions
all_model_versions = list(model.list_versions())
# Go to specific model version
model_v1 = client.app("app_id").model(model_id="model_id", model_version_id="model_version_id")
# List all models in an app
all_models = list(app.list_models())
# List all models in community filtered by model_type, description
all_llm_community_models = App().list_models(filter_by={"query": "LLM",
"model_type_id": "text-to-text"}, only_in_app=False)
all_llm_community_models = list(all_llm_community_models)Workflows offer a versatile framework for constructing the inference pipeline, simplifying the integration of diverse models. You can use the Workflow class to create and manage workflows using YAML configuration. For starting or making quick adjustments to existing Clarifai community workflows using an initial YAML configuration, the SDK provides an export feature.
# Note: CLARIFAI_PAT must be set as env variable.
from clarifai.client.workflow import Workflow
# Workflow Predict
workflow = Workflow("workflow_url") # Example: https://clarifai.com/clarifai/main/workflows/Face-Sentiment
workflow_prediction = workflow.predict_by_url(url="url", input_type="image") # Supports image, text, audio, video
# Customizing Workflow Inference Output
workflow = Workflow(user_id="user_id", app_id="app_id", workflow_id="workflow_id",
output_config={"min_value": 0.98}) # Return predictions having prediction confidence > 0.98
workflow_prediction = workflow.predict_by_filepath(filepath="local_filepath", input_type="text") # Supports image, text, audio, video# Note: CLARIFAI_PAT must be set as env variable.
# List all workflow versions
all_workflow_versions = list(workflow.list_versions())
# Go to specific workflow version
workflow_v1 = Workflow(workflow_id="workflow_id", workflow_version=dict(id="workflow_version_id"), app_id="app_id", user_id="user_id")
# List all workflow in an app
all_workflow = list(app.list_workflow())
# List all workflow in community filtered by description
all_face_community_workflows = App().list_workflows(filter_by={"query": "face"}, only_in_app=False) # Get all face related workflows
all_face_community_workflows = list(all_face_community_workflows)Create a new workflow specified by a yaml config file.
# Note: CLARIFAI_PAT must be set as env variable.
from clarifai.client.app import App
app = App(app_id="app_id", user_id="user_id")
workflow = app.create_workflow(config_filepath="config.yml")Export an existing workflow from Clarifai as a local yaml file.
# Note: CLARIFAI_PAT must be set as env variable.
from clarifai.client.workflow import Workflow
workflow = Workflow("https://clarifai.com/clarifai/main/workflows/Demographics")
workflow.export('demographics_workflow.yml')Clarifai's Smart Search feature leverages vector search capabilities to power the search experience. Vector search is a type of search engine that uses vectors to search and retrieve text, images, and videos.
Instead of traditional keyword-based search, where exact matches are sought, vector search allows for searching based on visual and/or semantic similarity by calculating distances between vector embedding representations of the data.
Here is an example of how to use vector search to find similar images:
# Note: CLARIFAI_PAT must be set as env variable.
from clarifai.client.search import Search
search = Search(user_id="user_id", app_id="app_id", top_k=1, metric="cosine")
# Search by image url
results = search.query(ranks=[{"image_url": "https://samples.clarifai.com/metro-north.jpg"}])
for data in results:
print(data.hits[0].input.data.image.url)Smart Text Search is our proprietary feature that uses deep learning techniques to sort, rank, and retrieve text data based on their content and semantic similarity.
Here is an example of how to use Smart Text Search to find similar text:
# Note: CLARIFAI_PAT must be set as env variable.
# Search by text
results = search.query(ranks=[{"text_raw": "I love my dog"}])You can use filters to narrow down your search results. Filters can be used to filter by concepts, metadata, and Geo Point.
It is possible to add together multiple search parameters to expand your search. You can even combine negated search terms for more advanced tasks.
For example, you can combine two concepts as below.
# query for images that contain concept "deer" or "dog"
results = search.query(ranks=[{"image_url": "https://samples.clarifai.com/metro-north.jpg"}],
filters=[{"concepts": [{"name": "deer", "value":1},
{"name": "dog", "value":1}]}])
# query for images that contain concepts "deer" and "dog"
results = search.query(ranks=[{"image_url": "https://samples.clarifai.com/metro-north.jpg"}],
filters=[{"concepts": [{"name": "deer", "value":1}],
"concepts": [{"name": "dog", "value":1}]}])Input filters allows to filter by input_type, status of inputs and by inputs_dataset_id
results = search.query(filters=[{'input_types': ['image', 'text']}])Below is an example of using Search with Pagination.
# Note: CLARIFAI_PAT must be set as env variable.
from clarifai.client.search import Search
search = Search(user_id="user_id", app_id="app_id", metric="cosine", pagination=True)
# Search by image url
results = search.query(ranks=[{"image_url": "https://samples.clarifai.com/metro-north.jpg"}],page_no=2,per_page=5)
for data in results:
print(data.hits[0].input.data.image.url)You can setup and start your RAG pipeline in 4 lines of code. The setup method automatically creates a new app and the necessary components under the hood. By default it uses the mistral-7B-Instruct model.
from clarifai.rag import RAG
rag_agent = RAG.setup(user_id="USER_ID")
rag_agent.upload(folder_path="~/docs")
rag_agent.chat(messages=[{"role":"human", "content":"What is Clarifai"}])If you have previously run the setup method, you can instantiate the RAG class with the prompter workflow URL:
from clarifai.rag import RAG
rag_agent = RAG(workflow_url="WORKFLOW_URL")See many more code examples in this repo. Also see the official Python SDK docs
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for clarifai-python
Similar Open Source Tools
clarifai-python
The Clarifai Python SDK offers a comprehensive set of tools to integrate Clarifai's AI platform to leverage computer vision capabilities like classification , detection ,segementation and natural language capabilities like classification , summarisation , generation , Q&A ,etc into your applications. With just a few lines of code, you can leverage cutting-edge artificial intelligence to unlock valuable insights from visual and textual content.
aiavatarkit
AIAvatarKit is a tool for building AI-based conversational avatars quickly. It supports various platforms like VRChat and cluster, along with real-world devices. The tool is extensible, allowing unlimited capabilities based on user needs. It requires VOICEVOX API, Google or Azure Speech Services API keys, and Python 3.10. Users can start conversations out of the box and enjoy seamless interactions with the avatars.
SimplerLLM
SimplerLLM is an open-source Python library that simplifies interactions with Large Language Models (LLMs) for researchers and beginners. It provides a unified interface for different LLM providers, tools for enhancing language model capabilities, and easy development of AI-powered tools and apps. The library offers features like unified LLM interface, generic text loader, RapidAPI connector, SERP integration, prompt template builder, and more. Users can easily set up environment variables, create LLM instances, use tools like SERP, generic text loader, calling RapidAPI APIs, and prompt template builder. Additionally, the library includes chunking functions to split texts into manageable chunks based on different criteria. Future updates will bring more tools, interactions with local LLMs, prompt optimization, response evaluation, GPT Trainer, document chunker, advanced document loader, integration with more providers, Simple RAG with SimplerVectors, integration with vector databases, agent builder, and LLM server.

instructor
Instructor is a popular Python library for managing structured outputs from large language models (LLMs). It offers a user-friendly API for validation, retries, and streaming responses. With support for various LLM providers and multiple languages, Instructor simplifies working with LLM outputs. The library includes features like response models, retry management, validation, streaming support, and flexible backends. It also provides hooks for logging and monitoring LLM interactions, and supports integration with Anthropic, Cohere, Gemini, Litellm, and Google AI models. Instructor facilitates tasks such as extracting user data from natural language, creating fine-tuned models, managing uploaded files, and monitoring usage of OpenAI models.

instructor
Instructor is a Python library that makes it a breeze to work with structured outputs from large language models (LLMs). Built on top of Pydantic, it provides a simple, transparent, and user-friendly API to manage validation, retries, and streaming responses. Get ready to supercharge your LLM workflows!

FlashLearn
FlashLearn is a tool that provides a simple interface and orchestration for incorporating Agent LLMs into workflows and ETL pipelines. It allows data transformations, classifications, summarizations, rewriting, and custom multi-step tasks using LLMs. Each step and task has a compact JSON definition, making pipelines easy to understand and maintain. FlashLearn supports LiteLLM, Ollama, OpenAI, DeepSeek, and other OpenAI-compatible clients.
funcchain
Funcchain is a Python library that allows you to easily write cognitive systems by leveraging Pydantic models as output schemas and LangChain in the backend. It provides a seamless integration of LLMs into your apps, utilizing OpenAI Functions or LlamaCpp grammars (json-schema-mode) for efficient structured output. Funcchain compiles the Funcchain syntax into LangChain runnables, enabling you to invoke, stream, or batch process your pipelines effortlessly.

LightRAG
LightRAG is a repository hosting the code for LightRAG, a system that supports seamless integration of custom knowledge graphs, Oracle Database 23ai, Neo4J for storage, and multiple file types. It includes features like entity deletion, batch insert, incremental insert, and graph visualization. LightRAG provides an API server implementation for RESTful API access to RAG operations, allowing users to interact with it through HTTP requests. The repository also includes evaluation scripts, code for reproducing results, and a comprehensive code structure.
genaiscript
GenAIScript is a scripting environment designed to facilitate file ingestion, prompt development, and structured data extraction. Users can define metadata and model configurations, specify data sources, and define tasks to extract specific information. The tool provides a convenient way to analyze files and extract desired content in a structured format. It offers a user-friendly interface for working with data and automating data extraction processes, making it suitable for various data processing tasks.

langchainrb
Langchain.rb is a Ruby library that makes it easy to build LLM-powered applications. It provides a unified interface to a variety of LLMs, vector search databases, and other tools, making it easy to build and deploy RAG (Retrieval Augmented Generation) systems and assistants. Langchain.rb is open source and available under the MIT License.

sparkle
Sparkle is a tool that streamlines the process of building AI-driven features in applications using Large Language Models (LLMs). It guides users through creating and managing agents, defining tools, and interacting with LLM providers like OpenAI. Sparkle allows customization of LLM provider settings, model configurations, and provides a seamless integration with Sparkle Server for exposing agents via an OpenAI-compatible chat API endpoint.

deep-searcher
DeepSearcher is a tool that combines reasoning LLMs and Vector Databases to perform search, evaluation, and reasoning based on private data. It is suitable for enterprise knowledge management, intelligent Q&A systems, and information retrieval scenarios. The tool maximizes the utilization of enterprise internal data while ensuring data security, supports multiple embedding models, and provides support for multiple LLMs for intelligent Q&A and content generation. It also includes features like private data search, vector database management, and document loading with web crawling capabilities under development.

GraphRAG-SDK
Build fast and accurate GenAI applications with GraphRAG SDK, a specialized toolkit for building Graph Retrieval-Augmented Generation (GraphRAG) systems. It integrates knowledge graphs, ontology management, and state-of-the-art LLMs to deliver accurate, efficient, and customizable RAG workflows. The SDK simplifies the development process by automating ontology creation, knowledge graph agent creation, and query handling, enabling users to interact and query their knowledge graphs effectively. It supports multi-agent systems and orchestrates agents specialized in different domains. The SDK is optimized for FalkorDB, ensuring high performance and scalability for large-scale applications. By leveraging knowledge graphs, it enables semantic relationships and ontology-driven queries that go beyond standard vector similarity, enhancing retrieval-augmented generation capabilities.

syncode
SynCode is a novel framework for the grammar-guided generation of Large Language Models (LLMs) that ensures syntactically valid output based on a Context-Free Grammar (CFG). It supports various programming languages like Python, Go, SQL, Math, JSON, and more. Users can define custom grammars using EBNF syntax. SynCode offers fast generation, seamless integration with HuggingFace Language Models, and the ability to sample with different decoding strategies.

instructor
Instructor is a tool that provides structured outputs from Large Language Models (LLMs) in a reliable manner. It simplifies the process of extracting structured data by utilizing Pydantic for validation, type safety, and IDE support. With Instructor, users can define models and easily obtain structured data without the need for complex JSON parsing, error handling, or retries. The tool supports automatic retries, streaming support, and extraction of nested objects, making it production-ready for various AI applications. Trusted by a large community of developers and companies, Instructor is used by teams at OpenAI, Google, Microsoft, AWS, and YC startups.

syncode
SynCode is a novel framework for the grammar-guided generation of Large Language Models (LLMs) that ensures syntactically valid output with respect to defined Context-Free Grammar (CFG) rules. It supports general-purpose programming languages like Python, Go, SQL, JSON, and more, allowing users to define custom grammars using EBNF syntax. The tool compares favorably to other constrained decoders and offers features like fast grammar-guided generation, compatibility with HuggingFace Language Models, and the ability to work with various decoding strategies.
For similar tasks

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

InternVL
InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM. It is a vision-language foundation model that can perform various tasks, including: **Visual Perception** - Linear-Probe Image Classification - Semantic Segmentation - Zero-Shot Image Classification - Multilingual Zero-Shot Image Classification - Zero-Shot Video Classification **Cross-Modal Retrieval** - English Zero-Shot Image-Text Retrieval - Chinese Zero-Shot Image-Text Retrieval - Multilingual Zero-Shot Image-Text Retrieval on XTD **Multimodal Dialogue** - Zero-Shot Image Captioning - Multimodal Benchmarks with Frozen LLM - Multimodal Benchmarks with Trainable LLM - Tiny LVLM InternVL has been shown to achieve state-of-the-art results on a variety of benchmarks. For example, on the MMMU image classification benchmark, InternVL achieves a top-1 accuracy of 51.6%, which is higher than GPT-4V and Gemini Pro. On the DocVQA question answering benchmark, InternVL achieves a score of 82.2%, which is also higher than GPT-4V and Gemini Pro. InternVL is open-sourced and available on Hugging Face. It can be used for a variety of applications, including image classification, object detection, semantic segmentation, image captioning, and question answering.
clarifai-python
The Clarifai Python SDK offers a comprehensive set of tools to integrate Clarifai's AI platform to leverage computer vision capabilities like classification , detection ,segementation and natural language capabilities like classification , summarisation , generation , Q&A ,etc into your applications. With just a few lines of code, you can leverage cutting-edge artificial intelligence to unlock valuable insights from visual and textual content.

X-AnyLabeling
X-AnyLabeling is a robust annotation tool that seamlessly incorporates an AI inference engine alongside an array of sophisticated features. Tailored for practical applications, it is committed to delivering comprehensive, industrial-grade solutions for image data engineers. This tool excels in swiftly and automatically executing annotations across diverse and intricate tasks.

ailia-models
The collection of pre-trained, state-of-the-art AI models. ailia SDK is a self-contained, cross-platform, high-speed inference SDK for AI. The ailia SDK provides a consistent C++ API across Windows, Mac, Linux, iOS, Android, Jetson, and Raspberry Pi platforms. It also supports Unity (C#), Python, Rust, Flutter(Dart) and JNI for efficient AI implementation. The ailia SDK makes extensive use of the GPU through Vulkan and Metal to enable accelerated computing. # Supported models 323 models as of April 8th, 2024

edenai-apis
Eden AI aims to simplify the use and deployment of AI technologies by providing a unique API that connects to all the best AI engines. With the rise of **AI as a Service** , a lot of companies provide off-the-shelf trained models that you can access directly through an API. These companies are either the tech giants (Google, Microsoft , Amazon) or other smaller, more specialized companies, and there are hundreds of them. Some of the most known are : DeepL (translation), OpenAI (text and image analysis), AssemblyAI (speech analysis). There are **hundreds of companies** doing that. We're regrouping the best ones **in one place** !

NanoLLM
NanoLLM is a tool designed for optimized local inference for Large Language Models (LLMs) using HuggingFace-like APIs. It supports quantization, vision/language models, multimodal agents, speech, vector DB, and RAG. The tool aims to provide efficient and effective processing for LLMs on local devices, enhancing performance and usability for various AI applications.

open-ai
Open AI is a powerful tool for artificial intelligence research and development. It provides a wide range of machine learning models and algorithms, making it easier for developers to create innovative AI applications. With Open AI, users can explore cutting-edge technologies such as natural language processing, computer vision, and reinforcement learning. The platform offers a user-friendly interface and comprehensive documentation to support users in building and deploying AI solutions. Whether you are a beginner or an experienced AI practitioner, Open AI offers the tools and resources you need to accelerate your AI projects and stay ahead in the rapidly evolving field of artificial intelligence.
For similar jobs
albumentations
Albumentations is a Python library for image augmentation. Image augmentation is used in deep learning and computer vision tasks to increase the quality of trained models. The purpose of image augmentation is to create new training samples from the existing data.
clarifai-python
The Clarifai Python SDK offers a comprehensive set of tools to integrate Clarifai's AI platform to leverage computer vision capabilities like classification , detection ,segementation and natural language capabilities like classification , summarisation , generation , Q&A ,etc into your applications. With just a few lines of code, you can leverage cutting-edge artificial intelligence to unlock valuable insights from visual and textual content.
ailia-models
The collection of pre-trained, state-of-the-art AI models. ailia SDK is a self-contained, cross-platform, high-speed inference SDK for AI. The ailia SDK provides a consistent C++ API across Windows, Mac, Linux, iOS, Android, Jetson, and Raspberry Pi platforms. It also supports Unity (C#), Python, Rust, Flutter(Dart) and JNI for efficient AI implementation. The ailia SDK makes extensive use of the GPU through Vulkan and Metal to enable accelerated computing. # Supported models 323 models as of April 8th, 2024
edenai-apis
Eden AI aims to simplify the use and deployment of AI technologies by providing a unique API that connects to all the best AI engines. With the rise of **AI as a Service** , a lot of companies provide off-the-shelf trained models that you can access directly through an API. These companies are either the tech giants (Google, Microsoft , Amazon) or other smaller, more specialized companies, and there are hundreds of them. Some of the most known are : DeepL (translation), OpenAI (text and image analysis), AssemblyAI (speech analysis). There are **hundreds of companies** doing that. We're regrouping the best ones **in one place** !
Awesome-Segment-Anything
The Segment Anything Model (SAM) is a powerful tool that allows users to segment any object in an image with just a few clicks. This makes it a great tool for a variety of tasks, such as object detection, tracking, and editing. SAM is also very easy to use, making it a great option for both beginners and experienced users.

llm2vec
LLM2Vec is a simple recipe to convert decoder-only LLMs into text encoders. It consists of 3 simple steps: 1) enabling bidirectional attention, 2) training with masked next token prediction, and 3) unsupervised contrastive learning. The model can be further fine-tuned to achieve state-of-the-art performance.

curated-transformers
Curated Transformers is a transformer library for PyTorch that provides state-of-the-art models composed of reusable components. It supports various transformer architectures, including encoders like ALBERT, BERT, and RoBERTa, and decoders like Falcon, Llama, and MPT. The library emphasizes consistent type annotations, minimal dependencies, and ease of use for education and research. It has been production-tested by Explosion and will be the default transformer implementation in spaCy 3.7.
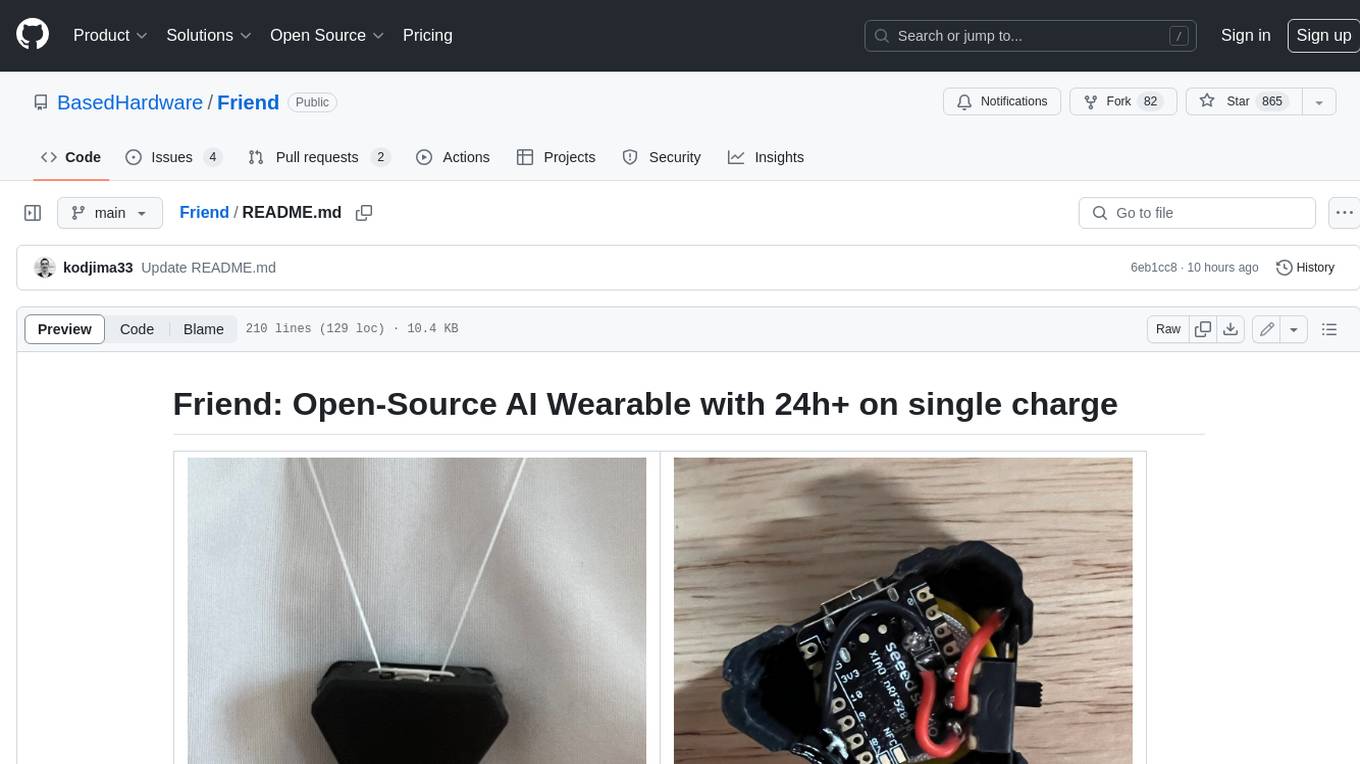
Friend
Friend is an open-source AI wearable device that records everything you say, gives you proactive feedback and advice. It has real-time AI audio processing capabilities, low-powered Bluetooth, open-source software, and a wearable design. The device is designed to be affordable and easy to use, with a total cost of less than $20. To get started, you can clone the repo, choose the version of the app you want to install, and follow the instructions for installing the firmware and assembling the device. Friend is still a prototype project and is provided "as is", without warranty of any kind. Use of the device should comply with all local laws and regulations concerning privacy and data protection.