Best AI tools for< Question Answering >
Infographic
20 - AI tool Sites
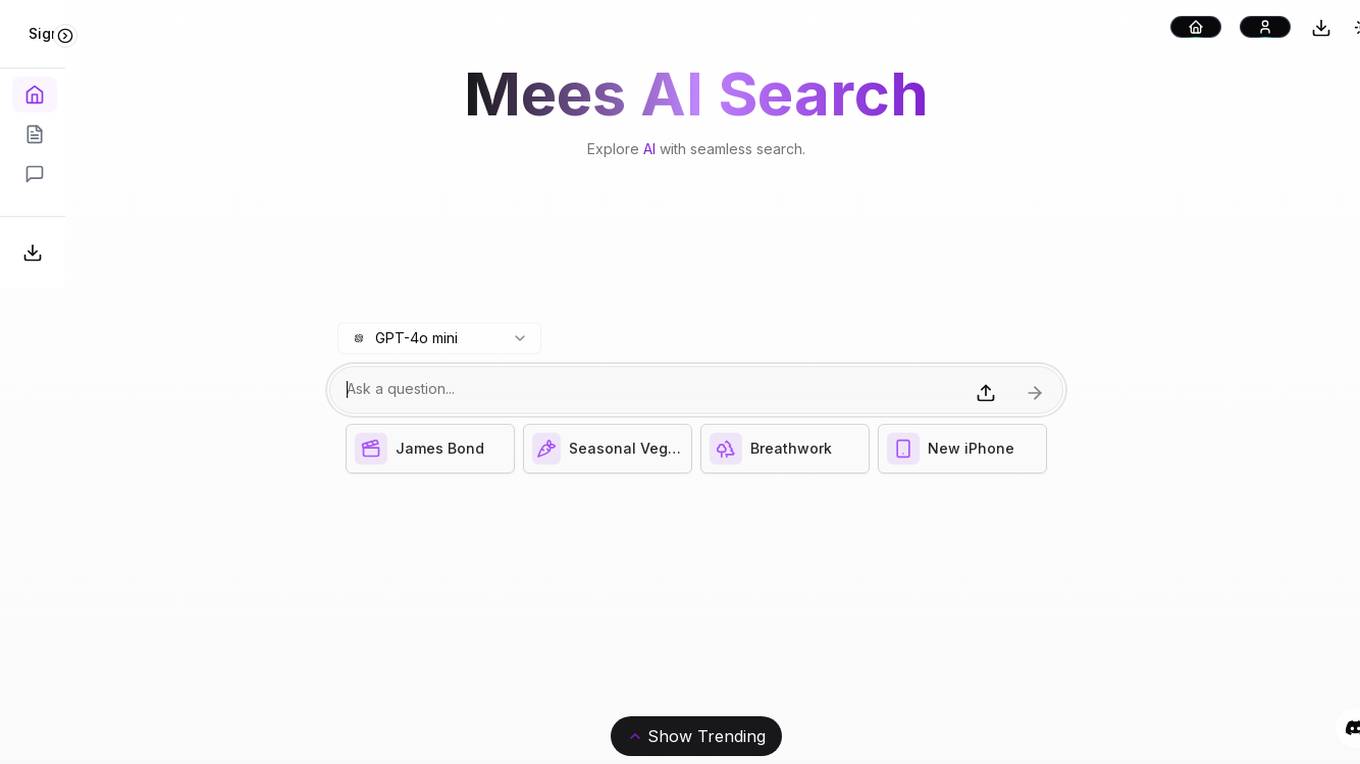
Mees Ai
Mees Ai is an advanced AI search and answer engine that allows users to explore AI with seamless search. The platform leverages cutting-edge technology, including GPT-4o, to provide accurate and relevant information on a wide range of topics. Users can search for anything from seasonal veggies to the latest iPhone show trends. Mees Ai aims to revolutionize the way people access information by offering a user-friendly interface and powerful AI capabilities.
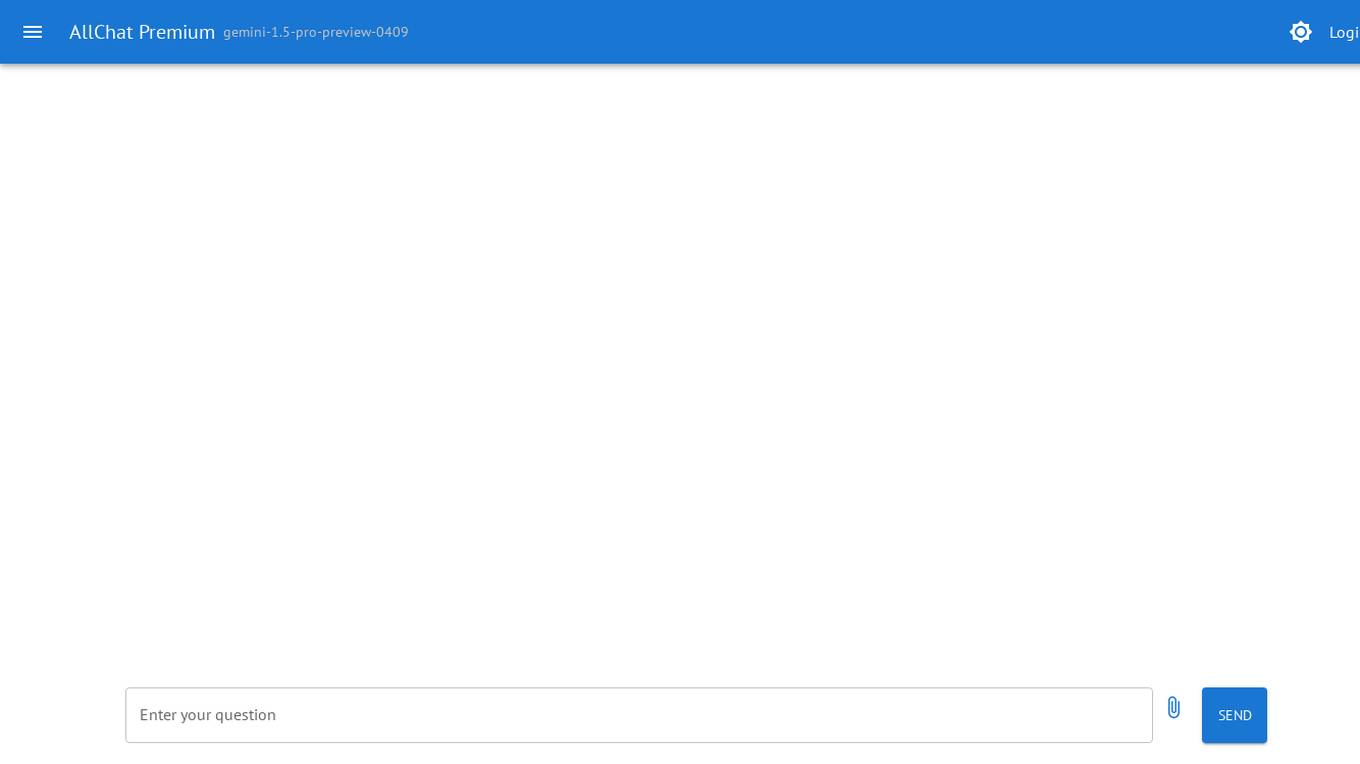
AllChat
AllChat is an intelligent conversational AI assistant designed to enhance user interactions and streamline communication processes. It leverages advanced AI algorithms to provide personalized assistance and support in various tasks. With its intuitive interface, AllChat aims to revolutionize the way users engage with technology, offering a seamless and efficient experience. Whether it's answering queries, scheduling appointments, or managing tasks, AllChat is your go-to virtual assistant for all your needs.
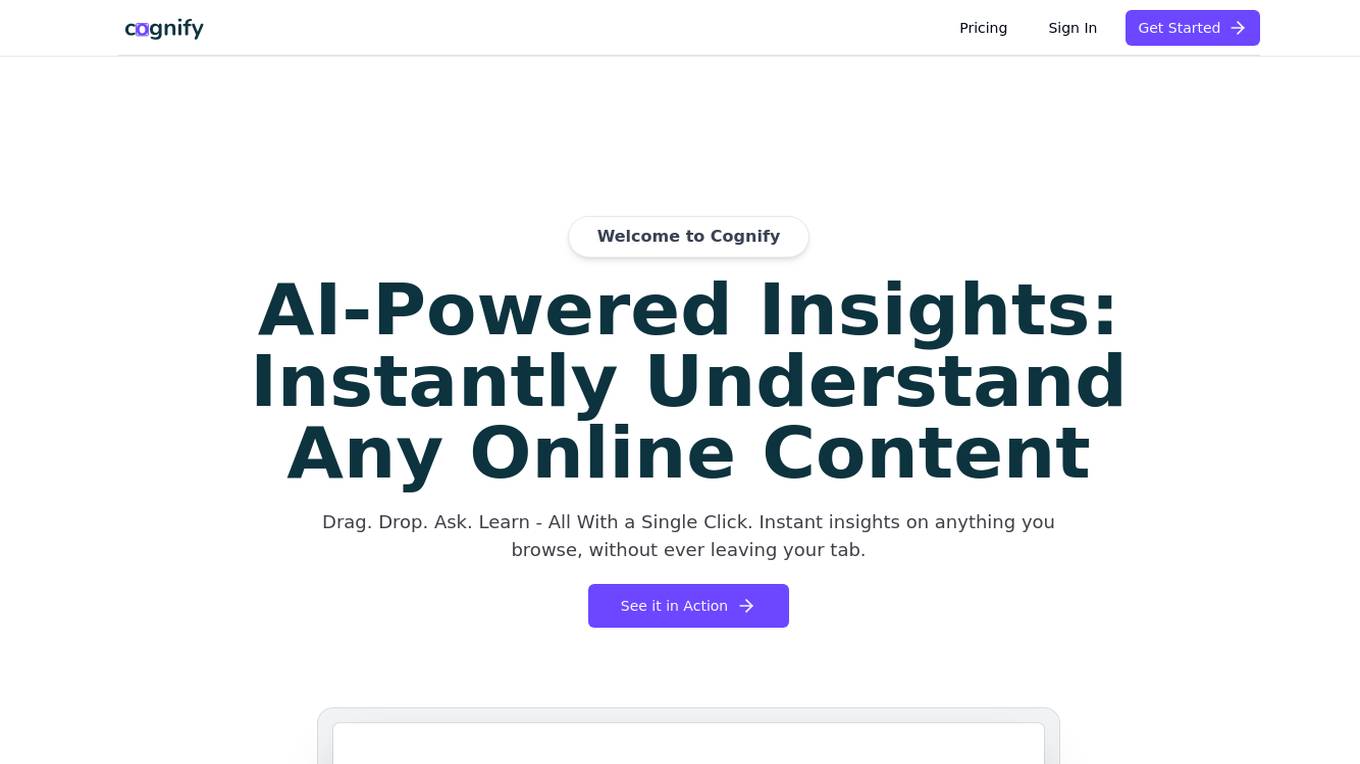
Cognify Insights
Cognify Insights is an AI-powered research assistant that provides instant understanding of online content such as text, diagrams, tables, and graphs. With a simple drag and drop feature, users can quickly analyze any type of content without leaving their browsing tab. The tool offers valuable insights and helps users unlock information efficiently.
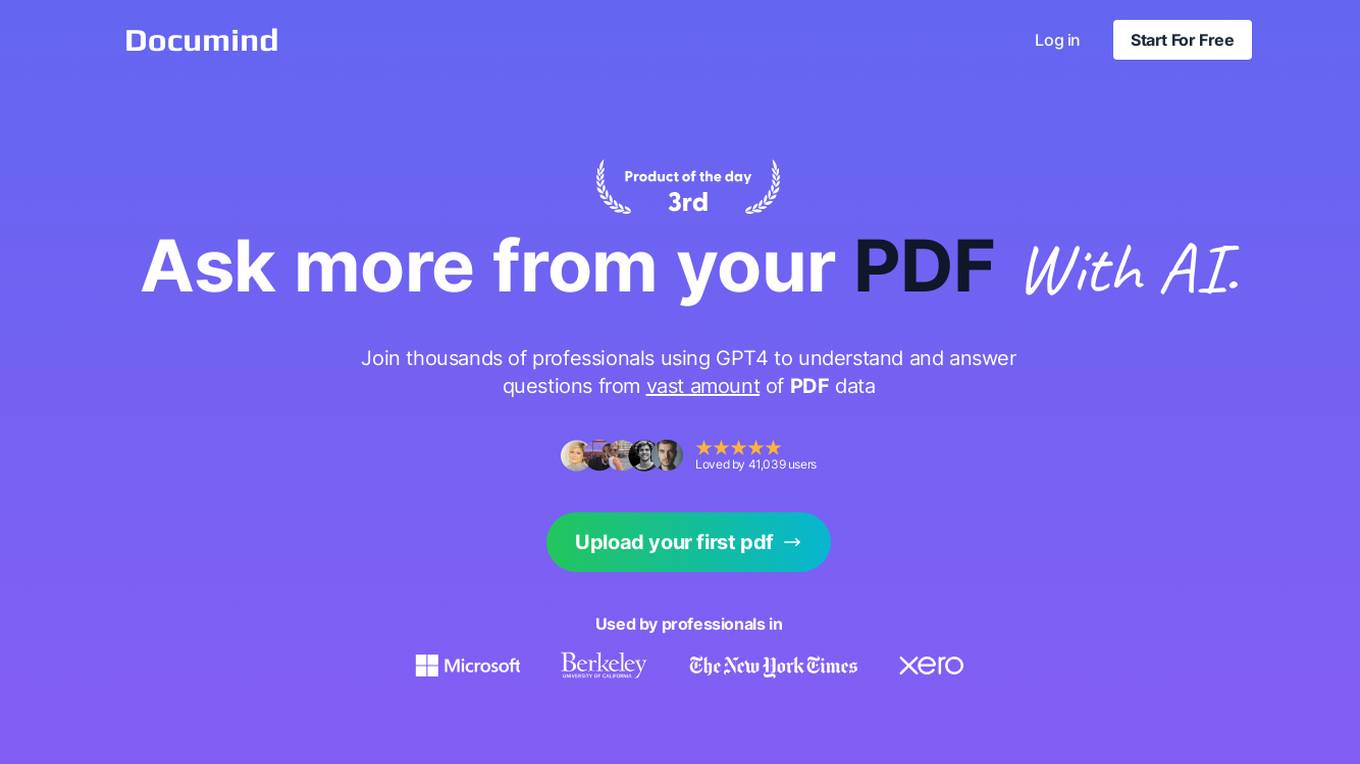
Chat With PDF AI Tool
The Chat With PDF AI Tool is an innovative application that allows users to interact with PDF documents using artificial intelligence technology. Users can engage in conversations with the AI tool to extract information, ask questions, and receive instant responses. The tool simplifies the process of working with PDF files by providing a conversational interface, making it user-friendly and efficient. With its advanced AI capabilities, the tool can understand natural language queries and provide accurate results, enhancing productivity and workflow efficiency.
ChatPDF
ChatPDF is an AI-powered tool that allows users to interact with PDF documents in a conversational manner. It uses natural language processing (NLP) to understand user queries and provide relevant information or perform actions on the PDF. With ChatPDF, users can ask questions about the content of the PDF, search for specific information, extract data, translate text, and more, all through a simple chat-like interface.
Chat With PDF AI Tool
Chat With PDF AI Tool is an innovative online application that allows users to interact with a virtual assistant powered by artificial intelligence to convert and manipulate PDF files. The tool simplifies the process of working with PDFs by offering a conversational interface for tasks such as conversion, editing, and extraction. Users can upload PDF files, ask questions, and receive instant responses and actions from the AI assistant. With its user-friendly design and advanced AI capabilities, Chat With PDF AI Tool revolutionizes the way users handle PDF documents.
Tinq.ai
Tinq.ai is a natural language processing (NLP) tool that provides a range of text analysis capabilities through its API. It offers tools for tasks such as plagiarism checking, text summarization, sentiment analysis, named entity recognition, and article extraction. Tinq.ai's API can be integrated into applications to add NLP functionality, such as content moderation, sentiment analysis, and text rewriting.
ChatPDF
ChatPDF is an AI-powered application that allows users to chat with PDF files and websites, enhancing creativity and productivity. Users can easily ask questions, access advanced AI models, and benefit from unlimited chats and knowledge bases. The application offers different plans to cater to various needs, including a free plan for small projects and a premium plan for unlimited chats and priority support. ChatPDF is ideal for students, researchers, copywriters, marketers, sales managers, and customer support professionals.
HotBot
HotBot is an AI-powered question-answering tool that provides smarter answers to user queries. It simplifies the process of seeking information by allowing users to ask questions directly. The platform utilizes artificial intelligence to understand and respond to a wide range of queries, making it easy for users to find the information they need quickly and efficiently.
GooseAI
GooseAI is a fully managed NLP-as-a-Service delivered via API, at 30% the cost of other providers. It offers a variety of NLP models, including GPT-Neo 1.3B, Fairseq 1.3B, GPT-J 6B, Fairseq 6B, Fairseq 13B, and GPT-NeoX 20B. GooseAI is easy to use, with feature parity with industry standard APIs. It is also highly performant, with the industry's fastest generation speeds.
Airtrain
Airtrain is a no-code compute platform for Large Language Models (LLMs). It provides a user-friendly interface for fine-tuning, evaluating, and deploying custom AI models. Airtrain also offers a marketplace of pre-trained models that can be used for a variety of tasks, such as text generation, translation, and question answering.

Google Gemma
Google Gemma is a lightweight, state-of-the-art open language model (LLM) developed by Google. It is part of the same research used in the creation of Google's Gemini models. Gemma models come in two sizes, the 2B and 7B parameter versions, where each has a base (pre-trained) and instruction-tuned modifications. Gemma models are designed to be cross-device compatible and optimized for Google Cloud and NVIDIA GPUs. They are also accessible through Kaggle, Hugging Face, Google Cloud with Vertex AI or GKE. Gemma models can be used for a variety of applications, including text generation, summarization, RAG, and both commercial and research use.
Cuecard
Cuecard is an AI-powered sales co-pilot tool designed to revolutionize the sales process by providing AI-driven knowledge and personalized experiences to help sales teams close deals faster. It offers features such as interactive outreach, efficient research, real-time answers, centralized knowledge access, and improved sales velocity. Cuecard is trusted by leading brands of all sizes and offers a live demo for users to experience its innovative features firsthand.
xTuring
xTuring is an open-source software that allows users to build and control their own Large Language Models (LLMs). It is designed to be simple and user-friendly, making it accessible to both new and experienced AI developers. xTuring provides users with complete control over the personalization of AI models, allowing them to tailor the models to their specific needs and applications.
GPT4All
GPT4All is a web-based platform that allows users to access the GPT-4 language model. GPT-4 is a large language model that can be used for a variety of tasks, including text generation, translation, question answering, and code generation. GPT4All makes it easy for users to get started with GPT-4, without having to worry about the technical details of setting up and running the model.
GPT-4
GPT-4 is a large language model that can be used for a variety of tasks, including text generation, translation, question answering, and code generation. It is one of the most powerful language models available, and it is constantly being improved. GPT-4 is used by a variety of businesses and organizations, including Google, Microsoft, and OpenAI. It is also used by researchers to develop new AI applications.
Grok-1.5 Vision
Grok-1.5 Vision (Grok-1.5V) is a groundbreaking multimodal AI model developed by Elon Musk's research lab, x.AI. This advanced model has the potential to revolutionize the field of artificial intelligence and shape the future of various industries. Grok-1.5V combines the capabilities of computer vision, natural language processing, and other AI techniques to provide a comprehensive understanding of the world around us. With its ability to analyze and interpret visual data, Grok-1.5V can assist in tasks such as object recognition, image classification, and scene understanding. Additionally, its natural language processing capabilities enable it to comprehend and generate human language, making it a powerful tool for communication and information retrieval. Grok-1.5V's multimodal nature sets it apart from traditional AI models, allowing it to handle complex tasks that require a combination of visual and linguistic understanding. This makes it a valuable asset for applications in fields such as healthcare, manufacturing, and customer service.

Jina AI
Jina AI is a company that provides multimodal AI solutions for businesses and developers. Their products include embeddings, rerankers, and prompt engineering tools. Jina AI's mission is to make AI accessible and easy to use for everyone.

Ask Buzzing AI
Ask Buzzing AI is a question-answering platform that uses artificial intelligence to provide comprehensive and informative responses to a wide range of queries. It is designed to be user-friendly and accessible, allowing users to ask questions in natural language and receive accurate and relevant answers.
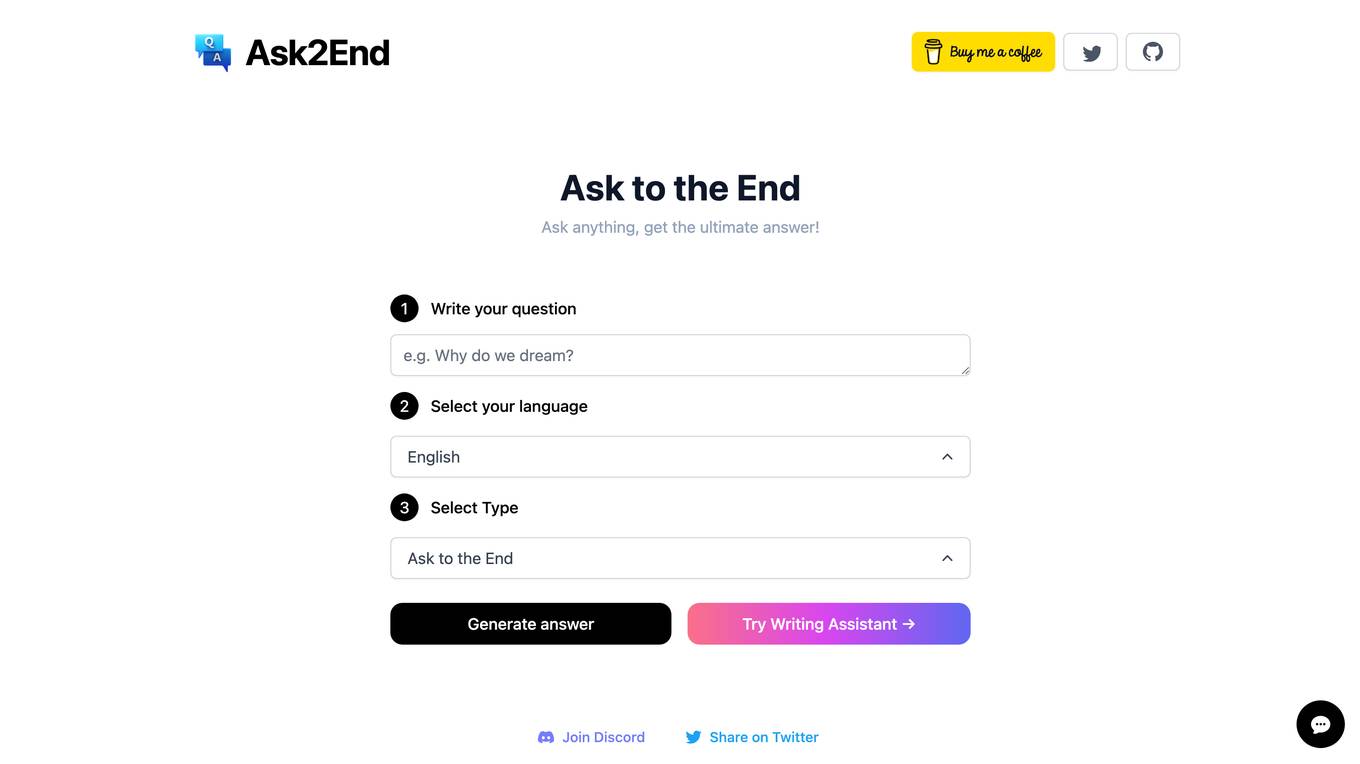
Ask2End
Ask2End is an AI-powered question-answering tool that provides comprehensive and accurate answers to any question you may have. It is designed to be user-friendly and accessible, allowing you to get the information you need quickly and easily.
22 - Open Source Tools

mistral.rs
Mistral.rs is a fast LLM inference platform written in Rust. We support inference on a variety of devices, quantization, and easy-to-use application with an Open-AI API compatible HTTP server and Python bindings.
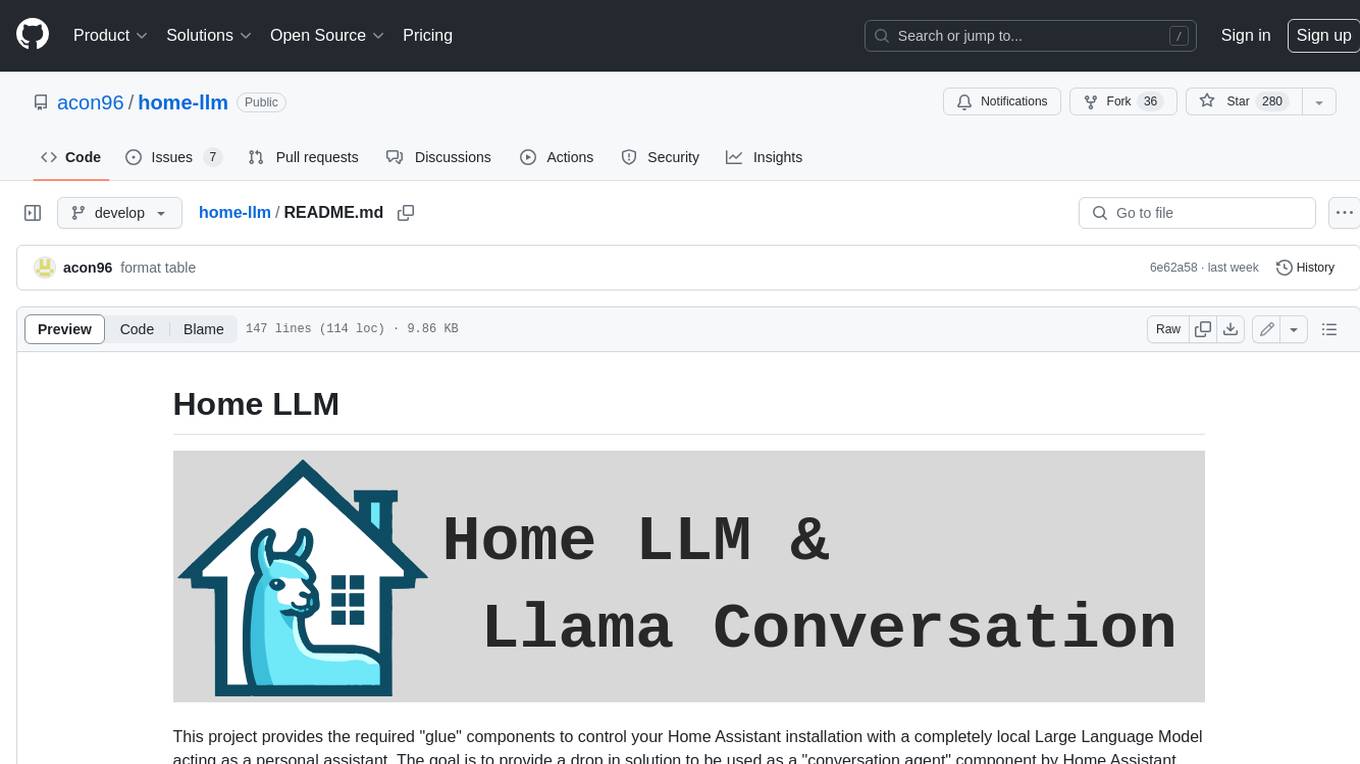
home-llm
Home LLM is a project that provides the necessary components to control your Home Assistant installation with a completely local Large Language Model acting as a personal assistant. The goal is to provide a drop-in solution to be used as a "conversation agent" component by Home Assistant. The 2 main pieces of this solution are Home LLM and Llama Conversation. Home LLM is a fine-tuning of the Phi model series from Microsoft and the StableLM model series from StabilityAI. The model is able to control devices in the user's house as well as perform basic question and answering. The fine-tuning dataset is a custom synthetic dataset designed to teach the model function calling based on the device information in the context. Llama Conversation is a custom component that exposes the locally running LLM as a "conversation agent" in Home Assistant. This component can be interacted with in a few ways: using a chat interface, integrating with Speech-to-Text and Text-to-Speech addons, or running the oobabooga/text-generation-webui project to provide access to the LLM via an API interface.

llama_ros
This repository provides a set of ROS 2 packages to integrate llama.cpp into ROS 2. By using the llama_ros packages, you can easily incorporate the powerful optimization capabilities of llama.cpp into your ROS 2 projects by running GGUF-based LLMs and VLMs.

R2R
R2R (RAG to Riches) is a fast and efficient framework for serving high-quality Retrieval-Augmented Generation (RAG) to end users. The framework is designed with customizable pipelines and a feature-rich FastAPI implementation, enabling developers to quickly deploy and scale RAG-based applications. R2R was conceived to bridge the gap between local LLM experimentation and scalable production solutions. **R2R is to LangChain/LlamaIndex what NextJS is to React**. A JavaScript client for R2R deployments can be found here. ### Key Features * **🚀 Deploy** : Instantly launch production-ready RAG pipelines with streaming capabilities. * **🧩 Customize** : Tailor your pipeline with intuitive configuration files. * **🔌 Extend** : Enhance your pipeline with custom code integrations. * **⚖️ Autoscale** : Scale your pipeline effortlessly in the cloud using SciPhi. * **🤖 OSS** : Benefit from a framework developed by the open-source community, designed to simplify RAG deployment.

curated-transformers
Curated Transformers is a transformer library for PyTorch that provides state-of-the-art models composed of reusable components. It supports various transformer architectures, including encoders like ALBERT, BERT, and RoBERTa, and decoders like Falcon, Llama, and MPT. The library emphasizes consistent type annotations, minimal dependencies, and ease of use for education and research. It has been production-tested by Explosion and will be the default transformer implementation in spaCy 3.7.

FlexFlow
FlexFlow Serve is an open-source compiler and distributed system for **low latency**, **high performance** LLM serving. FlexFlow Serve outperforms existing systems by 1.3-2.0x for single-node, multi-GPU inference and by 1.4-2.4x for multi-node, multi-GPU inference.

bert4torch
**bert4torch** is a high-level framework for training and deploying transformer models in PyTorch. It provides a simple and efficient API for building, training, and evaluating transformer models, and supports a wide range of pre-trained models, including BERT, RoBERTa, ALBERT, XLNet, and GPT-2. bert4torch also includes a number of useful features, such as data loading, tokenization, and model evaluation. It is a powerful and versatile tool for natural language processing tasks.
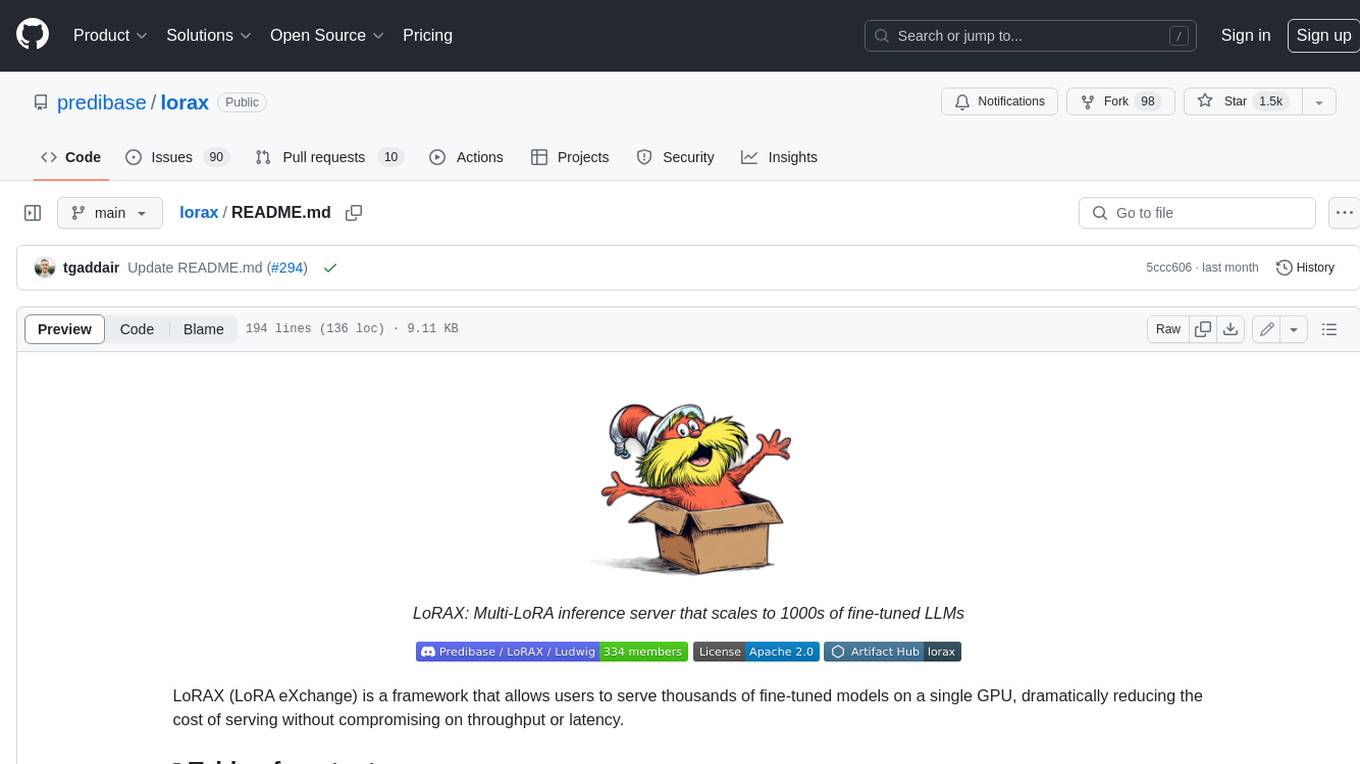
lorax
LoRAX is a framework that allows users to serve thousands of fine-tuned models on a single GPU, dramatically reducing the cost of serving without compromising on throughput or latency. It features dynamic adapter loading, heterogeneous continuous batching, adapter exchange scheduling, optimized inference, and is ready for production with prebuilt Docker images, Helm charts for Kubernetes, Prometheus metrics, and distributed tracing with Open Telemetry. LoRAX supports a number of Large Language Models as the base model including Llama, Mistral, and Qwen, and any of the linear layers in the model can be adapted via LoRA and loaded in LoRAX.
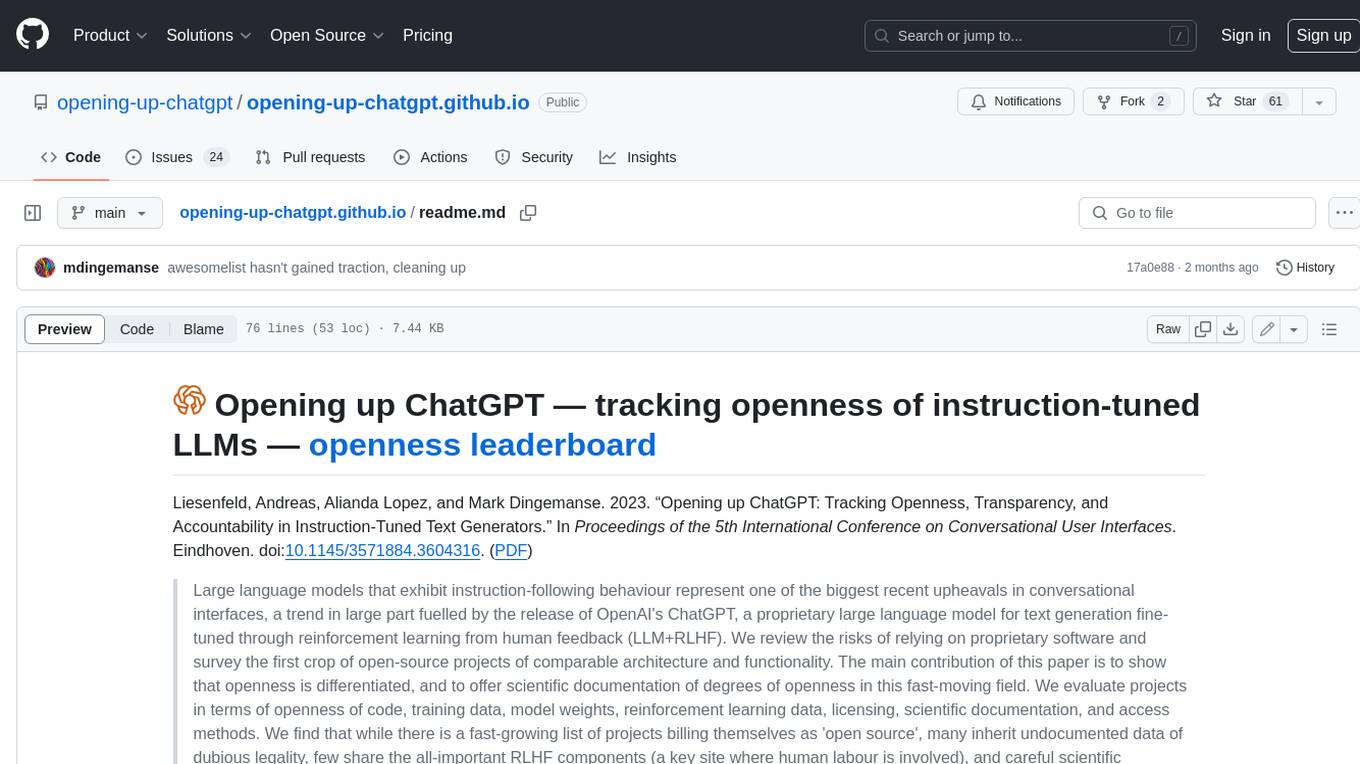
opening-up-chatgpt.github.io
This repository provides a curated list of open-source projects that implement instruction-tuned large language models (LLMs) with reinforcement learning from human feedback (RLHF). The projects are evaluated in terms of their openness across a predefined set of criteria in the areas of Availability, Documentation, and Access. The goal of this repository is to promote transparency and accountability in the development and deployment of LLMs.

KwaiAgents
KwaiAgents is a series of Agent-related works open-sourced by the [KwaiKEG](https://github.com/KwaiKEG) from [Kuaishou Technology](https://www.kuaishou.com/en). The open-sourced content includes: 1. **KAgentSys-Lite**: a lite version of the KAgentSys in the paper. While retaining some of the original system's functionality, KAgentSys-Lite has certain differences and limitations when compared to its full-featured counterpart, such as: (1) a more limited set of tools; (2) a lack of memory mechanisms; (3) slightly reduced performance capabilities; and (4) a different codebase, as it evolves from open-source projects like BabyAGI and Auto-GPT. Despite these modifications, KAgentSys-Lite still delivers comparable performance among numerous open-source Agent systems available. 2. **KAgentLMs**: a series of large language models with agent capabilities such as planning, reflection, and tool-use, acquired through the Meta-agent tuning proposed in the paper. 3. **KAgentInstruct**: over 200k Agent-related instructions finetuning data (partially human-edited) proposed in the paper. 4. **KAgentBench**: over 3,000 human-edited, automated evaluation data for testing Agent capabilities, with evaluation dimensions including planning, tool-use, reflection, concluding, and profiling.

lmdeploy
LMDeploy is a toolkit for compressing, deploying, and serving LLM, developed by the MMRazor and MMDeploy teams. It has the following core features: * **Efficient Inference** : LMDeploy delivers up to 1.8x higher request throughput than vLLM, by introducing key features like persistent batch(a.k.a. continuous batching), blocked KV cache, dynamic split&fuse, tensor parallelism, high-performance CUDA kernels and so on. * **Effective Quantization** : LMDeploy supports weight-only and k/v quantization, and the 4-bit inference performance is 2.4x higher than FP16. The quantization quality has been confirmed via OpenCompass evaluation. * **Effortless Distribution Server** : Leveraging the request distribution service, LMDeploy facilitates an easy and efficient deployment of multi-model services across multiple machines and cards. * **Interactive Inference Mode** : By caching the k/v of attention during multi-round dialogue processes, the engine remembers dialogue history, thus avoiding repetitive processing of historical sessions.

clarifai-python
The Clarifai Python SDK offers a comprehensive set of tools to integrate Clarifai's AI platform to leverage computer vision capabilities like classification , detection ,segementation and natural language capabilities like classification , summarisation , generation , Q&A ,etc into your applications. With just a few lines of code, you can leverage cutting-edge artificial intelligence to unlock valuable insights from visual and textual content.
fastllm
FastLLM is a high-performance large model inference library implemented in pure C++ with no third-party dependencies. Models of 6-7B size can run smoothly on Android devices. Deployment communication QQ group: 831641348
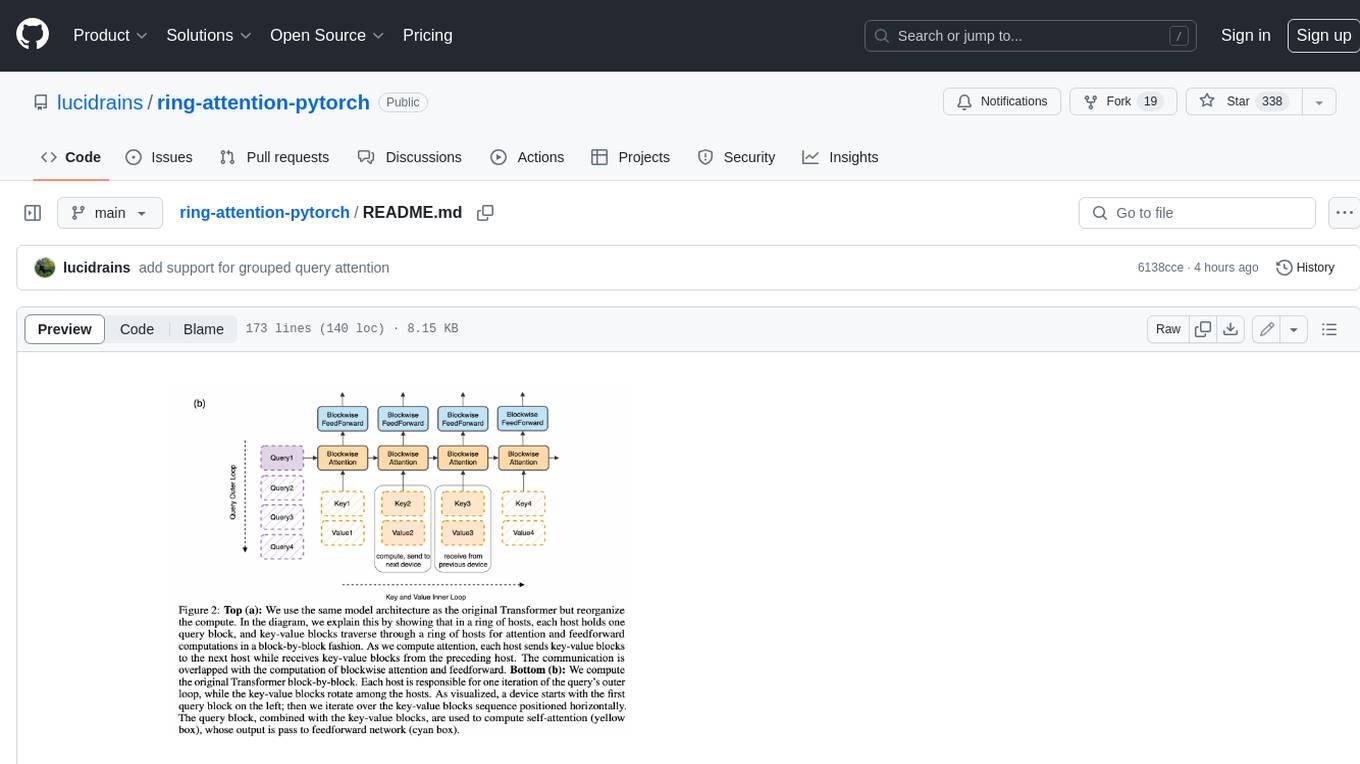
ring-attention-pytorch
This repository contains an implementation of Ring Attention, a technique for processing large sequences in transformers. Ring Attention splits the data across the sequence dimension and applies ring reduce to the processing of the tiles of the attention matrix, similar to flash attention. It also includes support for Striped Attention, a follow-up paper that permutes the sequence for better workload balancing for autoregressive transformers, and grouped query attention, which saves on communication costs during the ring reduce. The repository includes a CUDA version of the flash attention kernel, which is used for the forward and backward passes of the ring attention. It also includes logic for splitting the sequence evenly among ranks, either within the attention function or in the external ring transformer wrapper, and basic test cases with two processes to check for equivalent output and gradients.
LLaMa2lang
This repository contains convenience scripts to finetune LLaMa3-8B (or any other foundation model) for chat towards any language (that isn't English). The rationale behind this is that LLaMa3 is trained on primarily English data and while it works to some extent for other languages, its performance is poor compared to English.
ChatGLM3
ChatGLM3 is a conversational pretrained model jointly released by Zhipu AI and THU's KEG Lab. ChatGLM3-6B is the open-sourced model in the ChatGLM3 series. It inherits the advantages of its predecessors, such as fluent conversation and low deployment threshold. In addition, ChatGLM3-6B introduces the following features: 1. A stronger foundation model: ChatGLM3-6B's foundation model ChatGLM3-6B-Base employs more diverse training data, more sufficient training steps, and more reasonable training strategies. Evaluation on datasets from different perspectives, such as semantics, mathematics, reasoning, code, and knowledge, shows that ChatGLM3-6B-Base has the strongest performance among foundation models below 10B parameters. 2. More complete functional support: ChatGLM3-6B adopts a newly designed prompt format, which supports not only normal multi-turn dialogue, but also complex scenarios such as tool invocation (Function Call), code execution (Code Interpreter), and Agent tasks. 3. A more comprehensive open-source sequence: In addition to the dialogue model ChatGLM3-6B, the foundation model ChatGLM3-6B-Base, the long-text dialogue model ChatGLM3-6B-32K, and ChatGLM3-6B-128K, which further enhances the long-text comprehension ability, are also open-sourced. All the above weights are completely open to academic research and are also allowed for free commercial use after filling out a questionnaire.
InfLLM
InfLLM is a training-free memory-based method that unveils the intrinsic ability of LLMs to process streaming long sequences. It stores distant contexts into additional memory units and employs an efficient mechanism to lookup token-relevant units for attention computation. Thereby, InfLLM allows LLMs to efficiently process long sequences while maintaining the ability to capture long-distance dependencies. Without any training, InfLLM enables LLMs pre-trained on sequences of a few thousand tokens to achieve superior performance than competitive baselines continually training these LLMs on long sequences. Even when the sequence length is scaled to 1, 024K, InfLLM still effectively captures long-distance dependencies.

FlagEmbedding
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently: * **Long-Context LLM** : Activation Beacon * **Fine-tuning of LM** : LM-Cocktail * **Embedding Model** : Visualized-BGE, BGE-M3, LLM Embedder, BGE Embedding * **Reranker Model** : llm rerankers, BGE Reranker * **Benchmark** : C-MTEB
langroid
Langroid is a Python framework that makes it easy to build LLM-powered applications. It uses a multi-agent paradigm inspired by the Actor Framework, where you set up Agents, equip them with optional components (LLM, vector-store and tools/functions), assign them tasks, and have them collaboratively solve a problem by exchanging messages. Langroid is a fresh take on LLM app-development, where considerable thought has gone into simplifying the developer experience; it does not use Langchain.
llm_finetuning
This repository provides a comprehensive set of tools for fine-tuning large language models (LLMs) using various techniques, including full parameter training, LoRA (Low-Rank Adaptation), and P-Tuning V2. It supports a wide range of LLM models, including Qwen, Yi, Llama, and others. The repository includes scripts for data preparation, training, and inference, making it easy for users to fine-tune LLMs for specific tasks. Additionally, it offers a collection of pre-trained models and provides detailed documentation and examples to guide users through the process.

Qwen
Qwen is a series of large language models developed by Alibaba DAMO Academy. It outperforms the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen models outperform the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen-72B achieves better performance than LLaMA2-70B on all tasks and outperforms GPT-3.5 on 7 out of 10 tasks.
openai_trtllm
OpenAI-compatible API for TensorRT-LLM and NVIDIA Triton Inference Server, which allows you to integrate with langchain
20 - OpenAI Gpts

ChatGaia
I help you to explore the galaxy by answering astronomy questions with the Gaia Space Telescope. Ask a question, download .csv, upload .csv for plotting
Lil'PEDiA
Basic Questions Answered for Everyone - Your go-to guide for everyday queries. Simplify life, one question at a time!

Ai Doc
Join millions of students, researchers and professionals to instantly answer questions and understand research with Al
JustSQL (BigQuery Edition)
Natural Language to SQL. Just provide your database schema and ask your questions.
BibliotecarIA
[Beta] Bibliotecaria especializada en la preparación de oposiciones a bibliotecas