
opening-up-chatgpt.github.io
Tracking instruction-tuned LLM openness. Paper: Liesenfeld, Andreas, Alianda Lopez, and Mark Dingemanse. 2023. “Opening up ChatGPT: Tracking Openness, Transparency, and Accountability in Instruction-Tuned Text Generators.” In Proceedings of the 5th International Conference on Conversational User Interfaces. doi:10.1145/3571884.3604316.
Stars: 68
This repository provides a curated list of open-source projects that implement instruction-tuned large language models (LLMs) with reinforcement learning from human feedback (RLHF). The projects are evaluated in terms of their openness across a predefined set of criteria in the areas of Availability, Documentation, and Access. The goal of this repository is to promote transparency and accountability in the development and deployment of LLMs.
README:
 Opening up ChatGPT — tracking openness of instruction-tuned LLMs — openness leaderboard
Opening up ChatGPT — tracking openness of instruction-tuned LLMs — openness leaderboard
Liesenfeld, Andreas, Alianda Lopez, and Mark Dingemanse. 2023. “Opening up ChatGPT: Tracking Openness, Transparency, and Accountability in Instruction-Tuned Text Generators.” In Proceedings of the 5th International Conference on Conversational User Interfaces. Eindhoven. doi:10.1145/3571884.3604316. (PDF)
Large language models that exhibit instruction-following behaviour represent one of the biggest recent upheavals in conversational interfaces, a trend in large part fuelled by the release of OpenAI's ChatGPT, a proprietary large language model for text generation fine-tuned through reinforcement learning from human feedback (LLM+RLHF). We review the risks of relying on proprietary software and survey the first crop of open-source projects of comparable architecture and functionality. The main contribution of this paper is to show that openness is differentiated, and to offer scientific documentation of degrees of openness in this fast-moving field. We evaluate projects in terms of openness of code, training data, model weights, reinforcement learning data, licensing, scientific documentation, and access methods. We find that while there is a fast-growing list of projects billing themselves as 'open source', many inherit undocumented data of dubious legality, few share the all-important RLHF components (a key site where human labour is involved), and careful scientific documentation is exceedingly rare. Degrees of openness are relevant to fairness and accountability at all points, from data collection and curation to model architecture, and from training and fine-tuning to release and deployment.
We classify projects for their degrees of openness across a predefined set of criteria in the areas of Availability, Documentation and Access. The criteria are described in detail here.
| Availability | Documentation | Access |
|---|---|---|
|
|
|
If you find any of this useful, please cite our work:
@inproceedings{liesenfeld_dingemanse_2024,
author = {Liesenfeld, Andreas and Dingemanse, Mark},
title = {Rethinking open source generative AI: open washing and the EU AI Act},
year = {2024},
isbn = {9798400704505},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3630106.3659005},
doi = {10.1145/3630106.3659005},
pages = {1774–1787},
numpages = {14},
keywords = {Technology assessment, large language models, text generators, text-to-image generators},
location = {, Rio de Janeiro, Brazil, },
series = {FAccT '24}
}
@inproceedings{liesenfeld_opening_2023,
address = {Eindhoven},
title = {Opening up {ChatGPT}: tracking openness, transparency, and accountability in instruction-tuned text generators},
url = {https://opening-up-chatgpt.github.io},
doi = {10.1145/3571884.3604316},
booktitle = {Proceedings of the 5th {International} {Conference} on {Conversational} {User} {Interfaces}},
publisher = {Association for Computing Machinery},
author = {Liesenfeld, Andreas and Lopez, Alianda and Dingemanse, Mark},
year = {2023},
pages = {1--6},
}
If you know of a new instruction-tuned LLM+RLHF model we should be including, you can also add an issue.
How to contribute to the live table:
- Fork the repo and edit an existing yaml file or create a new one based on the sample
yamlfile in /projects - File a pull request to have your changes reviewed and, hopefully, merged into main.
The live table is updated whenever there is a change to the files in the /projects/ folder.
We try to be fairly systematic in our coverage of LLM+RLHF models, documenting degrees of openness for >10 features. There are many other resources that provide more free-form listings of relevant stuff or that offer ways to interact with (open) LLMs:
- Awesome Totally Open ChatGPT — a free-form awesomelist of ChatGPT alternatives.
- gpt4free: other models — another list of alternatives to GTP3.5/GPT4
- Jetstream's Awesome free and open sources alternatives to ChatGPT — a free-form listing "dedicated to showcasing a collection of awesome free and open-source alternatives to ChatGPT"
- LLMZoo — Motivation: "Break "AI supremacy" and democratize ChatGPT"
- text generation webui — provides gradio web app framework for interacting with a range of open LLMs
Here are some background readings on why openness matters, why closed models make bad baselines, and why some of us call for more counterfoil research in times of hype:
- The gradient of generative AI release — FACCT '23 paper by Irene Solaiman on degrees of openness in generative AI
- Closed AI models make bad baselines, by Anna Rogers. Proposes a simple principle: "That which is not open and reasonably reproducible cannot be considered a requisite baseline."
- Why ChatGPT is bad for open psycholinguistics — by Cassandra Jacobs. Quote: "The downsides of ChatGPT are specific to it—not intrinsic to language modeling as a whole. Using ChatGPT [in] one’s work undermines open science, reproducibility & lacks the flexibility of previous systems that could be manipulated & changed to suit one’s scientific needs."
- Stop feeding the hype and start resisting, by Iris van Rooij. Quote: "It’s almost as if academics are eager to do the PR work for OpenAI (the company that created ChatGPT; as well as its predecessor GPT-3 and its anticipated successor GPT-4). Why?"
- AI is a lot of work — by Josh Dzieza for The Verge. Quote: "ChatGPT seems so human because it was trained by an AI that was mimicking humans who were rating an AI that was mimicking humans who were pretending to be a better version of an AI that was trained on human writing."
Contributions welcome! Read the contribution guidelines first.
List of contributors:
Made with contrib.rocks.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for opening-up-chatgpt.github.io
Similar Open Source Tools
opening-up-chatgpt.github.io
This repository provides a curated list of open-source projects that implement instruction-tuned large language models (LLMs) with reinforcement learning from human feedback (RLHF). The projects are evaluated in terms of their openness across a predefined set of criteria in the areas of Availability, Documentation, and Access. The goal of this repository is to promote transparency and accountability in the development and deployment of LLMs.
suql
SUQL (Structured and Unstructured Query Language) is a tool that augments SQL with free text primitives for building chatbots that can interact with relational data sources containing both structured and unstructured information. It seamlessly integrates retrieval models, large language models (LLMs), and traditional SQL to provide a clean interface for hybrid data access. SUQL supports optimizations to minimize expensive LLM calls, scalability to large databases with PostgreSQL, and general SQL operations like JOINs and GROUP BYs.
ParrotServe
Parrot is a distributed serving system for LLM-based Applications, designed to efficiently serve LLM-based applications by adding Semantic Variable in the OpenAI-style API. It allows for horizontal scalability with multiple Engine instances running LLM models communicating with ServeCore. The system enables AI agents to interact with LLMs via natural language prompts for collaborative tasks.
Nucleoid
Nucleoid is a declarative (logic) runtime environment that manages both data and logic under the same runtime. It uses a declarative programming paradigm, which allows developers to focus on the business logic of the application, while the runtime manages the technical details. This allows for faster development and reduces the amount of code that needs to be written. Additionally, the sharding feature can help to distribute the load across multiple instances, which can further improve the performance of the system.

aitlas
The AiTLAS toolbox (Artificial Intelligence Toolbox for Earth Observation) includes state-of-the-art machine learning methods for exploratory and predictive analysis of satellite imagery as well as a repository of AI-ready Earth Observation (EO) datasets. It can be easily applied for a variety of Earth Observation tasks, such as land use and cover classification, crop type prediction, localization of specific objects (semantic segmentation), etc. The main goal of AiTLAS is to facilitate better usability and adoption of novel AI methods (and models) by EO experts, while offering easy access and standardized format of EO datasets to AI experts which allows benchmarking of various existing and novel AI methods tailored for EO data.

llm-reasoners
LLM Reasoners is a library that enables LLMs to conduct complex reasoning, with advanced reasoning algorithms. It approaches multi-step reasoning as planning and searches for the optimal reasoning chain, which achieves the best balance of exploration vs exploitation with the idea of "World Model" and "Reward". Given any reasoning problem, simply define the reward function and an optional world model (explained below), and let LLM reasoners take care of the rest, including Reasoning Algorithms, Visualization, LLM calling, and more!

Me-LLaMA
Me LLaMA introduces a suite of open-source medical Large Language Models (LLMs), including Me LLaMA 13B/70B and their chat-enhanced versions. Developed through innovative continual pre-training and instruction tuning, these models leverage a vast medical corpus comprising PubMed papers, medical guidelines, and general domain data. Me LLaMA sets new benchmarks on medical reasoning tasks, making it a significant asset for medical NLP applications and research. The models are intended for computational linguistics and medical research, not for clinical decision-making without validation and regulatory approval.
AixLib
AixLib is a Modelica model library for building performance simulations developed at RWTH Aachen University, E.ON Energy Research Center, Institute for Energy Efficient Buildings and Indoor Climate (EBC) in Aachen, Germany. It contains models of HVAC systems as well as high and reduced order building models. The name AixLib is derived from the city's French name Aix-la-Chapelle, following a local tradition. The library is continuously improved and offers citable papers for reference. Contributions to the development can be made via Issues section or Pull Requests, following the workflow described in the Wiki. AixLib is released under a 3-clause BSD-license with acknowledgements to public funded projects and financial support by BMWi (German Federal Ministry for Economic Affairs and Energy).

multilspy
Multilspy is a Python library developed for research purposes to facilitate the creation of language server clients for querying and obtaining results of static analyses from various language servers. It simplifies the process by handling server setup, communication, and configuration parameters, providing a common interface for different languages. The library supports features like finding function/class definitions, callers, completions, hover information, and document symbols. It is designed to work with AI systems like Large Language Models (LLMs) for tasks such as Monitor-Guided Decoding to ensure code generation correctness and boost compilability.
LLMSpeculativeSampling
This repository implements speculative sampling for large language model (LLM) decoding, utilizing two models - a target model and an approximation model. The approximation model generates token guesses, corrected by the target model, resulting in improved efficiency. It includes implementations of Google's and Deepmind's versions of speculative sampling, supporting models like llama-7B and llama-1B. The tool is designed for fast inference from transformers via speculative decoding.

aligner
Aligner is a model-agnostic alignment tool designed to efficiently correct responses from large language models. It redistributes initial answers to align with human intentions, improving performance across various LLMs. The tool can be applied with minimal training, enhancing upstream models and reducing hallucination. Aligner's 'copy and correct' method preserves the base structure while enhancing responses. It achieves significant performance improvements in helpfulness, harmlessness, and honesty dimensions, with notable success in boosting Win Rates on evaluation leaderboards.
hackingBuddyGPT
hackingBuddyGPT is a framework for testing LLM-based agents for security testing. It aims to create common ground truth by creating common security testbeds and benchmarks, evaluating multiple LLMs and techniques against those, and publishing prototypes and findings as open-source/open-access reports. The initial focus is on evaluating the efficiency of LLMs for Linux privilege escalation attacks, but the framework is being expanded to evaluate the use of LLMs for web penetration-testing and web API testing. hackingBuddyGPT is released as open-source to level the playing field for blue teams against APTs that have access to more sophisticated resources.
Graph-CoT
This repository contains the source code and datasets for Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs accepted to ACL 2024. It proposes a framework called Graph Chain-of-thought (Graph-CoT) to enable Language Models to traverse graphs step-by-step for reasoning, interaction, and execution. The motivation is to alleviate hallucination issues in Language Models by augmenting them with structured knowledge sources represented as graphs.
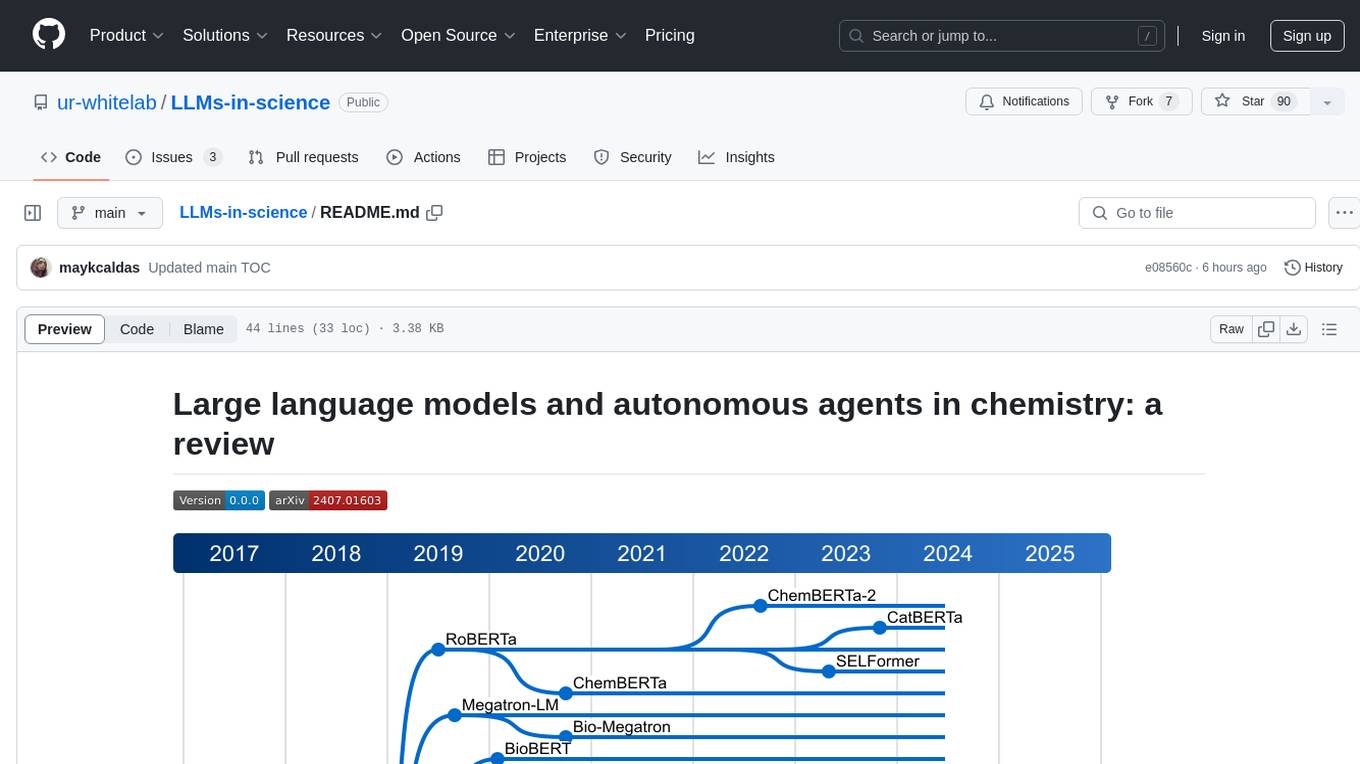
LLMs-in-science
The 'LLMs-in-science' repository is a collaborative environment for organizing papers related to large language models (LLMs) and autonomous agents in the field of chemistry. The goal is to discuss trend topics, challenges, and the potential for supporting scientific discovery in the context of artificial intelligence. The repository aims to maintain a systematic structure of the field and welcomes contributions from the community to keep the content up-to-date and relevant.

xlstm-jax
The xLSTM-jax repository contains code for training and evaluating the xLSTM model on language modeling using JAX. xLSTM is a Recurrent Neural Network architecture that improves upon the original LSTM through Exponential Gating, normalization, stabilization techniques, and a Matrix Memory. It is optimized for large-scale distributed systems with performant triton kernels for faster training and inference.
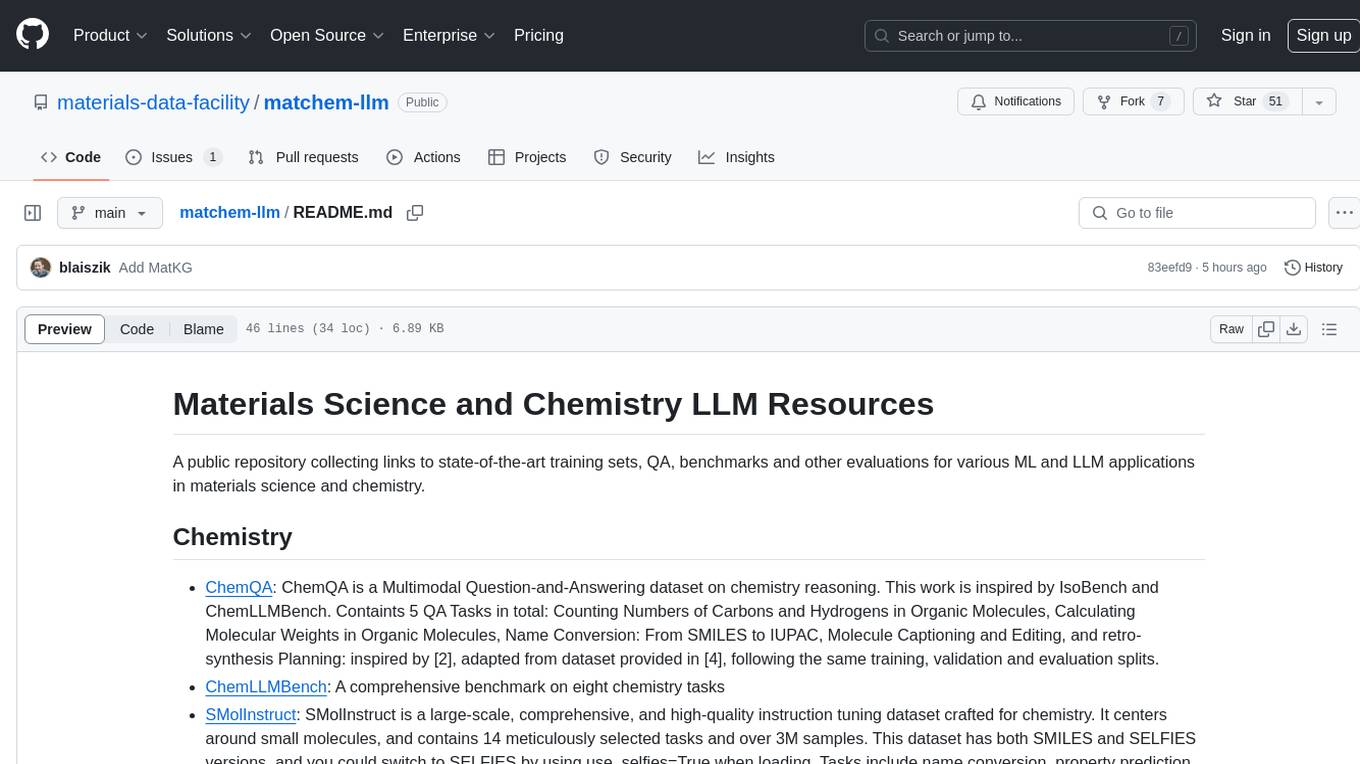
matchem-llm
A public repository collecting links to state-of-the-art training sets, QA, benchmarks and other evaluations for various ML and LLM applications in materials science and chemistry. It includes datasets related to chemistry, materials, multimodal data, and knowledge graphs in the field. The repository aims to provide resources for training and evaluating machine learning models in the materials science and chemistry domains.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

R2R
R2R (RAG to Riches) is a fast and efficient framework for serving high-quality Retrieval-Augmented Generation (RAG) to end users. The framework is designed with customizable pipelines and a feature-rich FastAPI implementation, enabling developers to quickly deploy and scale RAG-based applications. R2R was conceived to bridge the gap between local LLM experimentation and scalable production solutions. **R2R is to LangChain/LlamaIndex what NextJS is to React**. A JavaScript client for R2R deployments can be found here. ### Key Features * **🚀 Deploy** : Instantly launch production-ready RAG pipelines with streaming capabilities. * **🧩 Customize** : Tailor your pipeline with intuitive configuration files. * **🔌 Extend** : Enhance your pipeline with custom code integrations. * **⚖️ Autoscale** : Scale your pipeline effortlessly in the cloud using SciPhi. * **🤖 OSS** : Benefit from a framework developed by the open-source community, designed to simplify RAG deployment.

intel-extension-for-transformers
Intel® Extension for Transformers is an innovative toolkit designed to accelerate GenAI/LLM everywhere with the optimal performance of Transformer-based models on various Intel platforms, including Intel Gaudi2, Intel CPU, and Intel GPU. The toolkit provides the below key features and examples: * Seamless user experience of model compressions on Transformer-based models by extending [Hugging Face transformers](https://github.com/huggingface/transformers) APIs and leveraging [Intel® Neural Compressor](https://github.com/intel/neural-compressor) * Advanced software optimizations and unique compression-aware runtime (released with NeurIPS 2022's paper [Fast Distilbert on CPUs](https://arxiv.org/abs/2211.07715) and [QuaLA-MiniLM: a Quantized Length Adaptive MiniLM](https://arxiv.org/abs/2210.17114), and NeurIPS 2021's paper [Prune Once for All: Sparse Pre-Trained Language Models](https://arxiv.org/abs/2111.05754)) * Optimized Transformer-based model packages such as [Stable Diffusion](examples/huggingface/pytorch/text-to-image/deployment/stable_diffusion), [GPT-J-6B](examples/huggingface/pytorch/text-generation/deployment), [GPT-NEOX](examples/huggingface/pytorch/language-modeling/quantization#2-validated-model-list), [BLOOM-176B](examples/huggingface/pytorch/language-modeling/inference#BLOOM-176B), [T5](examples/huggingface/pytorch/summarization/quantization#2-validated-model-list), [Flan-T5](examples/huggingface/pytorch/summarization/quantization#2-validated-model-list), and end-to-end workflows such as [SetFit-based text classification](docs/tutorials/pytorch/text-classification/SetFit_model_compression_AGNews.ipynb) and [document level sentiment analysis (DLSA)](workflows/dlsa) * [NeuralChat](intel_extension_for_transformers/neural_chat), a customizable chatbot framework to create your own chatbot within minutes by leveraging a rich set of [plugins](https://github.com/intel/intel-extension-for-transformers/blob/main/intel_extension_for_transformers/neural_chat/docs/advanced_features.md) such as [Knowledge Retrieval](./intel_extension_for_transformers/neural_chat/pipeline/plugins/retrieval/README.md), [Speech Interaction](./intel_extension_for_transformers/neural_chat/pipeline/plugins/audio/README.md), [Query Caching](./intel_extension_for_transformers/neural_chat/pipeline/plugins/caching/README.md), and [Security Guardrail](./intel_extension_for_transformers/neural_chat/pipeline/plugins/security/README.md). This framework supports Intel Gaudi2/CPU/GPU. * [Inference](https://github.com/intel/neural-speed/tree/main) of Large Language Model (LLM) in pure C/C++ with weight-only quantization kernels for Intel CPU and Intel GPU (TBD), supporting [GPT-NEOX](https://github.com/intel/neural-speed/tree/main/neural_speed/models/gptneox), [LLAMA](https://github.com/intel/neural-speed/tree/main/neural_speed/models/llama), [MPT](https://github.com/intel/neural-speed/tree/main/neural_speed/models/mpt), [FALCON](https://github.com/intel/neural-speed/tree/main/neural_speed/models/falcon), [BLOOM-7B](https://github.com/intel/neural-speed/tree/main/neural_speed/models/bloom), [OPT](https://github.com/intel/neural-speed/tree/main/neural_speed/models/opt), [ChatGLM2-6B](https://github.com/intel/neural-speed/tree/main/neural_speed/models/chatglm), [GPT-J-6B](https://github.com/intel/neural-speed/tree/main/neural_speed/models/gptj), and [Dolly-v2-3B](https://github.com/intel/neural-speed/tree/main/neural_speed/models/gptneox). Support AMX, VNNI, AVX512F and AVX2 instruction set. We've boosted the performance of Intel CPUs, with a particular focus on the 4th generation Intel Xeon Scalable processor, codenamed [Sapphire Rapids](https://www.intel.com/content/www/us/en/products/docs/processors/xeon-accelerated/4th-gen-xeon-scalable-processors.html).
opening-up-chatgpt.github.io
This repository provides a curated list of open-source projects that implement instruction-tuned large language models (LLMs) with reinforcement learning from human feedback (RLHF). The projects are evaluated in terms of their openness across a predefined set of criteria in the areas of Availability, Documentation, and Access. The goal of this repository is to promote transparency and accountability in the development and deployment of LLMs.
LLaMa2lang
This repository contains convenience scripts to finetune LLaMa3-8B (or any other foundation model) for chat towards any language (that isn't English). The rationale behind this is that LLaMa3 is trained on primarily English data and while it works to some extent for other languages, its performance is poor compared to English.

ollama
Ollama is a lightweight, extensible framework for building and running language models on the local machine. It provides a simple API for creating, running, and managing models, as well as a library of pre-built models that can be easily used in a variety of applications. Ollama is designed to be easy to use and accessible to developers of all levels. It is open source and available for free on GitHub.

llama_ros
This repository provides a set of ROS 2 packages to integrate llama.cpp into ROS 2. By using the llama_ros packages, you can easily incorporate the powerful optimization capabilities of llama.cpp into your ROS 2 projects by running GGUF-based LLMs and VLMs.

lobe-chat
Lobe Chat is an open-source, modern-design ChatGPT/LLMs UI/Framework. Supports speech-synthesis, multi-modal, and extensible ([function call][docs-functionc-call]) plugin system. One-click **FREE** deployment of your private OpenAI ChatGPT/Claude/Gemini/Groq/Ollama chat application.
fastllm
FastLLM is a high-performance large model inference library implemented in pure C++ with no third-party dependencies. Models of 6-7B size can run smoothly on Android devices. Deployment communication QQ group: 831641348