
matchem-llm
A public repository collecting links to state of the art QA and evaluation sets for various ML and LLM applications
Stars: 51
A public repository collecting links to state-of-the-art training sets, QA, benchmarks and other evaluations for various ML and LLM applications in materials science and chemistry. It includes datasets related to chemistry, materials, multimodal data, and knowledge graphs in the field. The repository aims to provide resources for training and evaluating machine learning models in the materials science and chemistry domains.
README:
A public repository collecting links to state-of-the-art training sets, QA, benchmarks and other evaluations for various ML and LLM applications in materials science and chemistry.
- ChemQA: ChemQA is a Multimodal Question-and-Answering dataset on chemistry reasoning. This work is inspired by IsoBench and ChemLLMBench. Containts 5 QA Tasks in total: Counting Numbers of Carbons and Hydrogens in Organic Molecules, Calculating Molecular Weights in Organic Molecules, Name Conversion: From SMILES to IUPAC, Molecule Captioning and Editing, and retro-synthesis Planning: inspired by [2], adapted from dataset provided in [4], following the same training, validation and evaluation splits.
- ChemLLMBench: A comprehensive benchmark on eight chemistry tasks
- SMolInstruct: SMolInstruct is a large-scale, comprehensive, and high-quality instruction tuning dataset crafted for chemistry. It centers around small molecules, and contains 14 meticulously selected tasks and over 3M samples. This dataset has both SMILES and SELFIES versions, and you could switch to SELFIES by using use_selfies=True when loading. Tasks include name conversion, property prediction, molecule description, and chemical reaction prediction.
- CamelAI - Chemistry: Chemistry dataset is composed of 20K problem-solution pairs obtained using gpt-4. The dataset problem-solutions pairs generating from 25 chemistry topics, 25 subtopics for each topic and 32 problems for each "topic,subtopic" pairs.
- ChemData700k: ChemData is a large-scale chemistry competency instruction tuning dataset for language models, which includes nine chemistry core tasks and 730K high-quality questions and answers, sampled from 1/10 of 7 million pieces of data.
- ChemBench4k: ChemBench is a large-scale chemistry competency evaluation benchmark for language models, which includes nine chemistry core tasks and 4100 high-quality single-choice questions and answers.
- ChemBench - Lamalab: A benchmark with more than 7000 questions, manually curated for various chemical topics. Covering multi-choice and free-form questions. Supports models as well as tool-augmented systems. Provides leaderboards and human baseline. See paper for more details.
- Chem-RnD and ChemEDU CLAIRify: Chem-EDU (Everyday Educational Chemistry) - 40 natural language instructions containing only safe (edible) chamicals. Chem-RnD (Chemistry Research & Development) - 108 detailed chemistry-protocols for synthesizing different organic compounds in real-world chemisty labs. This is a subset of Benchmarking results and the XDL XML schema.
- Battery Device QA: Battery device records, including anode, cathode, and electrolyte. Examples of the question answering evaluation dataset: {'question': 'What is the cathode?', 'answer': 'Al foil', 'context': 'The blended slurry was then cast onto a clean current collector (Al foil for the cathode and Cu foil for the anode) and dried at 90 °C under vacuum overnight.', 'start index': 645}
- MaScQA: A dataset of 650 challenging questions from the materials domain that require the knowledge and skills of a materials science student who has cleared their undergraduate degree. Questions are classified based on their structure and the materials science domain-based subcategories.
- Optical BERT Training Data: Has HF errors, but data are available.
- Optical Table QA:
- LLMs for Sustainable Concrete paper
- PNCExtract: Extracting Polymer Nanocomposite Samples from Articles: The contains a manually curated list of samples for each PNC article. The data is divided into 52 validation articles and 151 test articles.
- MatKG: MatKG is a comprehensive Knowledge Graph of Materials Science that captures a diverse range of entities and relationships from scientific literature. MatKG includes materials, properties, applications, characterization methods, synthesis methods, symmetry phase labels, and descriptors, among other entities, which are extracted automatically using advanced natural language processing methods from over 5 million papers in the domain.
Chemistry Dataset from Andrersonbcedef
This is an area for relatively "open comments" one community needs.
- One good thing to add would be a benchmark set for weak interactions between aminoacids in proteins, if it exists. (Marcos Veríssimo Alves)
Ensuring safe usage of data is of paramount concern, especially for the chemistry data included in this list. We encourage all users of these data to read papers by e.g., Gabe Gomes et al. [1,2] on the potential dangers of dual use before constructing their datasets or models. If you have concerns about potential dual use of any of the datasets listed, create an issue and we will do our best to evaluate the safety concerns, remove the data, or consult with outside experts if necessary.
[1] Emergent autonomous scientific research capabilities of large language models [2] Censoring chemical data to mitigate dual use risk.
Add other resources to the list by 1. forking the repository and creating a pull request back to the main repository or 2. create an issue with the markdown that should be added to the repository and one of the admins will add to the main document.
If you would like to help maintain this repository, open an issue expressing your interest and we will reach out to you!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for matchem-llm
Similar Open Source Tools
matchem-llm
A public repository collecting links to state-of-the-art training sets, QA, benchmarks and other evaluations for various ML and LLM applications in materials science and chemistry. It includes datasets related to chemistry, materials, multimodal data, and knowledge graphs in the field. The repository aims to provide resources for training and evaluating machine learning models in the materials science and chemistry domains.

Me-LLaMA
Me LLaMA introduces a suite of open-source medical Large Language Models (LLMs), including Me LLaMA 13B/70B and their chat-enhanced versions. Developed through innovative continual pre-training and instruction tuning, these models leverage a vast medical corpus comprising PubMed papers, medical guidelines, and general domain data. Me LLaMA sets new benchmarks on medical reasoning tasks, making it a significant asset for medical NLP applications and research. The models are intended for computational linguistics and medical research, not for clinical decision-making without validation and regulatory approval.

kaapana
Kaapana is an open-source toolkit for state-of-the-art platform provisioning in the field of medical data analysis. The applications comprise AI-based workflows and federated learning scenarios with a focus on radiological and radiotherapeutic imaging. Obtaining large amounts of medical data necessary for developing and training modern machine learning methods is an extremely challenging effort that often fails in a multi-center setting, e.g. due to technical, organizational and legal hurdles. A federated approach where the data remains under the authority of the individual institutions and is only processed on-site is, in contrast, a promising approach ideally suited to overcome these difficulties. Following this federated concept, the goal of Kaapana is to provide a framework and a set of tools for sharing data processing algorithms, for standardized workflow design and execution as well as for performing distributed method development. This will facilitate data analysis in a compliant way enabling researchers and clinicians to perform large-scale multi-center studies. By adhering to established standards and by adopting widely used open technologies for private cloud development and containerized data processing, Kaapana integrates seamlessly with the existing clinical IT infrastructure, such as the Picture Archiving and Communication System (PACS), and ensures modularity and easy extensibility.

awesome-RLAIF
Reinforcement Learning from AI Feedback (RLAIF) is a concept that describes a type of machine learning approach where **an AI agent learns by receiving feedback or guidance from another AI system**. This concept is closely related to the field of Reinforcement Learning (RL), which is a type of machine learning where an agent learns to make a sequence of decisions in an environment to maximize a cumulative reward. In traditional RL, an agent interacts with an environment and receives feedback in the form of rewards or penalties based on the actions it takes. It learns to improve its decision-making over time to achieve its goals. In the context of Reinforcement Learning from AI Feedback, the AI agent still aims to learn optimal behavior through interactions, but **the feedback comes from another AI system rather than from the environment or human evaluators**. This can be **particularly useful in situations where it may be challenging to define clear reward functions or when it is more efficient to use another AI system to provide guidance**. The feedback from the AI system can take various forms, such as: - **Demonstrations** : The AI system provides demonstrations of desired behavior, and the learning agent tries to imitate these demonstrations. - **Comparison Data** : The AI system ranks or compares different actions taken by the learning agent, helping it to understand which actions are better or worse. - **Reward Shaping** : The AI system provides additional reward signals to guide the learning agent's behavior, supplementing the rewards from the environment. This approach is often used in scenarios where the RL agent needs to learn from **limited human or expert feedback or when the reward signal from the environment is sparse or unclear**. It can also be used to **accelerate the learning process and make RL more sample-efficient**. Reinforcement Learning from AI Feedback is an area of ongoing research and has applications in various domains, including robotics, autonomous vehicles, and game playing, among others.


aitlas
The AiTLAS toolbox (Artificial Intelligence Toolbox for Earth Observation) includes state-of-the-art machine learning methods for exploratory and predictive analysis of satellite imagery as well as a repository of AI-ready Earth Observation (EO) datasets. It can be easily applied for a variety of Earth Observation tasks, such as land use and cover classification, crop type prediction, localization of specific objects (semantic segmentation), etc. The main goal of AiTLAS is to facilitate better usability and adoption of novel AI methods (and models) by EO experts, while offering easy access and standardized format of EO datasets to AI experts which allows benchmarking of various existing and novel AI methods tailored for EO data.

text-to-sql-bedrock-workshop
This repository focuses on utilizing generative AI to bridge the gap between natural language questions and SQL queries, aiming to improve data consumption in enterprise data warehouses. It addresses challenges in SQL query generation, such as foreign key relationships and table joins, and highlights the importance of accuracy metrics like Execution Accuracy (EX) and Exact Set Match Accuracy (EM). The workshop content covers advanced prompt engineering, Retrieval Augmented Generation (RAG), fine-tuning models, and security measures against prompt and SQL injections.

RecAI
RecAI is a project that explores the integration of Large Language Models (LLMs) into recommender systems, addressing the challenges of interactivity, explainability, and controllability. It aims to bridge the gap between general-purpose LLMs and domain-specific recommender systems, providing a holistic perspective on the practical requirements of LLM4Rec. The project investigates various techniques, including Recommender AI agents, selective knowledge injection, fine-tuning language models, evaluation, and LLMs as model explainers, to create more sophisticated, interactive, and user-centric recommender systems.

awesome-synthetic-datasets
This repository focuses on organizing resources for building synthetic datasets using large language models. It covers important datasets, libraries, tools, tutorials, and papers related to synthetic data generation. The goal is to provide pragmatic and practical resources for individuals interested in creating synthetic datasets for machine learning applications.

awesome-generative-ai-guide
This repository serves as a comprehensive hub for updates on generative AI research, interview materials, notebooks, and more. It includes monthly best GenAI papers list, interview resources, free courses, and code repositories/notebooks for developing generative AI applications. The repository is regularly updated with the latest additions to keep users informed and engaged in the field of generative AI.
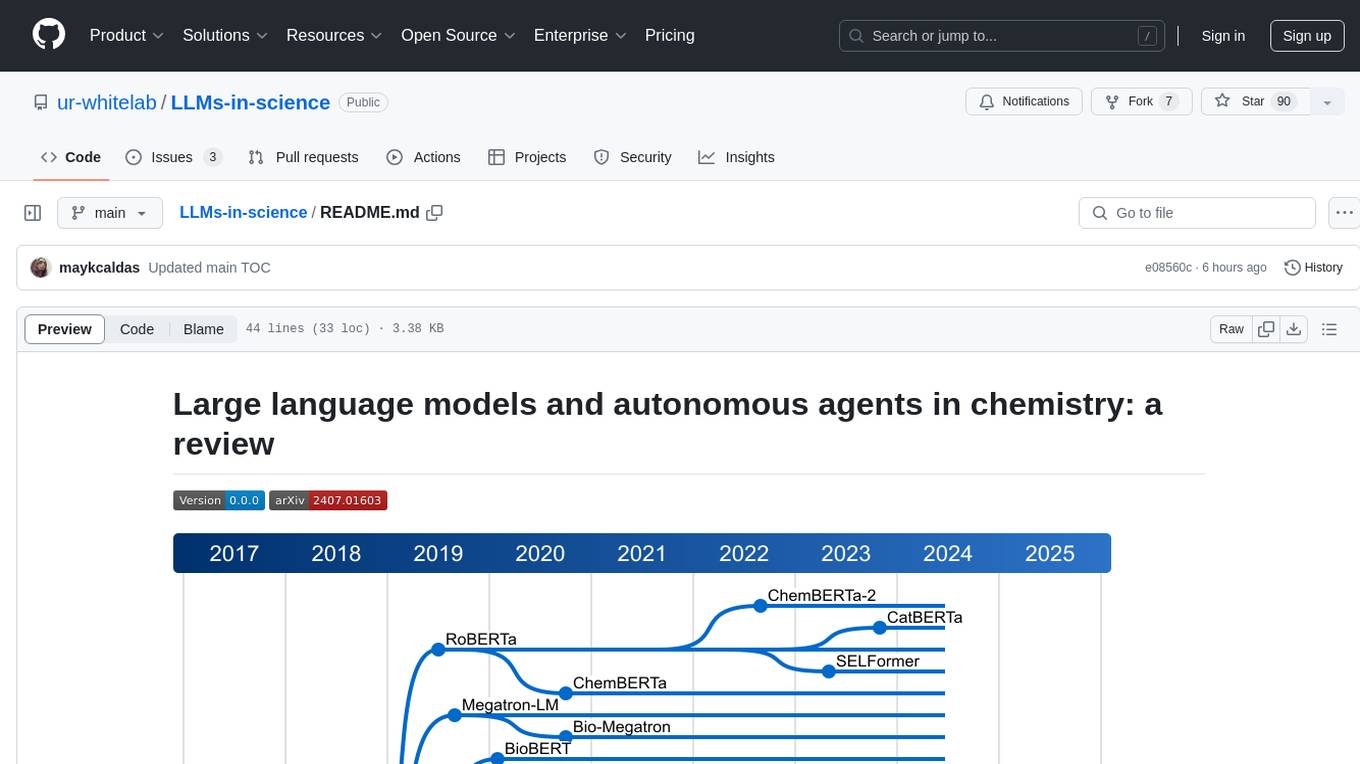
LLMs-in-science
The 'LLMs-in-science' repository is a collaborative environment for organizing papers related to large language models (LLMs) and autonomous agents in the field of chemistry. The goal is to discuss trend topics, challenges, and the potential for supporting scientific discovery in the context of artificial intelligence. The repository aims to maintain a systematic structure of the field and welcomes contributions from the community to keep the content up-to-date and relevant.

Main
This repository contains material related to the new book _Synthetic Data and Generative AI_ by the author, including code for NoGAN, DeepResampling, and NoGAN_Hellinger. NoGAN is a tabular data synthesizer that outperforms GenAI methods in terms of speed and results, utilizing state-of-the-art quality metrics. DeepResampling is a fast NoGAN based on resampling and Bayesian Models with hyperparameter auto-tuning. NoGAN_Hellinger combines NoGAN and DeepResampling with the Hellinger model evaluation metric.

DNAnalyzer
DNAnalyzer is a nonprofit organization dedicated to revolutionizing DNA analysis through AI-powered tools. It aims to democratize access to DNA analysis for a deeper understanding of human health and disease. The tool provides innovative AI-powered analysis and interpretive tools to empower geneticists, physicians, and researchers to gain deep insights into DNA sequences, revolutionizing how we understand human health and disease.

SuperKnowa
SuperKnowa is a fast framework to build Enterprise RAG (Retriever Augmented Generation) Pipelines at Scale, powered by watsonx. It accelerates Enterprise Generative AI applications to get prod-ready solutions quickly on private data. The framework provides pluggable components for tackling various Generative AI use cases using Large Language Models (LLMs), allowing users to assemble building blocks to address challenges in AI-driven text generation. SuperKnowa is battle-tested from 1M to 200M private knowledge base & scaled to billions of retriever tokens.

nlp-llms-resources
The 'nlp-llms-resources' repository is a comprehensive resource list for Natural Language Processing (NLP) and Large Language Models (LLMs). It covers a wide range of topics including traditional NLP datasets, data acquisition, libraries for NLP, neural networks, sentiment analysis, optical character recognition, information extraction, semantics, topic modeling, multilingual NLP, domain-specific LLMs, vector databases, ethics, costing, books, courses, surveys, aggregators, newsletters, papers, conferences, and societies. The repository provides valuable information and resources for individuals interested in NLP and LLMs.
For similar tasks
matchem-llm
A public repository collecting links to state-of-the-art training sets, QA, benchmarks and other evaluations for various ML and LLM applications in materials science and chemistry. It includes datasets related to chemistry, materials, multimodal data, and knowledge graphs in the field. The repository aims to provide resources for training and evaluating machine learning models in the materials science and chemistry domains.

Scientific-LLM-Survey
Scientific Large Language Models (Sci-LLMs) is a repository that collects papers on scientific large language models, focusing on biology and chemistry domains. It includes textual, molecular, protein, and genomic languages, as well as multimodal language. The repository covers various large language models for tasks such as molecule property prediction, interaction prediction, protein sequence representation, protein sequence generation/design, DNA-protein interaction prediction, and RNA prediction. It also provides datasets and benchmarks for evaluating these models. The repository aims to facilitate research and development in the field of scientific language modeling.
For similar jobs
matchem-llm
A public repository collecting links to state-of-the-art training sets, QA, benchmarks and other evaluations for various ML and LLM applications in materials science and chemistry. It includes datasets related to chemistry, materials, multimodal data, and knowledge graphs in the field. The repository aims to provide resources for training and evaluating machine learning models in the materials science and chemistry domains.

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.