
long-context-attention
Sequence Parallel Attention for Long Context LLM Model Training and Inference
Stars: 266

Long-Context-Attention (YunChang) is a unified sequence parallel approach that combines the strengths of DeepSpeed-Ulysses-Attention and Ring-Attention to provide a versatile and high-performance solution for long context LLM model training and inference. It addresses the limitations of both methods by offering no limitation on the number of heads, compatibility with advanced parallel strategies, and enhanced performance benchmarks. The tool is verified in Megatron-LM and offers best practices for 4D parallelism, making it suitable for various attention mechanisms and parallel computing advancements.
README:
Long-Context-Attention (YunChang-云长): A Unified Sequence Parallel (USP) Attention for Long Context LLM Model Training and Inference
[Tech Report] USP: A Unified Sequence Parallelism Approach for Long Context Generative AI

This repo provides a sequence parallel approach that synergizes the strengths of two popular distributed attentions, i.e. DeepSpeed-Ulysses-Attention and Ring-Attention, delivering a more general and stronger versatility and better performance. The project is built on zhuzilin/ring-flash-attention and refers to the DeepSpeed-Ulysses.
-
Ulysses is sensitive to the number of attention heads. The parallelism degree in Ulysses cannot exceed the number of heads. Consequently, it is not suitable for GQA (Grouped Query Attention) and MQA (Multi-Query Attention) scenarios. For instance, Ulysses does not operate effectively with a single head. In addition, since Tensor Parallelism also requires division across the head number dimension, achieving compatibility between Ulysses and TP can be challenging.
-
Ring-Attention is ineffient than Ulysses in computation and communication. Ring-Attention segments the Query, Key, and Value (QKV) into smaller blocks, which can lead to a decrease in efficiency when using FlashAttention. Even with the communication and computation processes fully overlapped, the total execution time lags behind that of Ulysses. Furthermore, Ring-Attention utilizes asynchronous peer-to-peer communication, which not only has a lower bandwidth utilization compared to collective communication methods but also poses the risk of potential communication deadlocks in large-scale deployments.
LongContextAttention is a unified sequence parallel , also known as hybrid sequence parallel ,that hybrid DeepSpeed-Ulysses-Attention and Ring-Attention therefore addressing the limitations of both methods.

Option 1: pip install from pypi.
pip install yunchang==0.2
Option 2: build from local.
pip install .
Features:
-
No Limitation on the Number of Heads: Our approach does not impose a restriction on the number of heads, providing greater flexibility for various attention mechanisms.
-
Cover the Capability of either Ulysses and Ring: By setting the ulysses_degree to the sequence parallel degree, the system operates identically to Ulysses. Conversely, setting the ulysses_degree to 1 mirrors the functionality of Ring.
-
Enhanced Performance: We achieve superior performance benchmarks over both Ulysses and Ring, offering a more efficient solution for attention mechanism computations.
-
Compatibility with Advanced Parallel Strategies: LongContextAttention is fully compatible with other sophisticated parallelization techniques, including Tensor Parallelism, ZeRO, and Pipeline Parallelism, ensuring seamless integration with the latest advancements in parallel computing.
The loss curves for Data Parallel (DP) and Unified Sequence Parallel (ulysses=2+ring=2) are closely aligned, as illustrated in the figure. This alignment confirms the accuracy of the unified sequence parallel.

You should reorder Query tensors with EXTRACT_FUNC_DICT when using load-balance Ring Attention when applying the causal mask. In the Megatron-LM, you can reorder the input tokens before feed them into the model and apply the same reordering to RoPE parameters. See our paper for detailed instructions.
We analyze the impact of introducing Sequnce Parallelism to Data/ZeRO/Tensor/Pipeline Parallelism in a technique report, which can be found at here.
Some best practices are listed here:
-
We suggest using Unified-SP in place of SP-Ring and SP-Ulysses, as it encompasses the capabilities of both while offering additional benefits.
-
DP (data parallelism) vs SP: We suggest prioritizing the use of DP over SP if possible. Only when the batch size (bs) is insufficient for partitioning should one consider whether to employ SP
-
Utilizing SP, it should always be used in conjunction wit ZeRO-1/2.
-
Unified-SP has lower communication cost than Tensor Parallel with megatron-lm sequence parallelism (TP-sp)! You can use Unified-SP to replace TP for better speed. However, now switching TP (tensor parallelism) to SP+ZeRO2 cannot increase the sequence length in training. SP+ZeRO3 can train a similar sequence length as TP-sp. We suggest that SP may have an advantage over TP when employing GQA in terms of communication cost, as GQA can reduce the communication cost of SP without affecting TP.
-
Setting a higher parallel degree of SP parallelism is possible, which may need to set a large ring degree when the head number is limited, to train a long sequence across a greater number of computational devices. But TP could not be set a high parallel.
torchrun --nproc_per_node 8 test/test_hybrid_qkvpacked_attn.pybash ./scripts/run_qkvpack_compare.shOn an 8xA100 NVLink machine, the benchmark results are as follows:

On an 8xL20 PCIe machine and a 4xA100 PCIe machine, the benchmark results are as follows:

Some Conclusions:
-
If the head number is enough, Ulysses outperforms Ring-Attention. The All-to-All communication of Ulysses is highly efficient within a single machine, with a very low overhead ratio. In contrast, Ring splits computation and communication, which increases the overall of computation time, and even with complete overlap, it is slower than Ulysses.
-
QKV packed (
LongContextAttentionQKVPacked) is better than the QKV no packed (LongContextAttention) version, with the difference becoming more pronounced as the sequence length decreases. MAQ and GQA can only use the no packed version. -
Among the variants of the Ring-Attention implementation,
zigzagandstripeperform better thanbasic. Typically, zigzag is slightly better than stripe, but as the sequence length increases, the difference between zigzag and stripe becomes less noticeable. It is worth noting that both zigzag and stripe have specific layout requirements for the sequence dimension. -
Hybrid parallelism works well to heterogeneous network devices. For example, on an 8-GPU L20 setup, the optimal performance is achieved when ulysess_degree is set to 2 and ring_degree is set to 4.
I am honored that this repository has contributed to the following projects:
- xdit-project/xDiT
- NVlabs/VILA
- feifeibear/Odysseus-Transformer
- Ascend/AscendSpeed
- jzhang38/EasyContext
@article{fang2024unified,
title={USP: A Unified Sequence Parallelism Approach for Long Context Generative AI},
author={Fang, Jiarui and Zhao, Shangchun},
journal={arXiv preprint arXiv:2405.07719},
year={2024}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for long-context-attention
Similar Open Source Tools
long-context-attention
Long-Context-Attention (YunChang) is a unified sequence parallel approach that combines the strengths of DeepSpeed-Ulysses-Attention and Ring-Attention to provide a versatile and high-performance solution for long context LLM model training and inference. It addresses the limitations of both methods by offering no limitation on the number of heads, compatibility with advanced parallel strategies, and enhanced performance benchmarks. The tool is verified in Megatron-LM and offers best practices for 4D parallelism, making it suitable for various attention mechanisms and parallel computing advancements.

LongRoPE
LongRoPE is a method to extend the context window of large language models (LLMs) beyond 2 million tokens. It identifies and exploits non-uniformities in positional embeddings to enable 8x context extension without fine-tuning. The method utilizes a progressive extension strategy with 256k fine-tuning to reach a 2048k context. It adjusts embeddings for shorter contexts to maintain performance within the original window size. LongRoPE has been shown to be effective in maintaining performance across various tasks from 4k to 2048k context lengths.
aihwkit
The IBM Analog Hardware Acceleration Kit is an open-source Python toolkit for exploring and using the capabilities of in-memory computing devices in the context of artificial intelligence. It consists of two main components: Pytorch integration and Analog devices simulator. The Pytorch integration provides a series of primitives and features that allow using the toolkit within PyTorch, including analog neural network modules, analog training using torch training workflow, and analog inference using torch inference workflow. The Analog devices simulator is a high-performant (CUDA-capable) C++ simulator that allows for simulating a wide range of analog devices and crossbar configurations by using abstract functional models of material characteristics with adjustable parameters. Along with the two main components, the toolkit includes other functionalities such as a library of device presets, a module for executing high-level use cases, a utility to automatically convert a downloaded model to its equivalent Analog model, and integration with the AIHW Composer platform. The toolkit is currently in beta and under active development, and users are advised to be mindful of potential issues and keep an eye for improvements, new features, and bug fixes in upcoming versions.

LLM-Viewer
LLM-Viewer is a tool for visualizing Language and Learning Models (LLMs) and analyzing performance on different hardware platforms. It enables network-wise analysis, considering factors such as peak memory consumption and total inference time cost. With LLM-Viewer, users can gain valuable insights into LLM inference and performance optimization. The tool can be used in a web browser or as a command line interface (CLI) for easy configuration and visualization. The ongoing project aims to enhance features like showing tensor shapes, expanding hardware platform compatibility, and supporting more LLMs with manual model graph configuration.
LLM-Geo
LLM-Geo is an AI-powered geographic information system (GIS) that leverages Large Language Models (LLMs) for automatic spatial data collection, analysis, and visualization. By adopting LLM as the reasoning core, it addresses spatial problems with self-generating, self-organizing, self-verifying, self-executing, and self-growing capabilities. The tool aims to make spatial analysis easier, faster, and more accessible by reducing manual operation time and delivering accurate results through case studies. It uses GPT-4 API in a Python environment and advocates for further research and development in autonomous GIS.

awesome-transformer-nlp
This repository contains a hand-curated list of great machine (deep) learning resources for Natural Language Processing (NLP) with a focus on Generative Pre-trained Transformer (GPT), Bidirectional Encoder Representations from Transformers (BERT), attention mechanism, Transformer architectures/networks, Chatbot, and transfer learning in NLP.
Nanoflow
NanoFlow is a throughput-oriented high-performance serving framework for Large Language Models (LLMs) that consistently delivers superior throughput compared to other frameworks by utilizing key techniques such as intra-device parallelism, asynchronous CPU scheduling, and SSD offloading. The framework proposes nano-batching to schedule compute-, memory-, and network-bound operations for simultaneous execution, leading to increased resource utilization. NanoFlow also adopts an asynchronous control flow to optimize CPU overhead and eagerly offloads KV-Cache to SSDs for multi-round conversations. The open-source codebase integrates state-of-the-art kernel libraries and provides necessary scripts for environment setup and experiment reproduction.
llvm-aie
This repository extends the LLVM framework to generate code for use with AMD/Xilinx AI Engine processors. AI Engine processors are in-order, exposed-pipeline VLIW processors focused on application acceleration for AI, Machine Learning, and DSP applications. The repository adds LLVM support for specific features like non-power of 2 pointers, operand latencies, resource conflicts, negative operand latencies, slot assignment, relocations, code alignment restrictions, and register allocation. It includes support for Clang, LLD, binutils, Compiler-RT, and LLVM-LIBC.

ManipVQA
ManipVQA is a framework that enhances Multimodal Large Language Models (MLLMs) with manipulation-centric knowledge through a Visual Question-Answering (VQA) format. It addresses the deficiency of conventional MLLMs in understanding affordances and physical concepts crucial for manipulation tasks. By infusing robotics-specific knowledge, including tool detection, affordance recognition, and physical concept comprehension, ManipVQA improves the performance of robots in manipulation tasks. The framework involves fine-tuning MLLMs with a curated dataset of interactive objects, enabling robots to understand and execute natural language instructions more effectively.
audioseal
AudioSeal is a method for speech localized watermarking, designed with state-of-the-art robustness and detector speed. It jointly trains a generator to embed a watermark in audio and a detector to detect watermarked fragments in longer audios, even in the presence of editing. The tool achieves top-notch detection performance at the sample level, generates minimal alteration of signal quality, and is robust to various audio editing types. With a fast, single-pass detector, AudioSeal surpasses existing models in speed, making it ideal for large-scale and real-time applications.

marlin
Marlin is a highly optimized FP16xINT4 matmul kernel designed for large language model (LLM) inference, offering close to ideal speedups up to batchsizes of 16-32 tokens. It is suitable for larger-scale serving, speculative decoding, and advanced multi-inference schemes like CoT-Majority. Marlin achieves optimal performance by utilizing various techniques and optimizations to fully leverage GPU resources, ensuring efficient computation and memory management.
algebraic-nnhw
This repository contains the source code for a GEMM & deep learning hardware accelerator system used to validate proposed systolic array hardware architectures implementing efficient matrix multiplication algorithms to increase performance-per-area limits of GEMM & AI accelerators. Achieved results include up to 3× faster CNN inference, >2× higher mults/multiplier/clock cycle, and low area with high clock frequency. The system is specialized for inference of non-sparse DNN models with fixed-point/quantized inputs, fully accelerating all DNN layers in hardware, and highly optimizing GEMM acceleration.
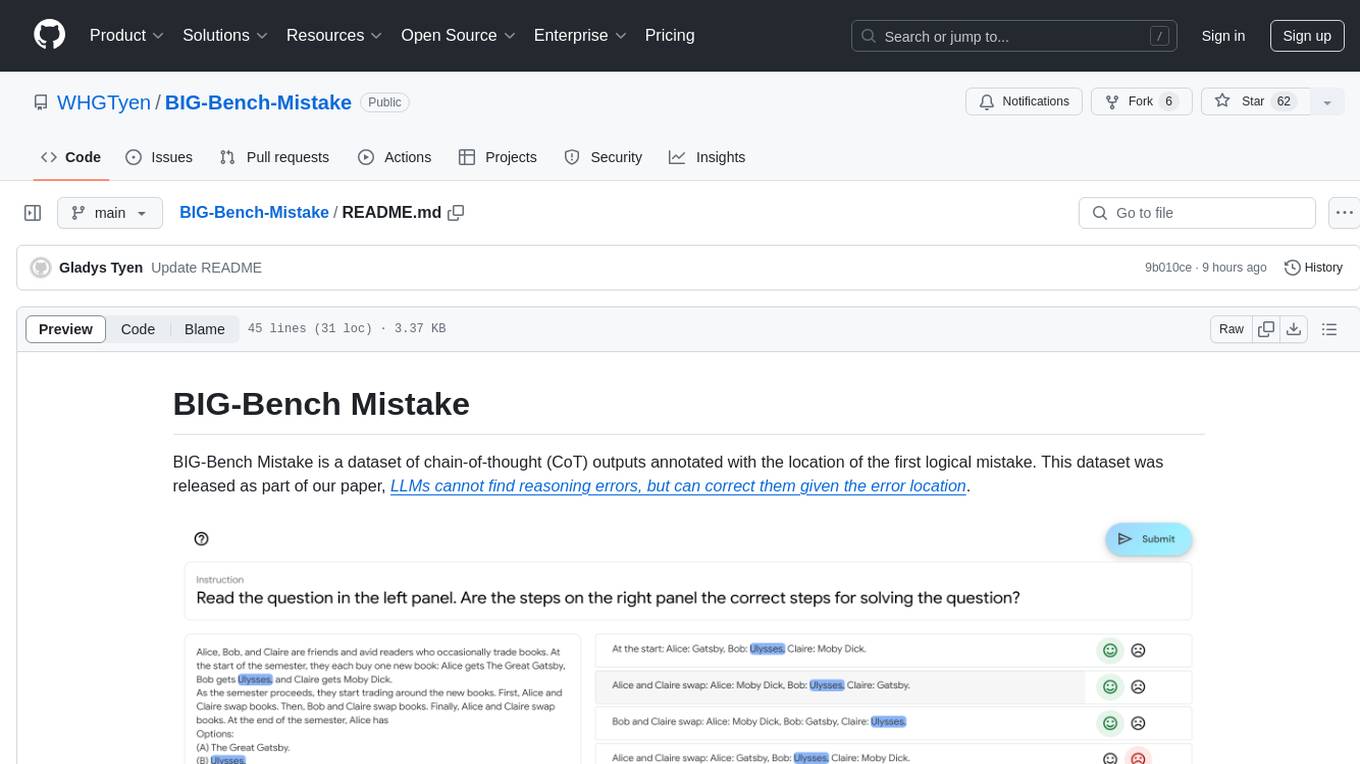
BIG-Bench-Mistake
BIG-Bench Mistake is a dataset of chain-of-thought (CoT) outputs annotated with the location of the first logical mistake. It was released as part of a research paper focusing on benchmarking LLMs in terms of their mistake-finding ability. The dataset includes CoT traces for tasks like Word Sorting, Tracking Shuffled Objects, Logical Deduction, Multistep Arithmetic, and Dyck Languages. Human annotators were recruited to identify mistake steps in these tasks, with automated annotation for Dyck Languages. Each JSONL file contains input questions, steps in the chain of thoughts, model's answer, correct answer, and the index of the first logical mistake.
aligner
Aligner is a model-agnostic alignment tool that learns correctional residuals between preferred and dispreferred answers using a small model. It can be directly applied to various open-source and API-based models with only one-off training, suitable for rapid iteration and improving model performance. Aligner has shown significant improvements in helpfulness, harmlessness, and honesty dimensions across different large language models.
AI4Animation
AI4Animation is a comprehensive framework for data-driven character animation, including data processing, neural network training, and runtime control, developed in Unity3D/PyTorch. It explores deep learning opportunities for character animation, covering biped and quadruped locomotion, character-scene interactions, sports and fighting games, and embodied avatar motions in AR/VR. The research focuses on generative frameworks, codebook matching, periodic autoencoders, animation layering, local motion phases, and neural state machines for character control and animation.
Graph-CoT
This repository contains the source code and datasets for Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs accepted to ACL 2024. It proposes a framework called Graph Chain-of-thought (Graph-CoT) to enable Language Models to traverse graphs step-by-step for reasoning, interaction, and execution. The motivation is to alleviate hallucination issues in Language Models by augmenting them with structured knowledge sources represented as graphs.
For similar tasks

arena-hard-auto
Arena-Hard-Auto-v0.1 is an automatic evaluation tool for instruction-tuned LLMs. It contains 500 challenging user queries. The tool prompts GPT-4-Turbo as a judge to compare models' responses against a baseline model (default: GPT-4-0314). Arena-Hard-Auto employs an automatic judge as a cheaper and faster approximator to human preference. It has the highest correlation and separability to Chatbot Arena among popular open-ended LLM benchmarks. Users can evaluate their models' performance on Chatbot Arena by using Arena-Hard-Auto.

max
The Modular Accelerated Xecution (MAX) platform is an integrated suite of AI libraries, tools, and technologies that unifies commonly fragmented AI deployment workflows. MAX accelerates time to market for the latest innovations by giving AI developers a single toolchain that unlocks full programmability, unparalleled performance, and seamless hardware portability.

ai-hub
AI Hub Project aims to continuously test and evaluate mainstream large language models, while accumulating and managing various effective model invocation prompts. It has integrated all mainstream large language models in China, including OpenAI GPT-4 Turbo, Baidu ERNIE-Bot-4, Tencent ChatPro, MiniMax abab5.5-chat, and more. The project plans to continuously track, integrate, and evaluate new models. Users can access the models through REST services or Java code integration. The project also provides a testing suite for translation, coding, and benchmark testing.
long-context-attention
Long-Context-Attention (YunChang) is a unified sequence parallel approach that combines the strengths of DeepSpeed-Ulysses-Attention and Ring-Attention to provide a versatile and high-performance solution for long context LLM model training and inference. It addresses the limitations of both methods by offering no limitation on the number of heads, compatibility with advanced parallel strategies, and enhanced performance benchmarks. The tool is verified in Megatron-LM and offers best practices for 4D parallelism, making it suitable for various attention mechanisms and parallel computing advancements.
marlin
Marlin is a highly optimized FP16xINT4 matmul kernel designed for large language model (LLM) inference, offering close to ideal speedups up to batchsizes of 16-32 tokens. It is suitable for larger-scale serving, speculative decoding, and advanced multi-inference schemes like CoT-Majority. Marlin achieves optimal performance by utilizing various techniques and optimizations to fully leverage GPU resources, ensuring efficient computation and memory management.

MMC
This repository, MMC, focuses on advancing multimodal chart understanding through large-scale instruction tuning. It introduces a dataset supporting various tasks and chart types, a benchmark for evaluating reasoning capabilities over charts, and an assistant achieving state-of-the-art performance on chart QA benchmarks. The repository provides data for chart-text alignment, benchmarking, and instruction tuning, along with existing datasets used in experiments. Additionally, it offers a Gradio demo for the MMCA model.

Tiktoken
Tiktoken is a high-performance implementation focused on token count operations. It provides various encodings like o200k_base, cl100k_base, r50k_base, p50k_base, and p50k_edit. Users can easily encode and decode text using the provided API. The repository also includes a benchmark console app for performance tracking. Contributions in the form of PRs are welcome.

ppl.llm.serving
ppl.llm.serving is a serving component for Large Language Models (LLMs) within the PPL.LLM system. It provides a server based on gRPC and supports inference for LLaMA. The repository includes instructions for prerequisites, quick start guide, model exporting, server setup, client usage, benchmarking, and offline inference. Users can refer to the LLaMA Guide for more details on using this serving component.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.