
LongRoPE
Implementation of the LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens Paper
Stars: 94

LongRoPE is a method to extend the context window of large language models (LLMs) beyond 2 million tokens. It identifies and exploits non-uniformities in positional embeddings to enable 8x context extension without fine-tuning. The method utilizes a progressive extension strategy with 256k fine-tuning to reach a 2048k context. It adjusts embeddings for shorter contexts to maintain performance within the original window size. LongRoPE has been shown to be effective in maintaining performance across various tasks from 4k to 2048k context lengths.
README:
tags:
- large-language-models
- text-generation
- context-extension
- transformer-models
- fine-tuning
- long-contexts
- natural-language-processing
- context-window
- context-length
- nlp
- llm
- llm-context-window
- llm-context-length datasets:
- wikitext
- custom-dataset metrics:
- perplexity
- accuracy
The paper introduces LongRoPE, a method to extend the context window of large language models (LLMs) beyond 2 million tokens.
The key ideas are:
-
Identify and exploit two forms of non-uniformities in positional embeddings to minimize information loss during interpolation. This enables 8x context extension without fine-tuning.
-
Use an efficient progressive extension strategy with 256k fine-tuning to reach 2048k context, instead of directly fine-tuning an extremely large context.
-
Adjust embeddings for shorter contexts to recover performance within original window size.
The method is applied to LLaMA2 and Mistral. Experiments across various tasks demonstrate LongRoPE's effectiveness in maintaining performance from 4k to 2048k context lengths.
The Transformer architecture struggles with the quadratic computational complexity of self-attention and its lack of generalization to token positions unseen at training time. To scale the self-attention computation to a large context, various methods have been proposed, such as the RoPE, AliBi, attention sinks, etc. Nonetheless, none of these solutions can effectively scale to context with millions of tokens while preserving the model's accuracy.
This paper presents a new technique, LongRoPE, expanding the context window of LLMs to over 2 million tokens.
LongRoPE utilizes a progressive extension strategy to attain a 2048k context window without necessitating direct fine-tuning on exceedingly lengthy texts, which are both rare and difficult to procure. This strategy initiates with a 256k extension on a pre-trained LLM, followed by fine-tuning at this length.
To address potential performance declines in the original (shorter) context window, LongRoPE further adjusts the RoPE rescale factors on the extended LLM, scaling down to 4k and 8k context windows on the 256k fine-tuned LLM using its search algorithm to minimize positional interpolation. During inference for sequences under 8k in length, RoPE is updated with these meticulously searched rescale factors.
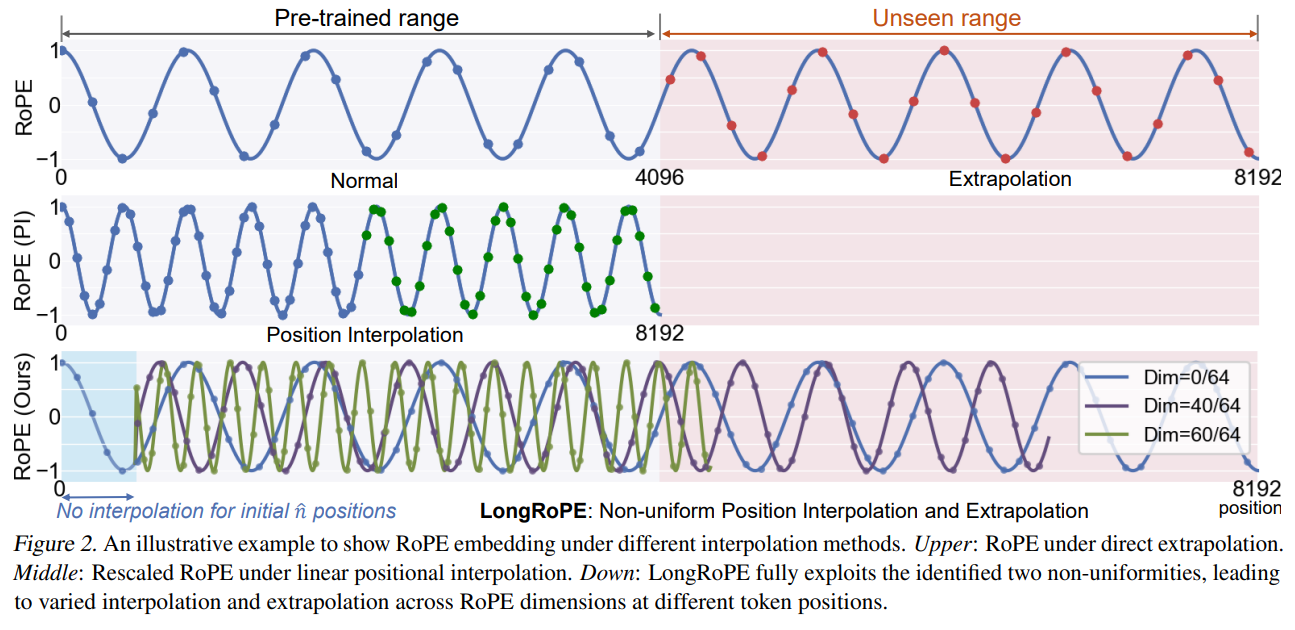
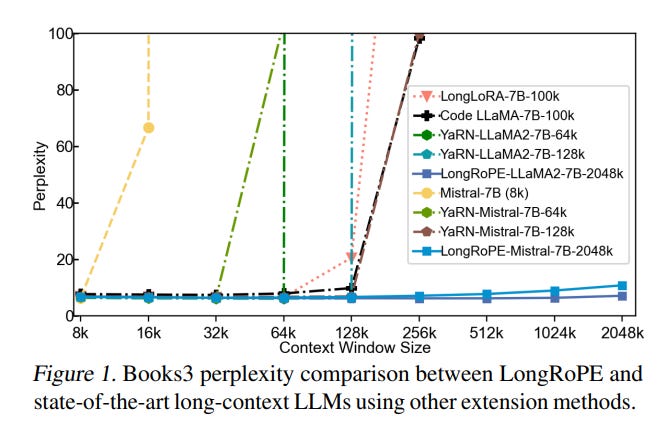
Testing across various LLMs and tasks requiring long contexts has validated LongRoPE's efficacy. The method significantly maintains low perplexity across evaluation lengths from 4k to 2048k tokens, achieves above 90% accuracy in passkey retrieval, and delivers accuracy comparable to standard benchmarks within a 4096 context window
- Enable in-context learning with more examples to boost LLM reasoning
- Build LLM agents that leverage longer context for tasks like dialog and question answering
- Summarize very long documents by utilizing the full document context
- Improve few-shot learning by providing more contextual examples to models
- Enable long-term memory by utilizing the full context window
An in-depth look at the structural modifications and their implications for model performance.
The LongRoPE model architecture is designed to extend the context window of large language models (LLMs) to over 2 million tokens, addressing the limitations of traditional Transformer architectures. The key innovation lies in the progressive extension strategy and the adjustment of positional embeddings.
The architecture begins with a pre-trained LLM and extends its context window incrementally. Initially, the model is fine-tuned to handle a context length of 256k tokens. This progressive approach avoids the need for direct fine-tuning on extremely long texts, which are rare and computationally expensive to process. By gradually increasing the context length, the model can adapt more effectively to longer sequences.
To maintain performance across varying context lengths, LongRoPE adjusts the Rotary Positional Embeddings (RoPE). The model identifies and exploits non-uniformities in positional embeddings to minimize information loss during interpolation. This allows for an 8x context extension without the need for fine-tuning. Additionally, the model employs a search algorithm to find optimal rescale factors for shorter contexts (e.g., 4k and 8k tokens) on the 256k fine-tuned LLM. These adjustments ensure that the model retains high performance even within the original context window size.
The architecture incorporates several structural modifications to handle the increased context length efficiently:
-
Layer Scaling: Adjustments are made to the scaling of layers to ensure stability and performance as the context window grows.
-
Memory Management: Efficient memory management techniques are employed to handle the large context sizes without overwhelming the system resources.
-
Attention Mechanisms: Enhanced attention mechanisms are integrated to ensure that the model can focus on relevant parts of the input sequence, even with the extended context.
Experiments demonstrate that LongRoPE maintains low perplexity across evaluation lengths from 4k to 2048k tokens and achieves high accuracy in tasks requiring long contexts. This makes it suitable for various applications, including in-context learning, long document summarization, and few-shot learning.
For more detailed information, please refer to the full paper here.
Insights into the coding and operational specifics that enable LongRoPE's functionality. This may include snippets or pseudocode illustrating key components.
For more detailed information, please refer to the paper.
Comprehensive examples demonstrating how to leverage LongRoPE for various applications, from text analysis to generating extensive documents.
# Example usage
data_path = "path/to/your/dataset"
d_model = 512
n_heads = 8
num_layers = 6
base_length = 4096
target_length = 2048 * 1024
data = load_data(data_path)
model = LongRoPEModel(d_model, n_heads, num_layers, base_length)
model = model.extend_context(data, target_length)
input_ids = torch.randn(2, target_length, d_model)
output = model(input_ids)
print(output.shape) # Expected shape: (batch_size, target_length, d_model)@article{ding2024longrope,
title={LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens},
author={Ding, Yiran and Zhang, Li Lyna and Zhang, Chengruidong and Xu, Yuanyuan and Shang, Ning and Xu, Jiahang and Yang, Fan and Yang, Mao},
journal={arXiv preprint arXiv:2402.13753},
year={2024}
}Note: This repository is a work in progress and is not yet ready for production use. Please refer to the paper for more details.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LongRoPE
Similar Open Source Tools
LongRoPE
LongRoPE is a method to extend the context window of large language models (LLMs) beyond 2 million tokens. It identifies and exploits non-uniformities in positional embeddings to enable 8x context extension without fine-tuning. The method utilizes a progressive extension strategy with 256k fine-tuning to reach a 2048k context. It adjusts embeddings for shorter contexts to maintain performance within the original window size. LongRoPE has been shown to be effective in maintaining performance across various tasks from 4k to 2048k context lengths.

llama3_interpretability_sae
This project focuses on implementing Sparse Autoencoders (SAEs) for mechanistic interpretability in Large Language Models (LLMs) like Llama 3.2-3B. The SAEs aim to untangle superimposed representations in LLMs into separate, interpretable features for each neuron activation. The project provides an end-to-end pipeline for capturing training data, training the SAEs, analyzing learned features, and verifying results experimentally. It includes comprehensive logging, visualization, and checkpointing of SAE training, interpretability analysis tools, and a pure PyTorch implementation of Llama 3.1/3.2 chat and text completion. The project is designed for scalability, efficiency, and maintainability.

long-context-attention
Long-Context-Attention (YunChang) is a unified sequence parallel approach that combines the strengths of DeepSpeed-Ulysses-Attention and Ring-Attention to provide a versatile and high-performance solution for long context LLM model training and inference. It addresses the limitations of both methods by offering no limitation on the number of heads, compatibility with advanced parallel strategies, and enhanced performance benchmarks. The tool is verified in Megatron-LM and offers best practices for 4D parallelism, making it suitable for various attention mechanisms and parallel computing advancements.


MemoryBear
MemoryBear is a next-generation AI memory system developed by RedBear AI, focusing on overcoming limitations in knowledge storage and multi-agent collaboration. It empowers AI with human-like memory capabilities, enabling deep knowledge understanding and cognitive collaboration. The system addresses challenges such as knowledge forgetting, memory gaps in multi-agent collaboration, and semantic ambiguity during reasoning. MemoryBear's core features include memory extraction engine, graph storage, hybrid search, memory forgetting engine, self-reflection engine, and FastAPI services. It offers a standardized service architecture for efficient integration and invocation across applications.

ManipVQA
ManipVQA is a framework that enhances Multimodal Large Language Models (MLLMs) with manipulation-centric knowledge through a Visual Question-Answering (VQA) format. It addresses the deficiency of conventional MLLMs in understanding affordances and physical concepts crucial for manipulation tasks. By infusing robotics-specific knowledge, including tool detection, affordance recognition, and physical concept comprehension, ManipVQA improves the performance of robots in manipulation tasks. The framework involves fine-tuning MLLMs with a curated dataset of interactive objects, enabling robots to understand and execute natural language instructions more effectively.
aligner
Aligner is a model-agnostic alignment tool that learns correctional residuals between preferred and dispreferred answers using a small model. It can be directly applied to various open-source and API-based models with only one-off training, suitable for rapid iteration and improving model performance. Aligner has shown significant improvements in helpfulness, harmlessness, and honesty dimensions across different large language models.
MoBA
MoBA (Mixture of Block Attention) is an innovative approach for long-context language models, enabling efficient processing of long sequences by dividing the full context into blocks and introducing a parameter-less gating mechanism. It allows seamless transitions between full and sparse attention modes, enhancing efficiency without compromising performance. MoBA has been deployed to support long-context requests and demonstrates significant advancements in efficient attention computation for large language models.

hallucination-index
LLM Hallucination Index - RAG Special is a comprehensive evaluation of large language models (LLMs) focusing on context length and open vs. closed-source attributes. The index explores the impact of context length on model performance and tests the assumption that closed-source LLMs outperform open-source ones. It also investigates the effectiveness of prompting techniques like Chain-of-Note across different context lengths. The evaluation includes 22 models from various brands, analyzing major trends and declaring overall winners based on short, medium, and long context insights. Methodologies involve rigorous testing with different context lengths and prompting techniques to assess models' abilities in handling extensive texts and detecting hallucinations.

Me-LLaMA
Me LLaMA introduces a suite of open-source medical Large Language Models (LLMs), including Me LLaMA 13B/70B and their chat-enhanced versions. Developed through innovative continual pre-training and instruction tuning, these models leverage a vast medical corpus comprising PubMed papers, medical guidelines, and general domain data. Me LLaMA sets new benchmarks on medical reasoning tasks, making it a significant asset for medical NLP applications and research. The models are intended for computational linguistics and medical research, not for clinical decision-making without validation and regulatory approval.

awesome-RLAIF
Reinforcement Learning from AI Feedback (RLAIF) is a concept that describes a type of machine learning approach where **an AI agent learns by receiving feedback or guidance from another AI system**. This concept is closely related to the field of Reinforcement Learning (RL), which is a type of machine learning where an agent learns to make a sequence of decisions in an environment to maximize a cumulative reward. In traditional RL, an agent interacts with an environment and receives feedback in the form of rewards or penalties based on the actions it takes. It learns to improve its decision-making over time to achieve its goals. In the context of Reinforcement Learning from AI Feedback, the AI agent still aims to learn optimal behavior through interactions, but **the feedback comes from another AI system rather than from the environment or human evaluators**. This can be **particularly useful in situations where it may be challenging to define clear reward functions or when it is more efficient to use another AI system to provide guidance**. The feedback from the AI system can take various forms, such as: - **Demonstrations** : The AI system provides demonstrations of desired behavior, and the learning agent tries to imitate these demonstrations. - **Comparison Data** : The AI system ranks or compares different actions taken by the learning agent, helping it to understand which actions are better or worse. - **Reward Shaping** : The AI system provides additional reward signals to guide the learning agent's behavior, supplementing the rewards from the environment. This approach is often used in scenarios where the RL agent needs to learn from **limited human or expert feedback or when the reward signal from the environment is sparse or unclear**. It can also be used to **accelerate the learning process and make RL more sample-efficient**. Reinforcement Learning from AI Feedback is an area of ongoing research and has applications in various domains, including robotics, autonomous vehicles, and game playing, among others.
ai-algorithms
This repository is a work in progress that contains first-principle implementations of groundbreaking AI algorithms using various deep learning frameworks. Each implementation is accompanied by supporting research papers, aiming to provide comprehensive educational resources for understanding and implementing foundational AI algorithms from scratch.

LLM-Viewer
LLM-Viewer is a tool for visualizing Language and Learning Models (LLMs) and analyzing performance on different hardware platforms. It enables network-wise analysis, considering factors such as peak memory consumption and total inference time cost. With LLM-Viewer, users can gain valuable insights into LLM inference and performance optimization. The tool can be used in a web browser or as a command line interface (CLI) for easy configuration and visualization. The ongoing project aims to enhance features like showing tensor shapes, expanding hardware platform compatibility, and supporting more LLMs with manual model graph configuration.


bocoel
BoCoEL is a tool that leverages Bayesian Optimization to efficiently evaluate large language models by selecting a subset of the corpus for evaluation. It encodes individual entries into embeddings, uses Bayesian optimization to select queries, retrieves from the corpus, and provides easily managed evaluations. The tool aims to reduce computation costs during evaluation with a dynamic budget, supporting models like GPT2, Pythia, and LLAMA through integration with Hugging Face transformers and datasets. BoCoEL offers a modular design and efficient representation of the corpus to enhance evaluation quality.
For similar tasks
LongRoPE
LongRoPE is a method to extend the context window of large language models (LLMs) beyond 2 million tokens. It identifies and exploits non-uniformities in positional embeddings to enable 8x context extension without fine-tuning. The method utilizes a progressive extension strategy with 256k fine-tuning to reach a 2048k context. It adjusts embeddings for shorter contexts to maintain performance within the original window size. LongRoPE has been shown to be effective in maintaining performance across various tasks from 4k to 2048k context lengths.
OpenAGI
OpenAGI is an AI agent creation package designed for researchers and developers to create intelligent agents using advanced machine learning techniques. The package provides tools and resources for building and training AI models, enabling users to develop sophisticated AI applications. With a focus on collaboration and community engagement, OpenAGI aims to facilitate the integration of AI technologies into various domains, fostering innovation and knowledge sharing among experts and enthusiasts.

GPTSwarm
GPTSwarm is a graph-based framework for LLM-based agents that enables the creation of LLM-based agents from graphs and facilitates the customized and automatic self-organization of agent swarms with self-improvement capabilities. The library includes components for domain-specific operations, graph-related functions, LLM backend selection, memory management, and optimization algorithms to enhance agent performance and swarm efficiency. Users can quickly run predefined swarms or utilize tools like the file analyzer. GPTSwarm supports local LM inference via LM Studio, allowing users to run with a local LLM model. The framework has been accepted by ICML2024 and offers advanced features for experimentation and customization.

AgentForge
AgentForge is a low-code framework tailored for the rapid development, testing, and iteration of AI-powered autonomous agents and Cognitive Architectures. It is compatible with a range of LLM models and offers flexibility to run different models for different agents based on specific needs. The framework is designed for seamless extensibility and database-flexibility, making it an ideal playground for various AI projects. AgentForge is a beta-testing ground and future-proof hub for crafting intelligent, model-agnostic autonomous agents.

atomic_agents
Atomic Agents is a modular and extensible framework designed for creating powerful applications. It follows the principles of Atomic Design, emphasizing small and single-purpose components. Leveraging Pydantic for data validation and serialization, the framework offers a set of tools and agents that can be combined to build AI applications. It depends on the Instructor package and supports various APIs like OpenAI, Cohere, Anthropic, and Gemini. Atomic Agents is suitable for developers looking to create AI agents with a focus on modularity and flexibility.
ax
Ax is a Typescript library that allows users to build intelligent agents inspired by agentic workflows and the Stanford DSP paper. It seamlessly integrates with multiple Large Language Models (LLMs) and VectorDBs to create RAG pipelines or collaborative agents capable of solving complex problems. The library offers advanced features such as streaming validation, multi-modal DSP, and automatic prompt tuning using optimizers. Users can easily convert documents of any format to text, perform smart chunking, embedding, and querying, and ensure output validation while streaming. Ax is production-ready, written in Typescript, and has zero dependencies.
Awesome-AI-Agents
Awesome-AI-Agents is a curated list of projects, frameworks, benchmarks, platforms, and related resources focused on autonomous AI agents powered by Large Language Models (LLMs). The repository showcases a wide range of applications, multi-agent task solver projects, agent society simulations, and advanced components for building and customizing AI agents. It also includes frameworks for orchestrating role-playing, evaluating LLM-as-Agent performance, and connecting LLMs with real-world applications through platforms and APIs. Additionally, the repository features surveys, paper lists, and blogs related to LLM-based autonomous agents, making it a valuable resource for researchers, developers, and enthusiasts in the field of AI.

CodeFuse-muAgent
CodeFuse-muAgent is a Multi-Agent framework designed to streamline Standard Operating Procedure (SOP) orchestration for agents. It integrates toolkits, code libraries, knowledge bases, and sandbox environments for rapid construction of complex Multi-Agent interactive applications. The framework enables efficient execution and handling of multi-layered and multi-dimensional tasks.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.