
Graph-CoT
Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs (ACL 2024)
Stars: 174
This repository contains the source code and datasets for Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs accepted to ACL 2024. It proposes a framework called Graph Chain-of-thought (Graph-CoT) to enable Language Models to traverse graphs step-by-step for reasoning, interaction, and execution. The motivation is to alleviate hallucination issues in Language Models by augmenting them with structured knowledge sources represented as graphs.
README:
This repository contains the source code and datasets for Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs accepted to ACL 2024.
The code is written in Python 3.8. Before running, you need to first install the required packages by typing following commands (Using a virtual environment is recommended):
conda create --name graphcot python==3.8
conda activate graphcot
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
conda install -c pytorch -c nvidia faiss-gpu=1.7.4
pip3 install -r requirements.txt
LLMs suffer from hallucination problems and sometimes tend to generate content that appears plausible but is ungrounded. To alleviate the hallucination issues, existing works propose to augment LLMs with external text corpora as knowledge sources and treat every single document as a knowledge unit.
However, in real-world scenarios, text units are generally interconnected, forming a (text-attributed) graph. The knowledge of such graphs is reflected not only in the form of texts but also in the structure of their connections.
This motivates the research on how to augment LLMs with such structured knowledge sources.

GRBench is a comprehensive benchmark dataset to support the development of methodology and facilitate the evaluation of the proposed models for Augmenting Large Language Models with External Textual Graphs.
GRBench includes 10 real-world graphs that can serve as external knowledge sources for LLMs from five domains including academic, e-commerce, literature, healthcare, and legal domains. Each sample in GRBench consists of a manually designed question and an answer, which can be directly answered by referring to the graphs or retrieving the information from the graphs as context. To make the dataset comprehensive, we include samples of different difficulty levels: easy questions (which can be answered with single-hop reasoning on graphs), medium questions (which necessitate multi-hop reasoning on graphs), and hard questions (which call for inductive reasoning with information on graphs as context).

You can directly download the graph environement files here and save them to data/processed_data/{data_name}.
You can access the question answering dataset for each domain here. They can also be found in data/processed_data/{data_name}/data.json.
Detailed information of the raw data and how this benchmark is constructed can be found in here.
Notes: GRBench is also a potential benchmark for researchers to study LLMs as agents with graphs as environments.
We propose a simple and effective framework called Graph Chain-of-thought (Graph-CoT). The main idea is to enable LLMs to traverse the graph step-by-step to figure out the key information needed, rather than directly feeding the whole subgraph as context into the LLMs.
Graph-CoT is an iterative framework, where one iteration corresponds to one step on the graph. Each iteration in Graph-CoT consists of three sub-steps:
- Reasoning: LLMs propose what conclusion we can make with the current information and what further information is needed from the graph;
- Interaction: LLMs generate the interactions needed to fetch information from the graph (e.g., finding the nodes, checking the neighbors, etc);
- Execution: The requests from the interaction step are executed on the graph and the corresponding information is returned.
In this way, LLMs can conduct chain-based reasoning on the graph and find the key information on the graph. This process will be iterated until LLMs conclude the final answer in the reasoning sub-step.

Graph CoT: Graph-CoT/.
You can refer to the README.md inside each folder to know how to run the models. Remember to change some of the bash variables first.
Opensource LLMs (with its RAG version): LLM/.
GPT models (with its RAG version): GPT/.
You can refer to the README.md inside each folder to know how to run the models. Remember to change some of the bash variables first.
Currently, we support both rule-based evaluation (e.g., EM, BLEU and ROUGE) and model-based evaluation (GPT4 as evaluator).
Remember to change all the DATASET to your dataset name and give your key to openai_key.
bash eval.sh
Please cite the following paper if you find the benchmark and code helpful for your research.
@article{jin2024graph,
title={Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs},
author={Jin, Bowen and Xie, Chulin and Zhang, Jiawei and Roy, Kashob Kumar and Zhang, Yu and Wang, Suhang and Meng, Yu and Han, Jiawei},
journal={arXiv preprint arXiv:2404.07103},
year={2024}
}
Some codes are adapted from ToolQA. Huge thanks to the contributors of the amazing repository!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Graph-CoT
Similar Open Source Tools
Graph-CoT
This repository contains the source code and datasets for Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs accepted to ACL 2024. It proposes a framework called Graph Chain-of-thought (Graph-CoT) to enable Language Models to traverse graphs step-by-step for reasoning, interaction, and execution. The motivation is to alleviate hallucination issues in Language Models by augmenting them with structured knowledge sources represented as graphs.

uncheatable_eval
Uncheatable Eval is a tool designed to assess the language modeling capabilities of LLMs on real-time, newly generated data from the internet. It aims to provide a reliable evaluation method that is immune to data leaks and cannot be gamed. The tool supports the evaluation of Hugging Face AutoModelForCausalLM models and RWKV models by calculating the sum of negative log probabilities on new texts from various sources such as recent papers on arXiv, new projects on GitHub, news articles, and more. Uncheatable Eval ensures that the evaluation data is not included in the training sets of publicly released models, thus offering a fair assessment of the models' performance.

bocoel
BoCoEL is a tool that leverages Bayesian Optimization to efficiently evaluate large language models by selecting a subset of the corpus for evaluation. It encodes individual entries into embeddings, uses Bayesian optimization to select queries, retrieves from the corpus, and provides easily managed evaluations. The tool aims to reduce computation costs during evaluation with a dynamic budget, supporting models like GPT2, Pythia, and LLAMA through integration with Hugging Face transformers and datasets. BoCoEL offers a modular design and efficient representation of the corpus to enhance evaluation quality.
LLMs-World-Models-for-Planning
This repository provides a Python implementation of a method that leverages pre-trained large language models to construct and utilize world models for model-based task planning. It includes scripts to generate domain models using natural language descriptions, correct domain models based on feedback, and support plan generation for tasks in different domains. The code has been refactored for better readability and includes tools for validating PDDL syntax and handling corrective feedback.

FigStep
FigStep is a black-box jailbreaking algorithm against large vision-language models (VLMs). It feeds harmful instructions through the image channel and uses benign text prompts to induce VLMs to output contents that violate common AI safety policies. The tool highlights the vulnerability of VLMs to jailbreaking attacks, emphasizing the need for safety alignments between visual and textual modalities.

ChainForge
ChainForge is a visual programming environment for battle-testing prompts to LLMs. It is geared towards early-stage, quick-and-dirty exploration of prompts, chat responses, and response quality that goes beyond ad-hoc chatting with individual LLMs. With ChainForge, you can: * Query multiple LLMs at once to test prompt ideas and variations quickly and effectively. * Compare response quality across prompt permutations, across models, and across model settings to choose the best prompt and model for your use case. * Setup evaluation metrics (scoring function) and immediately visualize results across prompts, prompt parameters, models, and model settings. * Hold multiple conversations at once across template parameters and chat models. Template not just prompts, but follow-up chat messages, and inspect and evaluate outputs at each turn of a chat conversation. ChainForge comes with a number of example evaluation flows to give you a sense of what's possible, including 188 example flows generated from benchmarks in OpenAI evals. This is an open beta of Chainforge. We support model providers OpenAI, HuggingFace, Anthropic, Google PaLM2, Azure OpenAI endpoints, and Dalai-hosted models Alpaca and Llama. You can change the exact model and individual model settings. Visualization nodes support numeric and boolean evaluation metrics. ChainForge is built on ReactFlow and Flask.

llms
The 'llms' repository is a comprehensive guide on Large Language Models (LLMs), covering topics such as language modeling, applications of LLMs, statistical language modeling, neural language models, conditional language models, evaluation methods, transformer-based language models, practical LLMs like GPT and BERT, prompt engineering, fine-tuning LLMs, retrieval augmented generation, AI agents, and LLMs for computer vision. The repository provides detailed explanations, examples, and tools for working with LLMs.
Nucleoid
Nucleoid is a declarative (logic) runtime environment that manages both data and logic under the same runtime. It uses a declarative programming paradigm, which allows developers to focus on the business logic of the application, while the runtime manages the technical details. This allows for faster development and reduces the amount of code that needs to be written. Additionally, the sharding feature can help to distribute the load across multiple instances, which can further improve the performance of the system.
SciMLBenchmarks.jl
SciMLBenchmarks.jl holds webpages, pdfs, and notebooks showing the benchmarks for the SciML Scientific Machine Learning Software ecosystem, including: * Benchmarks of equation solver implementations * Speed and robustness comparisons of methods for parameter estimation / inverse problems * Training universal differential equations (and subsets like neural ODEs) * Training of physics-informed neural networks (PINNs) * Surrogate comparisons, including radial basis functions, neural operators (DeepONets, Fourier Neural Operators), and more The SciML Bench suite is made to be a comprehensive open source benchmark from the ground up, covering the methods of computational science and scientific computing all the way to AI for science.
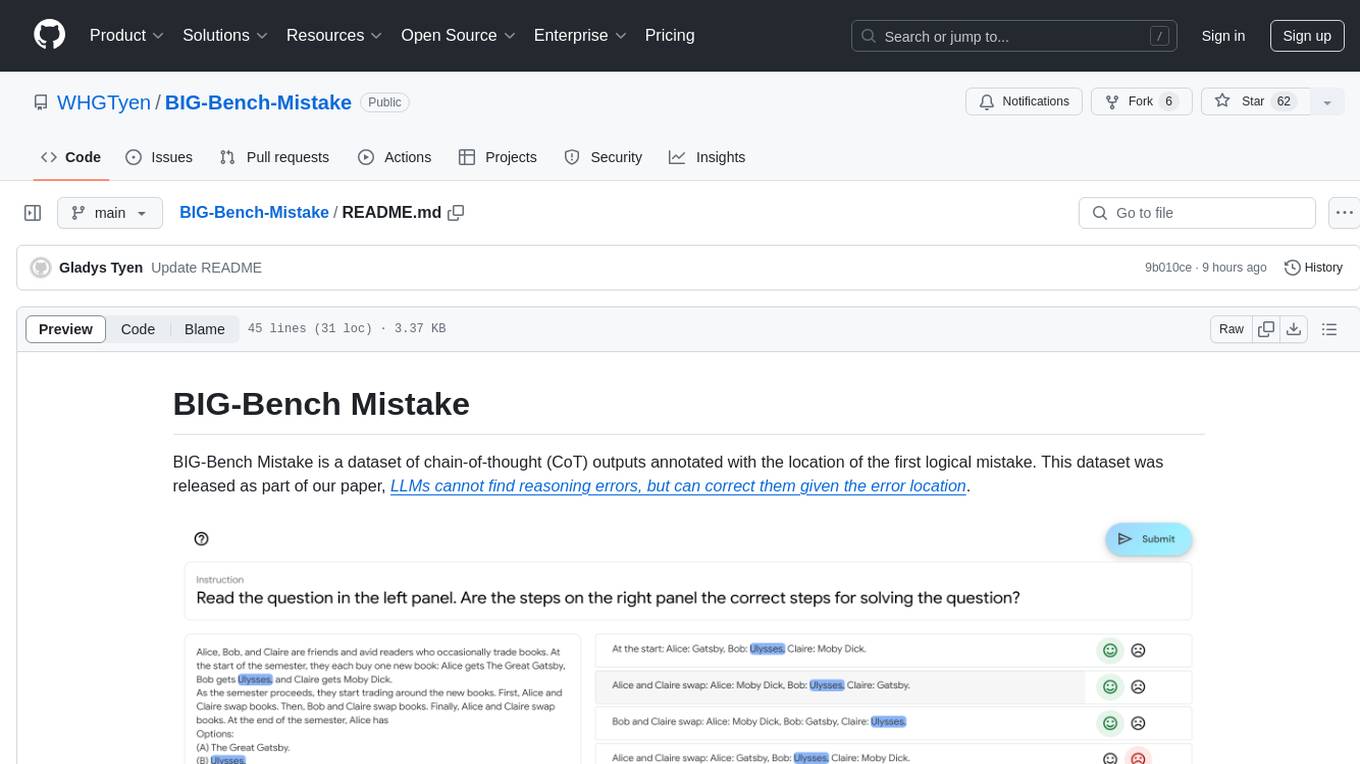
BIG-Bench-Mistake
BIG-Bench Mistake is a dataset of chain-of-thought (CoT) outputs annotated with the location of the first logical mistake. It was released as part of a research paper focusing on benchmarking LLMs in terms of their mistake-finding ability. The dataset includes CoT traces for tasks like Word Sorting, Tracking Shuffled Objects, Logical Deduction, Multistep Arithmetic, and Dyck Languages. Human annotators were recruited to identify mistake steps in these tasks, with automated annotation for Dyck Languages. Each JSONL file contains input questions, steps in the chain of thoughts, model's answer, correct answer, and the index of the first logical mistake.

intelligence-toolkit
The Intelligence Toolkit is a suite of interactive workflows designed to help domain experts make sense of real-world data by identifying patterns, themes, relationships, and risks within complex datasets. It utilizes generative AI (GPT models) to create reports on findings of interest. The toolkit supports analysis of case, entity, and text data, providing various interactive workflows for different intelligence tasks. Users are expected to evaluate the quality of data insights and AI interpretations before taking action. The system is designed for moderate-sized datasets and responsible use of personal case data. It uses the GPT-4 model from OpenAI or Azure OpenAI APIs for generating reports and insights.

aligner
Aligner is a model-agnostic alignment tool designed to efficiently correct responses from large language models. It redistributes initial answers to align with human intentions, improving performance across various LLMs. The tool can be applied with minimal training, enhancing upstream models and reducing hallucination. Aligner's 'copy and correct' method preserves the base structure while enhancing responses. It achieves significant performance improvements in helpfulness, harmlessness, and honesty dimensions, with notable success in boosting Win Rates on evaluation leaderboards.
context-cite
ContextCite is a tool for attributing statements generated by LLMs back to specific parts of the context. It allows users to analyze and understand the sources of information used by language models in generating responses. By providing attributions, users can gain insights into how the model makes decisions and where the information comes from.

PromptAgent
PromptAgent is a repository for a novel automatic prompt optimization method that crafts expert-level prompts using language models. It provides a principled framework for prompt optimization by unifying prompt sampling and rewarding using MCTS algorithm. The tool supports different models like openai, palm, and huggingface models. Users can run PromptAgent to optimize prompts for specific tasks by strategically sampling model errors, generating error feedbacks, simulating future rewards, and searching for high-reward paths leading to expert prompts.

CoLLM
CoLLM is a novel method that integrates collaborative information into Large Language Models (LLMs) for recommendation. It converts recommendation data into language prompts, encodes them with both textual and collaborative information, and uses a two-step tuning method to train the model. The method incorporates user/item ID fields in prompts and employs a conventional collaborative model to generate user/item representations. CoLLM is built upon MiniGPT-4 and utilizes pretrained Vicuna weights for training.
For similar tasks
Awesome-LLM4Graph-Papers
A collection of papers and resources about Large Language Models (LLM) for Graph Learning (Graph). Integrating LLMs with graph learning techniques to enhance performance in graph learning tasks. Categorizes approaches based on four primary paradigms and nine secondary-level categories. Valuable for research or practice in self-supervised learning for recommendation systems.
Graph-CoT
This repository contains the source code and datasets for Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs accepted to ACL 2024. It proposes a framework called Graph Chain-of-thought (Graph-CoT) to enable Language Models to traverse graphs step-by-step for reasoning, interaction, and execution. The motivation is to alleviate hallucination issues in Language Models by augmenting them with structured knowledge sources represented as graphs.
Awesome-Graph-LLM
Awesome-Graph-LLM is a curated collection of research papers exploring the intersection of graph-based techniques with Large Language Models (LLMs). The repository aims to bridge the gap between LLMs and graph structures prevalent in real-world applications by providing a comprehensive list of papers covering various aspects of graph reasoning, node classification, graph classification/regression, knowledge graphs, multimodal models, applications, and tools. It serves as a valuable resource for researchers and practitioners interested in leveraging LLMs for graph-related tasks.

all-in-rag
All-in-RAG is a comprehensive repository for all things related to Randomized Algorithms and Graphs. It provides a wide range of resources, including implementations of various randomized algorithms, graph data structures, and visualization tools. The repository aims to serve as a one-stop solution for researchers, students, and enthusiasts interested in exploring the intersection of randomized algorithms and graph theory. Whether you are looking to study theoretical concepts, implement algorithms in practice, or visualize graph structures, All-in-RAG has got you covered.
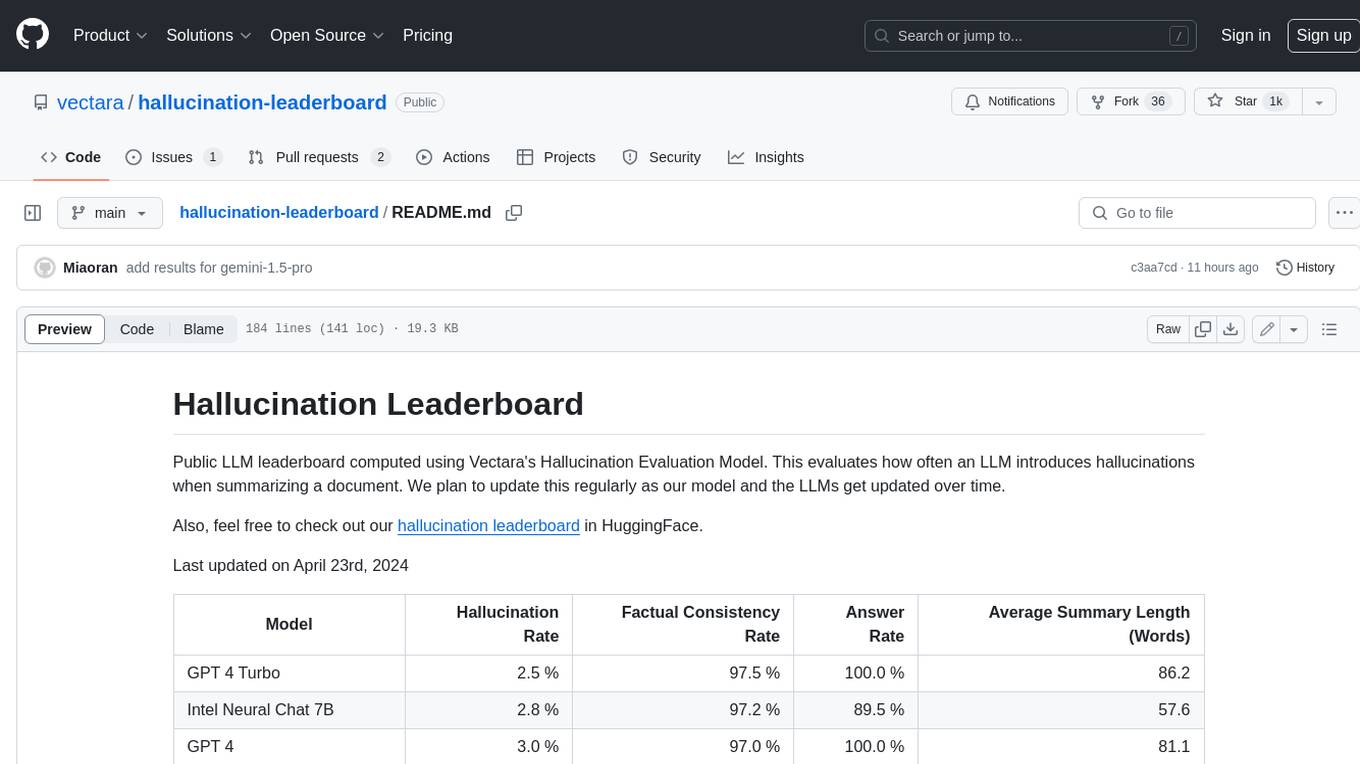
hallucination-leaderboard
This leaderboard evaluates the hallucination rate of various Large Language Models (LLMs) when summarizing documents. It uses a model trained by Vectara to detect hallucinations in LLM outputs. The leaderboard includes models from OpenAI, Anthropic, Google, Microsoft, Amazon, and others. The evaluation is based on 831 documents that were summarized by all the models. The leaderboard shows the hallucination rate, factual consistency rate, answer rate, and average summary length for each model.

h2o-llmstudio
H2O LLM Studio is a framework and no-code GUI designed for fine-tuning state-of-the-art large language models (LLMs). With H2O LLM Studio, you can easily and effectively fine-tune LLMs without the need for any coding experience. The GUI is specially designed for large language models, and you can finetune any LLM using a large variety of hyperparameters. You can also use recent finetuning techniques such as Low-Rank Adaptation (LoRA) and 8-bit model training with a low memory footprint. Additionally, you can use Reinforcement Learning (RL) to finetune your model (experimental), use advanced evaluation metrics to judge generated answers by the model, track and compare your model performance visually, and easily export your model to the Hugging Face Hub and share it with the community.

llm-jp-eval
LLM-jp-eval is a tool designed to automatically evaluate Japanese large language models across multiple datasets. It provides functionalities such as converting existing Japanese evaluation data to text generation task evaluation datasets, executing evaluations of large language models across multiple datasets, and generating instruction data (jaster) in the format of evaluation data prompts. Users can manage the evaluation settings through a config file and use Hydra to load them. The tool supports saving evaluation results and logs using wandb. Users can add new evaluation datasets by following specific steps and guidelines provided in the tool's documentation. It is important to note that using jaster for instruction tuning can lead to artificially high evaluation scores, so caution is advised when interpreting the results.

Awesome-LLM
Awesome-LLM is a curated list of resources related to large language models, focusing on papers, projects, frameworks, tools, tutorials, courses, opinions, and other useful resources in the field. It covers trending LLM projects, milestone papers, other papers, open LLM projects, LLM training frameworks, LLM evaluation frameworks, tools for deploying LLM, prompting libraries & tools, tutorials, courses, books, and opinions. The repository provides a comprehensive overview of the latest advancements and resources in the field of large language models.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.