
Awesome-LLM4Graph-Papers
[KDD'2024] "LLM4Graph: A Survey of Large Language Models for Graphs"
Stars: 290
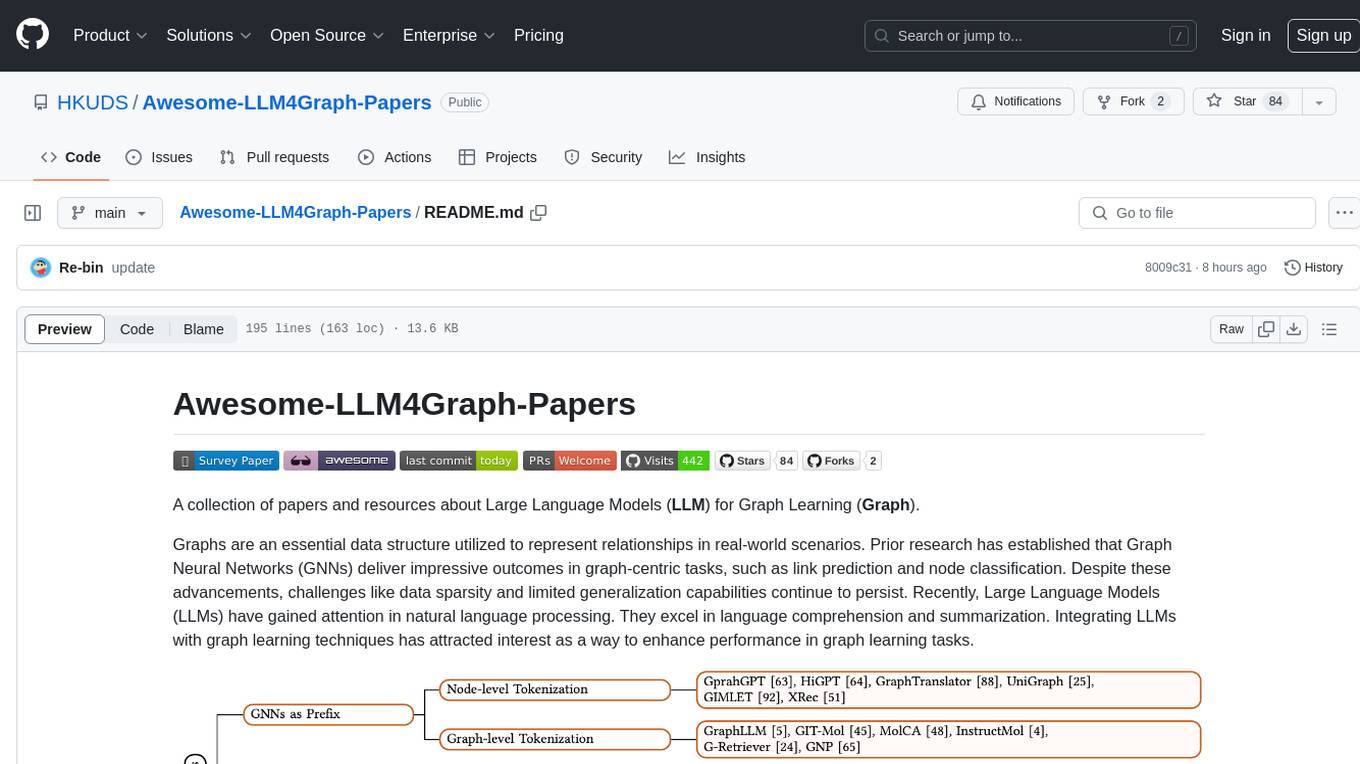
A collection of papers and resources about Large Language Models (LLM) for Graph Learning (Graph). Integrating LLMs with graph learning techniques to enhance performance in graph learning tasks. Categorizes approaches based on four primary paradigms and nine secondary-level categories. Valuable for research or practice in self-supervised learning for recommendation systems.
README:



A collection of papers and resources about Large Language Models (LLM) for Graph Learning (Graph).
Graphs are an essential data structure utilized to represent relationships in real-world scenarios. Prior research has established that Graph Neural Networks (GNNs) deliver impressive outcomes in graph-centric tasks, such as link prediction and node classification. Despite these advancements, challenges like data sparsity and limited generalization capabilities continue to persist. Recently, Large Language Models (LLMs) have gained attention in natural language processing. They excel in language comprehension and summarization. Integrating LLMs with graph learning techniques has attracted interest as a way to enhance performance in graph learning tasks.

🤗 We're actively working on this project, and your interest is greatly appreciated! To keep up with the latest developments, please consider hit the STAR and WATCH for updates.
-
🚀 Our LLM4Graph Survey is accepted by KDD 2024, and we will also give a lecture-style tutorial there!
-
🔥 We gave a tutorial on LLM4Graph at TheWebConf (WWW) 2024!
-
Our survey paper: A Survey of Large Language Models for Graphs is now ready.
This repository serves as a collection of recent advancements in employing large language models (LLMs) for modeling graph-structured data. We categorize and summarize the approaches based on four primary paradigms and nine secondary-level categories. The four primary categories include: 1) GNNs as Prefix, 2) LLMs as Prefix, 3) LLMs-Graphs Intergration, and 4) LLMs-Only
- GNNs as Prefix

- LLMs as Prefix

- LLMs-Graphs Intergration

- LLMs-Only

We hope this repository proves valuable to your research or practice in the field of self-supervised learning for recommendation systems. If you find it helpful, please consider citing our work:
@inproceedings{ren2024survey,
title={A survey of large language models for graphs},
author={Ren, Xubin and Tang, Jiabin and Yin, Dawei and Chawla, Nitesh and Huang, Chao},
booktitle={Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining},
pages={6616--6626},
year={2024}
}
@inproceedings{huang2024large,
title={Large Language Models for Graphs: Progresses and Directions},
author={Huang, Chao and Ren, Xubin and Tang, Jiabin and Yin, Dawei and Chawla, Nitesh},
booktitle={Companion Proceedings of the ACM on Web Conference 2024},
pages={1284--1287},
year={2024}
}- Awesome-LLM4Graph-Papers
- [TKDE'2024] Large language models on graphs: A comprehensive survey [paper]
- [IJCAI'2024] A Survey of Graph Meets Large Language Model: Progress and Future Directions [paper]
- [NeurIPS'2024] TEG-DB: A Comprehensive Dataset and Benchmark of Textual-Edge Graphs [paper]
- (SIGIR'2024) GraphGPT: Graph instruction tuning for large language models [paper]
- (arxiv'2024) HiGPT: Heterogeneous Graph Language Model [paper]
- (WWW'2024) GraphTranslator: Aligning Graph Model to Large Language Model for Open-ended Tasks [paper]
- (arxiv'2024) UniGraph: Learning a Cross-Domain Graph Foundation Model From Natural Language [paper]
- (NeurIPS'2024) GIMLET:Aunifiedgraph-textmodelforinstruction-based molecule zero-shot learning [paper]
- (arxiv'2024) XRec: Large Language Models for Explainable Recommendation [paper]
- (arxiv'2023) GraphLLM: Boosting graph reasoning ability of large language model [paper]
- (Computers in Biology and Medicine) GIT-Mol: A multi-modal large language model for molecular science with graph, image, and text [paper]
- (EMNLP'2023) MolCA: Molecular graph-language modeling with cross- modal projector and uni-modal adapter [paper]
- (arxiv'2023) InstructMol: Multi-modal integration for building a versatile and reliable molecular assistant in drug discovery [paper]
- (arxiv'2024) G-Retriever: Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering [paper]
- (AAAI'2024) Graph neural prompting with large language models [paper]
- (arxiv'2023) Prompt-based node feature extractor for few-shot learning on text-attributed graphs [paper]
- (arxiv'2023) SimTeG: A frustratingly simple approach improves textual graph learning [paper]
- (KDD'2023) Graph-aware language model pre-training on a large graph corpus can help multiple graph applications [paper]
- (ICLR'2024) One for all: Towards training one graph model for all classification tasks [paper]
- (ICLR'2024) Harnessing explanations: Llm-to-lm interpreter for enhanced text-attributed graph representation learning [paper]
- (WSDM'2024) LLMRec: Large language models with graph augmentation for recommendation [paper]
- (arxiv'2024) OpenGraph: Towards Open Graph Foundation Models [paper]
- (arxiv'2023) Label-free node classification on graphs with large language models (LLMs) [paper]
- (arxiv'2024) GraphEdit: Large Language Models for Graph Structure Learning [paper]
- (WWW'2024) Representation learning with large language models for recommendation [paper]
- (arxiv'2022) A molecular multimodal foundation model associating molecule graphs with natural language [paper]
- (arxiv'2023) ConGraT: Self-supervised contrastive pretraining for joint graph and text embeddings [paper]
- (arxiv'2023) Prompt tuning on graph-augmented low-resource text classification [paper]
- (arxiv'2023) GRENADE: Graph-Centric Language Model for Self-Supervised Representation Learning on Text-Attributed Graphs [paper]
- (Nature Machine Intelligence'2023) Multi-modal molecule structure–text model for text-based retrieval and editing [paper]
- (arxiv'2023) Pretraining language models with text-attributed heterogeneous graphs [paper]
- (arxiv'2022) Learning on large-scale text-attributed graphs via variational inference [paper]
- (ICLR'2022) GreaseLM: Graph reasoning enhanced language models for question answering [paper]
- (arxiv'2023) Disentangled representation learning with large language models for text-attributed graphs [paper]
- (arxiv'2024) Efficient Tuning and Inference for Large Language Models on Textual Graphs [paper]
- (WWW'2024) Can GNN be Good Adapter for LLMs? [paper]
- (ACL'2023) Don't Generate, Discriminate: A Proposal for Grounding Language Models to Real-World Environments[paper]
- (arxiv'2022) Graph Agent: Explicit Reasoning Agent for Graphs [paper]
- (arxiv'2024) Middleware for LLMs: Tools Are Instrumental for Language Agents in Complex Environments [paper]
- (arxiv'2023) Call Me When Necessary: LLMs can Efficiently and Faithfully Reason over Structured Environments [paper]
- (ICLR'2024) Reasoning on graphs: Faithful and interpretable large language model reasoning [paper]
- (NeurIPS'2024) Can language models solve graph problems in natural language? [paper]
- (arxiv'2023) GPT4Graph: Can large language models understand graph structured data? an empirical evaluation and benchmarking [paper]
- (arxiv'2023) BeyondText:ADeepDiveinto Large Language Models’ Ability on Understanding Graph Data [paper]
- (KDD'2024) Exploring the potential of large language models (llms) in learning on graphs [paper]
- (arxiv'2023) Graphtext: Graph reasoning in text space [paper]
- (arxiv'2023) Talk like a graph: Encoding graphs for large language models [paper]
- (arxiv'2023) LLM4DyG:Can Large Language Models Solve Problems on Dynamic Graphs? [paper]
- (arxiv'2023) Which Modality should I use–Text, Motif, or Image?: Understanding Graphs with Large Language Models [paper]
- (arxiv'2023) When Graph Data Meets Multimodal: A New Paradigm for Graph Understanding and Reasoning [paper]
- (arxiv'2023) Natural language is all a graph needs [paper]
- (NeurIPS'2024) Walklm:A uniform language model fine-tuning framework for attributed graph embedding [paper]
- (NeurIPS'2024) *GITA: Graph to Visual and Textual Integration for Vision-Language Graph Reasoning [paper]
- (arxiv'2024) LLaGA: Large Language and Graph Assistant [paper]
- (arxiv'2024) InstructGraph: Boosting Large Language Models via Graph-centric Instruction Tuning and Preference Alignment [paper]
- (arxiv'2024) ZeroG: Investigating Cross-dataset Zero-shot Transferability in Graphs [paper]
- (arxiv'2024) GraphWiz: An Instruction-Following Language Model for Graph Problems [paper]
- (arxiv'2024) GraphInstruct: Empowering Large Language Models with Graph Understanding and Reasoning Capability [paper]
- (arxiv'2024) MuseGraph: Graph-oriented Instruction Tuning of Large Language Models for Generic Graph Mining [paper]
If you have come across relevant resources, feel free to submit a pull request.
- (Journal/Confernce'20XX) **paper_name** [[paper](link)]
To add a paper to the survey, please consider providing more detailed information in the PR 😊
GNNs as Prefix
- (Node-level Tokenization / Graph-level Tokenization)
LLMs as Prefix
- (Embs. from LLMs for GNNs / Labels from LLMs for GNNs)
LLMs-Graphs Intergration
- (Alignment between GNNs and LLMs / Fusion Training of GNNs and LLMs / LLMs Agent for Graphs)
LLMs-Only
- (Tuning-free / Tuning-required)
Please also consider providing a brief introduction about the method to help us quickly add the paper to our survey :)
The design of our README.md is inspired by Awesome-LLM-KG and Awesome-LLMs-in-Graph-tasks, thanks to their works!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Awesome-LLM4Graph-Papers
Similar Open Source Tools
Awesome-LLM4Graph-Papers
A collection of papers and resources about Large Language Models (LLM) for Graph Learning (Graph). Integrating LLMs with graph learning techniques to enhance performance in graph learning tasks. Categorizes approaches based on four primary paradigms and nine secondary-level categories. Valuable for research or practice in self-supervised learning for recommendation systems.
Awesome-RL-based-LLM-Reasoning
This repository is dedicated to enhancing Language Model (LLM) reasoning with reinforcement learning (RL). It includes a collection of the latest papers, slides, and materials related to RL-based LLM reasoning, aiming to facilitate quick learning and understanding in this field. Starring this repository allows users to stay updated and engaged with the forefront of RL-based LLM reasoning.

Awesome-Text2SQL
Awesome Text2SQL is a curated repository containing tutorials and resources for Large Language Models, Text2SQL, Text2DSL, Text2API, Text2Vis, and more. It provides guidelines on converting natural language questions into structured SQL queries, with a focus on NL2SQL. The repository includes information on various models, datasets, evaluation metrics, fine-tuning methods, libraries, and practice projects related to Text2SQL. It serves as a comprehensive resource for individuals interested in working with Text2SQL and related technologies.
Awesome-explainable-AI
This repository contains frontier research on explainable AI (XAI), a hot topic in the field of artificial intelligence. It includes trends, use cases, survey papers, books, open courses, papers, and Python libraries related to XAI. The repository aims to organize and categorize publications on XAI, provide evaluation methods, and list various Python libraries for explainable AI.
innoshop
InnoShop is an innovative open-source e-commerce system based on Laravel 12. It supports multiple languages, multiple currencies, and is integrated with OpenAI. The system features plugin mechanisms and theme template development for enhanced user experience and system extensibility. It is globally oriented, user-friendly, and based on the latest technology with deep AI integration.
awesome-mcp-servers
A curated list of awesome Model Context Protocol (MCP) servers that enable AI models to securely interact with local and remote resources through standardized server implementations. The list focuses on production-ready and experimental servers extending AI capabilities through file access, database connections, API integrations, and other contextual services.
rllm
rLLM (relationLLM) is a Pytorch library for Relational Table Learning (RTL) with LLMs. It breaks down state-of-the-art GNNs, LLMs, and TNNs as standardized modules and facilitates novel model building in a 'combine, align, and co-train' way using these modules. The library is LLM-friendly, processes various graphs as multiple tables linked by foreign keys, introduces new relational table datasets, and is supported by students and teachers from Shanghai Jiao Tong University and Tsinghua University.
DeepMesh
DeepMesh is an auto-regressive artist-mesh creation tool that utilizes reinforcement learning to generate high-quality meshes conditioned on a given point cloud. It offers pretrained weights and allows users to generate obj/ply files based on specific input parameters. The tool has been tested on Ubuntu 22 with CUDA 11.8 and supports A100, A800, and A6000 GPUs. Users can clone the repository, create a conda environment, install pretrained model weights, and use command line inference to generate meshes.
NL2SQL_Handbook
NL2SQL Handbook provides a comprehensive overview of Natural Language to SQL (NL2SQL) advancements, including survey papers, tutorial slides, and a river diagram of NL2SQL methods. It covers the evolution of NL2SQL solutions, module-based methods, benchmark development, and future directions. The repository also offers practical guides for beginners, access to high-performance language models, and evaluation metrics for NL2SQL models.

kan-gpt
The KAN-GPT repository is a PyTorch implementation of Generative Pre-trained Transformers (GPTs) using Kolmogorov-Arnold Networks (KANs) for language modeling. It provides a model for generating text based on prompts, with a focus on improving performance compared to traditional MLP-GPT models. The repository includes scripts for training the model, downloading datasets, and evaluating model performance. Development tasks include integrating with other libraries, testing, and documentation.
llm-continual-learning-survey
This repository is an updating survey for Continual Learning of Large Language Models (CL-LLMs), providing a comprehensive overview of various aspects related to the continual learning of large language models. It covers topics such as continual pre-training, domain-adaptive pre-training, continual fine-tuning, model refinement, model alignment, multimodal LLMs, and miscellaneous aspects. The survey includes a collection of relevant papers, each focusing on different areas within the field of continual learning of large language models.
dom-to-semantic-markdown
DOM to Semantic Markdown is a tool that converts HTML DOM to Semantic Markdown for use in Large Language Models (LLMs). It maximizes semantic information, token efficiency, and preserves metadata to enhance LLMs' processing capabilities. The tool captures rich web content structure, including semantic tags, image metadata, table structures, and link destinations. It offers customizable conversion options and supports both browser and Node.js environments.
simulflow
Simulflow is a Clojure framework for building real-time voice-enabled AI applications using a data-driven, functional approach. It provides a composable pipeline architecture for processing audio, text, and AI interactions with built-in support for major AI providers. The framework uses processors that communicate through specialized frames to create voice-enabled AI agents, allowing for mental multitasking and rational thought. Simulflow offers a flow-based architecture, data-first design, streaming architecture, extensibility, flexible frame system, and built-in services for seamless integration with major AI providers. Users can easily swap components, add new functionality, or debug individual stages without affecting the entire system.
awesome-production-llm
This repository is a curated list of open-source libraries for production large language models. It includes tools for data preprocessing, training/finetuning, evaluation/benchmarking, serving/inference, application/RAG, testing/monitoring, and guardrails/security. The repository also provides a new category called LLM Cookbook/Examples for showcasing examples and guides on using various LLM APIs.
For similar tasks
Awesome-LLM4Graph-Papers
A collection of papers and resources about Large Language Models (LLM) for Graph Learning (Graph). Integrating LLMs with graph learning techniques to enhance performance in graph learning tasks. Categorizes approaches based on four primary paradigms and nine secondary-level categories. Valuable for research or practice in self-supervised learning for recommendation systems.
Graph-CoT
This repository contains the source code and datasets for Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs accepted to ACL 2024. It proposes a framework called Graph Chain-of-thought (Graph-CoT) to enable Language Models to traverse graphs step-by-step for reasoning, interaction, and execution. The motivation is to alleviate hallucination issues in Language Models by augmenting them with structured knowledge sources represented as graphs.
Awesome-Graph-LLM
Awesome-Graph-LLM is a curated collection of research papers exploring the intersection of graph-based techniques with Large Language Models (LLMs). The repository aims to bridge the gap between LLMs and graph structures prevalent in real-world applications by providing a comprehensive list of papers covering various aspects of graph reasoning, node classification, graph classification/regression, knowledge graphs, multimodal models, applications, and tools. It serves as a valuable resource for researchers and practitioners interested in leveraging LLMs for graph-related tasks.

all-in-rag
All-in-RAG is a comprehensive repository for all things related to Randomized Algorithms and Graphs. It provides a wide range of resources, including implementations of various randomized algorithms, graph data structures, and visualization tools. The repository aims to serve as a one-stop solution for researchers, students, and enthusiasts interested in exploring the intersection of randomized algorithms and graph theory. Whether you are looking to study theoretical concepts, implement algorithms in practice, or visualize graph structures, All-in-RAG has got you covered.
Awesome-LLM4RS-Papers
This paper list is about Large Language Model-enhanced Recommender System. It also contains some related works. Keywords: recommendation system, large language models

ai_projects
This repository contains a collection of AI projects covering various areas of machine learning. Each project is accompanied by detailed articles on the associated blog sciblog. Projects range from introductory topics like Convolutional Neural Networks and Transfer Learning to advanced topics like Fraud Detection and Recommendation Systems. The repository also includes tutorials on data generation, distributed training, natural language processing, and time series forecasting. Additionally, it features visualization projects such as football match visualization using Datashader.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.