
ai_projects
AI projects
Stars: 790

This repository contains a collection of AI projects covering various areas of machine learning. Each project is accompanied by detailed articles on the associated blog sciblog. Projects range from introductory topics like Convolutional Neural Networks and Transfer Learning to advanced topics like Fraud Detection and Recommendation Systems. The repository also includes tutorials on data generation, distributed training, natural language processing, and time series forecasting. Additionally, it features visualization projects such as football match visualization using Datashader.
README:




This repo contains AI projects in multiple areas of machine learning. Many of these projects have associated articles on the blog sciblog.
You can find a list of most the post I made in this file.
-
Introduction to Convolutional Neural Networks: In this project we explain what is a convolution and how to compute a CNN using MXNet deep learning library with the MNIST character recognition dataset. Here the blog entry.
-
Introduction to Transfer Learning: In this project we use PyTorch to explain the basic methodologies of transfer learning (finetuning and freezing) and analyze in which case is better to use each of them. Here the blog entry.
-
Cloud-Scale Text Classification With Convolutional Neural Networks: In these notebooks we show how to perform character level convolutions for sentiment analysis using Char-CNN and VDCNN models. Here the blog entry.
-
Introduction to Data Generation: In this notebook we show a number of simple techniques to generate new data in images, text and time series. Here the blog entry.
-
Introduction to Dimensionality Reduction with t-SNE: In this project we use sklearn and CUDA to show an example of t-SNE algorithm. We use a CNN to generate high-dimensional features from images and then show how they can be projected and visualized into a 2-dimensional space. Here the blog entry.
-
Introduction to Distributed Training with DeepSpeed: In this project we show how to use DeepSpeed to perform distributed training with PyTorch. Here the blog entry.
-
Introduction to Fraud Detection: In this notebook we design a real-time fraud detection model using LightGBM on GPU (also available on CPU). The model is then operationalized through an API using Flask and websockets. Here the blog entry.
-
Introduction to Machine Learning API: In this notebook we show how to create an image classification API. The system works with a pretrained CNN using CNTK deep learning library. The API is setup with Flask for managing the end point services and CherryPy as the backend server. Here the blog entry.
-
Introduction to Recommendation Systems with Deep Autoencoders: In this notebook we make an overview to recommendation systems and implement a recommendation API using a deep autoencoder with PyTorch and the Netflix dataset. Here the blog entry.
-
Introduction to Natural Language Processing with fastText: In this project we show how to implement text classification, sentiment analysis and word embedding using the library fastText. We also show a way to represent the word embeddings in a reduced space using t-SNE algorithm. Here the blog entry.
-
Time Series Forecasting of Stock Price: In this tutorial we show how to implement a simple stock forecasting model using different variants of LSTMs and Keras. Here the blog entry.
-
Visualization of Football Matches with Datashader: In this notebook we explain how to visualize all matches in the UEFA Champions League since its beginning using the python library datashader. To create the project we use the Lean Startup method. Here the blog entry.

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ai_projects
Similar Open Source Tools
ai_projects
This repository contains a collection of AI projects covering various areas of machine learning. Each project is accompanied by detailed articles on the associated blog sciblog. Projects range from introductory topics like Convolutional Neural Networks and Transfer Learning to advanced topics like Fraud Detection and Recommendation Systems. The repository also includes tutorials on data generation, distributed training, natural language processing, and time series forecasting. Additionally, it features visualization projects such as football match visualization using Datashader.
AliceVision
AliceVision is a photogrammetric computer vision framework which provides a 3D reconstruction pipeline. It is designed to process images from different viewpoints and create detailed 3D models of objects or scenes. The framework includes various algorithms for feature detection, matching, and structure from motion. AliceVision is suitable for researchers, developers, and enthusiasts interested in computer vision, photogrammetry, and 3D modeling. It can be used for applications such as creating 3D models of buildings, archaeological sites, or objects for virtual reality and augmented reality experiences.

NaLLM
The NaLLM project repository explores the synergies between Neo4j and Large Language Models (LLMs) through three primary use cases: Natural Language Interface to a Knowledge Graph, Creating a Knowledge Graph from Unstructured Data, and Generating a Report using static and LLM data. The repository contains backend and frontend code organized for easy navigation. It includes blog posts, a demo database, instructions for running demos, and guidelines for contributing. The project aims to showcase the potential of Neo4j and LLMs in various applications.
PythonDataScienceFullThrottle
PythonDataScienceFullThrottle is a comprehensive repository containing various Python scripts, libraries, and tools for data science enthusiasts. It includes a wide range of functionalities such as data preprocessing, visualization, machine learning algorithms, and statistical analysis. The repository aims to provide a one-stop solution for individuals looking to dive deep into the world of data science using Python.

SuperKnowa
SuperKnowa is a fast framework to build Enterprise RAG (Retriever Augmented Generation) Pipelines at Scale, powered by watsonx. It accelerates Enterprise Generative AI applications to get prod-ready solutions quickly on private data. The framework provides pluggable components for tackling various Generative AI use cases using Large Language Models (LLMs), allowing users to assemble building blocks to address challenges in AI-driven text generation. SuperKnowa is battle-tested from 1M to 200M private knowledge base & scaled to billions of retriever tokens.
Large-Language-Models
Large Language Models (LLM) are used to browse the Wolfram directory and associated URLs to create the category structure and good word embeddings. The goal is to generate enriched prompts for GPT, Wikipedia, Arxiv, Google Scholar, Stack Exchange, or Google search. The focus is on one subdirectory: Probability & Statistics. Documentation is in the project textbook `Projects4.pdf`, which is available in the folder. It is recommended to download the document and browse your local copy with Chrome, Edge, or other viewers. Unlike on GitHub, you will be able to click on all the links and follow the internal navigation features. Look for projects related to NLP and LLM / xLLM. The best starting point is project 7.2.2, which is the core project on this topic, with references to all satellite projects. The project textbook (with solutions to all projects) is the core document needed to participate in the free course (deep tech dive) called **GenAI Fellowship**. For details about the fellowship, follow the link provided. An uncompressed version of `crawl_final_stats.txt.gz` is available on Google drive, which contains all the crawled data needed as input to the Python scripts in the XLLM5 and XLLM6 folders.

wandb
Weights & Biases (W&B) is a platform that helps users build better machine learning models faster by tracking and visualizing all components of the machine learning pipeline, from datasets to production models. It offers tools for tracking, debugging, evaluating, and monitoring machine learning applications. W&B provides integrations with popular frameworks like PyTorch, TensorFlow/Keras, Hugging Face Transformers, PyTorch Lightning, XGBoost, and Sci-Kit Learn. Users can easily log metrics, visualize performance, and compare experiments using W&B. The platform also supports hosting options in the cloud or on private infrastructure, making it versatile for various deployment needs.

graphrag
The GraphRAG project is a data pipeline and transformation suite designed to extract meaningful, structured data from unstructured text using LLMs. It enhances LLMs' ability to reason about private data. The repository provides guidance on using knowledge graph memory structures to enhance LLM outputs, with a warning about the potential costs of GraphRAG indexing. It offers contribution guidelines, development resources, and encourages prompt tuning for optimal results. The Responsible AI FAQ addresses GraphRAG's capabilities, intended uses, evaluation metrics, limitations, and operational factors for effective and responsible use.

caikit
Caikit is an AI toolkit that enables users to manage models through a set of developer friendly APIs. It provides a consistent format for creating and using AI models against a wide variety of data domains and tasks.

asreview
The ASReview project implements active learning for systematic reviews, utilizing AI-aided pipelines to assist in finding relevant texts for search tasks. It accelerates the screening of textual data with minimal human input, saving time and increasing output quality. The software offers three modes: Oracle for interactive screening, Exploration for teaching purposes, and Simulation for evaluating active learning models. ASReview LAB is designed to support decision-making in any discipline or industry by improving efficiency and transparency in screening large amounts of textual data.

kai
Kai is an AI-enabled tool that simplifies the process of modernizing application source code to a new platform. It uses Large Language Models (LLMs) guided by static code analysis, along with data from Konveyor. This data provides insights into how the organization solved similar problems in the past, helping streamline and automate the code modernization process. Kai assists developers by providing suggestions and solutions to common problems through Retrieval Augmented Generation (RAG), working with LLMs using Konveyor analysis reports about the codebase and generating solutions based on previously solved examples.
motleycrew
Motleycrew is an ultimate framework for building multi-agent AI systems, allowing users to mix and match AI agents and tools from popular frameworks, design advanced workflows, and leverage dynamic knowledge graphs with simplicity and elegance. It acts as a conductor orchestrating a symphony of AI agents and tools, providing building blocks for creating AI systems and enabling users to focus on high-level design while taking care of the rest. The framework offers integration with various tools, flexibility in providing agents with tools or other agents, advanced flow design capabilities, and built-in observability and caching features.

GrAIdient
GrAIdient is a framework designed to enable the development of deep learning models using the internal GPU of a Mac. It provides access to the graph of layers, allowing for unique model design with greater understanding, control, and reproducibility. The goal is to challenge the understanding of deep learning models, transitioning from black box to white box models. Key features include direct access to layers, native Mac GPU support, Swift language implementation, gradient checking, PyTorch interoperability, and more. The documentation covers main concepts, architecture, and examples. GrAIdient is MIT licensed.
ai_gallery
AI Gallery is a showcase site built using React and Nextjs for static site generation, featuring interactive visualizations of classic algorithms, classic games implementation, and various interesting widgets. The project utilizes AI assistance from Claude 3.5 and GPT-4 to create components and enhance the development process. It aims to continually add more components with AI assistance, providing a platform for contributors to leverage AI in frontend development.

xef
xef.ai is a one-stop library designed to bring the power of modern AI to applications and services. It offers integration with Large Language Models (LLM), image generation, and other AI services. The library is packaged in two layers: core libraries for basic AI services integration and integrations with other libraries. xef.ai aims to simplify the transition to modern AI for developers by providing an idiomatic interface, currently supporting Kotlin. Inspired by LangChain and Hugging Face, xef.ai may transmit source code and user input data to third-party services, so users should review privacy policies and take precautions. Libraries are available in Maven Central under the `com.xebia` group, with `xef-core` as the core library. Developers can add these libraries to their projects and explore examples to understand usage.
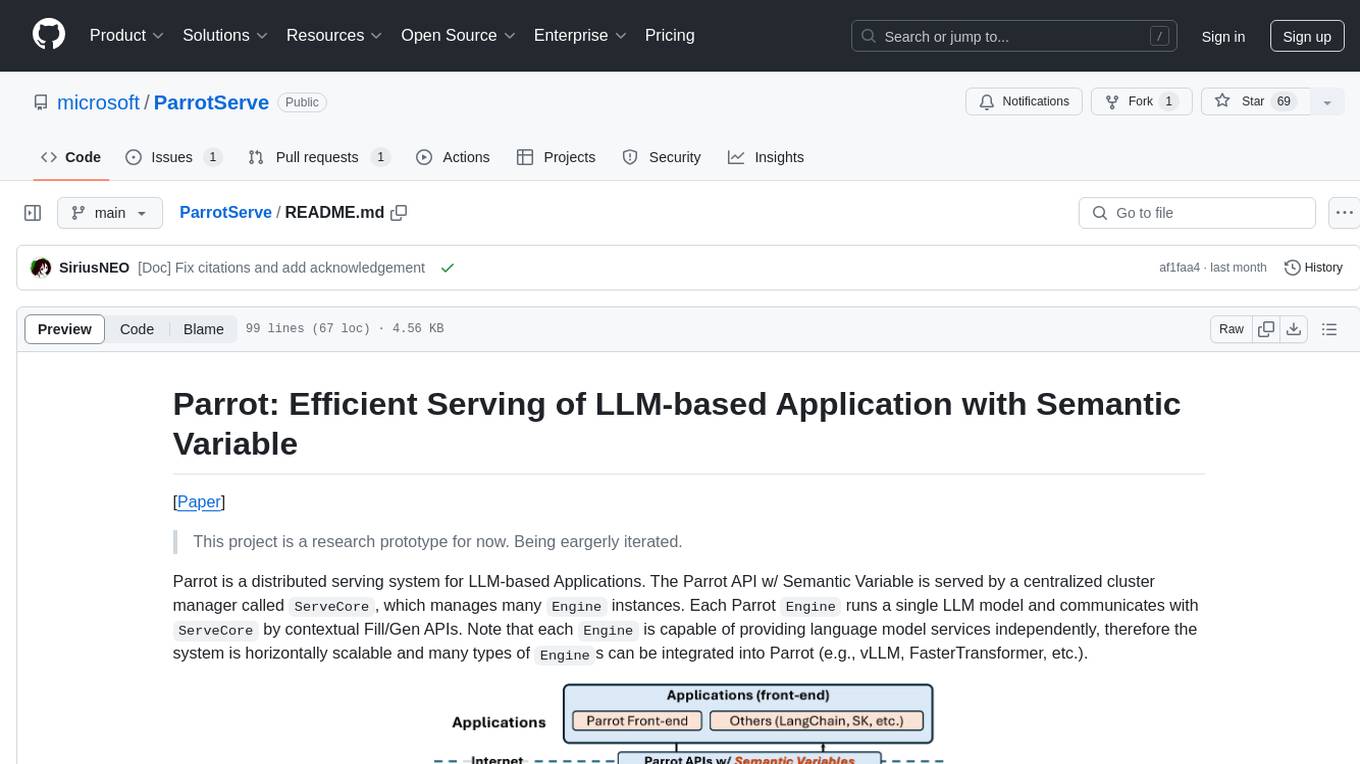
ParrotServe
Parrot is a distributed serving system for LLM-based Applications, designed to efficiently serve LLM-based applications by adding Semantic Variable in the OpenAI-style API. It allows for horizontal scalability with multiple Engine instances running LLM models communicating with ServeCore. The system enables AI agents to interact with LLMs via natural language prompts for collaborative tasks.
For similar tasks

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.