
Awesome-RL-based-LLM-Reasoning
Awesome RL-based LLM Reasoning
Stars: 380
This repository is dedicated to enhancing Language Model (LLM) reasoning with reinforcement learning (RL). It includes a collection of the latest papers, slides, and materials related to RL-based LLM reasoning, aiming to facilitate quick learning and understanding in this field. Starring this repository allows users to stay updated and engaged with the forefront of RL-based LLM reasoning.
README:
We have witnessed the powerful capabilities of pure RL-based LLM Reasoning. In this repository, we will add newest papers, slides, and other interesting materials that enhance LLM reasoning with reinforcement learning, helping everyone learn quickly!
Starring this repository is like being at the forefront of RL-based LLM reasoning.
在风口浪尖 (In the teeth of the storm)
- Why do we need reasoning?
- Why do we use reinforcement learning to get reasoning ability? (What are the advantages compared to reasoning methods that do not use reinforcement learning?)
- [2502] Exploring the Limit of Outcome Reward for Learning Mathematical Reasoning (Shanghai AI Lab)
- [2502] Demystifying Long Chain-of-Thought Reasoning in LLMs (Introduced cosine length-scaling reward with repetition penalty for stable CoT length growth) (IN.AI)
- [2501] SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training (HKU, Berkeley)
- [2501] Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning (Deepseek)
- [2501] Kimi k1.5: Scaling Reinforcement Learning with LLMs (Kimi)
- [2502] S2 R: Teaching LLMs to Self-verify and Self-correct via Reinforcement Learning (Tencent)
- [2502] Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling (THU)
- [2502] QLASS: Boosting Language Agent Inference via Q-Guided Stepwise Search (UCLA-Yizhou Sun)
- [2312] Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations (PKU & Deepseek)
- [2305] Let's verify step by step (OpenAI)
- [2211] Solving math word problems with process-and outcome-based feedback (DeepMind)
- [2504] GPG: A Simple and Strong Reinforcement Learning Baseline for Model Reasoning
- [2504] When To Solve, When To Verify: Compute-Optimal Problem Solving and Generative Verification for LLM Reasoning | Explain
- [2503] SWEET-RL: Training Multi-Turn LLM Agents on Collaborative Reasoning Tasks (agent & reasoning)
- [2503] DAST: Difficulty-Adaptive Slow-Thinking for Large Reasoning Models (short length of thinking by RL)
- [2503] L1: Controlling How Long A Reasoning Model Thinks With Reinforcement Learning (CMU)
- [2502] Scaling Test-Time Compute Without Verification or RL is Suboptimal (CMU, UC Berkeley) (verifier-based (VB) is better than verifier-free (VF))
- [2502] Reasoning with Reinforced Functional Token Tuning
- [2502] Provably Optimal Distributional RL for LLM Post-Training (Cornell, Harvard)
- [2502] On the Emergence of Thinking in LLMs I: Searching for the Right Intuition (Reinforcement Learning via Self-Play) (MIT)
- [2502] STP: Self-play LLM Theorem Provers with Iterative Conjecturing and Proving (the scarcity of correct proofs sparse rewards will make performance quickly plateaus. To overcome this, we draw inspiration from mathematicians, who continuously develop new results, partly by proposing novel conjectures or exercises (which are often variants of known results) and attempting to solve them.) (Stanford-Tengyu Ma)
- [2409] Training Language Models to Self-Correct via Reinforcement Learning (DeepMind)
- [2502] Don’t Get Lost in the Trees: Streamlining LLM Reasoning by Overcoming Tree Search Exploration Pitfalls (Tencent)
- [2408] Deepseek-prover-v1. 5: Harnessing proof assistant feedback for reinforcement learning and monte-carlo tree search (DeepSeek)
- [2310] Solving olympiad geometry without human demonstrations (DeepMind)
- [2504] Recitation over Reasoning: How Cutting-Edge Language Models Can Fail on Elementary School-Level Reasoning Problems? (ByteDance Seed) (by changing one phrase in the condition, top models such as OpenAI-o1 and DeepSeek-R1 can suffer 60% performance loss on elementary school-level arithmetic and reasoning problems)
- [2503] Proof or Bluff? Evaluating LLMs on 2025 USA Math Olympiad (the outcome of the 2025 USA Math Olympiad was worse. Most of the results were 0)
- [2503] Landscape of Thoughts: Visualizing the Reasoning Process of Large Language Models (visulize reasoning process)
- [2503] Efficient Test-Time Scaling via Self-Calibration (WUSTL) (LLMs are known to be overconfident and provide unreliable confidence estimation)
- [2503] Interpreting the Repeated Token Phenomenon in Large Language Models (DeepMind)
- [2503] Attentive Reasoning Queries: A Systematic Method for Optimizing Instruction-Following in Large Language Models (Emcie Co Ltd)
- [2501] Reasoning Language Models: A Blueprint
- [2502] When More is Less: Understanding Chain-of-Thought Length in LLMs (I think is also about overthinking) (PKU, MIT)
- [2502] Token Assorted: Mixing Latent and Text Tokens for Improved Language Model Reasoning (Meta-Yuandong Tian)
- [2502] CoT-Valve: Length-Compressible Chain-of-Thought Tuning (overthinking) (NUS)
- [2502] The Danger of Overthinking: Examining the Reasoning-Action Dilemma in Agentic Tasks (I think overthinking is a practical problem, interesting!) (Berkeley)
- [2502] ReasonFlux: Hierarchical LLM Reasoning via Scaling Thought Templates (Princeton)
- [2502] Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach (Current approaches to improving LM capabilities rely heavily on increasing model size or specialized prompting) (Max-Plank)
- [2502] LIMO: Less is More for Reasoning (LIMO offers a more principled and direct path through explicit trajectory design obtaining complex reasoning ability) (SJTU)
- [2502] Confidence Improves Self-Consistency in LLMs (the quality of LLM outputs) (Google Reasearch)
- [2502] LLMs Can Easily Learn to Reason from Demonstrations Structure, not content, is what matters! (UC Berkeley)
- [2502] BOLT: Bootstrap Long Chain-of-Thought in Language Models without Distillation (Salesforce AI Research)
- [2502] LLMs Can Teach Themselves to Better Predict the Future (self-play generate data) (LSE)
- [2501] s1: Simple test-time scaling (Stanford) (distillation and using 'wait' append response)
- [2412] Formal Mathematical Reasoning: A New Frontier in AI
- [2412] Efficiently Serving LLM Reasoning Programs with Certaindex (UCSD) (overthinking, probe in the middle)
- [2412] Training Large Language Model to Reason in a Continuous Latent Space (Meta-Yuandong Tian)
- [2412] Scaling of search and learning: A roadmap to reproduce o1 from reinforcement learning perspective
- [2408] Visual Agents as Fast and Slow Thinkers
- [2503] Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
- [2502] From System 1 to System 2: A Survey of Reasoning Large Language Models
- [2407] A comprehensive survey of LLM alignment techniques: RLHF, RLAIF, PPO, DPO and more
- Self-improvement of LLM agents through Reinforcement Learning at Scale
- A Visual Guide to Reasoning LLMs
- Understanding Reasoning LLMs Methods and Strategies for Building and Refining Reasoning Models
- What is the difference between large reasoning model and LLM? (Zhihu)
- LLM Reasoning: Key Ideas and Limitations Denny Zhou-DeepMind (Video)
- Towards Reasoning in Large Language Models Jie Huang-UIUC
- Can LLMs Reason & Plan? Subbarao Kambhampati-ASU
- Inference-Time Techniques for LLM Reasoning Xinyun Chen-DeepMind
- Chain-of-Thought Reasoning In Language Models Zhuosheng Zhang-SJTU
- Learning to Self-Improve & Reason with LLMs Jason Weston-Meta & NYU
- 为什么在Deepseek-R1-ZERO出现前,无人尝试放弃微调对齐,通过强化学习生成思考链推理模型? Zhihu
- Kimi Flood Sung Zhihu
- Deepseek系列文章梳理 Zhihu
- ChatGPT and The Art of Post-Training Stanford-25/02/18
- [LLM+RL] R1 论文导读,SFT vs. RL,RL 基础以及 GRPO 细节,以及一系列复现工作讨论
- [LLM+RL] 理解 GRPO 公式原理及 TRL GrpoTrainer 代码实现(advantage 与 loss 计算)
- LLM-Based Reasoning: Opportunities and Pitfalls (LAVA Workshop in ACCV 2024)
- Reinforcement Learning in DeepSeek r1 Visualized (Chinese)
- EZ撸paper: DeepSeek-R1 论文详解 part 3:GPT发展史 | scaling law | 训练范式 | emergent ability
- EZ撸paper: DeepSeek-R1 论文详解 part 2:AGI是什么? | Reinforcement Learning快速入门 | AlphaGo介绍
- EZ撸paper: DeepSeek-R1 论文详解 part 1:比肩 OpenAI-o1,如何做到的?
- [GRPO Explained] DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
- DeepSeek R1 Explained to your grandma
-
TinyZero (4*4090 is enough for 0.5B LLM, but can't observe aha moment)
-
Open-r1
-
Logic-RL
-
Unsloth-GRPO (simplest r1 implementation)
-
OpenR (An Open Source Framework for Advanced Reasoning)
- DeepSeek-RL-Qwen-0.5B-GRPO-gsm8k
- deepseek_r1_train





The core essence of reinforcement learning is how an agent determines the next action within an environment to maximize the return; the environment’s role is to provide the state and reward.
- Q-learning (Value-based method): A threshold is set, and if the current value is greater than the threshold (epsilon-greddy), a random action is selected; if it is smaller, an action is chosen from the Q-table. Regardless of which method is chosen, the Q-table needs to be updated. After every action, we update the Q-table of the previous state to maximize the return.
- REINFORCE (Policy-based method): It’s like playing Mario where every action in a given playthrough is determined by a policy network. After the game ends, we have the reward for each state and can compute the cumulative return (G) for each state. Then, using this computed G, we calculate the loss and update the parameters of the policy network.
- [2501] (REINFORCE++) A Simple and Efficient Approach for Aligning Large Language Models 6 (REINFORCE++ is more stable in training compared to GRPO and faster than PPO in OpenRLHF report)
- [2405] (SimPO) Simple Preference Optimization with a Reference-Free Reward 227
- [2402] (KTO) Model Alignment as Prospect Theoretic Optimization 326
- [2402] (GRPO) DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models 250
- [2305] (DPO) Direct Preference Optimization: Your Language Model is Secretly a Reward Model 2580
- [2203] (InstructGPT/PPO+LLM) Training language models to follow instructions with human feedback 12443
- [1707] (PPO) Proximal Policy Optimization Algorithms 23934
- [1706] (RLHF) Deep Reinforcement Learning from Human Preferences 3571
- Compshare (After registration, there is a quota of 50 yuan, enough to run R1 on unsloth)
- awesome-llm-reasoning-long2short-papers
- Awesome-Long2short-on-LRMs
- Awesome-Efficient-CoT-Reasoning-Summary
- Awesome RL-based Reasoning MLLMs
- DecryptPrompt (very comprehensive)
- Feel free to contribute more papers or other any resources!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Awesome-RL-based-LLM-Reasoning
Similar Open Source Tools
Awesome-RL-based-LLM-Reasoning
This repository is dedicated to enhancing Language Model (LLM) reasoning with reinforcement learning (RL). It includes a collection of the latest papers, slides, and materials related to RL-based LLM reasoning, aiming to facilitate quick learning and understanding in this field. Starring this repository allows users to stay updated and engaged with the forefront of RL-based LLM reasoning.
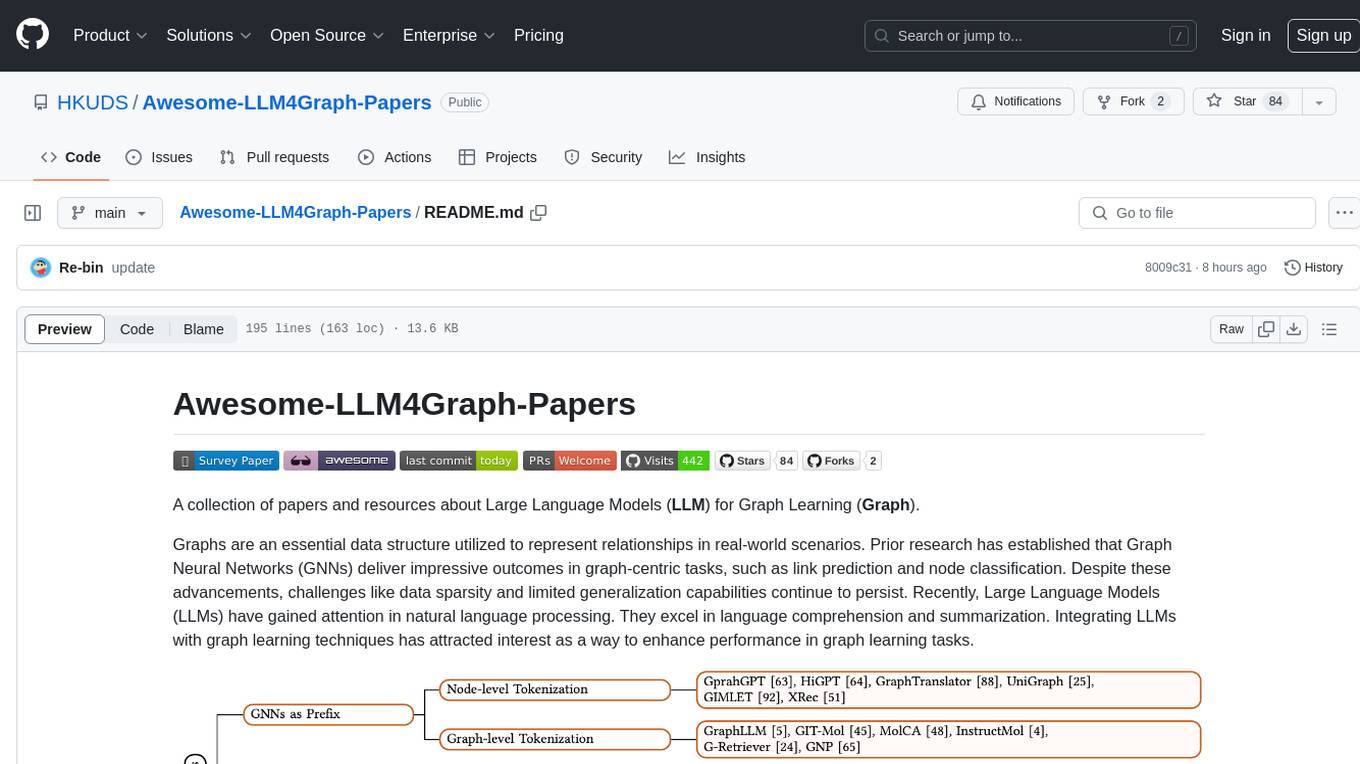
Awesome-LLM4Graph-Papers
A collection of papers and resources about Large Language Models (LLM) for Graph Learning (Graph). Integrating LLMs with graph learning techniques to enhance performance in graph learning tasks. Categorizes approaches based on four primary paradigms and nine secondary-level categories. Valuable for research or practice in self-supervised learning for recommendation systems.

Awesome-Text2SQL
Awesome Text2SQL is a curated repository containing tutorials and resources for Large Language Models, Text2SQL, Text2DSL, Text2API, Text2Vis, and more. It provides guidelines on converting natural language questions into structured SQL queries, with a focus on NL2SQL. The repository includes information on various models, datasets, evaluation metrics, fine-tuning methods, libraries, and practice projects related to Text2SQL. It serves as a comprehensive resource for individuals interested in working with Text2SQL and related technologies.
awesome-deliberative-prompting
The 'awesome-deliberative-prompting' repository focuses on how to ask Large Language Models (LLMs) to produce reliable reasoning and make reason-responsive decisions through deliberative prompting. It includes success stories, prompting patterns and strategies, multi-agent deliberation, reflection and meta-cognition, text generation techniques, self-correction methods, reasoning analytics, limitations, failures, puzzles, datasets, tools, and other resources related to deliberative prompting. The repository provides a comprehensive overview of research, techniques, and tools for enhancing reasoning capabilities of LLMs.
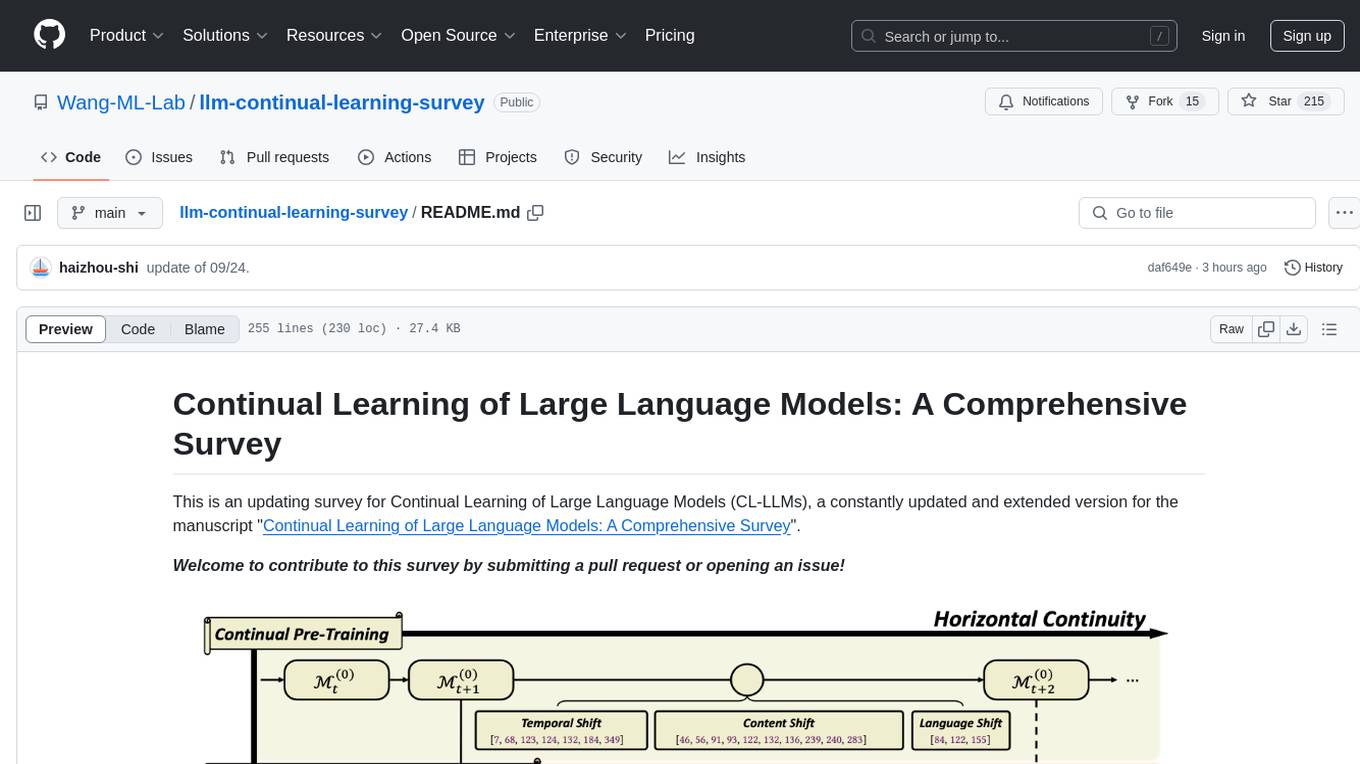
llm-continual-learning-survey
This repository is an updating survey for Continual Learning of Large Language Models (CL-LLMs), providing a comprehensive overview of various aspects related to the continual learning of large language models. It covers topics such as continual pre-training, domain-adaptive pre-training, continual fine-tuning, model refinement, model alignment, multimodal LLMs, and miscellaneous aspects. The survey includes a collection of relevant papers, each focusing on different areas within the field of continual learning of large language models.

cl-waffe2
cl-waffe2 is an experimental deep learning framework in Common Lisp, providing fast, systematic, and customizable matrix operations, reverse mode tape-based Automatic Differentiation, and neural network model building and training features accelerated by a JIT Compiler. It offers abstraction layers, extensibility, inlining, graph-level optimization, visualization, debugging, systematic nodes, and symbolic differentiation. Users can easily write extensions and optimize their networks without overheads. The framework is designed to eliminate barriers between users and developers, allowing for easy customization and extension.
Awesome-Attention-Heads
Awesome-Attention-Heads is a platform providing the latest research on Attention Heads, focusing on enhancing understanding of Transformer structure for model interpretability. It explores attention mechanisms for behavior, inference, and analysis, alongside feed-forward networks for knowledge storage. The repository aims to support researchers studying LLM interpretability and hallucination by offering cutting-edge information on Attention Head Mining.

FuseAI
FuseAI is a repository that focuses on knowledge fusion of large language models. It includes FuseChat, a state-of-the-art 7B LLM on MT-Bench, and FuseLLM, which surpasses Llama-2-7B by fusing three open-source foundation LLMs. The repository provides tech reports, releases, and datasets for FuseChat and FuseLLM, showcasing their performance and advancements in the field of chat models and large language models.
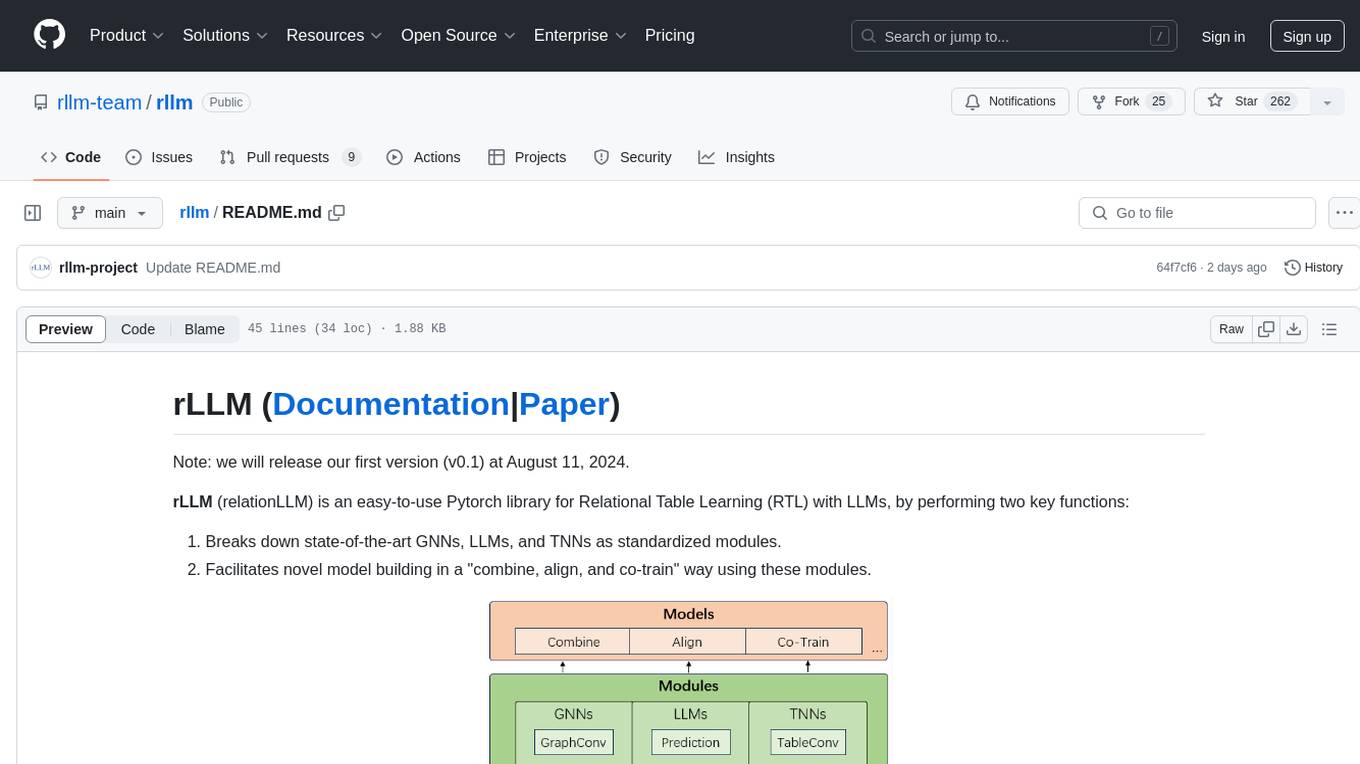
rllm
rLLM (relationLLM) is a Pytorch library for Relational Table Learning (RTL) with LLMs. It breaks down state-of-the-art GNNs, LLMs, and TNNs as standardized modules and facilitates novel model building in a 'combine, align, and co-train' way using these modules. The library is LLM-friendly, processes various graphs as multiple tables linked by foreign keys, introduces new relational table datasets, and is supported by students and teachers from Shanghai Jiao Tong University and Tsinghua University.
PURE
PURE (Process-sUpervised Reinforcement lEarning) is a framework that trains a Process Reward Model (PRM) on a dataset and fine-tunes a language model to achieve state-of-the-art mathematical reasoning capabilities. It uses a novel credit assignment method to calculate return and supports multiple reward types. The final model outperforms existing methods with minimal RL data or compute resources, achieving high accuracy on various benchmarks. The tool addresses reward hacking issues and aims to enhance long-range decision-making and reasoning tasks using large language models.

AceCoder
AceCoder is a tool that introduces a fully automated pipeline for synthesizing large-scale reliable tests used for reward model training and reinforcement learning in the coding scenario. It curates datasets, trains reward models, and performs RL training to improve coding abilities of language models. The tool aims to unlock the potential of RL training for code generation models and push the boundaries of LLM's coding abilities.
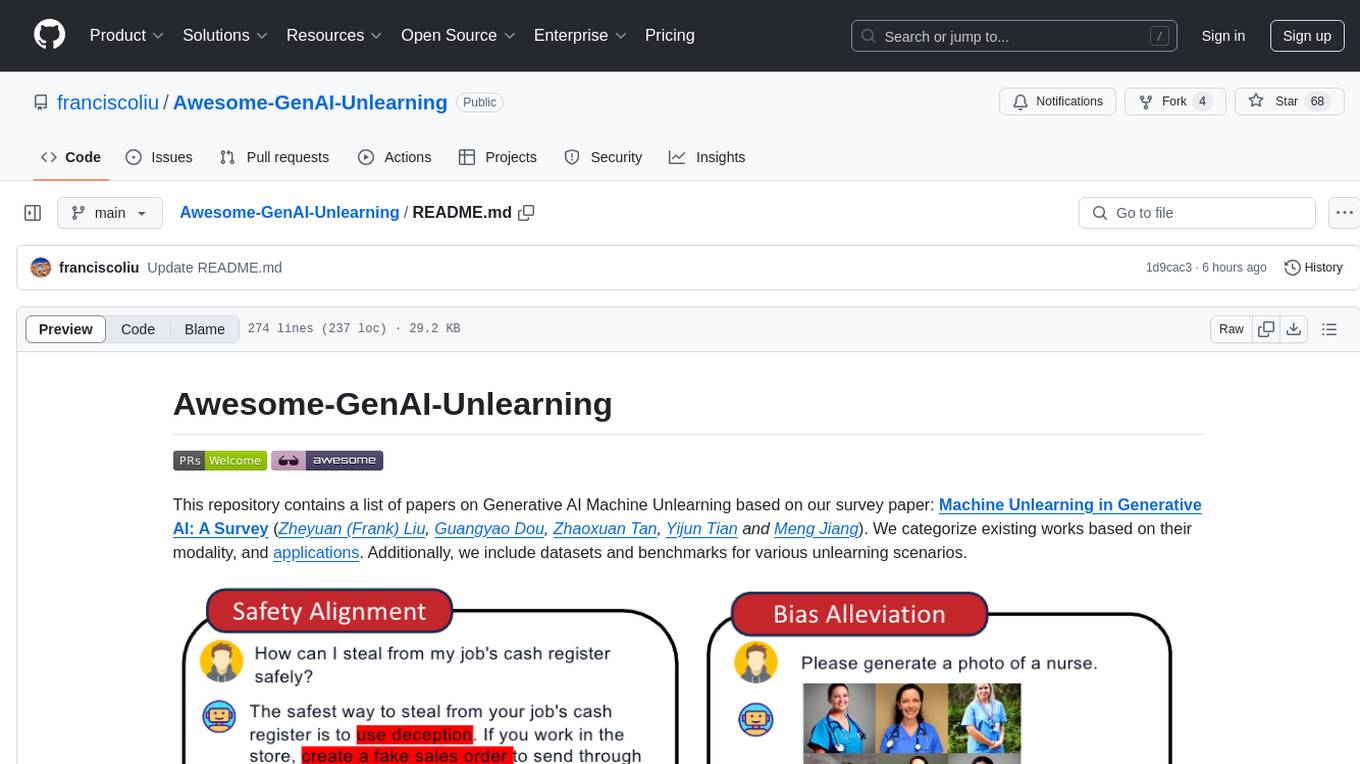
Awesome-GenAI-Unlearning
This repository is a collection of papers on Generative AI Machine Unlearning, categorized based on modality and applications. It includes datasets, benchmarks, and surveys related to unlearning scenarios in generative AI. The repository aims to provide a comprehensive overview of research in the field of machine unlearning for generative models.
DriveLM
DriveLM is a multimodal AI model that enables autonomous driving by combining computer vision and natural language processing. It is designed to understand and respond to complex driving scenarios using visual and textual information. DriveLM can perform various tasks related to driving, such as object detection, lane keeping, and decision-making. It is trained on a massive dataset of images and text, which allows it to learn the relationships between visual cues and driving actions. DriveLM is a powerful tool that can help to improve the safety and efficiency of autonomous vehicles.
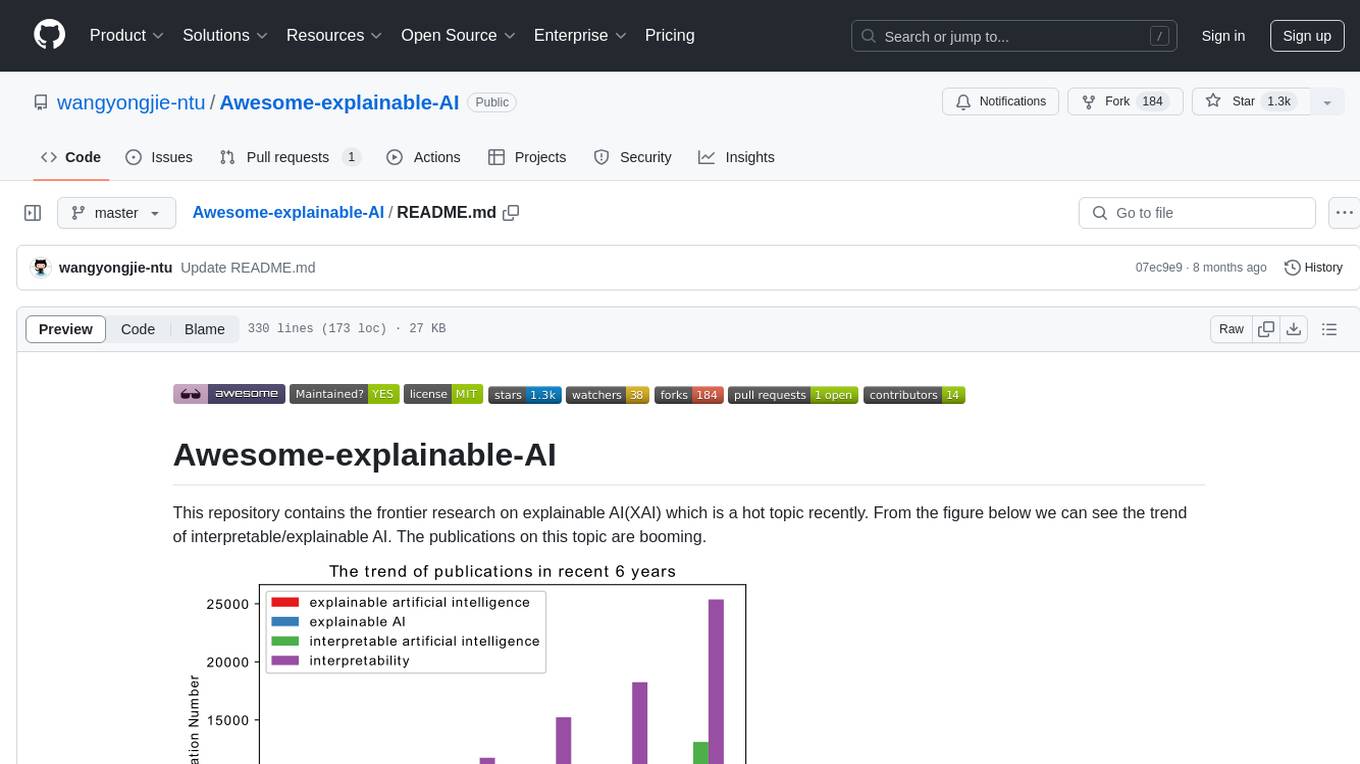
Awesome-explainable-AI
This repository contains frontier research on explainable AI (XAI), a hot topic in the field of artificial intelligence. It includes trends, use cases, survey papers, books, open courses, papers, and Python libraries related to XAI. The repository aims to organize and categorize publications on XAI, provide evaluation methods, and list various Python libraries for explainable AI.

LLM-Agent-Survey
LLM-Agent-Survey is a comprehensive repository that provides a curated list of papers related to Large Language Model (LLM) agents. The repository categorizes papers based on LLM-Profiled Roles and includes high-quality publications from prestigious conferences and journals. It aims to offer a systematic understanding of LLM-based agents, covering topics such as tool use, planning, and feedback learning. The repository also includes unpublished papers with insightful analysis and novelty, marked for future updates. Users can explore a wide range of surveys, tool use cases, planning workflows, and benchmarks related to LLM agents.
For similar tasks
Awesome-RL-based-LLM-Reasoning
This repository is dedicated to enhancing Language Model (LLM) reasoning with reinforcement learning (RL). It includes a collection of the latest papers, slides, and materials related to RL-based LLM reasoning, aiming to facilitate quick learning and understanding in this field. Starring this repository allows users to stay updated and engaged with the forefront of RL-based LLM reasoning.

Step-DPO
Step-DPO is a method for enhancing long-chain reasoning ability of LLMs with a data construction pipeline creating a high-quality dataset. It significantly improves performance on math and GSM8K tasks with minimal data and training steps. The tool fine-tunes pre-trained models like Qwen2-7B-Instruct with Step-DPO, achieving superior results compared to other models. It provides scripts for training, evaluation, and deployment, along with examples and acknowledgements.

optillm
optillm is an OpenAI API compatible optimizing inference proxy implementing state-of-the-art techniques to enhance accuracy and performance of LLMs, focusing on reasoning over coding, logical, and mathematical queries. By leveraging additional compute at inference time, it surpasses frontier models across diverse tasks.
MoBA
MoBA (Mixture of Block Attention) is an innovative approach for long-context language models, enabling efficient processing of long sequences by dividing the full context into blocks and introducing a parameter-less gating mechanism. It allows seamless transitions between full and sparse attention modes, enhancing efficiency without compromising performance. MoBA has been deployed to support long-context requests and demonstrates significant advancements in efficient attention computation for large language models.
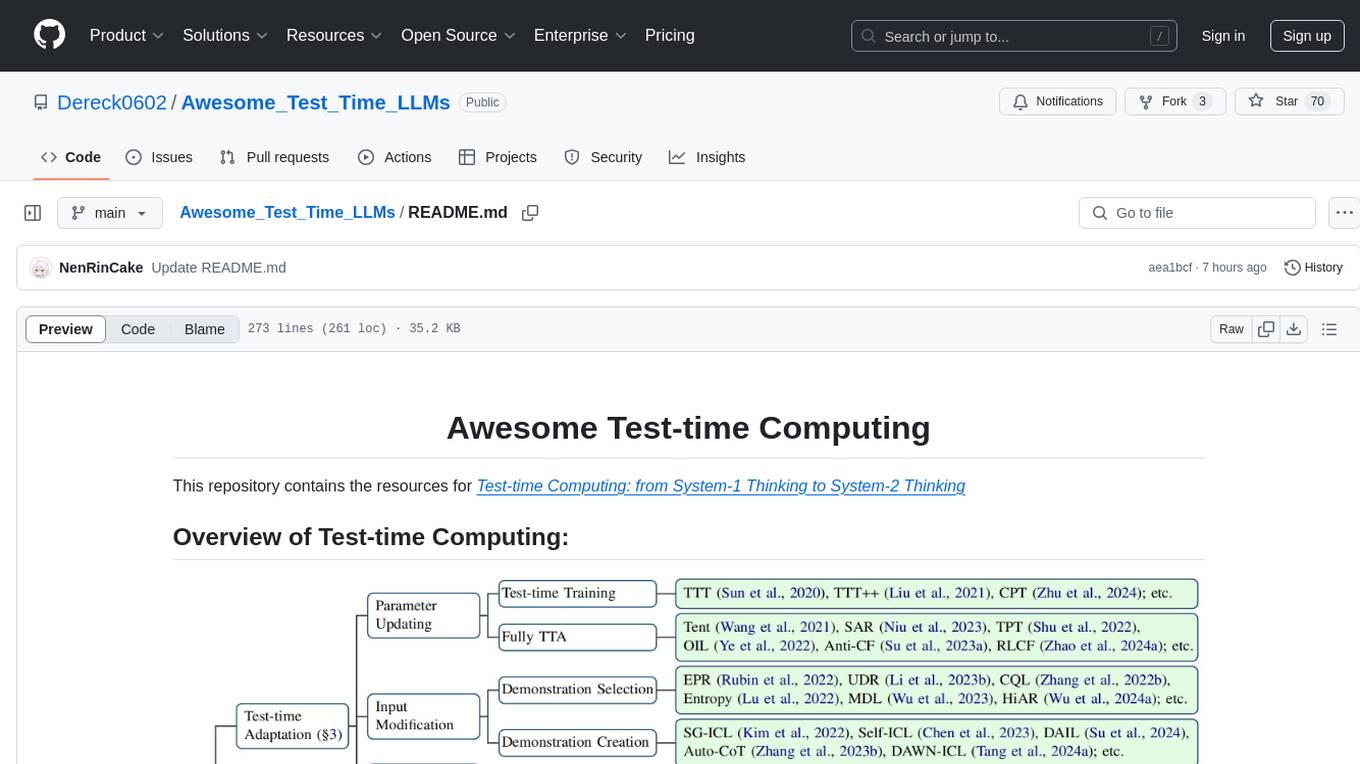
Awesome_Test_Time_LLMs
This repository focuses on test-time computing, exploring various strategies such as test-time adaptation, modifying the input, editing the representation, calibrating the output, test-time reasoning, and search strategies. It covers topics like self-supervised test-time training, in-context learning, activation steering, nearest neighbor models, reward modeling, and multimodal reasoning. The repository provides resources including papers and code for researchers and practitioners interested in enhancing the reasoning capabilities of large language models.
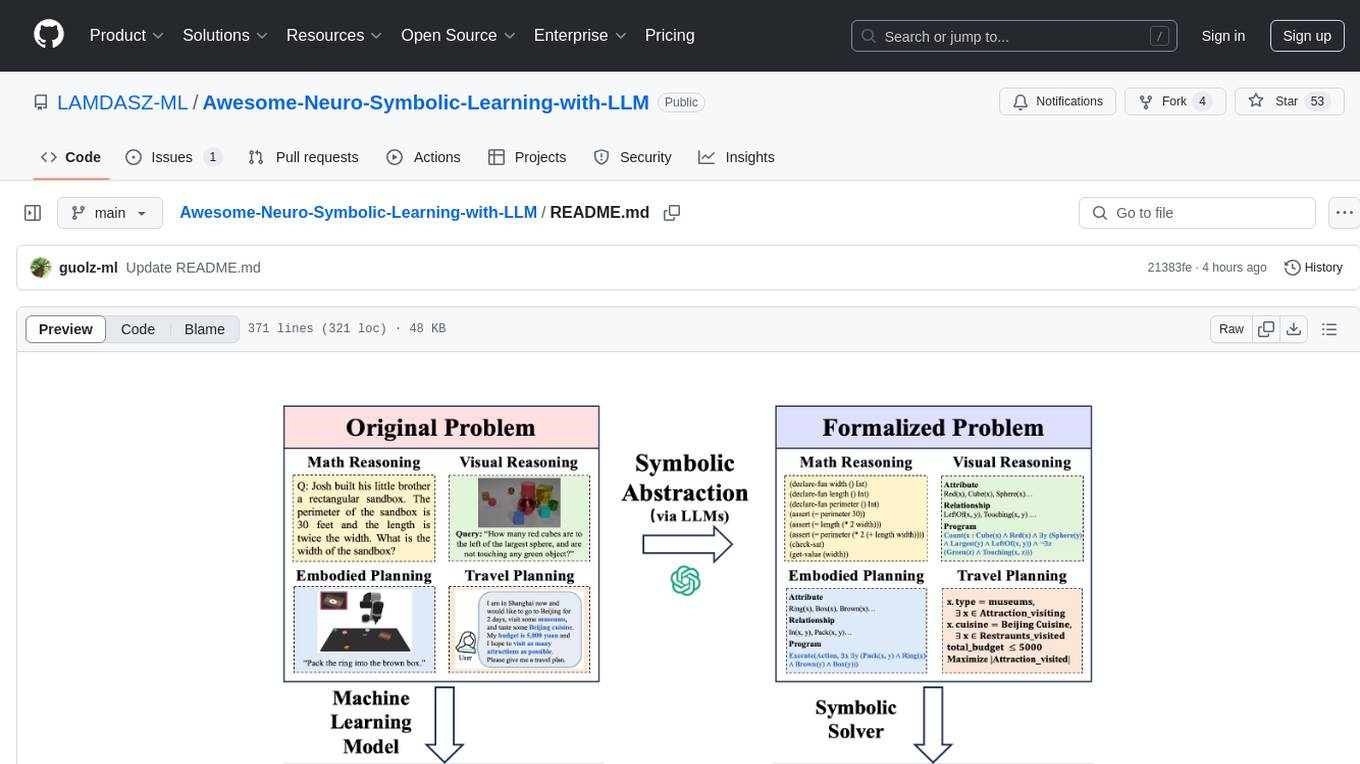
Awesome-Neuro-Symbolic-Learning-with-LLM
The Awesome-Neuro-Symbolic-Learning-with-LLM repository is a curated collection of papers and resources focusing on improving reasoning and planning capabilities of Large Language Models (LLMs) and Multi-Modal Large Language Models (MLLMs) through neuro-symbolic learning. It covers a wide range of topics such as neuro-symbolic visual reasoning, program synthesis, logical reasoning, mathematical reasoning, code generation, visual reasoning, geometric reasoning, classical planning, game AI planning, robotic planning, AI agent planning, and more. The repository provides a comprehensive overview of tutorials, workshops, talks, surveys, papers, datasets, and benchmarks related to neuro-symbolic learning with LLMs and MLLMs.
MemOS
MemOS is an operating system for Large Language Models (LLMs) that enhances them with long-term memory capabilities. It allows LLMs to store, retrieve, and manage information, enabling more context-aware, consistent, and personalized interactions. MemOS provides Memory-Augmented Generation (MAG) with a unified API for memory operations, a Modular Memory Architecture (MemCube) for easy integration and management of different memory types, and multiple memory types including Textual Memory, Activation Memory, and Parametric Memory. It is extensible, allowing users to customize memory modules, data sources, and LLM integrations. MemOS demonstrates significant improvements over baseline memory solutions in multiple reasoning tasks, with a notable improvement in temporal reasoning accuracy compared to the OpenAI baseline.
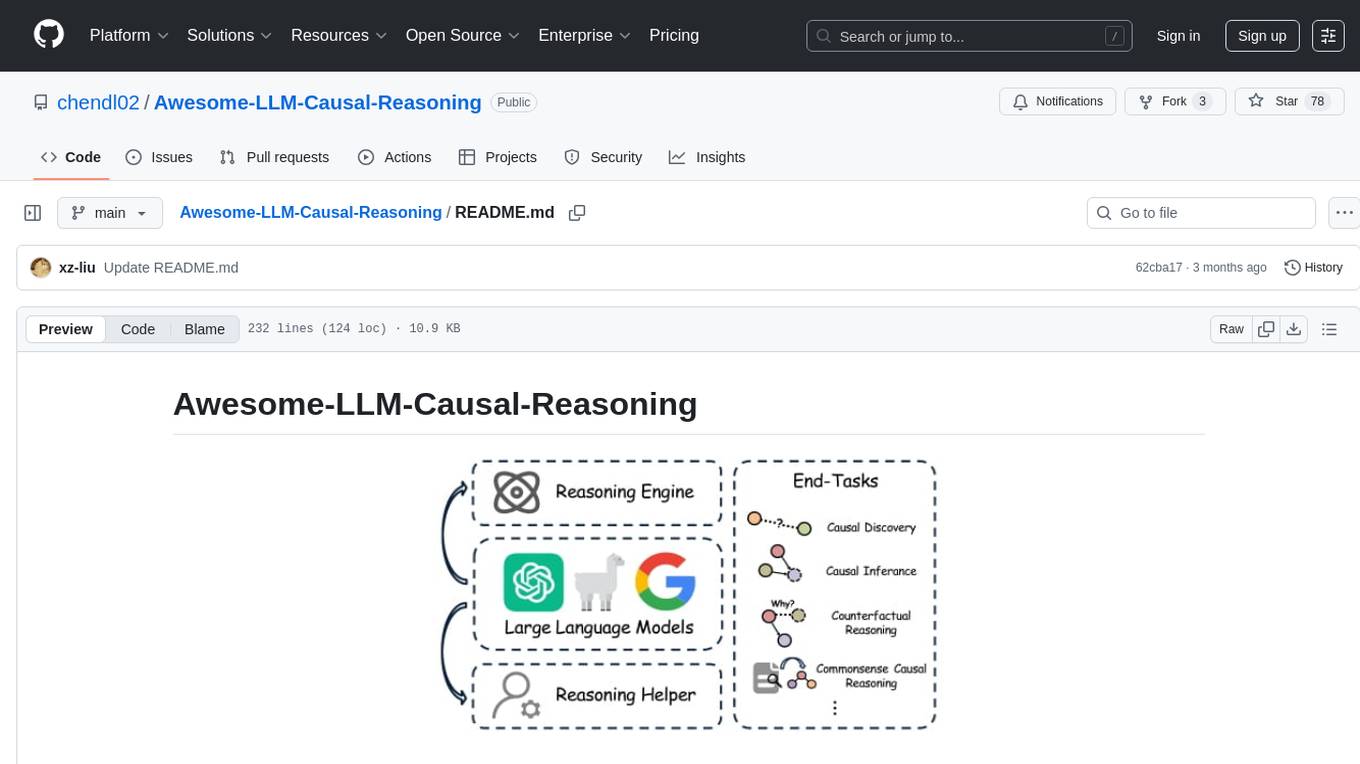
Awesome-LLM-Causal-Reasoning
The Awesome-LLM-Causal-Reasoning repository provides a comprehensive review of research focused on enhancing Large Language Models (LLMs) for causal reasoning (CR). It categorizes existing methods based on the role of LLMs as reasoning engines or helpers, evaluates LLMs' performance on various causal reasoning tasks, and discusses methodologies and insights for future research. The repository includes papers, datasets, and benchmarks related to causal reasoning in LLMs.
For similar jobs

Perplexica
Perplexica is an open-source AI-powered search engine that utilizes advanced machine learning algorithms to provide clear answers with sources cited. It offers various modes like Copilot Mode, Normal Mode, and Focus Modes for specific types of questions. Perplexica ensures up-to-date information by using SearxNG metasearch engine. It also features image and video search capabilities and upcoming features include finalizing Copilot Mode and adding Discover and History Saving features.

KULLM
KULLM (구름) is a Korean Large Language Model developed by Korea University NLP & AI Lab and HIAI Research Institute. It is based on the upstage/SOLAR-10.7B-v1.0 model and has been fine-tuned for instruction. The model has been trained on 8×A100 GPUs and is capable of generating responses in Korean language. KULLM exhibits hallucination and repetition phenomena due to its decoding strategy. Users should be cautious as the model may produce inaccurate or harmful results. Performance may vary in benchmarks without a fixed system prompt.

MMMU
MMMU is a benchmark designed to evaluate multimodal models on college-level subject knowledge tasks, covering 30 subjects and 183 subfields with 11.5K questions. It focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform tasks akin to those faced by experts. The evaluation of various models highlights substantial challenges, with room for improvement to stimulate the community towards expert artificial general intelligence (AGI).

1filellm
1filellm is a command-line data aggregation tool designed for LLM ingestion. It aggregates and preprocesses data from various sources into a single text file, facilitating the creation of information-dense prompts for large language models. The tool supports automatic source type detection, handling of multiple file formats, web crawling functionality, integration with Sci-Hub for research paper downloads, text preprocessing, and token count reporting. Users can input local files, directories, GitHub repositories, pull requests, issues, ArXiv papers, YouTube transcripts, web pages, Sci-Hub papers via DOI or PMID. The tool provides uncompressed and compressed text outputs, with the uncompressed text automatically copied to the clipboard for easy pasting into LLMs.

gpt-researcher
GPT Researcher is an autonomous agent designed for comprehensive online research on a variety of tasks. It can produce detailed, factual, and unbiased research reports with customization options. The tool addresses issues of speed, determinism, and reliability by leveraging parallelized agent work. The main idea involves running 'planner' and 'execution' agents to generate research questions, seek related information, and create research reports. GPT Researcher optimizes costs and completes tasks in around 3 minutes. Features include generating long research reports, aggregating web sources, an easy-to-use web interface, scraping web sources, and exporting reports to various formats.

ChatTTS
ChatTTS is a generative speech model optimized for dialogue scenarios, providing natural and expressive speech synthesis with fine-grained control over prosodic features. It supports multiple speakers and surpasses most open-source TTS models in terms of prosody. The model is trained with 100,000+ hours of Chinese and English audio data, and the open-source version on HuggingFace is a 40,000-hour pre-trained model without SFT. The roadmap includes open-sourcing additional features like VQ encoder, multi-emotion control, and streaming audio generation. The tool is intended for academic and research use only, with precautions taken to limit potential misuse.

HebTTS
HebTTS is a language modeling approach to diacritic-free Hebrew text-to-speech (TTS) system. It addresses the challenge of accurately mapping text to speech in Hebrew by proposing a language model that operates on discrete speech representations and is conditioned on a word-piece tokenizer. The system is optimized using weakly supervised recordings and outperforms diacritic-based Hebrew TTS systems in terms of content preservation and naturalness of generated speech.

do-research-in-AI
This repository is a collection of research lectures and experience sharing posts from frontline researchers in the field of AI. It aims to help individuals upgrade their research skills and knowledge through insightful talks and experiences shared by experts. The content covers various topics such as evaluating research papers, choosing research directions, research methodologies, and tips for writing high-quality scientific papers. The repository also includes discussions on academic career paths, research ethics, and the emotional aspects of research work. Overall, it serves as a valuable resource for individuals interested in advancing their research capabilities in the field of AI.