
KULLM
☁️ 구름(KULLM): 고려대학교에서 개발한, 한국어에 특화된 LLM
Stars: 527

KULLM (구름) is a Korean Large Language Model developed by Korea University NLP & AI Lab and HIAI Research Institute. It is based on the upstage/SOLAR-10.7B-v1.0 model and has been fine-tuned for instruction. The model has been trained on 8×A100 GPUs and is capable of generating responses in Korean language. KULLM exhibits hallucination and repetition phenomena due to its decoding strategy. Users should be cautious as the model may produce inaccurate or harmful results. Performance may vary in benchmarks without a fixed system prompt.
README:
![]()
- 2024.04.08: 🤗구름3(KULLM3) 양자화 모델(awq-4bit) 공개
- 2024.04.03: 🤗구름3(KULLM3) 공개
- 2023.06.23: 한국어 대화 평가 결과 공개
- 2023.06.08: 🤗Polyglot-ko 5.8B 기반 KULLM-Polyglot-5.8B-v2 fp16 모델 공개
- 2023.06.01: 구름(KULLM) 데이터셋 v2 HuggingFace Datasets 공개
- 2023.05.31: 🤗Polyglot-ko 12.8B 기반 KULLM-Polyglot-12.8B-v2 fp16 모델 공개
- 2023.05.30: 🤗Polyglot-ko 12.8B 기반 KULLM-Polyglot-12.8B fp16 모델 공개
KULLM(구름)은 고려대학교 NLP & AI 연구실과 HIAI 연구소가 개발한 한국어 Large Language Model (LLM) 입니다.
KULLM3을 공개합니다.
(이전 모델의 학습 방법 및 데이터는 kullm_v2 브랜치를 참고해 주세요.)





- torch / transformers / accelerate 설치
- (2024.04.03기준) transformers>=4.39.0 에서 generate 함수가 제대로 동작하지 않습니다. 4.38.2로 설치해주세요.
- (2024.04.28기준) transformers>=4.40.0 에서 정상 동작함을 확인했습니다.
pip install torch transformers==4.38.2 accelerate아래 예제 코드로 실행해볼 수 있습니다.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
MODEL_DIR = "nlpai-lab/KULLM3"
model = AutoModelForCausalLM.from_pretrained(MODEL_DIR, torch_dtype=torch.float16).to("cuda")
tokenizer = AutoTokenizer.from_pretrained(MODEL_DIR)
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
s = "고려대학교에 대해서 알고 있니?"
conversation = [{'role': 'user', 'content': s}]
inputs = tokenizer.apply_chat_template(
conversation,
tokenize=True,
add_generation_prompt=True,
return_tensors='pt').to("cuda")
_ = model.generate(inputs, streamer=streamer, max_new_tokens=1024, use_cache=True)
# 네, 고려대학교에 대해 알고 있습니다. 고려대학교는 대한민국 서울에 위치한 사립 대학교로, 1905년에 설립되었습니다. 이 대학교는 한국에서 가장 오래된 대학 중 하나로, 다양한 학부 및 대학원 프로그램을 제공합니다. 고려대학교는 특히 법학, 경제학, 정치학, 사회학, 문학, 과학 분야에서 높은 명성을 가지고 있습니다. 또한, 스포츠 분야에서도 활발한 활동을 보이며, 대한민국 대학 스포츠에서 중요한 역할을 하고 있습니다. 고려대학교는 국제적인 교류와 협력에도 적극적이며, 전 세계 다양한 대학과의 협력을 통해 글로벌 경쟁력을 강화하고 있습니다.- KULLM3은 upstage/SOLAR-10.7B-v1.0을 기반으로 instruction-tuning 된 모델입니다.
- 8×A100 GPU로 학습되었습니다.
- 다음 시스템 프롬프트가 주어진 상태로 학습하였습니다. (예제 코드에서도 시스템 프롬프트를 포함시키고 있습니다!)
당신은 고려대학교 NLP&AI 연구실에서 만든 AI 챗봇입니다.
당신의 이름은 'KULLM'으로, 한국어로는 '구름'을 뜻합니다.
당신은 비도덕적이거나, 성적이거나, 불법적이거나 또는 사회 통념적으로 허용되지 않는 발언은 하지 않습니다.
사용자와 즐겁게 대화하며, 사용자의 응답에 가능한 정확하고 친절하게 응답함으로써 최대한 도와주려고 노력합니다.
질문이 이상하다면, 어떤 부분이 이상한지 설명합니다. 거짓 정보를 발언하지 않도록 주의합니다.
- 대화 능력 평가는 다음을 참고하여 진행했습니다.
- G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment (Yang Liu. et. al. 2023)
- MT-Eval
- 평가 모델은 GPT-4-Turbo(gpt-4-0125-preview)를 사용하였고, 평가 데이터셋은 yizhongw/self-instruct의 휴먼 평가 데이터셋인
user_oriented_instructions.jsonl을 deepl로 번역한 데이터셋을 사용하였습니다. - 주어진 prompt 데이터에 대해 모델이 응답을 생성하고, 그 응답을 OpenAI API를 사용하여 평가하는 방식입니다.
- 해당 평가 결과는 repo에서 재현할 수 있습니다.
모델 평가에 사용한 프롬프트는 다음과 같습니다.
실험 결과, 한국어보다 영어 프롬프트가 더 정확한 평가 결과를 보여주었습니다.
따라서 평가의 정확성을 위해 영어 프롬프트로 진행했습니다.
You will be given evaluation instruction, input and AI-generated response.
Your task is to rate the response on given metric.
Please make sure you read and understand these instructions carefully. Please keep this document open while reviewing, and refer to it as needed.
Evaluation Criteria:
- Fluency (1-5): The quality of the language used in the translation. A high-quality response should be grammatically correct, idiomatic, and free from spelling and punctuation errors.
- Coherence (1-5): A high score indicates that the response maintains consistent context. A low score is given if the response shifts context or language inappropriately from instruction(e.g. instruction's language is Korean, but response is English).
- Accuracy (1-5) - The correctness of the answer. The answer should be factually correct and directly answer the question asked
- Completeness (1-5) - The extent to which the response covers all aspects of the question. The response should not just address one part of the question, but should provide a comprehensive response.
- Overall Quality (1-5) - The overall effectiveness and excellence of the response, integrating considerations of all above criteria.
Evaluation Steps:
1. Read the instruction and input carefully and understand what it is asking.
2. Read the AI-generated response and Evaluation Criteria.
3. Assign a score for each criterion on a scale of 1 to 5, where 1 is the lowest and 5 is the highest.
Instruction:
{instruction}
Input:
{input}
Response:
{response}
Evaluation Form (scores ONLY):
- Fluency (1-5):
- Coherence (1-5):
- Accuracy (1-5):
- Completeness (1-5):
- Overall Quality (1-5):
- 환각(Hallucination) 현상과, decoding strategy에 따라 동어 반복 현상이 존재하는 모델입니다.
- KULLM이 생성한 결과는 부정확하거나 유해한 결과를 포함할 수 있습니다.
- 고정된 system prompt로 훈련된 모델이므로, system prompt를 주지 않는 벤치마크의 경우 성능이 본래보다 낮을 수 있습니다.
Apache-2.0
Please cite the repo if you use the data or code in this repo.
@misc{kullm3,
author = {Kim, Jeongwook and Lee, Taemin and Jang, Yoonna and Moon, Hyeonseok and Son, Suhyune and Lee, Seungyoon and Kim, Dongjun},
title = {KULLM3: Korea University Large Language Model 3},
year = {2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/nlpai-lab/kullm}},
}
@inproceedings{lee2023kullm,
title={KULLM: Learning to Construct Korean Instruction-following Large Language Models},
author={Lee, SeungJun and Lee, Taemin and Lee, Jeongwoo and Jang, Yoona and Lim, Heuiseok},
booktitle={Annual Conference on Human and Language Technology},
pages={196--202},
year={2023},
organization={Human and Language Technology}
}
@misc{kullm,
author = {NLP & AI Lab and Human-Inspired AI research},
title = {KULLM: Korea University Large Language Model Project},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/nlpai-lab/kullm}},
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for KULLM
Similar Open Source Tools
KULLM
KULLM (구름) is a Korean Large Language Model developed by Korea University NLP & AI Lab and HIAI Research Institute. It is based on the upstage/SOLAR-10.7B-v1.0 model and has been fine-tuned for instruction. The model has been trained on 8×A100 GPUs and is capable of generating responses in Korean language. KULLM exhibits hallucination and repetition phenomena due to its decoding strategy. Users should be cautious as the model may produce inaccurate or harmful results. Performance may vary in benchmarks without a fixed system prompt.
LLMRec
LLMRec is a PyTorch implementation for the WSDM 2024 paper 'Large Language Models with Graph Augmentation for Recommendation'. It is a novel framework that enhances recommenders by applying LLM-based graph augmentation strategies to recommendation systems. The tool aims to make the most of content within online platforms to augment interaction graphs by reinforcing u-i interactive edges, enhancing item node attributes, and conducting user node profiling from a natural language perspective.

MotionLLM
MotionLLM is a framework for human behavior understanding that leverages Large Language Models (LLMs) to jointly model videos and motion sequences. It provides a unified training strategy, dataset MoVid, and MoVid-Bench for evaluating human behavior comprehension. The framework excels in captioning, spatial-temporal comprehension, and reasoning abilities.

catalyst
Catalyst is a C# Natural Language Processing library designed for speed, inspired by spaCy's design. It provides pre-trained models, support for training word and document embeddings, and flexible entity recognition models. The library is fast, modern, and pure-C#, supporting .NET standard 2.0. It is cross-platform, running on Windows, Linux, macOS, and ARM. Catalyst offers non-destructive tokenization, named entity recognition, part-of-speech tagging, language detection, and efficient binary serialization. It includes pre-built models for language packages and lemmatization. Users can store and load models using streams. Getting started with Catalyst involves installing its NuGet Package and setting the storage to use the online repository. The library supports lazy loading of models from disk or online. Users can take advantage of C# lazy evaluation and native multi-threading support to process documents in parallel. Training a new FastText word2vec embedding model is straightforward, and Catalyst also provides algorithms for fast embedding search and dimensionality reduction.
CodeGen
CodeGen is an official release of models for Program Synthesis by Salesforce AI Research. It includes CodeGen1 and CodeGen2 models with varying parameters. The latest version, CodeGen2.5, outperforms previous models. The tool is designed for code generation tasks using large language models trained on programming and natural languages. Users can access the models through the Hugging Face Hub and utilize them for program synthesis and infill sampling. The accompanying Jaxformer library provides support for data pre-processing, training, and fine-tuning of the CodeGen models.

rl
TorchRL is an open-source Reinforcement Learning (RL) library for PyTorch. It provides pytorch and **python-first** , low and high level abstractions for RL that are intended to be **efficient** , **modular** , **documented** and properly **tested**. The code is aimed at supporting research in RL. Most of it is written in python in a highly modular way, such that researchers can easily swap components, transform them or write new ones with little effort.

EasySteer
EasySteer is a unified framework built on vLLM for high-performance LLM steering. It offers fast, flexible, and easy-to-use steering capabilities with features like high performance, modular design, fine-grained control, pre-computed steering vectors, and an interactive demo. Users can interactively configure models, adjust steering parameters, and test interventions without writing code. The tool supports OpenAI-compatible APIs and provides modules for hidden states extraction, analysis-based steering, learning-based steering, and a frontend web interface for interactive steering and ReFT interventions.
PhoGPT
PhoGPT is an open-source 4B-parameter generative model series for Vietnamese, including the base pre-trained monolingual model PhoGPT-4B and its chat variant, PhoGPT-4B-Chat. PhoGPT-4B is pre-trained from scratch on a Vietnamese corpus of 102B tokens, with an 8192 context length and a vocabulary of 20K token types. PhoGPT-4B-Chat is fine-tuned on instructional prompts and conversations, demonstrating superior performance. Users can run the model with inference engines like vLLM and Text Generation Inference, and fine-tune it using llm-foundry. However, PhoGPT has limitations in reasoning, coding, and mathematics tasks, and may generate harmful or biased responses.

cellseg_models.pytorch
cellseg-models.pytorch is a Python library built upon PyTorch for 2D cell/nuclei instance segmentation models. It provides multi-task encoder-decoder architectures and post-processing methods for segmenting cell/nuclei instances. The library offers high-level API to define segmentation models, open-source datasets for training, flexibility to modify model components, sliding window inference, multi-GPU inference, benchmarking utilities, regularization techniques, and example notebooks for training and finetuning models with different backbones.
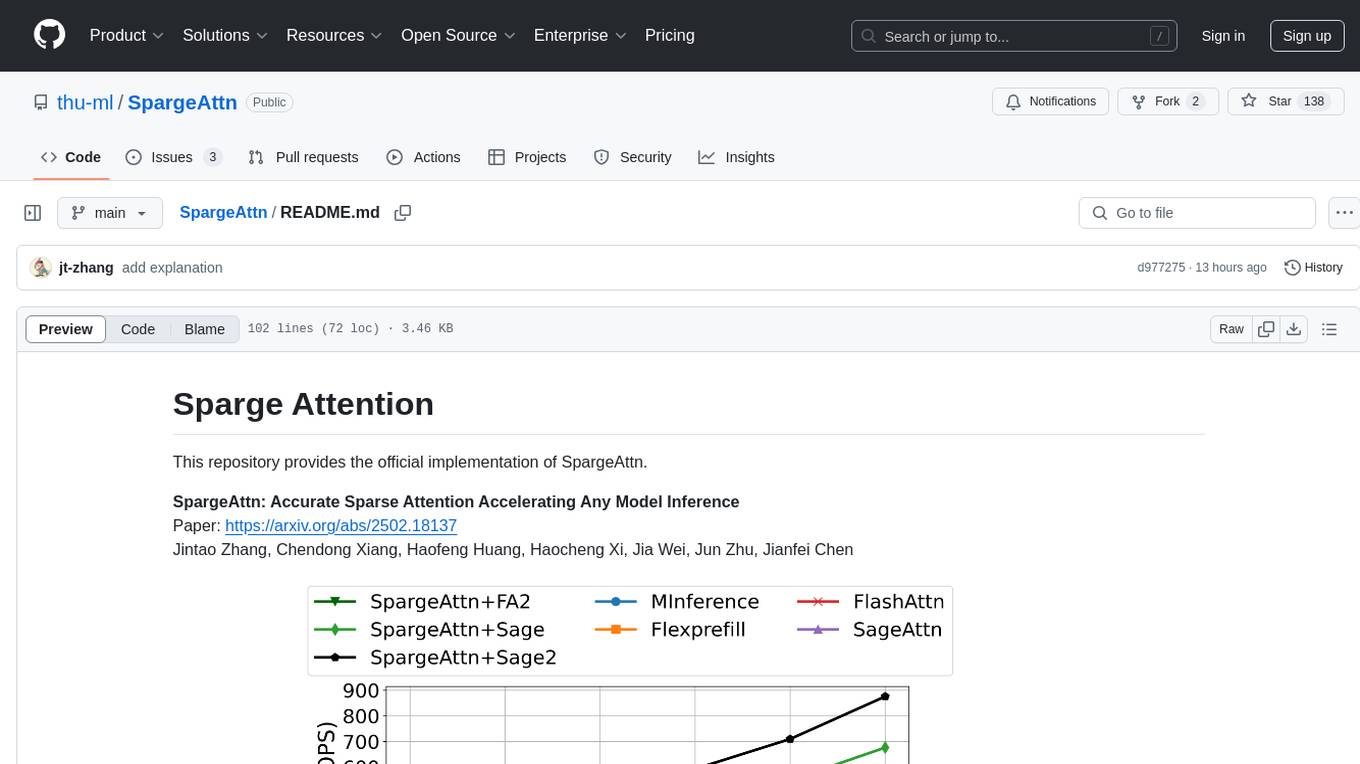
SpargeAttn
SpargeAttn is an official implementation designed for accelerating any model inference by providing accurate sparse attention. It offers a significant speedup in model performance while maintaining quality. The tool is based on SageAttention and SageAttention2, providing options for different levels of optimization. Users can easily install the package and utilize the available APIs for their specific needs. SpargeAttn is particularly useful for tasks requiring efficient attention mechanisms in deep learning models.

VITA
VITA is an open-source interactive omni multimodal Large Language Model (LLM) capable of processing video, image, text, and audio inputs simultaneously. It stands out with features like Omni Multimodal Understanding, Non-awakening Interaction, and Audio Interrupt Interaction. VITA can respond to user queries without a wake-up word, track and filter external queries in real-time, and handle various query inputs effectively. The model utilizes state tokens and a duplex scheme to enhance the multimodal interactive experience.
LongCite
LongCite is a tool that enables Large Language Models (LLMs) to generate fine-grained citations in long-context Question Answering (QA) scenarios. It provides models trained on GLM-4-9B and Meta-Llama-3.1-8B, supporting up to 128K context. Users can deploy LongCite chatbots, generate accurate responses, and obtain precise sentence-level citations. The tool includes components for model deployment, Coarse to Fine (CoF) pipeline for data construction, model training using LongCite-45k dataset, evaluation with LongBench-Cite benchmark, and citation generation.
MarkLLM
MarkLLM is an open-source toolkit designed for watermarking technologies within large language models (LLMs). It simplifies access, understanding, and assessment of watermarking technologies, supporting various algorithms, visualization tools, and evaluation modules. The toolkit aids researchers and the community in ensuring the authenticity and origin of machine-generated text.

ALMA
ALMA (Advanced Language Model-based Translator) is a many-to-many LLM-based translation model that utilizes a two-step fine-tuning process on monolingual and parallel data to achieve strong translation performance. ALMA-R builds upon ALMA models with LoRA fine-tuning and Contrastive Preference Optimization (CPO) for even better performance, surpassing GPT-4 and WMT winners. The repository provides ALMA and ALMA-R models, datasets, environment setup, evaluation scripts, training guides, and data information for users to leverage these models for translation tasks.
unitxt
Unitxt is a customizable library for textual data preparation and evaluation tailored to generative language models. It natively integrates with common libraries like HuggingFace and LM-eval-harness and deconstructs processing flows into modular components, enabling easy customization and sharing between practitioners. These components encompass model-specific formats, task prompts, and many other comprehensive dataset processing definitions. The Unitxt-Catalog centralizes these components, fostering collaboration and exploration in modern textual data workflows. Beyond being a tool, Unitxt is a community-driven platform, empowering users to build, share, and advance their pipelines collaboratively.

MInference
MInference is a tool designed to accelerate pre-filling for long-context Language Models (LLMs) by leveraging dynamic sparse attention. It achieves up to a 10x speedup for pre-filling on an A100 while maintaining accuracy. The tool supports various decoding LLMs, including LLaMA-style models and Phi models, and provides custom kernels for attention computation. MInference is useful for researchers and developers working with large-scale language models who aim to improve efficiency without compromising accuracy.
For similar tasks
KULLM
KULLM (구름) is a Korean Large Language Model developed by Korea University NLP & AI Lab and HIAI Research Institute. It is based on the upstage/SOLAR-10.7B-v1.0 model and has been fine-tuned for instruction. The model has been trained on 8×A100 GPUs and is capable of generating responses in Korean language. KULLM exhibits hallucination and repetition phenomena due to its decoding strategy. Users should be cautious as the model may produce inaccurate or harmful results. Performance may vary in benchmarks without a fixed system prompt.

mindsdb
MindsDB is a platform for customizing AI from enterprise data. You can create, serve, and fine-tune models in real-time from your database, vector store, and application data. MindsDB "enhances" SQL syntax with AI capabilities to make it accessible for developers worldwide. With MindsDB’s nearly 200 integrations, any developer can create AI customized for their purpose, faster and more securely. Their AI systems will constantly improve themselves — using companies’ own data, in real-time.

training-operator
Kubeflow Training Operator is a Kubernetes-native project for fine-tuning and scalable distributed training of machine learning (ML) models created with various ML frameworks such as PyTorch, Tensorflow, XGBoost, MPI, Paddle and others. Training Operator allows you to use Kubernetes workloads to effectively train your large models via Kubernetes Custom Resources APIs or using Training Operator Python SDK. > Note: Before v1.2 release, Kubeflow Training Operator only supports TFJob on Kubernetes. * For a complete reference of the custom resource definitions, please refer to the API Definition. * TensorFlow API Definition * PyTorch API Definition * Apache MXNet API Definition * XGBoost API Definition * MPI API Definition * PaddlePaddle API Definition * For details of all-in-one operator design, please refer to the All-in-one Kubeflow Training Operator * For details on its observability, please refer to the monitoring design doc.

helix
HelixML is a private GenAI platform that allows users to deploy the best of open AI in their own data center or VPC while retaining complete data security and control. It includes support for fine-tuning models with drag-and-drop functionality. HelixML brings the best of open source AI to businesses in an ergonomic and scalable way, optimizing the tradeoff between GPU memory and latency.

nntrainer
NNtrainer is a software framework for training neural network models on devices with limited resources. It enables on-device fine-tuning of neural networks using user data for personalization. NNtrainer supports various machine learning algorithms and provides examples for tasks such as few-shot learning, ResNet, VGG, and product rating. It is optimized for embedded devices and utilizes CBLAS and CUBLAS for accelerated calculations. NNtrainer is open source and released under the Apache License version 2.0.

petals
Petals is a tool that allows users to run large language models at home in a BitTorrent-style manner. It enables fine-tuning and inference up to 10x faster than offloading. Users can generate text with distributed models like Llama 2, Falcon, and BLOOM, and fine-tune them for specific tasks directly from their desktop computer or Google Colab. Petals is a community-run system that relies on people sharing their GPUs to increase its capacity and offer a distributed network for hosting model layers.

LLaVA-pp
This repository, LLaVA++, extends the visual capabilities of the LLaVA 1.5 model by incorporating the latest LLMs, Phi-3 Mini Instruct 3.8B, and LLaMA-3 Instruct 8B. It provides various models for instruction-following LMMS and academic-task-oriented datasets, along with training scripts for Phi-3-V and LLaMA-3-V. The repository also includes installation instructions and acknowledgments to related open-source contributions.

Firefly
Firefly is an open-source large model training project that supports pre-training, fine-tuning, and DPO of mainstream large models. It includes models like Llama3, Gemma, Qwen1.5, MiniCPM, Llama, InternLM, Baichuan, ChatGLM, Yi, Deepseek, Qwen, Orion, Ziya, Xverse, Mistral, Mixtral-8x7B, Zephyr, Vicuna, Bloom, etc. The project supports full-parameter training, LoRA, QLoRA efficient training, and various tasks such as pre-training, SFT, and DPO. Suitable for users with limited training resources, QLoRA is recommended for fine-tuning instructions. The project has achieved good results on the Open LLM Leaderboard with QLoRA training process validation. The latest version has significant updates and adaptations for different chat model templates.
For similar jobs

Perplexica
Perplexica is an open-source AI-powered search engine that utilizes advanced machine learning algorithms to provide clear answers with sources cited. It offers various modes like Copilot Mode, Normal Mode, and Focus Modes for specific types of questions. Perplexica ensures up-to-date information by using SearxNG metasearch engine. It also features image and video search capabilities and upcoming features include finalizing Copilot Mode and adding Discover and History Saving features.
KULLM
KULLM (구름) is a Korean Large Language Model developed by Korea University NLP & AI Lab and HIAI Research Institute. It is based on the upstage/SOLAR-10.7B-v1.0 model and has been fine-tuned for instruction. The model has been trained on 8×A100 GPUs and is capable of generating responses in Korean language. KULLM exhibits hallucination and repetition phenomena due to its decoding strategy. Users should be cautious as the model may produce inaccurate or harmful results. Performance may vary in benchmarks without a fixed system prompt.

MMMU
MMMU is a benchmark designed to evaluate multimodal models on college-level subject knowledge tasks, covering 30 subjects and 183 subfields with 11.5K questions. It focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform tasks akin to those faced by experts. The evaluation of various models highlights substantial challenges, with room for improvement to stimulate the community towards expert artificial general intelligence (AGI).

1filellm
1filellm is a command-line data aggregation tool designed for LLM ingestion. It aggregates and preprocesses data from various sources into a single text file, facilitating the creation of information-dense prompts for large language models. The tool supports automatic source type detection, handling of multiple file formats, web crawling functionality, integration with Sci-Hub for research paper downloads, text preprocessing, and token count reporting. Users can input local files, directories, GitHub repositories, pull requests, issues, ArXiv papers, YouTube transcripts, web pages, Sci-Hub papers via DOI or PMID. The tool provides uncompressed and compressed text outputs, with the uncompressed text automatically copied to the clipboard for easy pasting into LLMs.

gpt-researcher
GPT Researcher is an autonomous agent designed for comprehensive online research on a variety of tasks. It can produce detailed, factual, and unbiased research reports with customization options. The tool addresses issues of speed, determinism, and reliability by leveraging parallelized agent work. The main idea involves running 'planner' and 'execution' agents to generate research questions, seek related information, and create research reports. GPT Researcher optimizes costs and completes tasks in around 3 minutes. Features include generating long research reports, aggregating web sources, an easy-to-use web interface, scraping web sources, and exporting reports to various formats.

ChatTTS
ChatTTS is a generative speech model optimized for dialogue scenarios, providing natural and expressive speech synthesis with fine-grained control over prosodic features. It supports multiple speakers and surpasses most open-source TTS models in terms of prosody. The model is trained with 100,000+ hours of Chinese and English audio data, and the open-source version on HuggingFace is a 40,000-hour pre-trained model without SFT. The roadmap includes open-sourcing additional features like VQ encoder, multi-emotion control, and streaming audio generation. The tool is intended for academic and research use only, with precautions taken to limit potential misuse.

HebTTS
HebTTS is a language modeling approach to diacritic-free Hebrew text-to-speech (TTS) system. It addresses the challenge of accurately mapping text to speech in Hebrew by proposing a language model that operates on discrete speech representations and is conditioned on a word-piece tokenizer. The system is optimized using weakly supervised recordings and outperforms diacritic-based Hebrew TTS systems in terms of content preservation and naturalness of generated speech.

do-research-in-AI
This repository is a collection of research lectures and experience sharing posts from frontline researchers in the field of AI. It aims to help individuals upgrade their research skills and knowledge through insightful talks and experiences shared by experts. The content covers various topics such as evaluating research papers, choosing research directions, research methodologies, and tips for writing high-quality scientific papers. The repository also includes discussions on academic career paths, research ethics, and the emotional aspects of research work. Overall, it serves as a valuable resource for individuals interested in advancing their research capabilities in the field of AI.