
lancedb
Developer-friendly, embedded retrieval engine for multimodal AI. Search More; Manage Less.
Stars: 7561
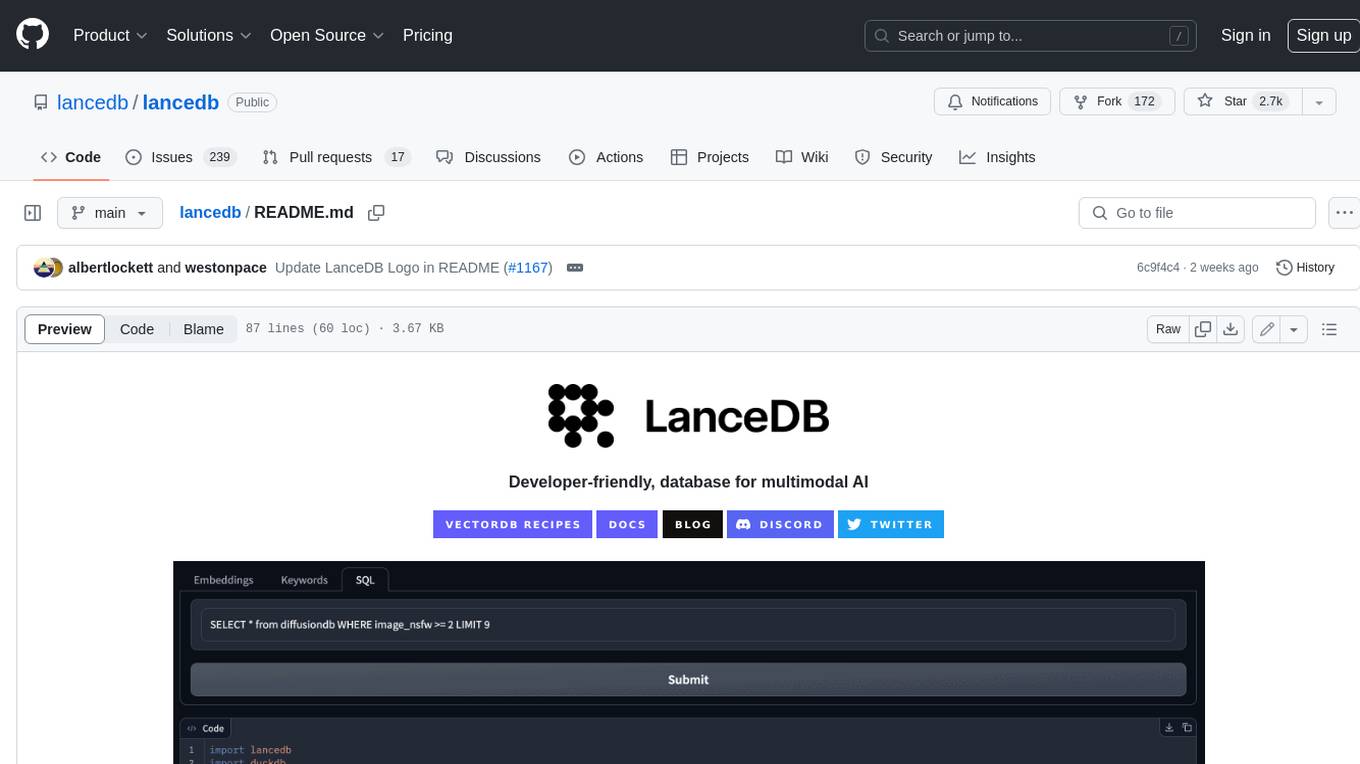
LanceDB is an open-source database for vector-search built with persistent storage, which greatly simplifies retrieval, filtering, and management of embeddings. The key features of LanceDB include: Production-scale vector search with no servers to manage. Store, query, and filter vectors, metadata, and multi-modal data (text, images, videos, point clouds, and more). Support for vector similarity search, full-text search, and SQL. Native Python and Javascript/Typescript support. Zero-copy, automatic versioning, manage versions of your data without needing extra infrastructure. GPU support in building vector index(*). Ecosystem integrations with LangChain 🦜️🔗, LlamaIndex 🦙, Apache-Arrow, Pandas, Polars, DuckDB, and more on the way. LanceDB's core is written in Rust 🦀 and is built using Lance, an open-source columnar format designed for performant ML workloads.
README:


How to Install ✦ Detailed Documentation ✦ Tutorials and Recipes ✦ Contributors
The ultimate multimodal data platform for AI/ML applications.
LanceDB is designed for fast, scalable, and production-ready vector search. It is built on top of the Lance columnar format. You can store, index, and search over petabytes of multimodal data and vectors with ease. LanceDB is a central location where developers can build, train and analyze their AI workloads.
⭐ Click here ⭐ to see how fast we're growing!
- Fast Vector Search: Search billions of vectors in milliseconds with state-of-the-art indexing.
- Comprehensive Search: Support for vector similarity search, full-text search and SQL.
- Multimodal Support: Store, query and filter vectors, metadata and multimodal data (text, images, videos, point clouds, and more).
- Advanced Features: Zero-copy, automatic versioning, manage versions of your data without needing extra infrastructure. GPU support in building vector index.
- Open Source & Local: 100% open source, runs locally or in your cloud. No vendor lock-in.
- Cloud and Enterprise: Production-scale vector search with no servers to manage. Complete data sovereignty and security.
- Columnar Storage: Built on the Lance columnar format for efficient storage and analytics.
- Seamless Integration: Python, Node.js, Rust, and REST APIs for easy integration. Native Python and Javascript/Typescript support.
- Rich Ecosystem: Integrations with LangChain 🦜️🔗, LlamaIndex 🦙, Apache-Arrow, Pandas, Polars, DuckDB and more on the way.
Follow the Quickstart doc to set up LanceDB locally.
API & SDK: We also support Python, Typescript and Rust SDKs
| Interface | Documentation |
|---|---|
| Python SDK | https://lancedb.github.io/lancedb/python/python/ |
| Typescript SDK | https://lancedb.github.io/lancedb/js/globals/ |
| Rust SDK | https://docs.rs/lancedb/latest/lancedb/index.html |
| REST API | https://docs.lancedb.com/api-reference/introduction |
We welcome contributions from everyone! Whether you're a developer, researcher, or just someone who wants to help out.
If you have any suggestions or feature requests, please feel free to open an issue on GitHub or discuss it on our Discord server.
Check out the GitHub Issues if you would like to work on the features that are planned for the future. If you have any suggestions or feature requests, please feel free to open an issue on GitHub.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for lancedb
Similar Open Source Tools
lancedb
LanceDB is an open-source database for vector-search built with persistent storage, which greatly simplifies retrieval, filtering, and management of embeddings. The key features of LanceDB include: Production-scale vector search with no servers to manage. Store, query, and filter vectors, metadata, and multi-modal data (text, images, videos, point clouds, and more). Support for vector similarity search, full-text search, and SQL. Native Python and Javascript/Typescript support. Zero-copy, automatic versioning, manage versions of your data without needing extra infrastructure. GPU support in building vector index(*). Ecosystem integrations with LangChain 🦜️🔗, LlamaIndex 🦙, Apache-Arrow, Pandas, Polars, DuckDB, and more on the way. LanceDB's core is written in Rust 🦀 and is built using Lance, an open-source columnar format designed for performant ML workloads.
chatbox
Chatbox is a desktop client for ChatGPT, Claude, and other LLMs, providing a user-friendly interface for AI copilot assistance on Windows, Mac, and Linux. It offers features like local data storage, multiple LLM provider support, image generation with Dall-E-3, enhanced prompting, keyboard shortcuts, and more. Users can collaborate, access the tool on various platforms, and enjoy multilingual support. Chatbox is constantly evolving with new features to enhance the user experience.
chatbox
Chatbox is a desktop client for ChatGPT, Claude, and other LLMs, providing features like local data storage, multiple LLM provider support, image generation, enhanced prompting, keyboard shortcuts, and more. It offers a user-friendly interface with dark theme, team collaboration, cross-platform availability, web version access, iOS & Android apps, multilingual support, and ongoing feature enhancements. Developed for prompt and API debugging, it has gained popularity for daily chatting and professional role-playing with AI assistance.
ComfyUI-Copilot
ComfyUI-Copilot is an intelligent assistant built on the Comfy-UI framework that simplifies and enhances the AI algorithm debugging and deployment process through natural language interactions. It offers intuitive node recommendations, workflow building aids, and model querying services to streamline development processes. With features like interactive Q&A bot, natural language node suggestions, smart workflow assistance, and model querying, ComfyUI-Copilot aims to lower the barriers to entry for beginners, boost development efficiency with AI-driven suggestions, and provide real-time assistance for developers.

LynxHub
LynxHub is a platform that allows users to seamlessly install, configure, launch, and manage all their AI interfaces from a single, intuitive dashboard. It offers features like AI interface management, arguments manager, custom run commands, pre-launch actions, extension management, in-app tools like terminal and web browser, AI information dashboard, Discord integration, and additional features like theme options and favorite interface pinning. The platform supports modular design for custom AI modules and upcoming extensions system for complete customization. LynxHub aims to streamline AI workflow and enhance user experience with a user-friendly interface and comprehensive functionalities.
MentraOS
MentraOS is an open source operating system designed for smart glasses. It simplifies the development of smart glasses apps by handling pairing, connection, data streaming, and cross-compatibility. Developers can create apps using the TypeScript SDK quickly and easily, with access to smart glasses I/O components like displays, microphones, cameras, and speakers. The platform emphasizes cross-compatibility, speed of app development, control over device features, and easy distribution to users. The MentraOS Community is dedicated to promoting open, cross-compatible, and user-controlled personal computing through the development and support of MentraOS.

promptfoo
Promptfoo is a tool for testing and evaluating LLM output quality. With promptfoo, you can build reliable prompts, models, and RAGs with benchmarks specific to your use-case, speed up evaluations with caching, concurrency, and live reloading, score outputs automatically by defining metrics, use as a CLI, library, or in CI/CD, and use OpenAI, Anthropic, Azure, Google, HuggingFace, open-source models like Llama, or integrate custom API providers for any LLM API.
codexia
Codexia is a powerful GUI and Toolkit for Codex CLI, offering features like fork chat, file-tree integration, notepad, git diff, built-in pdf/csv/xlsx viewer, and more. It provides multi-file format support, flexible configuration with multiple AI providers, professional UX with responsive UI, security features like sandbox execution modes, and prioritizes privacy. The tool supports interactive chat, code generation/editing, file operations with sandbox, command execution with approval, multiple AI providers, project-aware assistance, streaming responses, and built-in web search. The roadmap includes plans for MCP tool call, more file format support, better UI customization, plugin system, real-time collaboration, performance optimizations, and token count.
archestra
Archestra is an enterprise-grade platform that enables non-technical users to safely leverage AI agents and MCP servers. It provides a secure runtime environment for AI interactions with sandboxing, resource controls, and prompt injection prevention. The platform supports MCP Protocol and is designed with a local-first architecture, enterprise-level security, and extensible tool system.

univer
Univer is an isomorphic full-stack framework designed for creating and editing spreadsheets, documents, and slides across web and server. It is highly extensible, high-performance, and can be embedded into applications. Univer offers a wide range of features including formulas, conditional formatting, data validation, collaborative editing, printing, import & export, and more. It supports multiple languages and provides a distraction-free editing experience with a clean interface. Univer is suitable for data analysts, software developers, project managers, content creators, and educators.
memU
MemU is an open-source memory framework designed for AI companions, offering high accuracy, fast retrieval, and cost-effectiveness. It serves as an intelligent 'memory folder' that adapts to various AI companion scenarios. With MemU, users can create AI companions that remember them, learn their preferences, and evolve through interactions. The framework provides advanced retrieval strategies, 24/7 support, and is specialized for AI companions. MemU offers cloud, enterprise, and self-hosting options, with features like memory organization, interconnected knowledge graph, continuous self-improvement, and adaptive forgetting mechanism. It boasts high memory accuracy, fast retrieval, and low cost, making it suitable for building intelligent agents with persistent memory capabilities.
NotelyVoice
Notely Voice is a free, modern, cross-platform AI voice transcription and note-taking application. It offers powerful Whisper AI Voice to Text capabilities, making it ideal for students, professionals, doctors, researchers, and anyone in need of hands-free note-taking. The app features rich text editing, simple search, smart filtering, organization with folders and tags, advanced speech-to-text, offline capability, seamless integration, audio recording, theming, cross-platform support, and sharing functionality. It includes memory-efficient audio processing, chunking configuration, and utilizes OpenAI Whisper for speech recognition technology. Built with Kotlin, Compose Multiplatform, Coroutines, Android Architecture, ViewModel, Koin, Material 3, Whisper AI, and Native Compose Navigation, Notely follows Android Architecture principles with distinct layers for UI, presentation, domain, and data.
kserve
KServe provides a Kubernetes Custom Resource Definition for serving predictive and generative machine learning (ML) models. It encapsulates the complexity of autoscaling, networking, health checking, and server configuration to bring cutting edge serving features like GPU Autoscaling, Scale to Zero, and Canary Rollouts to ML deployments. KServe enables a simple, pluggable, and complete story for Production ML Serving including prediction, pre-processing, post-processing, and explainability. It is a standard, cloud agnostic Model Inference Platform for serving predictive and generative AI models on Kubernetes, built for highly scalable use cases.
db2rest
DB2Rest is a modern low code REST DATA API platform that enables the rapid development of intelligent applications by combining databases, language models, and vector stores. It facilitates context-aware, reasoning applications without vendor lock-in. The tool accelerates application delivery, fosters faster innovation with AI, serves as a secure database gateway, and simplifies integration. It supports various databases like PostgreSQL, MySQL, MS SQL Server, Oracle, MongoDB, and more, with planned support for additional databases. Users can connect on Discord for support and contact [email protected] for inquiries.
RisuAI
RisuAI, or Risu for short, is a cross-platform AI chatting software/web application with powerful features such as multiple API support, assets in the chat, regex functions, and much more.
panko-gpt
PankoGPT is an AI companion platform that allows users to easily create and deploy custom AI companions on messaging platforms like WhatsApp, Discord, and Telegram. Users can customize companion behavior, configure settings, and equip companions with various tools without the need for coding. The platform aims to provide contextual understanding and user-friendly interface for creating companions that respond based on context and offer configurable tools for enhanced capabilities. Planned features include expanded functionality, pre-built skills, and optimization for better performance.
For similar tasks
lancedb
LanceDB is an open-source database for vector-search built with persistent storage, which greatly simplifies retrieval, filtering, and management of embeddings. The key features of LanceDB include: Production-scale vector search with no servers to manage. Store, query, and filter vectors, metadata, and multi-modal data (text, images, videos, point clouds, and more). Support for vector similarity search, full-text search, and SQL. Native Python and Javascript/Typescript support. Zero-copy, automatic versioning, manage versions of your data without needing extra infrastructure. GPU support in building vector index(*). Ecosystem integrations with LangChain 🦜️🔗, LlamaIndex 🦙, Apache-Arrow, Pandas, Polars, DuckDB, and more on the way. LanceDB's core is written in Rust 🦀 and is built using Lance, an open-source columnar format designed for performant ML workloads.

deeplake
Deep Lake is a Database for AI powered by a storage format optimized for deep-learning applications. Deep Lake can be used for: 1. Storing data and vectors while building LLM applications 2. Managing datasets while training deep learning models Deep Lake simplifies the deployment of enterprise-grade LLM-based products by offering storage for all data types (embeddings, audio, text, videos, images, pdfs, annotations, etc.), querying and vector search, data streaming while training models at scale, data versioning and lineage, and integrations with popular tools such as LangChain, LlamaIndex, Weights & Biases, and many more. Deep Lake works with data of any size, it is serverless, and it enables you to store all of your data in your own cloud and in one place. Deep Lake is used by Intel, Bayer Radiology, Matterport, ZERO Systems, Red Cross, Yale, & Oxford.

nucliadb
NucliaDB is a robust database that allows storing and searching on unstructured data. It is an out of the box hybrid search database, utilizing vector, full text and graph indexes. NucliaDB is written in Rust and Python. We designed it to index large datasets and provide multi-teanant support. When utilizing NucliaDB with Nuclia cloud, you are able to the power of an NLP database without the hassle of data extraction, enrichment and inference. We do all the hard work for you.

pgvecto.rs
pgvecto.rs is a Postgres extension written in Rust that provides vector similarity search functions. It offers ultra-low-latency, high-precision vector search capabilities, including sparse vector search and full-text search. With complete SQL support, async indexing, and easy data management, it simplifies data handling. The extension supports various data types like FP16/INT8, binary vectors, and Matryoshka embeddings. It ensures system performance with production-ready features, high availability, and resource efficiency. Security and permissions are managed through easy access control. The tool allows users to create tables with vector columns, insert vector data, and calculate distances between vectors using different operators. It also supports half-precision floating-point numbers for better performance and memory usage optimization.

litegraph
LiteGraph is a property graph database designed for knowledge and artificial intelligence applications. It supports graph relationships, tags, labels, metadata, data, and vectors. LiteGraph can be used in-process with LiteGraphClient or as a standalone RESTful server with LiteGraph.Server. The latest version includes major internal refactor, batch APIs, enumeration APIs, statistics APIs, database caching, vector search enhancements, and bug fixes. LiteGraph allows for simple embedding into applications without user configuration. Users can create tenants, graphs, nodes, edges, and perform operations like finding routes and exporting to GEXF file. It also provides features for working with object labels, tags, data, and vectors, enabling filtering and searching based on various criteria. LiteGraph offers REST API deployment with LiteGraph.Server and Docker support with a Docker image available on Docker Hub.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.