
deeplake
Database for AI. Store Vectors, Images, Texts, Videos, etc. Use with LLMs/LangChain. Store, query, version, & visualize any AI data. Stream data in real-time to PyTorch/TensorFlow. https://activeloop.ai
Stars: 8804

Deep Lake is a Database for AI powered by a storage format optimized for deep-learning applications. Deep Lake can be used for: 1. Storing data and vectors while building LLM applications 2. Managing datasets while training deep learning models Deep Lake simplifies the deployment of enterprise-grade LLM-based products by offering storage for all data types (embeddings, audio, text, videos, images, pdfs, annotations, etc.), querying and vector search, data streaming while training models at scale, data versioning and lineage, and integrations with popular tools such as LangChain, LlamaIndex, Weights & Biases, and many more. Deep Lake works with data of any size, it is serverless, and it enables you to store all of your data in your own cloud and in one place. Deep Lake is used by Intel, Bayer Radiology, Matterport, ZERO Systems, Red Cross, Yale, & Oxford.
README:

Docs • Get Started • API Reference • LangChain & VectorDBs Course • Blog • Whitepaper • Slack • Twitter
Deep Lake is a Database for AI powered by a storage format optimized for deep-learning applications. Deep Lake can be used for:
- Storing and searching data plus vectors while building LLM applications
- Managing datasets while training deep learning models
Deep Lake simplifies the deployment of enterprise-grade LLM-based products by offering storage for all data types (embeddings, audio, text, videos, images, dicom, pdfs, annotations, and more), querying and vector search, data streaming while training models at scale, data versioning and lineage, and integrations with popular tools such as LangChain, LlamaIndex, Weights & Biases, and many more. Deep Lake works with data of any size, it is serverless, and it enables you to store all of your data in your own cloud and in one place. Deep Lake is used by Intel, Bayer Radiology, Matterport, ZERO Systems, Red Cross, Yale, & Oxford.
Multi-Cloud Support (S3, GCP, Azure)
Use one API to upload, download, and stream datasets to/from S3, Azure, GCP, Activeloop cloud, local storage, or in-memory storage. Compatible with any S3-compatible storage such as MinIO.Native Compression with Lazy NumPy-like Indexing
Store images, audio, and videos in their native compression. Slice, index, iterate, and interact with your data like a collection of NumPy arrays in your system's memory. Deep Lake lazily loads data only when needed, e.g., when training a model or running queries.Dataloaders for Popular Deep Learning Frameworks
Deep Lake comes with built-in dataloaders for Pytorch and TensorFlow. Train your model with a few lines of code - we even take care of dataset shuffling. :)Integrations with Powerful Tools
Deep Lake has integrations with Langchain and LLamaIndex as a vector store for LLM apps, Weights & Biases for data lineage during model training, MMDetection for training object detection models, and MMSegmentation for training semantic segmentation models.100+ most-popular image, video, and audio datasets available in seconds
Deep Lake community has uploaded 100+ image, video and audio datasets like MNIST, COCO, ImageNet, CIFAR, GTZAN and others.Instant Visualization Support in the Deep Lake App
Deep Lake datasets are instantly visualized with bounding boxes, masks, annotations, etc. in Deep Lake Visualizer (see below).
Deep Lake can be installed using pip:
pip install deeplakeTo access all of Deep Lake's features, please register in the Deep Lake App.
Using Deep Lake as a Vector Store for building LLM applications:
Using Deep Lake for managing data while training Deep Learning models:
Deep Lake offers integrations with other tools in order to streamline your deep learning workflows. Current integrations include:
-
LLM Apps
- Use Deep Lake as a vector store for LLM apps. Our integration combines the Langchain VectorStores API with Deep Lake datasets as the underlying data storage. The integration is a serverless vector store that can be deployed locally or in a cloud of your choice.
Getting started guides, examples, tutorials, API reference, and other useful information can be found on our documentation page.
Deep Lake users can access and visualize a variety of popular datasets through a free integration with Deep Lake's App. Universities can get up to 1TB of data storage and 100,000 monthly queries on the Tensor Database for free per month. Chat in on our website: to claim the access!
Deep Lake vs Chroma
Both Deep Lake & ChromaDB enable users to store and search vectors (embeddings) and offer integrations with LangChain and LlamaIndex. However, they are architecturally very different. ChromaDB is a Vector Database that can be deployed locally or on a server using Docker and will offer a hosted solution shortly. Deep Lake is a serverless Vector Store deployed on the user’s own cloud, locally, or in-memory. All computations run client-side, which enables users to support lightweight production apps in seconds. Unlike ChromaDB, Deep Lake’s data format can store raw data such as images, videos, and text, in addition to embeddings. ChromaDB is limited to light metadata on top of the embeddings and has no visualization. Deep Lake datasets can be visualized and version controlled. Deep Lake also has a performant dataloader for fine-tuning your Large Language Models.
Deep Lake vs Pinecone
Both Deep Lake and Pinecone enable users to store and search vectors (embeddings) and offer integrations with LangChain and LlamaIndex. However, they are architecturally very different. Pinecone is a fully-managed Vector Database that is optimized for highly demanding applications requiring a search for billions of vectors. Deep Lake is serverless. All computations run client-side, which enables users to get started in seconds. Unlike Pinecone, Deep Lake’s data format can store raw data such as images, videos, and text, in addition to embeddings. Deep Lake datasets can be visualized and version controlled. Pinecone is limited to light metadata on top of the embeddings and has no visualization. Deep Lake also has a performant dataloader for fine-tuning your Large Language Models.
Deep Lake vs Weaviate
Both Deep Lake and Weaviate enable users to store and search vectors (embeddings) and offer integrations with LangChain and LlamaIndex. However, they are architecturally very different. Weaviate is a Vector Database that can be deployed in a managed service or by the user via Kubernetes or Docker. Deep Lake is serverless. All computations run client-side, which enables users to support lightweight production apps in seconds. Unlike Weaviate, Deep Lake’s data format can store raw data such as images, videos, and text, in addition to embeddings. Deep Lake datasets can be visualized and version controlled. Weaviate is limited to light metadata on top of the embeddings and has no visualization. Deep Lake also has a performant dataloader for fine-tuning your Large Language Models.
Deep Lake vs DVC
Deep Lake and DVC offer dataset version control similar to git for data, but their methods for storing data differ significantly. Deep Lake converts and stores data as chunked compressed arrays, which enables rapid streaming to ML models, whereas DVC operates on top of data stored in less efficient traditional file structures. The Deep Lake format makes dataset versioning significantly easier compared to traditional file structures by DVC when datasets are composed of many files (i.e., many images). An additional distinction is that DVC primarily uses a command-line interface, whereas Deep Lake is a Python package. Lastly, Deep Lake offers an API to easily connect datasets to ML frameworks and other common ML tools and enables instant dataset visualization through Activeloop's visualization tool.
Deep Lake vs MosaicML MDS format
- Data Storage Format: Deep Lake operates on a columnar storage format, whereas MDS utilizes a row-wise storage approach. This fundamentally impacts how data is read, written, and organized in each system.
- Compression: Deep Lake offers a more flexible compression scheme, allowing control over both chunk-level and sample-level compression for each column or tensor. This feature eliminates the need for additional compressions like zstd, which would otherwise demand more CPU cycles for decompressing on top of formats like jpeg.
- Shuffling: MDS currently offers more advanced shuffling strategies.
- Version Control & Visualization Support: A notable feature of Deep Lake is its native version control and in-browser data visualization, a feature not present for MosaicML data format. This can provide significant advantages in managing, understanding, and tracking different versions of the data.
Deep Lake vs TensorFlow Datasets (TFDS)
Deep Lake and TFDS seamlessly connect popular datasets to ML frameworks. Deep Lake datasets are compatible with both PyTorch and TensorFlow, whereas TFDS are only compatible with TensorFlow. A key difference between Deep Lake and TFDS is that Deep Lake datasets are designed for streaming from the cloud, whereas TFDS must be downloaded locally prior to use. As a result, with Deep Lake, one can import datasets directly from TensorFlow Datasets and stream them either to PyTorch or TensorFlow. In addition to providing access to popular publicly available datasets, Deep Lake also offers powerful tools for creating custom datasets, storing them on a variety of cloud storage providers, and collaborating with others via simple API. TFDS is primarily focused on giving the public easy access to commonly available datasets, and management of custom datasets is not the primary focus. A full comparison article can be found here.
Deep Lake vs HuggingFace
Deep Lake and HuggingFace offer access to popular datasets, but Deep Lake primarily focuses on computer vision, whereas HuggingFace focuses on natural language processing. HuggingFace Transforms and other computational tools for NLP are not analogous to features offered by Deep Lake.Deep Lake vs WebDatasets
Deep Lake and WebDatasets both offer rapid data streaming across networks. They have nearly identical steaming speeds because the underlying network requests and data structures are very similar. However, Deep Lake offers superior random access and shuffling, its simple API is in python instead of command-line, and Deep Lake enables simple indexing and modification of the dataset without having to recreate it.Deep Lake vs Zarr
Deep Lake and Zarr both offer storage of data as chunked arrays. However, Deep Lake is primarily designed for returning data as arrays using a simple API, rather than actually storing raw arrays (even though that's also possible). Deep Lake stores data in use-case-optimized formats, such as jpeg or png for images, or mp4 for video, and the user treats the data as if it's an array, because Deep Lake handles all the data processing in between. Deep Lake offers more flexibility for storing arrays with dynamic shape (ragged tensors), and it provides several features that are not naively available in Zarr such as version control, data streaming, and connecting data to ML Frameworks.Join our Slack community to learn more about unstructured dataset management using Deep Lake and to get help from the Activeloop team and other users.
We'd love your feedback by completing our 3-minute survey.
As always, thanks to our amazing contributors!
Made with contributors-img.
Please read CONTRIBUTING.md to get started with making contributions to Deep Lake.
Using Deep Lake? Add a README badge to let everyone know:
[](https://github.com/activeloopai/deeplake)Dataset Licenses
Deep Lake users may have access to a variety of publicly available datasets. We do not host or distribute these datasets, vouch for their quality or fairness, or claim that you have a license to use the datasets. It is your responsibility to determine whether you have permission to use the datasets under their license.
If you're a dataset owner and do not want your dataset to be included in this library, please get in touch through a GitHub issue. Thank you for your contribution to the ML community!
If you use Deep Lake in your research, please cite Activeloop using:
@article{deeplake,
title = {Deep Lake: a Lakehouse for Deep Learning},
author = {Hambardzumyan, Sasun and Tuli, Abhinav and Ghukasyan, Levon and Rahman, Fariz and Topchyan, Hrant and Isayan, David and Harutyunyan, Mikayel and Hakobyan, Tatevik and Stranic, Ivo and Buniatyan, Davit},
url = {https://www.cidrdb.org/cidr2023/papers/p69-buniatyan.pdf},
booktitle={Proceedings of CIDR},
year = {2023},
}This technology was inspired by our research work at Princeton University. We would like to thank William Silversmith @SeungLab for his awesome cloud-volume tool.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for deeplake
Similar Open Source Tools
deeplake
Deep Lake is a Database for AI powered by a storage format optimized for deep-learning applications. Deep Lake can be used for: 1. Storing data and vectors while building LLM applications 2. Managing datasets while training deep learning models Deep Lake simplifies the deployment of enterprise-grade LLM-based products by offering storage for all data types (embeddings, audio, text, videos, images, pdfs, annotations, etc.), querying and vector search, data streaming while training models at scale, data versioning and lineage, and integrations with popular tools such as LangChain, LlamaIndex, Weights & Biases, and many more. Deep Lake works with data of any size, it is serverless, and it enables you to store all of your data in your own cloud and in one place. Deep Lake is used by Intel, Bayer Radiology, Matterport, ZERO Systems, Red Cross, Yale, & Oxford.

merlin
Merlin is a groundbreaking model capable of generating natural language responses intricately linked with object trajectories of multiple images. It excels in predicting and reasoning about future events based on initial observations, showcasing unprecedented capability in future prediction and reasoning. Merlin achieves state-of-the-art performance on the Future Reasoning Benchmark and multiple existing multimodal language models benchmarks, demonstrating powerful multi-modal general ability and foresight minds.
hopsworks
Hopsworks is a data platform for ML with a Python-centric Feature Store and MLOps capabilities. It provides collaboration for ML teams, offering a secure, governed platform for developing, managing, and sharing ML assets. Hopsworks supports project-based multi-tenancy, team collaboration, development tools for Data Science, and is available on any platform including managed cloud services and on-premise installations. The platform enables end-to-end responsibility from raw data to managed features and models, supports versioning, lineage, and provenance, and facilitates the complete MLOps life cycle.

nixtla
Nixtla is a production-ready generative pretrained transformer for time series forecasting and anomaly detection. It can accurately predict various domains such as retail, electricity, finance, and IoT with just a few lines of code. TimeGPT introduces a paradigm shift with its standout performance, efficiency, and simplicity, making it accessible even to users with minimal coding experience. The model is based on self-attention and is independently trained on a vast time series dataset to minimize forecasting error. It offers features like zero-shot inference, fine-tuning, API access, adding exogenous variables, multiple series forecasting, custom loss function, cross-validation, prediction intervals, and handling irregular timestamps.

llm-course
The LLM course is divided into three parts: 1. 🧩 **LLM Fundamentals** covers essential knowledge about mathematics, Python, and neural networks. 2. 🧑🔬 **The LLM Scientist** focuses on building the best possible LLMs using the latest techniques. 3. 👷 **The LLM Engineer** focuses on creating LLM-based applications and deploying them. For an interactive version of this course, I created two **LLM assistants** that will answer questions and test your knowledge in a personalized way: * 🤗 **HuggingChat Assistant**: Free version using Mixtral-8x7B. * 🤖 **ChatGPT Assistant**: Requires a premium account. ## 📝 Notebooks A list of notebooks and articles related to large language models. ### Tools | Notebook | Description | Notebook | |----------|-------------|----------| | 🧐 LLM AutoEval | Automatically evaluate your LLMs using RunPod |  | | 🥱 LazyMergekit | Easily merge models using MergeKit in one click. |  | | 🦎 LazyAxolotl | Fine-tune models in the cloud using Axolotl in one click. |  | | ⚡ AutoQuant | Quantize LLMs in GGUF, GPTQ, EXL2, AWQ, and HQQ formats in one click. |  | | 🌳 Model Family Tree | Visualize the family tree of merged models. |  | | 🚀 ZeroSpace | Automatically create a Gradio chat interface using a free ZeroGPU. |  |

ServerlessLLM
ServerlessLLM is a fast, affordable, and easy-to-use library designed for multi-LLM serving, optimized for environments with limited GPU resources. It supports loading various leading LLM inference libraries, achieving fast load times, and reducing model switching overhead. The library facilitates easy deployment via Ray Cluster and Kubernetes, integrates with the OpenAI Query API, and is actively maintained by contributors.
Sarvadnya
Sarvadnya is a repository focused on interfacing custom data using Large Language Models (LLMs) through Proof-of-Concepts (PoCs) like Retrieval Augmented Generation (RAG) and Fine-Tuning. It aims to enable domain adaptation for LLMs to answer on user-specific corpora. The repository also covers topics such as Indic-languages models, 3D World Simulations, Knowledge Graphs Generation, Signal Processing, Drones, UAV Image Processing, and Floor Plan Segmentation. It provides insights into building chatbots of various modalities, preparing videos, and creating content for different platforms like Medium, LinkedIn, and YouTube. The tech stacks involved range from enterprise solutions like Google Doc AI and Microsoft Azure Language AI Services to open-source tools like Langchain and HuggingFace.
suql
SUQL (Structured and Unstructured Query Language) is a tool that augments SQL with free text primitives for building chatbots that can interact with relational data sources containing both structured and unstructured information. It seamlessly integrates retrieval models, large language models (LLMs), and traditional SQL to provide a clean interface for hybrid data access. SUQL supports optimizations to minimize expensive LLM calls, scalability to large databases with PostgreSQL, and general SQL operations like JOINs and GROUP BYs.
llm-search
pyLLMSearch is an advanced RAG system that offers a convenient question-answering system with a simple YAML-based configuration. It enables interaction with multiple collections of local documents, with improvements in document parsing, hybrid search, chat history, deep linking, re-ranking, customizable embeddings, and more. The package is designed to work with custom Large Language Models (LLMs) from OpenAI or installed locally. It supports various document formats, incremental embedding updates, dense and sparse embeddings, multiple embedding models, 'Retrieve and Re-rank' strategy, HyDE (Hypothetical Document Embeddings), multi-querying, chat history, and interaction with embedded documents using different models. It also offers simple CLI and web interfaces, deep linking, offline response saving, and an experimental API.
langchain4j
LangChain for Java simplifies integrating Large Language Models (LLMs) into Java applications by offering unified APIs for various LLM providers and embedding stores. It provides a comprehensive toolbox with tools for prompt templating, chat memory management, function calling, and high-level patterns like Agents and RAG. The library supports 15+ popular LLM providers and 15+ embedding stores, offering numerous examples to help users quickly start building LLM-powered applications. LangChain4j is a fusion of ideas from various projects and actively incorporates new techniques and integrations to keep users up-to-date. The project is under active development, with core functionality already in place for users to start building LLM-powered apps.
azure-openai-samples
This repository provides resources to understand and utilize GPT (Generative Pre-trained Transformer) by Azure OpenAI. It includes sample solutions, use cases, and quick start guides. Users can explore various applications of GPT, such as chatbots, customer service, and content generation. The repository also offers Langchain, Semantic Kernel, and Prompt Flow samples, along with Serverless SQL GPT for natural language processing in Azure Synapse Analytics. The samples are based on GPT 3.5, with plans to update for GPT-4. Users are encouraged to contribute to keep the repository updated with the latest technologies and solutions.
kitops
KitOps is a CNCF open standards project for packaging, versioning, and securely sharing AI/ML projects. It provides a unified solution for packaging, versioning, and managing assets in security-conscious enterprises, governments, and cloud operators. KitOps elevates AI artifacts to first-class, governed assets through ModelKits, which are tamper-proof, signable, and compatible with major container registries. The tool simplifies collaboration between data scientists, developers, and SREs, ensuring reliable and repeatable workflows for both development and operations. KitOps supports packaging for various types of models, including large language models, computer vision models, multi-modal models, predictive models, and audio models. It also facilitates compliance with the EU AI Act by offering tamper-proof, signable, and auditable ModelKits.
miyagi
Project Miyagi showcases Microsoft's Copilot Stack in an envisioning workshop aimed at designing, developing, and deploying enterprise-grade intelligent apps. By exploring both generative and traditional ML use cases, Miyagi offers an experiential approach to developing AI-infused product experiences that enhance productivity and enable hyper-personalization. Additionally, the workshop introduces traditional software engineers to emerging design patterns in prompt engineering, such as chain-of-thought and retrieval-augmentation, as well as to techniques like vectorization for long-term memory, fine-tuning of OSS models, agent-like orchestration, and plugins or tools for augmenting and grounding LLMs.

SuperKnowa
SuperKnowa is a fast framework to build Enterprise RAG (Retriever Augmented Generation) Pipelines at Scale, powered by watsonx. It accelerates Enterprise Generative AI applications to get prod-ready solutions quickly on private data. The framework provides pluggable components for tackling various Generative AI use cases using Large Language Models (LLMs), allowing users to assemble building blocks to address challenges in AI-driven text generation. SuperKnowa is battle-tested from 1M to 200M private knowledge base & scaled to billions of retriever tokens.

oreilly-retrieval-augmented-gen-ai
This repository focuses on Retrieval-Augmented Generation (RAG) and Large Language Models (LLMs). It provides code and resources to augment LLMs with real-time data for dynamic, context-aware applications. The content covers topics such as semantic search, fine-tuning embeddings, building RAG chatbots, evaluating LLMs, and using knowledge graphs in RAG. Prerequisites include Python skills, knowledge of machine learning and LLMs, and introductory experience with NLP and AI models.
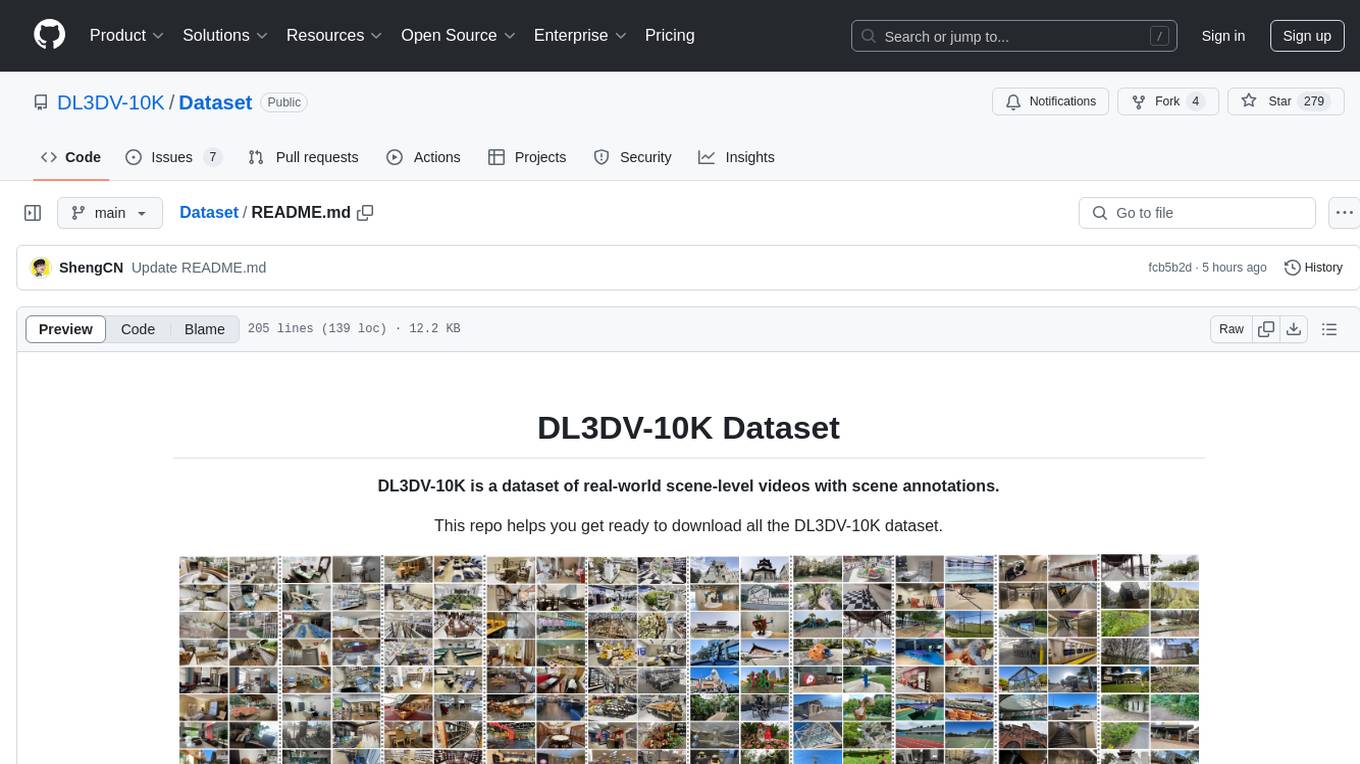
Dataset
DL3DV-10K is a large-scale dataset of real-world scene-level videos with annotations, covering diverse scenes with different levels of reflection, transparency, and lighting. It includes 10,510 multi-view scenes with 51.2 million frames at 4k resolution, and offers benchmark videos for novel view synthesis (NVS) methods. The dataset is designed to facilitate research in deep learning-based 3D vision and provides valuable insights for future research in NVS and 3D representation learning.
For similar tasks
deeplake
Deep Lake is a Database for AI powered by a storage format optimized for deep-learning applications. Deep Lake can be used for: 1. Storing data and vectors while building LLM applications 2. Managing datasets while training deep learning models Deep Lake simplifies the deployment of enterprise-grade LLM-based products by offering storage for all data types (embeddings, audio, text, videos, images, pdfs, annotations, etc.), querying and vector search, data streaming while training models at scale, data versioning and lineage, and integrations with popular tools such as LangChain, LlamaIndex, Weights & Biases, and many more. Deep Lake works with data of any size, it is serverless, and it enables you to store all of your data in your own cloud and in one place. Deep Lake is used by Intel, Bayer Radiology, Matterport, ZERO Systems, Red Cross, Yale, & Oxford.

python-aiplatform
The Vertex AI SDK for Python is a library that provides a convenient way to use the Vertex AI API. It offers a high-level interface for creating and managing Vertex AI resources, such as datasets, models, and endpoints. The SDK also provides support for training and deploying custom models, as well as using AutoML models. With the Vertex AI SDK for Python, you can quickly and easily build and deploy machine learning models on Vertex AI.

CSGHub
CSGHub is an open source, trustworthy large model asset management platform that can assist users in governing the assets involved in the lifecycle of LLM and LLM applications (datasets, model files, codes, etc). With CSGHub, users can perform operations on LLM assets, including uploading, downloading, storing, verifying, and distributing, through Web interface, Git command line, or natural language Chatbot. Meanwhile, the platform provides microservice submodules and standardized OpenAPIs, which could be easily integrated with users' own systems. CSGHub is committed to bringing users an asset management platform that is natively designed for large models and can be deployed On-Premise for fully offline operation. CSGHub offers functionalities similar to a privatized Huggingface(on-premise Huggingface), managing LLM assets in a manner akin to how OpenStack Glance manages virtual machine images, Harbor manages container images, and Sonatype Nexus manages artifacts.

fluid
Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It implements dataset abstraction, scalable cache runtime, automated data operations, elasticity and scheduling, and is runtime platform agnostic. Key concepts include Dataset and Runtime. Prerequisites include Kubernetes version > 1.16, Golang 1.18+, and Helm 3. The tool offers features like accelerating remote file accessing, machine learning, accelerating PVC, preloading dataset, and on-the-fly dataset cache scaling. Contributions are welcomed, and the project is under the Apache 2.0 license with a vendor-neutral approach.
awesome-object-detection-datasets
This repository is a curated list of awesome public object detection and recognition datasets. It includes a wide range of datasets related to object detection and recognition tasks, such as general detection and recognition datasets, autonomous driving datasets, adverse weather datasets, person detection datasets, anti-UAV datasets, optical aerial imagery datasets, low-light image datasets, infrared image datasets, SAR image datasets, multispectral image datasets, 3D object detection datasets, vehicle-to-everything field datasets, super-resolution field datasets, and face detection and recognition datasets. The repository also provides information on tools for data annotation, data augmentation, and data management related to object detection tasks.

aisheets
Hugging Face AI Sheets is an open-source tool for building, enriching, and transforming datasets using AI models with no code. It can be deployed locally or on the Hub, providing access to thousands of open models. Users can easily generate datasets, run data generation scripts, and customize inference endpoints for text generation. The tool supports custom LLMs and offers advanced configuration options for authentication, inference, and miscellaneous settings. With AI Sheets, users can leverage the power of AI models without writing any code, making dataset management and transformation efficient and accessible.

CosmosAIGraph
CosmosAIGraph is an AI-powered graph and RAG implementation of OmniRAG pattern, utilizing Azure Cosmos DB and other sources. It includes presentations, reference application documentation, FAQs, and a reference dataset of Python libraries pre-vectorized. The project focuses on Azure Cosmos DB for NoSQL and Apache Jena implementation for the in-memory RDF graph. It provides DockerHub images, with plans to add RBAC and Microsoft Entra ID/AAD authentication support, update AI model to gpt-4.5, and offer generic graph examples with a graph generation solution.
LMForge-End-to-End-LLMOps-Platform-for-Multi-Model-Agents
LMForge is an end-to-end LLMOps platform designed for multi-model agents. It provides a comprehensive solution for managing and deploying large language models efficiently. The platform offers tools for training, fine-tuning, and deploying various types of language models, enabling users to streamline the development and deployment process. With LMForge, users can easily experiment with different model architectures, optimize hyperparameters, and scale their models to meet specific requirements. The platform also includes features for monitoring model performance, managing datasets, and collaborating with team members, making it a versatile tool for researchers and developers working with language models.
For similar jobs

db2rest
DB2Rest is a modern low-code REST DATA API platform that simplifies the development of intelligent applications. It seamlessly integrates existing and new databases with language models (LMs/LLMs) and vector stores, enabling the rapid delivery of context-aware, reasoning applications without vendor lock-in.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

airflow
Apache Airflow (or simply Airflow) is a platform to programmatically author, schedule, and monitor workflows. When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative. Use Airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on DAGs a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.

airbyte-platform
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's low-code Connector Development Kit (CDK). Airbyte is used by data engineers and analysts at companies of all sizes to move data for a variety of purposes, including data warehousing, data analysis, and machine learning.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.