
LMForge-End-to-End-LLMOps-Platform-for-Multi-Model-Agents
AI Agent Development Platform - Supports multiple models (OpenAI/DeepSeek/Wenxin/Tongyi), knowledge base management, workflow automation, and enterprise-grade security. Built with Flask + Vue3 + LangChain, featuring one-click Docker deployment.
Stars: 175
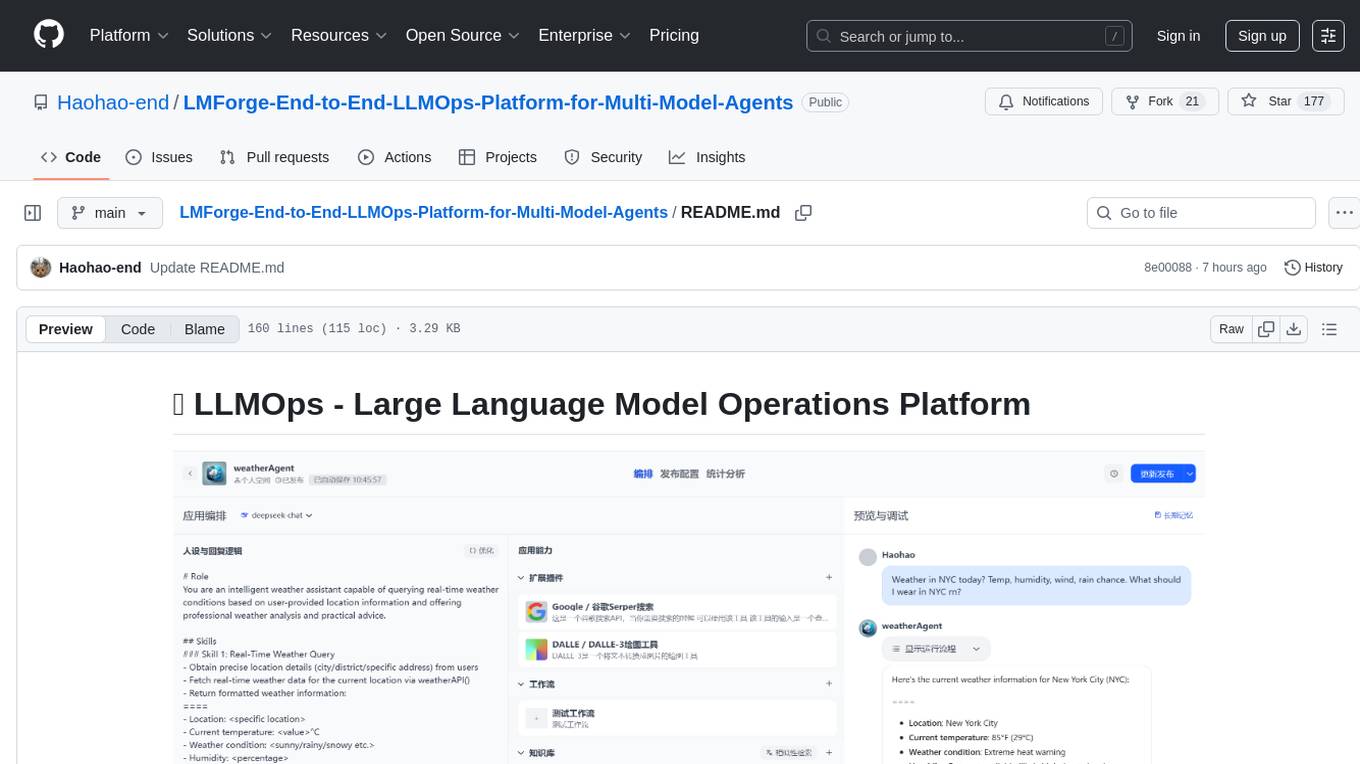
LMForge is an end-to-end LLMOps platform designed for multi-model agents. It provides a comprehensive solution for managing and deploying large language models efficiently. The platform offers tools for training, fine-tuning, and deploying various types of language models, enabling users to streamline the development and deployment process. With LMForge, users can easily experiment with different model architectures, optimize hyperparameters, and scale their models to meet specific requirements. The platform also includes features for monitoring model performance, managing datasets, and collaborating with team members, making it a versatile tool for researchers and developers working with language models.
README:
English | 中文
Online address: http://82.157.66.198/
Before deployment, you MUST configure:
-
Copy the environment template:
cp .env.example .env
-
Edit
.envwith your actual credentials:
# ===== REQUIRED =====
# PostgreSQL Database
SQLALCHEMY_DATABASE_URI=postgresql://postgres:your_strong_password@db:5432/llmops
# Redis Configuration
REDIS_PASSWORD=your_redis_password
# JWT Secret (Generate with: openssl rand -hex 32)
JWT_SECRET_KEY=your_jwt_secret_key_here
# ===== AI PROVIDERS =====
# Configure at least one LLM provider
MOONSHOT_API_KEY=sk-your-moonshot-key
DEEPSEEK_API_KEY=sk-your-deepseek-key
OPENAI_API_KEY=sk-your-openai-key
DASHSCOPE_API_KEY=sk-your-dashscope-key
# ===== OPTIONAL SERVICES =====
# Vector DB (Choose one)
PINECONE_API_KEY=your-pinecone-key
WEAVIATE_API_KEY=your-weaviate-key
# Third-party Services
GAODE_API_KEY=your-gaode-map-key
GITHUB_CLIENT_ID=your-github-oauth-id
GITHUB_CLIENT_SECRET=your-github-oauth-secret
- Docker 20.10+
- Docker Compose 2.0+
- Minimum 8GB RAM
# Clone repository
git clone https://github.com/Haohao-end/LMForge-End-to-End-LLMOps-Platform-for-Multi-Model-Agents.git
cd Open-Coze/docker
# Configure environment
nano .env # Fill with your actual credentials
# Launch services
docker compose up -d --build| Service | Access URL |
|---|---|
| Web UI | http://localhost:3000 |
| API Gateway | http://localhost:80 |
| Swagger Docs | http://localhost:80/docs |
Ensure persistence in docker-compose.yaml:
services:
db:
volumes:
- pg_data:/var/lib/postgresql/data
volumes:
pg_data:Comment unused providers in .env:
# Enable OpenAI
OPENAI_API_KEY=sk-xxx
# OPENAI_API_BASE=https://your-proxy.com/v1
# Disable Wenxin
# WENXIN_YIYAN_API_KEY=sk-xxx-
Always change default passwords in production
-
Enable CSRF protection:
WTF_CSRF_ENABLED=True WTF_CSRF_SECRET_KEY=your_csrf_secret
graph TD
A[Client] --> B[Nginx 80]
B --> C[Frontend Vue.js 3000]
B --> D[Backend Flask 5001]
D --> E[(PostgreSQL)]
D --> F[(Redis)]
D --> G[Celery Worker]
G --> H[AI Providers]Q: How to check service logs?
docker compose logs -fQ: How to update environment variables?
docker compose down
nano .env # Modify configurations
docker compose up -dQ: Port conflicts?
Modify port mappings in docker-compose.yaml:
ports:
- "8080:80" # Change host port to 8080MIT License | Copyright © 2025 Open-CozeTeam
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LMForge-End-to-End-LLMOps-Platform-for-Multi-Model-Agents
Similar Open Source Tools
LMForge-End-to-End-LLMOps-Platform-for-Multi-Model-Agents
LMForge is an end-to-end LLMOps platform designed for multi-model agents. It provides a comprehensive solution for managing and deploying large language models efficiently. The platform offers tools for training, fine-tuning, and deploying various types of language models, enabling users to streamline the development and deployment process. With LMForge, users can easily experiment with different model architectures, optimize hyperparameters, and scale their models to meet specific requirements. The platform also includes features for monitoring model performance, managing datasets, and collaborating with team members, making it a versatile tool for researchers and developers working with language models.

PaddleNLP
PaddleNLP is an easy-to-use and high-performance NLP library. It aggregates high-quality pre-trained models in the industry and provides out-of-the-box development experience, covering a model library for multiple NLP scenarios with industry practice examples to meet developers' flexible customization needs.

verl
veRL is a flexible and efficient reinforcement learning training framework designed for large language models (LLMs). It allows easy extension of diverse RL algorithms, seamless integration with existing LLM infrastructures, and flexible device mapping. The framework achieves state-of-the-art throughput and efficient actor model resharding with 3D-HybridEngine. It supports popular HuggingFace models and is suitable for users working with PyTorch FSDP, Megatron-LM, and vLLM backends.
agentscope
AgentScope is an agent-oriented programming tool for building LLM (Large Language Model) applications. It provides transparent development, realtime steering, agentic tools management, model agnostic programming, LEGO-style agent building, multi-agent support, and high customizability. The tool supports async invocation, reasoning models, streaming returns, async/sync tool functions, user interruption, group-wise tools management, streamable transport, stateful/stateless mode MCP client, distributed and parallel evaluation, multi-agent conversation management, and fine-grained MCP control. AgentScope Studio enables tracing and visualization of agent applications. The tool is highly customizable and encourages customization at various levels.

ml-engineering
This repository provides a comprehensive collection of methodologies, tools, and step-by-step instructions for successful training of large language models (LLMs) and multi-modal models. It is a technical resource suitable for LLM/VLM training engineers and operators, containing numerous scripts and copy-n-paste commands to facilitate quick problem-solving. The repository is an ongoing compilation of the author's experiences training BLOOM-176B and IDEFICS-80B models, and currently focuses on the development and training of Retrieval Augmented Generation (RAG) models at Contextual.AI. The content is organized into six parts: Insights, Hardware, Orchestration, Training, Development, and Miscellaneous. It includes key comparison tables for high-end accelerators and networks, as well as shortcuts to frequently needed tools and guides. The repository is open to contributions and discussions, and is licensed under Attribution-ShareAlike 4.0 International.
spec-workflow-mcp
Spec Workflow MCP is a Model Context Protocol (MCP) server that offers structured spec-driven development workflow tools for AI-assisted software development. It includes a real-time web dashboard and a VSCode extension for monitoring and managing project progress directly in the development environment. The tool supports sequential spec creation, real-time monitoring of specs and tasks, document management, archive system, task progress tracking, approval workflow, bug reporting, template system, and works on Windows, macOS, and Linux.
chinese-llm-benchmark
The Chinese LLM Benchmark is a continuous evaluation list of large models in CLiB, covering a wide range of commercial and open-source models from various companies and research institutions. It supports multidimensional evaluation of capabilities including classification, information extraction, reading comprehension, data analysis, Chinese encoding efficiency, and Chinese instruction compliance. The benchmark not only provides capability score rankings but also offers the original output results of all models for interested individuals to score and rank themselves.
Wave-executor
Wave Executor is an innovative Windows executor developed by SPDM Team and CodeX engineers, featuring cutting-edge technologies like AI, built-in script hub, HDWID spoofing, and enhanced scripting capabilities. It offers a 100% stealth mode Byfron bypass, advanced features like decompiler and save instance functionality, and a commercial edition with ad-free experience and direct download link. Wave Premium provides multi-instance, multi-inject, and 100% UNC support, making it a cost-effective option for executing scripts in popular Roblox games.

Fast-dLLM
Fast-DLLM is a diffusion-based Large Language Model (LLM) inference acceleration framework that supports efficient inference for models like Dream and LLaDA. It offers fast inference support, multiple optimization strategies, code generation, evaluation capabilities, and an interactive chat interface. Key features include Key-Value Cache for Block-Wise Decoding, Confidence-Aware Parallel Decoding, and overall performance improvements. The project structure includes directories for Dream and LLaDA model-related code, with installation and usage instructions provided for using the LLaDA and Dream models.
ktransformers
KTransformers is a flexible Python-centric framework designed to enhance the user's experience with advanced kernel optimizations and placement/parallelism strategies for Transformers. It provides a Transformers-compatible interface, RESTful APIs compliant with OpenAI and Ollama, and a simplified ChatGPT-like web UI. The framework aims to serve as a platform for experimenting with innovative LLM inference optimizations, focusing on local deployments constrained by limited resources and supporting heterogeneous computing opportunities like GPU/CPU offloading of quantized models.
youtu-graphrag
Youtu-GraphRAG is a vertically unified agentic paradigm that connects the entire framework based on graph schema, allowing seamless domain transfer with minimal intervention. It introduces key innovations like schema-guided hierarchical knowledge tree construction, dually-perceived community detection, agentic retrieval, advanced construction and reasoning capabilities, fair anonymous dataset 'AnonyRAG', and unified configuration management. The framework demonstrates robustness with lower token cost and higher accuracy compared to state-of-the-art methods, enabling enterprise-scale deployment with minimal manual intervention for new domains.
agentic
Agentic is a lightweight and flexible Python library for building multi-agent systems. It provides a simple and intuitive API for creating and managing agents, defining their behaviors, and simulating interactions in a multi-agent environment. With Agentic, users can easily design and implement complex agent-based models to study emergent behaviors, social dynamics, and decentralized decision-making processes. The library supports various agent architectures, communication protocols, and simulation scenarios, making it suitable for a wide range of research and educational applications in the fields of artificial intelligence, machine learning, social sciences, and robotics.
dagger
Dagger is an open-source runtime for composable workflows, ideal for systems requiring repeatability, modularity, observability, and cross-platform support. It features a reproducible execution engine, a universal type system, a powerful data layer, native SDKs for multiple languages, an open ecosystem, an interactive command-line environment, batteries-included observability, and seamless integration with various platforms and frameworks. It also offers LLM augmentation for connecting to LLM endpoints. Dagger is suitable for AI agents and CI/CD workflows.
OpenManus-RL
OpenManus-RL is an open-source initiative focused on enhancing reasoning and decision-making capabilities of large language models (LLMs) through advanced reinforcement learning (RL)-based agent tuning. The project explores novel algorithmic structures, diverse reasoning paradigms, sophisticated reward strategies, and extensive benchmark environments. It aims to push the boundaries of agent reasoning and tool integration by integrating insights from leading RL tuning frameworks and continuously updating progress in a dynamic, live-streaming fashion.
paiml-mcp-agent-toolkit
PAIML MCP Agent Toolkit (PMAT) is a zero-configuration AI context generation system with extreme quality enforcement and Toyota Way standards. It allows users to analyze any codebase instantly through CLI, MCP, or HTTP interfaces. The toolkit provides features such as technical debt analysis, advanced monitoring, metrics aggregation, performance profiling, bottleneck detection, alert system, multi-format export, storage flexibility, and more. It also offers AI-powered intelligence for smart recommendations, polyglot analysis, repository showcase, and integration points. PMAT enforces quality standards like complexity ≤20, zero SATD comments, test coverage >80%, no lint warnings, and synchronized documentation with commits. The toolkit follows Toyota Way development principles for iterative improvement, direct AST traversal, automated quality gates, and zero SATD policy.

ms-agent
MS-Agent is a lightweight framework designed to empower agents with autonomous exploration capabilities. It provides a flexible and extensible architecture for creating agents capable of tasks like code generation, data analysis, and tool calling with MCP support. The framework supports multi-agent interactions, deep research, code generation, and is lightweight and extensible for various applications.
For similar tasks

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

ray
Ray is a unified framework for scaling AI and Python applications. It consists of a core distributed runtime and a set of AI libraries for simplifying ML compute, including Data, Train, Tune, RLlib, and Serve. Ray runs on any machine, cluster, cloud provider, and Kubernetes, and features a growing ecosystem of community integrations. With Ray, you can seamlessly scale the same code from a laptop to a cluster, making it easy to meet the compute-intensive demands of modern ML workloads.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

djl
Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning. It is designed to be easy to get started with and simple to use for Java developers. DJL provides a native Java development experience and allows users to integrate machine learning and deep learning models with their Java applications. The framework is deep learning engine agnostic, enabling users to switch engines at any point for optimal performance. DJL's ergonomic API interface guides users with best practices to accomplish deep learning tasks, such as running inference and training neural networks.

mlflow
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
* `MLflow Tracking

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.

burn
Burn is a new comprehensive dynamic Deep Learning Framework built using Rust with extreme flexibility, compute efficiency and portability as its primary goals.

awsome-distributed-training
This repository contains reference architectures and test cases for distributed model training with Amazon SageMaker Hyperpod, AWS ParallelCluster, AWS Batch, and Amazon EKS. The test cases cover different types and sizes of models as well as different frameworks and parallel optimizations (Pytorch DDP/FSDP, MegatronLM, NemoMegatron...).
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.