
chinese-llm-benchmark
ReLE评测:中文AI大模型能力评测(持续更新):目前已囊括335个大模型,覆盖chatgpt、gpt-5.2、o4-mini、谷歌gemini-3-pro、Claude-4.5、文心ERNIE-X1.1、ERNIE-5.0-Thinking、qwen3-max、百川、讯飞星火、商汤senseChat等商用模型, 以及kimi-k2、ernie4.5、minimax-M2、deepseek-v3.2、qwen3-2507、llama4、智谱GLM-4.6、gemma3、mistral等开源大模型。不仅提供排行榜,也提供规模超200万的大模型缺陷库!方便广大社区研究分析、改进大模型。
Stars: 5531
The Chinese LLM Benchmark is a continuous evaluation list of large models in CLiB, covering a wide range of commercial and open-source models from various companies and research institutions. It supports multidimensional evaluation of capabilities including classification, information extraction, reading comprehension, data analysis, Chinese encoding efficiency, and Chinese instruction compliance. The benchmark not only provides capability score rankings but also offers the original output results of all models for interested individuals to score and rank themselves.
README:
- ReLE (Really Reliable Live Evaluation for LLM),原名CLiB
- 目前已囊括352个大模型,覆盖chatgpt、gpt-5.2、o4-mini、谷歌gemini-3-pro、Claude-4.6、文心ERNIE-X1.1、ERNIE-5.0、qwen3-max、qwen3-plus、百川、讯飞星火、商汤senseChat等商用模型, 以及step3.5-flash、kimi-k2.5、ernie4.5、MiniMax-M2.5、deepseek-v3.2、qwen3-2507、llama4、智谱GLM-5、GLM-4.7、LongCat、gemma3、mistral等开源大模型。
- 支持多维度能力评测,包括教育、医疗与心理健康、金融、法律与行政公务、推理与数学计算、语言与指令遵从、agent与工具调用等7个领域,以及细分的~300个维度(比如牙科、高中语文…)。详见我们的技术报告ReLE: A Scalable System and Structured Benchmark for Diagnosing Capability Anisotropy in Chinese LLMs 媒体报道(机器之心):全球304个中文大模型实测:没有“全能王者”,ReLE凭70%降本方案破解评估困局
- 不仅提供排行榜,也提供规模超200万的大模型缺陷库!方便广大社区研究分析、改进大模型。
- 为您的私有大模型提供免费评测服务,联系我们(非线智能 ReLE benchmark团队):加微信
- 🔄最近更新
- ⚓GitHub热门大模型评测项目
- 📝大模型基本信息
- 📊排行榜
- 🌐各项能力评分
- 为什么做榜单?
- 大模型选型及评测交流群
- Cite Us
- [2026/2/14] v5.8.14版本
- 新增大模型:Doubao-Seed-2.0-pro、Doubao-Seed-2.0-lite、Doubao-Seed-2.0-mini
- [2026/2/9] v5.8.13版本
- 新增大模型:claude-opus-4.6、GLM-5、MiniMax-M2.5、LongCat-Flash-Lite、MiMo-V2-Flash-0204、MiMo-V2-Flash-think-0204
- [2026/2/2] v5.8.12版本
- 新增大模型:step-3.5-flash
- [2026/1/27] v5.8.11版本
- 新增大模型:qwen3-max-2026-01-23、qwen3-max-think-2026-01-23(qwen3-max-2026-01-23开启思考模式)、Kimi-K2.5-Thinking
- [2026/1/22] v5.8.10版本
- 新增大模型:GLM-4.7-Flash、LongCat-Flash-Thinking-2601、ERNIE-5.0
- [2025/12/24] v5.8.9版本
- 新增大模型:qwen3-max-preview-think(qwen3-max-preview开启思考模式)
- [2025/12/23] v5.8.8版本
- 新增coding排行榜,暂不进入总分,详见coding排行榜
- 新增大模型:GLM-4.7、MiniMax-M2.1
- [2025/12/18] v5.8.7版本
- 新增大模型:gemini-3-flash-preview、doubao-seed-1-8-251215、MiMo-V2-Flash、MiMo-V2-Flash-think
- [2025/12/13] v5.8.6版本
- 新增大模型:gpt-5.2、gpt-5.2-high、gpt-5.2-medium、qwen-plus-2025-12-01、qwen-plus-think-2025-12-01
- 多模态评测新增:GLM-4.6V、GLM-4.6V-Flash
- [2025/12/6] v5.8.5版本
- 新增大模型:hunyuan-2.0-thinking-20251109、hunyuan-2.0-instruct-20251111、qwen3-next-80b-a3b-thinking、mistral-large-2512、 Ministral-3-14B-Instruct-2512、Ministral-3-8B-Instruct-2512、Ministral-3-3B-Instruct-2512
- [2025/12/3] v5.8.4版本
- 新增大模型:DeepSeek-V3.2、DeepSeek-V3.2-Think、qwen3-max-2025-09-23、gpt-5-mini-high、gpt-5-nano-high
- 更新Kimi-K2-Thinking评测结果
- [2025/11/3] v5.8版本,[2025/10/24] v5.7版本,[2025/10/13] v5.6版本,[2025/9/30] v5.5版本,[2025/9/22] v5.4版本,[2025/9/14] v5.3版本,[2025/9/10] v5.2版本,[2025/9/6] v5.1版本,[2025/9/1] v5.0版本,[2025/8/26]v4.13版本,[2025/8/20]v4.12版本,[2025/8/15]v4.11版本,[2025/8/10]v4.10版本,[2025/8/7]v4.9版本,[2025/8/1]v4.8版本,[2025/7/29]v4.7版本,[2025/7/26]v4.6版本,[2025/7/23]v4.5版本,[2025/7/17]v4.4版本,[2025/7/13]v4.3版本,[2025/7/12]v4.2版本,[2025/7/9]v4.1版本,[2025/7/2]v4.0版本,[2025/6/23]v3.33版本,[2025/6/18]v3.32版本,[2025/6/16]v3.31版本,[2025/6/13]v3.30版本,[2025/6/9]v3.29版本,[2025/6/4]v3.28版本,[2025/5/29]v3.27版本,[2025/5/23]v3.26版本,[2025/5/18]v3.25版本,[2025/5/15]v3.24版本,[2025/5/10]v3.23版本,[2025/5/5]v3.22版本,[2025/5/2]v3.21版本,[2025/4/30]v3.20版本,[2025/4/28]v3.19版本,[2025/4/22]v3.18版本,[2025/4/17]v3.17版本,[2025/4/9]v3.16版本,[2025/4/5]v3.15版本,[2025/4/3]v3.14版本,[2025/3/31]v3.13版本,[2025/3/29]v3.12版本,[2025/3/27]v3.11版本,[2025/3/25]v3.10版本,[2025/3/23]v3.9版本,[2025/3/21]v3.8版本,[2025/3/19]v3.7版本,[2025/3/17]v3.6版本,[2025/3/15]v3.5版本,[2025/3/13]v3.4版本,[2025/3/11]v3.3版本,[2025/3/10]v3.2版本,[2025/3/7]v3.1版本,[2025/3/4]v3.0版本,[2025/3/3]v2.22版本,[2025/2/28]v2.21版本,[2025/2/24]v2.20版本,[2025/2/22]v2.19版本,[2025/2/18]v2.18版本,[2025/2/14]v2.17版本,[2025/2/13]v2.16版本,[2025/2/12]v2.15版本,[2025/2/10]v2.14版本,[2025/1/29]v2.13版本,[2025/1/25]v2.12版本,[2025/1/23]v2.11版本,[2025/1/22]v2.10版本,[2025/1/20]v2.9版本,[2025/1/17]v2.8版本,[2025/1/7]v2.7版本
- 2024年:[2024/12/28]v2.6版本,[2024/12/27]v2.5版本,[2024/12/25]v2.4版本, [2024/10/20]v2.3版本,[2024/9/29]v2.2版本,[2024/8/27]v2.1版本,[2024/8/7]v2.0版本,[2024/7/26]v1.21版本,[2024/7/15]v1.20版本,[2024/6/29]v1.19版本,[2024/6/2]v1.18版本,[2024/5/8]v1.17版本,[2024/4/13]v1.16版本,[2024/3/20]v1.15版本,[2024/2/28]v1.14版本,[2024/1/29]v1.13版本
- 2023年:[2023/12/10]v1.12版本,[2023/11/22]v1.11版本,[2023/11/5]v1.10版本,[2023/10/11]v1.9版本,[2023/9/13]v1.8版本,[2023/8/29]v1.7版本,[2023/8/13]v1.6版本,[2023/7/26]v1.5版本, [2023/7/18]v1.4版本, [2023/7/2]v1.3版本, [2023/6/17]v1.2版, [2023/6/10]v1.1版本, [2023/6/4]v1版本
各版本更新详情:CHANGELOG
| repo | star | area | about |
|---|---|---|---|
| langfuse | 20.5k | 国外 | Open source LLM engineering platform: LLM Observability, metrics, evals, prompt management, playground, datasets. Integrates with OpenTelemetry, Langchain, OpenAI SDK, LiteLLM, and more. 🍊YC W23 |
| opik | 17.3k | 国外 | Debug, evaluate, and monitor your LLM applications, RAG systems, and agentic workflows with comprehensive tracing, automated evaluations, and production-ready dashboards. |
| deepeval | 13.0k | 国外 | The LLM Evaluation Framework |
| …… | …… | …… | …… |
| ⭐chinese-llm-benchmark(我们) | 5.4k | 国内 | ReLE中文大模型能力评测(持续更新) |
| …… | …… | …… | …… |
详见hot50
隆重推出 一站式 AI 模型超市 🛒,提供当下最全的大模型,让您永远快人一步。
- 🌐 全球模型,一网打尽:GPT-5.1、Gemini-3-Pro、Claude-4.5、DeepSeek-v3.2、Kimi-k2……
- ⚖️ 智能负载与高并发:我们聚合了多家顶级供应商,通过智能路由实现自动负载均衡。您从此可以告别烦人的 Rate Limit 报错,轻松应对任何流量洪峰!
- 🔀 自动故障切换:单一供应商的 API 临时“抽风”?没关系!我们的系统会毫秒级无感切换到健康的备用渠道,确保您的服务 99.9999% 高可用,让您的用户远离“服务不可用”的尴尬。
- 🛡️在线监控与智能选型:无缝衔接在线效果监测工具,打通模型选型评测闭环。用真实数据说话,助您轻松找到性能最佳、性价比最高的模型方案。 如何接入在线效果监测,如何接入模型选型评测
- 💰 限时9折,超高性价比!☛查看所有模型及价格
from openai import OpenAI
base_url = "https://api.nonelinear.com/v1"
api_key = "<your api key>" # 获取https://nonelinear.com/static/apikey.html
client = OpenAI(api_key=api_key, base_url=base_url)
client.chat.completions.create(
model="<model id>", # 模型列表https://nonelinear.com/static/models.html
messages=[{"role": "user", "content": "<your prompt>"}],
)
拒绝“盲选”大模型🎉!上传你的【专属测试数据】📊,5分钟🔍测出哪个模型在你的场景下效果最好🏆、最划算💰!选择最合适模型,成本或降90%💥!去体验>>

示例:
详细数据见多模态评测
“综合能力”计分方式:“综合能力”改为“专业能力”和“通用能力”的加权分,权重分别为0.3,0.7;其中“专业能力”为“教育”、“医疗与心理健康”、“金融”、“法律与行政公务”4大领域平均分,“通用能力”为“推理与数学计算”、“语言与指令遵从”、“agent与工具调用”3大领域平均分。

| 类别 | 机构 | 大模型 | 【总分】准确率 | 平均耗时 | 平均消耗token | 花费/千次(元) | 排名(准确率) |
|---|---|---|---|---|---|---|---|
| 商用 | 豆包 | Doubao-Seed-2.0-pro(new) | 76.5% | 309s | 1643 | 22.5 | 1 |
| 商用 | 豆包 | Doubao-Seed-2.0-lite(new) | 73.9% | 276s | 1761 | 5.4 | 2 |
详细数据见:综合能力排行榜 | 通用能力排行榜 | 专业能力排行榜
输出价格5元及以上商用大模型 | 输出价格1~5元商用大模型 | 输出价格1元以下商用大模型
DIY自定义维度筛选榜单:☛ link
5B以下开源大模型 | 5B~20B开源大模型 | 20B以上开源大模型
DIY自定义维度筛选榜单:☛link
☛☛完整排行榜见教育
☛☛完整排行榜见小学学科。
语文:排行榜|badcase,
英语:排行榜|badcase,
数学:排行榜|badcase,
道德与法治:排行榜|badcase,
科学:排行榜|badcase
☛☛完整排行榜见初中学科。
生物:排行榜|badcase,
化学:排行榜|badcase,
语文:排行榜|badcase,
英语:排行榜|badcase,
地理:排行榜|badcase,
历史:排行榜|badcase,
数学:排行榜|badcase,
物理:排行榜|badcase,
政治:排行榜|badcase
☛☛完整排行榜见高中学科。
生物:排行榜|badcase,
化学:排行榜|badcase,
语文:排行榜|badcase,
英语:排行榜|badcase,
地理:排行榜|badcase,
历史:排行榜|badcase,
数学:排行榜|badcase,
物理:排行榜|badcase,
政治:排行榜|badcase
历年高考真题,含简单题、填空题、选择题等等,只保留客观题。所有分数均为准确率,全部答对为100%;比如数学100,表示全部答对。☛☛完整排行榜见高考。
(1)2025年高考
生物:排行榜|badcase,
化学:排行榜|badcase,
语文:排行榜|badcase,
英语:排行榜|badcase,
地理:排行榜|badcase,
历史:排行榜|badcase,
数学:排行榜|badcase,
物理:排行榜|badcase,
政治:排行榜|badcase。
(2)2024年及之前高考
生物:排行榜|badcase,
化学:排行榜|badcase,
语文:排行榜|badcase,
地理:排行榜|badcase,
历史:排行榜|badcase,
数学:排行榜|badcase,
物理:排行榜|badcase,
政治:排行榜|badcase。
☛☛完整排行榜见医疗与心理健康
☛☛完整排行榜见医师
(1)内科,排行榜
内科规培结业:badcase,
中医内科主治医师:badcase,
内科主治医师:badcase,
心血管内科与呼吸内科主治医师:badcase,
肾内科主治医师:badcase,
消化内科主治医师:badcase,
中西医结合内科主治医师:badcase,
消化内科高级职称:badcase,
普通内科高级职称:badcase,
呼吸内科高级职称:badcase,
心内科高级职称:badcase,
结核病主治医师:badcase,
内分泌科高级职称:badcase
(2)外科,排行榜
外科规培结业:badcase,
口腔颌面外科主治医师:badcase,
整形外科主治医师:badcase,
外科主治医师:badcase,
普通外科高级职称:badcase,
骨科规培结业:badcase,
骨科中级职称:badcase,
骨科高级职称:badcase
(3)妇产科,排行榜
妇产科规培结业:badcase,
妇产科主治医师:badcase,
妇产科学副主任、主任医师职称考试:badcase
(4)儿科,排行榜
儿科规培结业:badcase,
儿科主治医师:badcase,
小儿外科规培结业:badcase
(5)眼科,排行榜
眼科规培结业:badcase,
眼科主治医师:badcase
(6)口腔科,排行榜
口腔科规培结业:badcase,
口腔执业助理医师:badcase,
口腔执业医师:badcase,
口腔内科主治医师:badcase,
口腔科主治医师:badcase,
口腔修复科主治医师:badcase,
口腔正畸学主治医师:badcase
(7)耳鼻咽喉科,排行榜
耳鼻咽喉科规培结业:badcase,
耳鼻咽喉科主治医师:badcase
(8)脑系科,排行榜
神经内科规培结业:badcase,
神经内科主治医师:badcase,
精神科规培结业:badcase,
精神病学主治医师:badcase,
心理治疗学主治医师:badcase,
心理咨询师:badcase
(9)皮肤科,排行榜
皮肤科规培结业:badcase,
皮肤科中级职称:badcase,
皮肤与性病学主治医师:badcase
(10)中医与中西医结合,排行榜
中西医结合执业助理医师:badcase,
中医执业助理医师:badcase,
中西医结合执业医师:badcase,
中医执业医师:badcase,
中医针灸主治医师:badcase
(11)康复医学科,排行榜
康复医学科规培结业:badcase,
康复医学主治医师:badcase
(12)全科医学科,排行榜
全科医学科规培结业:badcase,
全科主治医师:badcase
(13)临床营养与重症医学,排行榜
临床执业助理医师:badcase,
临床执业医师:badcase,
风湿与临床免疫主治医师:badcase,
重症医学主治医师:badcase,
营养学主治医师:badcase,
临床病理科规培结业:badcase
(15)麻醉疼痛科,排行榜
麻醉科规培结业:badcase,
麻醉科主治医师:badcase,
疼痛科主治医师:badcase
(16)公共卫生与职业病,排行榜
公共卫生执业助理医师:badcase,
公共卫生执业医师:badcase,
医院感染中级职称:badcase,
传染病主治医师:badcase,
预防医学主治医师:badcase,
传染病学中级职称:badcase,
职业病主治医师:badcase
☛☛完整排行榜见护理
护士执业资格考试:排行榜|badcase,
护师资格考试:排行榜|badcase,
儿科主管护师:排行榜|badcase,
内科护理学:排行榜|badcase,
妇产科护理学:排行榜|badcase,
妇产科主管护师:排行榜|badcase,
外科主管护师:排行榜|badcase,
主管护师资格考试:排行榜|badcase,
内科主管护师:排行榜|badcase,
副主任、主任护师资格考试:排行榜|badcase
☛☛完整排行榜见药师
执业西药师:排行榜|badcase,
执业中药师:排行榜|badcase,
药士初级考试:排行榜|badcase,
药师初级考试:排行榜|badcase,
中药学(士):排行榜|badcase,
中药学(师):排行榜|badcase,
主管药师资格考试:排行榜|badcase,
主管中药师:排行榜|badcase
☛☛完整排行榜见医技
超声科:排行榜|badcase,
超声波医学主治医师:排行榜|badcase,
超声波医学主管技师:排行榜|badcase,
心电学主管技师:排行榜|badcase,
医学影像科:排行榜|badcase,
核医学主治医师:排行榜|badcase,
核医学主管技师:排行榜|badcase,
放射科主治医师:排行榜|badcase,
放射学技术(士):排行榜|badcase,
放射学技术(师):排行榜|badcase,
放射医学主管技师:排行榜|badcase ,
检验技术(士):排行榜|badcase,
检验技术(师):排行榜|badcase,
微生物检验主管技师:排行榜|badcase,
理化检验主管技师:排行榜|badcase,
临床医学检验主管技师:排行榜|badcase,
病理科主治医师:排行榜|badcase,
病理学主管技师:排行榜|badcase,
病理学技术:排行榜|badcase,
康复医学治疗技术(士):排行榜|badcase,
康复医学治疗技术(师):排行榜|badcase,
康复医学与治疗主管技师:排行榜|badcase,
肿瘤学技术(士):排行榜|badcase,
肿瘤学技术(师):排行榜|badcase,
肿瘤放射治疗主管技师:排行榜|badcase,
输血技术主管技师:排行榜|badcase,
消毒技术主管技师:排行榜|badcase,
病案信息主管技师:排行榜|badcase
(1)基础医学,排行榜
医学三基:badcase,
医学心理学:badcase,
生物化学与分子生物学:badcase,
细胞生物学:badcase,
医学免疫学:badcase,
免疫学:badcase,
病理生理学:badcase,
病理学:badcase,
医学遗传学:badcase,
寄生虫学:badcase,
人体寄生虫学:badcase,
系统解剖学:badcase,
解剖学:badcase,
局部解剖学:badcase,
生物信息学:badcase,
生理学:badcase,
药理学:badcase,
药物分析学:badcase,
医学微生物学:badcase,
组织学与胚胎学:badcase,
医学统计学:badcase
(2)临床医学,排行榜
临床医学:badcase,
医学影像学:badcase,
放射学:badcase,
实验诊断学:badcase,
神经病学:badcase,
外科学:badcase,
皮肤性病学:badcase,
儿科学:badcase,
核医学:badcase,
物理诊断学:badcase,
牙体牙髓病学:badcase,
护理学基础:badcase,
护理学:badcase,
基础护理学:badcase,
诊断学:badcase,
超声医学:badcase,
口腔护理学:badcase,
循证医学:badcase,
流行病学:badcase,
口腔组织病理学:badcase,
传染病学:badcase,
口腔解剖生理学:badcase,
麻醉学:badcase,
介入放射学:badcase
(3)预防医学与公共卫生学,排行榜
预防医学:badcase,
卫生学:badcase,
医学伦理学:badcase
(4)中医学与中药学,排行榜
中医眼科学:badcase,
金匮要略讲义:badcase,
中医基础理论:badcase,
中医诊断学:badcase,
中医学:badcase,
温病学:badcase,
中国医学史:badcase,
中医内科学:badcase,
中医儿科学:badcase,
伤寒论:badcase,
内经讲义:badcase
医学考研,包含外科护理学、基础护理学、西医综合等5个方向,参考CMB。☛☛完整排行榜见医学考研。
(1)外科护理学:排行榜|badcase,
(2)基础护理学:排行榜|badcase,
(3)考研政治:排行榜|badcase,
(4)西医综合:排行榜|badcase,
(5)中医综合:排行榜|badcase
目前包含4个子项:心理综合,心理治疗学主治医师,心理咨询师,医学心理学。☛☛完整排行榜见心理健康。
(1)心理综合:排行榜|badcase,
(2)心理治疗学主治医师:排行榜|badcase,
(3)心理咨询师:排行榜|badcase,
(4)医学心理学:排行榜|badcase
☛☛完整排行榜见金融
☛☛完整排行榜见财务。
初级会计职称:排行榜|badcase,
注册会计师:排行榜|badcase,
会计从业资格:排行榜|badcase,
审计师考试:排行榜|badcase,
注册税务师:排行榜|badcase,
注册管理会计师:排行榜|badcase
☛☛完整排行榜见银行。
银行初级资格:排行榜|badcase,
银从中级资格:排行榜|badcase,
银行从业资格:排行榜|badcase
☛☛完整排行榜见保险。
保险从业资格:排行榜|badcase
☛☛完整排行榜见证券。
证券专项考试:排行榜|badcase,
证券从业资格:排行榜|badcase
☛☛完整排行榜见其他金融资格考试。
初级经济师:排行榜|badcase,
中级经济师:排行榜|badcase,
反假货币知识:排行榜|badcase,
期货从业资格:排行榜|badcase,
金融理财师AFP:排行榜|badcase,
基金从业资格:排行榜|badcase,
黄金从业资格:排行榜|badcase,
中国精算师:排行榜|badcase
☛☛完整排行榜见金融基础知识。
金融学:badcase,
公司战略与风险管理:badcase,
宏观经济学:badcase,
金融市场学:badcase,
会计学:badcase,
成本会计学:badcase,
货币金融学:badcase,
政治经济学:badcase,
投资学:badcase,
计量经济学:badcase,
公司金融学:badcase,
财政学:badcase,
商业银行金融学:badcase,
管理会计学:badcase,
中央银行学:badcase,
审计学:badcase,
国际经济学:badcase,
中级财务会计:badcase,
财务管理学:badcase,
微观经济学:badcase,
国际金融学:badcase,
金融工程学:badcase,
经济法:badcase,
高级财务会计:badcase,
保险学:badcase
☛☛完整排行榜见金融应用。
保险知识解读:badcase,
金融术语解释:badcase,
执业医师资格考试:badcase,
理财知识解读:badcase,
执业药师资格考试:badcase,
金融文档抽取:badcase,
研判观点提取:badcase,
金融情绪识别:badcase,
保险槽位识别:badcase,
保险意图理解:badcase,
金融意图理解:badcase,
保险属性抽取:badcase,
保险条款解读:badcase,
金融产品分析:badcase,
金融数值计算:badcase,
金融事件解读:badcase,
内容生成-投教话术生成:badcase,
内容生成-文本总结归纳:badcase,
内容生成-营销文案生成:badcase,
内容生成-资讯标题生成:badcase,
安全合规-金融合规性:badcase,
安全合规-金融问题识别:badcase,
安全合规-信息安全合规:badcase,
安全合规-金融事实性:badcase
☛☛完整排行榜见法律与行政公务
选择题,共1000道,参考AGIEval。
完整排行榜见JEC-QA-KD,☛查看JEC-QA-KD:badcase
选择题,共1000道,参考AGIEval。
完整排行榜见JEC-QA-CA,☛查看JEC-QA-CA:badcase
完整排行榜见法律综合,☛查看法律综合:badcase
公务员考试行测选择题,共651道,参考AGIEval。 评测样本举例:
某乡镇进行新区规划,决定以市民公园为中心,在东南西北分别建设一个特色社区。这四个社区分别定为,文化区、休闲区、商业区和行政服务区。已知行政服务区在文化区的西南方向,文化区在休闲区的东南方向。
根据以上陈述,可以得出以下哪项?
(A)市民公园在行政服务区的北面 (B)休闲区在文化区的西南 (C)文化区在商业区的东北 (D)商业区在休闲区的东南
完整排行榜见公务员考试
☛查看公务员考试:badcase
☛☛完整排行榜见推理与数学计算
演绎推理(modus_tollens)选择题,共123道,参考ISP。
评测样本举例:
考虑以下语句:
1.如果约翰是个好父母,那么约翰就是严格但公平的。2.约翰不严格但公平。 结论:因此,约翰不是一个好父母。 问题:根据陈述1.和2.,结论是否正确?
回答: (A) 否 (B) 是
完整排行榜见演绎推理
☛查看演绎推理:badcase
常识推理选择题,共99道,参考ISP。
评测样本举例:
以下是关于常识的选择题。
问题:当某人把土豆放到篝火边的余烬中,此时余烬并没有在
A、释放热量 B、吸收热量
完整排行榜见常识推理
☛查看常识推理:badcase
学术界最常用的符号推理评测集,包含23个子任务,详细介绍见BBH。 评测样本举例:
Task description: Answer questions about which times certain events could have occurred.
Q: Today, Emily went to the museum. Between what times could they have gone?
We know that:
Emily woke up at 1pm.
Elizabeth saw Emily reading at the library from 2pm to 4pm.
Jessica saw Emily watching a movie at the theater from 4pm to 5pm.
Leslie saw Emily waiting at the airport from 5pm to 6pm.
William saw Emily buying clothes at the mall from 6pm to 7pm.
The museum was closed after 7pm.
Between what times could Emily have gone to the museum?
Options:
(A) 1pm to 2pm (B) 6pm to 7pm (C) 5pm to 6pm (D) 2pm to 4pm
A:
完整排行榜见BBH
☛查看BBH符号推理:badcase
考查大模型的数学基础能力之算数能力,测试题目为1000以内的整数加减法、不超过2位有效数字的浮点数加减乘除。 举例:166 + 215 + 53 = ?,0.97 + 0.4 / 4.51 = ?
完整排行榜见算术能力
☛查看算术能力:badcase
专门考查大模型对表格的理解分析能力,常用于数据分析。
评测样本举例:
姓名,年龄,性别,国籍,身高(cm),体重(kg),学历
张三,28,男,中国,180,70,本科
Lisa,33,女,美国,165,58,硕士
Paulo,41,男,巴西,175,80,博士
Miyuki,25,女,日本,160,50,大专
Ahmed,30,男,埃及,175,68,本科
Maria,29,女,墨西哥,170,65,硕士
Antonio,36,男,西班牙,182,75,博士
基于这个表格回答:学历最低的是哪国人?
完整排行榜见表格问答
☛查看表格问答:badcase
专门考查大模型对表格的分析总结能力,常用于数据分析、文章撰写,没有固定的标准答案,但容易相对客观地分辨好坏。 评测样本举例(由于例子过长,部分数据予以省略):
类别 机构 大模型 准确率 平均耗时 平均消耗token 花费/千次(元) 排名(准确率) 商用 豆包 doubao-seed-1-6-thinking-250715 87.5 37s 1976 14.6 1 商用 百度 ERNIE-4.5-Turbo-32K 84.7 33s 676 1.8 2 商用 腾讯 hunyuan-t1-20250711 84.7 37s 2465 9.2 3 商用 腾讯 hunyuan-turbos-20250716 83.9 24s 1288 2.3 4 …… …… …… …… …… …… …… ……
已知新模型为:GLM-4.5,GLM-4.5-Air,GLM-4.5-Flash,step-3。
基于以上表格写一段总结,格式为:“xx机构、xx机构……占据前5(机构名不要重复),然后描述开源模型和商用模型的分布。新模型中,xx排第xx,xx排第xx……(排名由高到低)”。严格按照表格中的模型名称、机构名称。
完整排行榜见表格总结
☛查看表格总结:badcase
2024年预赛试题,参考Math24o。 评测样本举例:
设集合 $S={1, 2, 3, \cdots, 9 9 7, 9 9 8 }$,集合 $S$ 的 $k$ 个 $499$ 元子集 $A_{1},A_{2}, \cdots, A_{k}$ 满足:对 $S$ 中任一二元子集 $B$,均存在 $i \in{1, 2, \cdots, k }$,使得 $B \subset A_{i}$。求 $k$ 的最小值。
完整排行榜见高中奥林匹克数学竞赛
☛查看高中奥林匹克数学竞赛:badcase
完整排行榜见小学奥数
☛查看小学奥数:badcase
完整排行榜见数独
☛查看数独:badcase
☛☛完整排行榜见语言与指令遵从
给定上下文,选择最匹配的成语。
评测样本举例:
说完作品的优点,咱们再来聊聊为何说它最后的结局____,片子本身提出的话题观点很尖锐,“扶弟魔”也成为众多当代年轻人婚姻里的不定因素,所以对于这种过于敏感的东西,片子的结局仅仅只是以弟弟的可爱化解了姐姐的心结,最后选择陪伴照顾...
给上文空格处选择最合适的成语或俗语:
(A) 有条有理 (B) 偏听偏信 (C) 狗尾续貂 (D) 半壁江山 (E) 身家性命 (F) 胆小如鼠 (G) 独善其身
完整排行榜见成语理解
☛查看成语理解:badcase
分析用户评论的情感属性,消极或积极。
评测样本举例:
用了几天,发现很多问题,无线网容易掉线,屏幕容易刮花,打开网页容易死掉,不值的买
以上用户评论是正面还是负面?
(A) 负面 (B) 正面
完整排行榜见情感分析
☛查看情感分析:badcase
文本蕴含,判断两个句子之间的语义关系:蕴含、中立、矛盾,参考OCNLI。
评测样本举例:
句子一:农机具购置补贴覆盖到全国所有农牧业县(场),中央财政拟安排资金130亿元,比上年增加90亿元
句子二:按农民人数发放补贴
以上两个句子是什么关系?
(A)蕴含 (B)中立 (C)矛盾
完整排行榜见文本蕴含
☛查看文本蕴含:badcase
评测样本举例:
将下列单词按词性分类。
狗,追,跑,大人,高兴,树
完整排行榜见文本分类
☛查看文本分类:badcase
评测样本举例:
“中信银行3亿元,交通银行增长约2.7亿元,光大银行约1亿元。”
提取出以上文本中的所有组织机构名称
完整排行榜见信息抽取
☛查看信息抽取:badcase
阅读理解能力是一种符合能力,考查针对给定信息的理解能力。
依据给定信息的种类,可以细分为:文章问答、表格问答、对话问答……
评测样本举例:
牙医:好的,让我们看看你的牙齿。从你的描述和我们的检查结果来看,你可能有一些牙齦疾病,导致牙齿的神经受到刺激,引起了敏感。此外,这些黑色斑点可能是蛀牙。
病人:哦,真的吗?那我该怎么办?
牙医:别担心,我们可以为你制定一个治疗计划。我们需要首先治疗牙龈疾病,然后清除蛀牙并填充牙洞。在此过程中,我们将确保您感到舒适,并使用先进的技术和材料来实现最佳效果。
病人:好的,谢谢您,医生。那么我什么时候可以开始治疗?
牙医:让我们为您安排一个约会。您的治疗将在两天后开始。在此期间,请继续刷牙,使用牙线,并避免吃过于甜腻和酸性的食物和饮料。
病人:好的,我会的。再次感谢您,医生。
牙医:不用谢,我们会尽最大的努力帮助您恢复健康的牙齿。
基于以上对话回答:病人在检查中发现的牙齿问题有哪些?
完整排行榜见阅读理解
☛查看阅读理解:badcase
中文指代消解任务,参考CLUEWSC2020。 评测样本举例:
少平仍然不知道怎样给奶奶说清他姐夫的事,就只好随口说:“他犯了点错误,人家让他劳教!”
上述文本中的“他犯了点错误”中的“他”是指少平吗? 选项:(A)是 (B)否
完整排行榜见代词理解
☛查看代词理解:badcase
中国古典诗歌匹配,给定中国古典诗歌的现代问描述,要求从候选的四句诗中选出与现代文描述语义匹配的那一句。 利用古典诗歌和现代文翻译的平行语料构建正确选项,并利用正确选项从古代诗歌语料库中利用相似检索构造出错误候选。 参考CCPM。 评测样本举例:
昏暗的灯熄灭了又被重新点亮。
上述文本最匹配下面哪句诗:
(A)渔灯灭复明 (B)残灯灭又然 (C)残灯暗复明 (D)残灯灭又明
完整排行榜见诗词匹配
☛查看诗词匹配:badcase
参考谷歌IFEval,并将其翻译和适配到中文,精选9类25种指令,说明如下:

完整排行榜见IFEval
☛查看中文指令遵从:badcase
完整排行榜见汉字字形
☛查看汉字字形:badcase
计算TAU和BFCL-V3的平均分。
☛☛完整排行榜见agent与工具调用排行榜
完整排行榜见TAU
完整排行榜见TAU-airline
完整排行榜见TAU-retail
BFCL-V3是加州大学伯克利分校发布的工具调用评测集,首创多轮、多步函数调用场景,并通过API状态验证评估模型真实交互能力,是目前最权威的大模型工具使用基准之一。
完整排行榜见BFCL-V3
评估大模型编程能力,暂时不计入总分。
完整排行榜见livecodebench
整合我们ReLE评测(中文)和LMArena(英文)、Artificial Analysis(简称AA,英文)排行榜数据。
| 大模型 | ReLE评测(中文) | AA-Intelligence(英文) | AA-Coding(英文) | AA-Math(英文) | LMArena-Text-overall(英文) | LMArena-Text-coding(英文) | LMArena-WebDev(英文) | ||
|---|---|---|---|---|---|---|---|---|---|
| gemini-3-pro-preview(new) | 72.5 | 72.8 | 62.3 | 95.7 | 1495 | 1541 | 1487 | ||
| gpt-5.1-high(new) | 69.7 | 69.7 | 57.5 | 94.0 | 1454 | 1496 | / | ||
| gpt-5.1-medium(new) | 69.3 | / | / | / | / | / | / | ||
| gpt-5-high | / | 68.5 | 52.7 | 94.3 | 1436 | 1470 | 1473 | ||
| GPT-5 Codex (high) | / | 68.5 | 53.5 | 98.7 | / | / | / | ||
| kimi-k2-thinking(new) | 67.9 | 67.0 | 52.2 | 94.7 | 1422 | 1473 | / | ||
| gpt-5-2025-08-07 | 68.9 | 66.4 | 49.2 | 91.7 | / | / | / | ||
| DeepSeek-V3.2-Think | 70.9 | 66.0 | / | / | / | / | / | ||
| DeepSeek-V3.2 | 64.4 | 52.0 | / | / | / | / | / | ||
| o3 | / | 65.5 | 52.2 | 88.3 | 1435 | 1458 | 1186 | ||
| grok-4-0709 | 61.2 | 65.3 | 55.1 | 92.7 | 1410 | 1435 | 1174 | ||
| ... | ... | ... | ... | ... | ... | ... | ... |
完整分数见LMArena+AA
评分方法:从各个维度给大模型打分,每个维度都对应一个评测数据集,包含若干道题。 每道题依据大模型回复质量给1~5分,将评测集内所有题的得分累加并归一化为100分制,即作为最终得分。
所有评分数据详见alldata
- 大模型百花齐放,也参差不齐。不少媒体的宣传往往夸大其词,避重就轻,容易混淆视听;而某些公司为了PR,也过分标榜自己大模型的能力,动不动就“达到chatgpt水平”,动不动就“国内第一”。 所谓“外行看热闹,内行看门道”,业界急需一股气流,摒弃浮躁,静下心来打磨前沿技术,真真正正用技术实力说话。这就少不了一个公开、公正、公平的大模型评测系统,把各类大模型的优点、不足一一展示出来。 如此,大家既能把握当下的发展水平、与国外顶尖技术的差距,也能更加清晰地看明白未来的努力方向,而不被资本热潮、舆论热潮所裹挟。
- 对于产业界来说,特别是对于不具备大模型研发能力的公司,熟悉大模型的技术边界、高效有针对性地做大模型技术选型,在现如今显得尤为重要。 而一个公开、公正、公平的大模型评测系统,恰好能够提供应有的助力,避免重复造轮子,避免因技术栈不同而导致不必要的争论,避免“鸡同鸭讲”。
- 对于大模型研发人员,包括对大模型技术感兴趣的人、学术界看中实践的人,各类大模型的效果对比,反应出了背后不同技术路线、技术方法的有效性,这就提供了非常好的参考意义。
不同大模型的相互参考、借鉴,帮忙大家躲过不必要的坑、避免重复实验带来的资源浪费,有助于整个大模型生态圈的良性高效发展。
先加小编微信,后拉入群,备注“来源github,加群”

关注大模型评测微信公众号,及时获取最新评测信息

若您在自己的论文、报告或开源项目中使用了 ReLE( chinese-llm-benchmark )数据、结果或代码,请按以下格式引用,帮助我们持续维护开源评测生态。
ReLE 评测组. ReLE:中文 AI 大模型能力评测数据集与开放排行榜[EB/OL]. GitHub, 2023-06-04[2025-12-06]. https://github.com/jeinlee1991/chinese-llm-benchmark. DOI: 10.5281/zenodo.xxxxxxx.
ReLE Benchmark Team. (2023, June 4). ReLE: Really Reliable Live Evaluation for Chinese LLMs (Version v5.8.5) [Computer software]. GitHub. https://github.com/jeinlee1991/chinese-llm-benchmark
[1] ReLE Benchmark Team, "ReLE: Really Reliable Live Evaluation for Chinese LLMs," GitHub repository, v5.8.5, Jun. 4, 2023. https://github.com/jeinlee1991/chinese-llm-benchmark
@misc{rele2023benchmark,
author = {{ReLE Benchmark Team}},
title = {ReLE: Really Reliable Live Evaluation for Chinese LLMs},
year = {2025},
url = {https://github.com/jeinlee1991/chinese-llm-benchmark},
version = {v5.8.5},
publisher = {GitHub}
}ReLE 采用语义化版本号(主版本.次版本.修订号)。
- 主版本:重大框架或指标权级调整
- 次版本:新增领域、子榜单或>10% 题库扩充
- 修订号:bug 修复、样本去噪、模型增补
请在引用时注明您使用的 精确 tag(如 v5.8.5),以保证结果可复现。
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for chinese-llm-benchmark
Similar Open Source Tools
chinese-llm-benchmark
The Chinese LLM Benchmark is a continuous evaluation list of large models in CLiB, covering a wide range of commercial and open-source models from various companies and research institutions. It supports multidimensional evaluation of capabilities including classification, information extraction, reading comprehension, data analysis, Chinese encoding efficiency, and Chinese instruction compliance. The benchmark not only provides capability score rankings but also offers the original output results of all models for interested individuals to score and rank themselves.

Firefly
Firefly is an open-source large model training project that supports pre-training, fine-tuning, and DPO of mainstream large models. It includes models like Llama3, Gemma, Qwen1.5, MiniCPM, Llama, InternLM, Baichuan, ChatGLM, Yi, Deepseek, Qwen, Orion, Ziya, Xverse, Mistral, Mixtral-8x7B, Zephyr, Vicuna, Bloom, etc. The project supports full-parameter training, LoRA, QLoRA efficient training, and various tasks such as pre-training, SFT, and DPO. Suitable for users with limited training resources, QLoRA is recommended for fine-tuning instructions. The project has achieved good results on the Open LLM Leaderboard with QLoRA training process validation. The latest version has significant updates and adaptations for different chat model templates.

ChatGPT-Next-Web-Pro
ChatGPT-Next-Web-Pro is a tool that provides an enhanced version of ChatGPT-Next-Web with additional features and functionalities. It offers complete ChatGPT-Next-Web functionality, file uploading and storage capabilities, drawing and video support, multi-modal support, reverse model support, knowledge base integration, translation, customizations, and more. The tool can be deployed with or without a backend, allowing users to interact with AI models, manage accounts, create models, manage API keys, handle orders, manage memberships, and more. It supports various cloud services like Aliyun OSS, Tencent COS, and Minio for file storage, and integrates with external APIs like Azure, Google Gemini Pro, and Luma. The tool also provides options for customizing website titles, subtitles, icons, and plugin buttons, and offers features like voice input, file uploading, real-time token count display, and more.
Llama-Chinese
Llama中文社区是一个专注于Llama模型在中文方面的优化和上层建设的高级技术社区。 **已经基于大规模中文数据,从预训练开始对Llama2模型进行中文能力的持续迭代升级【Done】**。**正在对Llama3模型进行中文能力的持续迭代升级【Doing】** 我们热忱欢迎对大模型LLM充满热情的开发者和研究者加入我们的行列。
MedicalGPT
MedicalGPT is a training medical GPT model with ChatGPT training pipeline, implement of Pretraining, Supervised Finetuning, RLHF(Reward Modeling and Reinforcement Learning) and DPO(Direct Preference Optimization).
VideoCaptioner
VideoCaptioner is a video subtitle processing assistant based on a large language model (LLM), supporting speech recognition, subtitle segmentation, optimization, translation, and full-process handling. It is user-friendly and does not require high configuration, supporting both network calls and local offline (GPU-enabled) speech recognition. It utilizes a large language model for intelligent subtitle segmentation, correction, and translation, providing stunning subtitles for videos. The tool offers features such as accurate subtitle generation without GPU, intelligent segmentation and sentence splitting based on LLM, AI subtitle optimization and translation, batch video subtitle synthesis, intuitive subtitle editing interface with real-time preview and quick editing, and low model token consumption with built-in basic LLM model for easy use.

LLMs
LLMs is a Chinese large language model technology stack for practical use. It includes high-availability pre-training, SFT, and DPO preference alignment code framework. The repository covers pre-training data cleaning, high-concurrency framework, SFT dataset cleaning, data quality improvement, and security alignment work for Chinese large language models. It also provides open-source SFT dataset construction, pre-training from scratch, and various tools and frameworks for data cleaning, quality optimization, and task alignment.
crazyai-ml
The 'crazyai-ml' repository is a collection of resources related to machine learning, specifically focusing on explaining artificial intelligence models. It includes articles, code snippets, and tutorials covering various machine learning algorithms, data analysis, model training, and deployment. The content aims to provide a comprehensive guide for beginners in the field of AI, offering practical implementations and insights into popular machine learning packages and model tuning techniques. The repository also addresses the integration of AI models and frontend-backend concepts, making it a valuable resource for individuals interested in AI applications.

GodHook
GodHook is an Xposed module that integrates various fun features, including automatic replies with support for multiple AI language models, subscription functionality for daily news, inspirational quotes, and weather updates, as well as interface functions to execute host app message functions for operations alerts and data push scenarios. It also offers various other features waiting to be explored. The module is designed for learning and communication purposes only and should not be used for malicious purposes. It requires technical knowledge to configure API model information and aims to lower the technical barrier for wider usage in the future.
pmhub
PmHub is a smart project management system based on SpringCloud, SpringCloud Alibaba, and LLM. It aims to help students quickly grasp the architecture design and development process of microservices/distributed projects. PmHub provides a platform for students to experience the transformation from monolithic to microservices architecture, understand the pros and cons of both architectures, and prepare for job interviews. It offers popular technologies like SpringCloud-Gateway, Nacos, Sentinel, and provides high-quality code, continuous integration, product design documents, and an enterprise workflow system. PmHub is suitable for beginners and advanced learners who want to master core knowledge of microservices/distributed projects.
MiniCPM
MiniCPM is a series of open-source large models on the client side jointly developed by Face Intelligence and Tsinghua University Natural Language Processing Laboratory. The main language model MiniCPM-2B has only 2.4 billion (2.4B) non-word embedding parameters, with a total of 2.7B parameters. - After SFT, MiniCPM-2B performs similarly to Mistral-7B on public comprehensive evaluation sets (better in Chinese, mathematics, and code capabilities), and outperforms models such as Llama2-13B, MPT-30B, and Falcon-40B overall. - After DPO, MiniCPM-2B also surpasses many representative open-source large models such as Llama2-70B-Chat, Vicuna-33B, Mistral-7B-Instruct-v0.1, and Zephyr-7B-alpha on the current evaluation set MTBench, which is closest to the user experience. - Based on MiniCPM-2B, a multi-modal large model MiniCPM-V 2.0 on the client side is constructed, which achieves the best performance of models below 7B in multiple test benchmarks, and surpasses larger parameter scale models such as Qwen-VL-Chat 9.6B, CogVLM-Chat 17.4B, and Yi-VL 34B on the OpenCompass leaderboard. MiniCPM-V 2.0 also demonstrates leading OCR capabilities, approaching Gemini Pro in scene text recognition capabilities. - After Int4 quantization, MiniCPM can be deployed and inferred on mobile phones, with a streaming output speed slightly higher than human speech speed. MiniCPM-V also directly runs through the deployment of multi-modal large models on mobile phones. - A single 1080/2080 can efficiently fine-tune parameters, and a single 3090/4090 can fully fine-tune parameters. A single machine can continuously train MiniCPM, and the secondary development cost is relatively low.
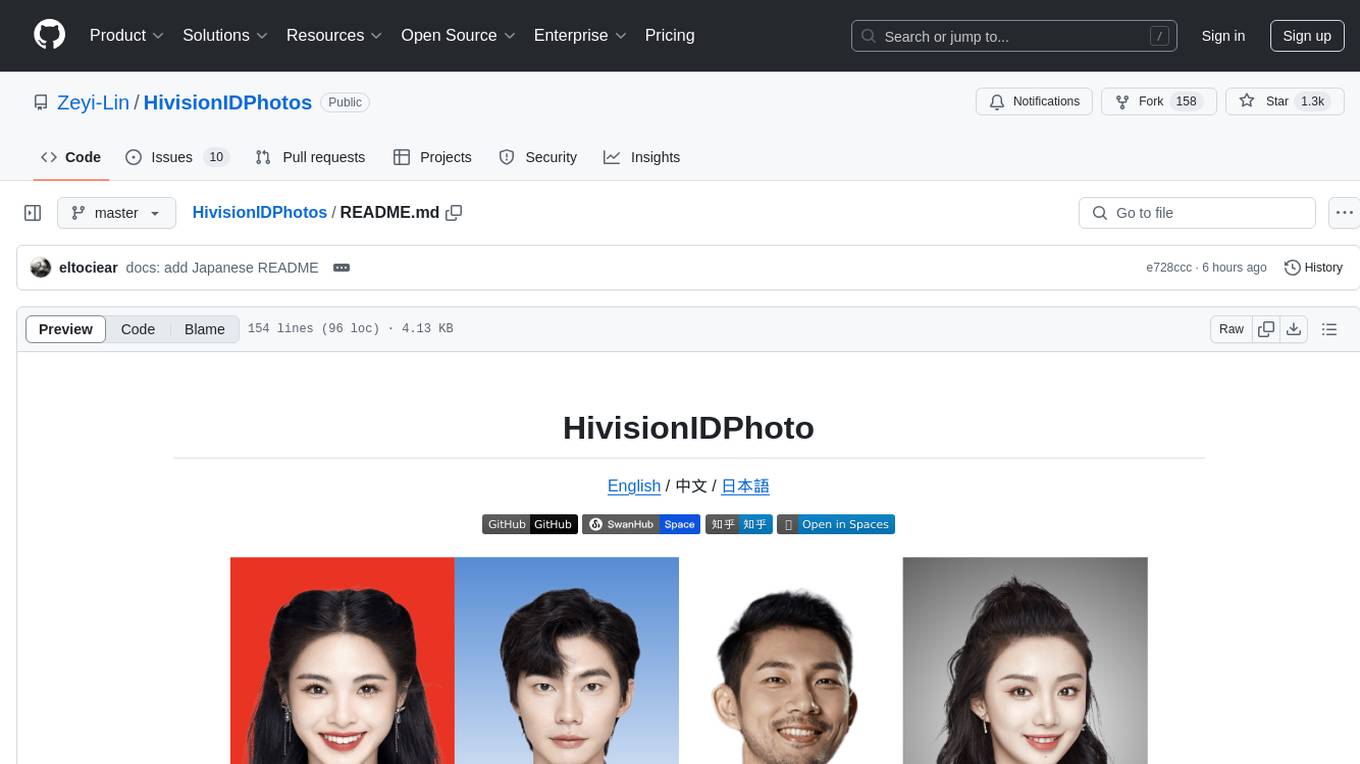
HivisionIDPhotos
HivisionIDPhoto is a practical algorithm for intelligent ID photo creation. It utilizes a comprehensive model workflow to recognize, cut out, and generate ID photos for various user photo scenarios. The tool offers lightweight cutting, standard ID photo generation based on different size specifications, six-inch layout photo generation, beauty enhancement (waiting), and intelligent outfit swapping (waiting). It aims to solve emergency ID photo creation issues.
MindChat
MindChat is a psychological large language model designed to help individuals relieve psychological stress and solve mental confusion, ultimately improving mental health. It aims to provide a relaxed and open conversation environment for users to build trust and understanding. MindChat offers privacy, warmth, safety, timely, and convenient conversation settings to help users overcome difficulties and challenges, achieve self-growth, and development. The tool is suitable for both work and personal life scenarios, providing comprehensive psychological support and therapeutic assistance to users while strictly protecting user privacy. It combines psychological knowledge with artificial intelligence technology to contribute to a healthier, more inclusive, and equal society.
go-stock
Go-stock is a tool for analyzing stock market data using the Go programming language. It provides functionalities for fetching stock data, performing technical analysis, and visualizing trends. With Go-stock, users can easily retrieve historical stock prices, calculate moving averages, and plot candlestick charts. This tool is designed to help investors and traders make informed decisions based on data-driven insights.
DISC-LawLLM
DISC-LawLLM is a legal domain large model that aims to provide professional, intelligent, and comprehensive **legal services** to users. It is developed and open-sourced by the Data Intelligence and Social Computing Lab (Fudan-DISC) at Fudan University.
For similar tasks

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.