
youtu-graphrag
Official repository of Youtu-GraphRAG: Vertically Unified Agents for Graph Retrieval-Augmented Complex Reasoning
Stars: 621
Youtu-GraphRAG is a vertically unified agentic paradigm that connects the entire framework based on graph schema, allowing seamless domain transfer with minimal intervention. It introduces key innovations like schema-guided hierarchical knowledge tree construction, dually-perceived community detection, agentic retrieval, advanced construction and reasoning capabilities, fair anonymous dataset 'AnonyRAG', and unified configuration management. The framework demonstrates robustness with lower token cost and higher accuracy compared to state-of-the-art methods, enabling enterprise-scale deployment with minimal manual intervention for new domains.
README:


🚀 Revolutionary framework moving Pareto Frontier with 33.6% lower token cost and 16.62% higher accuracy over SOTA baselines
Youtu-GraphRAG is a vertically unified agentic paradigm that jointly connects the entire framework as an intricate integration based on graph schema. We allow seamless domain transfer with minimal intervention on the graph schema, providing insights of the next evolutionary GraphRAG paradigm for real-world applications with remarkable adaptability.
![]()
🔗 Multi-hop Reasoning/Summarization/Conclusion: Complex questions requiring multi-step reasoning
📚 Knowledge-Intensive Tasks: Questions dependent on large amounts of structured/private/domain knowledge
🌐 Domain Scalability: Easily support encyclopedias, academic papers, commercial/private knowledge base and other domains with minimal intervention on the schema

A sketched overview of our proposed framework Youtu-GraphRAG.
This video walks through the main features of the project.


Based on our unified agentic paradigm for Graph Retrieval-Augmented Generation (GraphRAG), Youtu-GraphRAG introduces several key innovations that jointly connect the entire framework as an intricate integration:
🏗️ 1. Schema-Guided Hierarchical Knowledge Tree Construction
- 🌱 Seed Graph Schema: Introduces targeted entity types, relations, and attribute types to bound automatic extraction agents
- 📈 Scalable Schema Expansion: Continuously expands schemas for adaptability over unseen domains
- 🏢 Four-Level Architecture:
- Level 1 (Attributes): Entity property information
- Level 2 (Relations): Entity relationship triples
- Level 3 (Keywords): Keyword indexing
- Level 4 (Communities): Hierarchical community structure
- ⚡ Quick Adaptation to industrial applications: We allow seamless domain transfer with minimal intervention on the schema
🌳 2. Dually-Perceived Community Detection
- 🔬 Novel Community Detection Algorithm: Fuses structural topology with subgraph semantics for comprehensive knowledge organization
- 📊 Hierarchical Knowledge Tree: Naturally yields a structure supporting both top-down filtering and bottom-up reasoning that performs better than traditional Leiden and Louvain algorithms
- 📝 Community Summaries: LLM-enhanced community summarization for higher-level knowledge abstraction

🤖 3. Agentic Retrieval
- 🎯 Schema-Aware Decomposition: Interprets the same graph schema to transform complex queries into tractable and parallel sub-queries
- 🔄 Iterative Reflection: Performs reflection for more advanced reasoning through IRCoT (Iterative Retrieval Chain of Thought)

🧠 4. Advanced Construction and Reasoning Capabilities for real-world deployment
- 🎯 Performance Enhancement: Less token costs and higher accuracy with optimized prompting, indexing and retrieval strategies
- 🤹♀️ User friendly visualization: In
output/graphs/, the four-level knowledge tree supports visualization with neo4j import,making reasoning paths and knowledge organization vividly visable to users - ⚡ Parallel Sub-question Processing: Concurrent handling of decomposed questions for efficiency and complex scenarios
- 🤔 Iterative Reasoning: Step-by-step answer construction with reasoning traces
- 📊 Domain Scalability: Designed for enterprise-scale deployment with minimal manual intervention for new domains
📈 5. Fair Anonymous Dataset 'AnonyRAG'
- Link: Hugging Face AnonyRAG
- Against knowledeg leakage in LLM/embedding model pretraining
- In-depth test on real retrieval performance of GraphRAG
- Multi-lingual with Chinese and English versions
⚙️ 6. Unified Configuration Management
- 🎛️ Centralized Parameter Management: All components configured through a single YAML file
- 🔧 Runtime Parameter Override: Dynamic configuration adjustment during execution
- 🌍 Multi-Environment Support: Seamless domain transfer with minimal intervention on schema
- 🔄 Backward Compatibility: Ensures existing code continues to function
Extensive experiments across six challenging benchmarks, including GraphRAG-Bench, HotpotQA and MuSiQue, demonstrate the robustness of Youtu-GraphRAG, remarkably moving the Pareto frontier with 33.6% lower token cost compared to the sota methods and 16.62% higher accuracy over state-of-the-art baselines. The results indicate our adaptability, allowing seamless domain transfer with minimal intervention on schema.



youtu-graphrag/
├── 📁 config/ # Configuration System
│ ├── base_config.yaml # Main configuration file
│ ├── config_loader.py # Configuration loader
│ └── __init__.py # Configuration module interface
│
├── 📁 data/ # Data Directory
│
├── 📁 models/ # Core Models
│ ├── 📁 constructor/ # Knowledge Graph Construction
│ │ └── kt_gen.py # KTBuilder - Hierarchical graph builder
│ ├── 📁 retriever/ # Retrieval Module
│ │ ├── enhanced_kt_retriever.py # KTRetriever - Main retriever
│ │ ├── agentic_decomposer.py # Query decomposer
│ └── └── faiss_filter.py # DualFAISSRetriever - FAISS retrieval
│
├── 📁 utils/ # Utility Modules
│ ├── tree_comm.py # community detection algorithm
│ ├── call_llm_api.py # LLM API calling
│ ├── eval.py # Evaluation tools
│ └── graph_processor.py # Graph processing tools
│
├── 📁 schemas/ # Dataset Schemas
├── 📁 assets/ # Assets (images, figures)
│
├── 📁 output/ # Output Directory
│ ├── graphs/ # Constructed knowledge graphs
│ ├── chunks/ # Text chunk information
│ └── logs/ # Runtime logs
│
├── 📁 retriever/ # Retrieval Cache
│
├── main.py # 🎯 Main program entry
├── requirements.txt # Dependencies list
├── setup_env.sh # install web dependency
├── start.sh # start web service
└── README.md # Project documentation
We provide two approaches to run and experience the demo service. Considering the differences in the underlying environment, we recommend using Docker as the preferred deployment method.
This approach relies on the Docker environment, which could be installed according to official documentation.
# 1. Clone Youtu-GraphRAG project
git clone https://github.com/TencentCloudADP/youtu-graphrag
# 2. Create .env according to .env.example
cd youtu-graphrag && cp .env.example .env
# Config your LLM api in .env as OpenAI API format
# LLM_MODEL=deepseek-chat
# LLM_BASE_URL=https://api.deepseek.com
# LLM_API_KEY=sk-xxxxxx
# 3. Build with dockerfile
docker build -t youtu_graphrag:v1 .
# 4. Docker run
docker run -d -p 8000:8000 youtu_graphrag:v1
# 5. Visit http://localhost:8000
curl -v http://localhost:8000This approach relies on Python 3.10 and the corresponding pip environment, you can install it according to the official documentation.
# 1. Clone Youtu-GraphRAG project
git clone https://github.com/TencentCloudADP/youtu-graphrag
# 2. Create .env according to .env.example
cd youtu-graphrag && cp .env.example .env
# Config your LLM api in .env as OpenAI API format
# LLM_MODEL=deepseek-chat
# LLM_BASE_URL=https://api.deepseek.com
# LLM_API_KEY=sk-xxxxxx
# 3. Setup environment
./setup_env.sh
# 4. Launch the web
./start.sh
# 5. Visit http://localhost:8000
curl -v http://localhost:8000For advanced config and usage:🚀 FullGuide
We welcome contributions from the community! Here's how you can help:
- 🍴 Fork the project
- 🌿 Create a feature branch (
git checkout -b feature/AmazingFeature) - 💾 Commit your changes (
git commit -m 'Add some AmazingFeature') - 📤 Push to the branch (
git push origin feature/AmazingFeature) - 🔄 Create a Pull Request
- 🌱 New Seed Schemas: Add high-quality seed schema and data processing
- 📊 Custom Datasets: Integrate new datasets with minimal schema intervention
- 🎯 Domain-Specific Applications: Extend framework for specialized use cases with 'Best Practice'
Hanson Dong - [email protected] Siyu An - [email protected]
@misc{dong2025youtugraphrag,
title={Youtu-GraphRAG: Vertically Unified Agents for Graph Retrieval-Augmented Complex Reasoning},
author={Junnan Dong and Siyu An and Yifei Yu and Qian-Wen Zhang and Linhao Luo and Xiao Huang and Yunsheng Wu and Di Yin and Xing Sun},
year={2025},
eprint={2508.19855},
archivePrefix={arXiv},
url={https://arxiv.org/abs/2508.19855},
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for youtu-graphrag
Similar Open Source Tools
youtu-graphrag
Youtu-GraphRAG is a vertically unified agentic paradigm that connects the entire framework based on graph schema, allowing seamless domain transfer with minimal intervention. It introduces key innovations like schema-guided hierarchical knowledge tree construction, dually-perceived community detection, agentic retrieval, advanced construction and reasoning capabilities, fair anonymous dataset 'AnonyRAG', and unified configuration management. The framework demonstrates robustness with lower token cost and higher accuracy compared to state-of-the-art methods, enabling enterprise-scale deployment with minimal manual intervention for new domains.
OpenManus-RL
OpenManus-RL is an open-source initiative focused on enhancing reasoning and decision-making capabilities of large language models (LLMs) through advanced reinforcement learning (RL)-based agent tuning. The project explores novel algorithmic structures, diverse reasoning paradigms, sophisticated reward strategies, and extensive benchmark environments. It aims to push the boundaries of agent reasoning and tool integration by integrating insights from leading RL tuning frameworks and continuously updating progress in a dynamic, live-streaming fashion.
chinese-llm-benchmark
The Chinese LLM Benchmark is a continuous evaluation list of large models in CLiB, covering a wide range of commercial and open-source models from various companies and research institutions. It supports multidimensional evaluation of capabilities including classification, information extraction, reading comprehension, data analysis, Chinese encoding efficiency, and Chinese instruction compliance. The benchmark not only provides capability score rankings but also offers the original output results of all models for interested individuals to score and rank themselves.

PaddleNLP
PaddleNLP is an easy-to-use and high-performance NLP library. It aggregates high-quality pre-trained models in the industry and provides out-of-the-box development experience, covering a model library for multiple NLP scenarios with industry practice examples to meet developers' flexible customization needs.

ml-engineering
This repository provides a comprehensive collection of methodologies, tools, and step-by-step instructions for successful training of large language models (LLMs) and multi-modal models. It is a technical resource suitable for LLM/VLM training engineers and operators, containing numerous scripts and copy-n-paste commands to facilitate quick problem-solving. The repository is an ongoing compilation of the author's experiences training BLOOM-176B and IDEFICS-80B models, and currently focuses on the development and training of Retrieval Augmented Generation (RAG) models at Contextual.AI. The content is organized into six parts: Insights, Hardware, Orchestration, Training, Development, and Miscellaneous. It includes key comparison tables for high-end accelerators and networks, as well as shortcuts to frequently needed tools and guides. The repository is open to contributions and discussions, and is licensed under Attribution-ShareAlike 4.0 International.

verl
veRL is a flexible and efficient reinforcement learning training framework designed for large language models (LLMs). It allows easy extension of diverse RL algorithms, seamless integration with existing LLM infrastructures, and flexible device mapping. The framework achieves state-of-the-art throughput and efficient actor model resharding with 3D-HybridEngine. It supports popular HuggingFace models and is suitable for users working with PyTorch FSDP, Megatron-LM, and vLLM backends.

transformers
Transformers is a state-of-the-art pretrained models library that acts as the model-definition framework for machine learning models in text, computer vision, audio, video, and multimodal tasks. It centralizes model definition for compatibility across various training frameworks, inference engines, and modeling libraries. The library simplifies the usage of new models by providing simple, customizable, and efficient model definitions. With over 1M+ Transformers model checkpoints available, users can easily find and utilize models for their tasks.
llms-from-scratch-rs
This project provides Rust code that follows the text 'Build An LLM From Scratch' by Sebastian Raschka. It translates PyTorch code into Rust using the Candle crate, aiming to build a GPT-style LLM. Users can clone the repo, run examples/exercises, and access the same datasets as in the book. The project includes chapters on understanding large language models, working with text data, coding attention mechanisms, implementing a GPT model, pretraining unlabeled data, fine-tuning for classification, and fine-tuning to follow instructions.
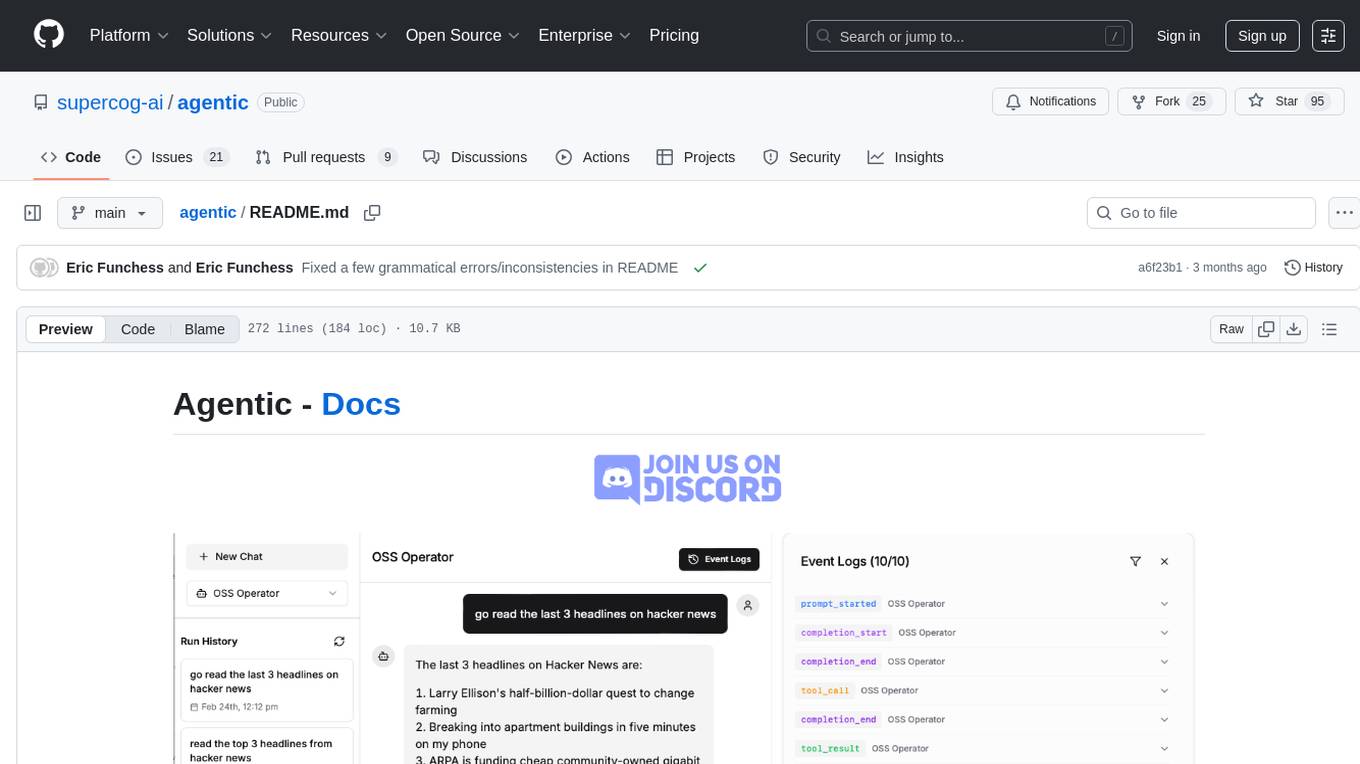
agentic
Agentic is a lightweight and flexible Python library for building multi-agent systems. It provides a simple and intuitive API for creating and managing agents, defining their behaviors, and simulating interactions in a multi-agent environment. With Agentic, users can easily design and implement complex agent-based models to study emergent behaviors, social dynamics, and decentralized decision-making processes. The library supports various agent architectures, communication protocols, and simulation scenarios, making it suitable for a wide range of research and educational applications in the fields of artificial intelligence, machine learning, social sciences, and robotics.

ms-agent
MS-Agent is a lightweight framework designed to empower agents with autonomous exploration capabilities. It provides a flexible and extensible architecture for creating agents capable of tasks like code generation, data analysis, and tool calling with MCP support. The framework supports multi-agent interactions, deep research, code generation, and is lightweight and extensible for various applications.

Fast-dLLM
Fast-DLLM is a diffusion-based Large Language Model (LLM) inference acceleration framework that supports efficient inference for models like Dream and LLaDA. It offers fast inference support, multiple optimization strategies, code generation, evaluation capabilities, and an interactive chat interface. Key features include Key-Value Cache for Block-Wise Decoding, Confidence-Aware Parallel Decoding, and overall performance improvements. The project structure includes directories for Dream and LLaDA model-related code, with installation and usage instructions provided for using the LLaDA and Dream models.
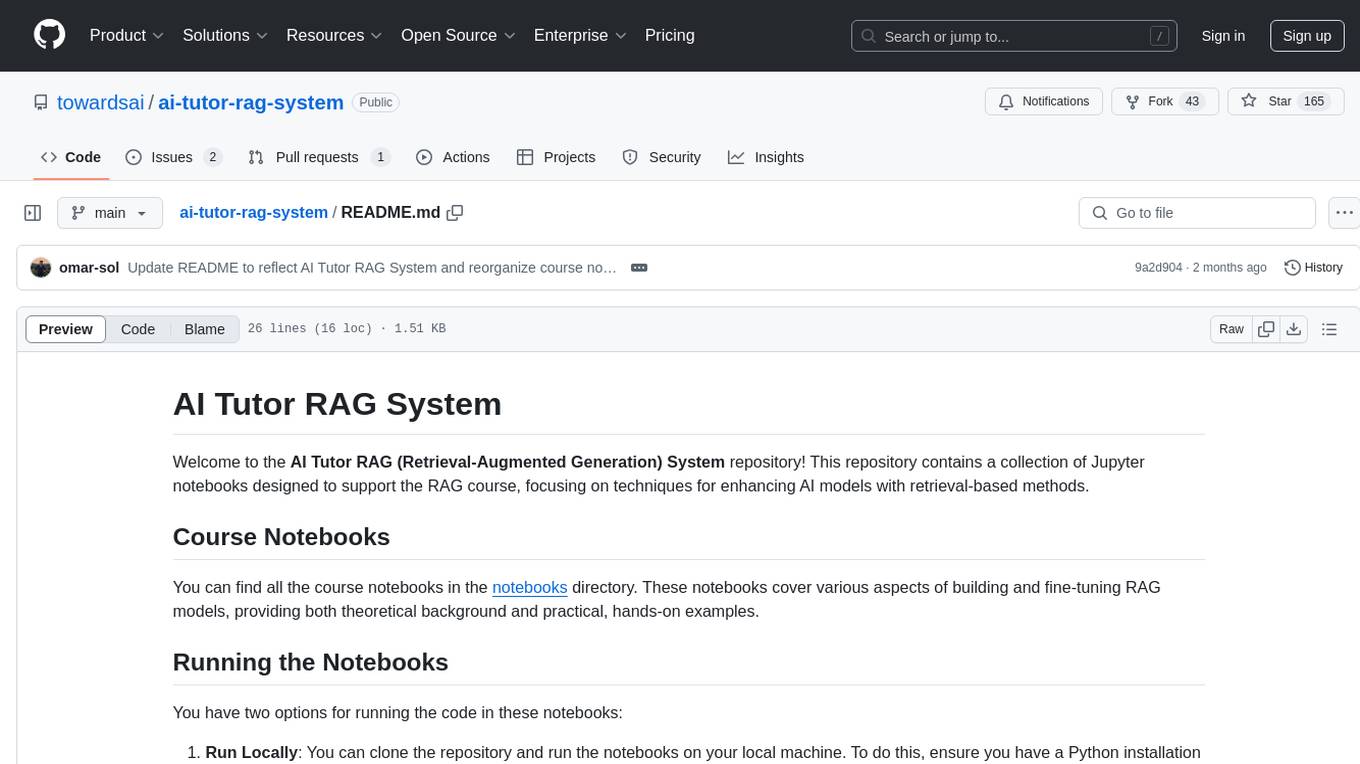
ai-tutor-rag-system
The AI Tutor RAG System repository contains Jupyter notebooks supporting the RAG course, focusing on enhancing AI models with retrieval-based methods. It covers foundational and advanced concepts in retrieval-augmented generation, including data retrieval techniques, model integration with retrieval systems, and practical applications of RAG in real-world scenarios.
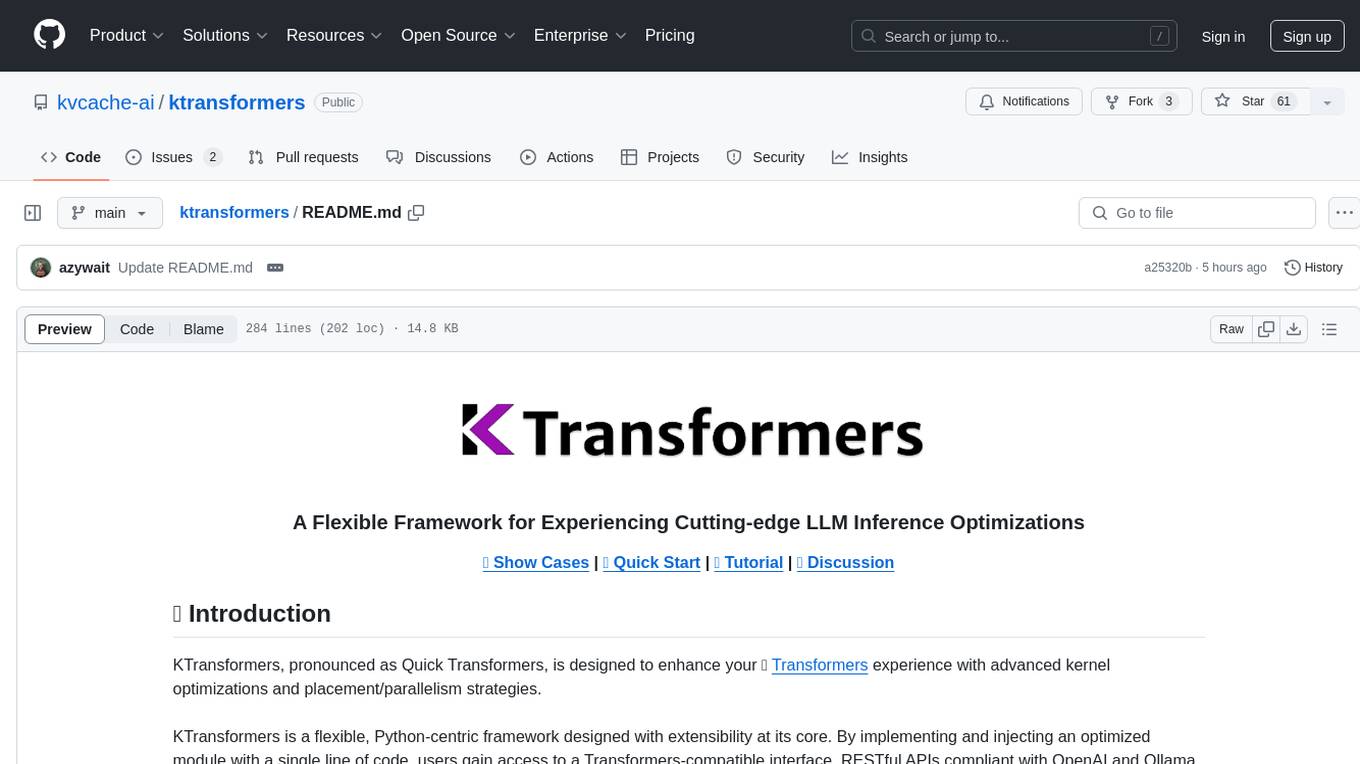
ktransformers
KTransformers is a flexible Python-centric framework designed to enhance the user's experience with advanced kernel optimizations and placement/parallelism strategies for Transformers. It provides a Transformers-compatible interface, RESTful APIs compliant with OpenAI and Ollama, and a simplified ChatGPT-like web UI. The framework aims to serve as a platform for experimenting with innovative LLM inference optimizations, focusing on local deployments constrained by limited resources and supporting heterogeneous computing opportunities like GPU/CPU offloading of quantized models.

auto-round
AutoRound is an advanced weight-only quantization algorithm for low-bits LLM inference. It competes impressively against recent methods without introducing any additional inference overhead. The method adopts sign gradient descent to fine-tune rounding values and minmax values of weights in just 200 steps, often significantly outperforming SignRound with the cost of more tuning time for quantization. AutoRound is tailored for a wide range of models and consistently delivers noticeable improvements.

open-webui-tools
Open WebUI Tools Collection is a set of tools for structured planning, arXiv paper search, Hugging Face text-to-image generation, prompt enhancement, and multi-model conversations. It enhances LLM interactions with academic research, image generation, and conversation management. Tools include arXiv Search Tool and Hugging Face Image Generator. Function Pipes like Planner Agent offer autonomous plan generation and execution. Filters like Prompt Enhancer improve prompt quality. Installation and configuration instructions are provided for each tool and pipe.
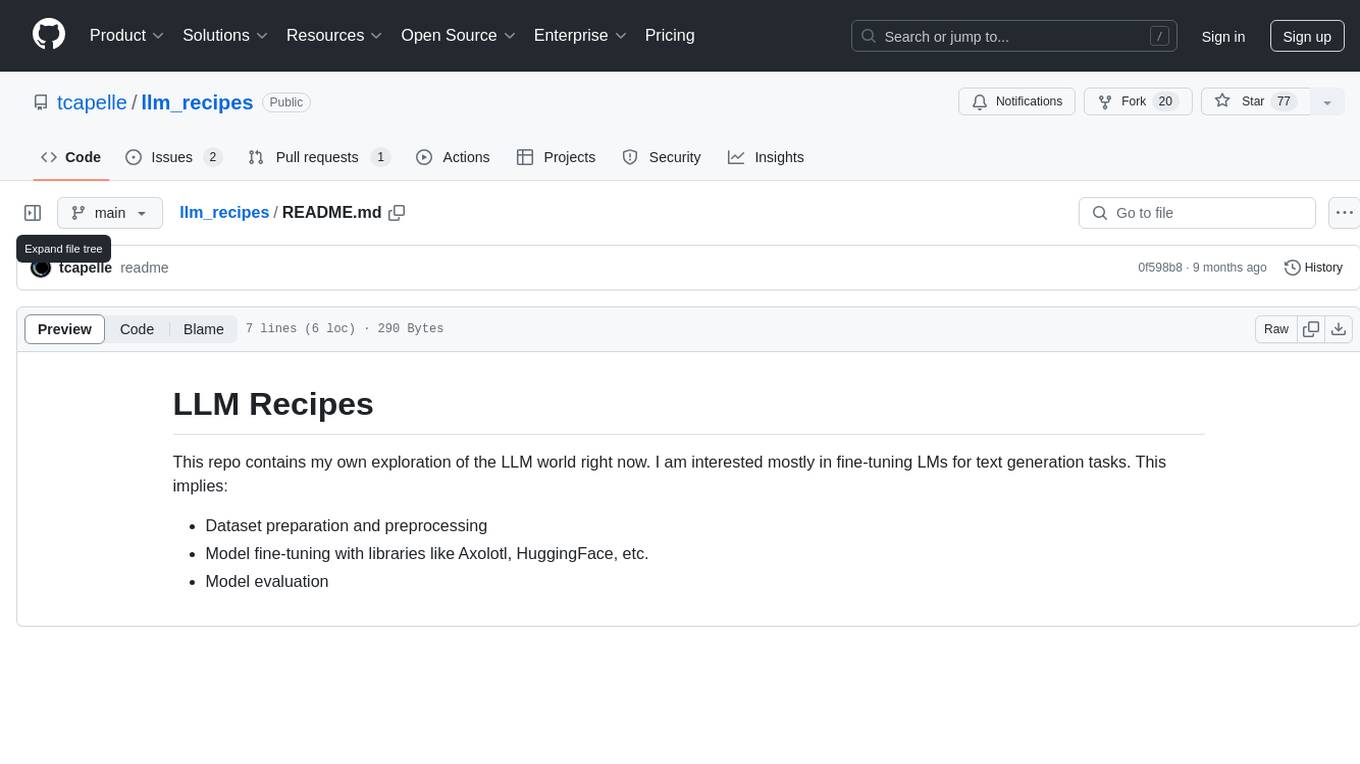
llm_recipes
This repository showcases the author's experiments with Large Language Models (LLMs) for text generation tasks. It includes dataset preparation, preprocessing, model fine-tuning using libraries such as Axolotl and HuggingFace, and model evaluation.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

llmops-promptflow-template
LLMOps with Prompt flow is a template and guidance for building LLM-infused apps using Prompt flow. It provides centralized code hosting, lifecycle management, variant and hyperparameter experimentation, A/B deployment, many-to-many dataset/flow relationships, multiple deployment targets, comprehensive reporting, BYOF capabilities, configuration-based development, local prompt experimentation and evaluation, endpoint testing, and optional Human-in-loop validation. The tool is customizable to suit various application needs.

azure-search-vector-samples
This repository provides code samples in Python, C#, REST, and JavaScript for vector support in Azure AI Search. It includes demos for various languages showcasing vectorization of data, creating indexes, and querying vector data. Additionally, it offers tools like Azure AI Search Lab for experimenting with AI-enabled search scenarios in Azure and templates for deploying custom chat-with-your-data solutions. The repository also features documentation on vector search, hybrid search, creating and querying vector indexes, and REST API references for Azure AI Search and Azure OpenAI Service.

geti-sdk
The Intel® Geti™ SDK is a python package that enables teams to rapidly develop AI models by easing the complexities of model development and enhancing collaboration between teams. It provides tools to interact with an Intel® Geti™ server via the REST API, allowing for project creation, downloading, uploading, deploying for local inference with OpenVINO, setting project and model configuration, launching and monitoring training jobs, and media upload and prediction. The SDK also includes tutorial-style Jupyter notebooks demonstrating its usage.

booster
Booster is a powerful inference accelerator designed for scaling large language models within production environments or for experimental purposes. It is built with performance and scaling in mind, supporting various CPUs and GPUs, including Nvidia CUDA, Apple Metal, and OpenCL cards. The tool can split large models across multiple GPUs, offering fast inference on machines with beefy GPUs. It supports both regular FP16/FP32 models and quantised versions, along with popular LLM architectures. Additionally, Booster features proprietary Janus Sampling for code generation and non-English languages.

xFasterTransformer
xFasterTransformer is an optimized solution for Large Language Models (LLMs) on the X86 platform, providing high performance and scalability for inference on mainstream LLM models. It offers C++ and Python APIs for easy integration, along with example codes and benchmark scripts. Users can prepare models in a different format, convert them, and use the APIs for tasks like encoding input prompts, generating token ids, and serving inference requests. The tool supports various data types and models, and can run in single or multi-rank modes using MPI. A web demo based on Gradio is available for popular LLM models like ChatGLM and Llama2. Benchmark scripts help evaluate model inference performance quickly, and MLServer enables serving with REST and gRPC interfaces.

amazon-transcribe-live-call-analytics
The Amazon Transcribe Live Call Analytics (LCA) with Agent Assist Sample Solution is designed to help contact centers assess and optimize caller experiences in real time. It leverages Amazon machine learning services like Amazon Transcribe, Amazon Comprehend, and Amazon SageMaker to transcribe and extract insights from contact center audio. The solution provides real-time supervisor and agent assist features, integrates with existing contact centers, and offers a scalable, cost-effective approach to improve customer interactions. The end-to-end architecture includes features like live call transcription, call summarization, AI-powered agent assistance, and real-time analytics. The solution is event-driven, ensuring low latency and seamless processing flow from ingested speech to live webpage updates.

ai-lab-recipes
This repository contains recipes for building and running containerized AI and LLM applications with Podman. It provides model servers that serve machine-learning models via an API, allowing developers to quickly prototype new AI applications locally. The recipes include components like model servers and AI applications for tasks such as chat, summarization, object detection, etc. Images for sample applications and models are available in `quay.io`, and bootable containers for AI training on Linux OS are enabled.

XLearning
XLearning is a scheduling platform for big data and artificial intelligence, supporting various machine learning and deep learning frameworks. It runs on Hadoop Yarn and integrates frameworks like TensorFlow, MXNet, Caffe, Theano, PyTorch, Keras, XGBoost. XLearning offers scalability, compatibility, multiple deep learning framework support, unified data management based on HDFS, visualization display, and compatibility with code at native frameworks. It provides functions for data input/output strategies, container management, TensorBoard service, and resource usage metrics display. XLearning requires JDK >= 1.7 and Maven >= 3.3 for compilation, and deployment on CentOS 7.2 with Java >= 1.7 and Hadoop 2.6, 2.7, 2.8.