
llms-from-scratch-rs
A comprehensive Rust translation of the code from Sebastian Raschka's Build an LLM from Scratch book.
Stars: 237
This project provides Rust code that follows the text 'Build An LLM From Scratch' by Sebastian Raschka. It translates PyTorch code into Rust using the Candle crate, aiming to build a GPT-style LLM. Users can clone the repo, run examples/exercises, and access the same datasets as in the book. The project includes chapters on understanding large language models, working with text data, coding attention mechanisms, implementing a GPT model, pretraining unlabeled data, fine-tuning for classification, and fine-tuning to follow instructions.
README:

This project aims to provide Rust code that follows the incredible text, Build An LLM From Scratch by Sebastian Raschka. The book provides arguably the most clearest step by step walkthrough for building a GPT-style LLM. Listed below are the titles for each of the 7 Chapters of the book.
- Understanding large language models
- Working with text data
- Coding attention mechanisms
- Implementing a GPT model from scratch to generate text
- Pretraining an unlabeled data
- Fine-tuning for classification
- Fine-tuning to follow instructions
The code (see associated github repo) provided in the book is all written in PyTorch (understandably so). In this project, we translate all of the PyTorch code into Rust code by using the Candle crate, which is a minimalist ML Framework.
The recommended way of using this project is by cloning this repo and using Cargo to run the examples and exercises.
# SSH
git clone [email protected]:nerdai/llms-from-scratch-rs.git
# HTTPS
git clone https://github.com/nerdai/llms-from-scratch-rs.gitIt is important to note that we use the same datasets that is used by Sebastian
in his book. Use the command below to download the data in a subfolder called
data/ which will eventually be used by the examples and exercises of the book.
mkdir -p 'data/'
wget 'https://raw.githubusercontent.com/rabst/LLMs-from-scratch/main/ch02/01_main-chapter-code/the-verdict.txt' -O 'data/the-verdict.txt'Users have the option of reading the code via their chosen IDE and the cloned repo, or by using the project's docs.
NOTE: The import style used in all of the examples and exercises modules are
not by convention. Specifically, relevant imports are made under the main() method
of every Example and Exercise implementation. This is done for educational
purposes to assist the reader of the book in knowing precisely what imports are
needed for the example/exercise at hand.
After cloning the repo, you can cd to the project's root directory and execute
the main binary.
# Run code for Example 05.07
cargo run example 05.07
# Run code for Exercise 5.5
cargo run exercise 5.5If using a cuda-enabled device, you turn on the cuda feature via the --features cuda
flag:
# Run code for Example 05.07
cargo run --features cuda example 05.07
# Run code for Exercise 5.5
cargo run --features cuda exercise 5.5To list the Examples, use the following command:
cargo run list --examplesA snippet of the output is pasted below.
EXAMPLES:
+-------+----------------------------------------------------------------------+
| Id | Description |
+==============================================================================+
| 02.01 | Example usage of `listings::ch02::sample_read_text` |
|-------+----------------------------------------------------------------------|
| 02.02 | Use candle to generate an Embedding Layer. |
|-------+----------------------------------------------------------------------|
| 02.03 | Create absolute postiional embeddings. |
|-------+----------------------------------------------------------------------|
| 03.01 | Computing attention scores as a dot product. |
...
|-------+----------------------------------------------------------------------|
| 06.13 | Example usage of `train_classifier_simple` and `plot_values` |
| | function. |
|-------+----------------------------------------------------------------------|
| 06.14 | Loading fine-tuned model and calculate performance on whole train, |
| | val and test sets. |
|-------+----------------------------------------------------------------------|
| 06.15 | Example usage of `classify_review`. |
+-------+----------------------------------------------------------------------+One can similarly list the Exercises using:
cargo run list --exercises# first few lines of output
EXERCISES:
+-----+------------------------------------------------------------------------+
| Id | Statement |
+==============================================================================+
| 2.1 | Byte pair encoding of unknown words |
| | |
| | Try the BPE tokenizer from the tiktoken library on the unknown words |
| | 'Akwirw ier' and print the individual token IDs. Then, call the decode |
| | function on each of the resulting integers in this list to reproduce |
| | the mapping shown in figure 2.11. Lastly, call the decode method on |
| | the token IDs to check whether it can reconstruct the original input, |
| | 'Akwirw ier.' |
|-----+------------------------------------------------------------------------|
| 2.2 | Data loaders with different strides and context sizes |
| | |
| | To develop more intuition for how the data loader works, try to run it |
| | with different settings such as `max_length=2` and `stride=2`, and |
| | `max_length=8` and `stride=2`. |
|-----+------------------------------------------------------------------------|
...
|-----+------------------------------------------------------------------------|
| 6.2 | Fine-tuning the whole model |
| | |
| | Instead of fine-tuning just the final transformer block, fine-tune the |
| | entire model and assess the effect on predictive performance. |
|-----+------------------------------------------------------------------------|
| 6.3 | Fine-tuning the first vs. last token |
| | |
| | Try fine-tuning the first output token. Notice the changes in |
| | predictive performance compared to fine-tuning the last output token. |
+-----+------------------------------------------------------------------------+Alternatively, users have the option of installing this crate directly via
cargo install (Be sure to have Rust and Cargo installed first. See
here for
installation instructions.):
cargo install llms-from-scratch-rsOnce installed, users can run the main binary in order to run the various Exercises and Examples.
# Run code for Example 05.07
cargo run example 05.07
# Run code for Exercise 5.5
cargo run exercsise 5.5For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llms-from-scratch-rs
Similar Open Source Tools
llms-from-scratch-rs
This project provides Rust code that follows the text 'Build An LLM From Scratch' by Sebastian Raschka. It translates PyTorch code into Rust using the Candle crate, aiming to build a GPT-style LLM. Users can clone the repo, run examples/exercises, and access the same datasets as in the book. The project includes chapters on understanding large language models, working with text data, coding attention mechanisms, implementing a GPT model, pretraining unlabeled data, fine-tuning for classification, and fine-tuning to follow instructions.

xlstm-jax
The xLSTM-jax repository contains code for training and evaluating the xLSTM model on language modeling using JAX. xLSTM is a Recurrent Neural Network architecture that improves upon the original LSTM through Exponential Gating, normalization, stabilization techniques, and a Matrix Memory. It is optimized for large-scale distributed systems with performant triton kernels for faster training and inference.
build-your-own-x-machine-learning
This repository provides a step-by-step guide for building your own machine learning models from scratch. It covers various machine learning algorithms and techniques, including linear regression, logistic regression, decision trees, and neural networks. The code examples are written in Python and include detailed explanations to help beginners understand the concepts behind machine learning. By following the tutorials in this repository, you can gain a deeper understanding of how machine learning works and develop your own models for different applications.
MoonshotAI-Cookbook
The MoonshotAI-Cookbook provides example code and guides for accomplishing common tasks with the MoonshotAI API. To run these examples, you'll need an MoonshotAI account and associated API key. Most code examples are written in Python, though the concepts can be applied in any language.
amazon-sagemaker-generativeai
Repository for training and deploying Generative AI models, including text-text, text-to-image generation, prompt engineering playground and chain of thought examples using SageMaker Studio. The tool provides a platform for users to experiment with generative AI techniques, enabling them to create text and image outputs based on input data. It offers a range of functionalities for training and deploying models, as well as exploring different generative AI applications.

Main
This repository contains material related to the new book _Synthetic Data and Generative AI_ by the author, including code for NoGAN, DeepResampling, and NoGAN_Hellinger. NoGAN is a tabular data synthesizer that outperforms GenAI methods in terms of speed and results, utilizing state-of-the-art quality metrics. DeepResampling is a fast NoGAN based on resampling and Bayesian Models with hyperparameter auto-tuning. NoGAN_Hellinger combines NoGAN and DeepResampling with the Hellinger model evaluation metric.
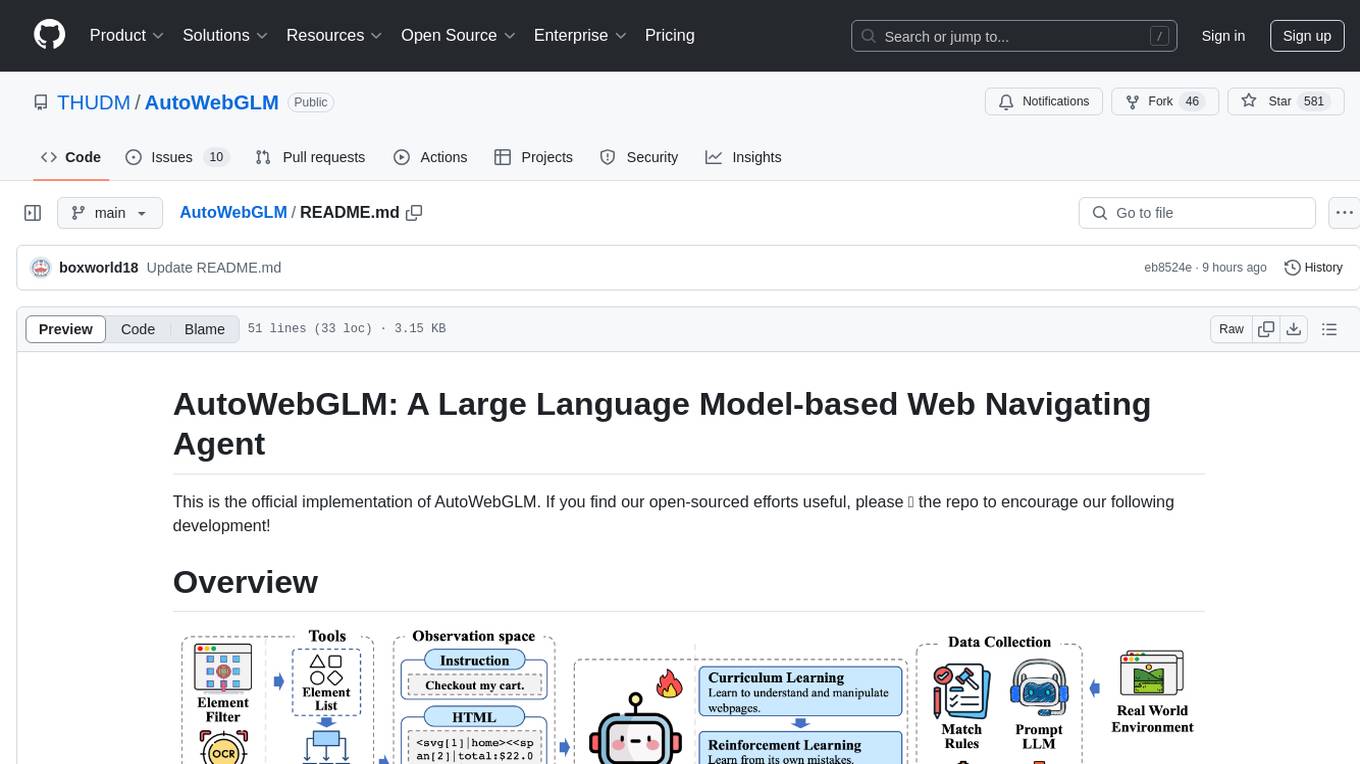
AutoWebGLM
AutoWebGLM is a project focused on developing a language model-driven automated web navigation agent. It extends the capabilities of the ChatGLM3-6B model to navigate the web more efficiently and address real-world browsing challenges. The project includes features such as an HTML simplification algorithm, hybrid human-AI training, reinforcement learning, rejection sampling, and a bilingual web navigation benchmark for testing AI web navigation agents.

nlp-llms-resources
The 'nlp-llms-resources' repository is a comprehensive resource list for Natural Language Processing (NLP) and Large Language Models (LLMs). It covers a wide range of topics including traditional NLP datasets, data acquisition, libraries for NLP, neural networks, sentiment analysis, optical character recognition, information extraction, semantics, topic modeling, multilingual NLP, domain-specific LLMs, vector databases, ethics, costing, books, courses, surveys, aggregators, newsletters, papers, conferences, and societies. The repository provides valuable information and resources for individuals interested in NLP and LLMs.

SuperKnowa
SuperKnowa is a fast framework to build Enterprise RAG (Retriever Augmented Generation) Pipelines at Scale, powered by watsonx. It accelerates Enterprise Generative AI applications to get prod-ready solutions quickly on private data. The framework provides pluggable components for tackling various Generative AI use cases using Large Language Models (LLMs), allowing users to assemble building blocks to address challenges in AI-driven text generation. SuperKnowa is battle-tested from 1M to 200M private knowledge base & scaled to billions of retriever tokens.
build-an-agentic-llm-assistant
This repository provides a hands-on workshop for developers and solution builders to build a real-life serverless LLM application using foundation models (FMs) through Amazon Bedrock and advanced design patterns such as Reason and Act (ReAct) Agent, text-to-SQL, and Retrieval Augmented Generation (RAG). It guides users through labs to explore common and advanced LLM application design patterns, helping them build a complex Agentic LLM assistant capable of answering retrieval and analytical questions on internal knowledge bases. The repository includes labs on IaC with AWS CDK, building serverless LLM assistants with AWS Lambda and Amazon Bedrock, refactoring LLM assistants into custom agents, extending agents with semantic retrieval, and querying SQL databases. Users need to set up AWS Cloud9, configure model access on Amazon Bedrock, and use Amazon SageMaker Studio environment to run data-pipelines notebooks.

learn-applied-generative-ai-fundamentals
This repository is part of the Certified Cloud Native Applied Generative AI Engineer program, focusing on Applied Generative AI Fundamentals. It covers prompt engineering, developing custom GPTs, and Multi AI Agent Systems. The course helps in building a strong understanding of generative AI, applying Large Language Models (LLMs) and diffusion models practically. It introduces principles of prompt engineering to work efficiently with AI, creating custom AI models and GPTs using OpenAI, Azure, and Google technologies. It also utilizes open source libraries like LangChain, CrewAI, and LangGraph to automate tasks and business processes.

llms-tools
The 'llms-tools' repository is a comprehensive collection of AI tools, open-source projects, and research related to Large Language Models (LLMs) and Chatbots. It covers a wide range of topics such as AI in various domains, open-source models, chats & assistants, visual language models, evaluation tools, libraries, devices, income models, text-to-image, computer vision, audio & speech, code & math, games, robotics, typography, bio & med, military, climate, finance, and presentation. The repository provides valuable resources for researchers, developers, and enthusiasts interested in exploring the capabilities of LLMs and related technologies.
Java-AI-Book-Code
The Java-AI-Book-Code repository contains code examples for the 2020 edition of 'Practical Artificial Intelligence With Java'. It is a comprehensive update of the previous 2013 edition, featuring new content on deep learning, knowledge graphs, anomaly detection, linked data, genetic algorithms, search algorithms, and more. The repository serves as a valuable resource for Java developers interested in AI applications and provides practical implementations of various AI techniques and algorithms.

ManipVQA
ManipVQA is a framework that enhances Multimodal Large Language Models (MLLMs) with manipulation-centric knowledge through a Visual Question-Answering (VQA) format. It addresses the deficiency of conventional MLLMs in understanding affordances and physical concepts crucial for manipulation tasks. By infusing robotics-specific knowledge, including tool detection, affordance recognition, and physical concept comprehension, ManipVQA improves the performance of robots in manipulation tasks. The framework involves fine-tuning MLLMs with a curated dataset of interactive objects, enabling robots to understand and execute natural language instructions more effectively.
llm-universe
This project is a tutorial on developing large model applications for novice developers. It aims to provide a comprehensive introduction to large model development, focusing on Alibaba Cloud servers and integrating personal knowledge assistant projects. The tutorial covers the following topics: 1. **Introduction to Large Models**: A simplified introduction for novice developers on what large models are, their characteristics, what LangChain is, and how to develop an LLM application. 2. **How to Call Large Model APIs**: This section introduces various methods for calling APIs of well-known domestic and foreign large model products, including calling native APIs, encapsulating them as LangChain LLMs, and encapsulating them as Fastapi calls. It also provides a unified encapsulation for various large model APIs, such as Baidu Wenxin, Xunfei Xinghuo, and Zh譜AI. 3. **Knowledge Base Construction**: Loading, processing, and vector database construction of different types of knowledge base documents. 4. **Building RAG Applications**: Integrating LLM into LangChain to build a retrieval question and answer chain, and deploying applications using Streamlit. 5. **Verification and Iteration**: How to implement verification and iteration in large model development, and common evaluation methods. The project consists of three main parts: 1. **Introduction to LLM Development**: A simplified version of V1 aims to help beginners get started with LLM development quickly and conveniently, understand the general process of LLM development, and build a simple demo. 2. **LLM Development Techniques**: More advanced LLM development techniques, including but not limited to: Prompt Engineering, processing of multiple types of source data, optimizing retrieval, recall ranking, Agent framework, etc. 3. **LLM Application Examples**: Introduce some successful open source cases, analyze the ideas, core concepts, and implementation frameworks of these application examples from the perspective of this course, and help beginners understand what kind of applications they can develop through LLM. Currently, the first part has been completed, and everyone is welcome to read and learn; the second and third parts are under creation. **Directory Structure Description**: requirements.txt: Installation dependencies in the official environment notebook: Notebook source code file docs: Markdown documentation file figures: Pictures data_base: Knowledge base source file used
graph-llm-asynchow-plan
Graph-enhanced Large Language Models in Asynchronous Plan Reasoning is a repository containing code and datasets for the ICML-2024 paper. It includes naturalistic datasets, code for generating data, benchmarking experiments, and prototypical experiments. The repository also offers a train/test-split version of the dataset on huggingface. The paper focuses on utilizing large language models with graph enhancements for asynchronous plan reasoning.
For similar tasks
local-assistant-examples
The Local Assistant Examples repository is a collection of educational examples showcasing the use of large language models (LLMs). It was initially created for a blog post on building a RAG model locally, and has since expanded to include more examples and educational material. Each example is housed in its own folder with a dedicated README providing instructions on how to run it. The repository is designed to be simple and educational, not for production use.
llms-from-scratch-rs
This project provides Rust code that follows the text 'Build An LLM From Scratch' by Sebastian Raschka. It translates PyTorch code into Rust using the Candle crate, aiming to build a GPT-style LLM. Users can clone the repo, run examples/exercises, and access the same datasets as in the book. The project includes chapters on understanding large language models, working with text data, coding attention mechanisms, implementing a GPT model, pretraining unlabeled data, fine-tuning for classification, and fine-tuning to follow instructions.

dstack
Dstack is an open-source orchestration engine for running AI workloads in any cloud. It supports a wide range of cloud providers (such as AWS, GCP, Azure, Lambda, TensorDock, Vast.ai, CUDO, RunPod, etc.) as well as on-premises infrastructure. With Dstack, you can easily set up and manage dev environments, tasks, services, and pools for your AI workloads.

one-click-llms
The one-click-llms repository provides templates for quickly setting up an API for language models. It includes advanced inferencing scripts for function calling and offers various models for text generation and fine-tuning tasks. Users can choose between Runpod and Vast.AI for different GPU configurations, with recommendations for optimal performance. The repository also supports Trelis Research and offers templates for different model sizes and types, including multi-modal APIs and chat models.

starcoder2-self-align
StarCoder2-Instruct is an open-source pipeline that introduces StarCoder2-15B-Instruct-v0.1, a self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. It generates instruction-response pairs to fine-tune StarCoder-15B without human annotations or data from proprietary LLMs. The tool is primarily finetuned for Python code generation tasks that can be verified through execution, with potential biases and limitations. Users can provide response prefixes or one-shot examples to guide the model's output. The model may have limitations with other programming languages and out-of-domain coding tasks.
enhance_llm
The enhance_llm repository contains three main parts: 1. Vector model domain fine-tuning based on llama_index and qwen fine-tuning BGE vector model. 2. Large model domain fine-tuning based on PEFT fine-tuning qwen1.5-7b-chat, with sft and dpo. 3. High-order retrieval enhanced generation (RAG) system based on the above domain work, implementing a two-stage RAG system. It includes query rewriting, recall reordering, retrieval reordering, multi-turn dialogue, and more. The repository also provides hardware and environment configurations along with star history and licensing information.
fms-fsdp
The 'fms-fsdp' repository is a companion to the Foundation Model Stack, providing a (pre)training example to efficiently train FMS models, specifically Llama2, using native PyTorch features like FSDP for training and SDPA implementation of Flash attention v2. It focuses on leveraging FSDP for training efficiently, not as an end-to-end framework. The repo benchmarks training throughput on different GPUs, shares strategies, and provides installation and training instructions. It trained a model on IBM curated data achieving high efficiency and performance metrics.

CogVLM2
CogVLM2 is a new generation of open source models that offer significant improvements in benchmarks such as TextVQA and DocVQA. It supports 8K content length, image resolution up to 1344 * 1344, and both Chinese and English languages. The project provides basic calling methods, fine-tuning examples, and OpenAI API format calling examples to help developers quickly get started with the model.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.