
starcoder2-self-align
StarCoder2-Instruct: Fully Transparent and Permissive Self-Alignment for Code Generation
Stars: 170

StarCoder2-Instruct is an open-source pipeline that introduces StarCoder2-15B-Instruct-v0.1, a self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. It generates instruction-response pairs to fine-tune StarCoder-15B without human annotations or data from proprietary LLMs. The tool is primarily finetuned for Python code generation tasks that can be verified through execution, with potential biases and limitations. Users can provide response prefixes or one-shot examples to guide the model's output. The model may have limitations with other programming languages and out-of-domain coding tasks.
README:
⭐️ About
| 🚀 Quick start
| 📚 Data generation
| 🧑💻 Training
| 📊 Evaluation
|

We introduce StarCoder2-15B-Instruct-v0.1, the very first entirely self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. Our open-source pipeline uses StarCoder2-15B to generate thousands of instruction-response pairs, which are then used to fine-tune StarCoder-15B itself without any human annotations or distilled data from huge and proprietary LLMs.
- Model: bigcode/starcoder2-15b-instruct-v0.1
- Code: bigcode-project/starcoder2-self-align
- Dataset: bigcode/self-oss-instruct-sc2-exec-filter-50k
- Authors: Yuxiang Wei, Federico Cassano, Jiawei Liu, Yifeng Ding, Naman Jain, Harm de Vries, Leandro von Werra, Arjun Guha, Lingming Zhang.

Here is an example to get started with StarCoder2-15B-Instruct-v0.1 using the transformers library:
import transformers
import torch
pipeline = transformers.pipeline(
model="bigcode/starcoder2-15b-instruct-v0.1",
task="text-generation",
torch_dtype=torch.bfloat16,
device_map="auto",
)
def respond(instruction: str, response_prefix: str) -> str:
messages = [{"role": "user", "content": instruction}]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False)
prompt += response_prefix
teminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("###"),
]
result = pipeline(
prompt,
max_length=256,
num_return_sequences=1,
do_sample=False,
eos_token_id=teminators,
pad_token_id=pipeline.tokenizer.eos_token_id,
truncation=True,
)
response = response_prefix + result[0]["generated_text"][len(prompt) :].split("###")[0].rstrip()
return response
instruction = "Write a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria."
response_prefix = ""
print(respond(instruction, response_prefix))Run
pip install -e .first to install the package locally. Check seed_gathering for details on how we collected the seeds.
We used vLLM's OpenAI compatible server for data generation. So, before running the following commands, make sure the vLLM server is running, and the associated openai environment variables are set.
For example, you can start an vLLM server with docker:
docker run --gpus '"device=0"' \
-v $HF_HOME:/root/.cache/huggingface \
-p 10000:8000 \
--ipc=host \
vllm/vllm-openai:v0.3.3 \
--model bigcode/starcoder2-15b \
--tensor-parallel-size 1 --dtype bfloat16And then set the environment variables as follows:
export OPENAI_API_KEY="EMPTY"
export OPENAI_BASE_URL="http://localhost:10000/v1/"Snippet to concepts generation
python src/star_align/self_ossinstruct.py \
--instruct_mode "S->C" \
--seed_data_files /path/to/seeds.jsonl \
--max_new_data 50000 \
--tag concept_gen \
--temperature 0.7 \
--seed_code_start_index 0 \
--model bigcode/starcoder2-15b \
--num_fewshots 8 \
--num_batched_requests 32 \
--num_sample_per_request 1Concepts to instruction generation
python src/star_align/self_ossinstruct.py \
--instruct_mode "C->I" \
--seed_data_files /path/to/concepts.jsonl \
--max_new_data 50000 \
--tag instruction_gen \
--temperature 0.7 \
--seed_code_start_index 0 \
--model bigcode/starcoder2-15b \
--num_fewshots 8 \
--num_sample_per_request 1 \
--num_batched_request 32Instruction to response (with self-validation code) generation
python src/star_align/self_ossinstruct.py \
--instruct_mode "I->R" \
--seed_data_files path/to/instructions.jsonl \
--max_new_data 50000 \
--tag response_gen \
--seed_code_start_index 0 \
--model bigcode/starcoder2-15b \
--num_fewshots 1 \
--num_batched_request 8 \
--num_sample_per_request 10 \
--temperature 0.7Execution filter
Warning: Though we implemented reliability guards, it is highly recommended to run execution in a sandbox environment. The command below doesn't provide sandboxing by default.
python src/star_align/execution_filter.py --response_path /path/to/response.jsonl --result_path /path/to/filtered.jsonl
# The current implementation may cause deadlock.
# If you encounter deadlock, manually do `ps -ef | grep execution_filter` and kill the stuck process.
# Note that filtered.jsonl may contain multiple passing samples for the same instruction which needs further selection.For using the the Docker container for executing code, you will first need to git submodule update --init --recursive to clone the server, then run:
pushd ./src/star_align/code_exec_server
./build_and_run.sh
popd
python src/star_align/execution_filter.py --response_path /path/to/response.jsonl --result_path /path/to/filtered.jsonl --container_server http://127.0.0.1:8000Data sanitization and selection
RAW=1 python src/star_align/sanitize_data.py /path/to/filtered.jsonl /path/to/sanitized.jsonl
python src/star_align/clean_data.py --data_files /path/to/sanitized.jsonl --output_file /path/to/sanitized.jsonl --diversify_func_names
SMART=1 python src/star_align/sanitize_data.py /path/to/sanitized.jsonl /path/to/sanitized.jsonlRun
pip install -e .first to install the package locally. And install Flash Attention to speed up the training.
- Optimizer: Adafactor
- Learning rate: 1e-5
- Epoch: 4
- Batch size: 64
- Warmup ratio: 0.05
- Scheduler: Linear
- Sequence length: 1280
- Dropout: Not applied
1 x NVIDIA A100 80GB. Yes, you just need one A100 to finetune StarCoder2-15B!
The following script finetunes StarCoder2-15B-Instruct-v0.1 from the base StarCoder2-15B model. /path/to/dataset.jsonl is the JSONL format of the 50k dataset we generated. You can dump the dataset to JSONL to fit the training script.
Click to see the training script
NOTE: StarCoder2-15B sets dropout values to 0.1 by default. We did not apply dropout in finetuning and thus set the them to 0.0.
MODEL_KEY=bigcode/starcoder2-15b
LR=1e-5
EPOCH=4
SEQ_LEN=1280
WARMUP_RATIO=0.05
OUTPUT_DIR=/path/to/output_model
DATASET_FILE=/path/to/50k-dataset.jsonl
accelerate launch -m star_align.train \
--model_key $MODEL_KEY \
--model_name_or_path $MODEL_KEY \
--use_flash_attention True \
--datafile_paths $DATASET_FILE \
--output_dir $OUTPUT_DIR \
--bf16 True \
--num_train_epochs $EPOCH \
--max_training_seq_length $SEQ_LEN \
--pad_to_max_length False \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 64 \
--group_by_length False \
--ddp_find_unused_parameters False \
--logging_steps 1 \
--log_level info \
--optim adafactor \
--max_grad_norm -1 \
--warmup_ratio $WARMUP_RATIO \
--learning_rate $LR \
--lr_scheduler_type linear \
--attention_dropout 0.0 \
--residual_dropout 0.0 \
--embedding_dropout 0.0Check evaluation for more details.
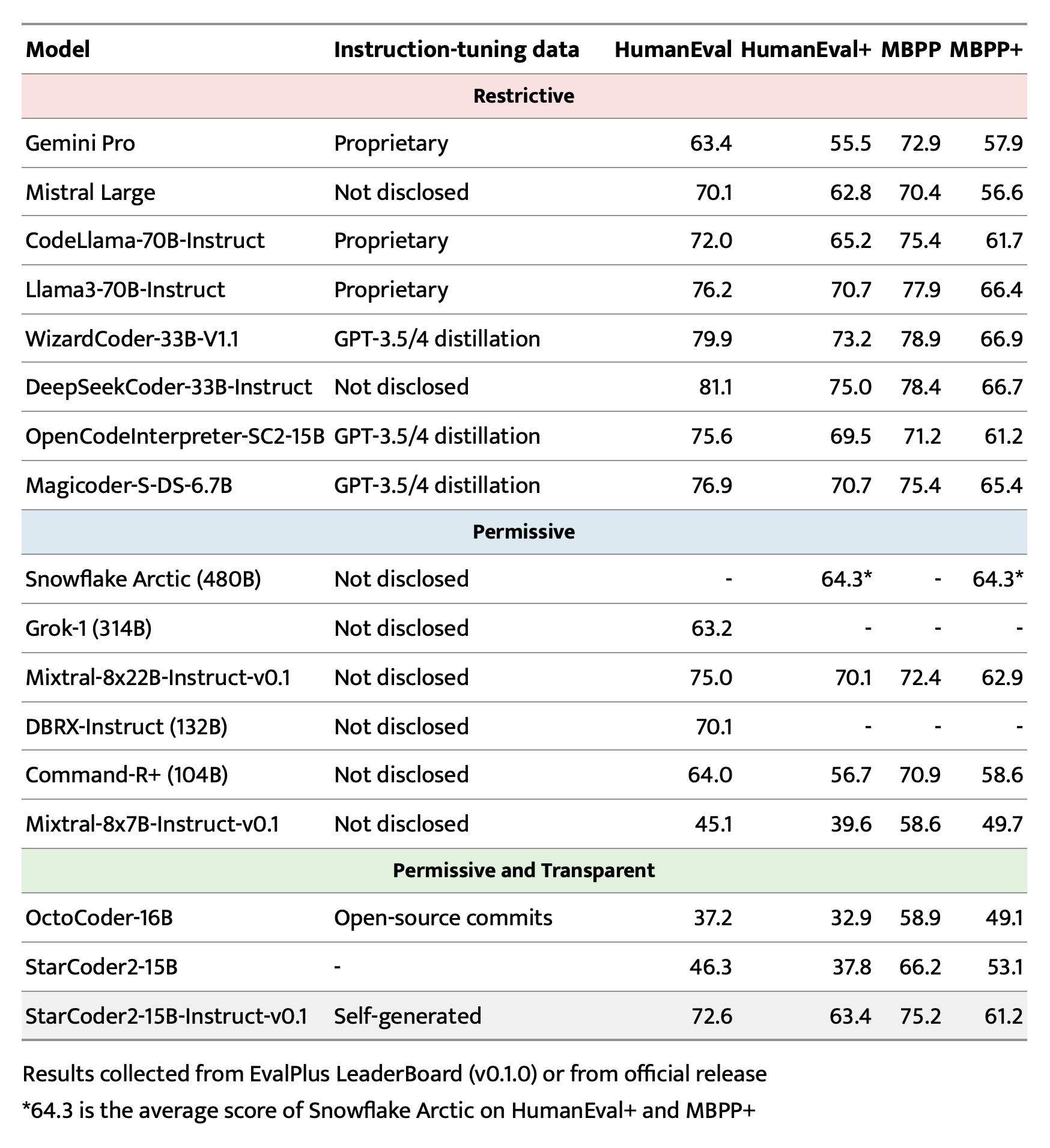
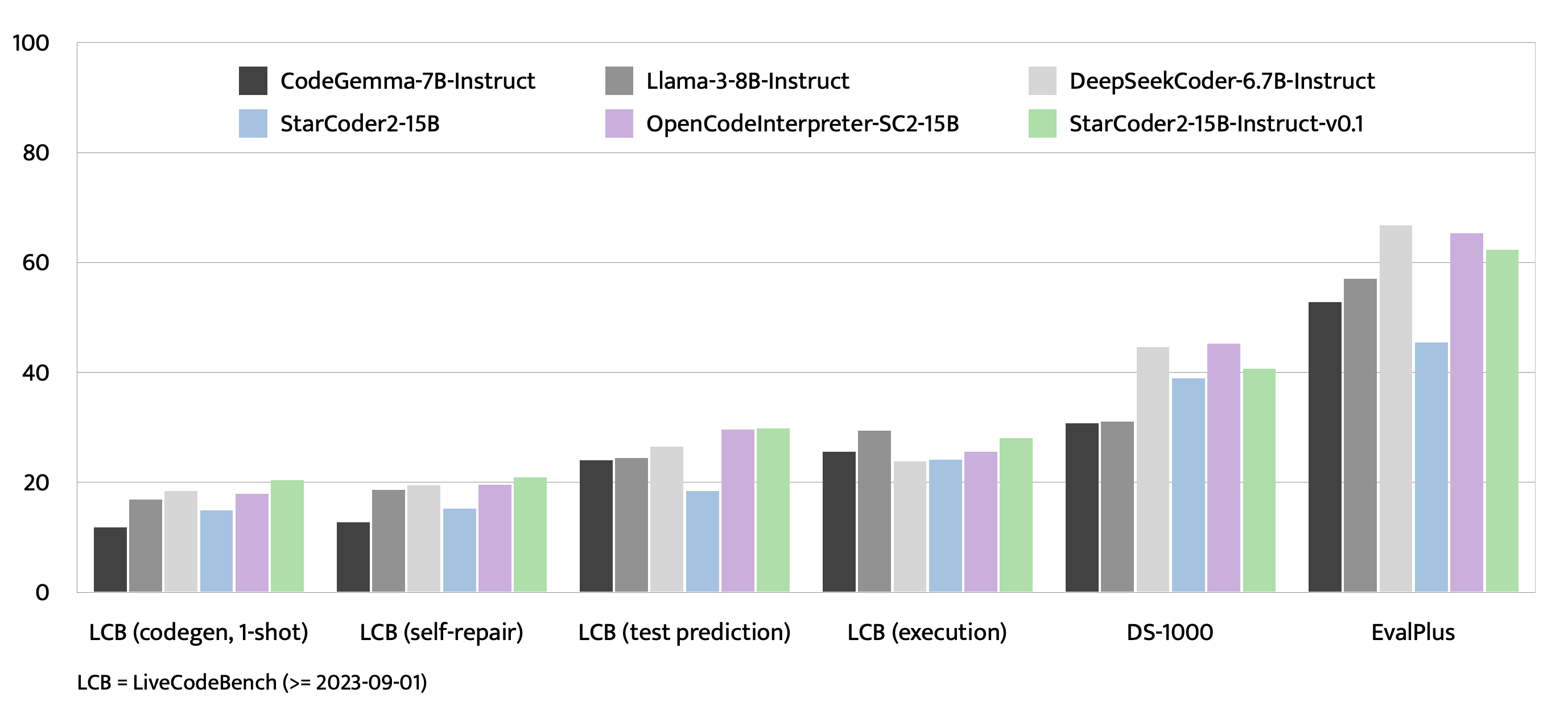
StarCoder2-15B-Instruct-v0.1 is primarily finetuned for Python code generation tasks that can be verified through execution, which may lead to certain biases and limitations. For example, the model might not adhere strictly to instructions that dictate the output format. In these situations, it's beneficial to provide a response prefix or a one-shot example to steer the model’s output. Additionally, the model may have limitations with other programming languages and out-of-domain coding tasks.
The model also inherits the bias, risks, and limitations from its base StarCoder2-15B model. For more information, please refer to the StarCoder2-15B model card.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for starcoder2-self-align
Similar Open Source Tools
starcoder2-self-align
StarCoder2-Instruct is an open-source pipeline that introduces StarCoder2-15B-Instruct-v0.1, a self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. It generates instruction-response pairs to fine-tune StarCoder-15B without human annotations or data from proprietary LLMs. The tool is primarily finetuned for Python code generation tasks that can be verified through execution, with potential biases and limitations. Users can provide response prefixes or one-shot examples to guide the model's output. The model may have limitations with other programming languages and out-of-domain coding tasks.

VLM-R1
VLM-R1 is a stable and generalizable R1-style Large Vision-Language Model proposed for Referring Expression Comprehension (REC) task. It compares R1 and SFT approaches, showing R1 model's steady improvement on out-of-domain test data. The project includes setup instructions, training steps for GRPO and SFT models, support for user data loading, and evaluation process. Acknowledgements to various open-source projects and resources are mentioned. The project aims to provide a reliable and versatile solution for vision-language tasks.

ragflow
RAGFlow is an open-source Retrieval-Augmented Generation (RAG) engine that combines deep document understanding with Large Language Models (LLMs) to provide accurate question-answering capabilities. It offers a streamlined RAG workflow for businesses of all sizes, enabling them to extract knowledge from unstructured data in various formats, including Word documents, slides, Excel files, images, and more. RAGFlow's key features include deep document understanding, template-based chunking, grounded citations with reduced hallucinations, compatibility with heterogeneous data sources, and an automated and effortless RAG workflow. It supports multiple recall paired with fused re-ranking, configurable LLMs and embedding models, and intuitive APIs for seamless integration with business applications.
langroid
Langroid is a Python framework that makes it easy to build LLM-powered applications. It uses a multi-agent paradigm inspired by the Actor Framework, where you set up Agents, equip them with optional components (LLM, vector-store and tools/functions), assign them tasks, and have them collaboratively solve a problem by exchanging messages. Langroid is a fresh take on LLM app-development, where considerable thought has gone into simplifying the developer experience; it does not use Langchain.

VITA
VITA is an open-source interactive omni multimodal Large Language Model (LLM) capable of processing video, image, text, and audio inputs simultaneously. It stands out with features like Omni Multimodal Understanding, Non-awakening Interaction, and Audio Interrupt Interaction. VITA can respond to user queries without a wake-up word, track and filter external queries in real-time, and handle various query inputs effectively. The model utilizes state tokens and a duplex scheme to enhance the multimodal interactive experience.
AutoRAG
AutoRAG is an AutoML tool designed to automatically find the optimal RAG pipeline for your data. It simplifies the process of evaluating various RAG modules to identify the best pipeline for your specific use-case. The tool supports easy evaluation of different module combinations, making it efficient to find the most suitable RAG pipeline for your needs. AutoRAG also offers a cloud beta version to assist users in running and optimizing the tool, along with building RAG evaluation datasets for a starting price of $9.99 per optimization.

CodeTF
CodeTF is a Python transformer-based library for code large language models (Code LLMs) and code intelligence. It provides an interface for training and inferencing on tasks like code summarization, translation, and generation. The library offers utilities for code manipulation across various languages, including easy extraction of code attributes. Using tree-sitter as its core AST parser, CodeTF enables parsing of function names, comments, and variable names. It supports fast model serving, fine-tuning of LLMs, various code intelligence tasks, preprocessed datasets, model evaluation, pretrained and fine-tuned models, and utilities to manipulate source code. CodeTF aims to facilitate the integration of state-of-the-art Code LLMs into real-world applications, ensuring a user-friendly environment for code intelligence tasks.
TheoremExplainAgent
TheoremExplainAgent is an AI system that generates long-form Manim videos to visually explain theorems, proving its deep understanding while uncovering reasoning flaws that text alone often hides. The codebase for the paper 'TheoremExplainAgent: Towards Multimodal Explanations for LLM Theorem Understanding' is available in this repository. It provides a tool for creating multimodal explanations for theorem understanding using AI technology.

swe-rl
SWE-RL is the official codebase for the paper 'SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution'. It is the first approach to scale reinforcement learning based LLM reasoning for real-world software engineering, leveraging open-source software evolution data and rule-based rewards. The code provides prompt templates and the implementation of the reward function based on sequence similarity. Agentless Mini, a part of SWE-RL, builds on top of Agentless with improvements like fast async inference, code refactoring for scalability, and support for using multiple reproduction tests for reranking. The tool can be used for localization, repair, and reproduction test generation in software engineering tasks.

volga
Volga is a general purpose real-time data processing engine in Python for modern AI/ML systems. It aims to be a Python-native alternative to Flink/Spark Streaming with extended functionality for real-time AI/ML workloads. It provides a hybrid push+pull architecture, Entity API for defining data entities and feature pipelines, DataStream API for general data processing, and customizable data connectors. Volga can run on a laptop or a distributed cluster, making it suitable for building custom real-time AI/ML feature platforms or general data pipelines without relying on third-party platforms.

consult-llm-mcp
Consult LLM MCP is an MCP server that enables users to consult powerful AI models like GPT-5.2, Gemini 3.0 Pro, and DeepSeek Reasoner for complex problem-solving. It supports multi-turn conversations, direct queries with optional file context, git changes inclusion for code review, comprehensive logging with cost estimation, and various CLI modes for Gemini and Codex. The tool is designed to simplify the process of querying AI models for assistance in resolving coding issues and improving code quality.

Acontext
Acontext is a context data platform designed for production AI agents, offering unified storage, built-in context management, and observability features. It helps agents scale from local demos to production without the need to rebuild context infrastructure. The platform provides solutions for challenges like scattered context data, long-running agents requiring context management, and tracking states from multi-modal agents. Acontext offers core features such as context storage, session management, disk storage, agent skills management, and sandbox for code execution and analysis. Users can connect to Acontext, install SDKs, initialize clients, store and retrieve messages, perform context engineering, and utilize agent storage tools. The platform also supports building agents using end-to-end scripts in Python and Typescript, with various templates available. Acontext's architecture includes client layer, backend with API and core components, infrastructure with PostgreSQL, S3, Redis, and RabbitMQ, and a web dashboard. Join the Acontext community on Discord and follow updates on GitHub.

HuixiangDou
HuixiangDou is a **group chat** assistant based on LLM (Large Language Model). Advantages: 1. Design a two-stage pipeline of rejection and response to cope with group chat scenario, answer user questions without message flooding, see arxiv2401.08772 2. Low cost, requiring only 1.5GB memory and no need for training 3. Offers a complete suite of Web, Android, and pipeline source code, which is industrial-grade and commercially viable Check out the scenes in which HuixiangDou are running and join WeChat Group to try AI assistant inside. If this helps you, please give it a star ⭐

DeepResearch
Tongyi DeepResearch is an agentic large language model with 30.5 billion total parameters, designed for long-horizon, deep information-seeking tasks. It demonstrates state-of-the-art performance across various search benchmarks. The model features a fully automated synthetic data generation pipeline, large-scale continual pre-training on agentic data, end-to-end reinforcement learning, and compatibility with two inference paradigms. Users can download the model directly from HuggingFace or ModelScope. The repository also provides benchmark evaluation scripts and information on the Deep Research Agent Family.
llm-detect-ai
This repository contains code and configurations for the LLM - Detect AI Generated Text competition. It includes setup instructions for hardware, software, dependencies, and datasets. The training section covers scripts and configurations for training LLM models, DeBERTa ranking models, and an embedding model. Text generation section details fine-tuning LLMs using the CLM objective on the PERSUADE corpus to generate student-like essays.
dspy.rb
DSPy.rb is a Ruby framework for building reliable LLM applications using composable, type-safe modules. It enables developers to define typed signatures and compose them into pipelines, offering a more structured approach compared to traditional prompting. The framework embraces Ruby conventions and adds innovations like CodeAct agents and enhanced production instrumentation, resulting in scalable LLM applications that are robust and efficient. DSPy.rb is actively developed, with a focus on stability and real-world feedback through the 0.x series before reaching a stable v1.0 API.
For similar tasks

dstack
Dstack is an open-source orchestration engine for running AI workloads in any cloud. It supports a wide range of cloud providers (such as AWS, GCP, Azure, Lambda, TensorDock, Vast.ai, CUDO, RunPod, etc.) as well as on-premises infrastructure. With Dstack, you can easily set up and manage dev environments, tasks, services, and pools for your AI workloads.

one-click-llms
The one-click-llms repository provides templates for quickly setting up an API for language models. It includes advanced inferencing scripts for function calling and offers various models for text generation and fine-tuning tasks. Users can choose between Runpod and Vast.AI for different GPU configurations, with recommendations for optimal performance. The repository also supports Trelis Research and offers templates for different model sizes and types, including multi-modal APIs and chat models.
starcoder2-self-align
StarCoder2-Instruct is an open-source pipeline that introduces StarCoder2-15B-Instruct-v0.1, a self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. It generates instruction-response pairs to fine-tune StarCoder-15B without human annotations or data from proprietary LLMs. The tool is primarily finetuned for Python code generation tasks that can be verified through execution, with potential biases and limitations. Users can provide response prefixes or one-shot examples to guide the model's output. The model may have limitations with other programming languages and out-of-domain coding tasks.
enhance_llm
The enhance_llm repository contains three main parts: 1. Vector model domain fine-tuning based on llama_index and qwen fine-tuning BGE vector model. 2. Large model domain fine-tuning based on PEFT fine-tuning qwen1.5-7b-chat, with sft and dpo. 3. High-order retrieval enhanced generation (RAG) system based on the above domain work, implementing a two-stage RAG system. It includes query rewriting, recall reordering, retrieval reordering, multi-turn dialogue, and more. The repository also provides hardware and environment configurations along with star history and licensing information.
fms-fsdp
The 'fms-fsdp' repository is a companion to the Foundation Model Stack, providing a (pre)training example to efficiently train FMS models, specifically Llama2, using native PyTorch features like FSDP for training and SDPA implementation of Flash attention v2. It focuses on leveraging FSDP for training efficiently, not as an end-to-end framework. The repo benchmarks training throughput on different GPUs, shares strategies, and provides installation and training instructions. It trained a model on IBM curated data achieving high efficiency and performance metrics.

CogVLM2
CogVLM2 is a new generation of open source models that offer significant improvements in benchmarks such as TextVQA and DocVQA. It supports 8K content length, image resolution up to 1344 * 1344, and both Chinese and English languages. The project provides basic calling methods, fine-tuning examples, and OpenAI API format calling examples to help developers quickly get started with the model.

liboai
liboai is a simple C++17 library for the OpenAI API, providing developers with access to OpenAI endpoints through a collection of methods and classes. It serves as a spiritual port of OpenAI's Python library, 'openai', with similar structure and features. The library supports various functionalities such as ChatGPT, Audio, Azure, Functions, Image DALL·E, Models, Completions, Edit, Embeddings, Files, Fine-tunes, Moderation, and Asynchronous Support. Users can easily integrate the library into their C++ projects to interact with OpenAI services.

extension-gen-ai
The Looker GenAI Extension provides code examples and resources for building a Looker Extension that integrates with Vertex AI Large Language Models (LLMs). Users can leverage the power of LLMs to enhance data exploration and analysis within Looker. The extension offers generative explore functionality to ask natural language questions about data and generative insights on dashboards to analyze data by asking questions. It leverages components like BQML Remote Models, BQML Remote UDF with Vertex AI, and Custom Fine Tune Model for different integration options. Deployment involves setting up infrastructure with Terraform and deploying the Looker Extension by creating a Looker project, copying extension files, configuring BigQuery connection, connecting to Git, and testing the extension. Users can save example prompts and configure user settings for the extension. Development of the Looker Extension environment includes installing dependencies, starting the development server, and building for production.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.