
one-click-llms
One click templates for inferencing Language Models
Stars: 139

The one-click-llms repository provides templates for quickly setting up an API for language models. It includes advanced inferencing scripts for function calling and offers various models for text generation and fine-tuning tasks. Users can choose between Runpod and Vast.AI for different GPU configurations, with recommendations for optimal performance. The repository also supports Trelis Research and offers templates for different model sizes and types, including multi-modal APIs and chat models.
README:
[!TIP] Deepseek v3 and Llama 3.3 70B are now supported. NEW: You can also now run on an AMD MI300X - see SGLang below!
[!TIP] Post a new issue if you would like other templates. Quickly boot up an API endpoint for a given language, vision or speech/transcription model.
Built by Trelis Research YouTube, Newsletter, Inferencing Scripts
[!TIP] To support the Trelis Research YouTube channel, you can sign up for an account with this link. Trelis is supported by a commission when you use one-click templates.
GPU Choices/Recommendations (last updated Oct 15 2024):
- VALUE and best UI: A40 on Runpod (48 GB VRAM) ~$0.39/hr.
- Higher Speed: H100 PCI or SXM (80 GB VRAM) - best for fp8 models, but expensive.
- CUDA 12.1 one-click template here
- [Transcription] Faster Whisper Server (Transcription only)
- [LLMs] SGLang is the fastest across all batch sizes.
- [LLMs and Multi-modal LLMs] vLLM and TGI are close on speed for small batches.
- [Multi-modal LLM] Moondream API (tiny vision + text language model).
- [LLMs] Nvidia NIM (paid service from Nvidia): a bit slower than SGLang. Also inconvenient to use as it requires login.
- Deepseek v3 FP8 - Nvidia - WARNING: takes ~30 mins to download + load shards onto 8X H100 (~140 GB). Should also work on 8X H200 (~140 GB) and allow for longer context.
- Deepseek v3 FP8 - ROCM/AMD - WARNING - not validated yet as working. Takes ~1-1.5 hours to download + load shards onto 8X MI300X. Gives ~ toks.
- Llama 3.1 Instruct 8B FP8 - ROCM/AMD
- Qwen 2.5 Coder 32B
- Llama 3.1 Instruct 8B FP8, Llama 3.1 Instruct 70B FP8, Llama 3.1 Instruct 70B INT4, Llama 3.1 Instruct 405B FP8, Llama 3.1 Instruct 405B INT4
- Llama 3.1 8B multi-lora server
- Llama 3.3 70B in fp8.
- Phi 4: fp8 - Runs at ~32 toks on an A40. bf16 Runs at ~17 toks on an A40.
- Qwen 2 Audio 7B
- Qwen 2 VL 2B, Qwen 2 VL 7B, Qwen 2 VL 70B
- Llama 3.2 Vision
- Pixtral
- Llama 3.1 Instruct 8B, Llama 3.1 Instruct 70B, Llama 3.1 Instruct FP8 405B, Llama 3.1 Instruct INT4 405B
- Phi 3 Mini, Phi 3 Small, Phi 3 Medium
- Mistral Nemo Instruct (fp8)
- Llama 3 8B Instruct
- Llama 3 70B Instruct
- Mistral Instruct 7B AWQ
- Mixtral Instruct 8x7B AWQ
- Qwen1.5 Chat 72B AWQ. Needs to be run on an A100 or H100. The 48 GB of VRAM on an A6000 is insufficient.
- CodeLlama 70B Instruct - 4bit AWQ. Requires an A6000 or A100 or H100.
[!IMPORTANT] Note: vLLM runs into issues sometimes if the pod template does not have the correct CUDA drivers. Unfortunately there is no way to know when picking a GPU. An issue has been raised here. As an alternative, you can run TGI (and even query in openai style, guide here). TGI is faster than vLLM and recommended in general. Note however, that TGI does not automatically apply the chat template to the prompt when using the OpenAI style endpoint.
- Llama 3.1 8B
- IDEFICS 2 8B multi-modal
- Llama 3 - 8B Instruct
- Llama 3 - 70B Instruct
- OpenChat 3.5 7B AWQ API - RECOMMENDED, OpenChat 3.5 7B bf16 - TGI API - lowest perplexity
- Mixtral Instruct API 4bit AWQ - RECOMMENDED, Mixtral Instruct API 8bit eetq, pod needs to be restarted multiple times to download all weights. Requires an A6000 or A100 or H100.
- Zephyr 141B - a Mixtral 8x22B fine-tune
- DRBX Instruct
- Smaug 34B Chat (a Yi fine-tune) - fits in bf16 on an A100. BEWARE that guardrails are weaker on this model than Yi. As such, it may be best suited for structured generation
-
TowerInstruct 13B (multi-lingual Llama 2 fine-tune) - needs ~30 GB to run in bf16 (fits on an A6000). Add
--quantize eetqto run with under 15 GB of VRAM (e.g. A6000). - Yi 34B Chat - fits in 16-bit on an A100
- Gemma Chat 9B.
- Notux 8x7B AWQ. Requires an A6000 or A100 or H100.
- CodeLlama 70B Instruct - 4bit AWQ, CodeLlama 70B Instruct - 4bit bitsandbytes. Requires an A6000 or A100 or H100.
- Mamba Instruct OpenHermes
- [Llama 70B API by TrelisResearch - DEPRECATED - USE LLAMA 3.1 TEMPLATES].
- Deepseek Coder 33B Template.
- Medusa Vicuna (high speed speculative decoding - mostly a glamour template because OpenChat with AWQ is better quality and faster)
- Llama 3.1 8B - 4_K_M
- Mistral Nemo Instruct - pending llama cpp support
- Mistral 7B Instruct v0.2 8-bit
[!TIP] As of July 23rd 2024, function calling fine-tuned models are being deprecated in favour of a one-shot approach with stronger models. Find the "Tool Use" video on the Trelis YouTube Channel for more info.
15Oct2024:
- Add whisper turbo endpoint
- Deprecate Vast.AI templates.
20Jul2023:
- Update the ./llama-server.sh command in line with breaking changes to llama.cpp
Feb 16 2023:
- Added a Mamba one click template.
Jan 21 2023:
- Swapped Runpod to before Vast.AI as user experience is much better with Runpod.
Jan 9 2023:
- Added Mixtral Instruct AWQ TGI
Dec 30 2023:
- Support gated models by adding HUGGING_FACE_HUB_TOKEN env variable.
- Speed up downloading using HuggingFace API.
Dec 29 2023:
- Add in one-click llama.cpp server template.
[!TIP] To support the Trelis Research YouTube channel, you can sign up for an account with this affiliate link. Trelis is supported by a commission when you use one-click templates.
- CUDA 12.1 one-click template here.
- Mistral 7B v0.2 AWQ
- Post a new issue if you would like other templates
One-click templates for function-calling are located on the HuggingFace model cards. Check out the collection here.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for one-click-llms
Similar Open Source Tools
one-click-llms
The one-click-llms repository provides templates for quickly setting up an API for language models. It includes advanced inferencing scripts for function calling and offers various models for text generation and fine-tuning tasks. Users can choose between Runpod and Vast.AI for different GPU configurations, with recommendations for optimal performance. The repository also supports Trelis Research and offers templates for different model sizes and types, including multi-modal APIs and chat models.
SecureAI-Tools
SecureAI Tools is a private and secure AI tool that allows users to chat with AI models, chat with documents (PDFs), and run AI models locally. It comes with built-in authentication and user management, making it suitable for family members or coworkers. The tool is self-hosting optimized and provides necessary scripts and docker-compose files for easy setup in under 5 minutes. Users can customize the tool by editing the .env file and enabling GPU support for faster inference. SecureAI Tools also supports remote OpenAI-compatible APIs, with lower hardware requirements for using remote APIs only. The tool's features wishlist includes chat sharing, mobile-friendly UI, and support for more file types and markdown rendering.
LocalAIVoiceChat
LocalAIVoiceChat is an experimental alpha software that enables real-time voice chat with a customizable AI personality and voice on your PC. It integrates Zephyr 7B language model with speech-to-text and text-to-speech libraries. The tool is designed for users interested in state-of-the-art voice solutions and provides an early version of a local real-time chatbot.

Stable-Diffusion-Android
Stable Diffusion AI is an easy-to-use app for generating images from text or other images. It allows communication with servers powered by various AI technologies like AI Horde, Hugging Face Inference API, OpenAI, StabilityAI, and LocalDiffusion. The app supports Txt2Img and Img2Img modes, positive and negative prompts, dynamic size and sampling methods, unique seed input, and batch image generation. Users can also inpaint images, select faces from gallery or camera, and export images. The app offers settings for server URL, SD Model selection, auto-saving images, and clearing cache.

DevoxxGenieIDEAPlugin
Devoxx Genie is a Java-based IntelliJ IDEA plugin that integrates with local and cloud-based LLM providers to aid in reviewing, testing, and explaining project code. It supports features like code highlighting, chat conversations, and adding files/code snippets to context. Users can modify REST endpoints and LLM parameters in settings, including support for cloud-based LLMs. The plugin requires IntelliJ version 2023.3.4 and JDK 17. Building and publishing the plugin is done using Gradle tasks. Users can select an LLM provider, choose code, and use commands like review, explain, or generate unit tests for code analysis.
ChatterUI
ChatterUI is a mobile app that allows users to manage chat files and character cards, and to interact with Large Language Models (LLMs). It supports multiple backends, including local, koboldcpp, text-generation-webui, Generic Text Completions, AI Horde, Mancer, Open Router, and OpenAI. ChatterUI provides a mobile-friendly interface for interacting with LLMs, making it easy to use them for a variety of tasks, such as generating text, translating languages, writing code, and answering questions.

QodeAssist
QodeAssist is an AI-powered coding assistant plugin for Qt Creator, offering intelligent code completion and suggestions for C++ and QML. It leverages large language models like Ollama to enhance coding productivity with context-aware AI assistance directly in the Qt development environment. The plugin supports multiple LLM providers, extensive model-specific templates, and easy configuration for enhanced coding experience.
upscayl
Upscayl is a free and open-source AI image upscaler that uses advanced AI algorithms to enlarge and enhance low-resolution images without losing quality. It is a cross-platform application built with the Linux-first philosophy, available on all major desktop operating systems. Upscayl utilizes Real-ESRGAN and Vulkan architecture for image enhancement, and its backend is fully open-source under the AGPLv3 license. It is important to note that a Vulkan compatible GPU is required for Upscayl to function effectively.

Easy-Voice-Toolkit
Easy Voice Toolkit is a toolkit based on open source voice projects, providing automated audio tools including speech model training. Users can seamlessly integrate functions like audio processing, voice recognition, voice transcription, dataset creation, model training, and voice conversion to transform raw audio files into ideal speech models. The toolkit supports multiple languages and is currently only compatible with Windows systems. It acknowledges the contributions of various projects and offers local deployment options for both users and developers. Additionally, cloud deployment on Google Colab is available. The toolkit has been tested on Windows OS devices and includes a FAQ section and terms of use for academic exchange purposes.

llm-answer-engine
This repository contains the code and instructions needed to build a sophisticated answer engine that leverages the capabilities of Groq, Mistral AI's Mixtral, Langchain.JS, Brave Search, Serper API, and OpenAI. Designed to efficiently return sources, answers, images, videos, and follow-up questions based on user queries, this project is an ideal starting point for developers interested in natural language processing and search technologies.

macai
Macai is a native macOS client for interacting with modern AI tools, such as ChatGPT and Ollama. It features organized chats with custom system messages, system-defined light/dark themes, backup and restore functionality, customizable context size, support for any model with a compatible API, formatted code blocks and tables, multiple chat tabs, CoreData data storage, streamed responses, and automatic chat name generation. Macai is in active development, with contributions welcome.
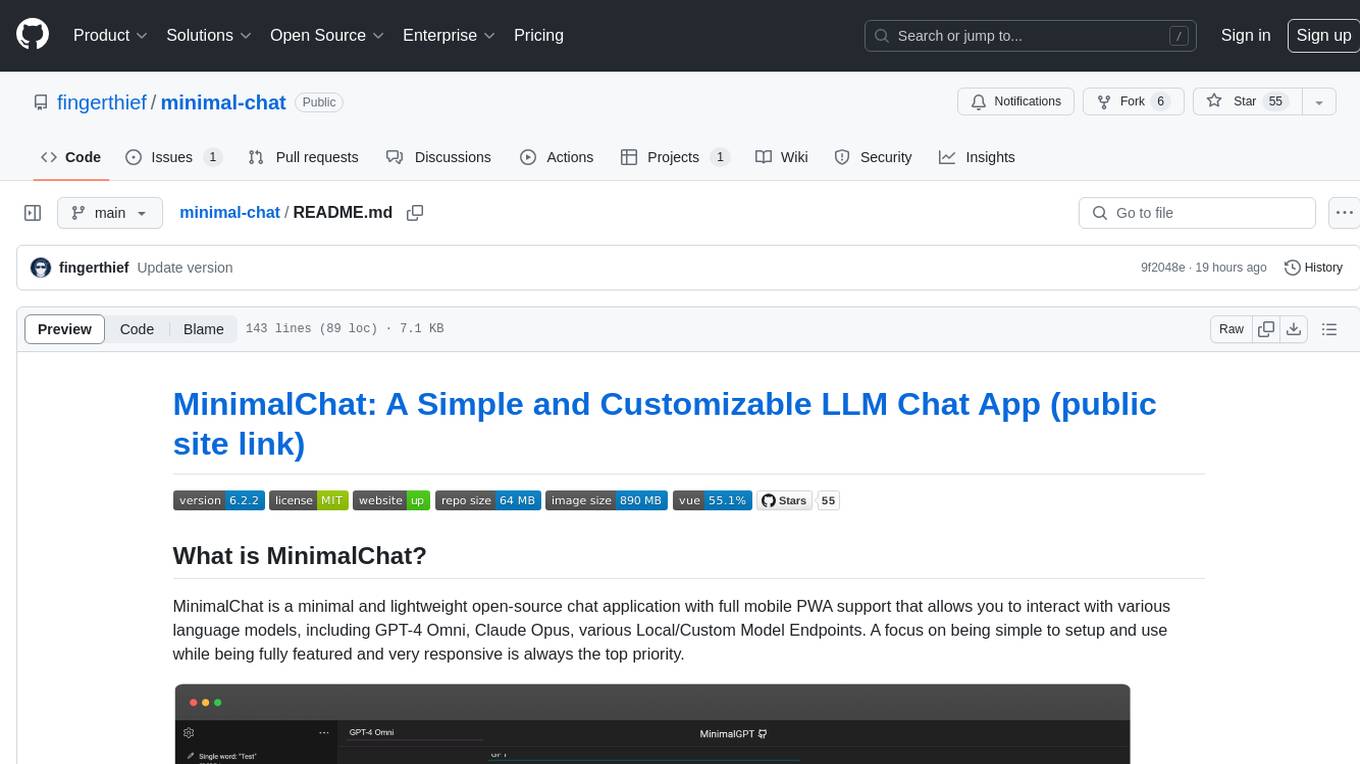
minimal-chat
MinimalChat is a minimal and lightweight open-source chat application with full mobile PWA support that allows users to interact with various language models, including GPT-4 Omni, Claude Opus, and various Local/Custom Model Endpoints. It focuses on simplicity in setup and usage while being fully featured and highly responsive. The application supports features like fully voiced conversational interactions, multiple language models, markdown support, code syntax highlighting, DALL-E 3 integration, conversation importing/exporting, and responsive layout for mobile use.
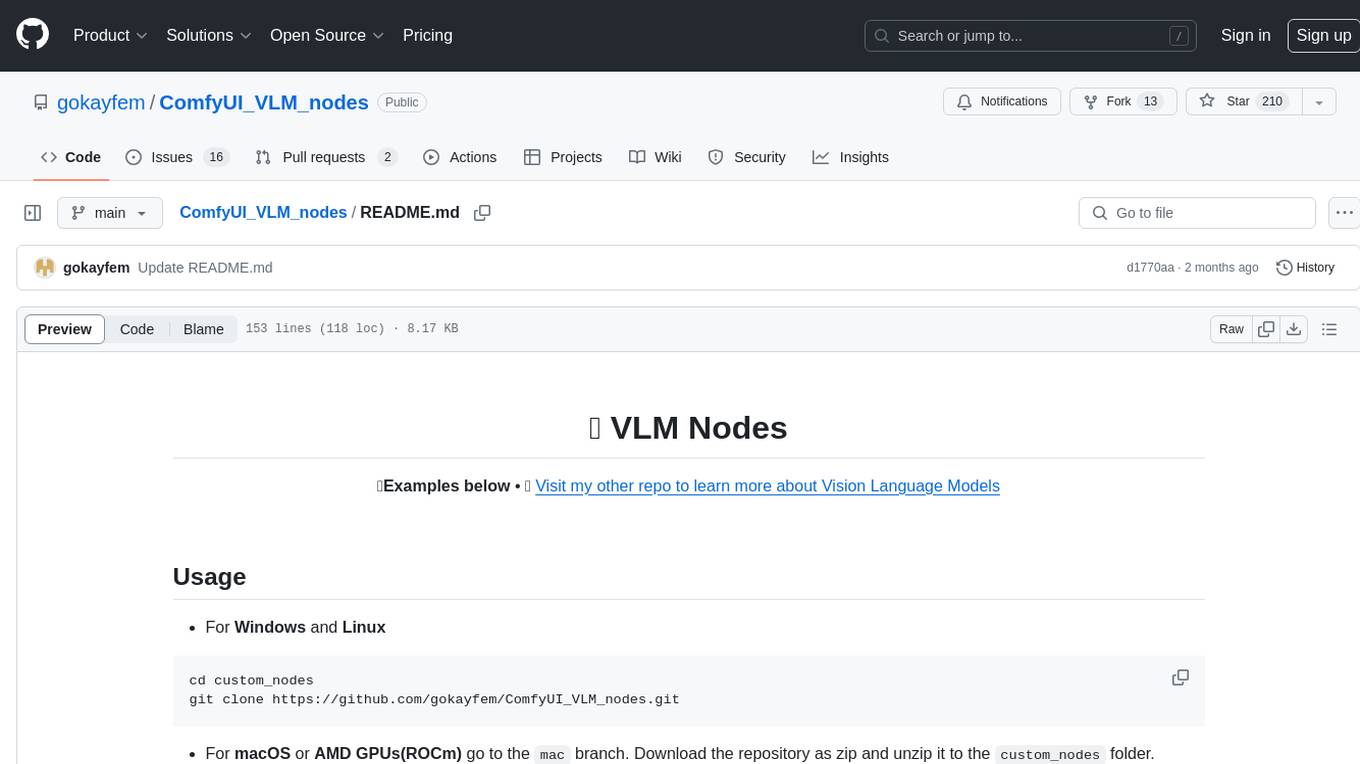
ComfyUI_VLM_nodes
ComfyUI_VLM_nodes is a repository containing various nodes for utilizing Vision Language Models (VLMs) and Language Models (LLMs). The repository provides nodes for tasks such as structured output generation, image to music conversion, LLM prompt generation, automatic prompt generation, and more. Users can integrate different models like InternLM-XComposer2-VL, UForm-Gen2, Kosmos-2, moondream1, moondream2, JoyTag, and Chat Musician. The nodes support features like extracting keywords, generating prompts, suggesting prompts, and obtaining structured outputs. The repository includes examples and instructions for using the nodes effectively.
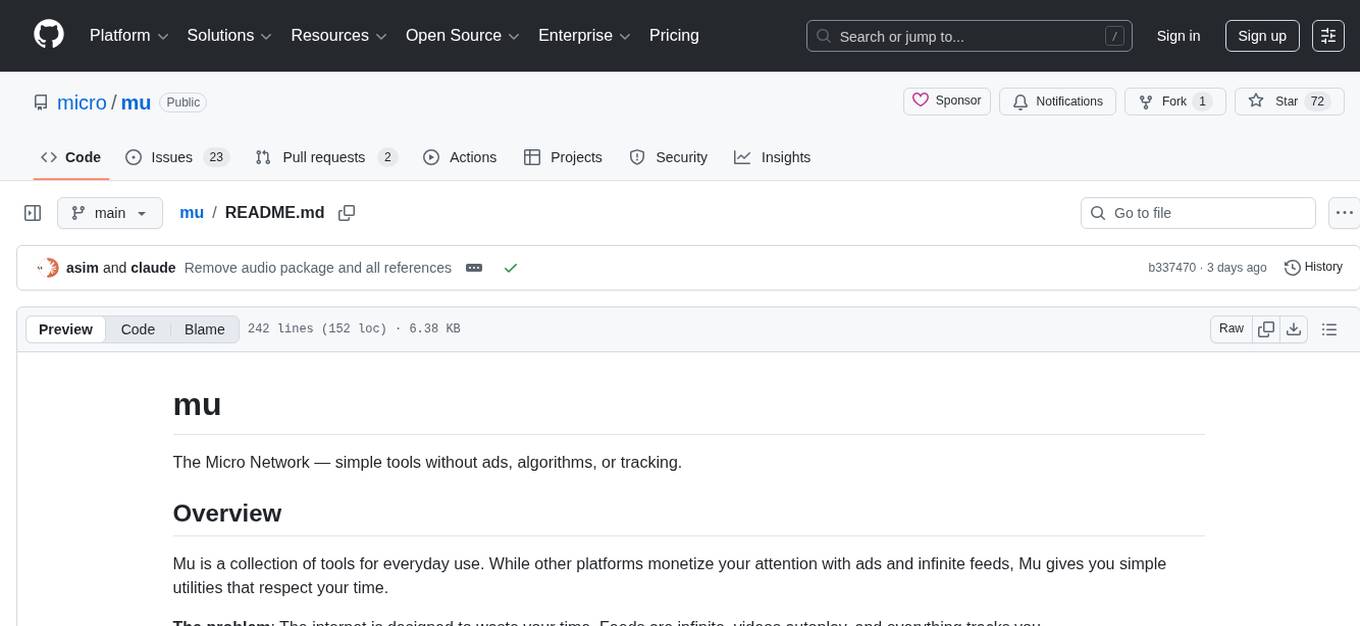
mu
Mu is a collection of simple tools for everyday use that respect users' time by providing utilities without ads, algorithms, or tracking. It includes features like personalized dashboard, microblogging, AI-powered chat, RSS feeds with AI summaries, ad-free YouTube viewing, private messaging & email, and crypto payments. Users can self-host Mu or use the hosted version at mu.xyz. The tools are designed to be small, focused, and do one thing well, enhancing some features with AI capabilities like auto-tagging topics, summarizing articles, and providing knowledge assistance.
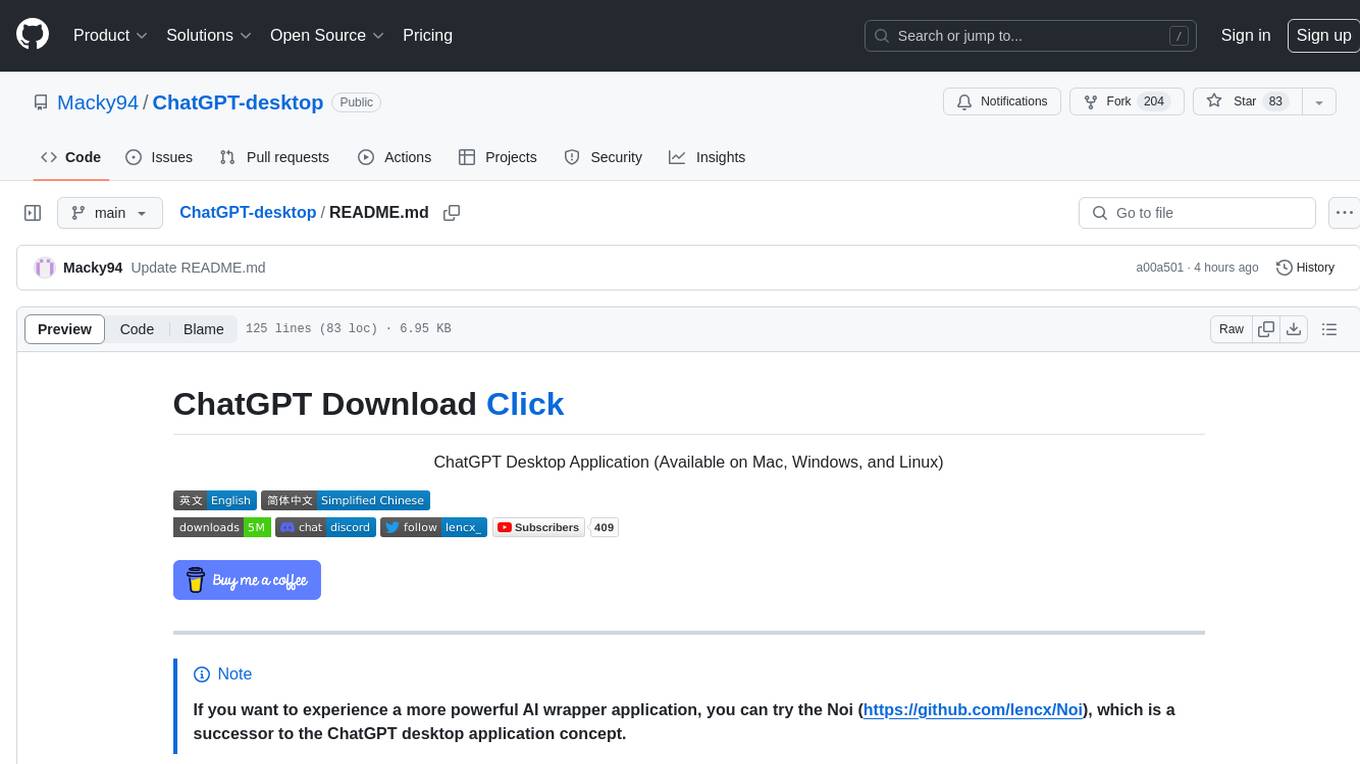
ChatGPT-desktop
ChatGPT Desktop Application is a multi-platform tool that provides a powerful AI wrapper for generating text. It offers features like text-to-speech, exporting chat history in various formats, automatic application upgrades, system tray hover window, support for slash commands, customization of global shortcuts, and pop-up search. The application is built using Tauri and aims to enhance user experience by simplifying text generation tasks. It is available for Mac, Windows, and Linux, and is designed for personal learning and research purposes.
colors_ai
Colors AI is a cross-platform color scheme generator that uses deep learning from public API providers. It is available for all mainstream operating systems, including mobile. Features: - Choose from open APIs, with the ability to set up custom settings - Export section with many export formats to save or clipboard copy - URL providers to other static color generators - Localized to several languages - Dark and light theme - Material Design 3 - Data encryption - Accessibility - And much more
For similar tasks
gorilla
Gorilla is a tool that enables LLMs to use tools by invoking APIs. Given a natural language query, Gorilla comes up with the semantically- and syntactically- correct API to invoke. With Gorilla, you can use LLMs to invoke 1,600+ (and growing) API calls accurately while reducing hallucination. Gorilla also releases APIBench, the largest collection of APIs, curated and easy to be trained on!
one-click-llms
The one-click-llms repository provides templates for quickly setting up an API for language models. It includes advanced inferencing scripts for function calling and offers various models for text generation and fine-tuning tasks. Users can choose between Runpod and Vast.AI for different GPU configurations, with recommendations for optimal performance. The repository also supports Trelis Research and offers templates for different model sizes and types, including multi-modal APIs and chat models.
awesome-llm-json
This repository is an awesome list dedicated to resources for using Large Language Models (LLMs) to generate JSON or other structured outputs. It includes terminology explanations, hosted and local models, Python libraries, blog articles, videos, Jupyter notebooks, and leaderboards related to LLMs and JSON generation. The repository covers various aspects such as function calling, JSON mode, guided generation, and tool usage with different providers and models.
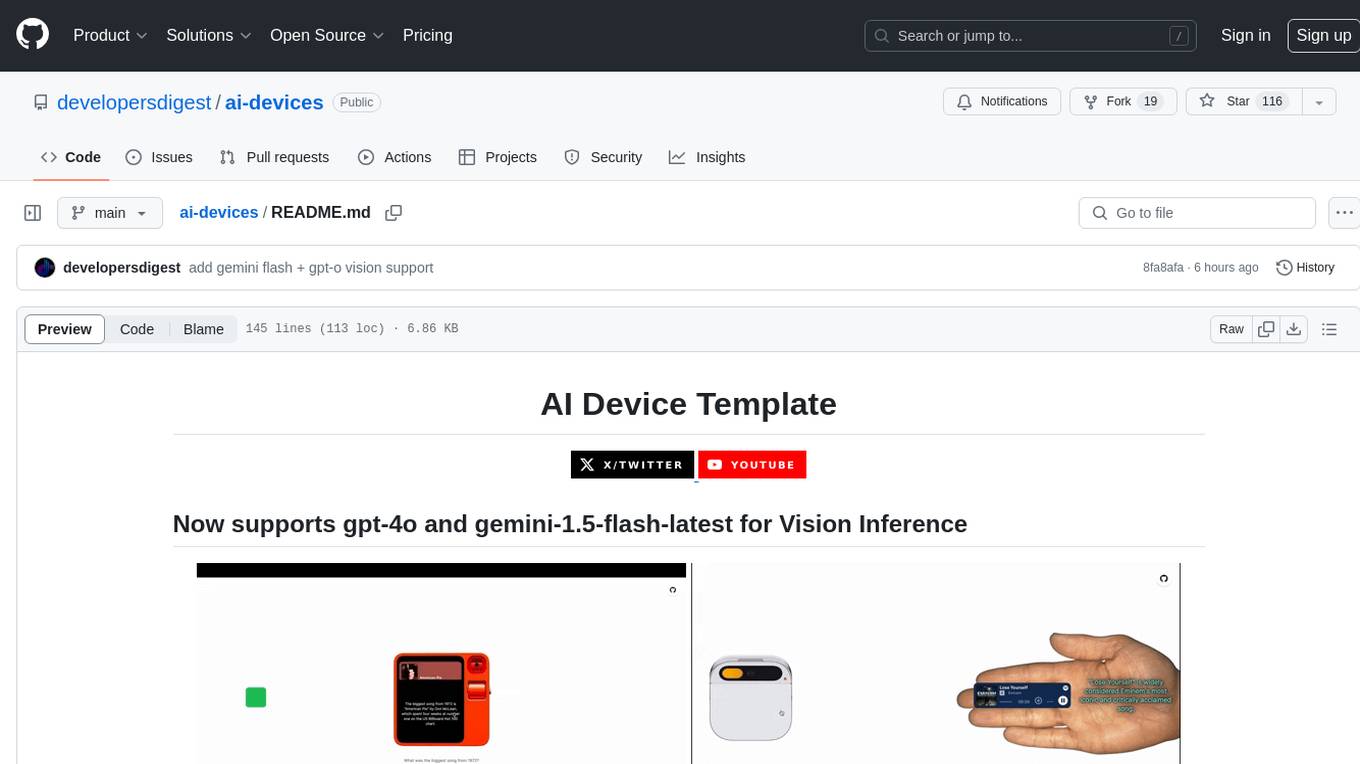
ai-devices
AI Devices Template is a project that serves as an AI-powered voice assistant utilizing various AI models and services to provide intelligent responses to user queries. It supports voice input, transcription, text-to-speech, image processing, and function calling with conditionally rendered UI components. The project includes customizable UI settings, optional rate limiting using Upstash, and optional tracing with Langchain's LangSmith for function execution. Users can clone the repository, install dependencies, add API keys, start the development server, and deploy the application. Configuration settings can be modified in `app/config.tsx` to adjust settings and configurations for the AI-powered voice assistant.

ragtacts
Ragtacts is a Clojure library that allows users to easily interact with Large Language Models (LLMs) such as OpenAI's GPT-4. Users can ask questions to LLMs, create question templates, call Clojure functions in natural language, and utilize vector databases for more accurate answers. Ragtacts also supports RAG (Retrieval-Augmented Generation) method for enhancing LLM output by incorporating external data. Users can use Ragtacts as a CLI tool, API server, or through a RAG Playground for interactive querying.

DelphiOpenAI
Delphi OpenAI API is an unofficial library providing Delphi implementation over OpenAI public API. It allows users to access various models, make completions, chat conversations, generate images, and call functions using OpenAI service. The library aims to facilitate tasks such as content generation, semantic search, and classification through AI models. Users can fine-tune models, work with natural language processing, and apply reinforcement learning methods for diverse applications.
token.js
Token.js is a TypeScript SDK that integrates with over 200 LLMs from 10 providers using OpenAI's format. It allows users to call LLMs, supports tools, JSON outputs, image inputs, and streaming, all running on the client side without the need for a proxy server. The tool is free and open source under the MIT license.
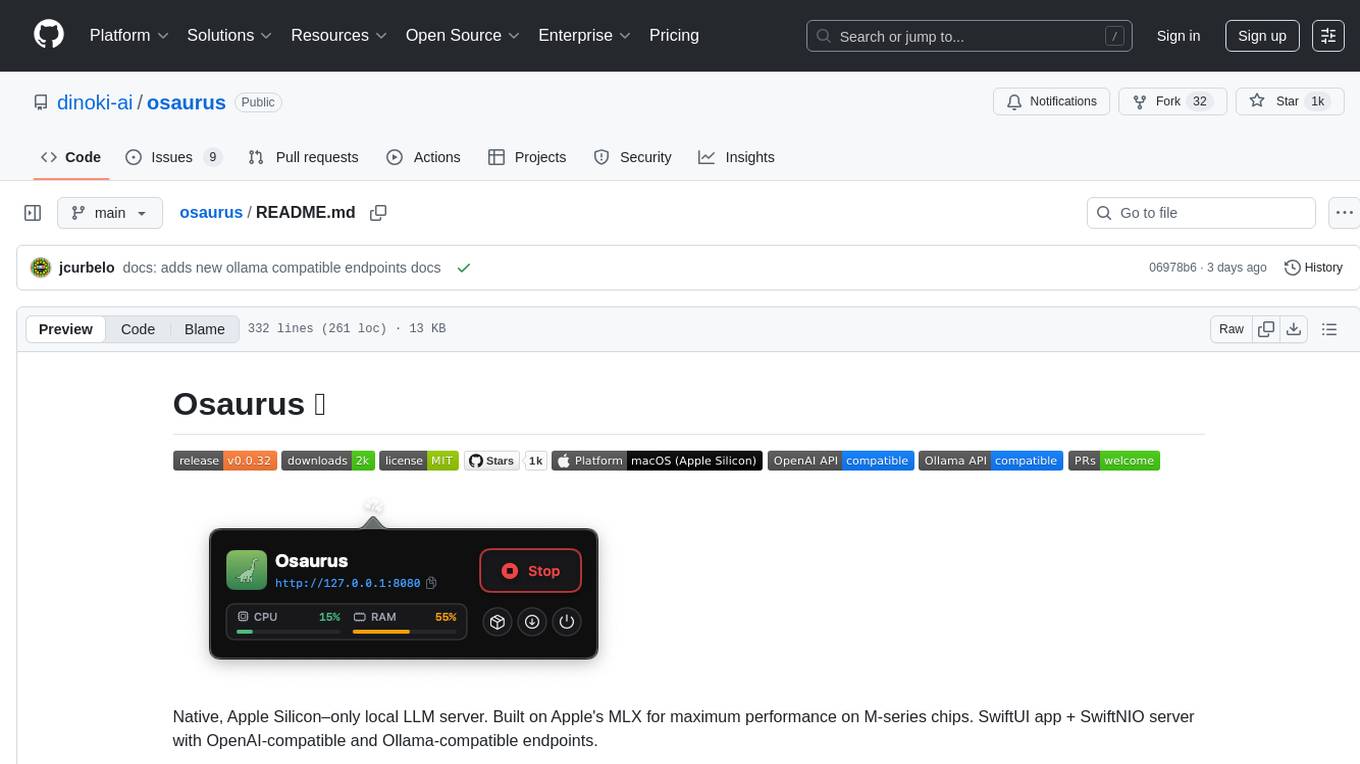
osaurus
Osaurus is a native, Apple Silicon-only local LLM server built on Apple's MLX for maximum performance on M‑series chips. It is a SwiftUI app + SwiftNIO server with OpenAI‑compatible and Ollama‑compatible endpoints. The tool supports native MLX text generation, model management, streaming and non‑streaming chat completions, OpenAI‑compatible function calling, real-time system resource monitoring, and path normalization for API compatibility. Osaurus is designed for macOS 15.5+ and Apple Silicon (M1 or newer) with Xcode 16.4+ required for building from source.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.