
VideoLingo
Netflix-level subtitle cutting, translation, alignment, and even dubbing - one-click fully automated AI video subtitle team | Netflix级字幕切割、翻译、对齐、甚至加上配音,一键全自动视频搬运AI字幕组
Stars: 12149
VideoLingo is an all-in-one video translation and localization dubbing tool designed to generate Netflix-level high-quality subtitles. It aims to eliminate stiff machine translation, multiple lines of subtitles, and can even add high-quality dubbing, allowing knowledge from around the world to be shared across language barriers. Through an intuitive Streamlit web interface, the entire process from video link to embedded high-quality bilingual subtitles and even dubbing can be completed with just two clicks, easily creating Netflix-quality localized videos. Key features and functions include using yt-dlp to download videos from Youtube links, using WhisperX for word-level timeline subtitle recognition, using NLP and GPT for subtitle segmentation based on sentence meaning, summarizing intelligent term knowledge base with GPT for context-aware translation, three-step direct translation, reflection, and free translation to eliminate strange machine translation, checking single-line subtitle length and translation quality according to Netflix standards, using GPT-SoVITS for high-quality aligned dubbing, and integrating package for one-click startup and one-click output in streamlit.
README:
🌟 Overview (Try VL Now!)
VideoLingo is an all-in-one video translation, localization, and dubbing tool aimed at generating Netflix-quality subtitles. It eliminates stiff machine translations and multi-line subtitles while adding high-quality dubbing, enabling global knowledge sharing across language barriers.
Key features:
-
🎥 YouTube video download via yt-dlp
-
🎙️ Word-level and Low-illusion subtitle recognition with WhisperX
-
📝 NLP and AI-powered subtitle segmentation
-
📚 Custom + AI-generated terminology for coherent translation
-
🔄 3-step Translate-Reflect-Adaptation for cinematic quality
-
✅ Netflix-standard, Single-line subtitles Only
-
🗣️ Dubbing with GPT-SoVITS, Azure, OpenAI, and more
-
🚀 One-click startup and processing in Streamlit
-
🌍 Multi-language support in Streamlit UI
-
📝 Detailed logging with progress resumption
Difference from similar projects: Single-line subtitles only, superior translation quality, seamless dubbing experience
Input Language Support(more to come):
🇺🇸 English 🤩 | 🇷🇺 Russian 😊 | 🇫🇷 French 🤩 | 🇩🇪 German 🤩 | 🇮🇹 Italian 🤩 | 🇪🇸 Spanish 🤩 | 🇯🇵 Japanese 😐 | 🇨🇳 Chinese* 😊
*Chinese uses a separate punctuation-enhanced whisper model, for now...
Translation supports all languages, while dubbing language depends on the chosen TTS method.
You don't have to read the whole docs, here is an online AI agent to help you.
Note: For Windows users with NVIDIA GPU, follow these steps before installation:
- Install CUDA Toolkit 12.6
- Install CUDNN 9.3.0
- Add
C:\Program Files\NVIDIA\CUDNN\v9.3\bin\12.6to your system PATH- Restart your computer
Note: FFmpeg is required. Please install it via package managers:
- Windows:
choco install ffmpeg(via Chocolatey)- macOS:
brew install ffmpeg(via Homebrew)- Linux:
sudo apt install ffmpeg(Debian/Ubuntu)
- Clone the repository
git clone https://github.com/Huanshere/VideoLingo.git
cd VideoLingo- Install dependencies(requires
python=3.10)
conda create -n videolingo python=3.10.0 -y
conda activate videolingo
python install.py- Start the application
streamlit run st.pyAlternatively, you can use Docker (requires CUDA 12.4 and NVIDIA Driver version >550), see Docker docs:
docker build -t videolingo .
docker run -d -p 8501:8501 --gpus all videolingoVideoLingo supports OpenAI-Like API format and various TTS interfaces:
- LLM:
claude-3-5-sonnet-20240620,deepseek-chat(v3),gemini-2.0-flash-exp,gpt-4o, ... (sorted by performance) - WhisperX: Run whisperX locally or use 302.ai API
- TTS:
azure-tts,openai-tts,siliconflow-fishtts,fish-tts,GPT-SoVITS,edge-tts,*custom-tts(You can modify your own TTS in custom_tts.py!)
Note: VideoLingo works with 302.ai - one API key for all services (LLM, WhisperX, TTS). Or run locally with Ollama and Edge-TTS for free, no API needed!
For detailed installation, API configuration, and batch mode instructions, please refer to the documentation: English | 中文
-
WhisperX transcription performance may be affected by video background noise, as it uses wav2vac model for alignment. For videos with loud background music, please enable Voice Separation Enhancement. Additionally, subtitles ending with numbers or special characters may be truncated early due to wav2vac's inability to map numeric characters (e.g., "1") to their spoken form ("one").
-
Using weaker models can lead to errors during intermediate processes due to strict JSON format requirements for responses. If this error occurs, please delete the
outputfolder and retry with a different LLM, otherwise repeated execution will read the previous erroneous response causing the same error. -
The dubbing feature may not be 100% perfect due to differences in speech rates and intonation between languages, as well as the impact of the translation step. However, this project has implemented extensive engineering processing for speech rates to ensure the best possible dubbing results.
-
Multilingual video transcription recognition will only retain the main language. This is because whisperX uses a specialized model for a single language when forcibly aligning word-level subtitles, and will delete unrecognized languages.
-
Cannot dub multiple characters separately, as whisperX's speaker distinction capability is not sufficiently reliable.
This project is licensed under the Apache 2.0 License. Special thanks to the following open source projects for their contributions:
whisperX, yt-dlp, json_repair, BELLE
- Submit Issues or Pull Requests on GitHub
- DM me on Twitter: @Huanshere
- Email me at: [email protected]
If you find VideoLingo helpful, please give me a ⭐️!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for VideoLingo
Similar Open Source Tools
VideoLingo
VideoLingo is an all-in-one video translation and localization dubbing tool designed to generate Netflix-level high-quality subtitles. It aims to eliminate stiff machine translation, multiple lines of subtitles, and can even add high-quality dubbing, allowing knowledge from around the world to be shared across language barriers. Through an intuitive Streamlit web interface, the entire process from video link to embedded high-quality bilingual subtitles and even dubbing can be completed with just two clicks, easily creating Netflix-quality localized videos. Key features and functions include using yt-dlp to download videos from Youtube links, using WhisperX for word-level timeline subtitle recognition, using NLP and GPT for subtitle segmentation based on sentence meaning, summarizing intelligent term knowledge base with GPT for context-aware translation, three-step direct translation, reflection, and free translation to eliminate strange machine translation, checking single-line subtitle length and translation quality according to Netflix standards, using GPT-SoVITS for high-quality aligned dubbing, and integrating package for one-click startup and one-click output in streamlit.
voice-pro
Voice-Pro is an integrated solution for subtitles, translation, and TTS. It offers features like multilingual subtitles, live translation, vocal remover, and supports OpenAI Whisper and Open-Source Translator. The tool provides a Studio tab for various functions, Whisper Caption tab for subtitle creation, Translate tab for translation, TTS tab for text-to-speech, Live Translation tab for real-time voice recognition, and Batch tab for processing multiple files. Users can download YouTube videos, improve voice recognition accuracy, create automatic subtitles, and produce multilingual videos with ease. The tool is easy to install with one-click and offers a Web-UI for user convenience.
Srt-AI-Voice-Assistant
Srt-AI-Voice-Assistant is a convenient tool that generates audio from uploaded .srt subtitle files by calling APIs such as Bert-VITS2 (HiyoriUI), GPT-SoVITS, and Microsoft TTS (online). The code is currently not perfect, and feedback on bugs or suggestions can be provided at https://github.com/YYuX-1145/Srt-AI-Voice-Assistant/issues. Recent updates include adding custom API functionality with a focus on security, support for Microsoft online TTS (requires key configuration), error handling improvements, automatic project path detection, compatibility with API-v1 for limited functionality, and significant feature updates supporting card synthesis.

gptme
Personal AI assistant/agent in your terminal, with tools for using the terminal, running code, editing files, browsing the web, using vision, and more. A great coding agent that is general-purpose to assist in all kinds of knowledge work, from a simple but powerful CLI. An unconstrained local alternative to ChatGPT with 'Code Interpreter', Cursor Agent, etc. Not limited by lack of software, internet access, timeouts, or privacy concerns if using local models.

LinguaHaru
Next-generation AI translation tool that provides high-quality, precise translations for various common file formats with a single click. It is based on cutting-edge large language models, offering exceptional translation quality with minimal operation, supporting multiple document formats and languages. Features include multi-format compatibility, global language translation, one-click rapid translation, flexible translation engines, and LAN sharing for efficient collaborative work.
Loyal-Elephie
Embark on an exciting adventure with Loyal Elephie, your faithful AI sidekick! This project combines the power of a neat Next.js web UI and a mighty Python backend, leveraging the latest advancements in Large Language Models (LLMs) and Retrieval Augmented Generation (RAG) to deliver a seamless and meaningful chatting experience. Features include controllable memory, hybrid search, secure web access, streamlined LLM agent, and optional Markdown editor integration. Loyal Elephie supports both open and proprietary LLMs and embeddings serving as OpenAI compatible APIs.
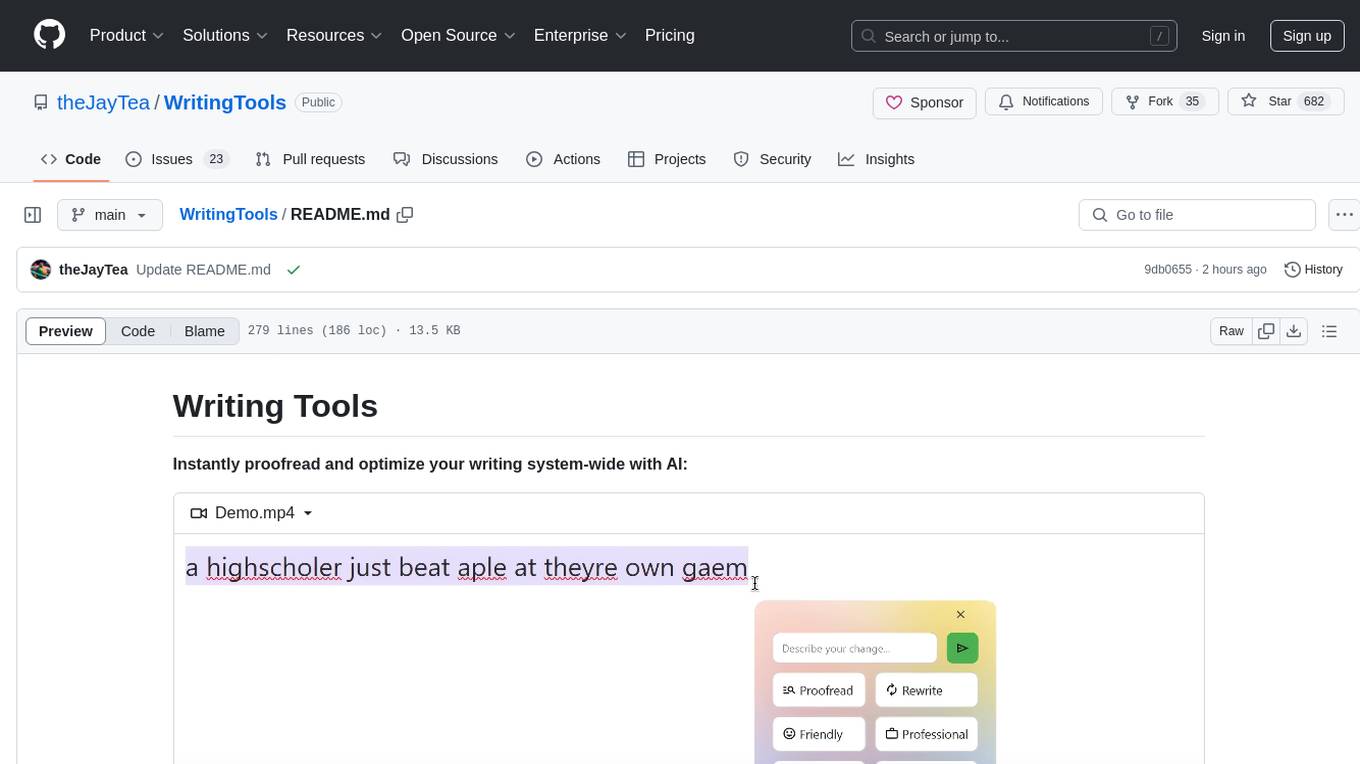
WritingTools
Writing Tools is an Apple Intelligence-inspired application for Windows, Linux, and macOS that supercharges your writing with an AI LLM. It allows users to instantly proofread, optimize text, and summarize content from webpages, YouTube videos, documents, etc. The tool is privacy-focused, open-source, and supports multiple languages. It offers powerful features like grammar correction, content summarization, and LLM chat mode, making it a versatile writing assistant for various tasks.

Easy-Voice-Toolkit
Easy Voice Toolkit is a toolkit based on open source voice projects, providing automated audio tools including speech model training. Users can seamlessly integrate functions like audio processing, voice recognition, voice transcription, dataset creation, model training, and voice conversion to transform raw audio files into ideal speech models. The toolkit supports multiple languages and is currently only compatible with Windows systems. It acknowledges the contributions of various projects and offers local deployment options for both users and developers. Additionally, cloud deployment on Google Colab is available. The toolkit has been tested on Windows OS devices and includes a FAQ section and terms of use for academic exchange purposes.
LocalAIVoiceChat
LocalAIVoiceChat is an experimental alpha software that enables real-time voice chat with a customizable AI personality and voice on your PC. It integrates Zephyr 7B language model with speech-to-text and text-to-speech libraries. The tool is designed for users interested in state-of-the-art voice solutions and provides an early version of a local real-time chatbot.
AIWritingCompanion
AIWritingCompanion is a lightweight and versatile browser extension designed to translate text within input fields. It offers universal compatibility, multiple activation methods, and support for various translation providers like Gemini, OpenAI, and WebAI to API. Users can install it via CRX file or Git, set API key, and use it for automatic translation or via shortcut. The tool is suitable for writers, translators, students, researchers, and bloggers. AI keywords include writing assistant, translation tool, browser extension, language translation, and text translator. Users can use it for tasks like translate text, assist in writing, simplify content, check language accuracy, and enhance communication.
viitor-voice
ViiTor-Voice is an LLM based TTS Engine that offers a lightweight design with 0.5B parameters for efficient deployment on various platforms. It provides real-time streaming output with low latency experience, a rich voice library with over 300 voice options, flexible speech rate adjustment, and zero-shot voice cloning capabilities. The tool supports both Chinese and English languages and is suitable for applications requiring quick response and natural speech fluency.
AI-Office-Translator
AI-Office-Translator is a free, fully localized, user-friendly translation tool that helps you translate Office files (Word, PowerPoint, and Excel) between different languages. It supports .docx, .pptx, and .xlsx files and allows translation between English, Chinese, and Japanese. Users can run the tool after installing CUDA, downloading Ollama dependencies and models, setting up a virtual environment (optional), and installing requirements. The tool provides a UI where users can select languages, models, upload files for translation, start translation, and download translated files. It also supports an online mode with API key integration. The software is open-source under GPL-3.0 license and only provides AI translation services, with users expected to engage in legal translation activities.

kollektiv
Kollektiv is a Retrieval-Augmented Generation (RAG) system designed to enable users to chat with their favorite documentation easily. It aims to provide LLMs with access to the most up-to-date knowledge, reducing inaccuracies and improving productivity. The system utilizes intelligent web crawling, advanced document processing, vector search, multi-query expansion, smart re-ranking, AI-powered responses, and dynamic system prompts. The technical stack includes Python/FastAPI for backend, Supabase, ChromaDB, and Redis for storage, OpenAI and Anthropic Claude 3.5 Sonnet for AI/ML, and Chainlit for UI. Kollektiv is licensed under a modified version of the Apache License 2.0, allowing free use for non-commercial purposes.

llm-answer-engine
This repository contains the code and instructions needed to build a sophisticated answer engine that leverages the capabilities of Groq, Mistral AI's Mixtral, Langchain.JS, Brave Search, Serper API, and OpenAI. Designed to efficiently return sources, answers, images, videos, and follow-up questions based on user queries, this project is an ideal starting point for developers interested in natural language processing and search technologies.
Open-LLM-VTuber
Open-LLM-VTuber is a voice-interactive AI companion supporting real-time voice conversations and featuring a Live2D avatar. It can run offline on Windows, macOS, and Linux, offering web and desktop client modes. Users can customize appearance and persona, with rich LLM inference, text-to-speech, and speech recognition support. The project is highly customizable, extensible, and actively developed with exciting features planned. It provides privacy with offline mode, persistent chat logs, and various interaction features like voice interruption, touch feedback, Live2D expressions, pet mode, and more.

pyqt-openai
VividNode is a cross-platform AI desktop chatbot application for LLM such as GPT, Claude, Gemini, Llama chatbot interaction and image generation. It offers customizable features, local chat history, and enhanced performance without requiring a browser. The application is powered by GPT4Free and allows users to interact with chatbots and generate images seamlessly. VividNode supports Windows, Mac, and Linux, securely stores chat history locally, and provides features like chat interface customization, image generation, focus and accessibility modes, and extensive customization options with keyboard shortcuts for efficient operations.
For similar tasks

gpt-subtrans
GPT-Subtrans is an open-source subtitle translator that utilizes large language models (LLMs) as translation services. It supports translation between any language pairs that the language model supports. Note that GPT-Subtrans requires an active internet connection, as subtitles are sent to the provider's servers for translation, and their privacy policy applies.
auto-subs
Auto-subs is a tool designed to automatically transcribe editing timelines using OpenAI Whisper and Stable-TS for extreme accuracy. It generates subtitles in a custom style, is completely free, and runs locally within Davinci Resolve. It works on Mac, Linux, and Windows, supporting both Free and Studio versions of Resolve. Users can jump to positions on the timeline using the Subtitle Navigator and translate from any language to English. The tool provides a user-friendly interface for creating and customizing subtitles for video content.
VideoLingo
VideoLingo is an all-in-one video translation and localization dubbing tool designed to generate Netflix-level high-quality subtitles. It aims to eliminate stiff machine translation, multiple lines of subtitles, and can even add high-quality dubbing, allowing knowledge from around the world to be shared across language barriers. Through an intuitive Streamlit web interface, the entire process from video link to embedded high-quality bilingual subtitles and even dubbing can be completed with just two clicks, easily creating Netflix-quality localized videos. Key features and functions include using yt-dlp to download videos from Youtube links, using WhisperX for word-level timeline subtitle recognition, using NLP and GPT for subtitle segmentation based on sentence meaning, summarizing intelligent term knowledge base with GPT for context-aware translation, three-step direct translation, reflection, and free translation to eliminate strange machine translation, checking single-line subtitle length and translation quality according to Netflix standards, using GPT-SoVITS for high-quality aligned dubbing, and integrating package for one-click startup and one-click output in streamlit.
voice-pro
Voice-Pro is an integrated solution for subtitles, translation, and TTS. It offers features like multilingual subtitles, live translation, vocal remover, and supports OpenAI Whisper and Open-Source Translator. The tool provides a Studio tab for various functions, Whisper Caption tab for subtitle creation, Translate tab for translation, TTS tab for text-to-speech, Live Translation tab for real-time voice recognition, and Batch tab for processing multiple files. Users can download YouTube videos, improve voice recognition accuracy, create automatic subtitles, and produce multilingual videos with ease. The tool is easy to install with one-click and offers a Web-UI for user convenience.

ai-no-jimaku-gumi
AI no jimaku gumi is a command-line utility designed to assist in video translation. It supports translating subtitles using AI models and provides options for different translation and subtitle sources. Users can easily set up the tool by following the installation steps and use it to translate videos to different languages with customizable settings. The tool currently supports DeepL and llm translation backends and SRT subtitle export. It aims to simplify the process of adding subtitles to videos by leveraging AI technology.

Pandrator
Pandrator is a GUI tool for generating audiobooks and dubbing using voice cloning and AI. It transforms text, PDF, EPUB, and SRT files into spoken audio in multiple languages. It leverages XTTS, Silero, and VoiceCraft models for text-to-speech conversion and voice cloning, with additional features like LLM-based text preprocessing and NISQA for audio quality evaluation. The tool aims to be user-friendly with a one-click installer and a graphical interface.

openlrc
Open-Lyrics is a Python library that transcribes voice files using faster-whisper and translates/polishes the resulting text into `.lrc` files in the desired language using LLM, e.g. OpenAI-GPT, Anthropic-Claude. It offers well preprocessed audio to reduce hallucination and context-aware translation to improve translation quality. Users can install the library from PyPI or GitHub and follow the installation steps to set up the environment. The tool supports GUI usage and provides Python code examples for transcription and translation tasks. It also includes features like utilizing context and glossary for translation enhancement, pricing information for different models, and a list of todo tasks for future improvements.

LTEngine
LTEngine is a free and open-source local AI machine translation API written in Rust. It is self-hosted and compatible with LibreTranslate. LTEngine utilizes large language models (LLMs) via llama.cpp, offering high-quality translations that rival or surpass DeepL for certain languages. It supports various accelerators like CUDA, Metal, and Vulkan, with the largest model 'gemma3-27b' fitting on a single consumer RTX 3090. LTEngine is actively developed, with a roadmap outlining future enhancements and features.
For similar jobs

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

daily-poetry-image
Daily Chinese ancient poetry and AI-generated images powered by Bing DALL-E-3. GitHub Action triggers the process automatically. Poetry is provided by Today's Poem API. The website is built with Astro.

exif-photo-blog
EXIF Photo Blog is a full-stack photo blog application built with Next.js, Vercel, and Postgres. It features built-in authentication, photo upload with EXIF extraction, photo organization by tag, infinite scroll, light/dark mode, automatic OG image generation, a CMD-K menu with photo search, experimental support for AI-generated descriptions, and support for Fujifilm simulations. The application is easy to deploy to Vercel with just a few clicks and can be customized with a variety of environment variables.

SillyTavern
SillyTavern is a user interface you can install on your computer (and Android phones) that allows you to interact with text generation AIs and chat/roleplay with characters you or the community create. SillyTavern is a fork of TavernAI 1.2.8 which is under more active development and has added many major features. At this point, they can be thought of as completely independent programs.

Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).

AISuperDomain
Aila Desktop Application is a powerful tool that integrates multiple leading AI models into a single desktop application. It allows users to interact with various AI models simultaneously, providing diverse responses and insights to their inquiries. With its user-friendly interface and customizable features, Aila empowers users to engage with AI seamlessly and efficiently. Whether you're a researcher, student, or professional, Aila can enhance your AI interactions and streamline your workflow.

ChatGPT-On-CS
This project is an intelligent dialogue customer service tool based on a large model, which supports access to platforms such as WeChat, Qianniu, Bilibili, Douyin Enterprise, Douyin, Doudian, Weibo chat, Xiaohongshu professional account operation, Xiaohongshu, Zhihu, etc. You can choose GPT3.5/GPT4.0/ Lazy Treasure Box (more platforms will be supported in the future), which can process text, voice and pictures, and access external resources such as operating systems and the Internet through plug-ins, and support enterprise AI applications customized based on their own knowledge base.

obs-localvocal
LocalVocal is a live-streaming AI assistant plugin for OBS that allows you to transcribe audio speech into text and perform various language processing functions on the text using AI / LLMs (Large Language Models). It's privacy-first, with all data staying on your machine, and requires no GPU, cloud costs, network, or downtime.