
voice-pro
The best gradio web-ui for ai transcription, translation and TTS. Automatic subtitle creation using faster whisper. Easy one click installation. Fully portable.
Stars: 233
Voice-Pro is an integrated solution for subtitles, translation, and TTS. It offers features like multilingual subtitles, live translation, vocal remover, and supports OpenAI Whisper and Open-Source Translator. The tool provides a Studio tab for various functions, Whisper Caption tab for subtitle creation, Translate tab for translation, TTS tab for text-to-speech, Live Translation tab for real-time voice recognition, and Batch tab for processing multiple files. Users can download YouTube videos, improve voice recognition accuracy, create automatic subtitles, and produce multilingual videos with ease. The tool is easy to install with one-click and offers a Web-UI for user convenience.
README:
🌍 한국어 ∙ English ∙ 中文简体 ∙ 中文繁體 ∙ 日本語


The best gradio web-ui for transcription, translation and tts. Easy one click installation. Fully portable.
- Voice-Pro is an integrated solution for subtitles, translation, and TTS.
- Add multilingual subtitles and multilingual audio to your video with Voice-Pro. Expansion into the global market is possible!
- You watch world news every morning? Then, try using the live translation feature. It supports real-time translation, just like what you see on YouTube.
- Voice-Pro is equipped with Vocal Remover provided by UVR5 and Meta's Demucs engine.
- Voice-Pro uses OpenAI Whisper and the free Open-Source Translator and Open-Source TTS.
- Voice-Pro can be easily installed with one click and provides Gradio Web-UI.
- Experience the highest level of On-Device AI Voice technology.
https://github.com/user-attachments/assets/27b4e79c-7b29-4efd-80c3-5757fa5f71e4
-
Studiotab- Provides integrated environment for YouTube downloader, noise removal, subtitles, translation, and TTS
- All video/audio formats supported by ffmpeg can be used
- Selectable output audio format (wav, flac, mp3)
- Speech recognition and subtitle creation for 100 languages
- Select subtitle creation options suitable for PC performance (Whisper Model & Compute Type)
- Translation into over 100 languages and voice generation through TTS
- The BGM and sound effects from the original video are maintained in the multilingual video.
- Supports TTS voice speed, volume, and pitch adjustment

-
Whisper Captiontab- A tab dedicated to creating subtitles. Supports over 90 languages
- Display subtitles created with the video
- World-Level Highlight function provided
- Denoise function provided (1-Demucs, 2-MDXNet)
-
Translatetab- Dedicated tab for translation. Supports over 100 languages
- Supports subtitle files (ass, ssa, srt, mpl2, tmp, vtt, microdvd, json)
- Direct text input is also possible
- Automatically detects the language of uploaded files
-
TTStab- TTS-only tab. Supports over 100 languages and 400 voices
- Supports subtitle files (ass, ssa, srt, mpl2, tmp, vtt, microdvd, json)
- Direct text input is also possible
- Automatically detects the language of uploaded files
- Pitch, volume, and speed adjustable
-
Live Translationtab- Real-time voice recognition & translation support
- Select audio input source such as Mic, Speaker, etc.
- Provides the ability to save captured audio, recognized subtitles, and translated subtitles
-
Batchtab- Batch processing for large amounts of files
- Subtitles, translation, TTS
- You can download YouTube videos (mp4, webm) and save them as audio files (mp3, wav, flac).
- You can increase the accuracy of voice recognition by removing noise and separating vocals. MDX-Net and Meta's Demucs are used.
- Provides automatic subtitle creation, machine translation, and TTS functions through AI voice recognition.
- You can easily produce multilingual videos.
- One-click installation. Once installed, you can use it permanently at no additional cost. (※ Free version has 30 minute limit on usage time)
- Provides Web-UI. Google Chrome browser is recommended.
- OS: Windows 10/11 (64bits) ※ Linux and Mac OS are not supported.
- CPU: Intel processor 2GHz or higher (or equivalent compatible)
- RAM: 4GB or more
- HDD: At least 20GB of free space during installation
- GPU: NVIDIA graphics card supporting CUDA 12.1 recommended. VRAM 4GB or more. 8GB or more recommended.
- Internet connection required (installation and translation work)
-
A. Paid version
- Unzip the compressed file (voice-pro-x.zip) included in the USB to an appropriate location on your computer.
- Or, copy the already unzipped folder (voice-pro-x) to an appropriate location on your computer.
-
B. Free version
- [
](https://github.com/abus-aikorea/voice-pro/ Download and unzip the latest release (Source code (zip)) from
- Or, download source code with git clone
- [
git clone https://github.com/abus-aikorea/voice-pro.git- Run
configure.bat- Install ffmpeg and CUDA (if using NVIDIA GPU) on Windows.
- You only need to run it the first time.
- Run
start.bat- Start Voice-Pro. Web-UI will run automatically.
- When running for the first time, Voice-Pro is installed first.
- Voice-Pro installation requires an Internet connection, and depending on the system, installation may take more than an hour.
- Never close the Windows-Command window during installation.
- If a problem occurs during installation, delete the installer_files folder and run start.bat again.
-
Run
uninstall.bat:- Remove the installer_files folder.
- Remove ffmepg and CUDA packages installed on Windows (if selected)
-
Voice-Pro has portable installation as standard. To uninstall the program, deleting the installation folder is sufficient.
- Close the Windows-Commnad window and run start.bat again.
- Run the browser directly and enter the address displayed in the Windows-Command window (e.g. http://127.0.0.1:7892) in the address bar.
- Check the GPU memory status in Windows Task Manager - Performance tab.
- Set the Denoise level to 0 or 1. Denoise level 2 requires at least 8GB of GPU memory.
- Set Compute Type to int type. The float type has better quality, but requires more GPU memory.
- The quality of subtitles tends to improve with larger Whisper models, but this is not necessarily the case. large > medium > small > base > tiny
- Among compute types, float type has good performance. The int type is a model that reduces GPU usage and increases speed through model quantization. On the other hand, performance decreases.
- If you increase the denoise level, more background sounds will be removed, and only the remaining voice will be used for voice recognition. It does not always guarantee good results.
When Windows Defender mistakenly recognizes a batch file as a Trojan, this is often called a 'False Positive'. To solve this problem, you can go through the following steps:
- File exception handling: In Windows Defender, you can set certain files or processes to skip security scanning. To do this, follow the steps below:
- Click the ‘Start’ button and go to ‘Settings’.
- Click ‘Update & Security’.
- Select ‘Windows Security’ and go to ‘Virus & threat protection’.
- Click ‘Manage Virus & Threat Protection Settings’.
- Select 'Add exception' in 'Virus & threat protection settings'.
- Select 'File or Folder', find the batch file in question and add it as an exception.
- Temporarily disable Windows Defender: This may be a temporary solution. However, you must be careful when using this method as it may expose your computer to other threats.
- Report the problem to anti-virus software: If you are sure that the file is not a Trojan horse, you can report it to Microsoft as a False Positive. Microsoft will review this and take any necessary action.
- e-mail: [email protected]
- homepage(Korean): https://abuskorea.imweb.me
- Amazon(US): https://www.amazon.com/dp/B0DBR69JPL
- Amazon(Japan): https://www.amazon.co.jp/dp/B0DBVRJ542
- Amazon(Singapore): https://www.amazon.sg/dp/B0DCGKL8R4
- Amazon(UAE): https://www.amazon.ae/dp/B0DCGKM7FF
- 네이버 스마트스토어 (S/W): https://smartstore.naver.com/abus/products/10385660040
- 네이버 스마트스토어 (Solution): https://smartstore.naver.com/abus/products/10298346364
- Product Information: https://youtube.com/playlist?list=PLwx5dnMDVC9Y7dAjm9r26CZUw1uU5VIeq&si=873MgzUtu4POE9jO
- Home Karaoke (Pop): https://youtube.com/playlist?list=PLwx5dnMDVC9bVxfGo58U-R-w3fUHqwiD6&si=aWRDfF8TxFp2oAR0
- Home Karaoke (K-Pop): https://youtube.com/playlist?list=PLwx5dnMDVC9Z8kB01tQKfzTysaCCxC3C8&si=1_-9p722rd_JXpzv
- Home Karaoke (J-Pop): https://youtube.com/playlist?list=PLwx5dnMDVC9apyxrP9LE9PiT821G7lJXk&si=0a474CP7ZIjMoGN9
- FacebookResearch Demucs: https://github.com/facebookresearch/demucs
- yt-dlp: https://github.com/yt-dlp/yt-dlp
- gradio: https://github.com/gradio-app/gradio
![]() by ABUS
by ABUS
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for voice-pro
Similar Open Source Tools
voice-pro
Voice-Pro is an integrated solution for subtitles, translation, and TTS. It offers features like multilingual subtitles, live translation, vocal remover, and supports OpenAI Whisper and Open-Source Translator. The tool provides a Studio tab for various functions, Whisper Caption tab for subtitle creation, Translate tab for translation, TTS tab for text-to-speech, Live Translation tab for real-time voice recognition, and Batch tab for processing multiple files. Users can download YouTube videos, improve voice recognition accuracy, create automatic subtitles, and produce multilingual videos with ease. The tool is easy to install with one-click and offers a Web-UI for user convenience.
whispering-ui
Whispering Tiger UI is a Native-UI tool designed to control the Whispering Tiger application, a free and Open-Source tool that can listen/watch to audio streams or in-game images on your machine and provide transcription or translation to a web browser using Websockets or over OSC. It features a Native-UI for Windows, easy access to all Whispering Tiger features including transcription, translation, text-to-speech, and in-game image recognition. The tool supports loopback audio device, configuration saving/loading, plugin support for additional features, and auto-update functionality. Users can create profiles, configure audio devices, select A.I. devices for speech-to-text, and install/manage plugins for extended functionality.
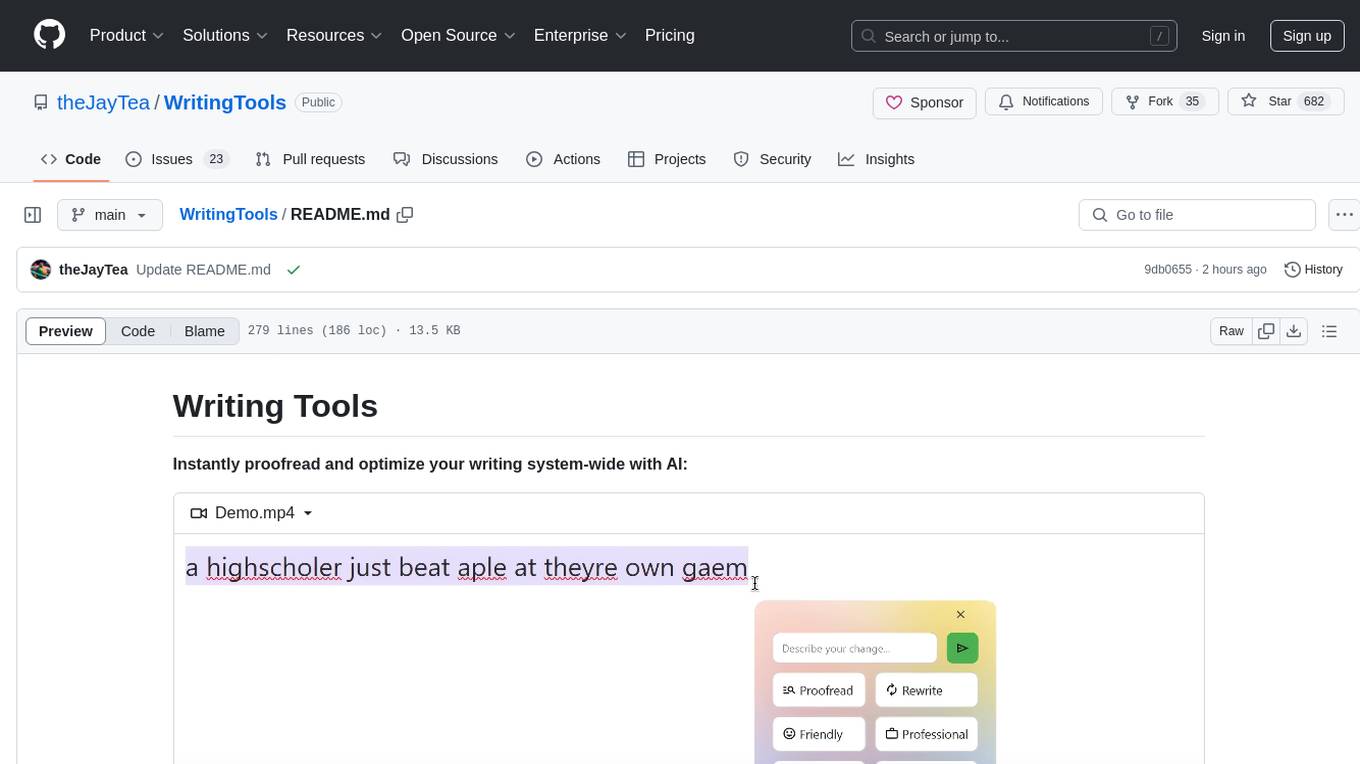
WritingTools
Writing Tools is an Apple Intelligence-inspired application for Windows, Linux, and macOS that supercharges your writing with an AI LLM. It allows users to instantly proofread, optimize text, and summarize content from webpages, YouTube videos, documents, etc. The tool is privacy-focused, open-source, and supports multiple languages. It offers powerful features like grammar correction, content summarization, and LLM chat mode, making it a versatile writing assistant for various tasks.

easydiffusion
Easy Diffusion 3.0 is a user-friendly tool for installing and using Stable Diffusion on your computer. It offers hassle-free installation, clutter-free UI, task queue, intelligent model detection, live preview, image modifiers, multiple prompts file, saving generated images, UI themes, searchable models dropdown, and supports various image generation tasks like 'Text to Image', 'Image to Image', and 'InPainting'. The tool also provides advanced features such as custom models, merge models, custom VAE models, multi-GPU support, auto-updater, developer console, and more. It is designed for both new users and advanced users looking for powerful AI image generation capabilities.
AIWritingCompanion
AIWritingCompanion is a lightweight and versatile browser extension designed to translate text within input fields. It offers universal compatibility, multiple activation methods, and support for various translation providers like Gemini, OpenAI, and WebAI to API. Users can install it via CRX file or Git, set API key, and use it for automatic translation or via shortcut. The tool is suitable for writers, translators, students, researchers, and bloggers. AI keywords include writing assistant, translation tool, browser extension, language translation, and text translator. Users can use it for tasks like translate text, assist in writing, simplify content, check language accuracy, and enhance communication.

Stable-Diffusion-Android
Stable Diffusion AI is an easy-to-use app for generating images from text or other images. It allows communication with servers powered by various AI technologies like AI Horde, Hugging Face Inference API, OpenAI, StabilityAI, and LocalDiffusion. The app supports Txt2Img and Img2Img modes, positive and negative prompts, dynamic size and sampling methods, unique seed input, and batch image generation. Users can also inpaint images, select faces from gallery or camera, and export images. The app offers settings for server URL, SD Model selection, auto-saving images, and clearing cache.

gptme
Personal AI assistant/agent in your terminal, with tools for using the terminal, running code, editing files, browsing the web, using vision, and more. A great coding agent that is general-purpose to assist in all kinds of knowledge work, from a simple but powerful CLI. An unconstrained local alternative to ChatGPT with 'Code Interpreter', Cursor Agent, etc. Not limited by lack of software, internet access, timeouts, or privacy concerns if using local models.

Easy-Voice-Toolkit
Easy Voice Toolkit is a toolkit based on open source voice projects, providing automated audio tools including speech model training. Users can seamlessly integrate functions like audio processing, voice recognition, voice transcription, dataset creation, model training, and voice conversion to transform raw audio files into ideal speech models. The toolkit supports multiple languages and is currently only compatible with Windows systems. It acknowledges the contributions of various projects and offers local deployment options for both users and developers. Additionally, cloud deployment on Google Colab is available. The toolkit has been tested on Windows OS devices and includes a FAQ section and terms of use for academic exchange purposes.

DevoxxGenieIDEAPlugin
Devoxx Genie is a Java-based IntelliJ IDEA plugin that integrates with local and cloud-based LLM providers to aid in reviewing, testing, and explaining project code. It supports features like code highlighting, chat conversations, and adding files/code snippets to context. Users can modify REST endpoints and LLM parameters in settings, including support for cloud-based LLMs. The plugin requires IntelliJ version 2023.3.4 and JDK 17. Building and publishing the plugin is done using Gradle tasks. Users can select an LLM provider, choose code, and use commands like review, explain, or generate unit tests for code analysis.
word-GPT-Plus
Word GPT Plus seamlessly integrates AI models into Microsoft Word, allowing users to generate, translate, summarize, and polish text directly within their documents. The tool supports multiple AI models, offers built-in templates for various text-related tasks, and provides customization options for user preferences. Users can install the tool through a hosted service, Docker deployment, or self-hosting, and can easily fill in API keys to access different AI services. Word GPT Plus enhances writing workflows by providing AI-powered assistance without leaving the Word environment.
Cerebr
Cerebr is an intelligent AI assistant browser extension designed to enhance work efficiency and learning experience. It integrates powerful AI capabilities from various sources to provide features such as smart sidebar, multiple API support, cross-browser API configuration synchronization, comprehensive Q&A support, elegant rendering, real-time response, theme switching, and more. With a minimalist design and focus on delivering a seamless, distraction-free browsing experience, Cerebr aims to be your second brain for deep reading and understanding.

plandex
Plandex is an open source, terminal-based AI coding engine designed for complex tasks. It uses long-running agents to break up large tasks into smaller subtasks, helping users work through backlogs, navigate unfamiliar technologies, and save time on repetitive tasks. Plandex supports various AI models, including OpenAI, Anthropic Claude, Google Gemini, and more. It allows users to manage context efficiently in the terminal, experiment with different approaches using branches, and review changes before applying them. The tool is platform-independent and runs from a single binary with no dependencies.
Srt-AI-Voice-Assistant
Srt-AI-Voice-Assistant is a convenient tool that generates audio from uploaded .srt subtitle files by calling APIs such as Bert-VITS2 (HiyoriUI), GPT-SoVITS, and Microsoft TTS (online). The code is currently not perfect, and feedback on bugs or suggestions can be provided at https://github.com/YYuX-1145/Srt-AI-Voice-Assistant/issues. Recent updates include adding custom API functionality with a focus on security, support for Microsoft online TTS (requires key configuration), error handling improvements, automatic project path detection, compatibility with API-v1 for limited functionality, and significant feature updates supporting card synthesis.
krita-ai-diffusion
Krita-AI-Diffusion is a plugin for Krita that allows users to generate images from within the program. It offers a variety of features, including inpainting, outpainting, generating images from scratch, refining existing content, live painting, and control over image creation. The plugin is designed to fit into an interactive workflow where AI generation is used as just another tool while painting. It is meant to synergize with traditional tools and the layer stack.

kollektiv
Kollektiv is a Retrieval-Augmented Generation (RAG) system designed to enable users to chat with their favorite documentation easily. It aims to provide LLMs with access to the most up-to-date knowledge, reducing inaccuracies and improving productivity. The system utilizes intelligent web crawling, advanced document processing, vector search, multi-query expansion, smart re-ranking, AI-powered responses, and dynamic system prompts. The technical stack includes Python/FastAPI for backend, Supabase, ChromaDB, and Redis for storage, OpenAI and Anthropic Claude 3.5 Sonnet for AI/ML, and Chainlit for UI. Kollektiv is licensed under a modified version of the Apache License 2.0, allowing free use for non-commercial purposes.

TaskingAI
TaskingAI brings Firebase's simplicity to **AI-native app development**. The platform enables the creation of GPTs-like multi-tenant applications using a wide range of LLMs from various providers. It features distinct, modular functions such as Inference, Retrieval, Assistant, and Tool, seamlessly integrated to enhance the development process. TaskingAI’s cohesive design ensures an efficient, intelligent, and user-friendly experience in AI application development.
For similar tasks

gpt-subtrans
GPT-Subtrans is an open-source subtitle translator that utilizes large language models (LLMs) as translation services. It supports translation between any language pairs that the language model supports. Note that GPT-Subtrans requires an active internet connection, as subtitles are sent to the provider's servers for translation, and their privacy policy applies.
auto-subs
Auto-subs is a tool designed to automatically transcribe editing timelines using OpenAI Whisper and Stable-TS for extreme accuracy. It generates subtitles in a custom style, is completely free, and runs locally within Davinci Resolve. It works on Mac, Linux, and Windows, supporting both Free and Studio versions of Resolve. Users can jump to positions on the timeline using the Subtitle Navigator and translate from any language to English. The tool provides a user-friendly interface for creating and customizing subtitles for video content.
VideoLingo
VideoLingo is an all-in-one video translation and localization dubbing tool designed to generate Netflix-level high-quality subtitles. It aims to eliminate stiff machine translation, multiple lines of subtitles, and can even add high-quality dubbing, allowing knowledge from around the world to be shared across language barriers. Through an intuitive Streamlit web interface, the entire process from video link to embedded high-quality bilingual subtitles and even dubbing can be completed with just two clicks, easily creating Netflix-quality localized videos. Key features and functions include using yt-dlp to download videos from Youtube links, using WhisperX for word-level timeline subtitle recognition, using NLP and GPT for subtitle segmentation based on sentence meaning, summarizing intelligent term knowledge base with GPT for context-aware translation, three-step direct translation, reflection, and free translation to eliminate strange machine translation, checking single-line subtitle length and translation quality according to Netflix standards, using GPT-SoVITS for high-quality aligned dubbing, and integrating package for one-click startup and one-click output in streamlit.
voice-pro
Voice-Pro is an integrated solution for subtitles, translation, and TTS. It offers features like multilingual subtitles, live translation, vocal remover, and supports OpenAI Whisper and Open-Source Translator. The tool provides a Studio tab for various functions, Whisper Caption tab for subtitle creation, Translate tab for translation, TTS tab for text-to-speech, Live Translation tab for real-time voice recognition, and Batch tab for processing multiple files. Users can download YouTube videos, improve voice recognition accuracy, create automatic subtitles, and produce multilingual videos with ease. The tool is easy to install with one-click and offers a Web-UI for user convenience.

ai-no-jimaku-gumi
AI no jimaku gumi is a command-line utility designed to assist in video translation. It supports translating subtitles using AI models and provides options for different translation and subtitle sources. Users can easily set up the tool by following the installation steps and use it to translate videos to different languages with customizable settings. The tool currently supports DeepL and llm translation backends and SRT subtitle export. It aims to simplify the process of adding subtitles to videos by leveraging AI technology.
youwee
Youwee is a modern YouTube video downloader tool built with Tauri and React. It offers features like downloading videos from various platforms, following channels, fetching metadata, live stream support, AI video summary and processing, time range download, batch and playlist downloads, audio extraction, subtitle support, subtitle workshop, post-processing, SponsorBlock, speed limit control, download library, multiple themes, and is fast and lightweight.
typewhisper-mac
TypeWhisper for Mac is a speech-to-text and AI text processing tool designed for macOS. It allows users to transcribe audio using on-device AI models or cloud APIs like Groq and OpenAI, and process the results with custom LLM prompts. The tool offers features such as multiple transcription engines, on-device or cloud processing, streaming preview, file transcription, subtitle export, system-wide dictation with hotkeys, AI processing with custom prompts and translation, personalization through profiles, dictionary, snippets, and history, integration and extensibility via plugins, HTTP API, and CLI tool. The tool is designed for macOS 15.0 and later, supports Apple Silicon, and offers a multilingual UI with English and German languages.

tts-generation-webui
TTS Generation WebUI is a comprehensive tool that provides a user-friendly interface for text-to-speech and voice cloning tasks. It integrates various AI models such as Bark, MusicGen, AudioGen, Tortoise, RVC, Vocos, Demucs, SeamlessM4T, and MAGNeT. The tool offers one-click installers, Google Colab demo, videos for guidance, and extra voices for Bark. Users can generate audio outputs, manage models, caches, and system space for AI projects. The project is open-source and emphasizes ethical and responsible use of AI technology.
For similar jobs
voice-pro
Voice-Pro is an integrated solution for subtitles, translation, and TTS. It offers features like multilingual subtitles, live translation, vocal remover, and supports OpenAI Whisper and Open-Source Translator. The tool provides a Studio tab for various functions, Whisper Caption tab for subtitle creation, Translate tab for translation, TTS tab for text-to-speech, Live Translation tab for real-time voice recognition, and Batch tab for processing multiple files. Users can download YouTube videos, improve voice recognition accuracy, create automatic subtitles, and produce multilingual videos with ease. The tool is easy to install with one-click and offers a Web-UI for user convenience.

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text

suno-api
Suno AI API is an open-source project that allows developers to integrate the music generation capabilities of Suno.ai into their own applications. The API provides a simple and convenient way to generate music, lyrics, and other audio content using Suno.ai's powerful AI models. With Suno AI API, developers can easily add music generation functionality to their apps, websites, and other projects.

bark.cpp
Bark.cpp is a C/C++ implementation of the Bark model, a real-time, multilingual text-to-speech generation model. It supports AVX, AVX2, and AVX512 for x86 architectures, and is compatible with both CPU and GPU backends. Bark.cpp also supports mixed F16/F32 precision and 4-bit, 5-bit, and 8-bit integer quantization. It can be used to generate realistic-sounding audio from text prompts.

NSMusicS
NSMusicS is a local music software that is expected to support multiple platforms with AI capabilities and multimodal features. The goal of NSMusicS is to integrate various functions (such as artificial intelligence, streaming, music library management, cross platform, etc.), which can be understood as similar to Navidrome but with more features than Navidrome. It wants to become a plugin integrated application that can almost have all music functions.

ai-voice-cloning
This repository provides a tool for AI voice cloning, allowing users to generate synthetic speech that closely resembles a target speaker's voice. The tool is designed to be user-friendly and accessible, with a graphical user interface that guides users through the process of training a voice model and generating synthetic speech. The tool also includes a variety of features that allow users to customize the generated speech, such as the pitch, volume, and speaking rate. Overall, this tool is a valuable resource for anyone interested in creating realistic and engaging synthetic speech.

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio

openvino-plugins-ai-audacity
OpenVINO™ AI Plugins for Audacity* are a set of AI-enabled effects, generators, and analyzers for Audacity®. These AI features run 100% locally on your PC -- no internet connection necessary! OpenVINO™ is used to run AI models on supported accelerators found on the user's system such as CPU, GPU, and NPU. * **Music Separation**: Separate a mono or stereo track into individual stems -- Drums, Bass, Vocals, & Other Instruments. * **Noise Suppression**: Removes background noise from an audio sample. * **Music Generation & Continuation**: Uses MusicGen LLM to generate snippets of music, or to generate a continuation of an existing snippet of music. * **Whisper Transcription**: Uses whisper.cpp to generate a label track containing the transcription or translation for a given selection of spoken audio or vocals.