Best AI tools for< Audio Engineer >
Infographic
72 - AI tool Sites
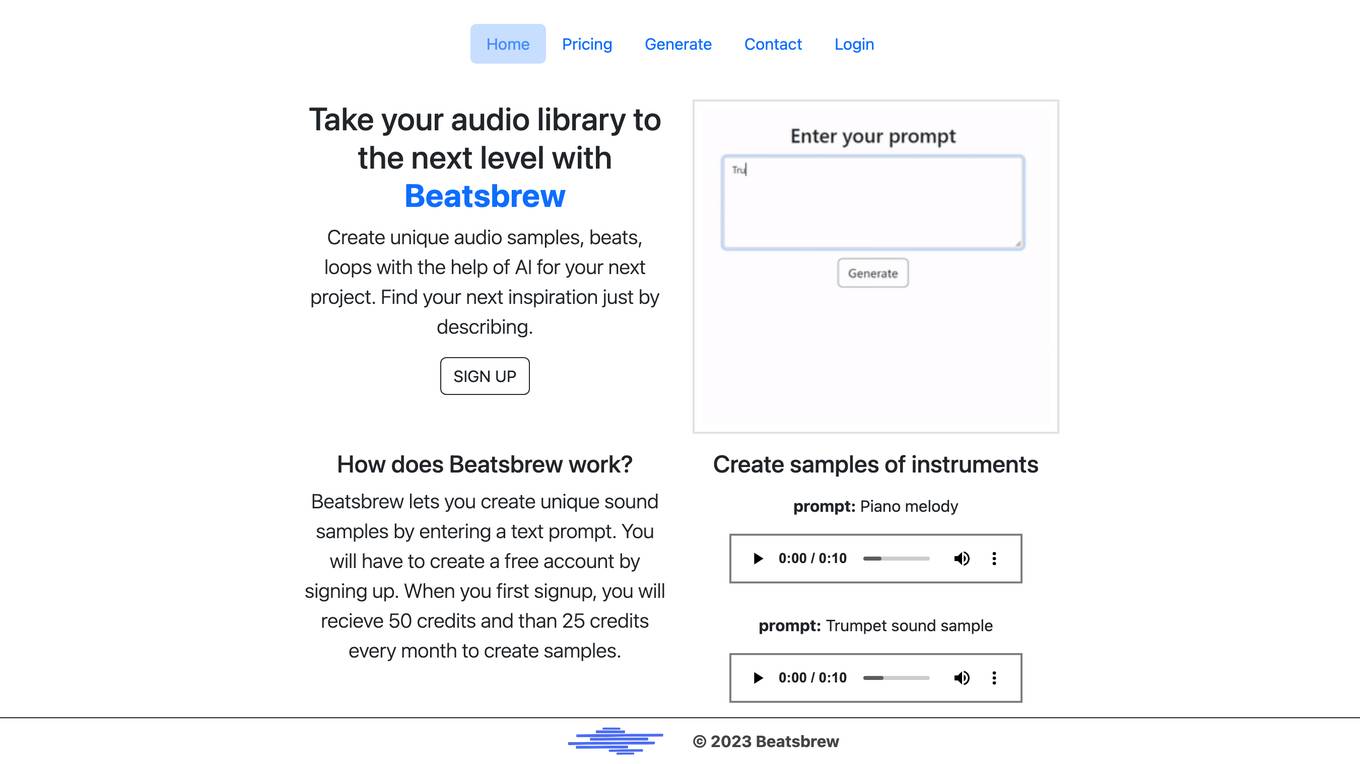
Beatsbrew
Beatsbrew is an AI-powered application that allows users to create unique audio samples, beats, and loops by entering text prompts. Users can generate a variety of sound assets, from instruments to beats, with the help of AI technology. The application provides a valuable resource for music producers and creators looking to enhance their projects with new and exciting sounds. Beatsbrew offers a user-friendly platform to easily create and explore sound samples, making music production and creative projects more efficient and innovative.
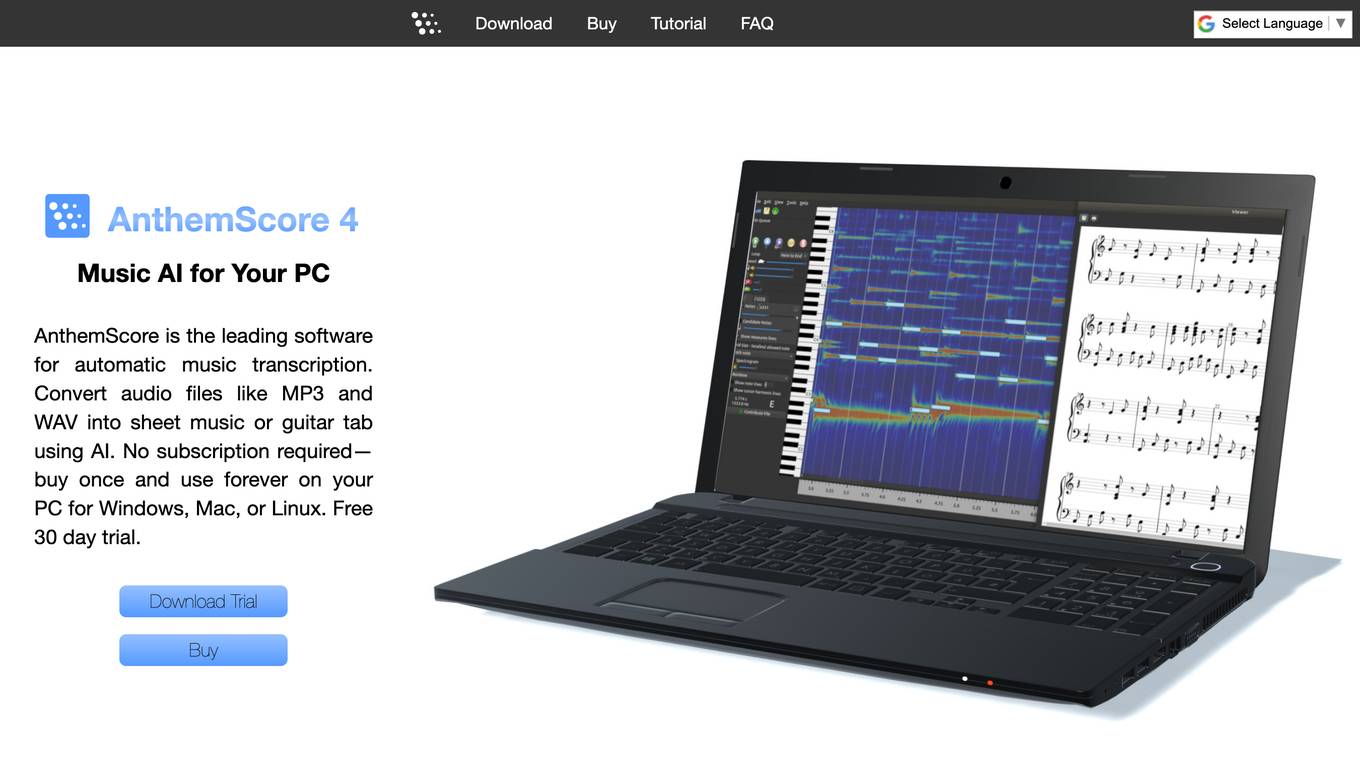
AnthemScore
AnthemScore is an automatic music transcription software that uses AI to convert audio files like MP3 and WAV into sheet music. It offers features like automatic note detection, easy correction, time-saving tools, customization for different instruments, and advanced editing options. Users can transcribe songs, view, save, and print sheet music, and choose from different editions based on their needs. AnthemScore is available for Windows, Mac, and Linux, with a free trial option and various pricing plans for Lite, Professional, and Studio editions.
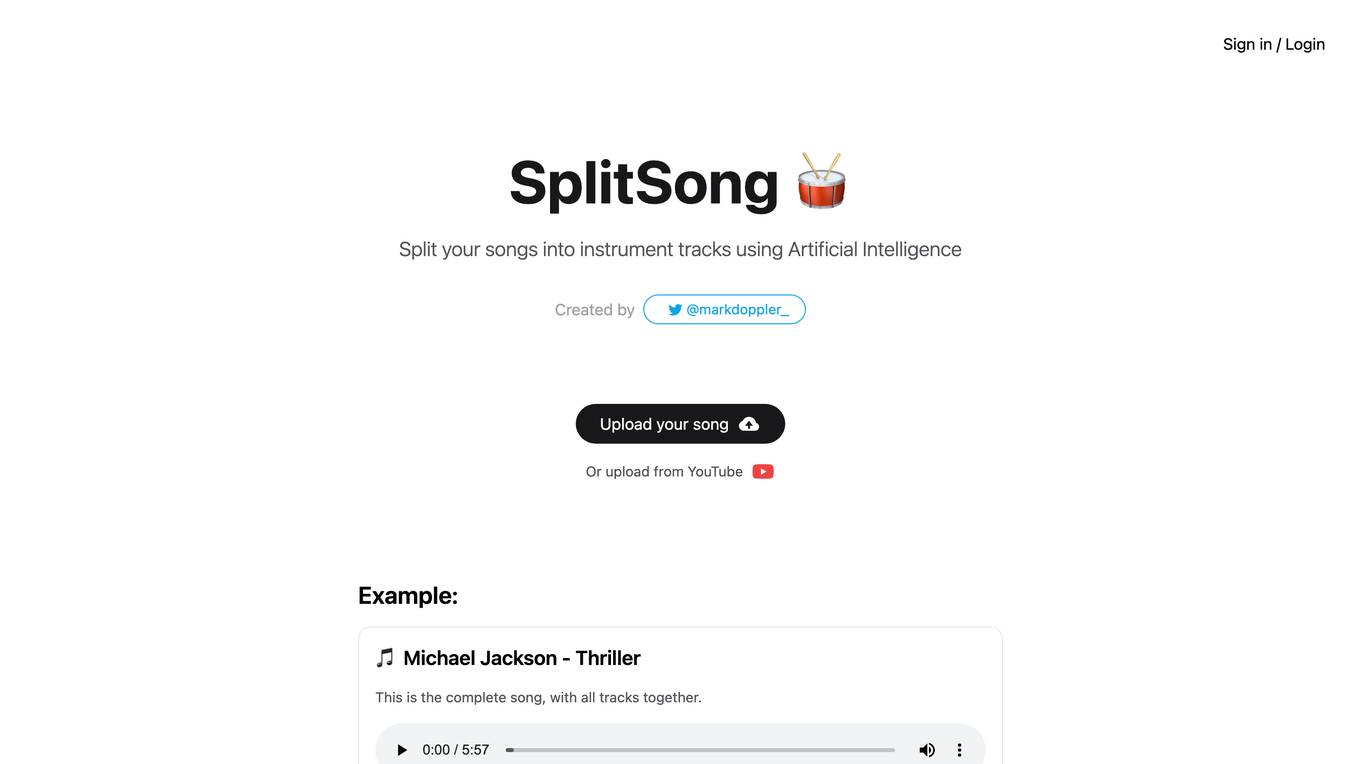
SplitSong
SplitSong.com is an AI tool that allows users to split songs into individual instrument tracks using Artificial Intelligence. Created by @markdoppler_, the website offers a user-friendly platform where users can upload their songs or extract them from YouTube. Users can then download separate tracks for drums, instrumental, bass, and vocals, enabling them to remix or study music in a more detailed manner.
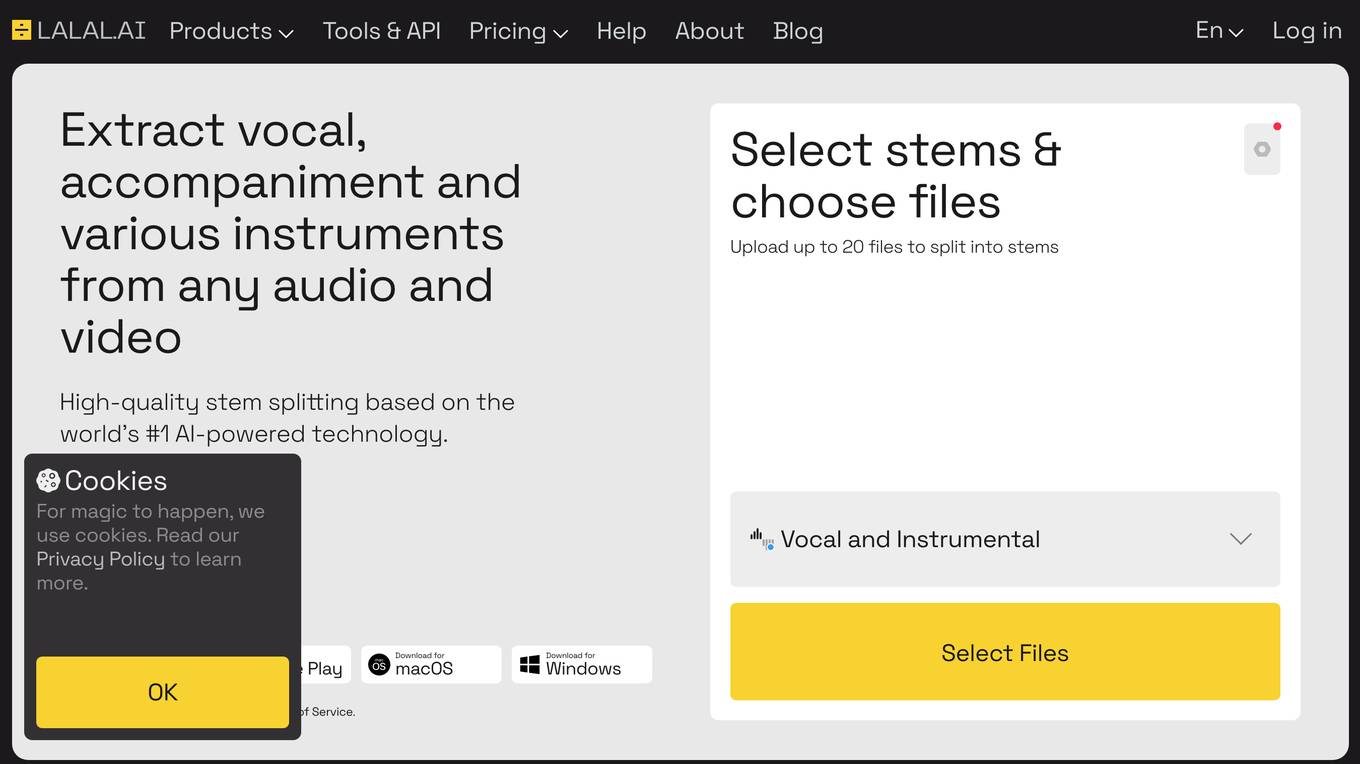
LALAL.AI
LALAL.AI is a next-generation vocal remover and music source separation service that offers fast, easy, and precise stem extraction. It allows users to remove vocals, instrumental tracks, drums, bass, guitar, and more without quality loss. The platform uses advanced AI technology to provide high-quality stem splitting based on transformer-based audio separation approach. Users can create custom voices, remove background noise, change voices, and separate lead and backing vocals with pinpoint accuracy. LALAL.AI offers various packages for individuals and businesses, with features like fast processing queue, batch upload, and stem download. The service supports a wide range of input/output formats for audio and video files.
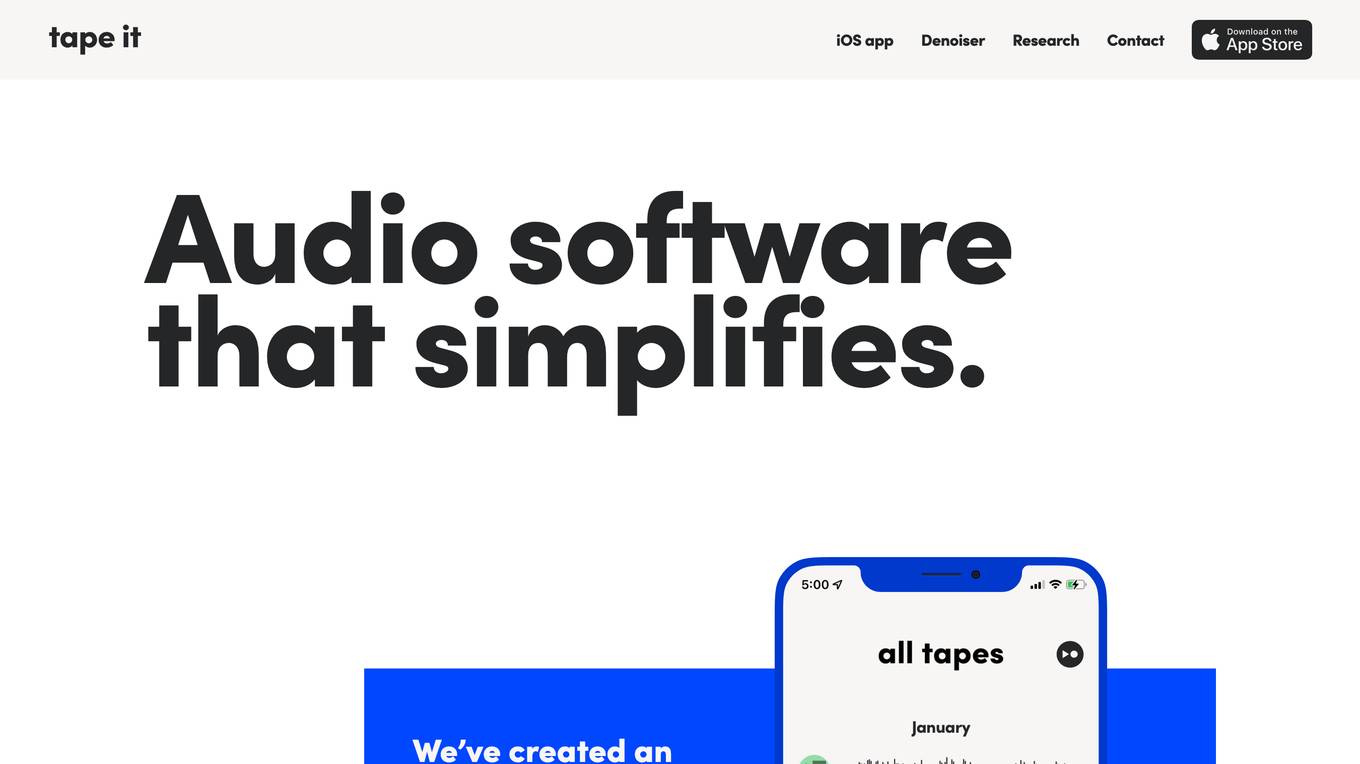
Tape It
Tape It is an iOS app designed for songwriting and audio recording. It provides a platform for creative musicians to organize their song ideas, record audio, and collaborate with others. Users can set markers while recording, create mixtapes, add text and photo notes, search for instruments, and organize recordings in batches. The app allows users to record in stereo, connect audio interfaces, and export recordings as wav or mp3 files. Additionally, users can share their work privately or publicly, collaborate with friends, and create videos for social media. Tape It aims to streamline the songwriting process and enhance the recording experience for musicians.
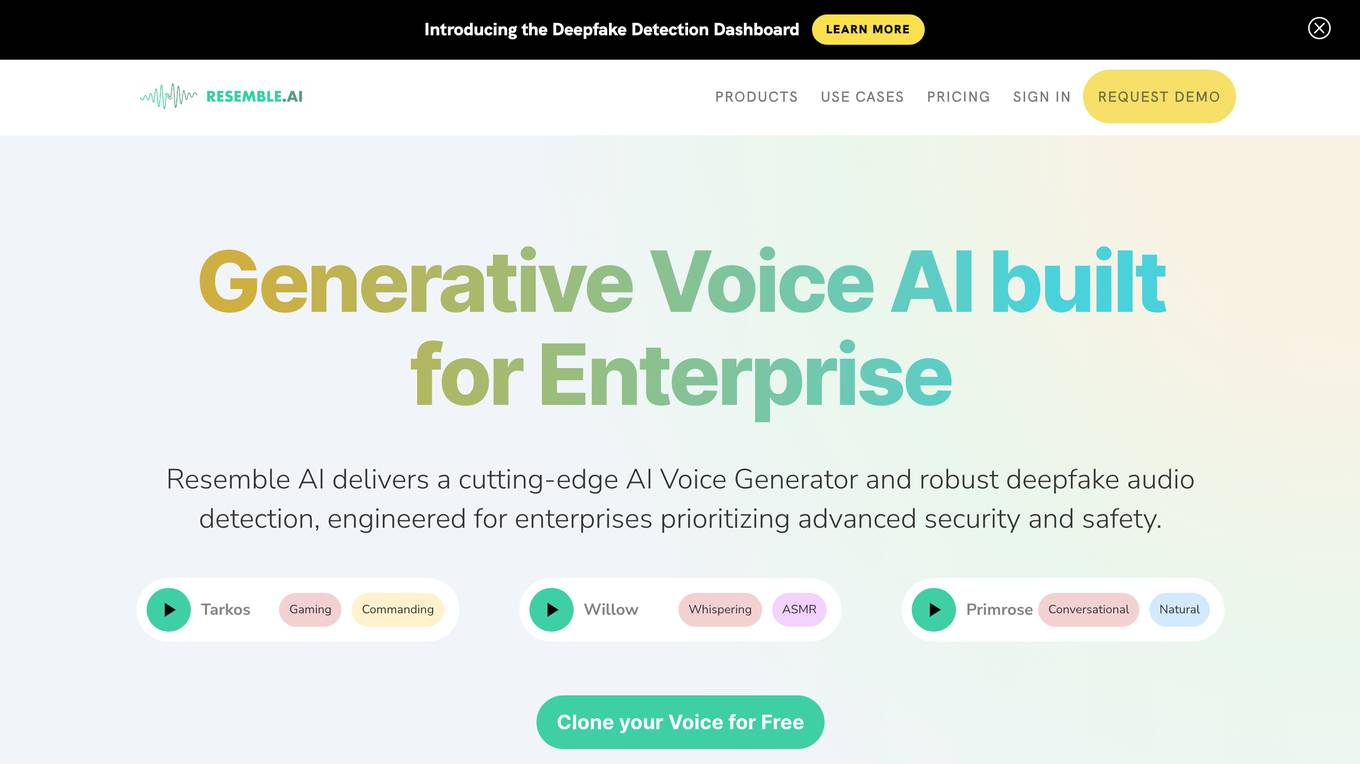
Resemble AI
Resemble AI is an AI-powered platform that offers AI Voice Generator and Deepfake Detection services for enterprises. The platform provides features such as Generative AI Voice Cloning, Text to Speech, Speech to Speech conversion, Multilingual support, Audio Editing, and Open Source Voice Cloning AI Model. Resemble AI focuses on delivering state-of-the-art AI models for voice generation and deepfake detection, ensuring security and trust for its users.
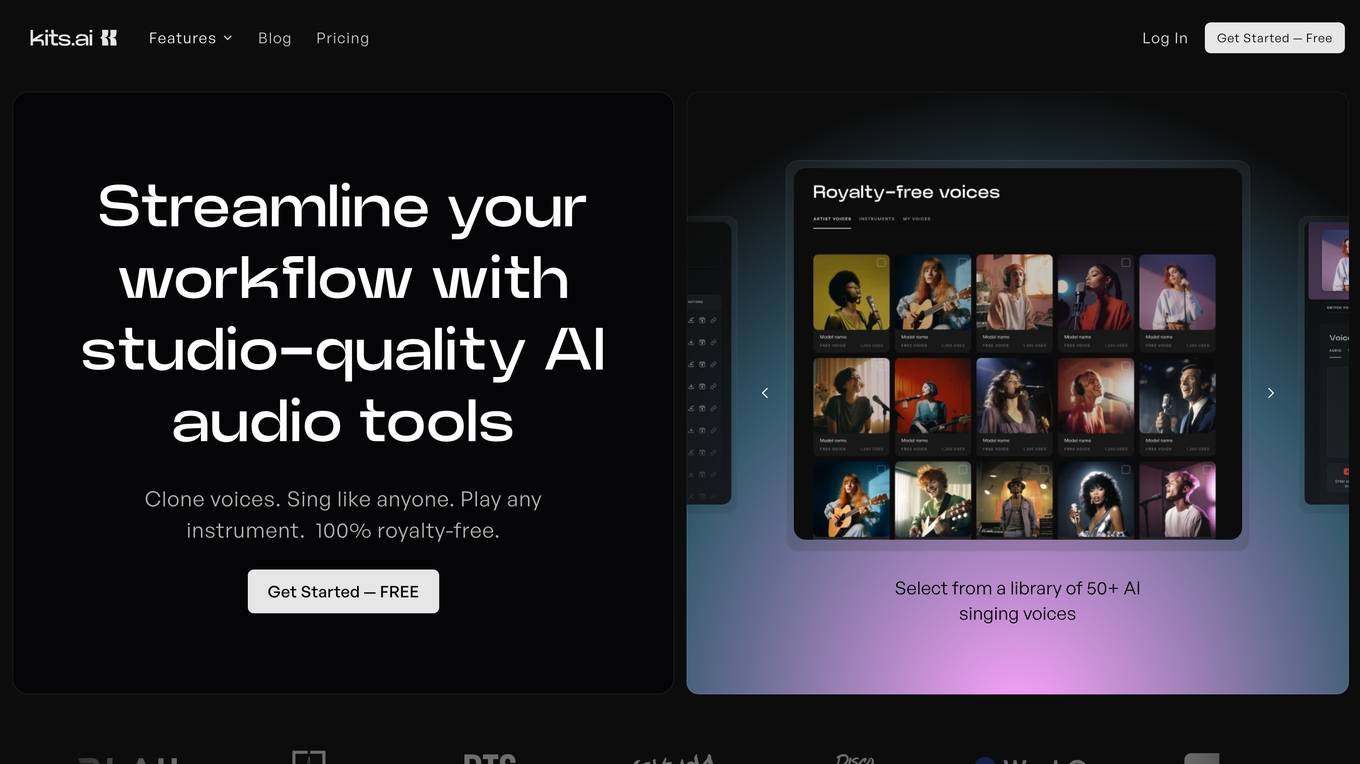
Kits AI
Kits AI is a studio-quality AI music tool that offers a range of features to streamline music production workflows. It provides tools for voice cloning, singing like anyone, playing any instrument, isolating vocals, and more. With 100% Royalty Free content, Kits AI allows users to create their own AI singing clones and collaborate without the need for recording sessions. The application is designed to enhance creativity, save time, and offer new revenue streams for vocalists and producers.

Controlla Voice
Controlla Voice is an AI application that allows users to transform vocals into new voices or instruments, swap any song to their own voice in any language, and create unique blended voices. Users can train their own AI singing voice, generate AI cover songs, and create realistic choirs with customizable harmonies. The application provides a vocal toolkit for never-before-heard sounds and offers flexible pricing options to access high-quality AI singing voices. With Controlla Voice, users can enhance their voice, express themselves in their most natural way, and monetize their music with automatic royalties.
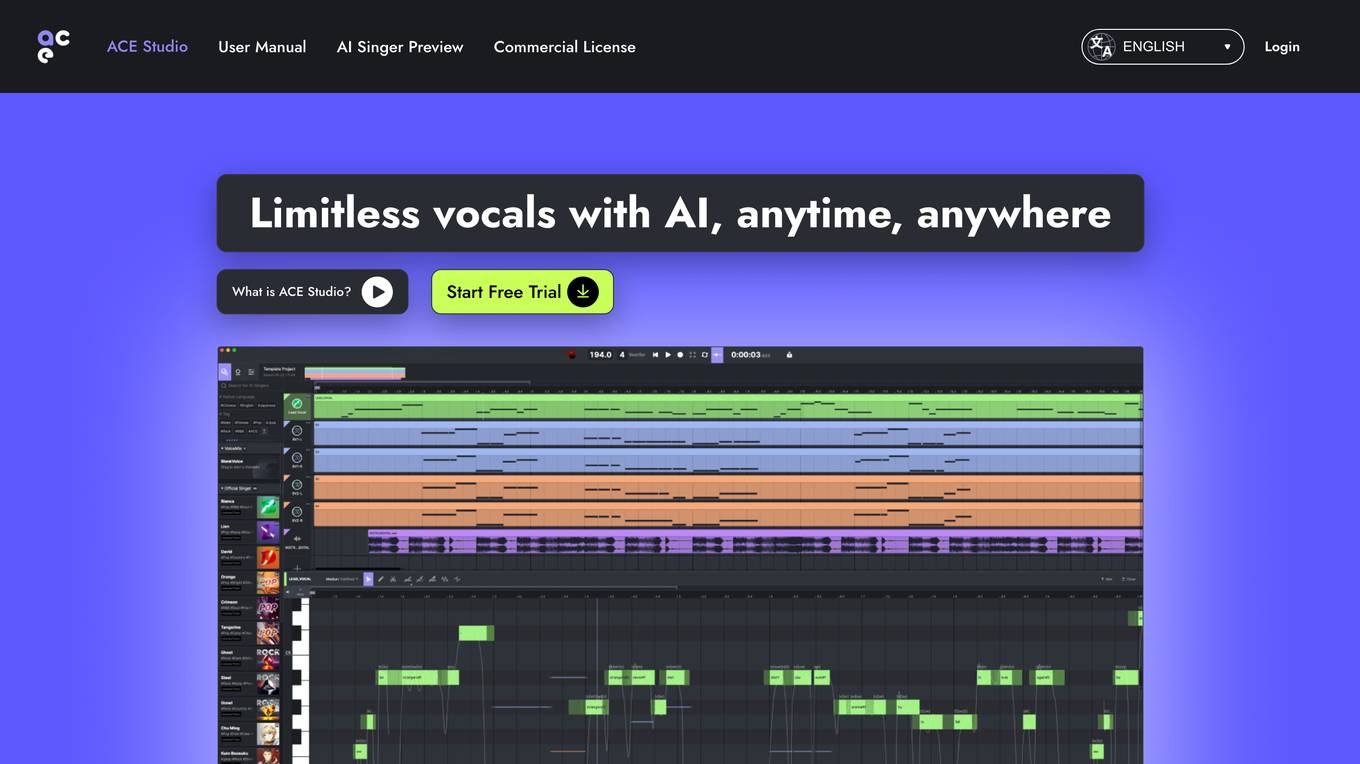
ACE Studio
ACE Studio is an AI Vocal Workstation that allows users to generate vocals from various professional AI vocalists by typing MIDI and lyrics. It simplifies the production of lead vocals, harmonies, backing vocals, and choirs. The platform features a next-generation AI Singing Synthesis Engine that aims to deliver natural and expressive vocal performances. Users can access over 41 AI pro-singers in English, Chinese, and Japanese for music production. ACE Studio offers tools for editing and controlling vocal emotions, converting dry vocals into MIDI clips, blending voices, and customizing AI voice models.
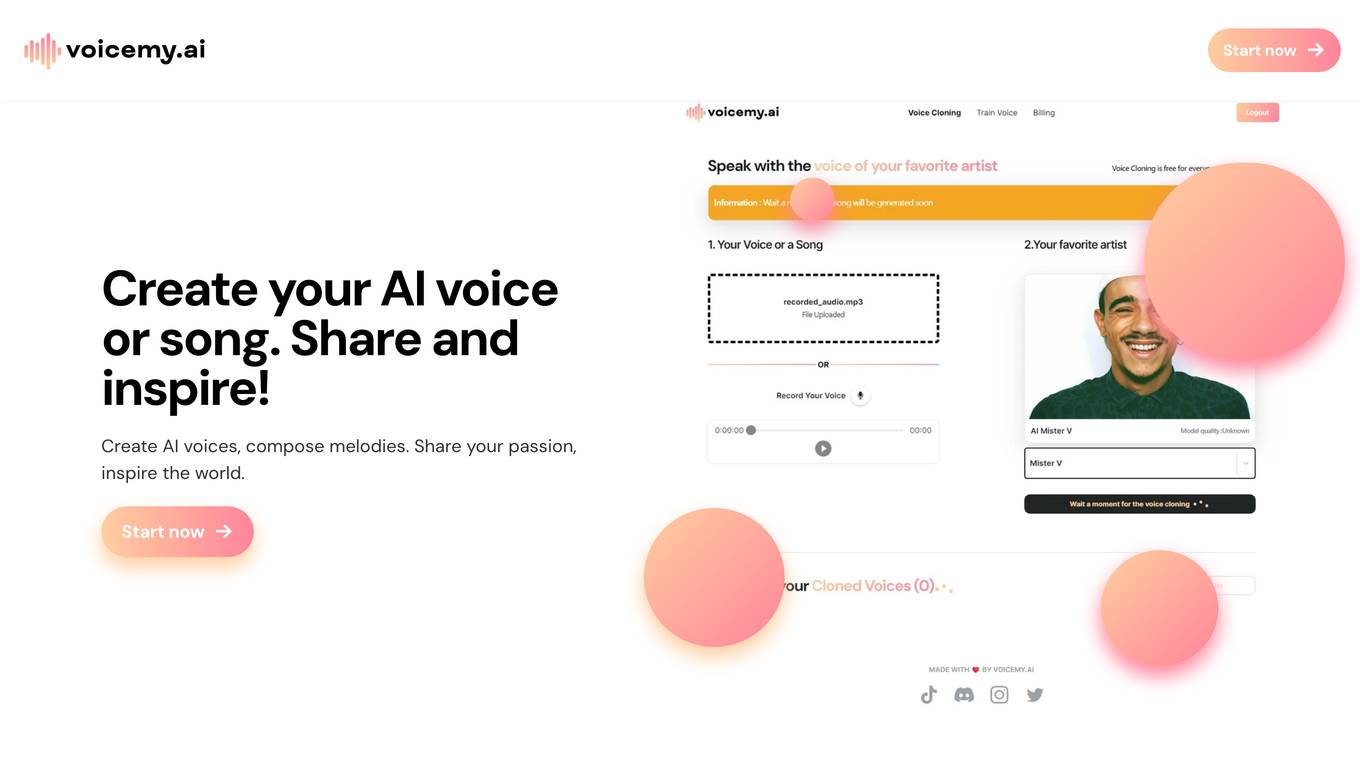
Voicemy.ai
Voicemy.ai is an AI application that allows users to create AI voices and songs. Users can clone voices of famous personalities, compose melodies, and convert text into spoken words using chosen voice models. The platform aims to inspire creativity and enable users to share their passion with the world.
Splitter.ai
Splitter.ai is an AI-driven audio processing platform developed by a Swedish research company. It offers advanced audio processing technologies, including stem separation/extraction, reverb removal, and direct YouTube splitting. The platform is designed to assist music producers, DJs, artists, forensics engineers, audio engineers, karaoke enthusiasts, police, scientists, and more in enhancing their audio processing tasks. Splitter.ai aims to provide high-quality services through AI-driven solutions to meet the diverse needs of its users.
Music AI
Music AI is an AI audio platform that offers state-of-the-art ethical AI solutions for audio and music applications. It provides a wide range of tools and modules for tasks such as stem separation, transcription, mixing, mastering, content generation, effects, utilities, classification, enhancement, style transfer, and more. The platform aims to streamline audio processing workflows, enhance creativity, improve accuracy, increase engagement, and save time for music professionals and businesses. Music AI prioritizes data security, privacy, and customization, allowing users to build custom workflows with over 50 AI modules.
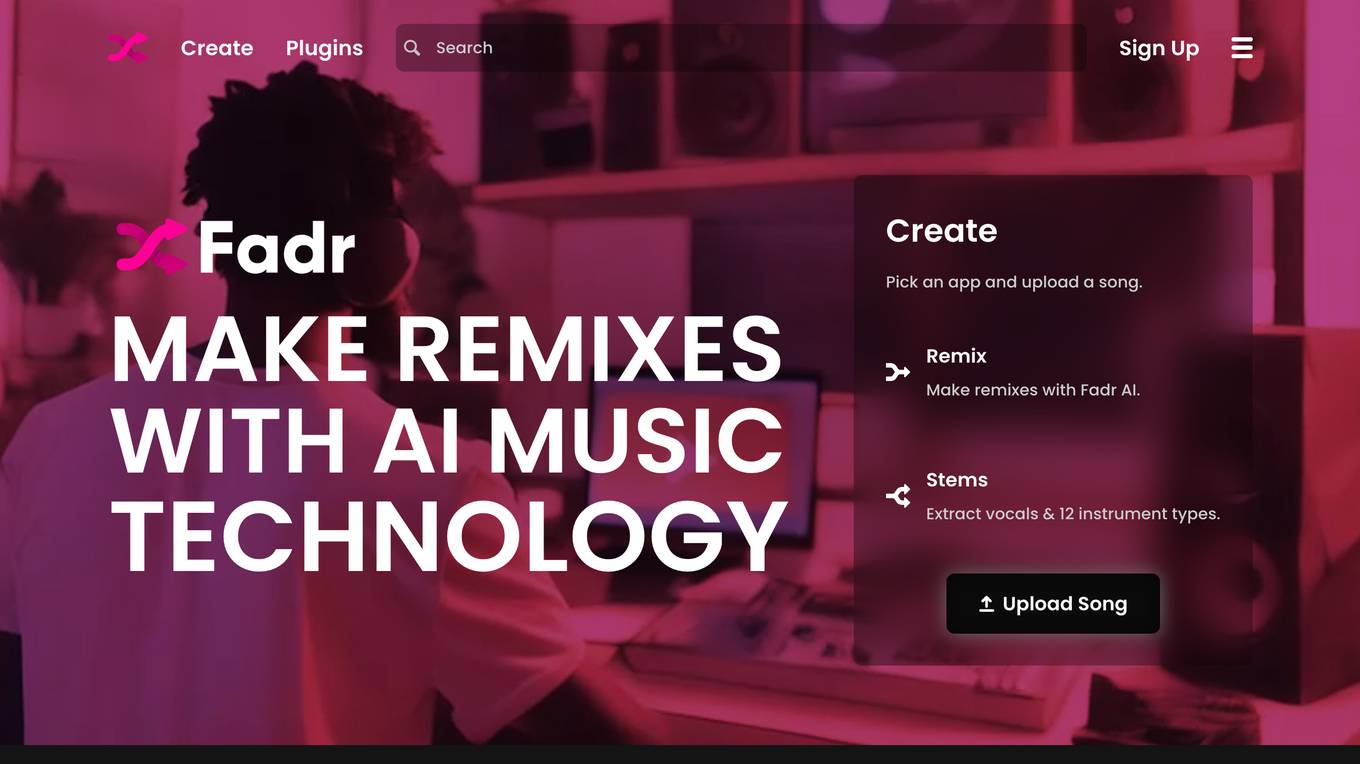
Fadr
Fadr is an AI music maker application that enhances creativity by providing tools for creating music using AI technology. Users can pick from a variety of tools like SynthGPT to create playable instruments with text, Remix to make remixes with Fadr AI, and Stems to extract vocals and instrument types. Fadr aims to amplify musical creativity by developing web apps and plugins that help users in making art and exploring new sounds.
Output
Output is the ultimate creative software for music makers, offering a range of tools and plugins to supercharge music production. With Output Arcade as the flagship product, musicians can access a powerful sampler and instrument plugin, along with FX plugins and Kontakt Instruments to transform their sound. The platform also introduces AI capabilities through features like Pack Generator, providing cutting-edge software for musicians to enhance their creativity and production workflow. Output aims to simplify the music-making process and empower artists to focus on their craft.
Stability AI
Stability AI is an AI application that offers a suite of models for various modalities such as image, video, audio, 3D, and language. It provides cutting-edge generative AI technology with a focus on stability and quality. Users can access advanced AI models for tasks like text-to-image generation, video modeling, audio generation, and more. The application also offers licensing options for commercial use and self-hosting benefits.
Tracksy
Tracksy is a generative AI assistant that empowers creators to effortlessly craft unique music, regardless of their musical background. With Tracksy, users can unleash their creativity by generating music using text, genre, or mood as their inspiration. The platform offers a user-friendly interface, making it accessible to both experienced musicians and those new to music creation. Tracksy's mission is to empower creators by providing them with the tools they need to bring their musical ideas to life.
VOCALOID
VOCALOID is a singing synthesizer software that allows users to create and edit vocal melodies and lyrics. It is used by musicians, producers, and songwriters to create a wide range of musical genres, from pop and rock to electronic and experimental music. VOCALOID is known for its realistic and expressive vocal synthesis, which is achieved through a combination of advanced sampling and modeling techniques.
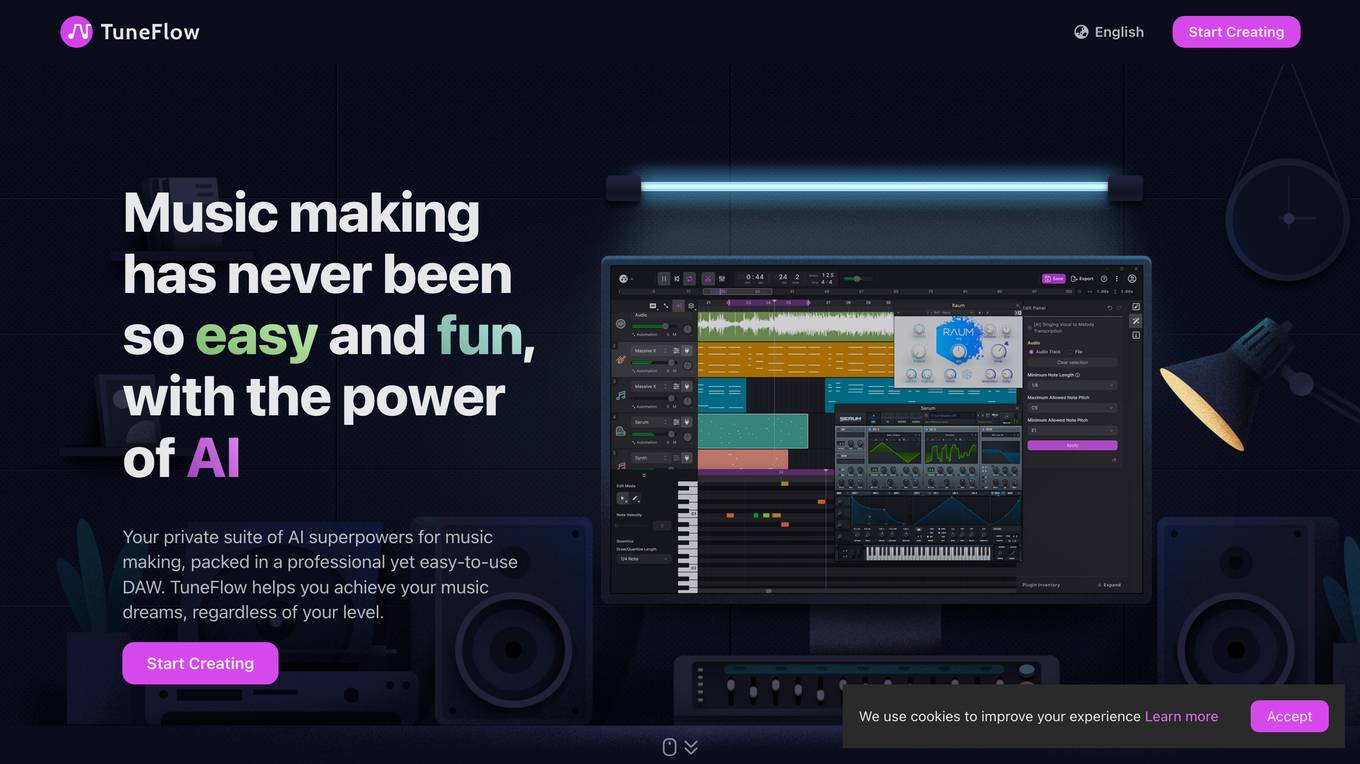
TuneFlow
TuneFlow is an intelligent music-making platform powered by AI. It provides users with a wide range of tools and features to create, edit, and share their music. TuneFlow is designed to be easy to use, even for beginners, and it offers a variety of features that make it a powerful tool for professional musicians as well.
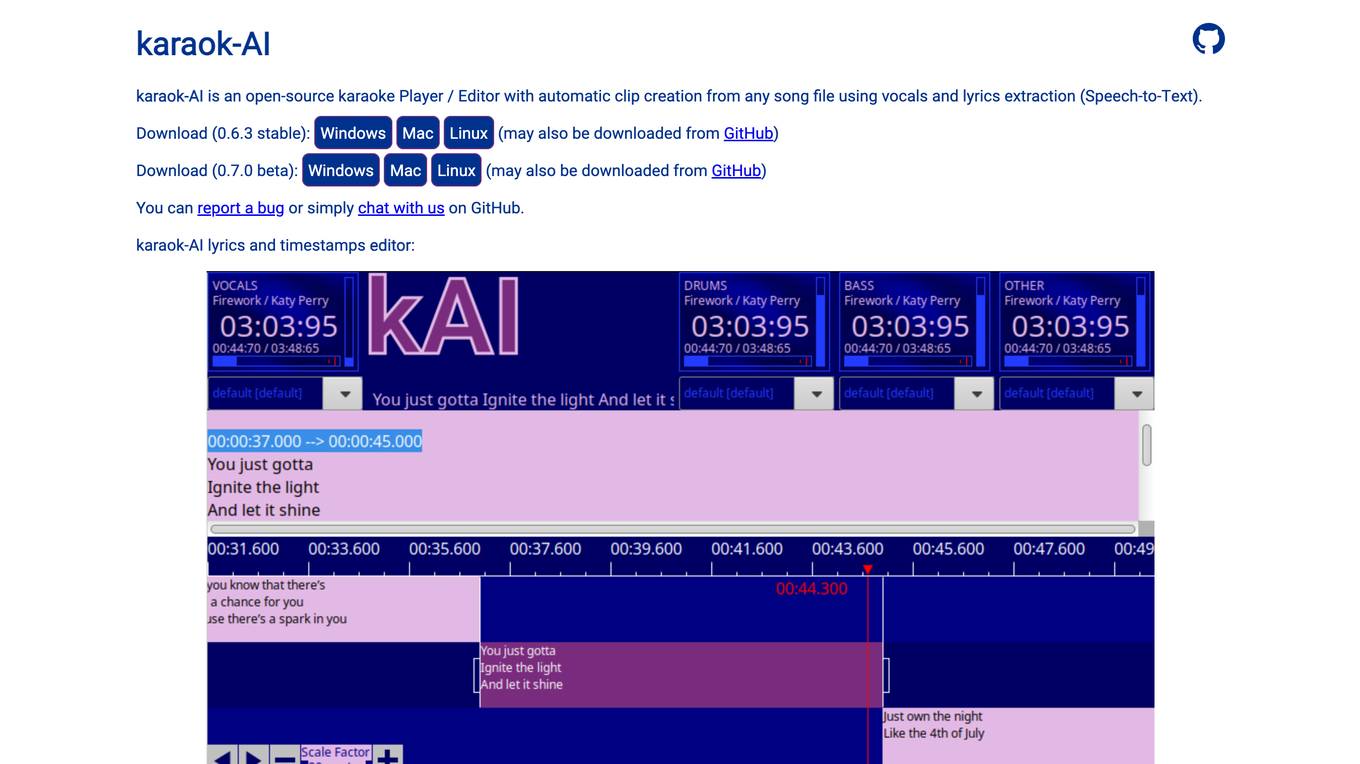
karaok-AI
karaok-AI is an open-source karaoke Player / Editor with automatic clip creation from any song file using vocals and lyrics extraction (Speech-to-Text). It uses WhisperHallu and WhisperTimeSync to extract vocals and lyrics. karaok-AI also includes kaiDJ, a minimalist and easy-to-use DJ Party Player with multi-sound cards support, two players with auto-mix between songs, and a pre-listen player. It can index thousands of songs in a single efficient database and allows for direct search and selection over all songs. Additionally, it offers playlist management with nested groups and the ability to open and save m3u and m3u8 playlists while keeping group definitions.
Virtuozy Pro
Virtuozy Pro is an AI-powered music assistant that helps musicians of all levels create, produce, and master their music. With its intuitive interface and powerful features, Virtuozy Pro makes it easy to generate chords, lyrics, and complete songs in a variety of genres. Whether you're a beginner looking to learn the basics of music theory or a professional musician looking to streamline your workflow, Virtuozy Pro has something to offer everyone.
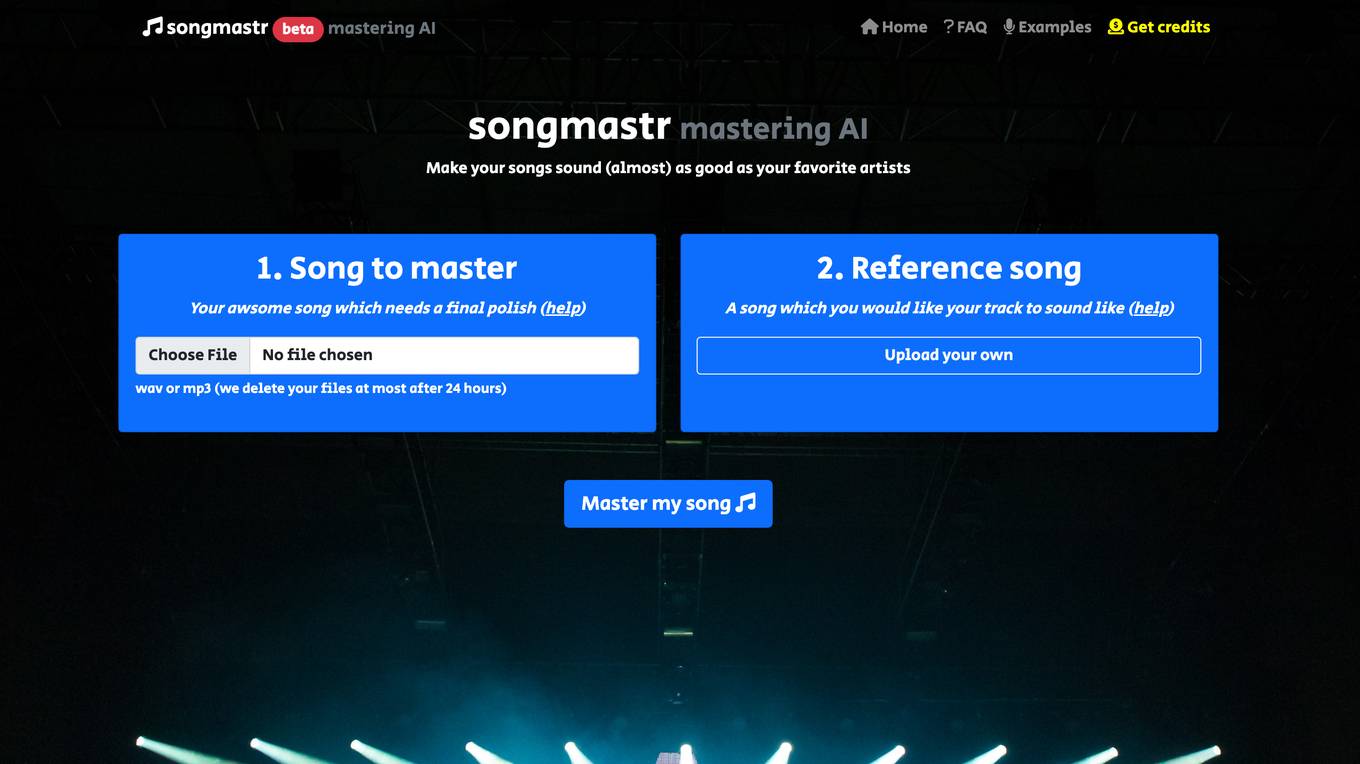
Songmastr
Songmastr is an automatic song mastering tool that uses artificial intelligence to master your songs to sound like a reference track. It's free to use for up to 7 songs per week, and you can master songs up to 10 minutes in length and 80MB in size. Songmastr is based on the open source library Matchering, and it uses the same RMS, FR, peak amplitude, and stereo width as the reference song you choose.

WarpSound
WarpSound is an AI music platform that uses cutting-edge generative AI technologies to create new forms of limitless music play and creativity. Its industry-leading music platform was developed in collaboration with Grammy-winning artists and uses a proprietary training dataset to produce original music in real time. It powers interactive music experiences and content for streaming, gaming, and more.

RipX DAW
RipX DAW is an AI-powered digital audio workstation (DAW) that allows users to edit notes in the mix, replace sounds, and separate stems. It is designed to assist musicians and producers in creating and editing music using AI-generated samples and loops. RipX DAW is known for its advanced features such as 6+ stem separation, sound replacement menu, and the ability to edit notes in the mix.
Respeecher
Respeecher is a voice cloning software that allows users to create synthetic voices that are indistinguishable from the original speaker. The software is used by content creators in a variety of industries, including film, television, gaming, advertising, and audiobooks. Respeecher's technology is based on artificial intelligence and machine learning, and it can replicate the voice of any person with just a few minutes of audio recording. The software is easy to use and can be accessed through a web interface. Respeecher offers a variety of features, including the ability to change the pitch, speed, and volume of the synthetic voice, as well as the ability to add effects such as reverb and delay. The software also includes a library of pre-recorded voices that can be used for a variety of purposes.

Emvoice
Emvoice is a cutting-edge vocal synthesis platform that empowers users to create realistic and expressive synthetic voices. With its advanced AI algorithms and intuitive interface, Emvoice makes it easy to generate high-quality voiceovers, audiobooks, and other audio content. Whether you're a professional voice actor, a content creator, or simply looking to add a touch of personality to your projects, Emvoice has the tools you need to bring your words to life.

Harmonai.org
Harmonai.org is a Stability AI Lab that develops open-source generative audio tools to make music production more accessible and enjoyable for everyone. The platform empowers artists by providing them with the ability to generate their own custom infinite sound libraries, fostering creativity without limitations.
AudioStrip
AudioStrip is a free online vocal isolator that allows you to remove vocals from any song. It uses artificial intelligence to separate the vocals from the music, and it does a surprisingly good job. You can use AudioStrip to create a cappella versions of your favorite songs, or you can use it to isolate the vocals from a song so that you can sing along with them. AudioStrip is easy to use. Just upload a song to the website, and then click the "Extract Vocals" button. AudioStrip will then process the song and create a new file that contains only the vocals. You can then download the new file to your computer.
Emergent Drums
Emergent Drums by Audialab is an AI-powered tool that allows users to generate an infinite number of royalty-free drum samples. With its advanced algorithms, Emergent Drums can create a wide range of drum sounds, from classic to modern, and everything in between. The tool is easy to use, and users can quickly generate drum samples that fit their specific needs. Emergent Drums is a valuable tool for musicians, producers, and anyone else who needs high-quality drum samples.

Resemble AI
Resemble AI is a cutting-edge generative voice AI platform that empowers enterprises with advanced voice cloning, deepfake detection, and AI watermarking capabilities. Our suite of tools enables the creation of realistic synthetic voices, detection of AI-generated content, and protection of intellectual property. With Resemble AI, businesses can enhance customer service, elevate gaming experiences, revolutionize entertainment, and safeguard their digital assets.
Synthesizer V
Dreamtonics is a Tokyo-based startup company specializing in computer music and speech technologies. They build music software to suit customers' creativity needs and offer technology licensing and the creation of artificial voices as a service for corporate clients. Their flagship product is Synthesizer V, a singing synthesizer that combines a powerful audio processing engine with an intuitive user interface. With Synthesizer V, users can create their own songs by sketching out the melody and filling in the lyrics.
Moises App
Moises App is a music application powered by AI that provides musicians with a range of tools to enhance their practice and performance. With Moises App, users can separate vocals and instruments in any song, adjust the speed and pitch, and detect chords in real time. The app also includes a smart metronome and audio speed changer, making it an ideal tool for musicians of all levels. Moises App is available as a desktop application, iOS app, and web app, making it accessible to musicians on any device.

Speech Studio
Speech Studio is a cloud-based speech-to-text and text-to-speech platform that enables developers to add speech capabilities to their applications. With Speech Studio, developers can easily transcribe audio and video files, generate synthetic speech, and build custom speech models. Speech Studio is a powerful tool that can be used to improve the accessibility, efficiency, and user experience of any application.
MusicGen AI
MusicGen AI is a free and advanced AI music generation tool developed by Meta. It utilizes a single Language Model (LM) to create high-quality music based on text descriptions, melodies, or audio prompts. MusicGen operates by encoding music into compressed tokens, which are then used to generate the music samples. It can produce music in various formats, including mono and stereo. MusicGen AI offers a range of features, including melody conditioning, text-conditional generation, audio-prompted generation, advanced model architecture, flexible generation modes, unconditional generation, extensive training dataset, and customizable generation process.
Sound of Text
Sound of Text is a free online text-to-speech converter that uses AI technology to convert written text into spoken words. It supports over 840 different voices in more than 135 languages, and allows users to download the resulting audio files in a variety of formats. Sound of Text is easy to use and can be used for a variety of purposes, such as creating audiobooks, podcasts, and presentations.

IA Hispano
IA Hispano is a platform that provides tools and resources for creating music. It offers a variety of features, including a music editor, a sound library, and a community forum. IA Hispano is designed to be easy to use, even for beginners, and it provides a great way to learn about music production.
Xound.io
Xound.io is an AI-powered voice cleaner and background noise removal tool designed for content creators, podcasters, YouTubers, TikTokers, and anyone who wants to improve the audio quality of their content. It uses advanced algorithms to remove background noise, enhance vocals, and improve the overall listening experience. Xound.io is easy to use, with a simple drag-and-drop interface and no need for any technical expertise. It also offers a variety of features, including natural pitch correction, AI background noise removal, and high-frequency presence.

Artificial Intelligence Radio
Artificial Intelligence Radio is a website that provides AI-generated music. The website features a variety of AI-generated songs that can be streamed or downloaded for free. The website also includes a blog that discusses the latest developments in AI music generation.
AudioShake
AudioShake is a cloud-based audio processing platform that uses artificial intelligence (AI) to separate audio into its component parts, such as vocals, music, and effects. This technology can be used for a variety of applications, including mixing and mastering, localization and captioning, interactive audio, and sync licensing.
Suno
Suno is an all-in-one AI music generation tool that allows users to create, edit, and share music with ease. With Suno, you can generate music from scratch, add lyrics, and even collaborate with other musicians. Suno is perfect for musicians of all levels, from beginners to professionals.

Rightsify
Rightsify is a global music licensing agency that provides music for almost every use case imaginable, with a catalog of over 10 million songs that gets heard by over one billion people every year. Rightsify's music is available for businesses worldwide, and its Hydra AI Music Model enables high-quality music production for all with full commercial rights.
AI Singing
AI Singing is an AI-powered tool that allows users to generate music and singing voices from text. With AI Singing, you can quickly and easily create songs by simply entering your lyrics. The tool uses advanced artificial intelligence algorithms to convert your text into realistic and expressive singing voices. AI Singing is perfect for musicians, singers, songwriters, and anyone who wants to create music without having to spend hours learning complex music production software.
Suno AI Download
Suno AI Download is a free tool for downloading music generated by Suno AI. It allows users to download music from Suno AI's website by providing a share URL. The tool is easy to use and does not require any registration or installation.
Audacity
Audacity is a free and open-source audio editing and recording software that runs on Windows, macOS, GNU/Linux, and other operating systems. It is popular for its ease of use, multi-track editing capabilities, and support for a wide range of audio formats. Audacity can be used for a variety of tasks, including recording and editing podcasts, music, and other audio content. It also supports a variety of plugins, which can extend its functionality even further.

SRVO
SRVO is a voice over service that provides high-quality, professional voice overs for a variety of purposes, including commercials, e-learning, and audiobooks. With a team of experienced voice actors and a state-of-the-art recording studio, SRVO can create custom voice overs that meet the specific needs of each client. SRVO also offers a variety of additional services, such as scriptwriting, audio editing, and mixing.
Vocalist.ai
Vocalist.ai is a cutting-edge AI-powered platform that empowers users to transform their vocals into world-class singers and rappers in a matter of seconds. With its innovative technology, users can leverage a diverse range of expertly curated and beautifully modeled vocalists and rappers covering multiple genres. This groundbreaking tool allows for effortless creation of both male and female versions of songs, or even the addition of rap features to enhance the musical experience. Vocalists.ai is committed to ethical AI practices, ensuring fair payment to artists and maintaining a low barrier to entry for creators. By balancing the goals of creators and artists, Vocalists.ai fosters a thriving ecosystem for emerging AI in the music industry.
LIDO
LIDO is an AI-powered music generator that allows users to create unique and original music with lyrics. It is designed to be accessible to both budding musicians and those simply looking to explore the endless possibilities of music. With LIDO, users can generate music in a variety of styles, including hip-hop, pop, rock, and electronic. The tool is easy to use and requires no prior musical knowledge. Simply select a style, enter some lyrics, and LIDO will generate a complete song.
Audio Enhancer
Audio Enhancer is an AI-powered tool that helps users enhance the quality of their audio files by removing background noise, improving clarity, and adjusting levels. It is designed to be easy to use, with a simple drag-and-drop interface and a variety of presets to choose from. Audio Enhancer is suitable for a wide range of audio applications, including podcasts, videos, music, and more.
Revoldiv
Revoldiv is a California-based platform that simplifies media creation and consumption for podcast enthusiasts and media creators. Their platform aims to provide a simple space for building a community by connecting podcasters, listeners, and industry professionals.
AISong.ai
AISong.ai is a free alternative AI music generator that allows users to create unique MP3 songs instantly. Users can generate custom music with lyrics, instrumental style, and title. The website offers innovative music creation capabilities, enabling users to download and enjoy their creations. AISong.ai is not affiliated with Suno AI, but it provides a similar AI music generation experience.

TRINITY Audio
TRINITY Audio is an AI tool designed for serving audio content. It specializes in providing audio solutions for various purposes. The platform offers advanced features to enhance the audio experience for users across different domains. TRINITY Audio is a reliable and efficient tool for managing and delivering audio content seamlessly.
Suno-Top
Suno-Top is a free AI-powered music downloader tool that allows users to easily download Suno music, including mp3 and mp4 files, lyrics, covers, and song prompts. Users can copy the Suno song link, paste it on the website, and download the desired content. Additionally, Suno-Top offers creative AI music crafting techniques, such as live performances, beat enhancements, instrumental nuances, and duet dynamics, to enhance musical creativity and collaboration. The tool supports various music genres and styles, providing a unique platform for users to explore and experiment with different musical compositions.
AI Mastering
AI Mastering is an automatic online audio mastering service powered by AI technology. It offers users the ability to easily improve the sound quality of their music by balancing loudness, dynamic range, and utilizing a powerful limiter. The tool provides customization options for mastering levels, output formats, and spectrum analysis. With over 2,700 total users and more than 3,600 masterings done monthly, AI Mastering is a popular choice for musicians and audio enthusiasts looking to enhance their music effortlessly.
SunoMusic
SunoMusic is a free AI music generator tool developed by SunoAI. Users can create unique Suno AI MP3 songs instantly and download them for free. The tool offers custom mode for song creation, allowing users to specify song description, lyrics, instrumental style of music, and title. SunoMusic aims to provide innovative music creation experience to its users.
AI Sound Effect Generator
The AI Sound Effect Generator is a free online tool that allows users to create realistic AI sounds for their projects. It offers a wide range of customizable sound effects, from futuristic tones to nature sounds, using cutting-edge technology. The platform features an easy-to-use interface and provides high-quality audio output for professional-grade projects.
Respeecher
Respeecher is an AI tool that combines technology and magic to deliver authentic voices across various industries. It uses cutting-edge public models and proprietary technology to provide high-quality voice solutions. The team of dedicated sound professionals at Respeecher ensures ethical use of synthetic media, making it a trusted choice for voice cloning and voice conversion services.
Umbra
Umbra is an AI application that focuses on AI entertainment, AI art, AI stories, and AI shows. It provides a platform for exploring the latest advancements in AI entertainment, including AI-generated music, AI art, and AI stories. Users can also find resources related to game development, gaming news, and top games. The application offers a variety of guides, tips, and tutorials for game development, Unreal Engine, game UIs, audio design, level design, 3D modeling, and game mechanics optimization.
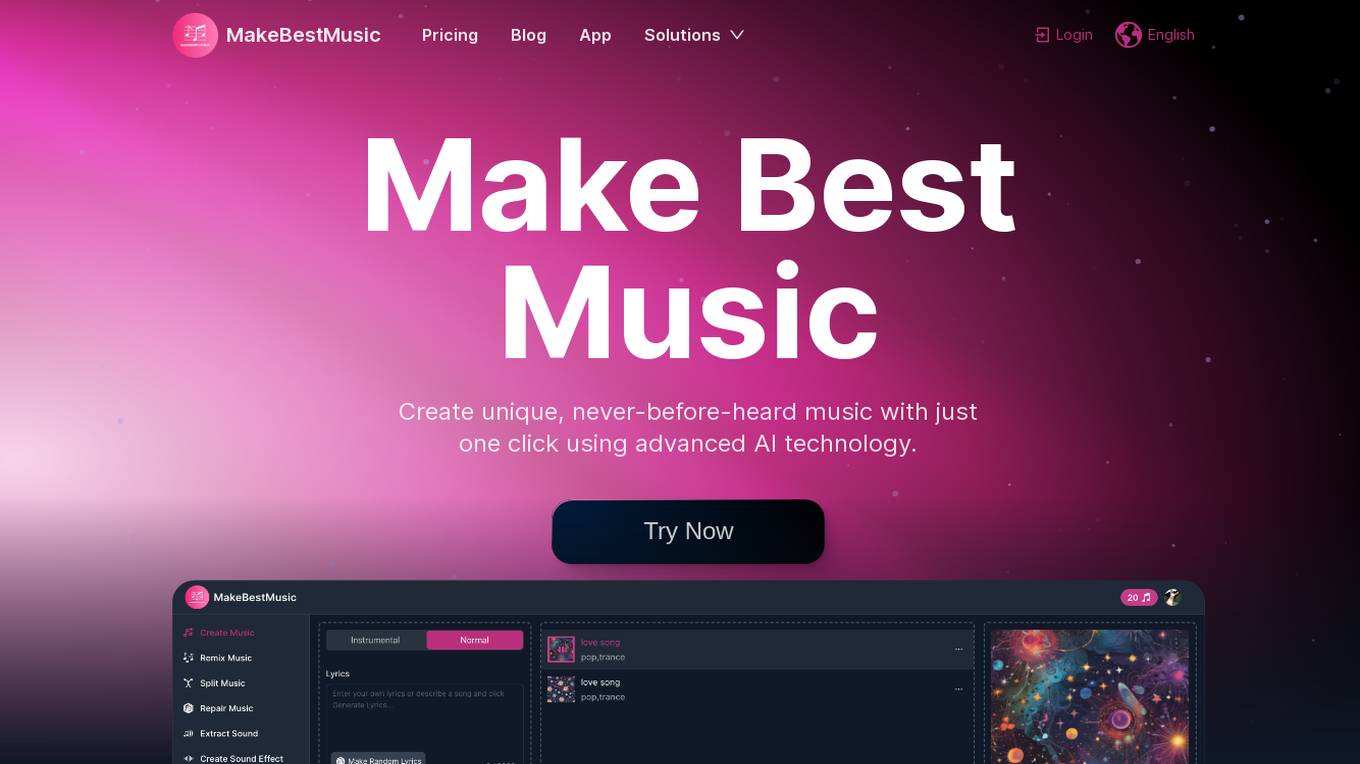
MakeBestMusic
MakeBestMusic is an AI-powered music production suite that allows users to create unique music with just one click using advanced AI technology. The platform offers features such as creating instrumental and vocal music by providing simple descriptive words or lyrics, remixing music by uploading audio files and providing remix descriptions, and splitting music files to extract drums and vocals. MakeBestMusic provides a versatile approach to music creation, catering to both instrumental and vocal preferences with ease. Users can generate dynamic music, remix original audio files, and extract sounds from background music using the powerful AI music tool.
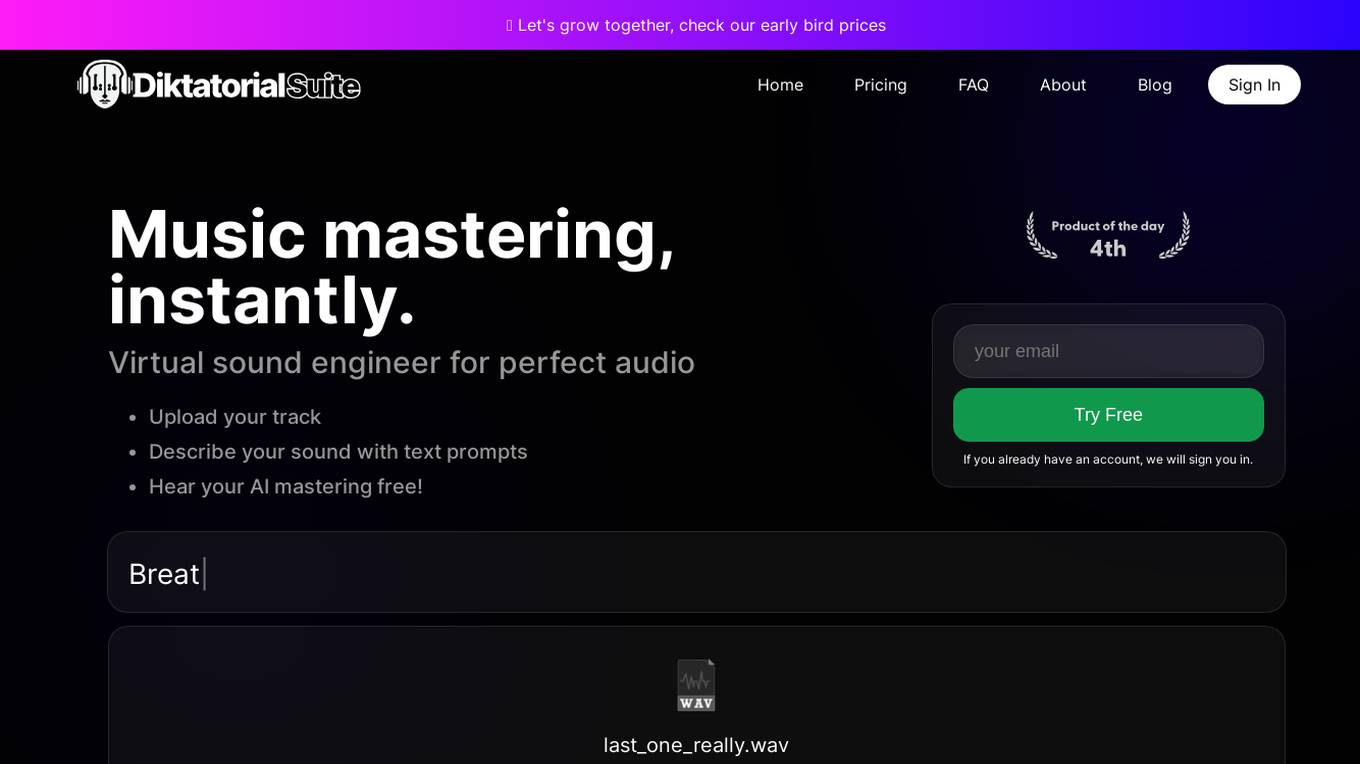
DIKTATORIAL Suite
DIKTATORIAL Suite is an online AI mastering tool for audio and music, offering instant music mastering with the help of virtual sound engineers. Users can upload their tracks, describe their sound preferences, and receive high-quality audio mastering within seconds. The tool is designed for audio professionals, musicians, mastering engineers, and bedroom producers, providing streaming optimization for platforms like Spotify and Apple Music. Developed by musicians, DIKTATORIAL Suite ensures safe and secure AI processing without sharing user data with third parties. With a focus on sonic possibilities and genre-specific mastering, the tool aims to deliver professional results for musicians worldwide.
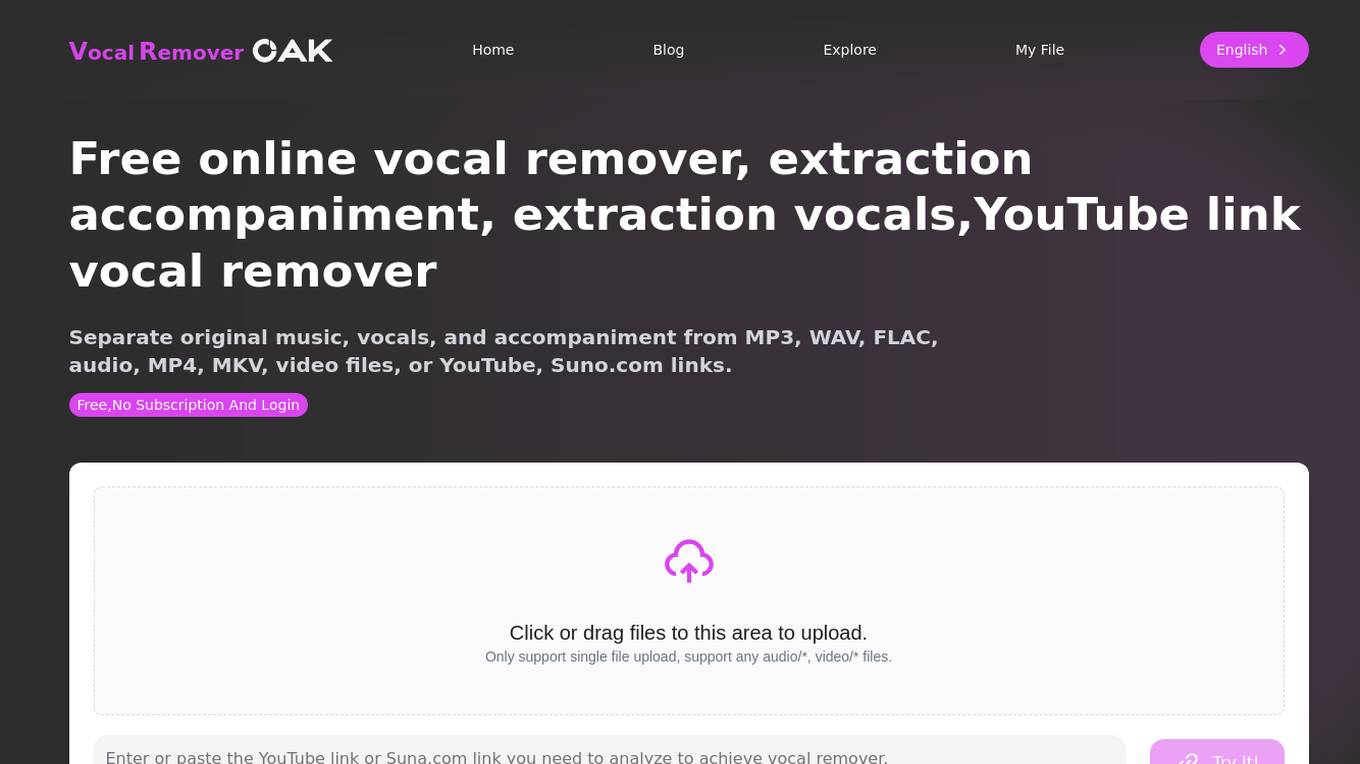
Vocal Remover Oak
Vocal Remover Oak is an advanced AI tool designed for music producers, video makers, and karaoke enthusiasts to easily separate vocals and accompaniment in audio files. The website offers a free online vocal remover service that utilizes deep learning technology to provide fast processing, high-quality output, and support for various audio and video formats. Users can upload local files or provide YouTube links to extract vocals, accompaniment, and original music. The tool ensures lossless audio output quality and compatibility with multiple formats, making it suitable for professional music production and personal entertainment projects.
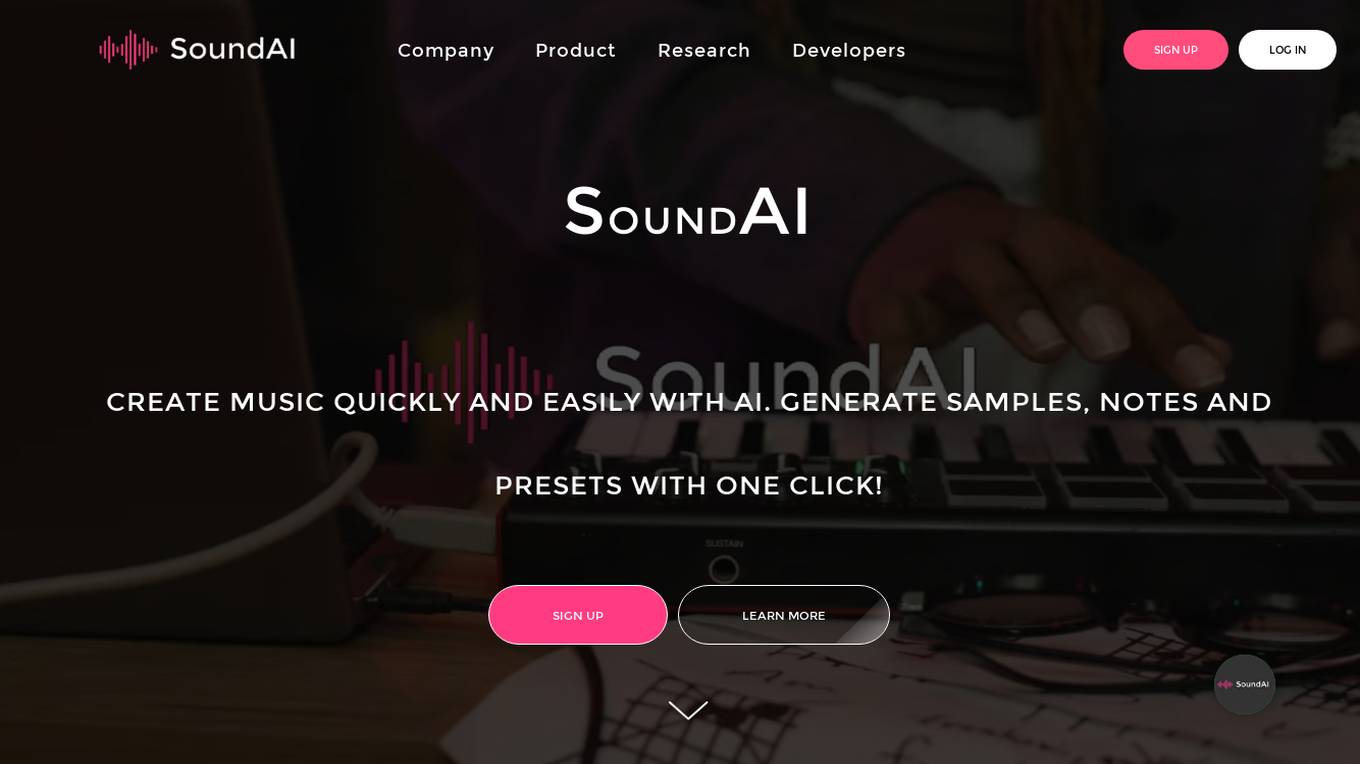
SoundAI
SoundAI is an artificial intelligence-based instrumental web service that enables users to create and generate music samples, MIDI files, and presets for virtual synthesizers. The platform utilizes AI technology to assist musicians and composers in generating new melodies, exploring musical ideas, synthesizing sounds, modifying audio characteristics, and integrating with various projects. SoundAI aims to revolutionize the music industry by providing advanced AI technology for high-quality sound creation and real-time collaboration.
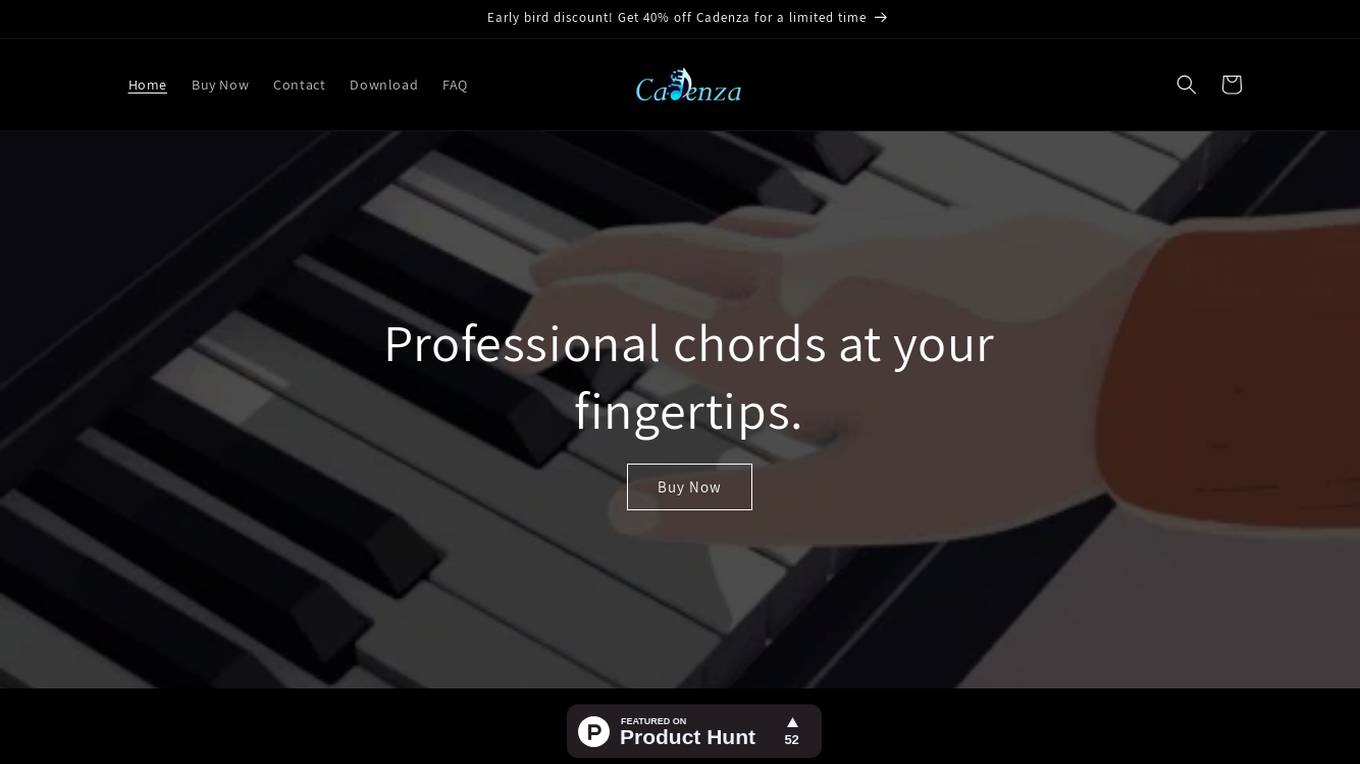
Cadenza
Cadenza is an AI-powered music production tool that helps users create professional-grade chord progressions effortlessly. By simply describing the chords or the vibe they want, users can generate midi chord progressions with smooth transitions. The tool allows users to prompt the AI with specific chord types or song descriptions, generate the midi file in real-time, and seamlessly integrate the created chords into their preferred DAW for further music production. Cadenza simplifies the music creation process by leveraging state-of-the-art AI algorithms to cater to both beginners and advanced music producers.
AudioForgeAI
AudioForgeAI is an AI-powered online platform that offers advanced audio editing and enhancement tools. Users can easily upload their audio files and apply various editing techniques to improve the quality and clarity of the sound. The platform is designed to be user-friendly and intuitive, making it suitable for both beginners and experienced audio professionals. With AudioForgeAI, users can enhance audio recordings, remove background noise, adjust volume levels, and apply various effects to create high-quality audio content.

Soundverse AI
Soundverse AI is an AI music generator and music assistant that allows users to create music instantly from text prompts, interact with a voice assistant for music-related help, chat with the assistant for music recommendations, extend existing tracks with new sections, isolate individual audio tracks from a mix, auto-complete songs using initial ideas, craft lyrics with AI assistance, and more. The platform offers a range of AI tools to help users iterate and personalize their music creation process, making it easy to transform ideas into music in seconds.
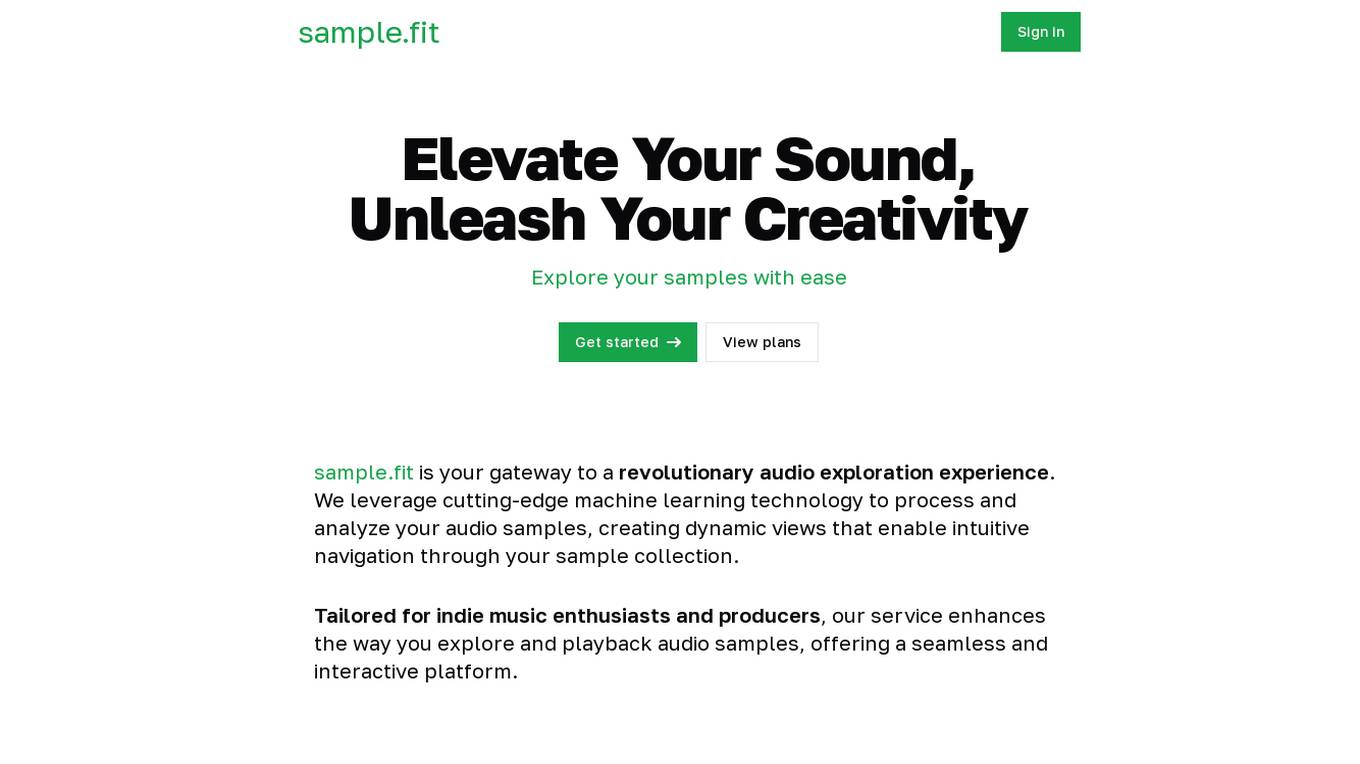
sample.fit
sample.fit is an AI tool designed to revolutionize the audio exploration experience for indie music enthusiasts and producers. By leveraging cutting-edge machine learning technology, the platform processes and analyzes audio samples to create dynamic views for intuitive navigation through sample collections. The service offers a seamless and interactive platform for exploring and playback audio samples, enhancing creativity and sound production.
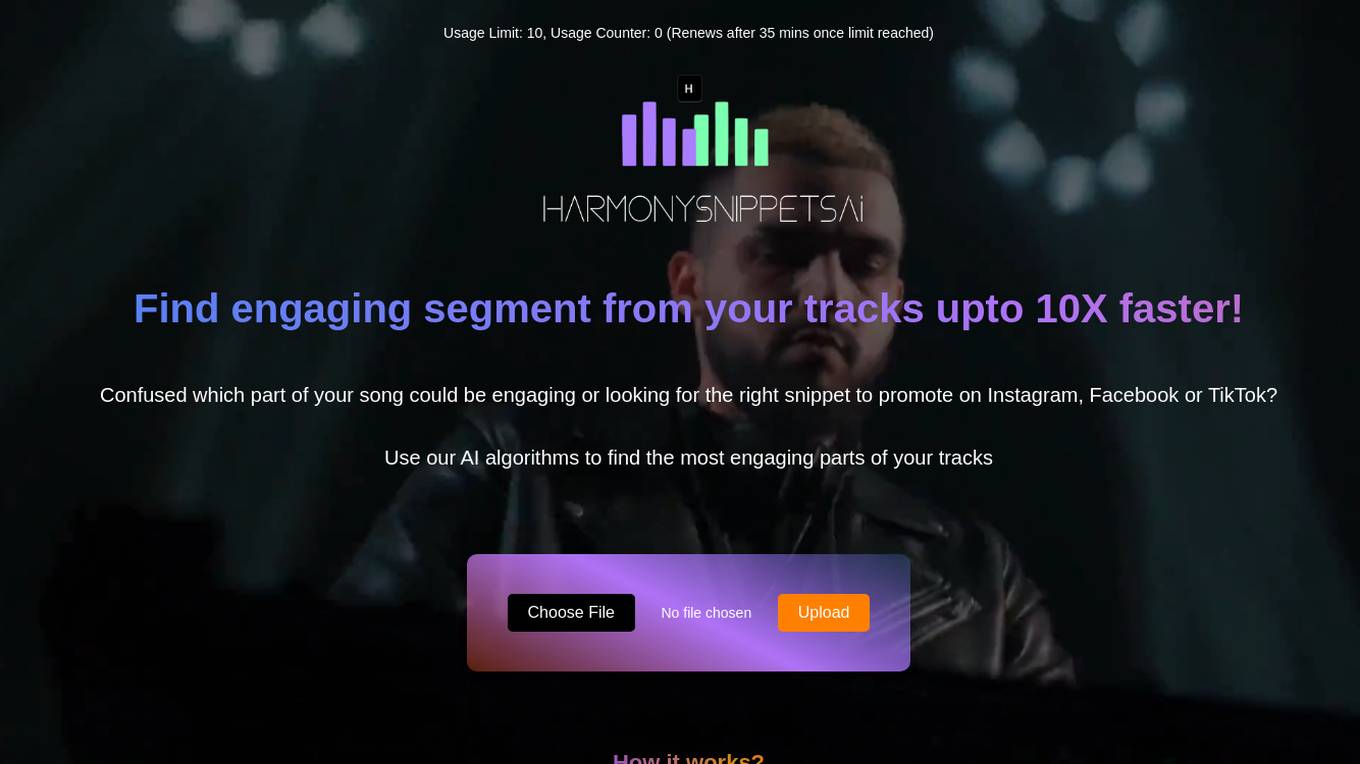
HarmonySnippetsAI
HarmonySnippetsAI is an AI application designed to help music creators and content producers identify engaging segments within their tracks quickly and efficiently. By leveraging AI algorithms, users can upload audio files and receive results that highlight the most captivating parts of their music. This tool is ideal for musicians looking to promote their work on social media platforms like Instagram, Facebook, and TikTok, enhancing audience engagement and expanding their reach.
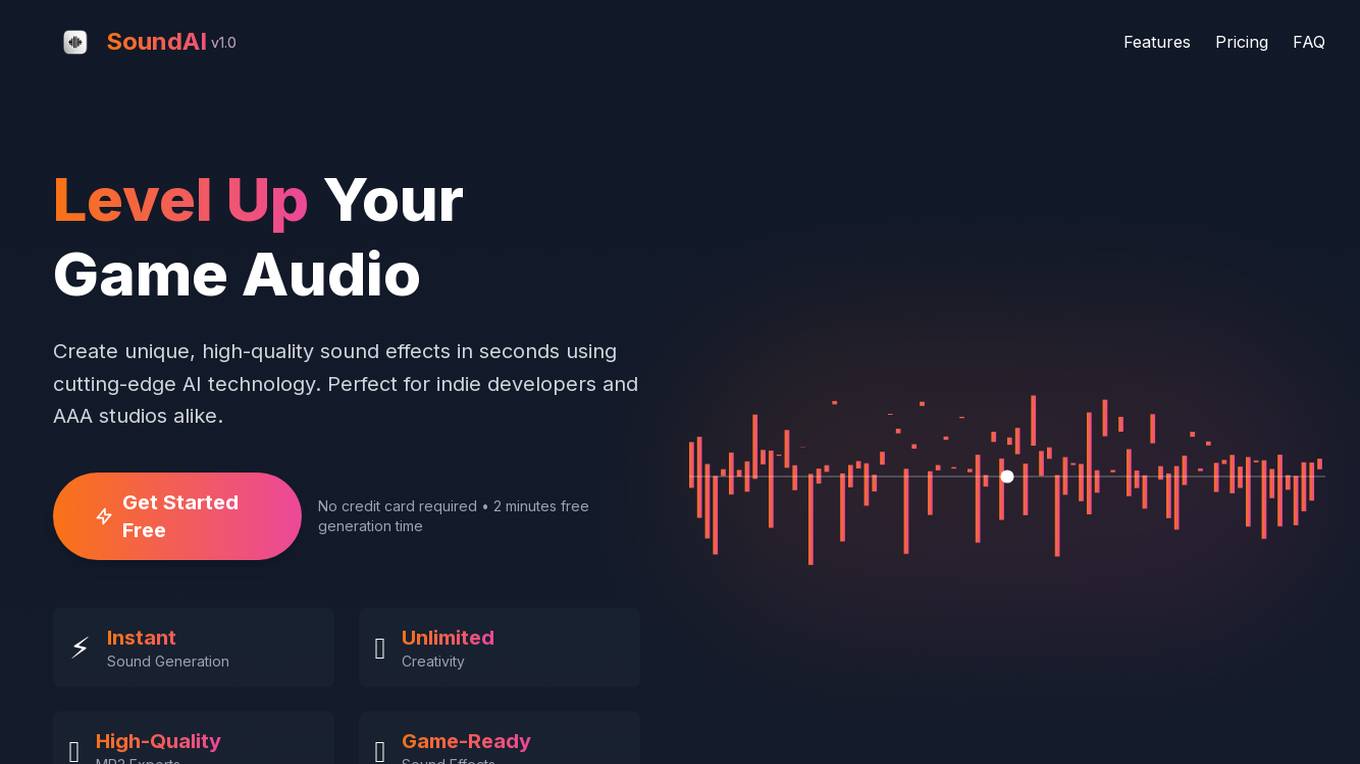
SoundAI Studio
SoundAI Studio is an AI-powered tool designed to help users create unique and high-quality sound effects for video games in seconds. It harnesses cutting-edge AI technology to generate custom sound effects based on text descriptions, offering instant sound generation, unlimited creativity, and game-ready sound effects. With simple and transparent pricing, users can access features like high-quality MP3 exports, customizable parameters, and a personal library of AI-generated sound effects. Whether you're an indie developer or a AAA studio, SoundAI Studio is the perfect solution to level up your game audio effortlessly.
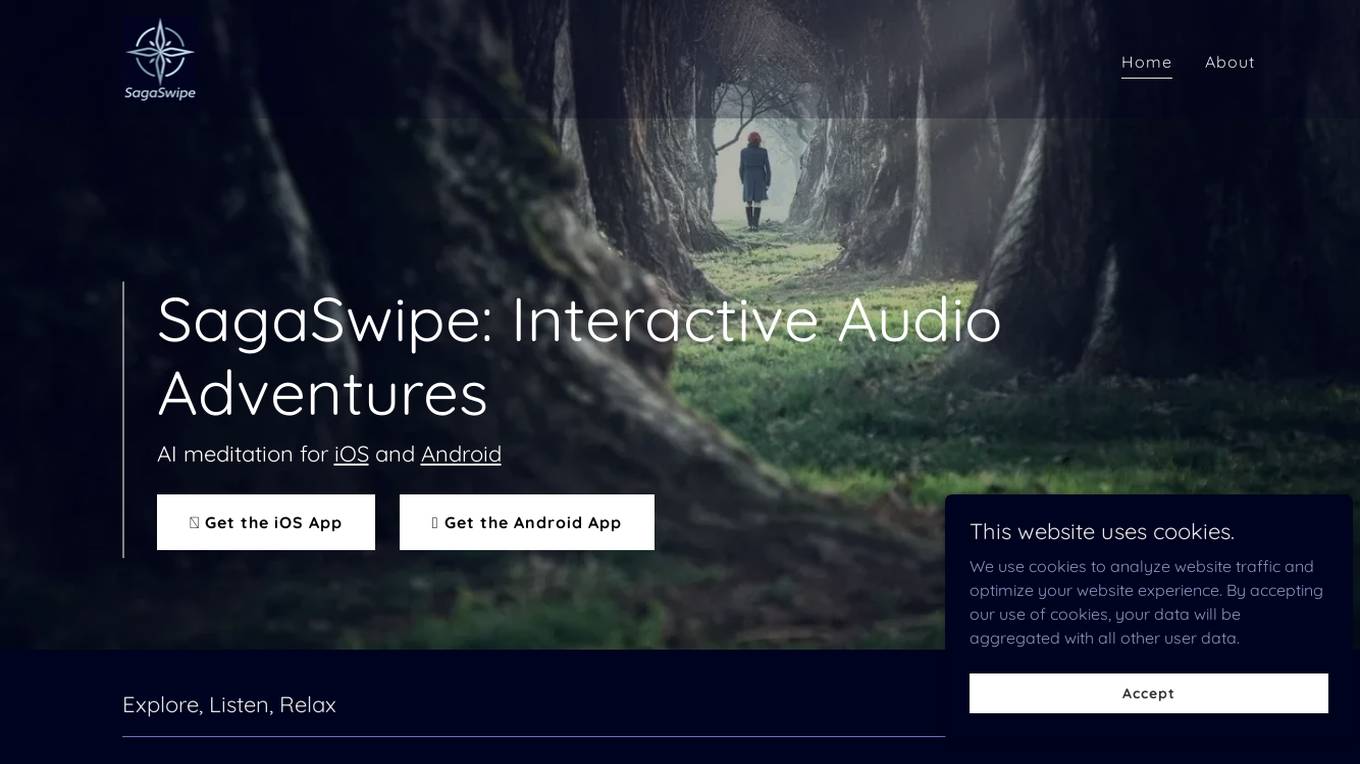
SagaSwipe
SagaSwipe is an interactive audio adventure application designed for iOS and Android users. It offers a unique experience where users can immerse themselves in infinite audio realms guided solely by touch. Unlike traditional sleep apps, SagaSwipe provides engaging escapes into magical realms, vibrant cities, serene landscapes, or mysterious outer space. The application combines AI and voice synthesis technology with an intuitive interface to generate personalized audio worlds for users to explore and relax.
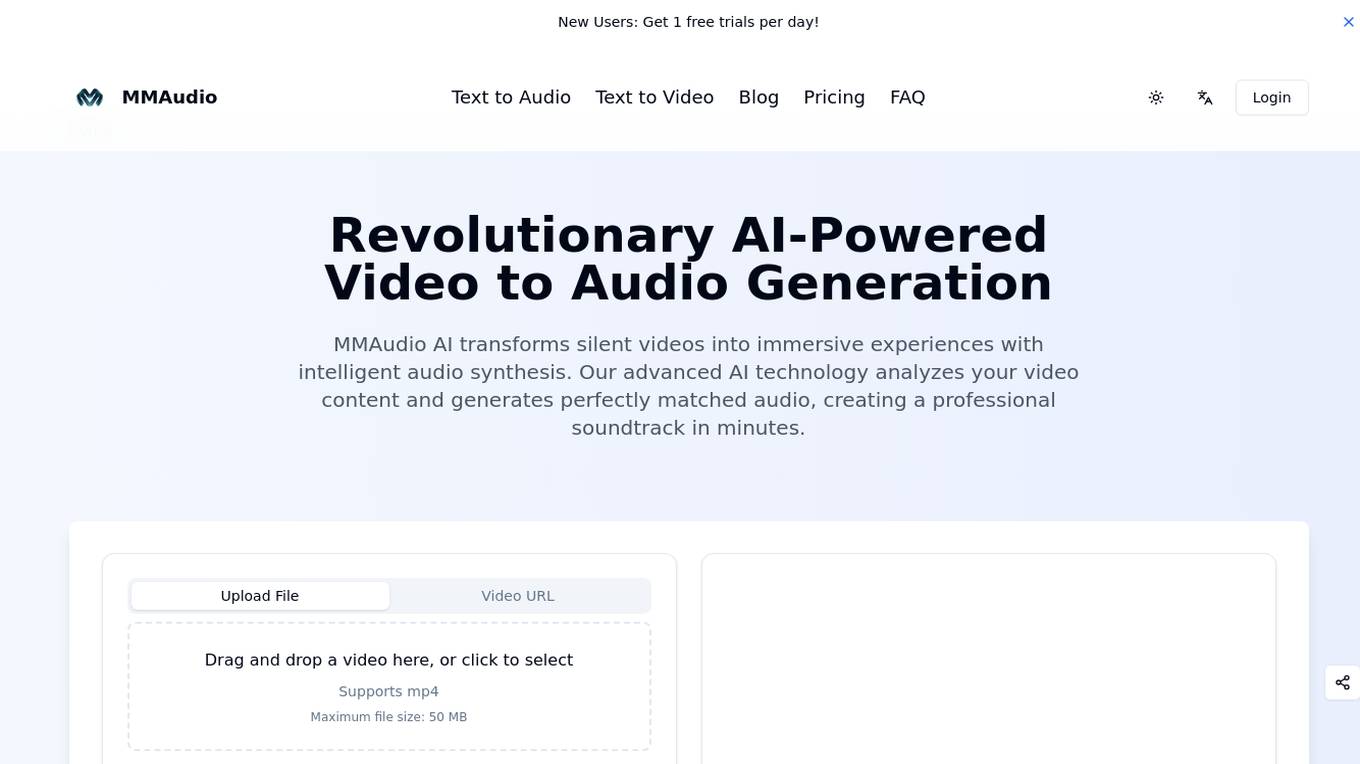
MMAudio
MMAudio is an AI-powered platform that specializes in transforming silent videos into immersive experiences with intelligent audio synthesis. The advanced AI technology analyzes video content to generate perfectly matched audio, creating professional soundtracks in minutes. MMAudio offers cutting-edge features for video audio generation, catering to various industries such as education, film production, game development, historical film enhancement, social media content, and storytelling. The platform provides seamless AI-powered video to audio transformation in three simple steps: uploading the video, advanced AI analysis, and intelligent audio generation. MMAudio stands out through its high-quality output, real-time processing capabilities, and extensive customization options.
fal
fal is an AI platform that offers cutting-edge AI models and tools for image and video generation, editing, and audio processing. It partners with leading AI companies to bring state-of-the-art technology to its users, enabling them to create stunning visual and audio content with ease. fal is at the forefront of the AI-driven media creation revolution, providing developers and creators with advanced tools to push the boundaries of creativity.
pyannote AI Speaker Intelligence Platform
The pyannote AI Speaker Intelligence Platform is an advanced AI tool designed for developers to detect, segment, label, and separate speakers in any language. It offers state-of-the-art speaker diarization models that accurately identify speakers in audio recordings, providing valuable insights and improving productivity. With optimized AI models, the platform saves time, effort, and money by delivering top-tier performance. The tool is language agnostic and offers advanced features such as speaker partitioning, identification, overlapping speech detection, voice activity detection, speaker separation, and confidence scoring.
Meloflow
Meloflow is an AI-powered music platform that offers an AI Music Generator & AI Song Generator. Users can effortlessly create songs, compose tracks, and enjoy royalty-free music creation with ease. The platform revolutionizes content creation across industries by providing professional-quality music, beats, and melodies in seconds using cutting-edge artificial intelligence technology. Meloflow caters to content creators, musicians, podcasters, and businesses looking to harness the power of AI for creative and commercial purposes.
Boris FX
Boris FX is an award-winning AI-powered post-production tool that offers a comprehensive suite of products for film, video, photography, and audio editing. With a focus on VFX, tracking, masking, rotoscoping, 3D solving, and audio restoration, Boris FX provides a one-stop solution for content creators. The platform also features tutorials, premium training, live interviews, and community forums to support users in mastering their post-production tasks.
49 - Open Source Tools

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text

suno-api
Suno AI API is an open-source project that allows developers to integrate the music generation capabilities of Suno.ai into their own applications. The API provides a simple and convenient way to generate music, lyrics, and other audio content using Suno.ai's powerful AI models. With Suno AI API, developers can easily add music generation functionality to their apps, websites, and other projects.

bark.cpp
Bark.cpp is a C/C++ implementation of the Bark model, a real-time, multilingual text-to-speech generation model. It supports AVX, AVX2, and AVX512 for x86 architectures, and is compatible with both CPU and GPU backends. Bark.cpp also supports mixed F16/F32 precision and 4-bit, 5-bit, and 8-bit integer quantization. It can be used to generate realistic-sounding audio from text prompts.

NSMusicS
NSMusicS is a local music software that is expected to support multiple platforms with AI capabilities and multimodal features. The goal of NSMusicS is to integrate various functions (such as artificial intelligence, streaming, music library management, cross platform, etc.), which can be understood as similar to Navidrome but with more features than Navidrome. It wants to become a plugin integrated application that can almost have all music functions.

ai-voice-cloning
This repository provides a tool for AI voice cloning, allowing users to generate synthetic speech that closely resembles a target speaker's voice. The tool is designed to be user-friendly and accessible, with a graphical user interface that guides users through the process of training a voice model and generating synthetic speech. The tool also includes a variety of features that allow users to customize the generated speech, such as the pitch, volume, and speaking rate. Overall, this tool is a valuable resource for anyone interested in creating realistic and engaging synthetic speech.

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio

openvino-plugins-ai-audacity
OpenVINO™ AI Plugins for Audacity* are a set of AI-enabled effects, generators, and analyzers for Audacity®. These AI features run 100% locally on your PC -- no internet connection necessary! OpenVINO™ is used to run AI models on supported accelerators found on the user's system such as CPU, GPU, and NPU. * **Music Separation**: Separate a mono or stereo track into individual stems -- Drums, Bass, Vocals, & Other Instruments. * **Noise Suppression**: Removes background noise from an audio sample. * **Music Generation & Continuation**: Uses MusicGen LLM to generate snippets of music, or to generate a continuation of an existing snippet of music. * **Whisper Transcription**: Uses whisper.cpp to generate a label track containing the transcription or translation for a given selection of spoken audio or vocals.

WavCraft
WavCraft is an LLM-driven agent for audio content creation and editing. It applies LLM to connect various audio expert models and DSP function together. With WavCraft, users can edit the content of given audio clip(s) conditioned on text input, create an audio clip given text input, get more inspiration from WavCraft by prompting a script setting and let the model do the scriptwriting and create the sound, and check if your audio file is synthesized by WavCraft.

lhotse
Lhotse is a Python library designed to make speech and audio data preparation flexible and accessible. It aims to attract a wider community to speech processing tasks by providing a Python-centric design and an expressive command-line interface. Lhotse offers standard data preparation recipes, PyTorch Dataset classes for speech tasks, and efficient data preparation for model training with audio cuts. It supports data augmentation, feature extraction, and feature-space cut mixing. The tool extends Kaldi's data preparation recipes with seamless PyTorch integration, human-readable text manifests, and convenient Python classes.
audioseal
AudioSeal is a method for speech localized watermarking, designed with state-of-the-art robustness and detector speed. It jointly trains a generator to embed a watermark in audio and a detector to detect watermarked fragments in longer audios, even in the presence of editing. The tool achieves top-notch detection performance at the sample level, generates minimal alteration of signal quality, and is robust to various audio editing types. With a fast, single-pass detector, AudioSeal surpasses existing models in speed, making it ideal for large-scale and real-time applications.
obs-cleanstream
CleanStream is an OBS plugin that utilizes AI to clean live audio streams by removing unwanted words and utterances, such as 'uh's and 'um's, and configurable words like profanity. It uses a neural network (OpenAI Whisper) in real-time to predict speech and eliminate unwanted words. The plugin is still experimental and not recommended for live production use, but it is functional for testing purposes. Users can adjust settings and configure the plugin to enhance audio quality during live streams.
aiotone
Aiotone is a repository containing audio synthesis and MIDI processing tools in AsyncIO. It includes a work-in-progress polyphonic 4-operator FM synthesizer, tools for performing on Moog Mother 32 synthesizers, sequencing Novation Circuit and Novation Circuit Mono Station, and self-generating sequences for Moog Mother 32 synthesizers and Moog Subharmonicon. The tools are designed for real-time audio processing and MIDI control, with features like polyphony, modulation, and sequencing. The repository provides examples and tutorials for using the tools in music production and live performances.
airwin2rack
The 'airwin2rack' repository is a collection of Airwindows audio plugins presented in various formats, including as a static library, a module for VCV Rack, and as CLAP/VST3/AU/LV2/Standalone plugins for DAWs. Users can access these plugins through different methods and interfaces, such as a uniform registry and access pattern, making it easy to integrate Airwindows plugins into their audio projects. The repository also provides instructions for updating the Airwindows sub-library and information on licensing, ensuring that users can utilize the plugins in both open and closed source environments.
Demucs-Gui
Demucs GUI is a graphical user interface for the music separation project Demucs. It aims to allow users without coding experience to easily separate tracks. The tool provides a user-friendly interface for running the Demucs project, which originally used the scientific library torch. The GUI simplifies the process of separating tracks and provides support for different platforms such as Windows, macOS, and Linux. Users can donate to support the development of new models for the project, and the tool has specific system requirements including minimum system versions and hardware specifications.

speechlib
Speechlib is a Python library that provides functionalities for speaker diarization, speaker recognition, and transcription on audio files. It offers features such as converting audio formats to WAV, converting stereo to mono, and re-encoding to 16-bit PCM. The library allows users to transcribe audio files, store transcripts, specify language and model size, and perform speaker recognition using voice samples. It supports various languages and provides performance metrics for different model sizes. Speechlib utilizes huggingface models for speaker recognition and transcription tasks.

openlrc
Open-Lyrics is a Python library that transcribes voice files using faster-whisper and translates/polishes the resulting text into `.lrc` files in the desired language using LLM, e.g. OpenAI-GPT, Anthropic-Claude. It offers well preprocessed audio to reduce hallucination and context-aware translation to improve translation quality. Users can install the library from PyPI or GitHub and follow the installation steps to set up the environment. The tool supports GUI usage and provides Python code examples for transcription and translation tasks. It also includes features like utilizing context and glossary for translation enhancement, pricing information for different models, and a list of todo tasks for future improvements.
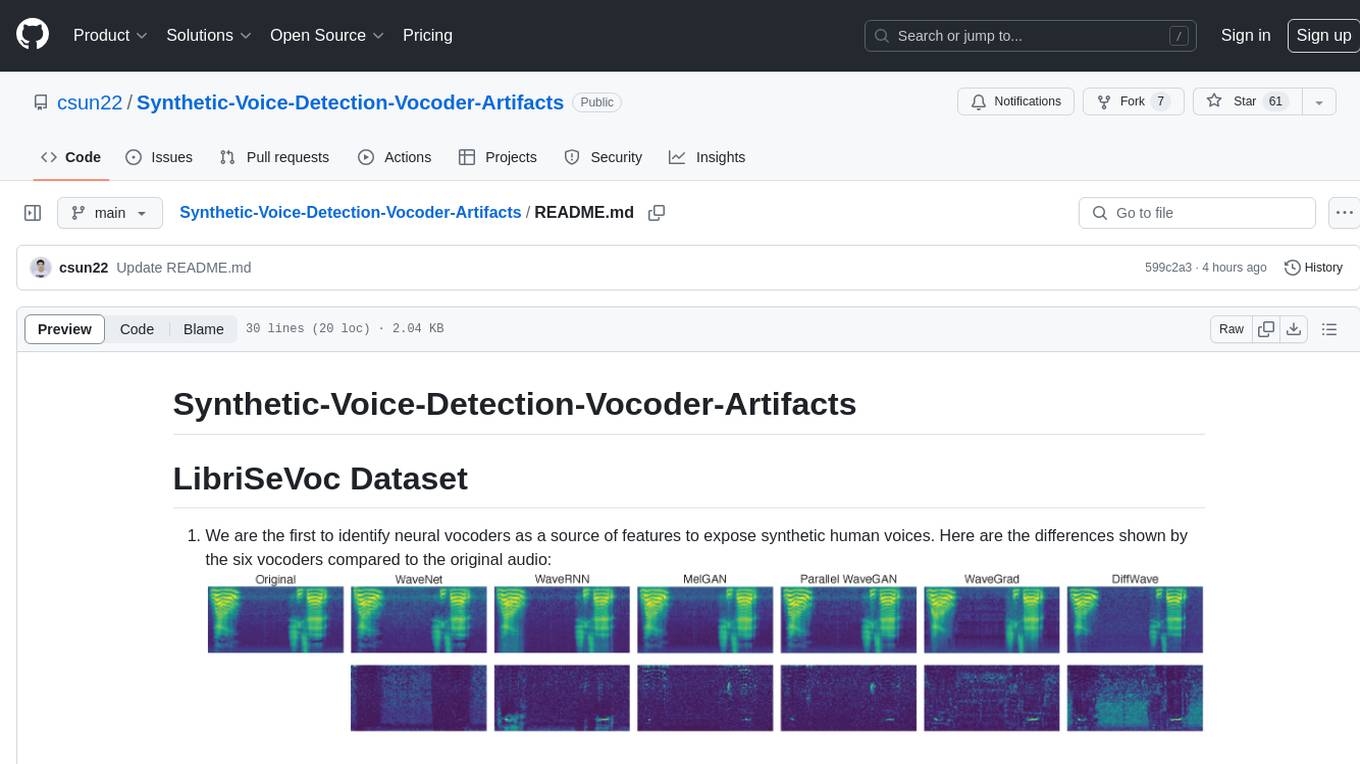
Synthetic-Voice-Detection-Vocoder-Artifacts
The Synthetic-Voice-Detection-Vocoder-Artifacts repository provides the LibriSeVoc dataset containing self-vocoding samples created with six state-of-the-art vocoders to expose and exploit vocoder artifacts. It also introduces a new approach for detecting synthetic human voices by identifying signal artifacts left by neural vocoders and enhancing the RawNet2 baseline. The repository includes a paper and dataset for further reference and offers instructions for training the model and testing it in the wild.
audio-webui
Audio Webui is a tool designed to provide a user-friendly interface for audio processing tasks. It supports automatic installers, Docker deployment, local manual installation, Google Colab integration, and common command line flags. Users can easily download, install, update, and run the tool for various audio-related tasks. The tool requires Python 3.10, Git, and ffmpeg for certain features. It also offers extensions for additional functionalities.

aimp-discord-presence
AIMP - Discord Presence is a plugin for AIMP that changes the status of Discord based on the music you are listening to. It allows users to share their detected activity with others on Discord. The plugin settings are stored in the AIMP configuration file, and users can customize various options such as application ID, timestamp, album art display, and image settings for different playback states.

VoiceStreamAI
VoiceStreamAI is a Python 3-based server and JavaScript client solution for near-realtime audio streaming and transcription using WebSocket. It employs Huggingface's Voice Activity Detection (VAD) and OpenAI's Whisper model for accurate speech recognition. The system features real-time audio streaming, modular design for easy integration of VAD and ASR technologies, customizable audio chunk processing strategies, support for multilingual transcription, and secure sockets support. It uses a factory and strategy pattern implementation for flexible component management and provides a unit testing framework for robust development.
ai-audio-startups
The 'ai-audio-startups' repository is a community list of startups working with AI for audio and music tech. It includes a comprehensive collection of tools and platforms that leverage artificial intelligence to enhance various aspects of music creation, production, source separation, analysis, recommendation, health & wellbeing, radio/podcast, hearing, sound detection, speech transcription, synthesis, enhancement, and manipulation. The repository serves as a valuable resource for individuals interested in exploring innovative AI applications in the audio and music industry.

ai-audio-datasets
AI Audio Datasets List (AI-ADL) is a comprehensive collection of datasets consisting of speech, music, and sound effects, used for Generative AI, AIGC, AI model training, and audio applications. It includes datasets for speech recognition, speech synthesis, music information retrieval, music generation, audio processing, sound synthesis, and more. The repository provides a curated list of diverse datasets suitable for various AI audio tasks.
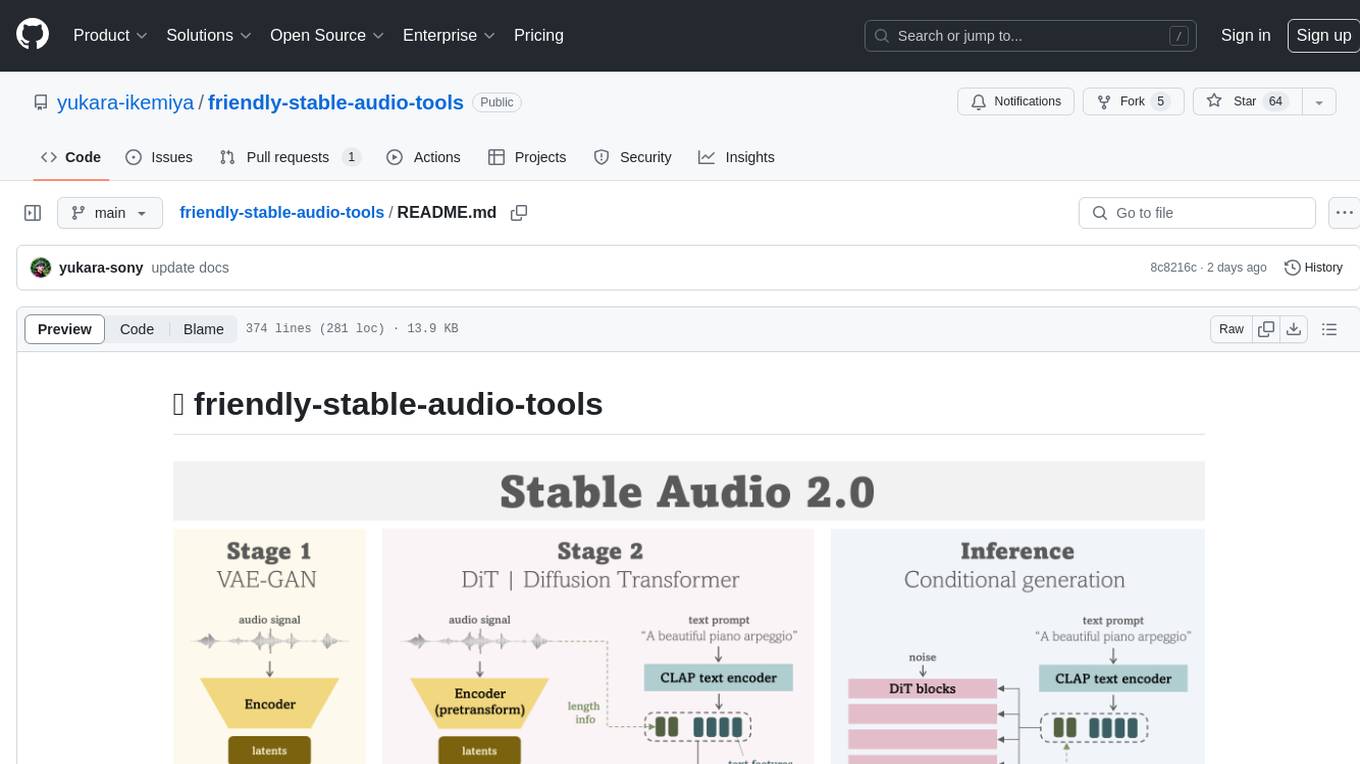
friendly-stable-audio-tools
This repository is a refactored and updated version of `stable-audio-tools`, an open-source code for audio/music generative models originally by Stability AI. It contains refactored codes for improved readability and usability, useful scripts for evaluating and playing with trained models, and instructions on how to train models such as `Stable Audio 2.0`. The repository does not contain any pretrained checkpoints. Requirements include PyTorch 2.0 or later for Flash Attention support and Python 3.8.10 or later for development. The repository provides guidance on installing, building a training environment using Docker or Singularity, logging with Weights & Biases, training configurations, and stages for VAE-GAN and Diffusion Transformer (DiT) training.
nodejs-whisper
Node.js bindings for OpenAI's Whisper model that automatically converts audio to WAV format with a 16000 Hz frequency to support the whisper model. It outputs transcripts to various formats, is optimized for CPU including Apple Silicon ARM, provides timestamp precision to single word, allows splitting on word rather than token, translation from source language to English, and conversion of audio format to WAV for whisper model support.
Godot4ThirdPersonCombatPrototype
Godot4ThirdPersonCombatPrototype is a base project for third person combat, featuring player movement and camera controls with lock-on functionality. It includes setups for models, animations, AI behavior, state machines, audio, and custom resources. The project aims to provide a foundation for developers to create third-person combat mechanics in their games.
whispering-ui
Whispering Tiger UI is a Native-UI tool designed to control the Whispering Tiger application, a free and Open-Source tool that can listen/watch to audio streams or in-game images on your machine and provide transcription or translation to a web browser using Websockets or over OSC. It features a Native-UI for Windows, easy access to all Whispering Tiger features including transcription, translation, text-to-speech, and in-game image recognition. The tool supports loopback audio device, configuration saving/loading, plugin support for additional features, and auto-update functionality. Users can create profiles, configure audio devices, select A.I. devices for speech-to-text, and install/manage plugins for extended functionality.

Easy-Voice-Toolkit
Easy Voice Toolkit is a toolkit based on open source voice projects, providing automated audio tools including speech model training. Users can seamlessly integrate functions like audio processing, voice recognition, voice transcription, dataset creation, model training, and voice conversion to transform raw audio files into ideal speech models. The toolkit supports multiple languages and is currently only compatible with Windows systems. It acknowledges the contributions of various projects and offers local deployment options for both users and developers. Additionally, cloud deployment on Google Colab is available. The toolkit has been tested on Windows OS devices and includes a FAQ section and terms of use for academic exchange purposes.

RVC_CLI
RVC_CLI is a command line interface tool for retrieval-based voice conversion. It provides functionalities for installation, getting started, inference, training, UVR, additional features, and API integration. Users can perform tasks like single inference, batch inference, TTS inference, preprocess dataset, extract features, start training, generate index file, model extract, model information, model blender, launch TensorBoard, download models, audio analyzer, and prerequisites download. The tool is built on various projects like ContentVec, HIFIGAN, audio-slicer, python-audio-separator, RMVPE, FCPE, VITS, So-Vits-SVC, Harmonify, and others.
pianotrans
ByteDance's Piano Transcription is a PyTorch implementation for transcribing piano recordings into MIDI files with pedals. This repository provides a simple GUI and packaging for Windows and Nix on Linux/macOS. It supports using GPU for inference and includes CLI usage. Users can upgrade the tool and report issues to the upstream project. The tool focuses on providing MIDI files, and any other improvements to transcription results should be directed to the original project.
AI-Song-Cover-RVC
AI-Song-Cover-RVC is an all-in-one repository that provides tools for downloading YouTube WAV files, separating vocals, splitting audio, training models, and performing inference using Google Colab or Kaggle. The repository offers tutorials in Indonesian for training and inference tasks. Users can access various tools and resources for processing audio data and generating song covers. The repository aims to simplify the process of working with audio data for music-related projects.

awesome-large-audio-models
This repository is a curated list of awesome large AI models in audio signal processing, focusing on the application of large language models to audio tasks. It includes survey papers, popular large audio models, automatic speech recognition, neural speech synthesis, speech translation, other speech applications, large audio models in music, and audio datasets. The repository aims to provide a comprehensive overview of recent advancements and challenges in applying large language models to audio signal processing, showcasing the efficacy of transformer-based architectures in various audio tasks.
awesome-sound_event_detection
The 'awesome-sound_event_detection' repository is a curated reading list focusing on sound event detection and Sound AI. It includes research papers covering various sub-areas such as learning formulation, network architecture, pooling functions, missing or noisy audio, data augmentation, representation learning, multi-task learning, few-shot learning, zero-shot learning, knowledge transfer, polyphonic sound event detection, loss functions, audio and visual tasks, audio captioning, audio retrieval, audio generation, and more. The repository provides a comprehensive collection of papers, datasets, and resources related to sound event detection and Sound AI, making it a valuable reference for researchers and practitioners in the field.
LLM-Codec
This repository provides an LLM-driven audio codec model, LLM-Codec, for building multi-modal LLMs (text and audio modalities). The model enables frozen LLMs to achieve multiple audio tasks in a few-shot style without parameter updates. It compresses the audio modality into a well-trained LLMs token space, treating audio representation as a 'foreign language' that LLMs can learn with minimal examples. The proposed approach supports tasks like speech emotion classification, audio classification, text-to-speech generation, speech enhancement, etc., demonstrating feasibility and effectiveness in simple scenarios. The LLM-Codec model is open-sourced to facilitate research on few-shot audio task learning and multi-modal LLMs.
whisper
Whisper is an open-source library by Open AI that converts/extracts text from audio. It is a cross-platform tool that supports real-time transcription of various types of audio/video without manual conversion to WAV format. The library is designed to run on Linux and Android platforms, with plans for expansion to other platforms. Whisper utilizes three frameworks to function: DART for CLI execution, Flutter for mobile app integration, and web/WASM for web application deployment. The tool aims to provide a flexible and easy-to-use solution for transcription tasks across different programs and platforms.
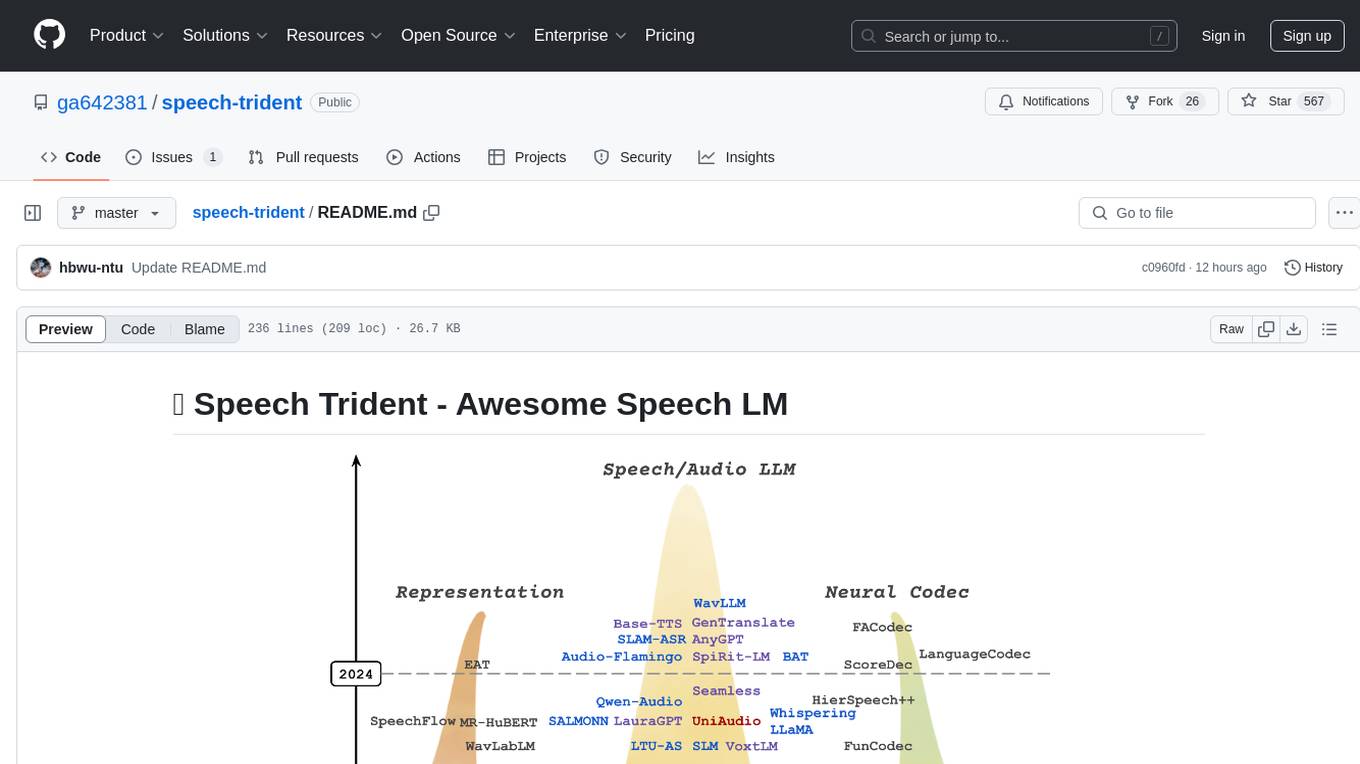
speech-trident
Speech Trident is a repository focusing on speech/audio large language models, covering representation learning, neural codec, and language models. It explores speech representation models, speech neural codec models, and speech large language models. The repository includes contributions from various researchers and provides a comprehensive list of speech/audio language models, representation models, and codec models.

obs-cleanstream
CleanStream is an OBS plugin that utilizes real-time local AI to clean live audio streams by removing unwanted words and utterances, such as 'uh' and 'um', and configurable words like profanity. It employs a neural network (OpenAI Whisper) to predict speech in real-time and eliminate undesired words. The plugin runs efficiently using the Whisper.cpp project from ggerganov. CleanStream offers users the ability to adjust settings and add the plugin to any audio-generating source in OBS, providing a seamless experience for content creators looking to enhance the quality of their live audio streams.

qa-mdt
This repository provides an implementation of QA-MDT, integrating state-of-the-art models for music generation. It offers a Quality-Aware Masked Diffusion Transformer for enhanced music generation. The code is based on various repositories like AudioLDM, PixArt-alpha, MDT, AudioMAE, and Open-Sora. The implementation allows for training and fine-tuning the model with different strategies and datasets. The repository also includes instructions for preparing datasets in LMDB format and provides a script for creating a toy LMDB dataset. The model can be used for music generation tasks, with a focus on quality injection to enhance the musicality of generated music.
voice-pro
Voice-Pro is an integrated solution for subtitles, translation, and TTS. It offers features like multilingual subtitles, live translation, vocal remover, and supports OpenAI Whisper and Open-Source Translator. The tool provides a Studio tab for various functions, Whisper Caption tab for subtitle creation, Translate tab for translation, TTS tab for text-to-speech, Live Translation tab for real-time voice recognition, and Batch tab for processing multiple files. Users can download YouTube videos, improve voice recognition accuracy, create automatic subtitles, and produce multilingual videos with ease. The tool is easy to install with one-click and offers a Web-UI for user convenience.
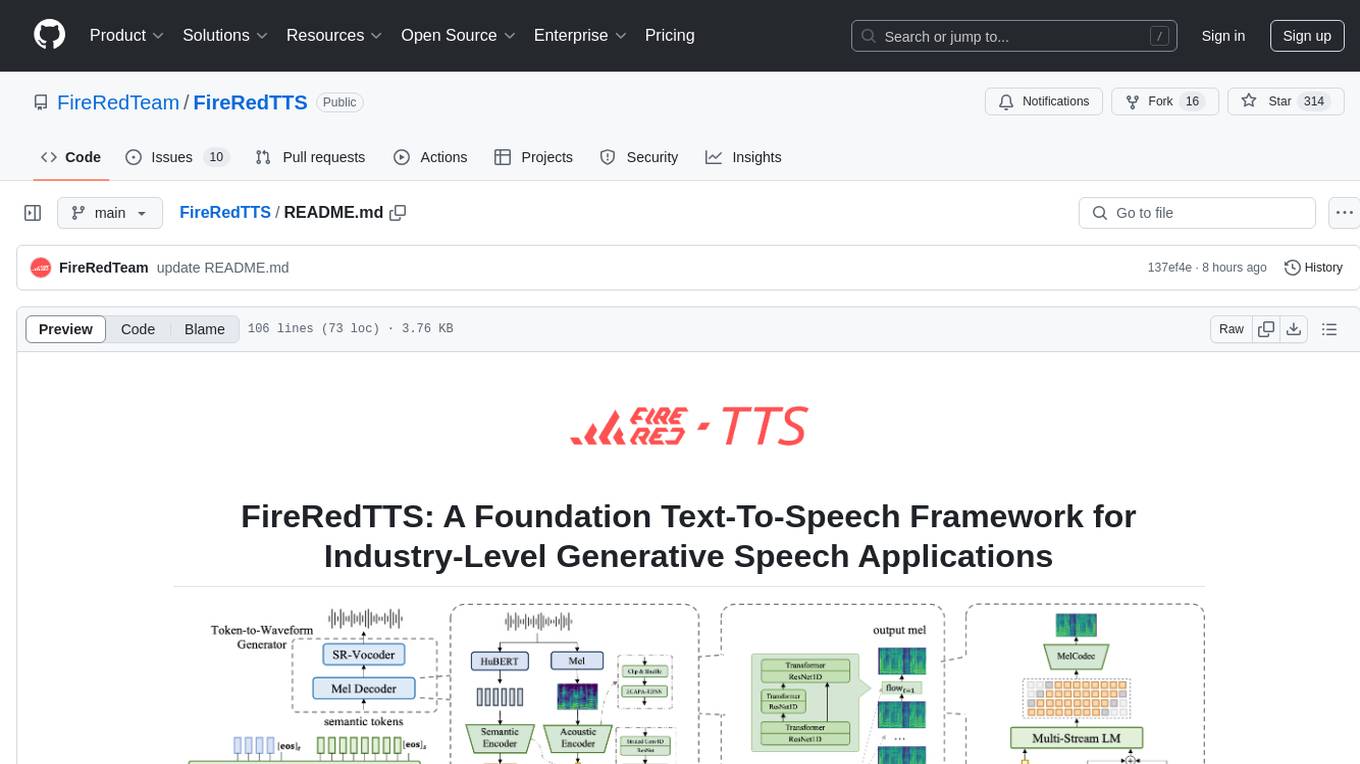
FireRedTTS
FireRedTTS is a foundation text-to-speech framework designed for industry-level generative speech applications. It offers a rich-punctuation model with expanded punctuation coverage and enhanced audio production consistency. The tool provides pre-trained checkpoints, inference code, and an interactive demo space. Users can clone the repository, create a conda environment, download required model files, and utilize the tool for synthesizing speech in various languages. FireRedTTS aims to enhance stability and provide controllable human-like speech generation capabilities.
open-dubbing
Open dubbing is an AI dubbing system that uses machine learning models to automatically translate and synchronize audio dialogue into different languages. It is designed as a command line tool. The project is experimental and aims to explore speech-to-text, text-to-speech, and translation systems combined. It supports multiple text-to-speech engines, translation engines, and gender voice detection. The tool can automatically dub videos, detect source language, and is built on open-source models. The roadmap includes better voice control, optimization for long videos, and support for multiple video input formats. Users can post-edit dubbed files by manually adjusting text, voice, and timings. Supported languages vary based on the combination of systems used.

OpenMusic
OpenMusic is a repository providing an implementation of QA-MDT, a Quality-Aware Masked Diffusion Transformer for music generation. The code integrates state-of-the-art models and offers training strategies for music generation. The repository includes implementations of AudioLDM, PixArt-alpha, MDT, AudioMAE, and Open-Sora. Users can train or fine-tune the model using different strategies and datasets. The model is well-pretrained and can be used for music generation tasks. The repository also includes instructions for preparing datasets, training the model, and performing inference. Contact information is provided for any questions or suggestions regarding the project.
MusicGPT
MusicGPT is an application that allows running the latest music generation AI models locally in a performant way, supporting different music generation models transparently to the user. It can be interacted with through UI mode or CLI mode, generating music based on natural language prompts. The tool requires access to storage to save downloaded models and generated audios along with metadata. It is licensed under MIT License for the code and CC-BY-NC-4.0 License for the AI model weights.
Audio-Upscaler
Audio Upscaler (AudioSR) is a powerful tool designed to enhance the fidelity of audio files, regardless of type or sampling rates. It leverages cutting-edge super-resolution techniques to upscale audio signals, resulting in superior quality output. The tool is versatile, handling all types of audio content, easy to use with a simple interface, and ensures high fidelity output with enhanced clarity and detail.
ai-enhanced-audio-book
The ai-enhanced-audio-book repository contains AI-enhanced audio plugins developed using C++, JUCE, libtorch, RTNeural, and other libraries. It showcases neural networks learning to emulate guitar amplifiers through waveforms. Users can visit the official website for more information and obtain a copy of the book from the publisher Taylor and Francis/ Routledge/ Focal.
echosharp
EchoSharp is an open-source library designed for near-real-time audio processing, orchestrating different AI models seamlessly for various audio analysis scopes. It focuses on flexibility and performance, allowing near-real-time Transcription and Translation by integrating components for Speech-to-Text and Voice Activity Detection. With interchangeable components, easy orchestration, and first-party components like Whisper.net, SileroVad, OpenAI Whisper, AzureAI SpeechServices, WebRtcVadSharp, Onnx.Whisper, and Onnx.Sherpa, EchoSharp provides efficient audio analysis solutions for developers.
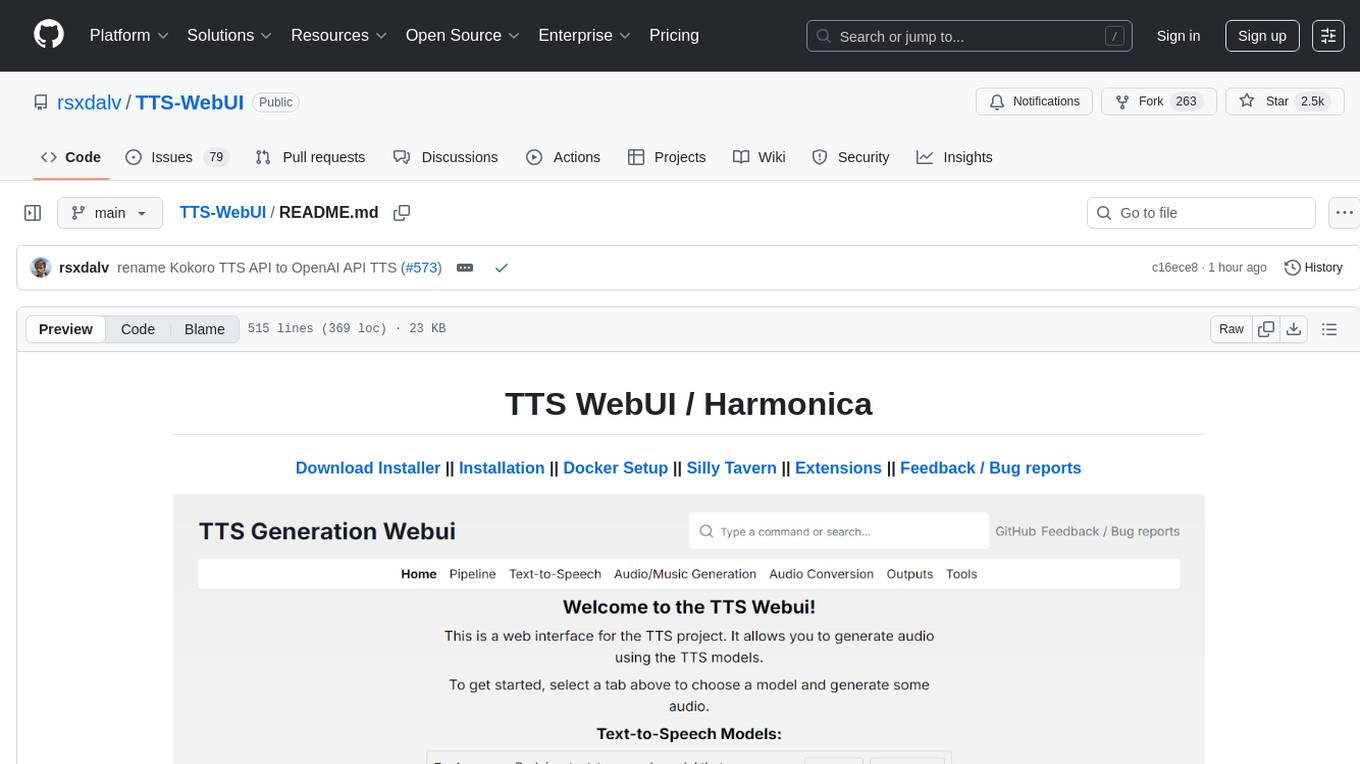
TTS-WebUI
TTS WebUI is a comprehensive tool for text-to-speech synthesis, audio/music generation, and audio conversion. It offers a user-friendly interface for various AI projects related to voice and audio processing. The tool provides a range of models and extensions for different tasks, along with integrations like Silly Tavern and OpenWebUI. With support for Docker setup and compatibility with Linux and Windows, TTS WebUI aims to facilitate creative and responsible use of AI technologies in a user-friendly manner.
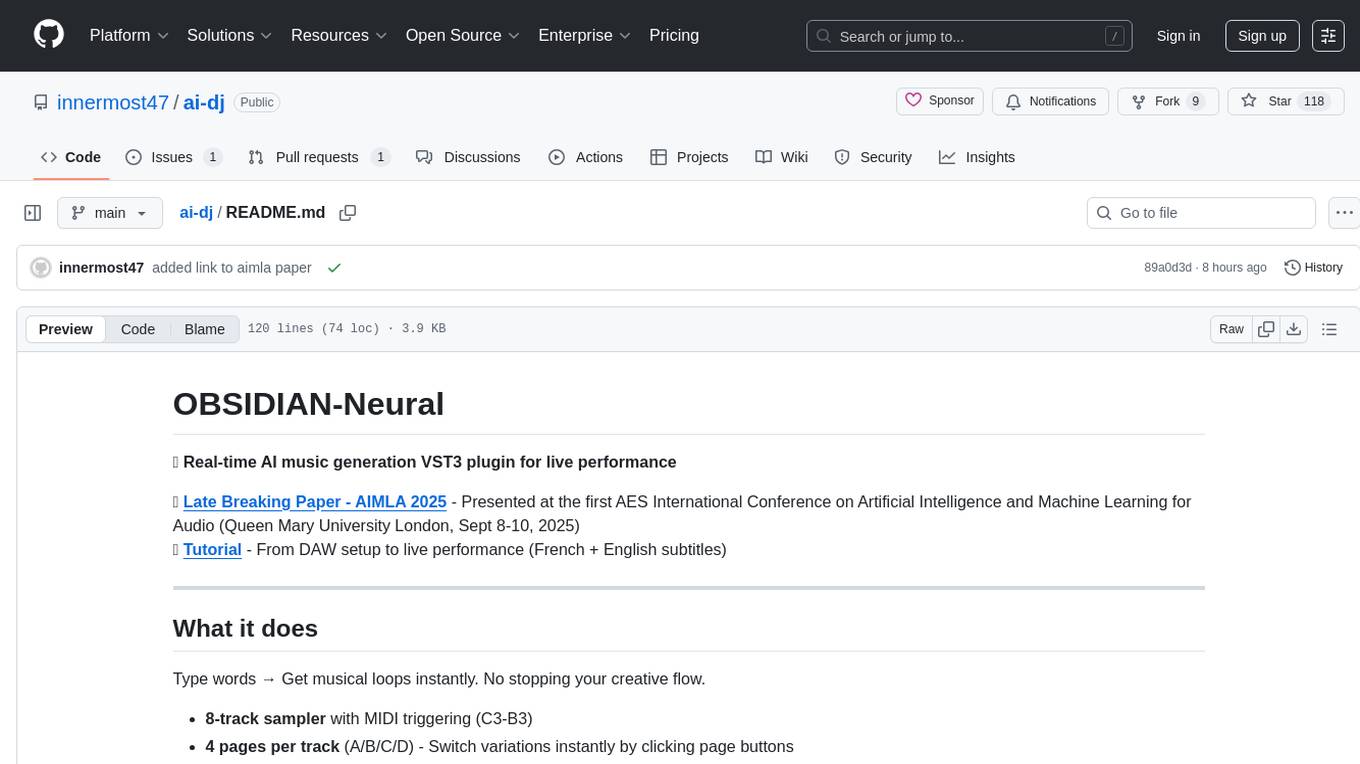
ai-dj
OBSIDIAN-Neural is a real-time AI music generation VST3 plugin designed for live performance. It allows users to type words and instantly receive musical loops, enhancing creative flow. The plugin features an 8-track sampler with MIDI triggering, 4 pages per track for easy variation switching, perfect DAW sync, real-time generation without pre-recorded samples, and stems separation for isolated drums, bass, and vocals. Users can generate music by typing specific keywords and trigger loops with MIDI while jamming. The tool offers different setups for server + GPU, local models for offline use, and a free API option with no setup required. OBSIDIAN-Neural is actively developed and has received over 110 GitHub stars, with ongoing updates and bug fixes. It is dual licensed under GNU Affero General Public License v3.0 and offers a commercial license option for interested parties.
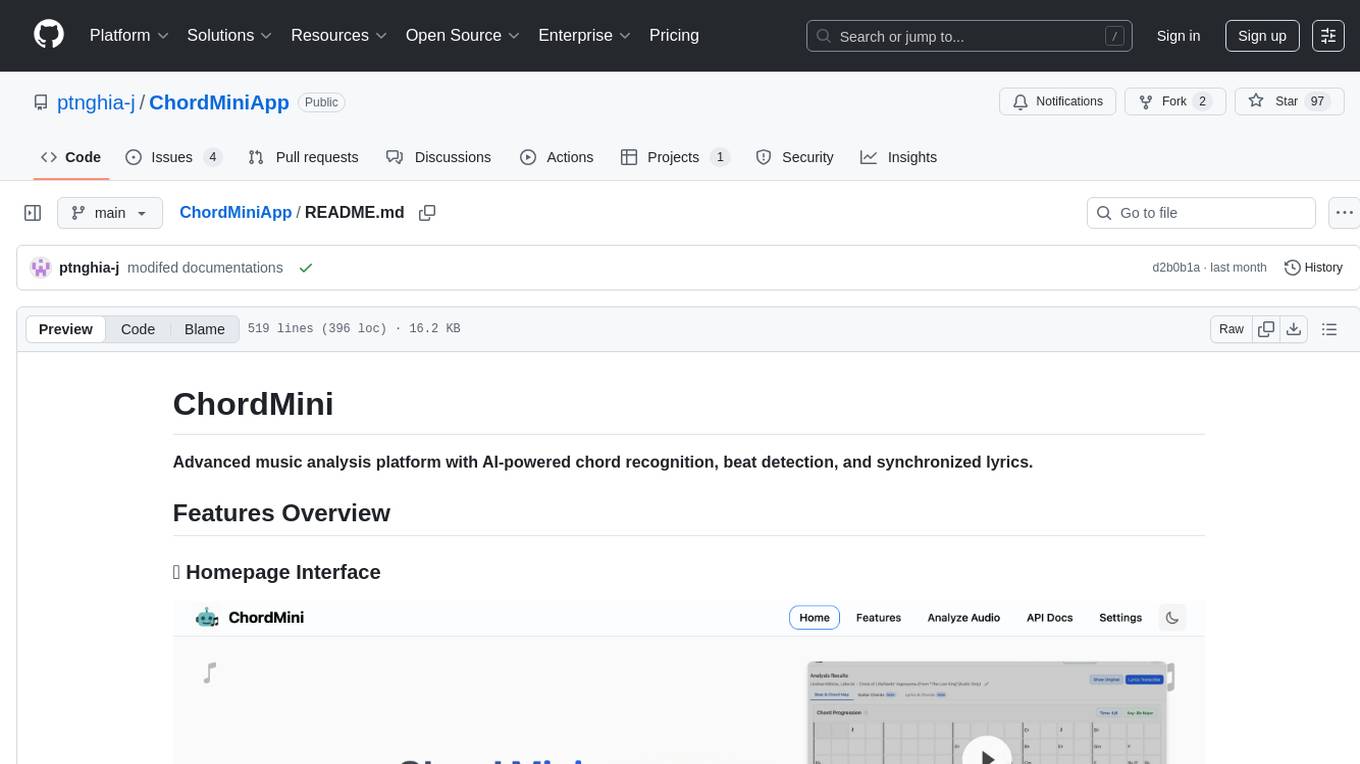
ChordMiniApp
ChordMini is an advanced music analysis platform with AI-powered chord recognition, beat detection, and synchronized lyrics. It features a clean and intuitive interface for YouTube search, chord progression visualization, interactive guitar diagrams with accurate fingering patterns, lead sheet with AI assistant for synchronized lyrics transcription, and various add-on features like Roman Numeral Analysis, Key Modulation Signals, Simplified Chord Notation, and Enhanced Chord Correction. The tool requires Node.js, Python 3.9+, and a Firebase account for setup. It offers a hybrid backend architecture for local development and production deployments, with features like beat detection, chord recognition, lyrics processing, rate limiting, and audio processing supporting MP3, WAV, and FLAC formats. ChordMini provides a comprehensive music analysis workflow from user input to visualization, including dual input support, environment-aware processing, intelligent caching, advanced ML pipeline, and rich visualization options.
Advanced-RVC-Inference
Advanced RVC Inference is a state-of-the-art web UI tool designed to streamline rapid and effortless inference. It includes a model downloader, a voice splitter, and training functionalities. The tool is stable and mature, focusing on security patches, dependency updates, and occasional feature improvements. Users can perform voice conversion, pitch shifting, batch processing, music separation, and more using the web interface or command line interface. The tool is suitable for tasks like voice conversion, audio processing, and model training.
55 - OpenAI Gpts
AI Tools Navigator Genie
Your ultimate guide for navigating AI tools in fields like video, audio, writing, from beginner to expert.
EDM Maestro
I'm an EDM Producer here to help you master electronic music production and mixing!

Music Production Teacher
It acts as an instructor guiding you through music production skills, such as fine-tuning parameters in mixing, mastering, and compression. Additionally, it functions as an aide, offering advice for your music production hurdles with just a screenshot of your production or parameter settings.


L6 Helix Sound Designer
I help you with Line 6 Helix sound design, focusing on custom patches and guitar tone guidance - V 0.3

MIXING & MASTERING GPT
Your personal audio mixing and mastering engineer assistant for music production
Mike Russell
Virtual Mike Russell from Music Radio Creative. Ask me your audio, podcasting and AI questions!

Logic Pro - Talk to the Manual
I'm Logic Pro X's manual. Let me answer your questions, troubleshoot whatever issue you're having and get you back into the groove!


Sound Sage
Top-level audio expert in audio engineering for music, and film, with advanced knowledge of recording history, acoustics, gear, and plugins, with a sarcastic touch.
Guitar Melody Harmonizer
Harmonizes ABC-notation melodies for guitar and assists with mp3 to MIDI conversion, MIDI to ABC-notation, and more.
Synth Guide
Expert in guiding musicians on creating sounds with synthesizers like Serum, Massive, and more.

All Purpose Audio Format Converter
Expert in audio format conversion, guiding through simple steps.
AI Song Idea Generator 🎵✍️
Generate complete song concept, with story, theme, mood, lyrics, key, chords, and instrument suggestions.

Signal Processing Advisor
Provides expert guidance on signal processing in engineering projects.
O cara do som
Expert in residential speaker systems, offering detailed advice and product recommendations.
Ableton Live Mentor
Your personal Ableton Live mentor. Ask me anything about using Live for music production or live performance.
AI Music Production Assistant
Your go-to assistant for all music production needs. I am AI Music Production Assistant, designed to assist with a wide range of music production needs. My expertise encompasses songwriting, composition, music theory, and audio engineering.
Able-Nature's Echo.
Guides users through beautiful landscapes with spatial audio for immersion.
MUSIC + AI = MUSI.CAI
MUSIC + AI: Your key to original AI music creation. Create hits, explore genres, and tap into global trends. The ultimate tool for artists and producers.

ReaperGPT
Expert for the Reaper DAW with extensive knowledge on Reapack Packages, ReaScript, EEL, Lua, Python, general commands, and audio workflows.
Ableton Genius
Expert in Ableton Live for music production, focusing on drum and bass genres.