
pianotrans
Simple GUI for ByteDance's Piano Transcription with Pedals
Stars: 1235
ByteDance's Piano Transcription is a PyTorch implementation for transcribing piano recordings into MIDI files with pedals. This repository provides a simple GUI and packaging for Windows and Nix on Linux/macOS. It supports using GPU for inference and includes CLI usage. Users can upgrade the tool and report issues to the upstream project. The tool focuses on providing MIDI files, and any other improvements to transcription results should be directed to the original project.
README:
![]()
ByteDance's Piano Transcription is the PyTorch implementation of the
piano transcription system, "High-resolution Piano Transcription with Pedals
by Regressing Onsets and Offsets Times [1]".
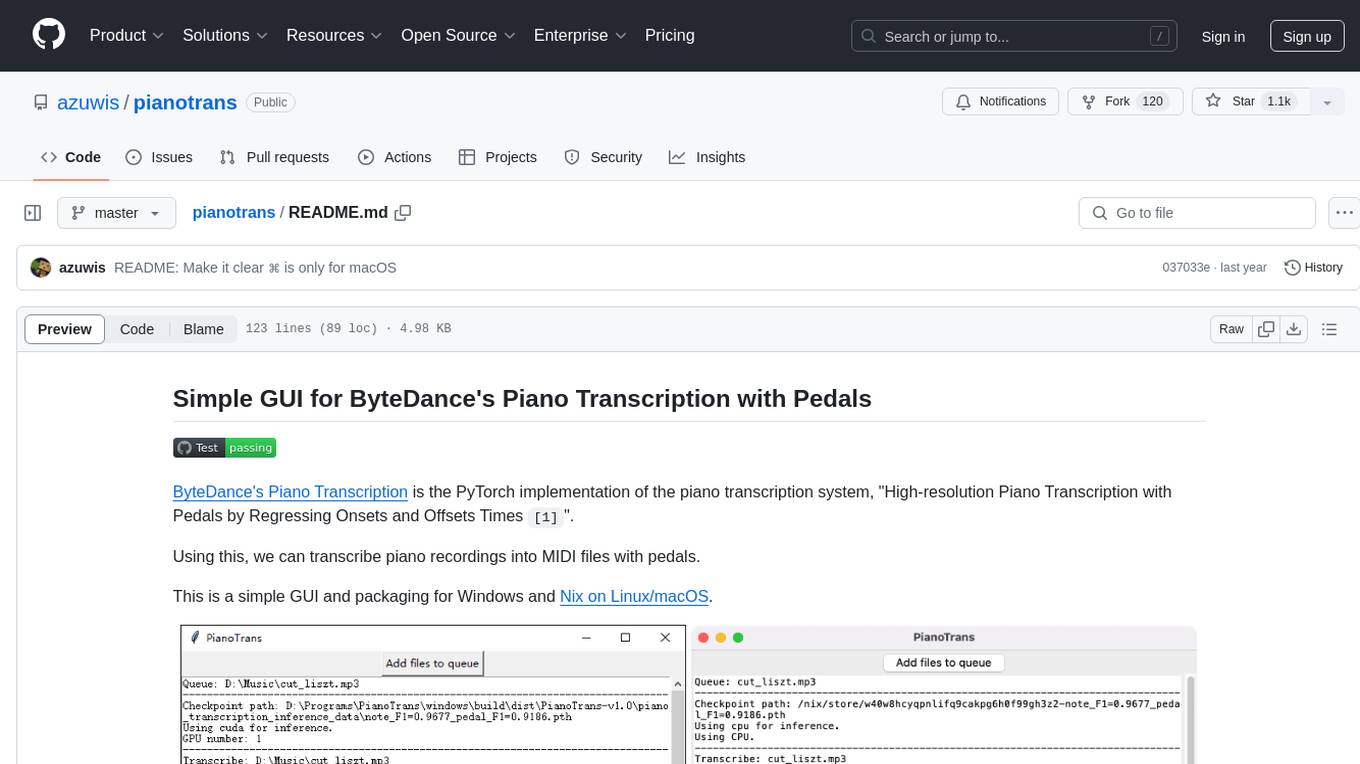
Using this, we can transcribe piano recordings into MIDI files with pedals.
This is a simple GUI and packaging for Windows and Nix on Linux/macOS.



- OS: Windows 7 or later (64-bit), Linux, macOS (Intel/M1)
- Memory: at least 4G
Only Windows 10, Debian Linux 10, and macOS 12.1 M1 are tested.
- Download Microsoft Visual C++ Redistributable for Visual Studio 2015, 2017 and 2019
vc_redist_x64.exeand install - Download and unpack PianoTrans-v1.0.7z (1.5GB download, unpack using 7zip)
- Close other apps to free memory, need at least 2G free memory
- Run
PianoTrans.exeinPianoTransdirectory - Choose audio/video files, hold
CTRLto select multiple files - Result MIDI files are in the same directory as the input files
If you want right click menu, run RightClickMenuRegister.bat, then you can
select multiple audio/video files, right click and choose Piano Transcribe.
PianoTrans automatically uses GPU for inference, if you encounter any problem,
you can try PianoTrans-CPU.bat to force using CPU.
Note: This howto is for Nix on Linux/macOS, if you don't use Nix, you can also follow the upstream install and usage guide for Python pip instead.
- Open the terminal
- Install and setup Nix:
See https://nixos.org/download.html for more details
sh <(curl -L https://nixos.org/nix/install) --daemon mkdir -p ~/.config/nix echo 'experimental-features = nix-command flakes' > ~/.config/nix/nix.conf
- Use Nix to install pianotrans:
nix profile install github:azuwis/pianotrans
- Run
pianotransto open the GUI, choose audio/video files, holdCTRL(⌘for macOS) to select multiple files
For CLI usage, run pianotrans file1 file2 ....
To upgrade pianotrans, run:
$ nix profile list
0 github:azuwis/pianotrans#defaultPackage.aarch64-linux github:azuwis/pianotrans/e19d5fd12f4295816fad49f6398e2e53ed2d2b7a#defaultPackage.aarch64-linux /nix/store/zdalndvcralish8d43drzslv0p4pm97v-python3.9-pianotrans-0.2.1
# list nix profiles, `0` is pianotrans
$ nix --option tarball-ttl 1 profile upgrade 0
$ nix profile list
0 github:azuwis/pianotrans#defaultPackage.aarch64-linux github:azuwis/pianotrans/e944720dd0dfcc2b87dcc39c1fdaab086eba4ca6#defaultPackage.aarch64-linux /nix/store/rv5iikrdvc7jrc7mqs8mkc21qh2gklhx-python3.9-pianotrans-1.0
# pianotrans upgraded to v1.0Q: Can you improve transcription result?
A: This project is about packaging for https://github.com/bytedance/piano_transcription, as long as it gives you MIDI files, all other issues are out of scope of this project.
You should report to the upstream project here https://github.com/bytedance/piano_transcription/issues
- Add
--clioption to force disable GUI - Remove filetypes arg from askopenfilenames to avoid crash
- Update Nix flake, and remove mido/soundfile/torchlibrosa/piano-transcription-inference overlay, all patches accepted in nixpkgs, this means more dependances can be fetched directly from Nix binary cache, less local builds
- Add github test workflow
- Support Linux/macOS using Nix
- All platforms:
- Add real GUI alongside CLI
- GUI allow adding files to transcribe queue
- Windows:
- Right-click menu supports multiple files (need to re-run
RightClickMenuRegister.bat) - Update pytorch to 1.10.2
- Right-click menu supports multiple files (need to re-run
- Update pytorch to 1.10.1.
- Update piano-transcription-inference to 0.0.5
- Update pytorch to 1.9.1.
- Add PianoTrans-CPU.bat to force using CPU for inference.
- Initial release.
[1] Qiuqiang Kong, Bochen Li, Xuchen Song, Yuan Wan, and Yuxuan Wang. "High-resolution Piano Transcription with Pedals by Regressing Onsets and Offsets Times." arXiv preprint arXiv:2010.01815 (2020). [pdf]
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for pianotrans
Similar Open Source Tools
pianotrans
ByteDance's Piano Transcription is a PyTorch implementation for transcribing piano recordings into MIDI files with pedals. This repository provides a simple GUI and packaging for Windows and Nix on Linux/macOS. It supports using GPU for inference and includes CLI usage. Users can upgrade the tool and report issues to the upstream project. The tool focuses on providing MIDI files, and any other improvements to transcription results should be directed to the original project.
obs-localvocal
LocalVocal is a Speech AI assistant OBS Plugin that enables users to transcribe speech into text and translate it into any language locally on their machine. The plugin runs OpenAI's Whisper for real-time speech processing and prediction. It supports features like transcribing audio in real-time, displaying captions on screen, sending captions to files, syncing captions with recordings, and translating captions to major languages. Users can bring their own Whisper model, filter or replace captions, and experience partial transcriptions for streaming. The plugin is privacy-focused, requiring no GPU, cloud costs, network, or downtime.
Airshipper
Airshipper is a cross-platform Veloren launcher that allows users to update/download and start nightly builds of the game. It features a fancy UI with self-updating capabilities on Windows. Users can compile it from source and also have the option to install Airshipper-Server for advanced configurations. Note that Airshipper is still in development and may not be stable for all users.

fiftyone
FiftyOne is an open-source tool designed for building high-quality datasets and computer vision models. It supercharges machine learning workflows by enabling users to visualize datasets, interpret models faster, and improve efficiency. With FiftyOne, users can explore scenarios, identify failure modes, visualize complex labels, evaluate models, find annotation mistakes, and much more. The tool aims to streamline the process of improving machine learning models by providing a comprehensive set of features for data analysis and model interpretation.
RWKV-Runner
RWKV Runner is a project designed to simplify the usage of large language models by automating various processes. It provides a lightweight executable program and is compatible with the OpenAI API. Users can deploy the backend on a server and use the program as a client. The project offers features like model management, VRAM configurations, user-friendly chat interface, WebUI option, parameter configuration, model conversion tool, download management, LoRA Finetune, and multilingual localization. It can be used for various tasks such as chat, completion, composition, and model inspection.
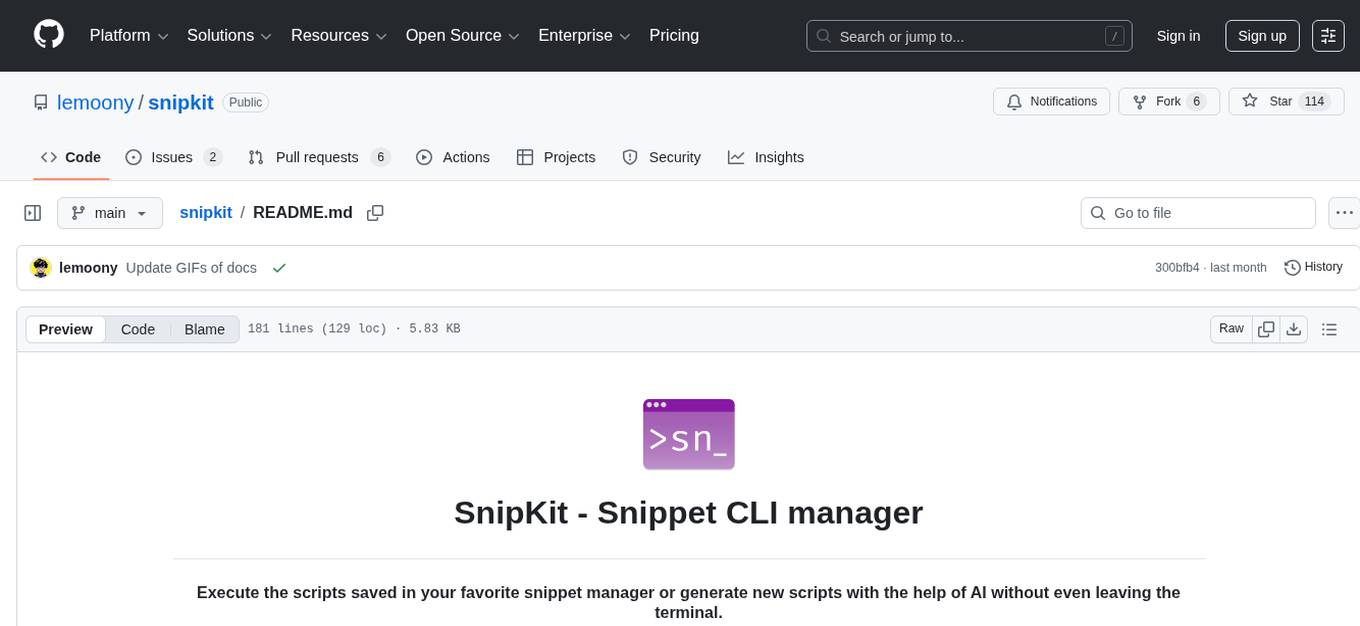
snipkit
SnipKit is a CLI tool designed to manage snippets efficiently, allowing users to execute saved scripts or generate new ones with the help of AI directly from the terminal. It supports loading snippets from various sources, parameter substitution, different parameter types, themes, and customization options. The tool includes an interactive chat-style interface called SnipKit Assistant for generating parameterized scripts. Users can also work with different AI providers like OpenAI, Anthropic, Google Gemini, and more. SnipKit aims to streamline script execution and script generation workflows for developers and users who frequently work with code snippets.
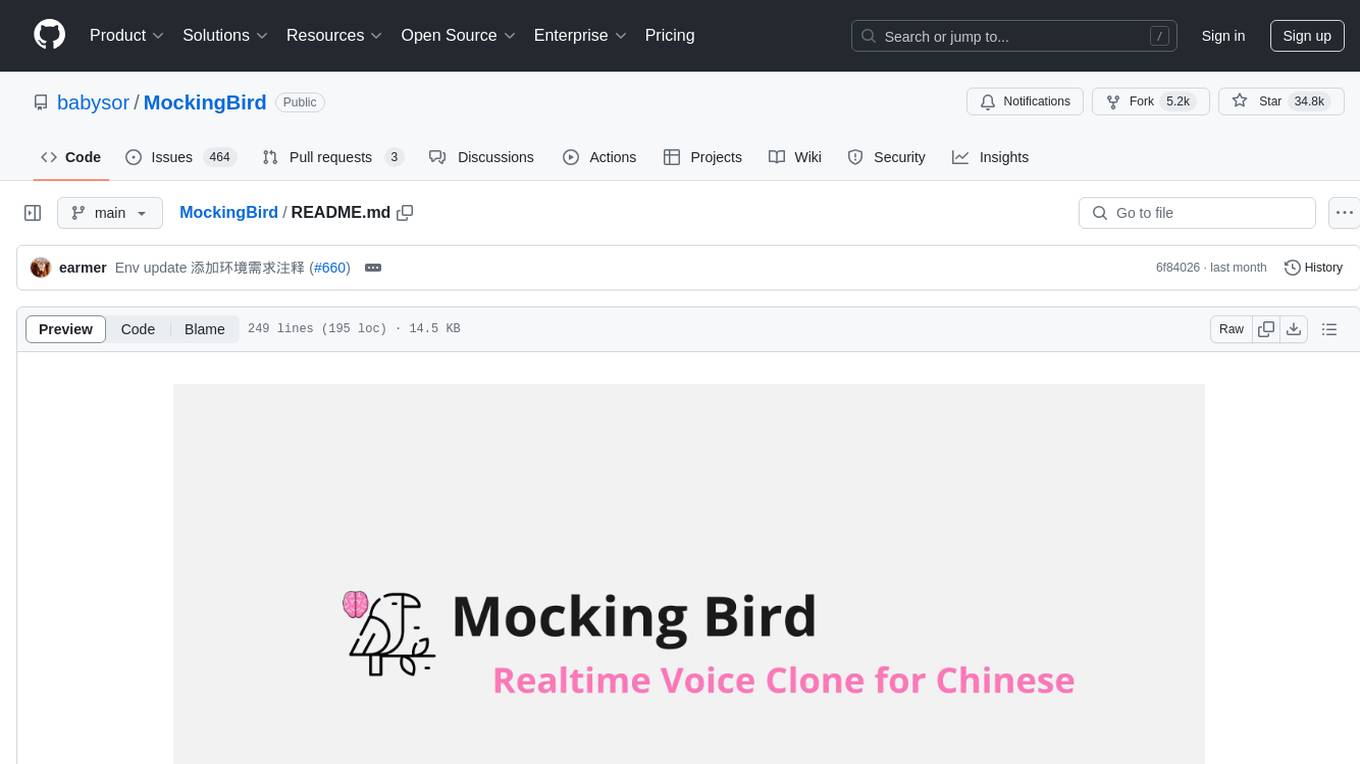
MockingBird
MockingBird is a toolbox designed for Mandarin speech synthesis using PyTorch. It supports multiple datasets such as aidatatang_200zh, magicdata, aishell3, and data_aishell. The toolbox can run on Windows, Linux, and M1 MacOS, providing easy and effective speech synthesis with pretrained encoder/vocoder models. It is webserver ready for remote calling. Users can train their own models or use existing ones for the encoder, synthesizer, and vocoder. The toolbox offers a demo video and detailed setup instructions for installation and model training.
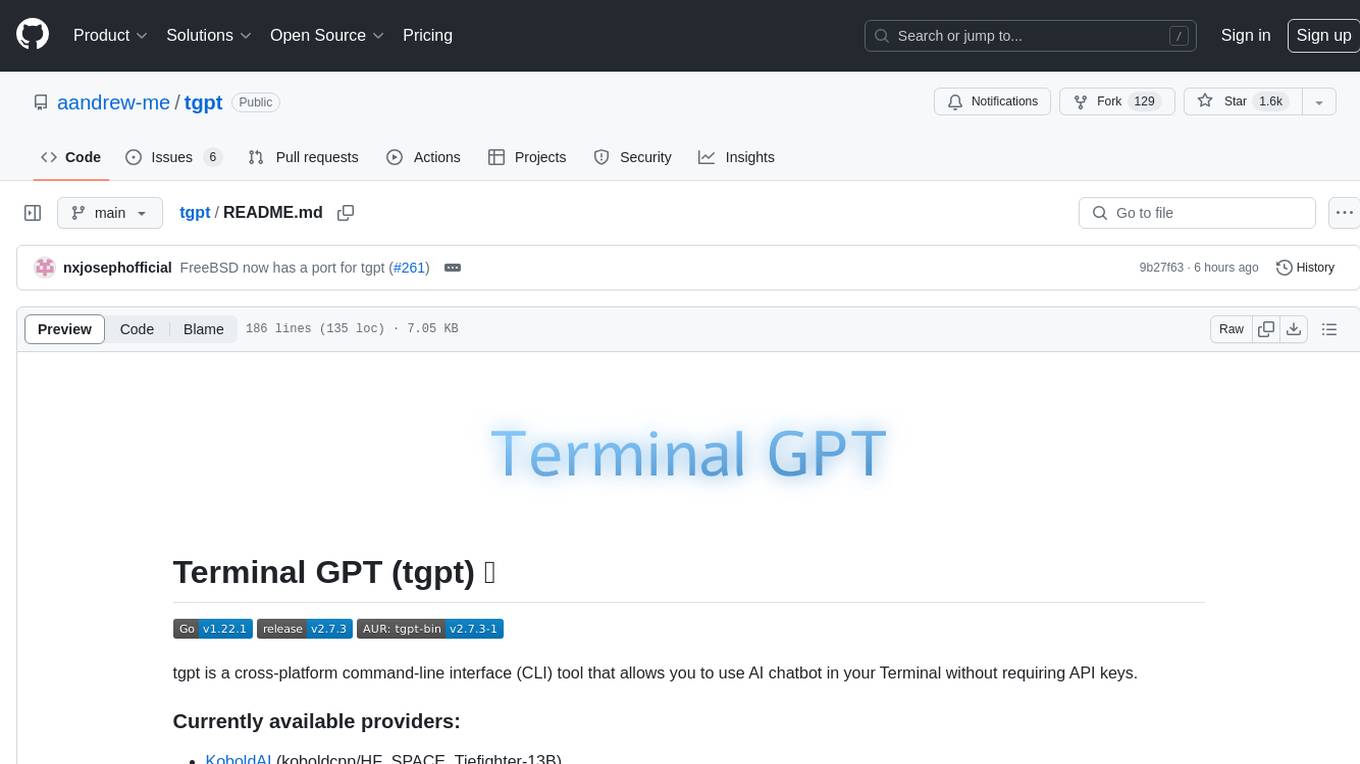
tgpt
tgpt is a cross-platform command-line interface (CLI) tool that allows users to interact with AI chatbots in the Terminal without needing API keys. It supports various AI providers such as KoboldAI, Phind, Llama2, Blackbox AI, and OpenAI. Users can generate text, code, and images using different flags and options. The tool can be installed on GNU/Linux, MacOS, FreeBSD, and Windows systems. It also supports proxy configurations and provides options for updating and uninstalling the tool.
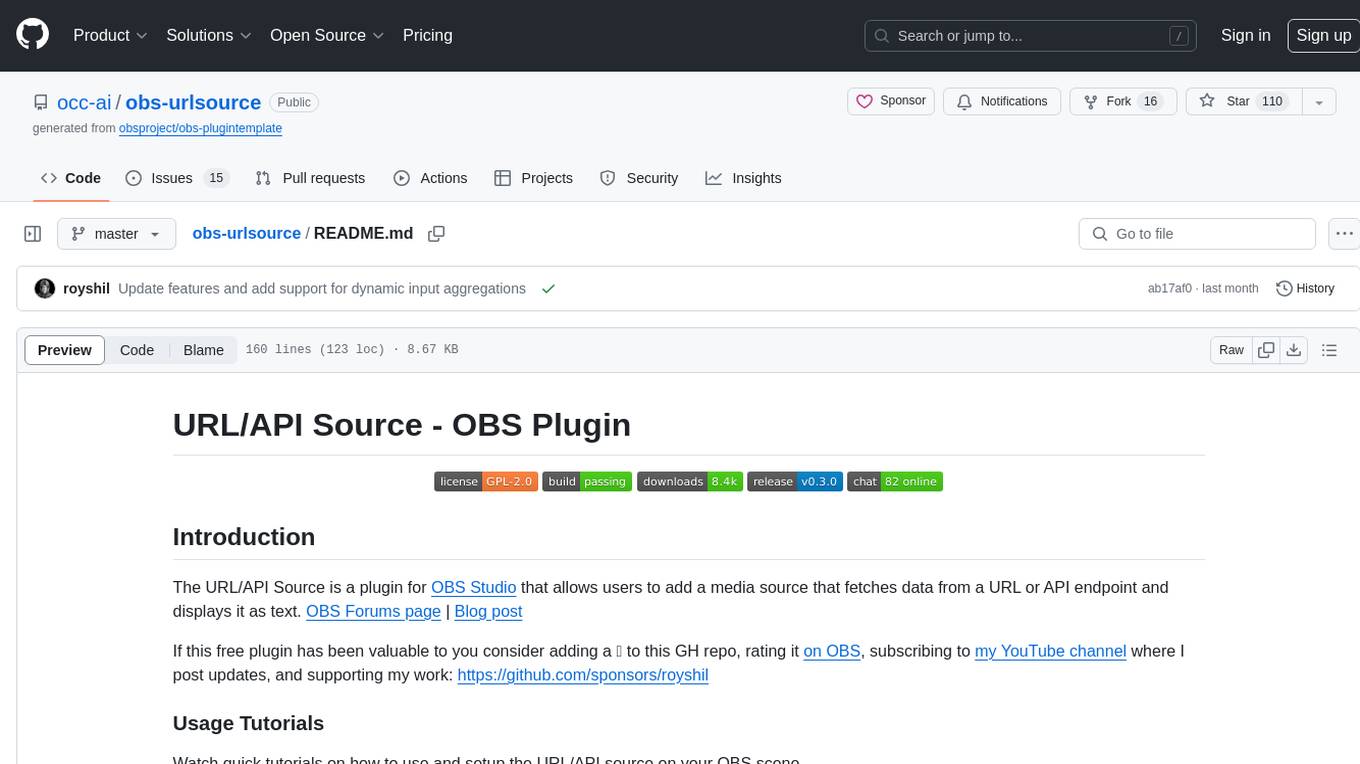
obs-urlsource
The URL/API Source is a plugin for OBS Studio that allows users to add a media source fetching data from a URL or API endpoint and displaying it as text. It supports input and output templating, various request types, output parsing (JSON, XML/HTML, Regex, CSS selectors), live data updating, output styling, and formatting. Future features include authentication, websocket support, more parsing options, request types, and output formats. The plugin is cross-platform compatible and actively maintained by the developer. Users can support the project on GitHub.

ragflow
RAGFlow is an open-source Retrieval-Augmented Generation (RAG) engine that combines deep document understanding with Large Language Models (LLMs) to provide accurate question-answering capabilities. It offers a streamlined RAG workflow for businesses of all sizes, enabling them to extract knowledge from unstructured data in various formats, including Word documents, slides, Excel files, images, and more. RAGFlow's key features include deep document understanding, template-based chunking, grounded citations with reduced hallucinations, compatibility with heterogeneous data sources, and an automated and effortless RAG workflow. It supports multiple recall paired with fused re-ranking, configurable LLMs and embedding models, and intuitive APIs for seamless integration with business applications.
qwen-code
Qwen Code is an open-source AI agent optimized for Qwen3-Coder, designed to help users understand large codebases, automate tedious work, and expedite the shipping process. It offers an agentic workflow with rich built-in tools, a terminal-first approach with optional IDE integration, and supports both OpenAI-compatible API and Qwen OAuth authentication methods. Users can interact with Qwen Code in interactive mode, headless mode, IDE integration, and through a TypeScript SDK. The tool can be configured via settings.json, environment variables, and CLI flags, and offers benchmark results for performance evaluation. Qwen Code is part of an ecosystem that includes AionUi and Gemini CLI Desktop for graphical interfaces, and troubleshooting guides are available for issue resolution.
kantv
KanTV is an open-source project that focuses on studying and practicing state-of-the-art AI technology in real applications and scenarios, such as online TV playback, transcription, translation, and video/audio recording. It is derived from the original ijkplayer project and includes many enhancements and new features, including: * Watching online TV and local media using a customized FFmpeg 6.1. * Recording online TV to automatically generate videos. * Studying ASR (Automatic Speech Recognition) using whisper.cpp. * Studying LLM (Large Language Model) using llama.cpp. * Studying SD (Text to Image by Stable Diffusion) using stablediffusion.cpp. * Generating real-time English subtitles for English online TV using whisper.cpp. * Running/experiencing LLM on Xiaomi 14 using llama.cpp. * Setting up a customized playlist and using the software to watch the content for R&D activity. * Refactoring the UI to be closer to a real commercial Android application (currently only supports English). Some goals of this project are: * To provide a well-maintained "workbench" for ASR researchers interested in practicing state-of-the-art AI technology in real scenarios on mobile devices (currently focusing on Android). * To provide a well-maintained "workbench" for LLM researchers interested in practicing state-of-the-art AI technology in real scenarios on mobile devices (currently focusing on Android). * To create an Android "turn-key project" for AI experts/researchers (who may not be familiar with regular Android software development) to focus on device-side AI R&D activity, where part of the AI R&D activity (algorithm improvement, model training, model generation, algorithm validation, model validation, performance benchmark, etc.) can be done very easily using Android Studio IDE and a powerful Android phone.
podscript
Podscript is a tool designed to generate transcripts for podcasts and similar audio files using Language Model Models (LLMs) and Speech-to-Text (STT) APIs. It provides a command-line interface (CLI) for transcribing audio from various sources, including YouTube videos and audio files, using different speech-to-text services like Deepgram, Assembly AI, and Groq. Additionally, Podscript offers a web-based user interface for convenience. Users can configure keys for supported services, transcribe audio, and customize the transcription models. The tool aims to simplify the process of creating accurate transcripts for audio content.
chunkr
Chunkr is an open-source document intelligence API that provides a production-ready service for document layout analysis, OCR, and semantic chunking. It allows users to convert PDFs, PPTs, Word docs, and images into RAG/LLM-ready chunks. The API offers features such as layout analysis, OCR with bounding boxes, structured HTML and markdown output, and VLM processing controls. Users can interact with Chunkr through a Python SDK, enabling them to upload documents, process them, and export results in various formats. The tool also supports self-hosted deployment options using Docker Compose or Kubernetes, with configurations for different AI models like OpenAI, Google AI Studio, and OpenRouter. Chunkr is dual-licensed under the GNU Affero General Public License v3.0 (AGPL-3.0) and a commercial license, providing flexibility for different usage scenarios.

mLoRA
mLoRA (Multi-LoRA Fine-Tune) is an open-source framework for efficient fine-tuning of multiple Large Language Models (LLMs) using LoRA and its variants. It allows concurrent fine-tuning of multiple LoRA adapters with a shared base model, efficient pipeline parallelism algorithm, support for various LoRA variant algorithms, and reinforcement learning preference alignment algorithms. mLoRA helps save computational and memory resources when training multiple adapters simultaneously, achieving high performance on consumer hardware.
Windows-Use
Windows-Use is a powerful automation agent that interacts directly with the Windows OS at the GUI layer. It bridges the gap between AI agents and Windows to perform tasks such as opening apps, clicking buttons, typing, executing shell commands, and capturing UI state without relying on traditional computer vision models. It enables any large language model (LLM) to perform computer automation instead of relying on specific models for it.
For similar tasks
pianotrans
ByteDance's Piano Transcription is a PyTorch implementation for transcribing piano recordings into MIDI files with pedals. This repository provides a simple GUI and packaging for Windows and Nix on Linux/macOS. It supports using GPU for inference and includes CLI usage. Users can upgrade the tool and report issues to the upstream project. The tool focuses on providing MIDI files, and any other improvements to transcription results should be directed to the original project.
shadcn-nextjs-boilerplate
Horizon AI Boilerplate is an open-source Admin Dashboard template designed for Shadcn UI, NextJS, and Tailwind CSS. It provides over 30 dark/light frontend elements for creating Chat AI SaaS Apps quickly. The documentation is detailed and complex, guiding users through installation and usage. Users can start their local server with simple commands. The tool requires a valid OpenAI API key for ChatGPT functionality. Additionally, a Figma version is available for design purposes. The PRO version offers more components and pages. Users can report issues on GitHub and connect with the community via Discord. The tool credits open-source resources like Shadcn UI Library, NextJS Subscription Payments, and ChatBot UI by mckaywrigley.
catalog
AIA Podcast's AI Tools Catalog is a collection of AI-powered tools mentioned in the podcast. These tools can be beneficial for programming, content creation, and enhancing productivity. To contribute, users can add services by providing a brief description in the Telegram chat or suggest improvements by forking the repository and submitting a PR. Users can also report closed or inoperative tools through the creation of an Issue. The catalog is a valuable resource for discovering innovative AI tools and services.

mojo
Mojo is a new programming language that combines Python syntax and ecosystem with systems programming and metaprogramming features. It aims to bridge the gap between research and production, designed to be the best way to extend Python over time. The repository includes source code for Mojo examples, documentation hosted at modular.com, and the Mojo standard library. It has two primary branches: 'main' for stable released versions and 'nightly' for the latest builds. To install Mojo, follow the guide for the last released build or use the nightly builds for a view of the development progress. Contributions are welcome on the 'nightly' branch, and the repository is licensed under the Apache License v2.0 with LLVM Exceptions.
mslearn-ai-studio
The mslearn-ai-studio repository provides hands-on exercises for building generative AI solutions on Microsoft Azure. Users can explore common tasks related to generative AI models and Azure resources. The exercises are designed to complement Microsoft Learn modules and require an Azure subscription for completion.
grammar-llm
GrammarLLM is an AI-powered grammar correction tool that utilizes fine-tuned language models to fix grammatical errors in text. It offers real-time grammar and spelling correction with individual suggestion acceptance. The tool features a clean and responsive web interface, a FastAPI backend integrated with llama.cpp, and support for multiple grammar models. Users can easily deploy the tool using Docker Compose and interact with it through a web interface or REST API. The default model, GRMR-V3-G4B-Q8_0, provides grammar correction, spelling correction, punctuation fixes, and style improvements without requiring a GPU. The tool also includes endpoints for applying single or multiple suggestions to text, a health check endpoint, and detailed documentation for functionality and model details. Testing and verification steps are provided for manual and Docker testing, along with community guidelines for contributing, reporting issues, and getting support.
For similar jobs

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text

suno-api
Suno AI API is an open-source project that allows developers to integrate the music generation capabilities of Suno.ai into their own applications. The API provides a simple and convenient way to generate music, lyrics, and other audio content using Suno.ai's powerful AI models. With Suno AI API, developers can easily add music generation functionality to their apps, websites, and other projects.

bark.cpp
Bark.cpp is a C/C++ implementation of the Bark model, a real-time, multilingual text-to-speech generation model. It supports AVX, AVX2, and AVX512 for x86 architectures, and is compatible with both CPU and GPU backends. Bark.cpp also supports mixed F16/F32 precision and 4-bit, 5-bit, and 8-bit integer quantization. It can be used to generate realistic-sounding audio from text prompts.

NSMusicS
NSMusicS is a local music software that is expected to support multiple platforms with AI capabilities and multimodal features. The goal of NSMusicS is to integrate various functions (such as artificial intelligence, streaming, music library management, cross platform, etc.), which can be understood as similar to Navidrome but with more features than Navidrome. It wants to become a plugin integrated application that can almost have all music functions.

ai-voice-cloning
This repository provides a tool for AI voice cloning, allowing users to generate synthetic speech that closely resembles a target speaker's voice. The tool is designed to be user-friendly and accessible, with a graphical user interface that guides users through the process of training a voice model and generating synthetic speech. The tool also includes a variety of features that allow users to customize the generated speech, such as the pitch, volume, and speaking rate. Overall, this tool is a valuable resource for anyone interested in creating realistic and engaging synthetic speech.

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio

openvino-plugins-ai-audacity
OpenVINO™ AI Plugins for Audacity* are a set of AI-enabled effects, generators, and analyzers for Audacity®. These AI features run 100% locally on your PC -- no internet connection necessary! OpenVINO™ is used to run AI models on supported accelerators found on the user's system such as CPU, GPU, and NPU. * **Music Separation**: Separate a mono or stereo track into individual stems -- Drums, Bass, Vocals, & Other Instruments. * **Noise Suppression**: Removes background noise from an audio sample. * **Music Generation & Continuation**: Uses MusicGen LLM to generate snippets of music, or to generate a continuation of an existing snippet of music. * **Whisper Transcription**: Uses whisper.cpp to generate a label track containing the transcription or translation for a given selection of spoken audio or vocals.

WavCraft
WavCraft is an LLM-driven agent for audio content creation and editing. It applies LLM to connect various audio expert models and DSP function together. With WavCraft, users can edit the content of given audio clip(s) conditioned on text input, create an audio clip given text input, get more inspiration from WavCraft by prompting a script setting and let the model do the scriptwriting and create the sound, and check if your audio file is synthesized by WavCraft.