
ComfyUI-IF_AI_tools
ComfyUI-IF_AI_tools is a set of custom nodes for ComfyUI that allows you to generate prompts using a local Large Language Model (LLM) via Ollama. This tool enables you to enhance your image generation workflow by leveraging the power of language models.
Stars: 610

ComfyUI-IF_AI_tools is a set of custom nodes for ComfyUI that allows you to generate prompts using a local Large Language Model (LLM) via Ollama. This tool enables you to enhance your image generation workflow by leveraging the power of language models.
README:

ComfyUI-IF_AI_tools is a set of custom nodes to Run Local and API LLMs and LMMs, Features OCR-RAG (Bialdy), nanoGraphRAG, Supervision Object Detection, supports Ollama, LlamaCPP LMstudio, Koboldcpp, TextGen, Transformers or via APIs Anthropic, Groq, OpenAI, Google Gemini, Mistral, xAI and create your own charcters assistants (SystemPrompts) with custom presets and muchmore
################# ATENTION ####################
** I am Moving the prompt generation to this new node PromptImaGen https://github.com/if-ai/ComfyUI-IF_AI_PromptImaGen/tree/main You will need to uninstall or disable this repo to use the PromptImaGen **
###############################################
To ensure compatibility and functionality with all tools, you may need poppler for PDF-related operations. Use scoop to install poppler on Windows:
If you haven't installed scoop yet, run the following command in PowerShell:
iwr -useb get.scoop.sh | iexStep 2: Install poppler with scoop Once scoop is installed, you can install poppler by running:
windows 10+ istall scoop and then
scoop install popplerDebian/Ubuntu
sudo apt-get install poppler-utilsMacOS
brew install popplercheck is working
pdftotext -vYou can technically use any LLM API that you want, but for the best expirience install Ollama and set it up.
- Visit ollama.com for more information.
To install Ollama models just open CMD or any terminal and type the run command follow by the model name such as
ollama run llama3.2-visionIf you want to use omost
ollama run impactframes/dolphin_llama3_omostif you need a good smol model
ollama run ollama run llama3.2Optionally Set enviromnet variables for any of your favourite LLM API keys "XAI_API_KEY", "GOOGLE_API_KEY", "ANTHROPIC_API_KEY", "MISTRAL_API_KEY", "OPENAI_API_KEY" or "GROQ_API_KEY" with those names or otherwise it won't pick it up you can also use .env file to store your keys
[NEW] nanoGraphRAG,
[NEW] OCR-RAG ColPali & ColQwen (Bialdy),
[NEW] Supervision Object Detection Florence2
[NEW] Endpoints xAI, Transformers,
[NEW] IF_Assistants System Prompts with Reasoning/Reflection/Reward Templates and custom presets
- Gemini, Groq, Mistral, OpenAI, Anthropic, Google, xAI, Transformers, Koboldcpp, TextGen, LlamaCPP, LMstudio, Ollama
- Omost_tool the first tool
- Vision Models Haiku, Florence2
- [Ollama-Omost]https://ollama.com/impactframes/dolphin_llama3_omost can be 2x to 3x faster than other Omost Models
LLama3 and Phi3 IF_AI Prompt mkr models released
ollama run impactframes/llama3_ifai_sd_prompt_mkr_q4km:latest
ollama run impactframes/ifai_promptmkr_dolphin_phi3:latest
https://huggingface.co/impactframes/llama3_if_ai_sdpromptmkr_q4km
https://huggingface.co/impactframes/ifai_promptmkr_dolphin_phi3_gguf
- Open the manager search for IF_AI_tools and install
- Navigate to your ComfyUI
custom_nodesfolder, typeCMDon the address bar to open a command prompt, and run the following command to clone the repository:git clone https://github.com/if-ai/ComfyUI-IF_AI_tools.git
OR
-
In ComfyUI protable version just dounle click
embedded_install.bator typeCMDon the address bar on the newly createdcustom_nodes\ComfyUI-IF_AI_toolsfolder typeH:\ComfyUI_windows_portable\python_embeded\python.exe -m pip install -r requirements.txt
replace
C:\for your Drive letter where you have the ComfyUI_windows_portable directory -
On custom environment activate the environment and move to the newly created ComfyUI-IF_AI_tools
cd ComfyUI-IF_AI_tools python -m pip install -r requirements.txt
- IF_prompt_MKR
- A similar tool available for Stable Diffusion WebUI
AIFuzz made a great video usining ollama and IF_AI tools

Also Future thinker @ Benji Thankyou both for putting out this awesome videos

ancient Megastructure, small lone figure
'A dwarfed figure standing atop an ancient megastructure, worn stone towering overhead. Underneath the dim moonlight, intricate engravings adorn the crumbling walls. Overwhelmed by the sheer size and age of the structure, the small figure appears lost amidst the weathered stone behemoth. The background reveals a dark landscape, dotted with faint twinkles from other ancient structures, scattered across the horizon. The silent air is only filled with the soft echoes of distant whispers, carrying secrets of times long past. ethereal-fantasy-concept-art, magical-ambiance, magnificent, celestial, ethereal-lighting, painterly, epic, majestic, dreamy-atmosphere, otherworldly, mystic-elements, surreal, immersive-detail'
- [ ] Fix Bugs and make it work on latest ComfyUI
- [ ] Fix Graph Visualizer Node
- [ ] Tweak IF_Assistants and Templates
- [ ] FrontEnd for IF_Assistants and Chat
- [ ] Node and workflow creator
- [ ] two additional Endpoints one API and one Local
- [ ] Add New workflows
- [ ] Image Generation, Text 2 Image, Image to Image, Video Generation
If you find this tool useful, please consider supporting my work by:
- Starring the repository on GitHub: ComfyUI-IF_AI_tools
- Subscribing to my YouTube channel: Impact Frames
- Follow me on X: Impact Frames X
- Supporting me on Ko-fi: Impact Frames Ko-fi
- Becoming a patron on Patreon: Impact Frames Patreon Thank You!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ComfyUI-IF_AI_tools
Similar Open Source Tools
ComfyUI-IF_AI_tools
ComfyUI-IF_AI_tools is a set of custom nodes for ComfyUI that allows you to generate prompts using a local Large Language Model (LLM) via Ollama. This tool enables you to enhance your image generation workflow by leveraging the power of language models.
ComfyUI-IF_LLM
ComfyUI-IF_AI_LLM is a lighter version of ComfyUI-IF_AI_tools, providing custom nodes to run local and API LLMs and LMMs. It supports various models like Ollama, LlamaCPP, LMstudio, Koboldcpp, TextGen, Transformers, and APIs such as Anthropic, Groq, OpenAI, Google Gemini, Mistral, xAI. Users can create their own profiles (SystemPrompts) with custom presets. The tool offers features like xAI Grok Vision, Mistral, Google Gemini, Anthropic Haiku, OpenAI preview, auto prompts generation, image generation with IF_PROMPTImaGEN via Dalle3, and more. Installation involves searching for IF_LLM in the manager or manually installing ComfyUI-IF_AI_ImaGenPromptMaker by cloning the repository and installing requirements.
ChatGPT-desktop
ChatGPT Desktop Application is a multi-platform tool that provides a powerful AI wrapper for generating text. It offers features like text-to-speech, exporting chat history in various formats, automatic application upgrades, system tray hover window, support for slash commands, customization of global shortcuts, and pop-up search. The application is built using Tauri and aims to enhance user experience by simplifying text generation tasks. It is available for Mac, Windows, and Linux, and is designed for personal learning and research purposes.

PySpur
PySpur is a graph-based editor designed for LLM workflows, offering modular building blocks for easy workflow creation and debugging at node level. It allows users to evaluate final performance and promises self-improvement features in the future. PySpur is easy-to-hack, supports JSON configs for workflow graphs, and is lightweight with minimal dependencies, making it a versatile tool for workflow management in the field of AI and machine learning.
air-light
Air-light is a minimalist WordPress starter theme designed to be an ultra minimal starting point for a WordPress project. It is built to be very straightforward, backwards compatible, front-end developer friendly and modular by its structure. Air-light is free of weird "app-like" folder structures or odd syntaxes that nobody else uses. It loves WordPress as it was and as it is.

depthai
This repository contains a demo application for DepthAI, a tool that can load different networks, create pipelines, record video, and more. It provides documentation for installation and usage, including running programs through Docker. Users can explore DepthAI features via command line arguments or a clickable QT interface. Supported models include various AI models for tasks like face detection, human pose estimation, and object detection. The tool collects anonymous usage statistics by default, which can be disabled. Users can report issues to the development team for support and troubleshooting.

rclip
rclip is a command-line photo search tool powered by the OpenAI's CLIP neural network. It allows users to search for images using text queries, similar image search, and combining multiple queries. The tool extracts features from photos to enable searching and indexing, with options for previewing results in supported terminals or custom viewers. Users can install rclip on Linux, macOS, and Windows using different installation methods. The repository follows the Conventional Commits standard and welcomes contributions from the community.
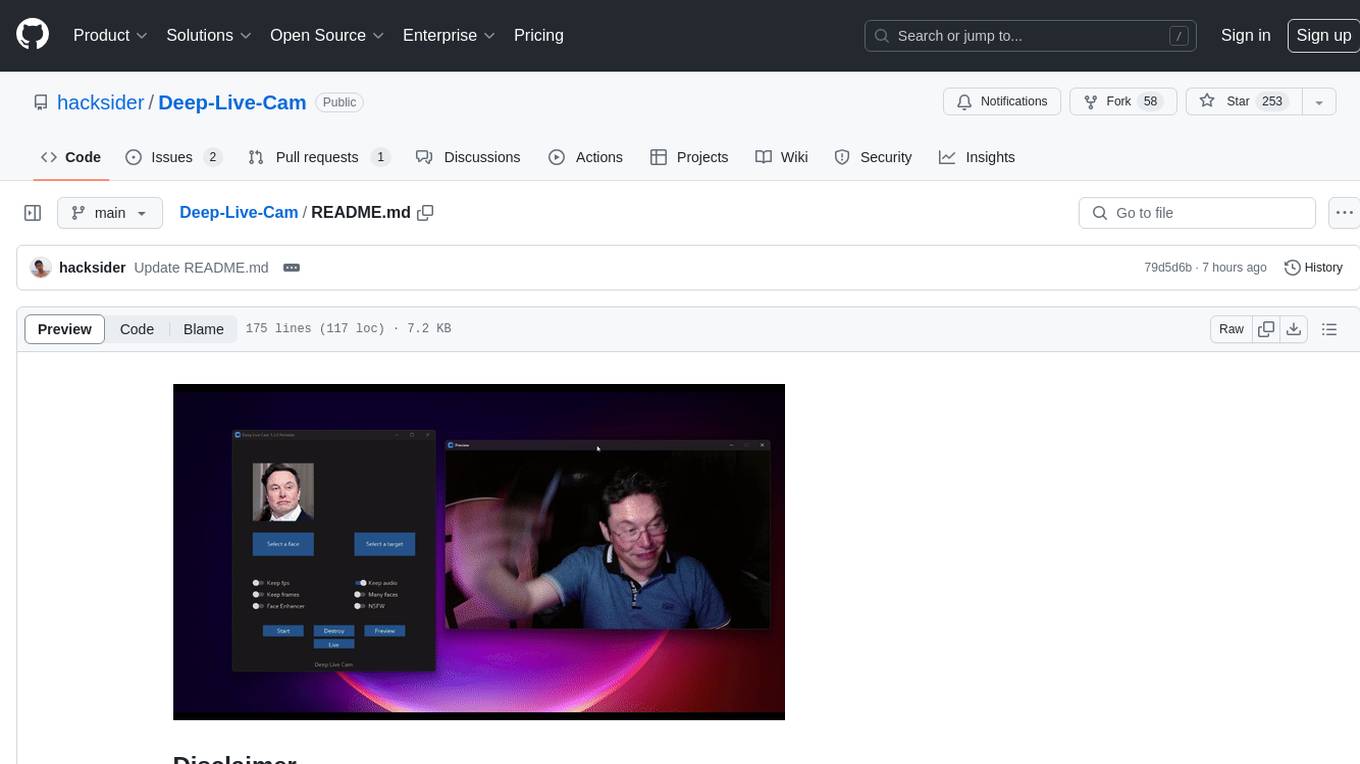
Deep-Live-Cam
Deep-Live-Cam is a software tool designed to assist artists in tasks such as animating custom characters or using characters as models for clothing. The tool includes built-in checks to prevent unethical applications, such as working on inappropriate media. Users are expected to use the tool responsibly and adhere to local laws, especially when using real faces for deepfake content. The tool supports both CPU and GPU acceleration for faster processing and provides a user-friendly GUI for swapping faces in images or videos.

trieve
Trieve is an advanced relevance API for hybrid search, recommendations, and RAG. It offers a range of features including self-hosting, semantic dense vector search, typo tolerant full-text/neural search, sub-sentence highlighting, recommendations, convenient RAG API routes, the ability to bring your own models, hybrid search with cross-encoder re-ranking, recency biasing, tunable popularity-based ranking, filtering, duplicate detection, and grouping. Trieve is designed to be flexible and customizable, allowing users to tailor it to their specific needs. It is also easy to use, with a simple API and well-documented features.

ComfyUI
ComfyUI is a powerful and modular visual AI engine and application that allows users to design and execute advanced stable diffusion pipelines using a graph/nodes/flowchart based interface. It provides a user-friendly environment for creating complex Stable Diffusion workflows without the need for coding. ComfyUI supports various models for image editing, video processing, audio manipulation, 3D modeling, and more. It offers features like smart memory management, support for different GPU types, loading and saving workflows as JSON files, and offline functionality. Users can also use API nodes to access paid models from external providers through the online Comfy API.
ComfyUI
ComfyUI is a powerful and modular visual AI engine and application that allows users to design and execute advanced stable diffusion pipelines using a graph/nodes/flowchart based interface. It provides a user-friendly environment for creating complex Stable Diffusion workflows without the need for coding. ComfyUI supports various models for image, video, audio, and 3D processing, along with features like smart memory management, model loading, embeddings/textual inversion, and offline usage. Users can experiment with different models, create complex workflows, and optimize their processes efficiently.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.
pear-landing-page
PearAI Landing Page is an open-source AI-powered code editor managed by Nang and Pan. It is built with Next.js, Vercel, Tailwind CSS, and TypeScript. The project requires setting up environment variables for proper configuration. Users can run the project locally by starting the development server and visiting the specified URL in the browser. Recommended extensions include Prettier, ESLint, and JavaScript and TypeScript Nightly. Contributions to the project are welcomed and appreciated.
upscayl
Upscayl is a free and open-source AI image upscaler that uses advanced AI algorithms to enlarge and enhance low-resolution images without losing quality. It is a cross-platform application built with the Linux-first philosophy, available on all major desktop operating systems. Upscayl utilizes Real-ESRGAN and Vulkan architecture for image enhancement, and its backend is fully open-source under the AGPLv3 license. It is important to note that a Vulkan compatible GPU is required for Upscayl to function effectively.
parllama
PAR LLAMA is a Text UI application for managing and using LLMs, designed with Textual and Rich and PAR AI Core. It runs on major OS's including Windows, Windows WSL, Mac, and Linux. Supports Dark and Light mode, custom themes, and various workflows like Ollama chat, image chat, and OpenAI provider chat. Offers features like custom prompts, themes, environment variables configuration, and remote instance connection. Suitable for managing and using LLMs efficiently.

refact-lsp
Refact Agent is a small executable written in Rust as part of the Refact Agent project. It lives inside your IDE to keep AST and VecDB indexes up to date, supporting connection graphs between definitions and usages in popular programming languages. It functions as an LSP server, offering code completion, chat functionality, and integration with various tools like browsers, databases, and debuggers. Users can interact with it through a Text UI in the command line.
For similar tasks
ComfyUI-IF_AI_tools
ComfyUI-IF_AI_tools is a set of custom nodes for ComfyUI that allows you to generate prompts using a local Large Language Model (LLM) via Ollama. This tool enables you to enhance your image generation workflow by leveraging the power of language models.

InvokeAI
InvokeAI is a leading creative engine built to empower professionals and enthusiasts alike. Generate and create stunning visual media using the latest AI-driven technologies. InvokeAI offers an industry leading Web Interface, interactive Command Line Interface, and also serves as the foundation for multiple commercial products.

StableSwarmUI
StableSwarmUI is a modular Stable Diffusion web user interface that emphasizes making power tools easily accessible, high performance, and extensible. It is designed to be a one-stop-shop for all things Stable Diffusion, providing a wide range of features and capabilities to enhance the user experience.

civitai
Civitai is a platform where people can share their stable diffusion models (textual inversions, hypernetworks, aesthetic gradients, VAEs, and any other crazy stuff people do to customize their AI generations), collaborate with others to improve them, and learn from each other's work. The platform allows users to create an account, upload their models, and browse models that have been shared by others. Users can also leave comments and feedback on each other's models to facilitate collaboration and knowledge sharing.

ap-plugin
AP-PLUGIN is an AI drawing plugin for the Yunzai series robot framework, allowing you to have a convenient AI drawing experience in the input box. It uses the open source Stable Diffusion web UI as the backend, deploys it for free, and generates a variety of images with richer functions.
midjourney-proxy
Midjourney-proxy is a proxy for the Discord channel of MidJourney, enabling API-based calls for AI drawing. It supports Imagine instructions, adding image base64 as a placeholder, Blend and Describe commands, real-time progress tracking, Chinese prompt translation, prompt sensitive word pre-detection, user-token connection to WSS, multi-account configuration, and more. For more advanced features, consider using midjourney-proxy-plus, which includes Shorten, focus shifting, image zooming, local redrawing, nearly all associated button actions, Remix mode, seed value retrieval, account pool persistence, dynamic maintenance, /info and /settings retrieval, account settings configuration, Niji bot robot, InsightFace face replacement robot, and an embedded management dashboard.
krita-ai-diffusion
Krita-AI-Diffusion is a plugin for Krita that allows users to generate images from within the program. It offers a variety of features, including inpainting, outpainting, generating images from scratch, refining existing content, live painting, and control over image creation. The plugin is designed to fit into an interactive workflow where AI generation is used as just another tool while painting. It is meant to synergize with traditional tools and the layer stack.
cog-comfyui
Cog-comfyui allows users to run ComfyUI workflows on Replicate. ComfyUI is a visual programming tool for creating and sharing generative art workflows. With cog-comfyui, users can access a variety of pre-trained models and custom nodes to create their own unique artworks. The tool is easy to use and does not require any coding experience. Users simply need to upload their API JSON file and any necessary input files, and then click the "Run" button. Cog-comfyui will then generate the output image or video file.
For similar jobs
ComfyUI-IF_AI_tools
ComfyUI-IF_AI_tools is a set of custom nodes for ComfyUI that allows you to generate prompts using a local Large Language Model (LLM) via Ollama. This tool enables you to enhance your image generation workflow by leveraging the power of language models.
StableSwarmUI
StableSwarmUI is a modular Stable Diffusion web user interface that emphasizes making power tools easily accessible, high performance, and extensible. It is designed to be a one-stop-shop for all things Stable Diffusion, providing a wide range of features and capabilities to enhance the user experience.
civitai
Civitai is a platform where people can share their stable diffusion models (textual inversions, hypernetworks, aesthetic gradients, VAEs, and any other crazy stuff people do to customize their AI generations), collaborate with others to improve them, and learn from each other's work. The platform allows users to create an account, upload their models, and browse models that have been shared by others. Users can also leave comments and feedback on each other's models to facilitate collaboration and knowledge sharing.
Awesome-Segment-Anything
The Segment Anything Model (SAM) is a powerful tool that allows users to segment any object in an image with just a few clicks. This makes it a great tool for a variety of tasks, such as object detection, tracking, and editing. SAM is also very easy to use, making it a great option for both beginners and experienced users.
krita-ai-diffusion
Krita-AI-Diffusion is a plugin for Krita that allows users to generate images from within the program. It offers a variety of features, including inpainting, outpainting, generating images from scratch, refining existing content, live painting, and control over image creation. The plugin is designed to fit into an interactive workflow where AI generation is used as just another tool while painting. It is meant to synergize with traditional tools and the layer stack.
ai-toolkit
The AI Toolkit by Ostris is a collection of tools for machine learning, specifically designed for image generation, LoRA (latent representations of attributes) extraction and manipulation, and model training. It provides a user-friendly interface and extensive documentation to make it accessible to both developers and non-developers. The toolkit is actively under development, with new features and improvements being added regularly. Some of the key features of the AI Toolkit include: - Batch Image Generation: Allows users to generate a batch of images based on prompts or text files, using a configuration file to specify the desired settings. - LoRA (lierla), LoCON (LyCORIS) Extractor: Facilitates the extraction of LoRA and LoCON representations from pre-trained models, enabling users to modify and manipulate these representations for various purposes. - LoRA Rescale: Provides a tool to rescale LoRA weights, allowing users to adjust the influence of specific attributes in the generated images. - LoRA Slider Trainer: Enables the training of LoRA sliders, which can be used to control and adjust specific attributes in the generated images, offering a powerful tool for fine-tuning and customization. - Extensions: Supports the creation and sharing of custom extensions, allowing users to extend the functionality of the toolkit with their own tools and scripts. - VAE (Variational Auto Encoder) Trainer: Facilitates the training of VAEs for image generation, providing users with a tool to explore and improve the quality of generated images. The AI Toolkit is a valuable resource for anyone interested in exploring and utilizing machine learning for image generation and manipulation. Its user-friendly interface, extensive documentation, and active development make it an accessible and powerful tool for both beginners and experienced users.

LocalAI
LocalAI is a free and open-source OpenAI alternative that acts as a drop-in replacement REST API compatible with OpenAI (Elevenlabs, Anthropic, etc.) API specifications for local AI inferencing. It allows users to run LLMs, generate images, audio, and more locally or on-premises with consumer-grade hardware, supporting multiple model families and not requiring a GPU. LocalAI offers features such as text generation with GPTs, text-to-audio, audio-to-text transcription, image generation with stable diffusion, OpenAI functions, embeddings generation for vector databases, constrained grammars, downloading models directly from Huggingface, and a Vision API. It provides a detailed step-by-step introduction in its Getting Started guide and supports community integrations such as custom containers, WebUIs, model galleries, and various bots for Discord, Slack, and Telegram. LocalAI also offers resources like an LLM fine-tuning guide, instructions for local building and Kubernetes installation, projects integrating LocalAI, and a how-tos section curated by the community. It encourages users to cite the repository when utilizing it in downstream projects and acknowledges the contributions of various software from the community.

h2ogpt
h2oGPT is an Apache V2 open-source project that allows users to query and summarize documents or chat with local private GPT LLMs. It features a private offline database of any documents (PDFs, Excel, Word, Images, Video Frames, Youtube, Audio, Code, Text, MarkDown, etc.), a persistent database (Chroma, Weaviate, or in-memory FAISS) using accurate embeddings (instructor-large, all-MiniLM-L6-v2, etc.), and efficient use of context using instruct-tuned LLMs (no need for LangChain's few-shot approach). h2oGPT also offers parallel summarization and extraction, reaching an output of 80 tokens per second with the 13B LLaMa2 model, HYDE (Hypothetical Document Embeddings) for enhanced retrieval based upon LLM responses, a variety of models supported (LLaMa2, Mistral, Falcon, Vicuna, WizardLM. With AutoGPTQ, 4-bit/8-bit, LORA, etc.), GPU support from HF and LLaMa.cpp GGML models, and CPU support using HF, LLaMa.cpp, and GPT4ALL models. Additionally, h2oGPT provides Attention Sinks for arbitrarily long generation (LLaMa-2, Mistral, MPT, Pythia, Falcon, etc.), a UI or CLI with streaming of all models, the ability to upload and view documents through the UI (control multiple collaborative or personal collections), Vision Models LLaVa, Claude-3, Gemini-Pro-Vision, GPT-4-Vision, Image Generation Stable Diffusion (sdxl-turbo, sdxl) and PlaygroundAI (playv2), Voice STT using Whisper with streaming audio conversion, Voice TTS using MIT-Licensed Microsoft Speech T5 with multiple voices and Streaming audio conversion, Voice TTS using MPL2-Licensed TTS including Voice Cloning and Streaming audio conversion, AI Assistant Voice Control Mode for hands-free control of h2oGPT chat, Bake-off UI mode against many models at the same time, Easy Download of model artifacts and control over models like LLaMa.cpp through the UI, Authentication in the UI by user/password via Native or Google OAuth, State Preservation in the UI by user/password, Linux, Docker, macOS, and Windows support, Easy Windows Installer for Windows 10 64-bit (CPU/CUDA), Easy macOS Installer for macOS (CPU/M1/M2), Inference Servers support (oLLaMa, HF TGI server, vLLM, Gradio, ExLLaMa, Replicate, OpenAI, Azure OpenAI, Anthropic), OpenAI-compliant, Server Proxy API (h2oGPT acts as drop-in-replacement to OpenAI server), Python client API (to talk to Gradio server), JSON Mode with any model via code block extraction. Also supports MistralAI JSON mode, Claude-3 via function calling with strict Schema, OpenAI via JSON mode, and vLLM via guided_json with strict Schema, Web-Search integration with Chat and Document Q/A, Agents for Search, Document Q/A, Python Code, CSV frames (Experimental, best with OpenAI currently), Evaluate performance using reward models, and Quality maintained with over 1000 unit and integration tests taking over 4 GPU-hours.