
Whisper-WebUI
A Web UI for easy subtitle using whisper model.
Stars: 1772
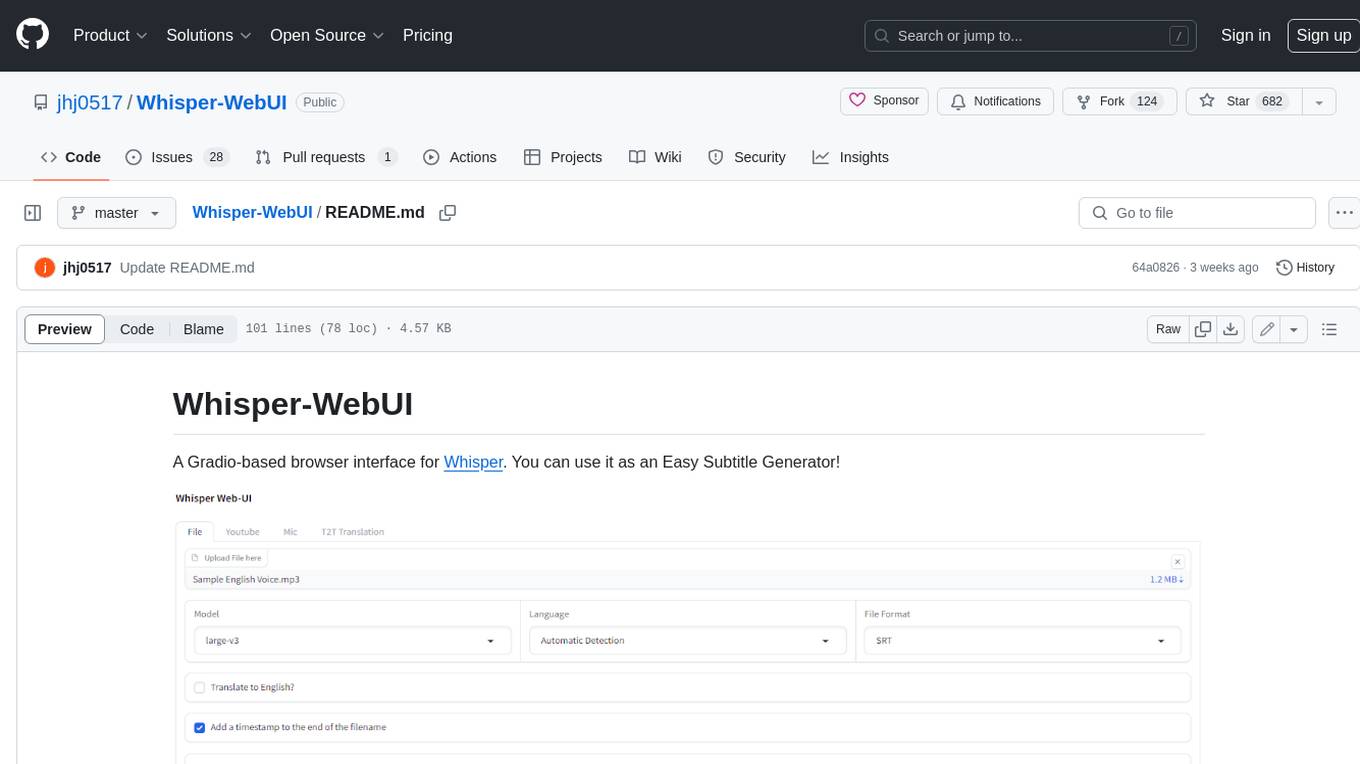
Whisper-WebUI is a Gradio-based browser interface for Whisper, serving as an Easy Subtitle Generator. It supports generating subtitles from various sources such as files, YouTube, and microphone. The tool also offers speech-to-text and text-to-text translation features, utilizing Facebook NLLB models and DeepL API. Users can translate subtitle files from other languages to English and vice versa. The project integrates faster-whisper for improved VRAM usage and transcription speed, providing efficiency metrics for optimized whisper models. Additionally, users can choose from different Whisper models based on size and language requirements.
README:
A Gradio-based browser interface for Whisper. You can use it as an Easy Subtitle Generator!
If you wish to try this on Colab, you can do it in here!
- Select the Whisper implementation you want to use between :
- openai/whisper
- SYSTRAN/faster-whisper (used by default)
- Vaibhavs10/insanely-fast-whisper
- Generate subtitles from various sources, including :
- Files
- Youtube
- Microphone
- Currently supported subtitle formats :
- SRT
- WebVTT
- txt ( only text file without timeline )
- Speech to Text Translation
- From other languages to English. ( This is Whisper's end-to-end speech-to-text translation feature )
- Text to Text Translation
- Translate subtitle files using Facebook NLLB models
- Translate subtitle files using DeepL API
- Pre-processing audio input with Silero VAD.
- Pre-processing audio input to separate BGM with UVR.
- Post-processing with speaker diarization using the pyannote model.
- To download the pyannote model, you need to have a Huggingface token and manually accept their terms in the pages below.
The app is able to run with Pinokio.
- Install Pinokio Software.
- Open the software and search for Whisper-WebUI and install it.
- Start the Whisper-WebUI and connect to the
http://localhost:7860.
-
Install and launch Docker-Desktop.
-
Git clone the repository
git clone https://github.com/jhj0517/Whisper-WebUI.git- Build the image ( Image is about 7GB~ )
docker compose build - Run the container
docker compose up- Connect to the WebUI with your browser at
http://localhost:7860
If needed, update the docker-compose.yaml to match your environment.
To run this WebUI, you need to have git, 3.10 <= python <= 3.12, FFmpeg.
Edit --extra-index-url in the requirements.txt to match your device.
By default, the WebUI assumes you're using an Nvidia GPU and CUDA 12.4. If you're using Intel or another CUDA version, read the requirements.txt and edit --extra-index-url.
Please follow the links below to install the necessary software:
- git : https://git-scm.com/downloads
- python : https://www.python.org/downloads/
3.10 ~ 3.12is recommended. - FFmpeg : https://ffmpeg.org/download.html
- CUDA : https://developer.nvidia.com/cuda-downloads
After installing FFmpeg, make sure to add the FFmpeg/bin folder to your system PATH!
- git clone this repository
git clone https://github.com/jhj0517/Whisper-WebUI.git- Run
install.batorinstall.shto install dependencies. (It will create avenvdirectory and install dependencies there.) - Start WebUI with
start-webui.batorstart-webui.sh(It will runpython app.pyafter activating the venv)
And you can also run the project with command line arguments if you like to, see wiki for a guide to arguments.
This project is integrated with faster-whisper by default for better VRAM usage and transcription speed.
According to faster-whisper, the efficiency of the optimized whisper model is as follows:
| Implementation | Precision | Beam size | Time | Max. GPU memory | Max. CPU memory |
|---|---|---|---|---|---|
| openai/whisper | fp16 | 5 | 4m30s | 11325MB | 9439MB |
| faster-whisper | fp16 | 5 | 54s | 4755MB | 3244MB |
If you want to use an implementation other than faster-whisper, use --whisper_type arg and the repository name.
Read wiki for more info about CLI args.
If you want to use a fine-tuned model, manually place the models in models/Whisper/ corresponding to the implementation.
Alternatively, if you enter the huggingface repo id (e.g, deepdml/faster-whisper-large-v3-turbo-ct2) in the "Model" dropdown, it will be automatically downloaded in the directory.
If you're interested in deploying this app as a REST API, please check out /backend.
- [x] Add DeepL API translation
- [x] Add NLLB Model translation
- [x] Integrate with faster-whisper
- [x] Integrate with insanely-fast-whisper
- [x] Integrate with whisperX ( Only speaker diarization part )
- [x] Add background music separation pre-processing with UVR
- [x] Add fast api script
- [ ] Add CLI usages
- [ ] Support real-time transcription for microphone
Any PRs that translate the language into translation.yaml would be greatly appreciated!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Whisper-WebUI
Similar Open Source Tools
Whisper-WebUI
Whisper-WebUI is a Gradio-based browser interface for Whisper, serving as an Easy Subtitle Generator. It supports generating subtitles from various sources such as files, YouTube, and microphone. The tool also offers speech-to-text and text-to-text translation features, utilizing Facebook NLLB models and DeepL API. Users can translate subtitle files from other languages to English and vice versa. The project integrates faster-whisper for improved VRAM usage and transcription speed, providing efficiency metrics for optimized whisper models. Additionally, users can choose from different Whisper models based on size and language requirements.
KrillinAI
KrillinAI is a video subtitle translation and dubbing tool based on AI large models, featuring speech recognition, intelligent sentence segmentation, professional translation, and one-click deployment of the entire process. It provides a one-stop workflow from video downloading to the final product, empowering cross-language cultural communication with AI. The tool supports multiple languages for input and translation, integrates features like automatic dependency installation, video downloading from platforms like YouTube and Bilibili, high-speed subtitle recognition, intelligent subtitle segmentation and alignment, custom vocabulary replacement, professional-level translation engine, and diverse external service selection for speech and large model services.

KlicStudio
Klic Studio is a versatile audio and video localization and enhancement solution developed by Krillin AI. This minimalist yet powerful tool integrates video translation, dubbing, and voice cloning, supporting both landscape and portrait formats. With an end-to-end workflow, users can transform raw materials into beautifully ready-to-use cross-platform content with just a few clicks. The tool offers features like video acquisition, accurate speech recognition, intelligent segmentation, terminology replacement, professional translation, voice cloning, video composition, and cross-platform support. It also supports various speech recognition services, large language models, and TTS text-to-speech services. Users can easily deploy the tool using Docker and configure it for different tasks like subtitle translation, large model translation, and optional voice services.

tts-generation-webui
TTS Generation WebUI is a comprehensive tool that provides a user-friendly interface for text-to-speech and voice cloning tasks. It integrates various AI models such as Bark, MusicGen, AudioGen, Tortoise, RVC, Vocos, Demucs, SeamlessM4T, and MAGNeT. The tool offers one-click installers, Google Colab demo, videos for guidance, and extra voices for Bark. Users can generate audio outputs, manage models, caches, and system space for AI projects. The project is open-source and emphasizes ethical and responsible use of AI technology.

ComfyUI
ComfyUI is a powerful and modular visual AI engine and application that allows users to design and execute advanced stable diffusion pipelines using a graph/nodes/flowchart based interface. It provides a user-friendly environment for creating complex Stable Diffusion workflows without the need for coding. ComfyUI supports various models for image editing, video processing, audio manipulation, 3D modeling, and more. It offers features like smart memory management, support for different GPU types, loading and saving workflows as JSON files, and offline functionality. Users can also use API nodes to access paid models from external providers through the online Comfy API.
pyht
pyht is a Python SDK for the PlayHT's AI Text-to-Speech API, allowing users to convert text into high-quality audio streams in humanlike voice. It supports real-time text-to-speech streaming, pre-built and custom voices, various audio formats, and different sample rates.
Whisper-TikTok
Discover Whisper-TikTok, an innovative AI-powered tool that leverages the prowess of Edge TTS, OpenAI-Whisper, and FFMPEG to craft captivating TikTok videos. Whisper-TikTok effortlessly generates accurate transcriptions from audio files and integrates Microsoft Edge Cloud Text-to-Speech API for vibrant voiceovers. The program orchestrates the synthesis of videos using a structured JSON dataset, generating mesmerizing TikTok content in minutes.
ComfyUI
ComfyUI is a powerful and modular visual AI engine and application that allows users to design and execute advanced stable diffusion pipelines using a graph/nodes/flowchart based interface. It provides a user-friendly environment for creating complex Stable Diffusion workflows without the need for coding. ComfyUI supports various models for image, video, audio, and 3D processing, along with features like smart memory management, model loading, embeddings/textual inversion, and offline usage. Users can experiment with different models, create complex workflows, and optimize their processes efficiently.
ChatGPT-desktop
ChatGPT Desktop Application is a multi-platform tool that provides a powerful AI wrapper for generating text. It offers features like text-to-speech, exporting chat history in various formats, automatic application upgrades, system tray hover window, support for slash commands, customization of global shortcuts, and pop-up search. The application is built using Tauri and aims to enhance user experience by simplifying text generation tasks. It is available for Mac, Windows, and Linux, and is designed for personal learning and research purposes.

Easy-Translate
Easy-Translate is a script designed for translating large text files with a single command. It supports various models like M2M100, NLLB200, SeamlessM4T, LLaMA, and Bloom. The tool is beginner-friendly and offers seamless and customizable features for advanced users. It allows acceleration on CPU, multi-CPU, GPU, multi-GPU, and TPU, with support for different precisions and decoding strategies. Easy-Translate also provides an evaluation script for translations. Built on HuggingFace's Transformers and Accelerate library, it supports prompt usage and loading huge models efficiently.
LocalAIVoiceChat
LocalAIVoiceChat is an experimental alpha software that enables real-time voice chat with a customizable AI personality and voice on your PC. It integrates Zephyr 7B language model with speech-to-text and text-to-speech libraries. The tool is designed for users interested in state-of-the-art voice solutions and provides an early version of a local real-time chatbot.

PySpur
PySpur is a graph-based editor designed for LLM workflows, offering modular building blocks for easy workflow creation and debugging at node level. It allows users to evaluate final performance and promises self-improvement features in the future. PySpur is easy-to-hack, supports JSON configs for workflow graphs, and is lightweight with minimal dependencies, making it a versatile tool for workflow management in the field of AI and machine learning.
AIWritingCompanion
AIWritingCompanion is a lightweight and versatile browser extension designed to translate text within input fields. It offers universal compatibility, multiple activation methods, and support for various translation providers like Gemini, OpenAI, and WebAI to API. Users can install it via CRX file or Git, set API key, and use it for automatic translation or via shortcut. The tool is suitable for writers, translators, students, researchers, and bloggers. AI keywords include writing assistant, translation tool, browser extension, language translation, and text translator. Users can use it for tasks like translate text, assist in writing, simplify content, check language accuracy, and enhance communication.
UltraSinger
UltraSinger is a tool under development that automatically creates UltraStar.txt, midi, and notes from music. It pitches UltraStar files, adds text and tapping, creates separate UltraStar karaoke files, re-pitches current UltraStar files, and calculates in-game score. It uses multiple AI models to extract text from voice and determine pitch. Users should mention UltraSinger in UltraStar.txt files and only use it on Creative Commons licensed songs.
transcriptionstream
Transcription Stream is a self-hosted diarization service that works offline, allowing users to easily transcribe and summarize audio files. It includes a web interface for file management, Ollama for complex operations on transcriptions, and Meilisearch for fast full-text search. Users can upload files via SSH or web interface, with output stored in named folders. The tool requires a NVIDIA GPU and provides various scripts for installation and running. Ports for SSH, HTTP, Ollama, and Meilisearch are specified, along with access details for SSH server and web interface. Customization options and troubleshooting tips are provided in the documentation.
NekoImageGallery
NekoImageGallery is an online AI image search engine that utilizes the Clip model and Qdrant vector database. It supports keyword search and similar image search. The tool generates 768-dimensional vectors for each image using the Clip model, supports OCR text search using PaddleOCR, and efficiently searches vectors using the Qdrant vector database. Users can deploy the tool locally or via Docker, with options for metadata storage using Qdrant database or local file storage. The tool provides API documentation through FastAPI's built-in Swagger UI and can be used for tasks like image search, text extraction, and vector search.
For similar tasks
Whisper-WebUI
Whisper-WebUI is a Gradio-based browser interface for Whisper, serving as an Easy Subtitle Generator. It supports generating subtitles from various sources such as files, YouTube, and microphone. The tool also offers speech-to-text and text-to-text translation features, utilizing Facebook NLLB models and DeepL API. Users can translate subtitle files from other languages to English and vice versa. The project integrates faster-whisper for improved VRAM usage and transcription speed, providing efficiency metrics for optimized whisper models. Additionally, users can choose from different Whisper models based on size and language requirements.

wunjo.wladradchenko.ru
Wunjo AI is a comprehensive tool that empowers users to explore the realm of speech synthesis, deepfake animations, video-to-video transformations, and more. Its user-friendly interface and privacy-first approach make it accessible to both beginners and professionals alike. With Wunjo AI, you can effortlessly convert text into human-like speech, clone voices from audio files, create multi-dialogues with distinct voice profiles, and perform real-time speech recognition. Additionally, you can animate faces using just one photo combined with audio, swap faces in videos, GIFs, and photos, and even remove unwanted objects or enhance the quality of your deepfakes using the AI Retouch Tool. Wunjo AI is an all-in-one solution for your voice and visual AI needs, offering endless possibilities for creativity and expression.

Open-Sora-Plan
Open-Sora-Plan is a project that aims to create a simple and scalable repo to reproduce Sora (OpenAI, but we prefer to call it "ClosedAI"). The project is still in its early stages, but the team is working hard to improve it and make it more accessible to the open-source community. The project is currently focused on training an unconditional model on a landscape dataset, but the team plans to expand the scope of the project in the future to include text2video experiments, training on video2text datasets, and controlling the model with more conditions.
Rewind-AI-Main
Rewind AI is a free and open-source AI-powered video editing tool that allows users to easily create and edit videos. It features a user-friendly interface, a wide range of editing tools, and support for a variety of video formats. Rewind AI is perfect for beginners and experienced video editors alike.

CushyStudio
CushyStudio is a generative AI platform designed for creatives of any level to effortlessly create stunning images, videos, and 3D models. It offers CushyApps, a collection of visual tools tailored for different artistic tasks, and CushyKit, an extensive toolkit for custom apps development and task automation. Users can dive into the AI revolution, unleash their creativity, share projects, and connect with a vibrant community. The platform aims to simplify the AI art creation process and provide a user-friendly environment for designing interfaces, adding custom logic, and accessing various tools.
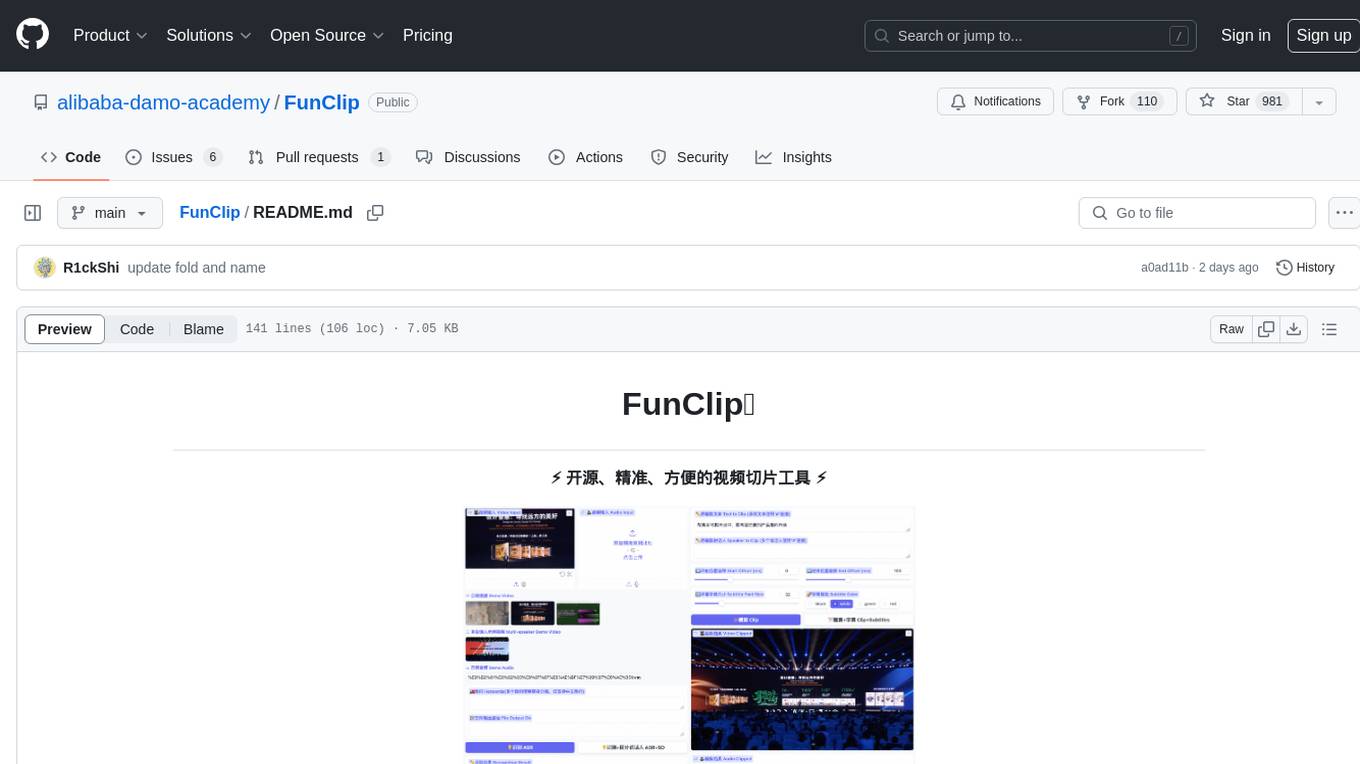
FunClip
FunClip is an open-source, locally deployable automated video editing tool that utilizes the FunASR Paraformer series models from Alibaba DAMO Academy for speech recognition in videos. Users can select text segments or speakers from the recognition results and click the clip button to obtain the corresponding video segments. FunClip integrates advanced features such as the Paraformer-Large model for accurate Chinese ASR, SeACo-Paraformer for customized hotword recognition, CAM++ speaker recognition model, Gradio interactive interface for easy usage, support for multiple free edits with automatic SRT subtitles generation, and segment-specific SRT subtitles.
ChopperBot
A multifunctional, intelligent, personalized, scalable, easy to build, and fully automated multi platform intelligent live video editing and publishing robot. ChopperBot is a comprehensive AI tool that automatically analyzes and slices the most interesting clips from popular live streaming platforms, generates and publishes content, and manages accounts. It supports plugin DIY development and hot swapping functionality, making it easy to customize and expand. With ChopperBot, users can quickly build their own live video editing platform without the need to install any software, thanks to its visual management interface.
ComfyUI-BRIA_AI-RMBG
ComfyUI-BRIA_AI-RMBG is an unofficial implementation of the BRIA Background Removal v1.4 model for ComfyUI. The tool supports batch processing, including video background removal, and introduces a new mask output feature. Users can install the tool using ComfyUI Manager or manually by cloning the repository. The tool includes nodes for automatically loading the Removal v1.4 model and removing backgrounds. Updates include support for batch processing and the addition of a mask output feature.
For similar jobs

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

daily-poetry-image
Daily Chinese ancient poetry and AI-generated images powered by Bing DALL-E-3. GitHub Action triggers the process automatically. Poetry is provided by Today's Poem API. The website is built with Astro.

exif-photo-blog
EXIF Photo Blog is a full-stack photo blog application built with Next.js, Vercel, and Postgres. It features built-in authentication, photo upload with EXIF extraction, photo organization by tag, infinite scroll, light/dark mode, automatic OG image generation, a CMD-K menu with photo search, experimental support for AI-generated descriptions, and support for Fujifilm simulations. The application is easy to deploy to Vercel with just a few clicks and can be customized with a variety of environment variables.

SillyTavern
SillyTavern is a user interface you can install on your computer (and Android phones) that allows you to interact with text generation AIs and chat/roleplay with characters you or the community create. SillyTavern is a fork of TavernAI 1.2.8 which is under more active development and has added many major features. At this point, they can be thought of as completely independent programs.

Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).

AISuperDomain
Aila Desktop Application is a powerful tool that integrates multiple leading AI models into a single desktop application. It allows users to interact with various AI models simultaneously, providing diverse responses and insights to their inquiries. With its user-friendly interface and customizable features, Aila empowers users to engage with AI seamlessly and efficiently. Whether you're a researcher, student, or professional, Aila can enhance your AI interactions and streamline your workflow.

ChatGPT-On-CS
This project is an intelligent dialogue customer service tool based on a large model, which supports access to platforms such as WeChat, Qianniu, Bilibili, Douyin Enterprise, Douyin, Doudian, Weibo chat, Xiaohongshu professional account operation, Xiaohongshu, Zhihu, etc. You can choose GPT3.5/GPT4.0/ Lazy Treasure Box (more platforms will be supported in the future), which can process text, voice and pictures, and access external resources such as operating systems and the Internet through plug-ins, and support enterprise AI applications customized based on their own knowledge base.

obs-localvocal
LocalVocal is a live-streaming AI assistant plugin for OBS that allows you to transcribe audio speech into text and perform various language processing functions on the text using AI / LLMs (Large Language Models). It's privacy-first, with all data staying on your machine, and requires no GPU, cloud costs, network, or downtime.