
trieve
All-in-one platform for search, recommendations, RAG, and analytics offered via API
Stars: 2482

Trieve is an advanced relevance API for hybrid search, recommendations, and RAG. It offers a range of features including self-hosting, semantic dense vector search, typo tolerant full-text/neural search, sub-sentence highlighting, recommendations, convenient RAG API routes, the ability to bring your own models, hybrid search with cross-encoder re-ranking, recency biasing, tunable popularity-based ranking, filtering, duplicate detection, and grouping. Trieve is designed to be flexible and customizable, allowing users to tailor it to their specific needs. It is also easy to use, with a simple API and well-documented features.
README:
Sign Up (1k chunks free) | PDF2MD | Hacker News Search Engine | Documentation | Meet a Maintainer | Discord | Matrix


- 🔒 Self-Hosting in your VPC or on-prem: We have full self-hosting guides for AWS, GCP, Kubernetes generally, and docker compose available on our documentation page here.
- 🧠 Semantic Dense Vector Search: Integrates with OpenAI or Jina embedding models and Qdrant to provide semantic vector search.
- 🔍 Typo Tolerant Full-Text/Neural Search: Every uploaded chunk is vector'ized with naver/efficient-splade-VI-BT-large-query for typo tolerant, quality neural sparse-vector search.
- 🖊️ Sub-Sentence Highlighting: Highlight the matching words or sentences within a chunk and bold them on search to enhance UX for your users. Shout out to the simsearch crate!
- 🌟 Recommendations: Find similar chunks (or files if using grouping) with the recommendation API. Very helpful if you have a platform where users' favorite, bookmark, or upvote content.
- 🤖 Convenient RAG API Routes: We integrate with OpenRouter to provide you with access to any LLM you would like for RAG. Try our routes for fully-managed RAG with topic-based memory management or select your own context RAG.
- 💼 Bring Your Own Models: If you'd like, you can bring your own text-embedding, SPLADE, cross-encoder re-ranking, and/or large-language model (LLM) and plug it into our infrastructure.
- 🔄 Hybrid Search with cross-encoder re-ranking: For the best results, use hybrid search with BAAI/bge-reranker-large re-rank optimization.
- 📆 Recency Biasing: Easily bias search results for what was most recent to prevent staleness
- 🛠️ Tunable Merchandizing: Adjust relevance using signals like clicks, add-to-carts, or citations
- 🕳️ Filtering: Date-range, substring match, tag, numeric, and other filter types are supported.
- 👥 Grouping: Mark multiple chunks as being part of the same file and search on the file-level such that the same top-level result never appears twice
Are we missing a feature that your use case would need? - call us at 628-222-4090, make a Github issue, or join the Matrix community and tell us! We are a small company who is still very hands-on and eager to build what you need; professional services are available.
To install Trieve for Claude Desktop automatically via Smithery:
npx -y @smithery/cli install trieve-mcp-server --client claudesudo apt install curl \
gcc \
g++ \
make \
pkg-config \
python3 \
python3-pip \
libpq-dev \
libssl-dev \
opensslsudo pacman -S base-devel postgresql-libsYou can install NVM using its install script.
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.5/install.sh | bash
You should restart the terminal to update bash profile with NVM. Then, you can install NodeJS LTS release and Yarn.
nvm install --lts
npm install -g yarn
mkdir server/tmp
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
cargo install cargo-watch
You might need to create the analytics directory in ./frontends
cp .env.analytics ./frontends/analytics/.env
cp .env.chat ./frontends/chat/.env
cp .env.search ./frontends/search/.env
cp .env.example ./server/.env
cp .env.dashboard ./frontends/dashboard/.env
Here is a guide for acquiring that.
- Open the
./server/.envfile - Replace the value for
LLM_API_KEYto be your own OpenAI API key. - Replace the value for
OPENAI_API_KEYto be your own OpenAI API key.
The PAGEFIND_CDN_BASE_URL and S3_SECRET_KEY_CSVJSONL could be set to a random list of strings.
export OPENAI_API_KEY="your_OpenAI_api_key" \
LLM_API_KEY="your_OpenAI_api_key" \
PAGEFIND_CDN_BASE_URL="lZP8X4h0Q5Sj2ZmV,aAmu1W92T6DbFUkJ,DZ5pMvz8P1kKNH0r,QAqwvKh8rI5sPmuW,YMwgsBz7jLfN0oX8" \
S3_SECRET_KEY_CSVJSONL="Gq6wzS3mjC5kL7i4KwexnL3gP8Z1a5Xv,V2c4ZnL0uHqBzFvR2NcN8Pb1g6CjmX9J,TfA1h8LgI5zYkH9A9p7NvWlL0sZzF9p8N,pKr81pLq5n6MkNzT1X09R7Qb0Vn5cFr0d,DzYwz82FQiW6T3u9A4z9h7HLOlJb7L2V1" \
GROQ_API_KEY="GROQ_API_KEY_if_applicable"
cat .env.chat .env.search .env.server .env.docker-compose > .env
./convenience.sh -l
cd frontends
yarn
cd ..
cd clients/ts-sdk
yarn build
cd ../..
It is recommend to manage services through tmuxp, see the guide here or terminal tabs.
cd frontends
yarn
yarn dev
cd server
cargo watch -x run
cd server
cargo run --bin ingestion-worker
cd server
cargo run --bin file-worker
cd server
cargo run --bin delete-worker
cd search
yarn
yarn dev
After the cargo build has finished (after the tmuxp load trieve):
- check that you can see redoc with the OpenAPI reference at localhost:8090/redoc
- make an account create a dataset with test data at localhost:5173
- search that dataset with test data at localhost:5174
To test the Cross Encoder rerankers in local dev,
- click on the dataset, go to the Dataset Settings -> Dataset Options -> Additional Options and uncheck the
Fulltext Enabledoption. - in the Embedding Settings, select your reranker model and enter the respective key in the adjacent textbox, and hit save.
- in the search playground, set Type -> Semantic and select Rerank By -> Cross Encoder
- if AIMon Reranker is selected in the Embedding Settings, you can enter an optional Task Definition in the search playground to specify the domain of context documents to the AIMon reranker.
Reach out to us on discord for assistance. We are available and more than happy to assist.
diesel::debug_query(&query).to_string();
The evals package loads an mcp client that then runs the index.ts file, so there is no need to rebuild between tests. You can load environment variables by prefixing the npx command. Full documentation can be found here.
OPENAI_API_KEY=your-key npx mcp-eval evals.ts clients/mcp-server/src/index.tsInstall Stripe CLI.
stripe loginstripe listen --forward-to localhost:8090/api/stripe/webhook- set the
STRIPE_WEBHOOK_SECRETin theserver/.envto the resulting webhook signing secret stripe products create --name trieve --default-price-data.unit-amount 1200 --default-price-data.currency usdstripe plans create --amount=1200 --currency=usd --interval=month --product={id from response of step 3}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for trieve
Similar Open Source Tools
trieve
Trieve is an advanced relevance API for hybrid search, recommendations, and RAG. It offers a range of features including self-hosting, semantic dense vector search, typo tolerant full-text/neural search, sub-sentence highlighting, recommendations, convenient RAG API routes, the ability to bring your own models, hybrid search with cross-encoder re-ranking, recency biasing, tunable popularity-based ranking, filtering, duplicate detection, and grouping. Trieve is designed to be flexible and customizable, allowing users to tailor it to their specific needs. It is also easy to use, with a simple API and well-documented features.

gitingest
GitIngest is a tool that allows users to turn any Git repository into a prompt-friendly text ingest for LLMs. It provides easy code context by generating a text digest from a git repository URL or directory. The tool offers smart formatting for optimized output format for LLM prompts and provides statistics about file and directory structure, size of the extract, and token count. GitIngest can be used as a CLI tool on Linux and as a Python package for code integration. The tool is built using Tailwind CSS for frontend, FastAPI for backend framework, tiktoken for token estimation, and apianalytics.dev for simple analytics. Users can self-host GitIngest by building the Docker image and running the container. Contributions to the project are welcome, and the tool aims to be beginner-friendly for first-time contributors with a simple Python and HTML codebase.
rag-gpt
RAG-GPT is a tool that allows users to quickly launch an intelligent customer service system with Flask, LLM, and RAG. It includes frontend, backend, and admin console components. The tool supports cloud-based and local LLMs, enables deployment of conversational service robots in minutes, integrates diverse knowledge bases, offers flexible configuration options, and features an attractive user interface.

raglite
RAGLite is a Python toolkit for Retrieval-Augmented Generation (RAG) with PostgreSQL or SQLite. It offers configurable options for choosing LLM providers, database types, and rerankers. The toolkit is fast and permissive, utilizing lightweight dependencies and hardware acceleration. RAGLite provides features like PDF to Markdown conversion, multi-vector chunk embedding, optimal semantic chunking, hybrid search capabilities, adaptive retrieval, and improved output quality. It is extensible with a built-in Model Context Protocol server, customizable ChatGPT-like frontend, document conversion to Markdown, and evaluation tools. Users can configure RAGLite for various tasks like configuring, inserting documents, running RAG pipelines, computing query adapters, evaluating performance, running MCP servers, and serving frontends.
llama.vscode
llama.vscode is a local LLM-assisted text completion extension for Visual Studio Code. It provides auto-suggestions on input, allows accepting suggestions with shortcuts, and offers various features to enhance text completion. The extension is designed to be lightweight and efficient, enabling high-quality completions even on low-end hardware. Users can configure the scope of context around the cursor and control text generation time. It supports very large contexts and displays performance statistics for better user experience.
pear-landing-page
PearAI Landing Page is an open-source AI-powered code editor managed by Nang and Pan. It is built with Next.js, Vercel, Tailwind CSS, and TypeScript. The project requires setting up environment variables for proper configuration. Users can run the project locally by starting the development server and visiting the specified URL in the browser. Recommended extensions include Prettier, ESLint, and JavaScript and TypeScript Nightly. Contributions to the project are welcomed and appreciated.

openai-kotlin
OpenAI Kotlin API client is a Kotlin client for OpenAI's API with multiplatform and coroutines capabilities. It allows users to interact with OpenAI's API using Kotlin programming language. The client supports various features such as models, chat, images, embeddings, files, fine-tuning, moderations, audio, assistants, threads, messages, and runs. It also provides guides on getting started, chat & function call, file source guide, and assistants. Sample apps are available for reference, and troubleshooting guides are provided for common issues. The project is open-source and licensed under the MIT license, allowing contributions from the community.

lexido
Lexido is an innovative assistant for the Linux command line, designed to boost your productivity and efficiency. Powered by Gemini Pro 1.0 and utilizing the free API, Lexido offers smart suggestions for commands based on your prompts and importantly your current environment. Whether you're installing software, managing files, or configuring system settings, Lexido streamlines the process, making it faster and more intuitive.
SecureAI-Tools
SecureAI Tools is a private and secure AI tool that allows users to chat with AI models, chat with documents (PDFs), and run AI models locally. It comes with built-in authentication and user management, making it suitable for family members or coworkers. The tool is self-hosting optimized and provides necessary scripts and docker-compose files for easy setup in under 5 minutes. Users can customize the tool by editing the .env file and enabling GPU support for faster inference. SecureAI Tools also supports remote OpenAI-compatible APIs, with lower hardware requirements for using remote APIs only. The tool's features wishlist includes chat sharing, mobile-friendly UI, and support for more file types and markdown rendering.
browser
Lightpanda Browser is an open-source headless browser designed for fast web automation, AI agents, LLM training, scraping, and testing. It features ultra-low memory footprint, exceptionally fast execution, and compatibility with Playwright and Puppeteer through CDP. Built for performance, Lightpanda offers Javascript execution, support for Web APIs, and is optimized for minimal memory usage. It is a modern solution for web scraping and automation tasks, providing a lightweight alternative to traditional browsers like Chrome.
Fyin
Fyin is an open-source tool that serves as an alternative to Perplexity AI, allowing users to run it locally for faster answers. It features the ability to run locally using ollama or OpenAI API, a local VectorDB for fast search, quick searching, scraping & answering due to parallelism, configurable number of search results to parse, and local scraping of websites. The tool aims to provide a more efficient and customizable solution for obtaining answers through search and scraping functionalities.
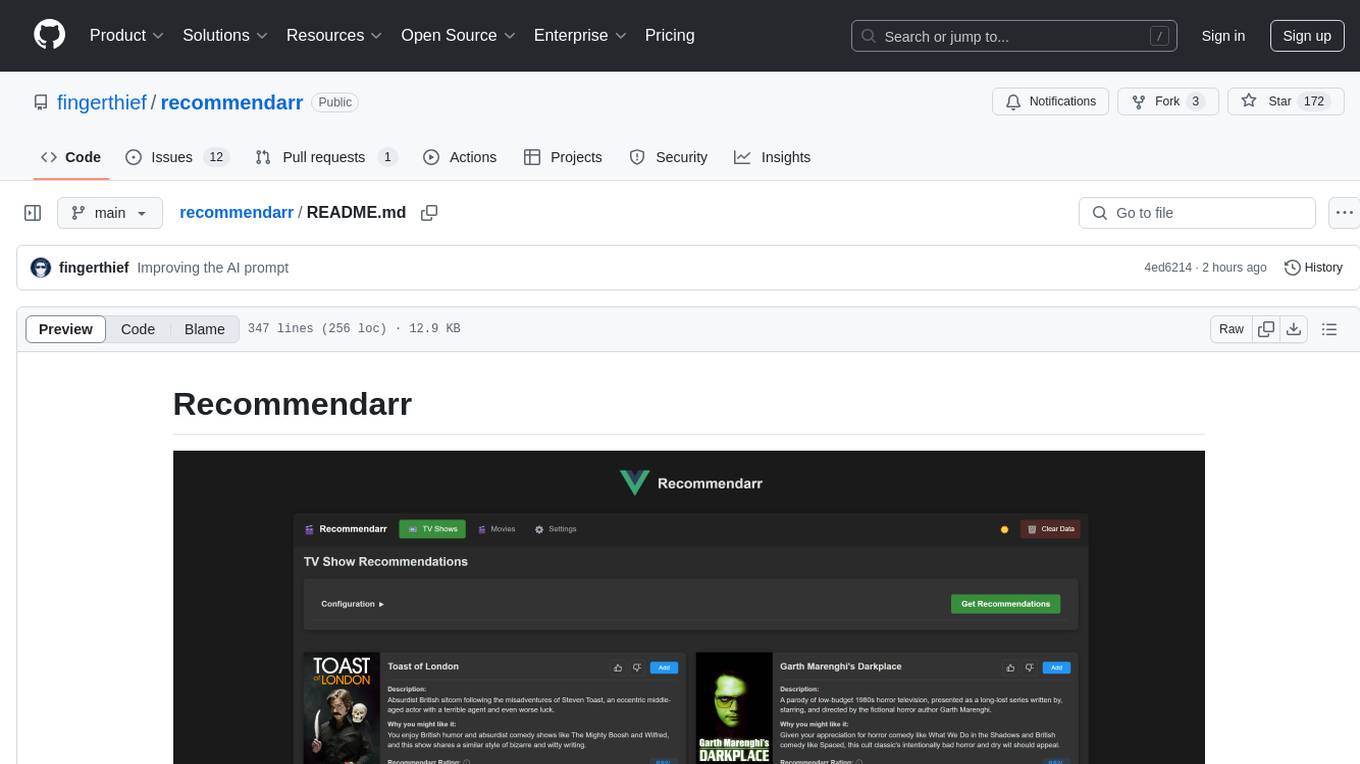
recommendarr
Recommendarr is a tool that generates personalized TV show and movie recommendations based on your Sonarr, Radarr, Plex, and Jellyfin libraries using AI. It offers AI-powered recommendations, media server integration, flexible AI support, watch history analysis, customization options, and dark/light mode toggle. Users can connect their media libraries and watch history services, configure AI service settings, and get personalized recommendations based on genre, language, and mood/vibe preferences. The tool works with any OpenAI-compatible API and offers various recommended models for different cost options and performance levels. It provides personalized suggestions, detailed information, filter options, watch history analysis, and one-click adding of recommended content to Sonarr/Radarr.
chunkr
Chunkr is an open-source document intelligence API that provides a production-ready service for document layout analysis, OCR, and semantic chunking. It allows users to convert PDFs, PPTs, Word docs, and images into RAG/LLM-ready chunks. The API offers features such as layout analysis, OCR with bounding boxes, structured HTML and markdown output, and VLM processing controls. Users can interact with Chunkr through a Python SDK, enabling them to upload documents, process them, and export results in various formats. The tool also supports self-hosted deployment options using Docker Compose or Kubernetes, with configurations for different AI models like OpenAI, Google AI Studio, and OpenRouter. Chunkr is dual-licensed under the GNU Affero General Public License v3.0 (AGPL-3.0) and a commercial license, providing flexibility for different usage scenarios.

agenticSeek
AgenticSeek is a voice-enabled AI assistant powered by DeepSeek R1 agents, offering a fully local alternative to cloud-based AI services. It allows users to interact with their filesystem, code in multiple languages, and perform various tasks autonomously. The tool is equipped with memory to remember user preferences and past conversations, and it can divide tasks among multiple agents for efficient execution. AgenticSeek prioritizes privacy by running entirely on the user's hardware without sending data to the cloud.
steel-browser
Steel is an open-source browser API designed for AI agents and applications, simplifying the process of building live web agents and browser automation tools. It serves as a core building block for a production-ready, containerized browser sandbox with features like stealth capabilities, text-to-markdown session management, UI for session viewing/debugging, and full browser control through popular automation frameworks. Steel allows users to control, run, and manage a production-ready browser environment via a REST API, offering features such as full browser control, session management, proxy support, extension support, debugging tools, anti-detection mechanisms, resource management, and various browser tools. It aims to streamline complex browsing tasks programmatically, enabling users to focus on their AI applications while Steel handles the underlying complexity.

PySpur
PySpur is a graph-based editor designed for LLM workflows, offering modular building blocks for easy workflow creation and debugging at node level. It allows users to evaluate final performance and promises self-improvement features in the future. PySpur is easy-to-hack, supports JSON configs for workflow graphs, and is lightweight with minimal dependencies, making it a versatile tool for workflow management in the field of AI and machine learning.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.
LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.