
orama-core
OramaCore is the database you need for your AI projects, answer engines, copilots, and search. It includes a fully-fledged full-text search engine, vector database, LLM interface, and many more utilities.
Stars: 128

OramaCore is a database designed for AI projects, answer engines, copilots, and search functionalities. It offers features such as a full-text search engine, vector database, LLM interface, and various utilities. The tool is currently under active development and not recommended for production use due to potential API changes. OramaCore aims to provide a comprehensive solution for managing data and enabling advanced AI capabilities in projects.
README:
🚧 Under active development. Do not use in production - APIs will change 🚧
OramaCore is the database you need for your AI projects, answer engines, copilots, and search.
It includes a fully-fledged full-text search engine, vector database, LLM interface, and many more utilities.
-
v0.1.0. ETA Jan 31st, 2025 (🚧 beta release)
- ✅ Full-text search
- ✅ Vector search
- ✅ Search filters
- ✅ Automatic embeddings generation
- ✅ Built-in multiple LLM inference setup
- ✅ Basic JavaScript integration
- ✅ Disk persistence
- ✅ Unified configuration
- ✅ Dockerfile for load testing in production environment
- 🚧 Vector compression
- 🚧 Benchmarks
-
v1.0.0. ETA Feb 28th, 2025 (🎉 production ready!)
- 🔜 Long-term user memory
- 🔜 Multi-node setup
- 🔜 Content expansion APIs
- 🔜 JavaScript API integration
- 🔜 Production-ready build
- 🔜 Geosearch
- 🔜 Zero-downtime upgrades
To run Orama Core locally, you need to have the following programming languages installed:
- Python >= 3.11
- Rust >= 1.83.0
The Rust part of Orama Core communicates with Python via gRPC. So you'll also need to install a protobuf compiler:
apt-get install protobuf-compilerAfter that, just install the dependencies:
cargo buildcd ./src/ai_server && pip install -r requirements.txtAn NVIDIA GPU is highly recommended for running the application.
How to run:
RUST_LOG=trace PROTOC=/usr/bin/protoc cargo run --bin oramacoreor, for release mode:
RUST_LOG=trace PROTOC=/usr/bin/protoc cargo run --bin oramacore --releaseThe configuration file is located at config.jsonc and contains an example of the configuration.
You can persist the database status on disk by runnng the following commands:
curl 'http://localhost:8080/v0/reader/dump_all' -X POSTcurl 'http://localhost:8080/v0/writer/dump_all' -X POSTAfter killing and restarting the server, you'll find your data back in memory.
To run the tests, use:
cargo testInstall hurl:
cargo install hurl
Run the tests:
hurl --very-verbose --test --variables-file api-test.hurl.property api-test.hurl
hurl --very-verbose --test --variables-file api-test.hurl.property embedding-api-test.hurl
NB: you need to have the server running before running the tests.
OramaCore integrates Grafana and Prometheus for monitoring and collenting metrics.
Make sure your OramaCore configuration enables the prometheus exporter (http.with_prometheus: true).
Change the otel/prometheus.yml file to match your IP configuration and run the following command:
docker run --rm --name prometheus -d -p 9090:9090 -v $(pwd)/otel/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
docker run --rm --name grafana -d -p 3000:3000 grafana/grafana
We have a Grafana dashboard available at otel/OramaCore Dashboard.json. You can import it into your Grafana instance.
NB: the default username and password for Grafana are admin and admin.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for orama-core
Similar Open Source Tools
orama-core
OramaCore is a database designed for AI projects, answer engines, copilots, and search functionalities. It offers features such as a full-text search engine, vector database, LLM interface, and various utilities. The tool is currently under active development and not recommended for production use due to potential API changes. OramaCore aims to provide a comprehensive solution for managing data and enabling advanced AI capabilities in projects.
oxy
Oxy is an open-source framework for building comprehensive agentic analytics systems grounded in deterministic execution principles. Written in Rust and declarative by design, Oxy provides the foundational components needed to transform AI-driven data analysis into reliable, production-ready systems through structured primitives, semantic understanding, and predictable execution.
xlang
XLang™ is a cutting-edge language designed for AI and IoT applications, offering exceptional dynamic and high-performance capabilities. It excels in distributed computing and seamless integration with popular languages like C++, Python, and JavaScript. Notably efficient, running 3 to 5 times faster than Python in AI and deep learning contexts. Features optimized tensor computing architecture for constructing neural networks through tensor expressions. Automates tensor data flow graph generation and compilation for specific targets, enhancing GPU performance by 6 to 10 times in CUDA environments.
middleware
Middleware is an open-source engineering management tool that helps engineering leaders measure and analyze team effectiveness using DORA metrics. It integrates with CI/CD tools, automates DORA metric collection and analysis, visualizes key performance indicators, provides customizable reports and dashboards, and integrates with project management platforms. Users can set up Middleware using Docker or manually, generate encryption keys, set up backend and web servers, and access the application to view DORA metrics. The tool calculates DORA metrics using GitHub data, including Deployment Frequency, Lead Time for Changes, Mean Time to Restore, and Change Failure Rate. Middleware aims to provide DORA metrics to users based on their Git data, simplifying the process of tracking software delivery performance and operational efficiency.
manifold
Manifold is a powerful platform for workflow automation using AI models. It supports text generation, image generation, and retrieval-augmented generation, integrating seamlessly with popular AI endpoints. Additionally, Manifold provides robust semantic search capabilities using PGVector combined with the SEFII engine. It is under active development and not production-ready.
aisdk-prompt-optimizer
AISDK Prompt Optimizer is an open-source tool designed to transform AI interactions by optimizing prompts. It utilizes the GEPA reflective optimizer to evolve textual components of AI systems, providing features such as reflective prompt mutation, rich textual feedback, and Pareto-based selection. Users can teach their AI desired behaviors, collect ideal samples, run optimization to generate optimized prompts, and deploy the results in their applications. The tool leverages advanced optimization algorithms to guide AI through interactive conversations and refine prompt candidates for improved performance.
pipecat-flows
Pipecat Flows is a framework designed for building structured conversations in AI applications. It allows users to create both predefined conversation paths and dynamically generated flows, handling state management and LLM interactions. The framework includes a Python module for building conversation flows and a visual editor for designing and exporting flow configurations. Pipecat Flows is suitable for scenarios such as customer service scripts, intake forms, personalized experiences, and complex decision trees.
batteries-included
Batteries Included is an all-in-one platform for building and running modern applications, simplifying cloud infrastructure complexity. It offers production-ready capabilities through an intuitive interface, focusing on automation, security, and enterprise-grade features. The platform includes databases like PostgreSQL and Redis, AI/ML capabilities with Jupyter notebooks, web services deployment, security features like SSL/TLS management, and monitoring tools like Grafana dashboards. Batteries Included is designed to streamline infrastructure setup and management, allowing users to concentrate on application development without dealing with complex configurations.

mattermost-plugin-agents
The Mattermost Agents Plugin integrates AI capabilities directly into your Mattermost workspace, allowing users to run local LLMs on their infrastructure or connect to cloud providers. It offers multiple AI assistants with specialized personalities, thread and channel summarization, action item extraction, meeting transcription, semantic search, smart reactions, direct conversations with AI assistants, and flexible LLM support. The plugin comes with comprehensive documentation, installation instructions, system requirements, and development guidelines for users to interact with AI features and configure LLM providers.
frontend
Nuclia frontend apps and libraries repository contains various frontend applications and libraries for the Nuclia platform. It includes components such as Dashboard, Widget, SDK, Sistema (design system), NucliaDB admin, CI/CD Deployment, and Maintenance page. The repository provides detailed instructions on installation, dependencies, and usage of these components for both Nuclia employees and external developers. It also covers deployment processes for different components and tools like ArgoCD for monitoring deployments and logs. The repository aims to facilitate the development, testing, and deployment of frontend applications within the Nuclia ecosystem.
langstream
LangStream is a tool for natural language processing tasks, providing a CLI for easy installation and usage. Users can try sample applications like Chat Completions and create their own applications using the developer documentation. It supports running on Kubernetes for production-ready deployment, with support for various Kubernetes distributions and external components like Apache Kafka or Apache Pulsar cluster. Users can deploy LangStream locally using minikube and manage the cluster with mini-langstream. Development requirements include Docker, Java 17, Git, Python 3.11+, and PIP, with the option to test local code changes using mini-langstream.
mycoder
An open-source mono-repository containing the MyCoder agent and CLI. It leverages Anthropic's Claude API for intelligent decision making, has a modular architecture with various tool categories, supports parallel execution with sub-agents, can modify code by writing itself, features a smart logging system for clear output, and is human-compatible using README.md, project files, and shell commands to build its own context.

gitingest
GitIngest is a tool that allows users to turn any Git repository into a prompt-friendly text ingest for LLMs. It provides easy code context by generating a text digest from a git repository URL or directory. The tool offers smart formatting for optimized output format for LLM prompts and provides statistics about file and directory structure, size of the extract, and token count. GitIngest can be used as a CLI tool on Linux and as a Python package for code integration. The tool is built using Tailwind CSS for frontend, FastAPI for backend framework, tiktoken for token estimation, and apianalytics.dev for simple analytics. Users can self-host GitIngest by building the Docker image and running the container. Contributions to the project are welcome, and the tool aims to be beginner-friendly for first-time contributors with a simple Python and HTML codebase.
svelte-bench
SvelteBench is an LLM benchmark tool for evaluating Svelte components generated by large language models. It supports multiple LLM providers such as OpenAI, Anthropic, Google, and OpenRouter. Users can run predefined test suites to verify the functionality of the generated components. The tool allows configuration of API keys for different providers and offers debug mode for faster development. Users can provide a context file to improve component generation. Benchmark results are saved in JSON format for analysis and visualization.
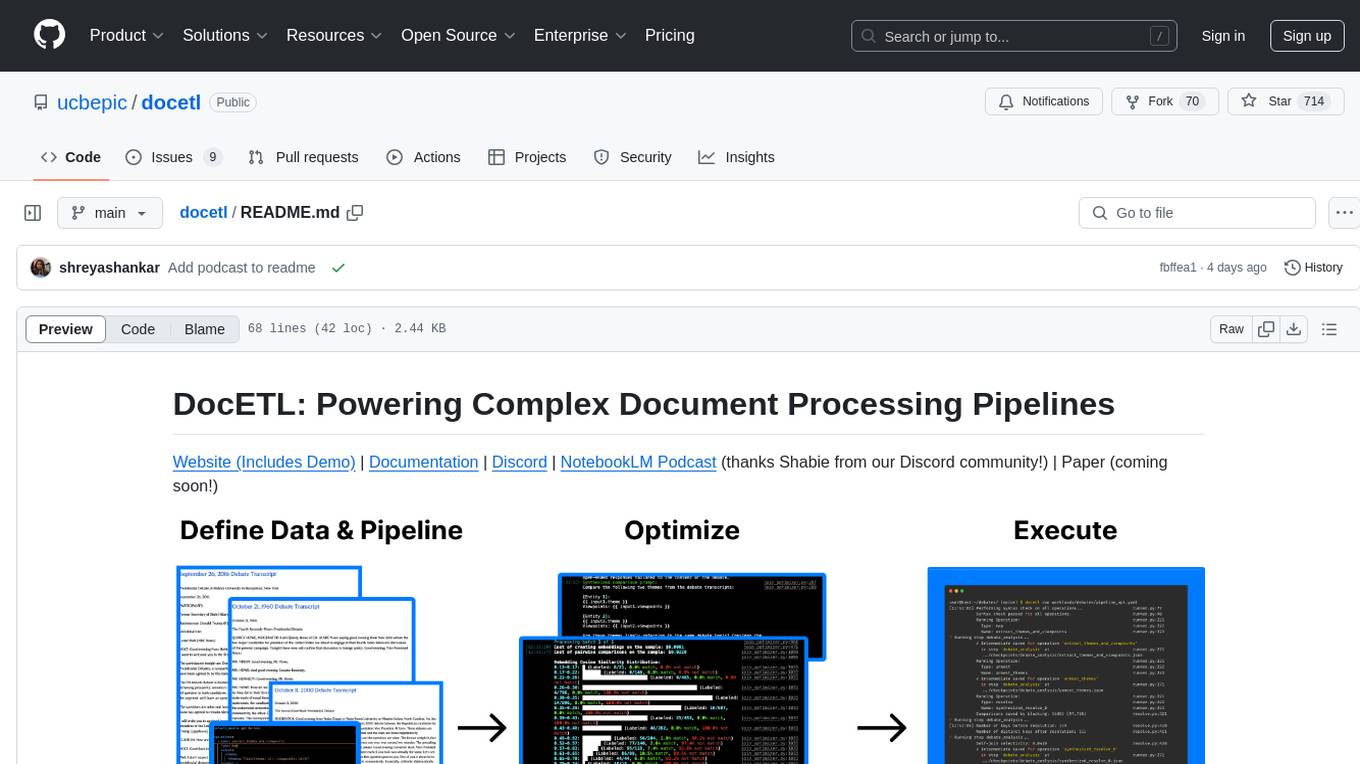
docetl
DocETL is a tool for creating and executing data processing pipelines, especially suited for complex document processing tasks. It offers a low-code, declarative YAML interface to define LLM-powered operations on complex data. Ideal for maximizing correctness and output quality for semantic processing on a collection of data, representing complex tasks via map-reduce, maximizing LLM accuracy, handling long documents, and automating task retries based on validation criteria.
cortex
Nitro is a high-efficiency C++ inference engine for edge computing, powering Jan. It is lightweight and embeddable, ideal for product integration. The binary of nitro after zipped is only ~3mb in size with none to minimal dependencies (if you use a GPU need CUDA for example) make it desirable for any edge/server deployment.
For similar tasks
blockoli
Blockoli is a high-performance tool for code indexing, embedding generation, and semantic search tool for use with LLMs. It is built in Rust and uses the ASTerisk crate for semantic code parsing. Blockoli allows you to efficiently index, store, and search code blocks and their embeddings using vector similarity. Key features include indexing code blocks from a codebase, generating vector embeddings for code blocks using a pre-trained model, storing code blocks and their embeddings in a SQLite database, performing efficient similarity search on code blocks using vector embeddings, providing a REST API for easy integration with other tools and platforms, and being fast and memory-efficient due to its implementation in Rust.

client-js
The Mistral JavaScript client is a library that allows you to interact with the Mistral AI API. With this client, you can perform various tasks such as listing models, chatting with streaming, chatting without streaming, and generating embeddings. To use the client, you can install it in your project using npm and then set up the client with your API key. Once the client is set up, you can use it to perform the desired tasks. For example, you can use the client to chat with a model by providing a list of messages. The client will then return the response from the model. You can also use the client to generate embeddings for a given input. The embeddings can then be used for various downstream tasks such as clustering or classification.
fastllm
A collection of LLM services you can self host via docker or modal labs to support your applications development. The goal is to provide docker containers or modal labs deployments of common patterns when using LLMs and endpoints to integrate easily with existing codebases using the openai api. It supports GPT4all's embedding api, JSONFormer api for chat completion, Cross Encoders based on sentence transformers, and provides documentation using MkDocs.

openai-kotlin
OpenAI Kotlin API client is a Kotlin client for OpenAI's API with multiplatform and coroutines capabilities. It allows users to interact with OpenAI's API using Kotlin programming language. The client supports various features such as models, chat, images, embeddings, files, fine-tuning, moderations, audio, assistants, threads, messages, and runs. It also provides guides on getting started, chat & function call, file source guide, and assistants. Sample apps are available for reference, and troubleshooting guides are provided for common issues. The project is open-source and licensed under the MIT license, allowing contributions from the community.

azure-search-vector-samples
This repository provides code samples in Python, C#, REST, and JavaScript for vector support in Azure AI Search. It includes demos for various languages showcasing vectorization of data, creating indexes, and querying vector data. Additionally, it offers tools like Azure AI Search Lab for experimenting with AI-enabled search scenarios in Azure and templates for deploying custom chat-with-your-data solutions. The repository also features documentation on vector search, hybrid search, creating and querying vector indexes, and REST API references for Azure AI Search and Azure OpenAI Service.
llm
LLM is a CLI utility and Python library for interacting with Large Language Models, both via remote APIs and models that can be installed and run on your own machine. It allows users to run prompts from the command-line, store results in SQLite, generate embeddings, and more. The tool supports self-hosted language models via plugins and provides access to remote and local models. Users can install plugins to access models by different providers, including models that can be installed and run on their own device. LLM offers various options for running Mistral models in the terminal and enables users to start chat sessions with models. Additionally, users can use a system prompt to provide instructions for processing input to the tool.
GenAI-Showcase
The Generative AI Use Cases Repository showcases a wide range of applications in generative AI, including Retrieval-Augmented Generation (RAG), AI Agents, and industry-specific use cases. It provides practical notebooks and guidance on utilizing frameworks such as LlamaIndex and LangChain, and demonstrates how to integrate models from leading AI research companies like Anthropic and OpenAI.

warc-gpt
WARC-GPT is an experimental retrieval augmented generation pipeline for web archive collections. It allows users to interact with WARC files, extract text, generate text embeddings, visualize embeddings, and interact with a web UI and API. The tool is highly customizable, supporting various LLMs, providers, and embedding models. Users can configure the application using environment variables, ingest WARC files, start the server, and interact with the web UI and API to search for content and generate text completions. WARC-GPT is designed for exploration and experimentation in exploring web archives using AI.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.