
BentoML
The easiest way to serve AI apps and models - Build Model Inference APIs, Job queues, LLM apps, Multi-model pipelines, and more!
Stars: 7561

BentoML is an open-source model serving library for building performant and scalable AI applications with Python. It comes with everything you need for serving optimization, model packaging, and production deployment.
README:
🍱 Build model inference APIs and multi-model serving systems with any open-source or custom AI models. 👉 Join our Slack community!

![]()
BentoML is a Python library for building online serving systems optimized for AI apps and model inference.
- 🍱 Easily build APIs for Any AI/ML Model. Turn any model inference script into a REST API server with just a few lines of code and standard Python type hints.
- 🐳 Docker Containers made simple. No more dependency hell! Manage your environments, dependencies and model versions with a simple config file. BentoML automatically generates Docker images, ensures reproducibility, and simplifies how you deploy to different environments.
- 🧭 Maximize CPU/GPU utilization. Build high performance inference APIs leveraging built-in serving optimization features like dynamic batching, model parallelism, multi-stage pipeline and multi-model inference-graph orchestration.
- 👩💻 Fully customizable. Easily implement your own APIs or task queues, with custom business logic, model inference and multi-model composition. Supports any ML framework, modality, and inference runtime.
- 🚀 Ready for Production. Develop, run and debug locally. Seamlessly deploy to production with Docker containers or BentoCloud.
Install BentoML:
# Requires Python≥3.9
pip install -U bentoml
Define APIs in a service.py file.
import bentoml
@bentoml.service(
image=bentoml.images.PythonImage(python_version="3.11").python_packages("torch", "transformers"),
)
class Summarization:
def __init__(self) -> None:
import torch
from transformers import pipeline
device = "cuda" if torch.cuda.is_available() else "cpu"
self.pipeline = pipeline('summarization', device=device)
@bentoml.api(batchable=True)
def summarize(self, texts: list[str]) -> list[str]:
results = self.pipeline(texts)
return [item['summary_text'] for item in results]Install PyTorch and Transformers packages to your Python virtual environment.
pip install torch transformers # additional dependencies for local runRun the service code locally (serving at http://localhost:3000 by default):
bentoml serveYou should expect to see the following output.
[INFO] [cli] Starting production HTTP BentoServer from "service:Summarization" listening on http://localhost:3000 (Press CTRL+C to quit)
[INFO] [entry_service:Summarization:1] Service Summarization initialized
Now you can run inference from your browser at http://localhost:3000 or with a Python script:
import bentoml
with bentoml.SyncHTTPClient('http://localhost:3000') as client:
summarized_text: str = client.summarize([bentoml.__doc__])[0]
print(f"Result: {summarized_text}")Run bentoml build to package necessary code, models, dependency configs into a Bento - the standardized deployable artifact in BentoML:
bentoml buildEnsure Docker is running. Generate a Docker container image for deployment:
bentoml containerize summarization:latestRun the generated image:
docker run --rm -p 3000:3000 summarization:latestBentoCloud provides compute infrastructure for rapid and reliable GenAI adoption. It helps speed up your BentoML development process leveraging cloud compute resources, and simplify how you deploy, scale and operate BentoML in production.
Sign up for BentoCloud for personal access; for enterprise use cases, contact our team.
# After signup, run the following command to create an API token:
bentoml cloud login
# Deploy from current directory:
bentoml deploy
For detailed explanations, read the Hello World example.
- LLMs: Llama 3.2, Mistral, DeepSeek Distil, and more.
- Image Generation: Stable Diffusion 3 Medium, Stable Video Diffusion, Stable Diffusion XL Turbo, ControlNet, and LCM LoRAs.
- Embeddings: SentenceTransformers and ColPali
- Audio: ChatTTS, XTTS, WhisperX, Bark
- Computer Vision: YOLO and ResNet
- Advanced examples: Function calling, LangGraph, CrewAI
Check out the full list for more sample code and usage.
- Model composition
- Workers and model parallelization
- Adaptive batching
- GPU inference
- Distributed serving systems
- Concurrency and autoscaling
- Model loading and Model Store
- Observability
- BentoCloud deployment
See Documentation for more tutorials and guides.
Get involved and join our Community Slack 💬, where thousands of AI/ML engineers help each other, contribute to the project, and talk about building AI products.
To report a bug or suggest a feature request, use GitHub Issues.
There are many ways to contribute to the project:
- Report bugs and "Thumbs up" on issues that are relevant to you.
- Investigate issues and review other developers' pull requests.
- Contribute code or documentation to the project by submitting a GitHub pull request.
- Check out the Contributing Guide and Development Guide to learn more.
- Share your feedback and discuss roadmap plans in the
#bentoml-contributorschannel here.
Thanks to all of our amazing contributors!
The BentoML framework collects anonymous usage data that helps our community improve the product. Only BentoML's internal API calls are being reported. This excludes any sensitive information, such as user code, model data, model names, or stack traces. Here's the code used for usage tracking. You can opt-out of usage tracking by the --do-not-track CLI option:
bentoml [command] --do-not-trackOr by setting the environment variable:
export BENTOML_DO_NOT_TRACK=TrueFor Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for BentoML
Similar Open Source Tools
BentoML
BentoML is an open-source model serving library for building performant and scalable AI applications with Python. It comes with everything you need for serving optimization, model packaging, and production deployment.

labo
LABO is a time series forecasting and analysis framework that integrates pre-trained and fine-tuned LLMs with multi-domain agent-based systems. It allows users to create and tune agents easily for various scenarios, such as stock market trend prediction and web public opinion analysis. LABO requires a specific runtime environment setup, including system requirements, Python environment, dependency installations, and configurations. Users can fine-tune their own models using LABO's Low-Rank Adaptation (LoRA) for computational efficiency and continuous model updates. Additionally, LABO provides a Python library for building model training pipelines and customizing agents for specific tasks.

deep-research
Deep Research is a lightning-fast tool that uses powerful AI models to generate comprehensive research reports in just a few minutes. It leverages advanced 'Thinking' and 'Task' models, combined with an internet connection, to provide fast and insightful analysis on various topics. The tool ensures privacy by processing and storing all data locally. It supports multi-platform deployment, offers support for various large language models, web search functionality, knowledge graph generation, research history preservation, local and server API support, PWA technology, multi-key payload support, multi-language support, and is built with modern technologies like Next.js and Shadcn UI. Deep Research is open-source under the MIT License.

langmanus
LangManus is a community-driven AI automation framework that combines language models with specialized tools for tasks like web search, crawling, and Python code execution. It implements a hierarchical multi-agent system with agents like Coordinator, Planner, Supervisor, Researcher, Coder, Browser, and Reporter. The framework supports LLM integration, search and retrieval tools, Python integration, workflow management, and visualization. LangManus aims to give back to the open-source community and welcomes contributions in various forms.
Memori
Memori is a memory fabric designed for enterprise AI that seamlessly integrates into existing software and infrastructure. It is agnostic to LLM, datastore, and framework, providing support for major foundational models and databases. With features like vectorized memories, in-memory semantic search, and a knowledge graph, Memori simplifies the process of attributing LLM interactions and managing sessions. It offers Advanced Augmentation for enhancing memories at different levels and supports various platforms, frameworks, database integrations, and datastores. Memori is designed to reduce development overhead and provide efficient memory management for AI applications.

djl
Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning. It is designed to be easy to get started with and simple to use for Java developers. DJL provides a native Java development experience and allows users to integrate machine learning and deep learning models with their Java applications. The framework is deep learning engine agnostic, enabling users to switch engines at any point for optimal performance. DJL's ergonomic API interface guides users with best practices to accomplish deep learning tasks, such as running inference and training neural networks.

ControlLLM
ControlLLM is a framework that empowers large language models to leverage multi-modal tools for solving complex real-world tasks. It addresses challenges like ambiguous user prompts, inaccurate tool selection, and inefficient tool scheduling by utilizing a task decomposer, a Thoughts-on-Graph paradigm, and an execution engine with a rich toolbox. The framework excels in tasks involving image, audio, and video processing, showcasing superior accuracy, efficiency, and versatility compared to existing methods.

arbigent
Arbigent (Arbiter-Agent) is an AI agent testing framework designed to make AI agent testing practical for modern applications. It addresses challenges faced by traditional UI testing frameworks and AI agents by breaking down complex tasks into smaller, dependent scenarios. The framework is customizable for various AI providers, operating systems, and form factors, empowering users with extensive customization capabilities. Arbigent offers an intuitive UI for scenario creation and a powerful code interface for seamless test execution. It supports multiple form factors, optimizes UI for AI interaction, and is cost-effective by utilizing models like GPT-4o mini. With a flexible code interface and open-source nature, Arbigent aims to revolutionize AI agent testing in modern applications.
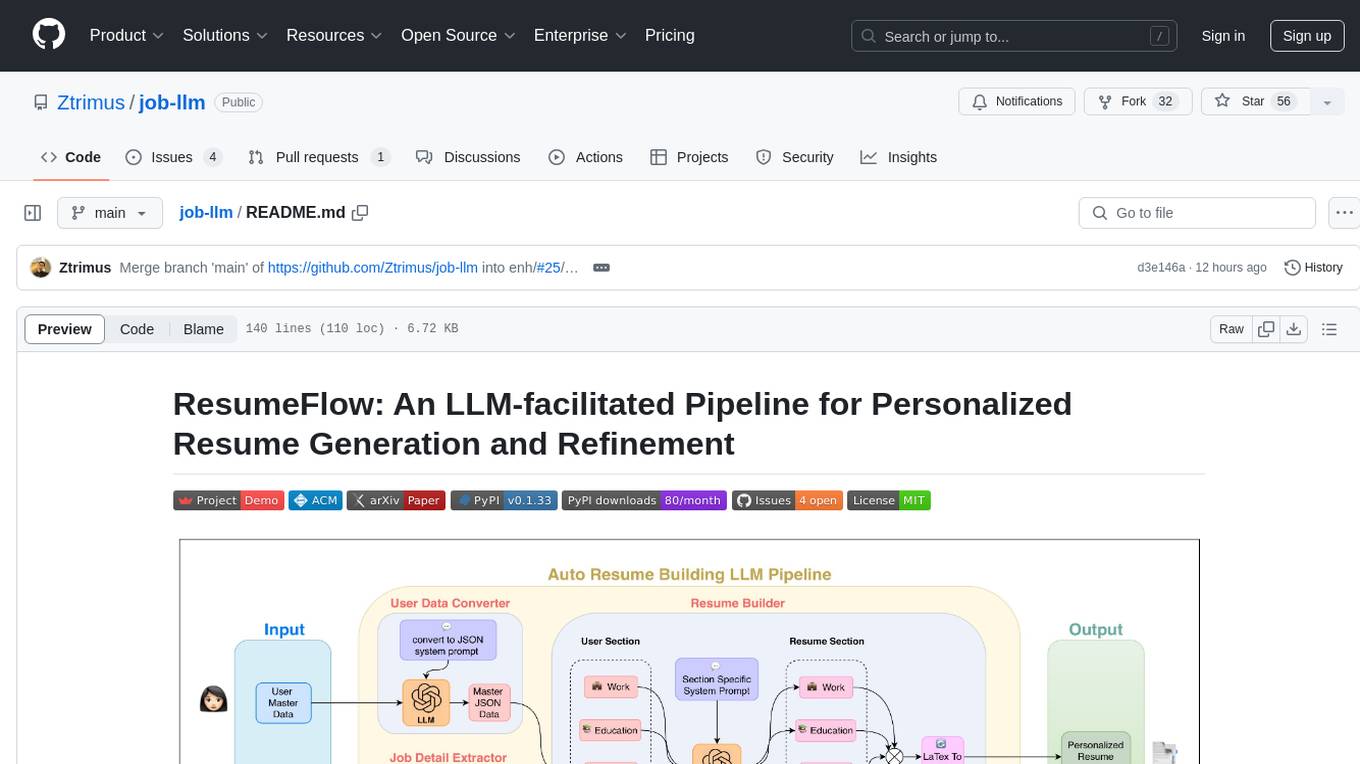
job-llm
ResumeFlow is an automated system utilizing Large Language Models (LLMs) to streamline the job application process. It aims to reduce human effort in various steps of job hunting by integrating LLM technology. Users can access ResumeFlow as a web tool, install it as a Python package, or download the source code. The project focuses on leveraging LLMs to automate tasks such as resume generation and refinement, making job applications smoother and more efficient.
fastagency
FastAgency is an open-source framework designed to accelerate the transition from prototype to production for multi-agent AI workflows. It provides a unified programming interface for deploying agentic workflows written in AG2 agentic framework in both development and productional settings. With features like seamless external API integration, a Tester Class for continuous integration, and a Command-Line Interface (CLI) for orchestration, FastAgency streamlines the deployment process, saving time and effort while maintaining flexibility and performance. Whether orchestrating complex AI agents or integrating external APIs, FastAgency helps users quickly transition from concept to production, reducing development cycles and optimizing multi-agent systems.

atropos
Atropos is a robust and scalable framework for Reinforcement Learning Environments with Large Language Models (LLMs). It provides a flexible platform to accelerate LLM-based RL research across diverse interactive settings. Atropos supports multi-turn and asynchronous RL interactions, integrates with various inference APIs, offers a standardized training interface for experimenting with different RL algorithms, and allows for easy scalability by launching more environment instances. The framework manages diverse environment types concurrently for heterogeneous, multi-modal training.
fastagency
FastAgency is a powerful tool that leverages the AutoGen framework to quickly build applications with multi-agent workflows. It supports various interfaces like ConsoleUI and MesopUI, allowing users to create interactive applications. The tool enables defining workflows between agents, such as students and teachers, and summarizing conversations. FastAgency aims to expand its capabilities by integrating with additional agentic frameworks like CrewAI, providing more options for workflow definition and AI tool integration.

codebox-api
CodeBox is a cloud infrastructure tool designed for running Python code in an isolated environment. It also offers simple file input/output capabilities and will soon support vector database operations. Users can install CodeBox using pip and utilize it by setting up an API key. The tool allows users to execute Python code snippets and interact with the isolated environment. CodeBox is currently in early development stages and requires manual handling for certain operations like refunds and cancellations. The tool is open for contributions through issue reporting and pull requests. It is licensed under MIT and can be contacted via email at [email protected].

helix-db
HelixDB is a database designed specifically for AI applications, providing a single platform to manage all components needed for AI applications. It supports graph + vector data model and also KV, documents, and relational data. Key features include built-in tools for MCP, embeddings, knowledge graphs, RAG, security, logical isolation, and ultra-low latency. Users can interact with HelixDB using the Helix CLI tool and SDKs in TypeScript and Python. The roadmap includes features like organizational auth, server code improvements, 3rd party integrations, educational content, and binary quantisation for better performance. Long term projects involve developing in-house tools for knowledge graph ingestion, graph-vector storage engine, and network protocol & serdes libraries.
nous
Nous is an open-source TypeScript platform for autonomous AI agents and LLM based workflows. It aims to automate processes, support requests, review code, assist with refactorings, and more. The platform supports various integrations, multiple LLMs/services, CLI and web interface, human-in-the-loop interactions, flexible deployment options, observability with OpenTelemetry tracing, and specific agents for code editing, software engineering, and code review. It offers advanced features like reasoning/planning, memory and function call history, hierarchical task decomposition, and control-loop function calling options. Nous is designed to be a flexible platform for the TypeScript community to expand and support different use cases and integrations.

RainbowGPT
RainbowGPT is a versatile tool that offers a range of functionalities, including Stock Analysis for financial decision-making, MySQL Management for database navigation, and integration of AI technologies like GPT-4 and ChatGlm3. It provides a user-friendly interface suitable for all skill levels, ensuring seamless information flow and continuous expansion of emerging technologies. The tool enhances adaptability, creativity, and insight, making it a valuable asset for various projects and tasks.
For similar tasks
agent-os
The Agent OS is an experimental framework and runtime to build sophisticated, long running, and self-coding AI agents. We believe that the most important super-power of AI agents is to write and execute their own code to interact with the world. But for that to work, they need to run in a suitable environment—a place designed to be inhabited by agents. The Agent OS is designed from the ground up to function as a long-term computing substrate for these kinds of self-evolving agents.
AISystem
This open-source project, also known as **Deep Learning System** or **AI System (AISys)**, aims to explore and learn about the system design of artificial intelligence and deep learning. The project is centered around the full-stack content of AI systems that ZOMI has accumulated,整理, and built during his work. The goal is to collaborate with all friends who are interested in AI open-source projects to jointly promote learning and discussion.

skypilot
SkyPilot is a framework for running LLMs, AI, and batch jobs on any cloud, offering maximum cost savings, highest GPU availability, and managed execution. SkyPilot abstracts away cloud infra burdens: - Launch jobs & clusters on any cloud - Easy scale-out: queue and run many jobs, automatically managed - Easy access to object stores (S3, GCS, R2) SkyPilot maximizes GPU availability for your jobs: * Provision in all zones/regions/clouds you have access to (the _Sky_), with automatic failover SkyPilot cuts your cloud costs: * Managed Spot: 3-6x cost savings using spot VMs, with auto-recovery from preemptions * Optimizer: 2x cost savings by auto-picking the cheapest VM/zone/region/cloud * Autostop: hands-free cleanup of idle clusters SkyPilot supports your existing GPU, TPU, and CPU workloads, with no code changes.
BentoML
BentoML is an open-source model serving library for building performant and scalable AI applications with Python. It comes with everything you need for serving optimization, model packaging, and production deployment.

council
Council is an open-source platform designed for the rapid development and deployment of customized generative AI applications using teams of agents. It extends the LLM tool ecosystem by providing advanced control flow and scalable oversight for AI agents. Users can create sophisticated agents with predictable behavior by leveraging Council's powerful approach to control flow using Controllers, Filters, Evaluators, and Budgets. The framework allows for automated routing between agents, comparing, evaluating, and selecting the best results for a task. Council aims to facilitate packaging and deploying agents at scale on multiple platforms while enabling enterprise-grade monitoring and quality control.

LazyLLM
LazyLLM is a low-code development tool for building complex AI applications with multiple agents. It assists developers in building AI applications at a low cost and continuously optimizing their performance. The tool provides a convenient workflow for application development and offers standard processes and tools for various stages of application development. Users can quickly prototype applications with LazyLLM, analyze bad cases with scenario task data, and iteratively optimize key components to enhance the overall application performance. LazyLLM aims to simplify the AI application development process and provide flexibility for both beginners and experts to create high-quality applications.

spring-ai-alibaba
Spring AI Alibaba is an AI application framework for Java developers that seamlessly integrates with Alibaba Cloud QWen LLM services and cloud-native infrastructures. It provides features like support for various AI models, high-level AI agent abstraction, function calling, and RAG support. The framework aims to simplify the development, evaluation, deployment, and observability of AI native Java applications. It offers open-source framework and ecosystem integrations to support features like prompt template management, event-driven AI applications, and more.
AimRT
AimRT is a basic runtime framework for modern robotics, developed in modern C++ with lightweight and easy deployment. It integrates research and development for robot applications in various deployment scenarios, providing debugging tools and observability support. AimRT offers a plug-in development interface compatible with ROS2, HTTP, Grpc, and other ecosystems for progressive system upgrades.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.