
SciPIP
The official repository for the Scientific Paper Idea Proposer (SciPIP)
Stars: 60
SciPIP is a scientific paper idea generation tool powered by a large language model (LLM) designed to assist researchers in quickly generating novel research ideas. It conducts a literature review based on user-provided background information and generates fresh ideas for potential studies. The tool is designed to help researchers in various fields by providing a GUI environment for idea generation, supporting NLP, multimodal, and CV fields, and allowing users to interact with the tool through a web app or terminal. SciPIP uses Neo4j as its database and provides functionalities for generating new ideas, fetching papers, and constructing the database.
README:



![]()
SciPIP is a scientific paper idea generation tool powered by a large language model (LLM) designed to assist researchers in quickly generating novel research ideas. Based on the background information provided by the user, SciPIP first conducts a literature review to identify relevant research, then generates fresh ideas for potential studies.

🤗 Try it on the Hugging Face: https://huggingface.co/spaces/lihuigu/SciPIP (The demo uses the old version code temporally and will be updated soon.)
- [x] Idea generation in a GUI enviroment (web app).
- [x] Idea generation for the NLP and multimodal field.
- [x] Idea generation for the CV field.
- [ ] Idea generation for other fields.
- [x] Release the Huggingface demo.
- [x] Support DeepSeek-v3 as an backend, now. 🎉 🎉 🎉
The following enviroments are tested under Ubuntu 22.04 with python>=3.10.3.
-
Install essential packages, feel free to copy and paste the following commans into your terminal. After that, you can visit your Neo4j databse in a browser.
## Install git-lfs curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash sudo apt install git-lfs ## Create new conda environment scipip conda env create -f environment.yml conda activate scipip ## Install Neo4j database sudo apt install -y openjdk-17-jre # Install Neo4j required JDK # cd ~/Downloads # or /your/path/to/download/Neo4j wget http://dist.neo4j.org/neo4j-community-5.25.1-unix.tar.gz tar -xvf neo4j-community-5.25.1-unix.tar.gz ## Start Neo4j cd ./neo4j-community-5.25.1 # Uncomment server.default_listen_address=0.0.0.0 in conf/neo4j.conf to visit Neo4j through a browser sed -i 's/# server.default_listen_address=0.0.0.0/server.default_listen_address=0.0.0.0/g' ./conf/neo4j.conf ./bin/neo4j start # Default URL for neo4j is "http://127.0.0.1:7474" # Default URI for ner4j is "bolt://127.0.0.1:7687" # Default username and password for neo4j database are both "neo4j" # !![IMPORTANT] You must visit "http://127.0.0.1:7474" and change the default password before next step. It is because Neo4j does not permit running with a default password.
-
Clone this repository (SciPIP) and edit the configuration files. Specifically, LLMs' API token and the Neo4j' username/password are need configuring, and we have provided the template.
## Clone our repository git clone [email protected]:cheerss/SciPIP.git && cd SciPIP ## Edit scripts/env.sh # Must be corrected: NEO4J_USERNAME / NEO4J_PASSWD / MODEL_API_KEY / MODEL_URL # Others are optional ## source env source scripts/env.sh
-
Prepare the literature database
- Download the literature data from google_drive or baidu disk. Replace the
/your/path/neo4j-community-5.25.1/datafolder with our provideddatafolder, which contains literature of CV, NLP, ML, etc. - [Optional] Prepare the embedding model. Our algorithm uses jina-embedding v3 and will automatically download it from Huggingface the first time the program is run. However, if you're concerned about potential download failures due to network issues, you can download it in advance and place it in the specified directory.
cd /root/path/of/SciPIP && mkdir -p assets/model/ git clone https://huggingface.co/jinaai/jina-embeddings-v3 assets/model
- Download the literature data from google_drive or baidu disk. Replace the
streamlit run app.py
# OR
python -m streamlit run app.pyThen, visit http://localhost:8501 in your browser with an interactive enviroment.
1. Generate new idea
Input your backgound in assets/data/test_background.json
python src/generator.py new-idea --brainstorm-mode mode_c --use-inspiration True --num 2
Results dump in assets/output_idea/output-file.json.
SciPIP uses Neo4j as its database. You can directly import the provided data or add your own research papers.ddddddsfasdfldsafkldsjfdkls
wget https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.7.1/en_core_web_sm-3.7.1-py3-none-any.whl
pip install en_core_web_sm-3.7.1-py3-none-any.whl
The directory for storing papers can be modified in the pdf_cached field of configs/datasets.yaml.
1. Generate json list
python src/paper_manager.py crawling --year all --venue-name nips
json files are saved at ./assets/paper/<$venue-name>/<$year>
2. Fetch Papers
python src/paper_manager.py update --year all --venue-name nips
@article{wang2024scipip,
title={SciPIP: An LLM-based Scientific Paper Idea Proposer},
author={Wenxiao Wang, Lihui Gu, Liye Zhang, Yunxiang Luo, Yi Dai, Chen Shen, Liang Xie, Binbin Lin, Xiaofei He, Jieping Ye},
journal={arXiv preprint arXiv:2410.23166},
url={https://arxiv.org/abs/2410.23166},
year={2024}
}
https://forms.gle/YpLUrhqs1ahyCAe99
Thank you for your use! We hope SciPIP can help you generate research ideas! 🎉
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for SciPIP
Similar Open Source Tools
SciPIP
SciPIP is a scientific paper idea generation tool powered by a large language model (LLM) designed to assist researchers in quickly generating novel research ideas. It conducts a literature review based on user-provided background information and generates fresh ideas for potential studies. The tool is designed to help researchers in various fields by providing a GUI environment for idea generation, supporting NLP, multimodal, and CV fields, and allowing users to interact with the tool through a web app or terminal. SciPIP uses Neo4j as its database and provides functionalities for generating new ideas, fetching papers, and constructing the database.
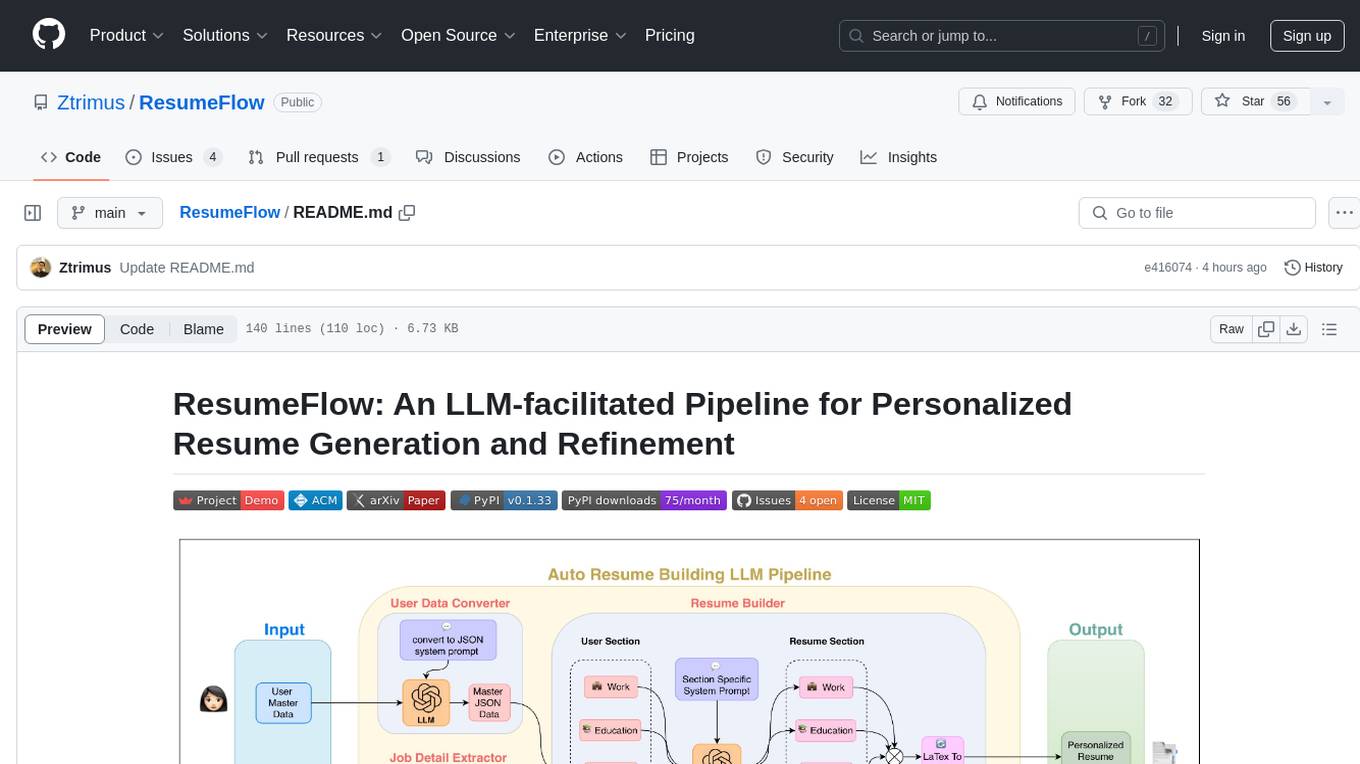
ResumeFlow
ResumeFlow is an automated system that leverages Large Language Models (LLMs) to streamline the job application process. By integrating LLM technology, the tool aims to automate various stages of job hunting, making it easier for users to apply for jobs. Users can access ResumeFlow as a web tool, install it as a Python package, or download the source code from GitHub. The tool requires Python 3.11.6 or above and an LLM API key from OpenAI or Gemini Pro for usage. ResumeFlow offers functionalities such as generating curated resumes and cover letters based on job URLs and user's master resume data.

cognee
Cognee is an open-source framework designed for creating self-improving deterministic outputs for Large Language Models (LLMs) using graphs, LLMs, and vector retrieval. It provides a platform for AI engineers to enhance their models and generate more accurate results. Users can leverage Cognee to add new information, utilize LLMs for knowledge creation, and query the system for relevant knowledge. The tool supports various LLM providers and offers flexibility in adding different data types, such as text files or directories. Cognee aims to streamline the process of working with LLMs and improving AI models for better performance and efficiency.
fiftyone-brain
FiftyOne Brain contains the open source AI/ML capabilities for the FiftyOne ecosystem, enabling users to automatically analyze and manipulate their datasets and models. Features include visual similarity search, query by text, finding unique and representative samples, finding media quality problems and annotation mistakes, and more.
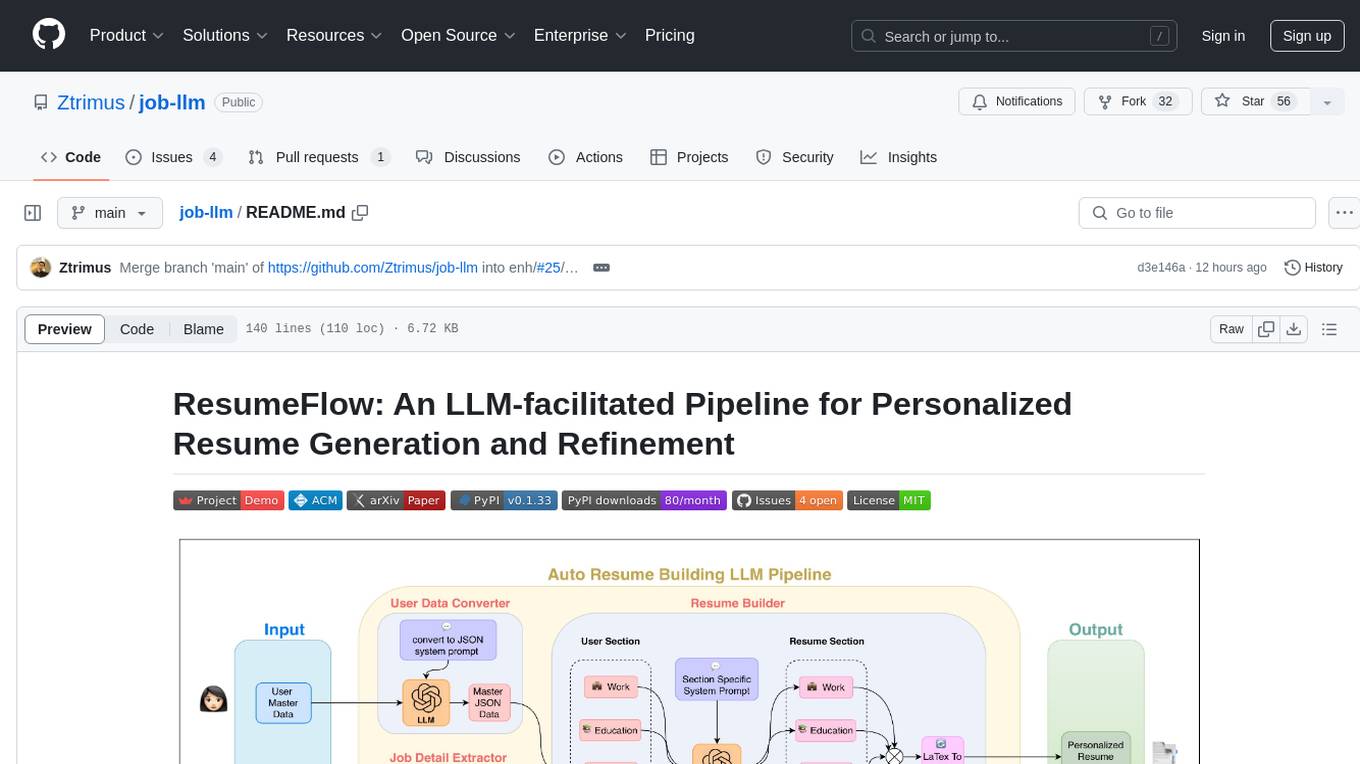
job-llm
ResumeFlow is an automated system utilizing Large Language Models (LLMs) to streamline the job application process. It aims to reduce human effort in various steps of job hunting by integrating LLM technology. Users can access ResumeFlow as a web tool, install it as a Python package, or download the source code. The project focuses on leveraging LLMs to automate tasks such as resume generation and refinement, making job applications smoother and more efficient.
lunary
Lunary is an open-source observability and prompt platform for Large Language Models (LLMs). It provides a suite of features to help AI developers take their applications into production, including analytics, monitoring, prompt templates, fine-tuning dataset creation, chat and feedback tracking, and evaluations. Lunary is designed to be usable with any model, not just OpenAI, and is easy to integrate and self-host.
openmeter
OpenMeter is a real-time and scalable usage metering tool for AI, usage-based billing, infrastructure, and IoT use cases. It provides a REST API for integrations and offers client SDKs in Node.js, Python, Go, and Web. OpenMeter is licensed under the Apache 2.0 License.

Biomni
Biomni is a general-purpose biomedical AI agent designed to autonomously execute a wide range of research tasks across diverse biomedical subfields. By integrating cutting-edge large language model (LLM) reasoning with retrieval-augmented planning and code-based execution, Biomni helps scientists dramatically enhance research productivity and generate testable hypotheses.
lingoose
LinGoose is a modular Go framework designed for building AI/LLM applications. It offers the flexibility to import only the necessary modules, abstracts features for customization, and provides a comprehensive solution for developing AI/LLM applications from scratch. The framework simplifies the process of creating intelligent applications by allowing users to choose preferred implementations or create their own. LinGoose empowers developers to leverage its capabilities to streamline the development of cutting-edge AI and LLM projects.

opencode
Opencode is an AI coding agent designed for the terminal. It is a tool that allows users to interact with AI models for coding tasks in a terminal-based environment. Opencode is open source, provider-agnostic, and focuses on a terminal user interface (TUI) for coding. It offers features such as client/server architecture, support for various AI models, and a strong emphasis on community contributions and feedback.
MetaGPT
MetaGPT is a multi-agent framework that enables GPT to work in a software company, collaborating to tackle more complex tasks. It assigns different roles to GPTs to form a collaborative entity for complex tasks. MetaGPT takes a one-line requirement as input and outputs user stories, competitive analysis, requirements, data structures, APIs, documents, etc. Internally, MetaGPT includes product managers, architects, project managers, and engineers. It provides the entire process of a software company along with carefully orchestrated SOPs. MetaGPT's core philosophy is "Code = SOP(Team)", materializing SOP and applying it to teams composed of LLMs.

labo
LABO is a time series forecasting and analysis framework that integrates pre-trained and fine-tuned LLMs with multi-domain agent-based systems. It allows users to create and tune agents easily for various scenarios, such as stock market trend prediction and web public opinion analysis. LABO requires a specific runtime environment setup, including system requirements, Python environment, dependency installations, and configurations. Users can fine-tune their own models using LABO's Low-Rank Adaptation (LoRA) for computational efficiency and continuous model updates. Additionally, LABO provides a Python library for building model training pipelines and customizing agents for specific tasks.
elyra
Elyra is a set of AI-centric extensions to JupyterLab Notebooks that includes features like Visual Pipeline Editor, running notebooks/scripts as batch jobs, reusable code snippets, hybrid runtime support, script editors with execution capabilities, debugger, version control using Git, and more. It provides a comprehensive environment for data scientists and AI practitioners to develop, test, and deploy machine learning models and workflows efficiently.
browser
Lightpanda Browser is an open-source headless browser designed for fast web automation, AI agents, LLM training, scraping, and testing. It features ultra-low memory footprint, exceptionally fast execution, and compatibility with Playwright and Puppeteer through CDP. Built for performance, Lightpanda offers Javascript execution, support for Web APIs, and is optimized for minimal memory usage. It is a modern solution for web scraping and automation tasks, providing a lightweight alternative to traditional browsers like Chrome.

ProX
ProX is a lm-based data refinement framework that automates the process of cleaning and improving data used in pre-training large language models. It offers better performance, domain flexibility, efficiency, and cost-effectiveness compared to traditional methods. The framework has been shown to improve model performance by over 2% and boost accuracy by up to 20% in tasks like math. ProX is designed to refine data at scale without the need for manual adjustments, making it a valuable tool for data preprocessing in natural language processing tasks.

codebox-api
CodeBox is a cloud infrastructure tool designed for running Python code in an isolated environment. It also offers simple file input/output capabilities and will soon support vector database operations. Users can install CodeBox using pip and utilize it by setting up an API key. The tool allows users to execute Python code snippets and interact with the isolated environment. CodeBox is currently in early development stages and requires manual handling for certain operations like refunds and cancellations. The tool is open for contributions through issue reporting and pull requests. It is licensed under MIT and can be contacted via email at [email protected].
For similar tasks
SciPIP
SciPIP is a scientific paper idea generation tool powered by a large language model (LLM) designed to assist researchers in quickly generating novel research ideas. It conducts a literature review based on user-provided background information and generates fresh ideas for potential studies. The tool is designed to help researchers in various fields by providing a GUI environment for idea generation, supporting NLP, multimodal, and CV fields, and allowing users to interact with the tool through a web app or terminal. SciPIP uses Neo4j as its database and provides functionalities for generating new ideas, fetching papers, and constructing the database.
auto-paper-digest
Auto Paper Digest (APD) is a tool designed to automatically fetch cutting-edge AI research papers, download PDFs, generate video explanations, and publish them on platforms like HuggingFace, Douyin, and portal websites. It provides functionalities such as fetching papers from Hugging Face, downloading PDFs from arXiv, generating videos using NotebookLM, automatic publishing to HuggingFace Dataset, automatic publishing to Douyin, and hosting videos on a Gradio portal website. The tool also supports resuming interrupted tasks, persistent login states for Google and Douyin, and a structured workflow divided into three phases: Upload, Download, and Publish.
For similar jobs

asreview
The ASReview project implements active learning for systematic reviews, utilizing AI-aided pipelines to assist in finding relevant texts for search tasks. It accelerates the screening of textual data with minimal human input, saving time and increasing output quality. The software offers three modes: Oracle for interactive screening, Exploration for teaching purposes, and Simulation for evaluating active learning models. ASReview LAB is designed to support decision-making in any discipline or industry by improving efficiency and transparency in screening large amounts of textual data.
NewEraAI-Papers
The NewEraAI-Papers repository provides links to collections of influential and interesting research papers from top AI conferences, along with open-source code to promote reproducibility and provide detailed implementation insights beyond the scope of the article. Users can stay up to date with the latest advances in AI research by exploring this repository. Contributions to improve the completeness of the list are welcomed, and users can create pull requests, open issues, or contact the repository owner via email to enhance the repository further.
cltk
The Classical Language Toolkit (CLTK) is a Python library that provides natural language processing (NLP) capabilities for pre-modern languages. It offers a modular processing pipeline with pre-configured defaults and supports almost 20 languages. Users can install the latest version using pip and access detailed documentation on the official website. The toolkit is designed to meet the unique needs of researchers working with historical languages, filling a void in the NLP landscape that often neglects non-spoken languages and different research goals.
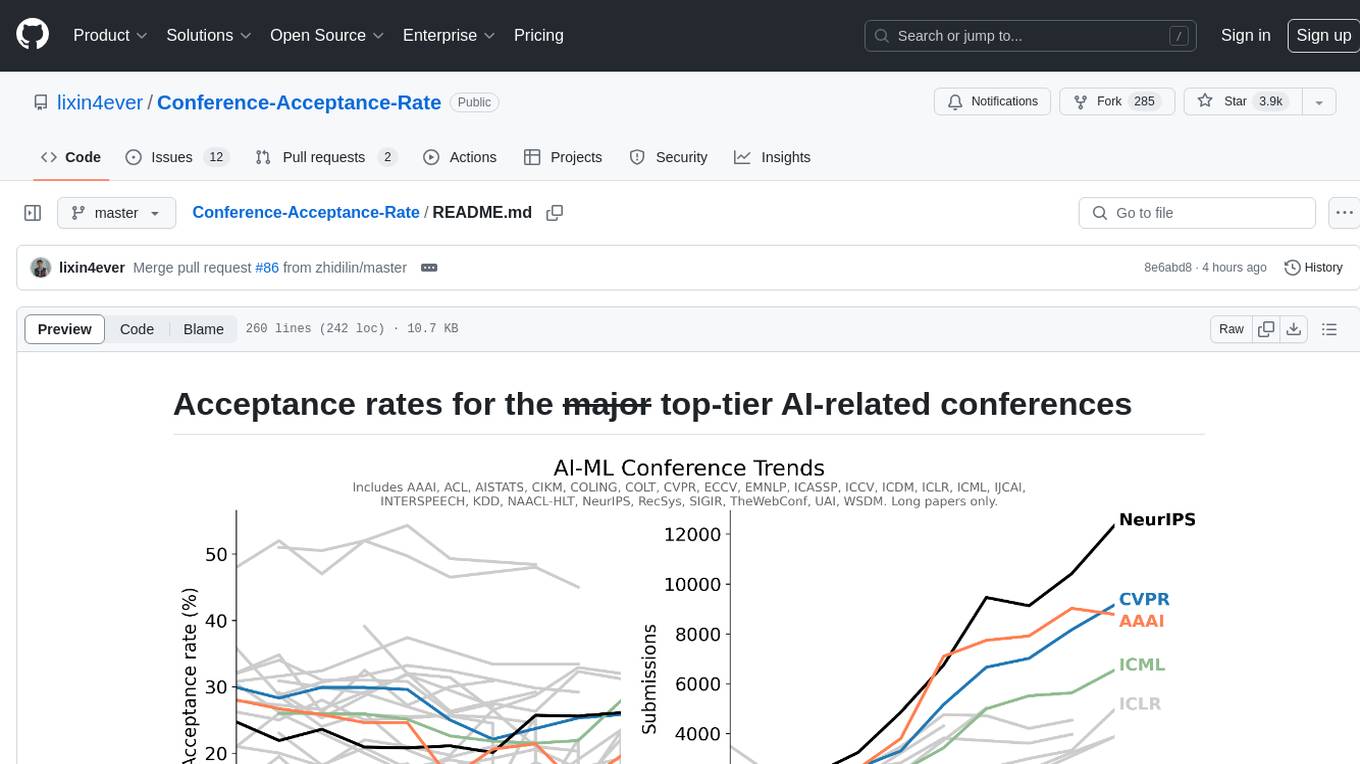
Conference-Acceptance-Rate
The 'Conference-Acceptance-Rate' repository provides acceptance rates for top-tier AI-related conferences in the fields of Natural Language Processing, Computational Linguistics, Computer Vision, Pattern Recognition, Machine Learning, Learning Theory, Artificial Intelligence, Data Mining, Information Retrieval, Speech Processing, and Signal Processing. The data includes acceptance rates for long papers and short papers over several years for each conference, allowing researchers to track trends and make informed decisions about where to submit their work.
pdftochat
PDFToChat is a tool that allows users to chat with their PDF documents in seconds. It is powered by Together AI and Pinecone, utilizing a tech stack including Next.js, Mixtral, M2 Bert, LangChain.js, MongoDB Atlas, Bytescale, Vercel, Clerk, and Tailwind CSS. Users can deploy the tool to Vercel or any other host by setting up Together.ai, MongoDB Atlas database, Bytescale, Clerk, and Vercel. The tool enables users to interact with PDFs through chat, with future tasks including adding features like trash icon for deleting PDFs, exploring different embedding models, implementing auto scrolling, improving replies, benchmarking accuracy, researching chunking and retrieval best practices, adding demo video, upgrading to Next.js 14, adding analytics, customizing tailwind prose, saving chats in postgres DB, compressing large PDFs, implementing custom uploader, session tracking, error handling, and support for images in PDFs.

tods-arxiv-daily-paper
This repository provides a tool for fetching and summarizing daily papers from the arXiv repository. It allows users to stay updated with the latest research in various fields by automatically retrieving and summarizing papers on a daily basis. The tool simplifies the process of accessing and digesting academic papers, making it easier for researchers and enthusiasts to keep track of new developments in their areas of interest.
Awesome-LLM-Strawberry
Awesome LLM Strawberry is a collection of research papers and blogs related to OpenAI Strawberry(o1) and Reasoning. The repository is continuously updated to track the frontier of LLM Reasoning.
Call-for-Reviewers
The `Call-for-Reviewers` repository aims to collect the latest 'call for reviewers' links from various top CS/ML/AI conferences/journals. It provides an opportunity for individuals in the computer/ machine learning/ artificial intelligence fields to gain review experience for applying for NIW/H1B/EB1 or enhancing their CV. The repository helps users stay updated with the latest research trends and engage with the academic community.