
cltk
The Classical Language Toolkit
Stars: 819
The Classical Language Toolkit (CLTK) is a Python library that provides natural language processing (NLP) capabilities for pre-modern languages. It offers a modular processing pipeline with pre-configured defaults and supports almost 20 languages. Users can install the latest version using pip and access detailed documentation on the official website. The toolkit is designed to meet the unique needs of researchers working with historical languages, filling a void in the NLP landscape that often neglects non-spoken languages and different research goals.
README:
|circleci| |pypi| |twitter| |discord|
.. |circleci| image:: https://circleci.com/gh/cltk/cltk/tree/master.svg?style=svg :target: https://circleci.com/gh/cltk/cltk/tree/master
{kind=link}
.. |rtd| image:: https://img.shields.io/readthedocs/cltk :target: http://docs.cltk.org/
.. |codecov| image:: https://codecov.io/gh/cltk/cltk/branch/master/graph/badge.svg :target: https://codecov.io/gh/cltk/cltk
{kind=link}
.. |pypi| image:: https://img.shields.io/pypi/v/cltk :target: https://pypi.org/project/cltk/
.. |zenodo| image:: https://zenodo.org/badge/DOI/10.5281/zenodo.3445585.svg :target: https://doi.org/10.5281/zenodo.3445585
{kind=link}
.. |binder| image:: https://mybinder.org/badge_logo.svg :target: https://mybinder.org/v2/gh/cltk/tutorials/master
{kind=link}
.. |twitter| image:: https://img.shields.io/twitter/url?style=social&url=https%3A%2F%2Ftwitter.com%2FCLTKorg&label=Follow%20%40CLTKorg :target: https://twitter.com/CLTKorg
.. |discord| image:: https://img.shields.io/discord/974033391542480936 :target: https://discord.gg/ATUDJQX7cg
The Classical Language Toolkit (CLTK) is a Python library offering natural language processing (NLP) for pre-modern languages.
For the CLTK's latest version:
.. code-block:: bash
$ pip install cltk
For more information, see Installation docs <https://docs.cltk.org/en/latest/installation.html>_ or, to install from source, Development <https://docs.cltk.org/en/latest/development.html>_.
Pre-1.0 software remains available on the branch v0.1.x <https://github.com/cltk/cltk/tree/v0.1.x>_ and docs at <https://legacy.cltk.org>_. Install it with pip install "cltk<1.0".
Documentation at <https://docs.cltk.org>_.
When using the CLTK, please cite the following publication <https://aclanthology.org/2021.acl-demo.3>_, including the DOI:
Johnson, Kyle P., Patrick J. Burns, John Stewart, Todd Cook, Clément Besnier, and William J. B. Mattingly. "The Classical Language Toolkit: An NLP Framework for Pre-Modern Languages." In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations, pp. 20-29. 2021. 10.18653/v1/2021.acl-demo.3
The complete BibTeX entry:
.. code-block:: bibtex
@inproceedings{johnson-etal-2021-classical, title = "The {C}lassical {L}anguage {T}oolkit: {A}n {NLP} Framework for Pre-Modern Languages", author = "Johnson, Kyle P. and Burns, Patrick J. and Stewart, John and Cook, Todd and Besnier, Cl{'e}ment and Mattingly, William J. B.", booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations", month = aug, year = "2021", address = "Online", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/2021.acl-demo.3", doi = "10.18653/v1/2021.acl-demo.3", pages = "20--29", abstract = "This paper announces version 1.0 of the Classical Language Toolkit (CLTK), an NLP framework for pre-modern languages. The vast majority of NLP, its algorithms and software, is created with assumptions particular to living languages, thus neglecting certain important characteristics of largely non-spoken historical languages. Further, scholars of pre-modern languages often have different goals than those of living-language researchers. To fill this void, the CLTK adapts ideas from several leading NLP frameworks to create a novel software architecture that satisfies the unique needs of pre-modern languages and their researchers. Its centerpiece is a modular processing pipeline that balances the competing demands of algorithmic diversity with pre-configured defaults. The CLTK currently provides pipelines, including models, for almost 20 languages.", }
.. |year| date:: %Y
Copyright (c) 2014-|year| Kyle P. Johnson under the MIT License <https://github.com/cltk/cltk/blob/master/LICENSE>_.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for cltk
Similar Open Source Tools
cltk
The Classical Language Toolkit (CLTK) is a Python library that provides natural language processing (NLP) capabilities for pre-modern languages. It offers a modular processing pipeline with pre-configured defaults and supports almost 20 languages. Users can install the latest version using pip and access detailed documentation on the official website. The toolkit is designed to meet the unique needs of researchers working with historical languages, filling a void in the NLP landscape that often neglects non-spoken languages and different research goals.
opening-up-chatgpt.github.io
This repository provides a curated list of open-source projects that implement instruction-tuned large language models (LLMs) with reinforcement learning from human feedback (RLHF). The projects are evaluated in terms of their openness across a predefined set of criteria in the areas of Availability, Documentation, and Access. The goal of this repository is to promote transparency and accountability in the development and deployment of LLMs.

AutoMathText
AutoMathText is an extensive dataset of around 200 GB of mathematical texts autonomously selected by the language model Qwen-72B. It aims to facilitate research in mathematics and artificial intelligence, serve as an educational tool for learning complex mathematical concepts, and provide a foundation for developing AI models specialized in processing mathematical content.
GOLEM
GOLEM is an open-source AI framework focused on optimization and learning of structured graph-based models using meta-heuristic methods. It emphasizes the potential of meta-heuristics in complex problem spaces where gradient-based methods are not suitable, and the importance of structured models in various problem domains. The framework offers features like structured model optimization, metaheuristic methods, multi-objective optimization, constrained optimization, extensibility, interpretability, and reproducibility. It can be applied to optimization problems represented as directed graphs with defined fitness functions. GOLEM has applications in areas like AutoML, Bayesian network structure search, differential equation discovery, geometric design, and neural architecture search. The project structure includes packages for core functionalities, adapters, graph representation, optimizers, genetic algorithms, utilities, serialization, visualization, examples, and testing. Contributions are welcome, and the project is supported by ITMO University's Research Center Strong Artificial Intelligence in Industry.

LongBench
LongBench v2 is a benchmark designed to assess the ability of large language models (LLMs) to handle long-context problems requiring deep understanding and reasoning across various real-world multitasks. It consists of 503 challenging multiple-choice questions with contexts ranging from 8k to 2M words, covering six major task categories. The dataset is collected from nearly 100 highly educated individuals with diverse professional backgrounds and is designed to be challenging even for human experts. The evaluation results highlight the importance of enhanced reasoning ability and scaling inference-time compute to tackle the long-context challenges in LongBench v2.
OpenNARS-for-Applications
OpenNARS-for-Applications is an implementation of a Non-Axiomatic Reasoning System, a general-purpose reasoner that adapts under the Assumption of Insufficient Knowledge and Resources. The system combines the logic and conceptual ideas of OpenNARS, event handling and procedure learning capabilities of ANSNA and 20NAR1, and the control model from ALANN. It is written in C, offers improved reasoning performance, and has been compared with Reinforcement Learning and means-end reasoning approaches. The system has been used in real-world applications such as assisting first responders, real-time traffic surveillance, and experiments with autonomous robots. It has been developed with a pragmatic mindset focusing on effective implementation of existing theory.

zshot
Zshot is a highly customizable framework for performing Zero and Few shot named entity and relationships recognition. It can be used for mentions extraction, wikification, zero and few shot named entity recognition, zero and few shot named relationship recognition, and visualization of zero-shot NER and RE extraction. The framework consists of two main components: the mentions extractor and the linker. There are multiple mentions extractors and linkers available, each serving a specific purpose. Zshot also includes a relations extractor and a knowledge extractor for extracting relations among entities and performing entity classification. The tool requires Python 3.6+ and dependencies like spacy, torch, transformers, evaluate, and datasets for evaluation over datasets like OntoNotes. Optional dependencies include flair and blink for additional functionalities. Zshot provides examples, tutorials, and evaluation methods to assess the performance of the components.

matsciml
The Open MatSci ML Toolkit is a flexible framework for machine learning in materials science. It provides a unified interface to a variety of materials science datasets, as well as a set of tools for data preprocessing, model training, and evaluation. The toolkit is designed to be easy to use for both beginners and experienced researchers, and it can be used to train models for a wide range of tasks, including property prediction, materials discovery, and materials design.

aitlas
The AiTLAS toolbox (Artificial Intelligence Toolbox for Earth Observation) includes state-of-the-art machine learning methods for exploratory and predictive analysis of satellite imagery as well as a repository of AI-ready Earth Observation (EO) datasets. It can be easily applied for a variety of Earth Observation tasks, such as land use and cover classification, crop type prediction, localization of specific objects (semantic segmentation), etc. The main goal of AiTLAS is to facilitate better usability and adoption of novel AI methods (and models) by EO experts, while offering easy access and standardized format of EO datasets to AI experts which allows benchmarking of various existing and novel AI methods tailored for EO data.

Woodpecker
Woodpecker is a tool designed to correct hallucinations in Multimodal Large Language Models (MLLMs) by introducing a training-free method that picks out and corrects inconsistencies between generated text and image content. It consists of five stages: key concept extraction, question formulation, visual knowledge validation, visual claim generation, and hallucination correction. Woodpecker can be easily integrated with different MLLMs and provides interpretable results by accessing intermediate outputs of the stages. The tool has shown significant improvements in accuracy over baseline models like MiniGPT-4 and mPLUG-Owl.

babilong
BABILong is a generative benchmark designed to evaluate the performance of NLP models in processing long documents with distributed facts. It consists of 20 tasks that simulate interactions between characters and objects in various locations, requiring models to distinguish important information from irrelevant details. The tasks vary in complexity and reasoning aspects, with test samples potentially containing millions of tokens. The benchmark aims to challenge and assess the capabilities of Large Language Models (LLMs) in handling complex, long-context information.
FedLLM-Bench
FedLLM-Bench is a realistic benchmark for the Federated Learning of Large Language Models community. It includes datasets for federated instruction tuning and preference alignment tasks, exhibiting diversities in language, quality, quantity, instruction, sequence length, embedding, and preference. The repository provides training scripts and code for open-ended evaluation, aiming to facilitate research and development in federated learning of large language models.
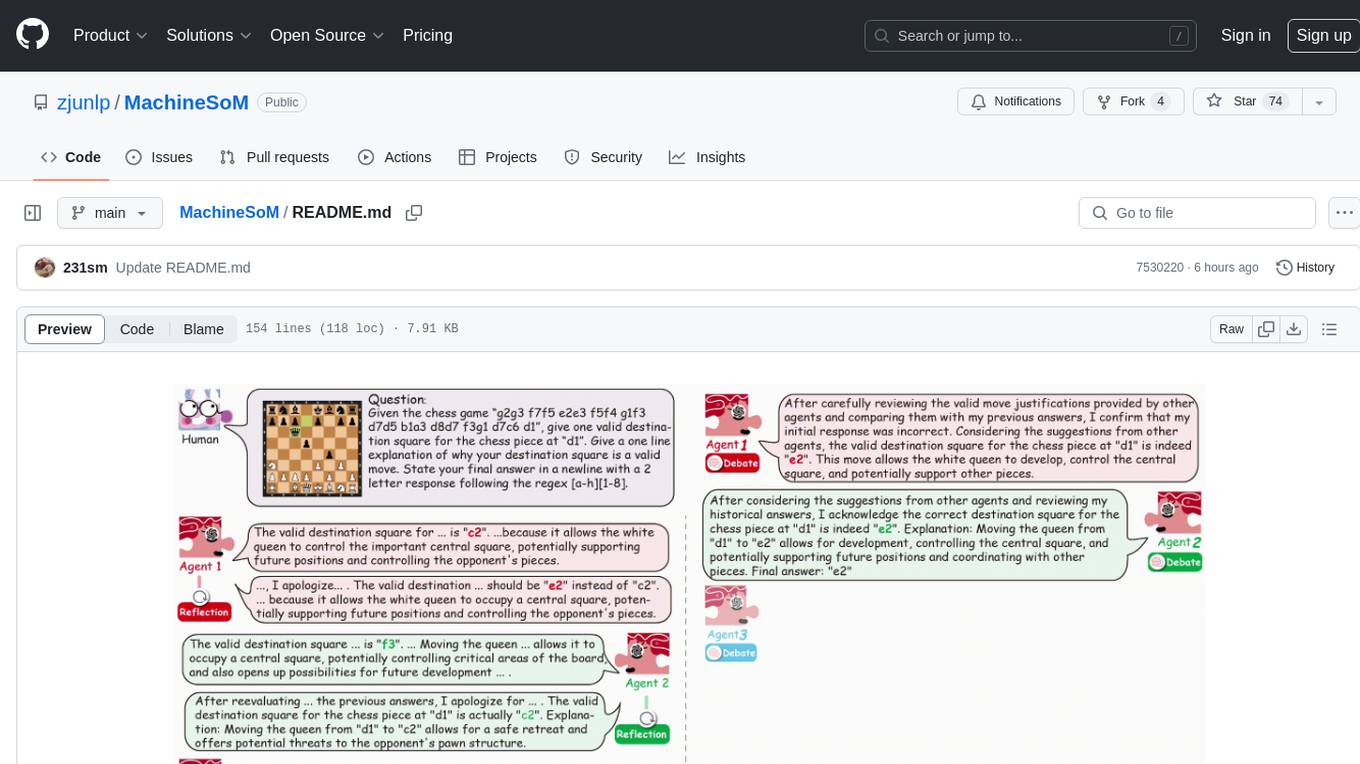
MachineSoM
MachineSoM is a code repository for the paper 'Exploring Collaboration Mechanisms for LLM Agents: A Social Psychology View'. It focuses on the emergence of intelligence from collaborative and communicative computational modules, enabling effective completion of complex tasks. The repository includes code for societies of LLM agents with different traits, collaboration processes such as debate and self-reflection, and interaction strategies for determining when and with whom to interact. It provides a coding framework compatible with various inference services like Replicate, OpenAI, Dashscope, and Anyscale, supporting models like Qwen and GPT. Users can run experiments, evaluate results, and draw figures based on the paper's content, with available datasets for MMLU, Math, and Chess Move Validity.

Adaptive-MT-LLM-Fine-tuning
The repository Adaptive-MT-LLM-Fine-tuning contains code and data for the paper 'Fine-tuning Large Language Models for Adaptive Machine Translation'. It focuses on enhancing Mistral 7B, a large language model, for real-time adaptive machine translation in the medical domain. The fine-tuning process involves using zero-shot and one-shot translation prompts to improve terminology and style adherence. The repository includes training and test data, data processing code, fuzzy match retrieval techniques, fine-tuning methods, conversion to CTranslate2 format, tokenizers, translation codes, and evaluation metrics.

ChatDev
ChatDev is a virtual software company powered by intelligent agents like CEO, CPO, CTO, programmer, reviewer, tester, and art designer. These agents collaborate to revolutionize the digital world through programming. The platform offers an easy-to-use, highly customizable, and extendable framework based on large language models, ideal for studying collective intelligence. ChatDev introduces innovative methods like Iterative Experience Refinement and Experiential Co-Learning to enhance software development efficiency. It supports features like incremental development, Docker integration, Git mode, and Human-Agent-Interaction mode. Users can customize ChatChain, Phase, and Role settings, and share their software creations easily. The project is open-source under the Apache 2.0 License and utilizes data licensed under CC BY-NC 4.0.
AIW
AIW is a code base for experiments and raw data related to Alice in Wonderland, showcasing complete reasoning breakdown in state-of-the-art large language models. Users can collect experiments data using LiteLLM and TogetherAI, and plot the data using provided scripts. The tool allows for executing experiments over LiteLLM and lmsys, with options for different prompt types and AIW variations. The project also includes acknowledgments and a citation for reference.
For similar tasks
cltk
The Classical Language Toolkit (CLTK) is a Python library that provides natural language processing (NLP) capabilities for pre-modern languages. It offers a modular processing pipeline with pre-configured defaults and supports almost 20 languages. Users can install the latest version using pip and access detailed documentation on the official website. The toolkit is designed to meet the unique needs of researchers working with historical languages, filling a void in the NLP landscape that often neglects non-spoken languages and different research goals.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.

SillyTavern
SillyTavern is a user interface you can install on your computer (and Android phones) that allows you to interact with text generation AIs and chat/roleplay with characters you or the community create. SillyTavern is a fork of TavernAI 1.2.8 which is under more active development and has added many major features. At this point, they can be thought of as completely independent programs.
langfun
Langfun is a Python library that aims to make language models (LM) fun to work with. It enables a programming model that flows naturally, resembling the human thought process. Langfun emphasizes the reuse and combination of language pieces to form prompts, thereby accelerating innovation. Unlike other LM frameworks, which feed program-generated data into the LM, langfun takes a distinct approach: It starts with natural language, allowing for seamless interactions between language and program logic, and concludes with natural language and optional structured output. Consequently, langfun can aptly be described as Language as functions, capturing the core of its methodology.
litellm
LiteLLM is a tool that allows you to call all LLM APIs using the OpenAI format. This includes Bedrock, Huggingface, VertexAI, TogetherAI, Azure, OpenAI, and more. LiteLLM manages translating inputs to provider's `completion`, `embedding`, and `image_generation` endpoints, providing consistent output, and retry/fallback logic across multiple deployments. It also supports setting budgets and rate limits per project, api key, and model.
For similar jobs

asreview
The ASReview project implements active learning for systematic reviews, utilizing AI-aided pipelines to assist in finding relevant texts for search tasks. It accelerates the screening of textual data with minimal human input, saving time and increasing output quality. The software offers three modes: Oracle for interactive screening, Exploration for teaching purposes, and Simulation for evaluating active learning models. ASReview LAB is designed to support decision-making in any discipline or industry by improving efficiency and transparency in screening large amounts of textual data.
NewEraAI-Papers
The NewEraAI-Papers repository provides links to collections of influential and interesting research papers from top AI conferences, along with open-source code to promote reproducibility and provide detailed implementation insights beyond the scope of the article. Users can stay up to date with the latest advances in AI research by exploring this repository. Contributions to improve the completeness of the list are welcomed, and users can create pull requests, open issues, or contact the repository owner via email to enhance the repository further.
cltk
The Classical Language Toolkit (CLTK) is a Python library that provides natural language processing (NLP) capabilities for pre-modern languages. It offers a modular processing pipeline with pre-configured defaults and supports almost 20 languages. Users can install the latest version using pip and access detailed documentation on the official website. The toolkit is designed to meet the unique needs of researchers working with historical languages, filling a void in the NLP landscape that often neglects non-spoken languages and different research goals.
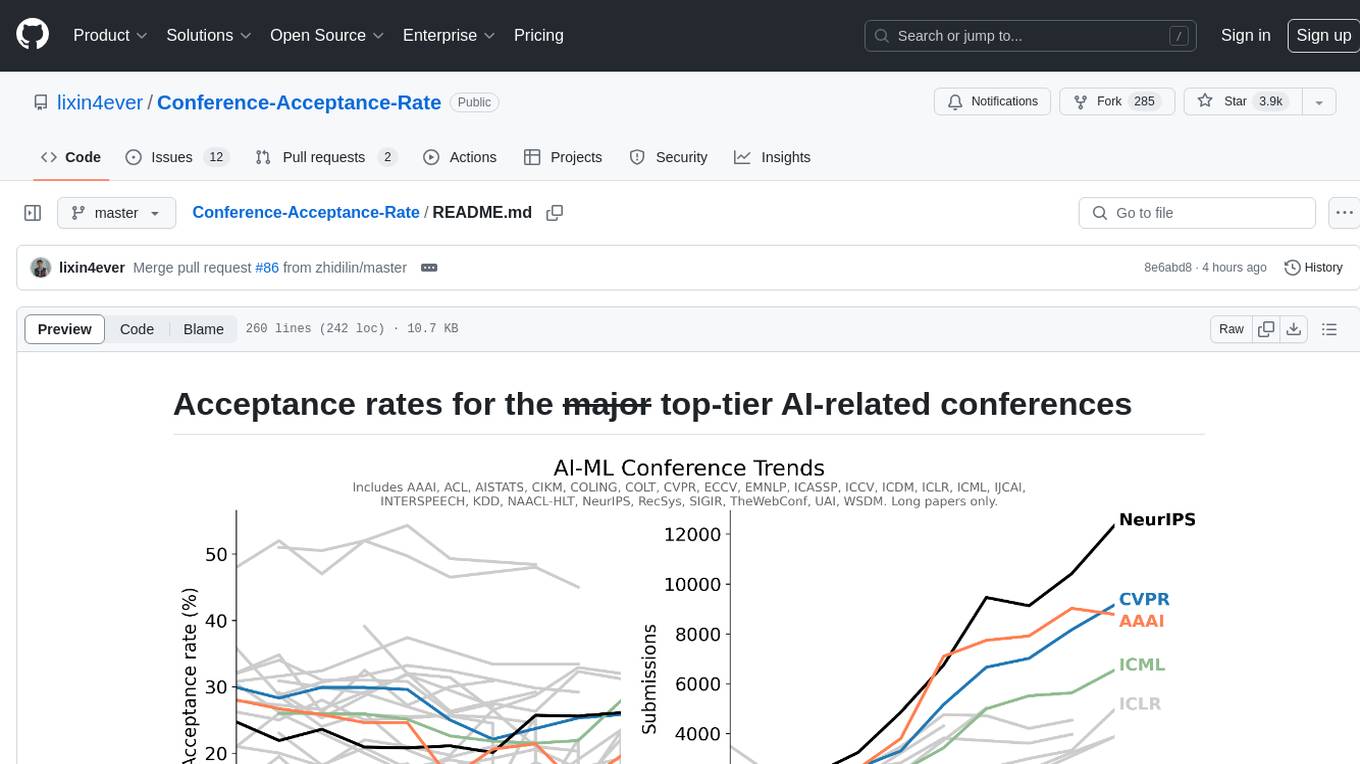
Conference-Acceptance-Rate
The 'Conference-Acceptance-Rate' repository provides acceptance rates for top-tier AI-related conferences in the fields of Natural Language Processing, Computational Linguistics, Computer Vision, Pattern Recognition, Machine Learning, Learning Theory, Artificial Intelligence, Data Mining, Information Retrieval, Speech Processing, and Signal Processing. The data includes acceptance rates for long papers and short papers over several years for each conference, allowing researchers to track trends and make informed decisions about where to submit their work.
pdftochat
PDFToChat is a tool that allows users to chat with their PDF documents in seconds. It is powered by Together AI and Pinecone, utilizing a tech stack including Next.js, Mixtral, M2 Bert, LangChain.js, MongoDB Atlas, Bytescale, Vercel, Clerk, and Tailwind CSS. Users can deploy the tool to Vercel or any other host by setting up Together.ai, MongoDB Atlas database, Bytescale, Clerk, and Vercel. The tool enables users to interact with PDFs through chat, with future tasks including adding features like trash icon for deleting PDFs, exploring different embedding models, implementing auto scrolling, improving replies, benchmarking accuracy, researching chunking and retrieval best practices, adding demo video, upgrading to Next.js 14, adding analytics, customizing tailwind prose, saving chats in postgres DB, compressing large PDFs, implementing custom uploader, session tracking, error handling, and support for images in PDFs.

tods-arxiv-daily-paper
This repository provides a tool for fetching and summarizing daily papers from the arXiv repository. It allows users to stay updated with the latest research in various fields by automatically retrieving and summarizing papers on a daily basis. The tool simplifies the process of accessing and digesting academic papers, making it easier for researchers and enthusiasts to keep track of new developments in their areas of interest.
Awesome-LLM-Strawberry
Awesome LLM Strawberry is a collection of research papers and blogs related to OpenAI Strawberry(o1) and Reasoning. The repository is continuously updated to track the frontier of LLM Reasoning.
Call-for-Reviewers
The `Call-for-Reviewers` repository aims to collect the latest 'call for reviewers' links from various top CS/ML/AI conferences/journals. It provides an opportunity for individuals in the computer/ machine learning/ artificial intelligence fields to gain review experience for applying for NIW/H1B/EB1 or enhancing their CV. The repository helps users stay updated with the latest research trends and engage with the academic community.