
pdftochat
Chat with your PDFs with AI
Stars: 916
PDFToChat is a tool that allows users to chat with their PDF documents in seconds. It is powered by Together AI and Pinecone, utilizing a tech stack including Next.js, Mixtral, M2 Bert, LangChain.js, MongoDB Atlas, Bytescale, Vercel, Clerk, and Tailwind CSS. Users can deploy the tool to Vercel or any other host by setting up Together.ai, MongoDB Atlas database, Bytescale, Clerk, and Vercel. The tool enables users to interact with PDFs through chat, with future tasks including adding features like trash icon for deleting PDFs, exploring different embedding models, implementing auto scrolling, improving replies, benchmarking accuracy, researching chunking and retrieval best practices, adding demo video, upgrading to Next.js 14, adding analytics, customizing tailwind prose, saving chats in postgres DB, compressing large PDFs, implementing custom uploader, session tracking, error handling, and support for images in PDFs.
README:

Chat with your PDFs in seconds. Powered by Together AI and Pinecone.
Tech Stack · Deploy Your Own · Common Errors · Credits · Future Tasks
- Next.js App Router for the framework
- Mixtral through Together AI inference for the LLM
- M2 Bert 80M through Together AI for embeddings
- LangChain.js for the RAG code
- MongoDB Atlas for the vector database
- Bytescale for the PDF storage
- Vercel for hosting and for the postgres DB
- Clerk for user authentication
- Tailwind CSS for styling
You can deploy this template to Vercel or any other host. Note that you'll need to:
- Set up Together.ai
- Set up a MongoDB Atlas Atlas database with 768 dimensions
- See instructions below for MongoDB
- Set up Bytescale
- Set up Clerk
- Set up Vercel
- (Optional) Set up LangSmith for tracing.
See the .example.env for a list of all the required environment variables.
You will also need to prepare your database schema by running npx prisma db push.
To set up a MongoDB Atlas database as the backing vectorstore, you will need to perform the following steps:
- Sign up on their website, then create a database cluster. Find it under the
Databasesidebar tab. - Create a collection by switching to
Collectionsthe tab and creating a blank collection. - Create an index by switching to the
Atlas Searchtab and clickingCreate Search Index. - Make sure you select
Atlas Vector Search - JSON Editor, select the appropriate database and collection, and paste the following into the textbox:
{
"fields": [
{
"numDimensions": 768,
"path": "embedding",
"similarity": "euclidean",
"type": "vector"
},
{
"path": "docstore_document_id",
"type": "filter"
}
]
}Note that the numDimensions is 768 dimensions to match the embeddings model we're using, and that we have another index on docstore_document_id. This allows us to filter later.
You may call the index whatever you wish, just make a note of it!
- Finally, retrieve and set the following environment variables:
NEXT_PUBLIC_VECTORSTORE=mongodb # Set MongoDB Atlas as your vectorstore
MONGODB_ATLAS_URI= # Connection string for your database.
MONGODB_ATLAS_DB_NAME= # The name of your database.
MONGODB_ATLAS_COLLECTION_NAME= # The name of your collection.
MONGODB_ATLAS_INDEX_NAME= # The name of the index you just created.- Check that you've created an
.envfile that contains your valid (and working) API keys, environment and index name. - Check that you've set the vector dimensions to
768and thatindexmatched your specified field in the.env variable. - Check that you've added a credit card on Together AI if you're hitting rate limiting issues due to the free tier
- Youssef for the design of the app
- Mayo for the original RAG repo and inspiration
- Jacob for the LangChain help
- Together AI, Bytescale, Pinecone, and Clerk for sponsoring
These are some future tasks that I have planned. Contributions are welcome!
- [ ] Add a trash icon for folks to delete PDFs from the dashboard and implement delete functionality
- [ ] Try different embedding models like UAE-large-v1 to see if it improves accuracy
- [ ] Explore best practices for auto scrolling based on other chat apps like chatGPT
- [ ] Do some prompt engineering for Mixtral to make replies as good as possible
- [ ] Protect API routes by making sure users are signed in before executing chats
- [ ] Run an initial benchmark on how accurate chunking / retrieval are
- [ ] Research best practices for chunking and retrieval and play around with them – ideally run benchmarks
- [ ] Try out Langsmith for more observability into how the RAG app runs
- [ ] Add demo video to the homepage to demonstrate functionality more easily
- [ ] Upgrade to Next.js 14 and fix any issues with that
- [ ] Implement sources like perplexity to be clickable with more info
- [ ] Add analytics to track the number of chats & errors
- [ ] Make some changes to the default tailwind
proseto decrease padding - [ ] Add an initial message with sample questions or just add them as bubbles on the page
- [ ] Add an option to get answers as markdown or in regular paragraphs
- [ ] Implement something like SWR to automatically revalidate data
- [ ] Save chats for each user to get back to later in the postgres DB
- [ ] Bring up a message to direct folks to compress PDFs if they're beyond 10MB
- [ ] Use a self-designed custom uploader
- [ ] Use a session tracking tool to better understand how folks are using the site
- [ ] Add better error handling overall with appropriate toasts when actions fail
- [ ] Add support for images in PDFs with something like Nougat
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for pdftochat
Similar Open Source Tools
pdftochat
PDFToChat is a tool that allows users to chat with their PDF documents in seconds. It is powered by Together AI and Pinecone, utilizing a tech stack including Next.js, Mixtral, M2 Bert, LangChain.js, MongoDB Atlas, Bytescale, Vercel, Clerk, and Tailwind CSS. Users can deploy the tool to Vercel or any other host by setting up Together.ai, MongoDB Atlas database, Bytescale, Clerk, and Vercel. The tool enables users to interact with PDFs through chat, with future tasks including adding features like trash icon for deleting PDFs, exploring different embedding models, implementing auto scrolling, improving replies, benchmarking accuracy, researching chunking and retrieval best practices, adding demo video, upgrading to Next.js 14, adding analytics, customizing tailwind prose, saving chats in postgres DB, compressing large PDFs, implementing custom uploader, session tracking, error handling, and support for images in PDFs.
DistiLlama
DistiLlama is a Chrome extension that leverages a locally running Large Language Model (LLM) to perform various tasks, including text summarization, chat, and document analysis. It utilizes Ollama as the locally running LLM instance and LangChain for text summarization. DistiLlama provides a user-friendly interface for interacting with the LLM, allowing users to summarize web pages, chat with documents (including PDFs), and engage in text-based conversations. The extension is easy to install and use, requiring only the installation of Ollama and a few simple steps to set up the environment. DistiLlama offers a range of customization options, including the choice of LLM model and the ability to configure the summarization chain. It also supports multimodal capabilities, allowing users to interact with the LLM through text, voice, and images. DistiLlama is a valuable tool for researchers, students, and professionals who seek to leverage the power of LLMs for various tasks without compromising data privacy.

dataline
DataLine is an AI-driven data analysis and visualization tool designed for technical and non-technical users to explore data quickly. It offers privacy-focused data storage on the user's device, supports various data sources, generates charts, executes queries, and facilitates report building. The tool aims to speed up data analysis tasks for businesses and individuals by providing a user-friendly interface and natural language querying capabilities.
LLPlayer
LLPlayer is a specialized media player designed for language learning, offering unique features such as dual subtitles, AI-generated subtitles, real-time OCR, real-time translation, word lookup, and more. It supports multiple languages, online video playback, customizable settings, and integration with browser extensions. Written in C#/WPF, LLPlayer is free, open-source, and aims to enhance the language learning experience through innovative functionalities.
devika
Devika is an advanced AI software engineer that can understand high-level human instructions, break them down into steps, research relevant information, and write code to achieve the given objective. Devika utilizes large language models, planning and reasoning algorithms, and web browsing abilities to intelligently develop software. Devika aims to revolutionize the way we build software by providing an AI pair programmer who can take on complex coding tasks with minimal human guidance. Whether you need to create a new feature, fix a bug, or develop an entire project from scratch, Devika is here to assist you.
tribe
Tribe AI is a low code tool designed to rapidly build and coordinate multi-agent teams. It leverages the langgraph framework to customize and coordinate teams of agents, allowing tasks to be split among agents with different strengths for faster and better problem-solving. The tool supports persistent conversations, observability, tool calling, human-in-the-loop functionality, easy deployment with Docker, and multi-tenancy for managing multiple users and teams.
Dough
Dough is a tool for crafting videos with AI, allowing users to guide video generations with precision using images and example videos. Users can create guidance frames, assemble shots, and animate them by defining parameters and selecting guidance videos. The tool aims to help users make beautiful and unique video creations, providing control over the generation process. Setup instructions are available for Linux and Windows platforms, with detailed steps for installation and running the app.

Open_Data_QnA
Open Data QnA is a Python library that allows users to interact with their PostgreSQL or BigQuery databases in a conversational manner, without needing to write SQL queries. The library leverages Large Language Models (LLMs) to bridge the gap between human language and database queries, enabling users to ask questions in natural language and receive informative responses. It offers features such as conversational querying with multiturn support, table grouping, multi schema/dataset support, SQL generation, query refinement, natural language responses, visualizations, and extensibility. The library is built on a modular design and supports various components like Database Connectors, Vector Stores, and Agents for SQL generation, validation, debugging, descriptions, embeddings, responses, and visualizations.

Instrukt
Instrukt is a terminal-based AI integrated environment that allows users to create and instruct modular AI agents, generate document indexes for question-answering, and attach tools to any agent. It provides a platform for users to interact with AI agents in natural language and run them inside secure containers for performing tasks. The tool supports custom AI agents, chat with code and documents, tools customization, prompt console for quick interaction, LangChain ecosystem integration, secure containers for agent execution, and developer console for debugging and introspection. Instrukt aims to make AI accessible to everyone by providing tools that empower users without relying on external APIs and services.
turboseek
TurboSeek is an open source AI search engine powered by Together.ai. It utilizes Next.js with Tailwind for the app router, Together AI for LLM inference, Mixtral 8x7B & Llama-3 for the LLMs, Bing for the search API, Helicone for observability, and Plausible for website analytics. The tool takes a user's question, queries the Bing search API for top results, scrapes text from the links, sends the question and context to Mixtral-8x7B, and generates follow-up questions using Llama-3-8B. Future tasks include optimizing source parsing, ignoring video links, adding regeneration option, ensuring proper citations, enabling sharing, implementing scrolling during answers, fixing hard refresh, adding caching with upstash redis, incorporating advanced RAG techniques, and adding authentication with Clerk and postgres/prisma.
StoryToolkitAI
StoryToolkitAI is a film editing tool that utilizes AI to transcribe, index scenes, search through footage, and create stories. It offers features like full video indexing, automatic transcriptions and translations, compatibility with OpenAI GPT and ollama, story editor for screenplay writing, speaker detection, project file management, and more. It integrates with DaVinci Resolve Studio 18 and offers planned features like automatic topic classification and integration with other AI tools. The tool is developed by Octavian Mot and is actively being updated with new features based on user needs and feedback.

Perplexica
Perplexica is an open-source AI-powered search engine that utilizes advanced machine learning algorithms to provide clear answers with sources cited. It offers various modes like Copilot Mode, Normal Mode, and Focus Modes for specific types of questions. Perplexica ensures up-to-date information by using SearxNG metasearch engine. It also features image and video search capabilities and upcoming features include finalizing Copilot Mode and adding Discover and History Saving features.
OrionChat
Orion is a web-based chat interface that simplifies interactions with multiple AI model providers. It provides a unified platform for chatting and exploring various large language models (LLMs) such as Ollama, OpenAI (GPT model), Cohere (Command-r models), Google (Gemini models), Anthropic (Claude models), Groq Inc., Cerebras, and SambaNova. Users can easily navigate and assess different AI models through an intuitive, user-friendly interface. Orion offers features like browser-based access, code execution with Google Gemini, text-to-speech (TTS), speech-to-text (STT), seamless integration with multiple AI models, customizable system prompts, language translation tasks, document uploads for analysis, and more. API keys are stored locally, and requests are sent directly to official providers' APIs without external proxies.
local_multimodal_ai_chat
Local Multimodal AI Chat is a hands-on project that teaches you how to build a multimodal chat application. It integrates different AI models to handle audio, images, and PDFs in a single chat interface. This project is perfect for anyone interested in AI and software development who wants to gain practical experience with these technologies.
litlytics
LitLytics is an affordable analytics platform leveraging LLMs for automated data analysis. It simplifies analytics for teams without data scientists, generates custom pipelines, and allows customization. Cost-efficient with low data processing costs. Scalable and flexible, works with CSV, PDF, and plain text data formats.

crawlee-python
Crawlee-python is a web scraping and browser automation library that covers crawling and scraping end-to-end, helping users build reliable scrapers fast. It allows users to crawl the web for links, scrape data, and store it in machine-readable formats without worrying about technical details. With rich configuration options, users can customize almost any aspect of Crawlee to suit their project's needs.
For similar tasks
pdftochat
PDFToChat is a tool that allows users to chat with their PDF documents in seconds. It is powered by Together AI and Pinecone, utilizing a tech stack including Next.js, Mixtral, M2 Bert, LangChain.js, MongoDB Atlas, Bytescale, Vercel, Clerk, and Tailwind CSS. Users can deploy the tool to Vercel or any other host by setting up Together.ai, MongoDB Atlas database, Bytescale, Clerk, and Vercel. The tool enables users to interact with PDFs through chat, with future tasks including adding features like trash icon for deleting PDFs, exploring different embedding models, implementing auto scrolling, improving replies, benchmarking accuracy, researching chunking and retrieval best practices, adding demo video, upgrading to Next.js 14, adding analytics, customizing tailwind prose, saving chats in postgres DB, compressing large PDFs, implementing custom uploader, session tracking, error handling, and support for images in PDFs.
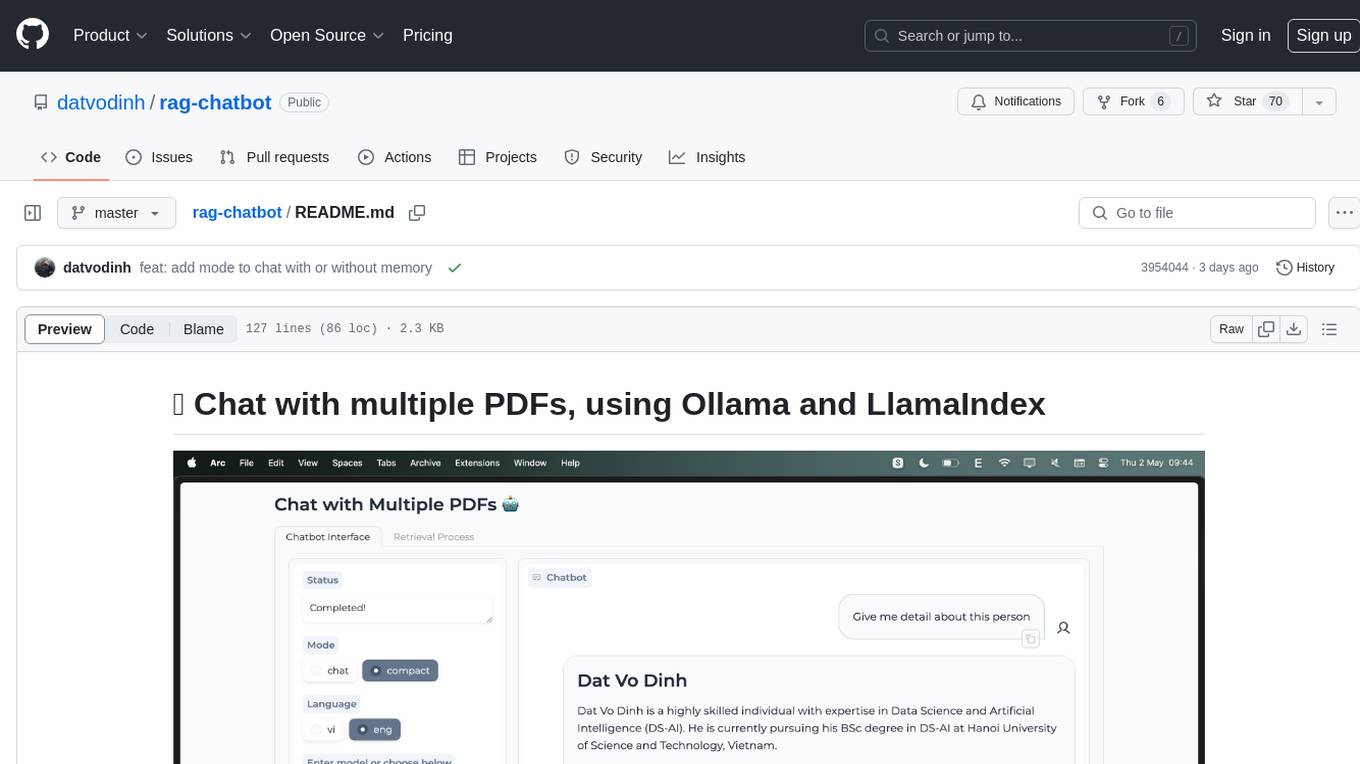
rag-chatbot
rag-chatbot is a tool that allows users to chat with multiple PDFs using Ollama and LlamaIndex. It provides an easy setup for running on local machines or Kaggle notebooks. Users can leverage models from Huggingface and Ollama, process multiple PDF inputs, and chat in multiple languages. The tool offers a simple UI with Gradio, supporting chat with history and QA modes. Setup instructions are provided for both Kaggle and local environments, including installation steps for Docker, Ollama, Ngrok, and the rag_chatbot package. Users can run the tool locally and access it via a web interface. Future enhancements include adding evaluation, better embedding models, knowledge graph support, improved document processing, MLX model integration, and Corrective RAG.
END-TO-END-GENERATIVE-AI-PROJECTS
The 'END TO END GENERATIVE AI PROJECTS' repository is a collection of awesome industry projects utilizing Large Language Models (LLM) for various tasks such as chat applications with PDFs, image to speech generation, video transcribing and summarizing, resume tracking, text to SQL conversion, invoice extraction, medical chatbot, financial stock analysis, and more. The projects showcase the deployment of LLM models like Google Gemini Pro, HuggingFace Models, OpenAI GPT, and technologies such as Langchain, Streamlit, LLaMA2, LLaMAindex, and more. The repository aims to provide end-to-end solutions for different AI applications.
llama-index
This repository, llama-index, contains a collection of apps powered by LlamaIndex. LlamaIndex is an open-source project that provides a simple interface between LLMs and external data sources like APIs, PDFs, SQL etc. It provides indices over structured and unstructured data, helping to abstract away the differences across data sources. The repository includes apps like chat-with-pdf and summarize-url, showcasing the capabilities of LlamaIndex in interacting with PDFs and summarizing URLs.

papersgpt-for-zotero
PapersGPT For Zotero is an AI plugin that enhances papers reading and research efficiency by integrating cutting-edge LLMs and offering seamless Zotero integration. Users can ask questions, extract insights, and converse with PDFs directly, making it a powerful research assistant for scholars, researchers, and anyone dealing with large amounts of text in PDF format. The plugin ensures privacy and data safety by using locally stored models and modules, with the ability to switch between different models easily. It provides a user-friendly interface for managing and chatting documents within Zotero, making research tasks more streamlined and productive.
For similar jobs

asreview
The ASReview project implements active learning for systematic reviews, utilizing AI-aided pipelines to assist in finding relevant texts for search tasks. It accelerates the screening of textual data with minimal human input, saving time and increasing output quality. The software offers three modes: Oracle for interactive screening, Exploration for teaching purposes, and Simulation for evaluating active learning models. ASReview LAB is designed to support decision-making in any discipline or industry by improving efficiency and transparency in screening large amounts of textual data.
NewEraAI-Papers
The NewEraAI-Papers repository provides links to collections of influential and interesting research papers from top AI conferences, along with open-source code to promote reproducibility and provide detailed implementation insights beyond the scope of the article. Users can stay up to date with the latest advances in AI research by exploring this repository. Contributions to improve the completeness of the list are welcomed, and users can create pull requests, open issues, or contact the repository owner via email to enhance the repository further.
cltk
The Classical Language Toolkit (CLTK) is a Python library that provides natural language processing (NLP) capabilities for pre-modern languages. It offers a modular processing pipeline with pre-configured defaults and supports almost 20 languages. Users can install the latest version using pip and access detailed documentation on the official website. The toolkit is designed to meet the unique needs of researchers working with historical languages, filling a void in the NLP landscape that often neglects non-spoken languages and different research goals.
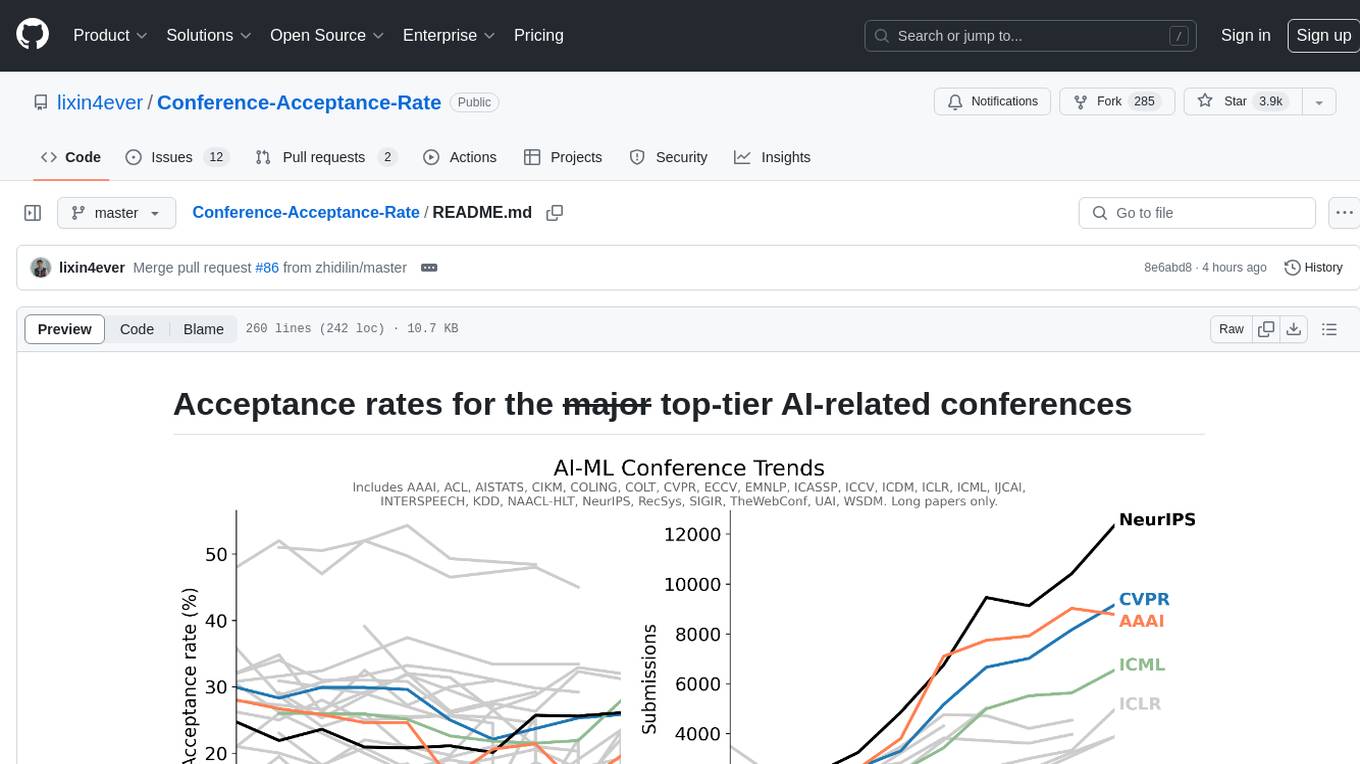
Conference-Acceptance-Rate
The 'Conference-Acceptance-Rate' repository provides acceptance rates for top-tier AI-related conferences in the fields of Natural Language Processing, Computational Linguistics, Computer Vision, Pattern Recognition, Machine Learning, Learning Theory, Artificial Intelligence, Data Mining, Information Retrieval, Speech Processing, and Signal Processing. The data includes acceptance rates for long papers and short papers over several years for each conference, allowing researchers to track trends and make informed decisions about where to submit their work.
pdftochat
PDFToChat is a tool that allows users to chat with their PDF documents in seconds. It is powered by Together AI and Pinecone, utilizing a tech stack including Next.js, Mixtral, M2 Bert, LangChain.js, MongoDB Atlas, Bytescale, Vercel, Clerk, and Tailwind CSS. Users can deploy the tool to Vercel or any other host by setting up Together.ai, MongoDB Atlas database, Bytescale, Clerk, and Vercel. The tool enables users to interact with PDFs through chat, with future tasks including adding features like trash icon for deleting PDFs, exploring different embedding models, implementing auto scrolling, improving replies, benchmarking accuracy, researching chunking and retrieval best practices, adding demo video, upgrading to Next.js 14, adding analytics, customizing tailwind prose, saving chats in postgres DB, compressing large PDFs, implementing custom uploader, session tracking, error handling, and support for images in PDFs.

tods-arxiv-daily-paper
This repository provides a tool for fetching and summarizing daily papers from the arXiv repository. It allows users to stay updated with the latest research in various fields by automatically retrieving and summarizing papers on a daily basis. The tool simplifies the process of accessing and digesting academic papers, making it easier for researchers and enthusiasts to keep track of new developments in their areas of interest.
Awesome-LLM-Strawberry
Awesome LLM Strawberry is a collection of research papers and blogs related to OpenAI Strawberry(o1) and Reasoning. The repository is continuously updated to track the frontier of LLM Reasoning.
Call-for-Reviewers
The `Call-for-Reviewers` repository aims to collect the latest 'call for reviewers' links from various top CS/ML/AI conferences/journals. It provides an opportunity for individuals in the computer/ machine learning/ artificial intelligence fields to gain review experience for applying for NIW/H1B/EB1 or enhancing their CV. The repository helps users stay updated with the latest research trends and engage with the academic community.